Initialization is Half the Battle: Generating Diverse Images from a Guidance Potential Posterior
Pith reviewed 2026-06-28 15:17 UTC · model grok-4.3
The pith
Selecting initial noise from a guidance potential posterior re-weights diffusion trajectories toward diversity-rich regions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
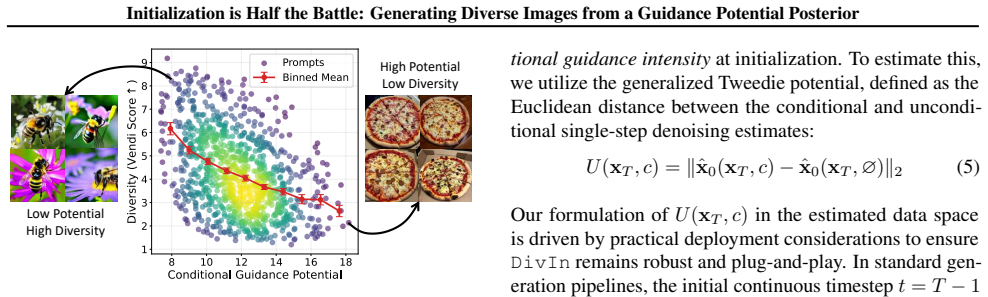
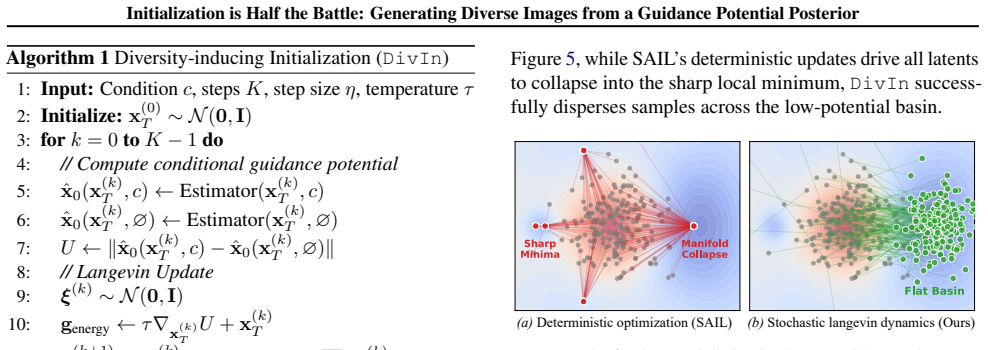
We formulate selecting the initial noise from a guidance potential posterior, which effectively re-weights the prior towards diversity-rich regions. To sample from this distribution efficiently, we introduce Diversity-inducing Initialization (DivIn), which leverages Langevin dynamics to actively navigate the initialization landscape, steering initial noise away from collapsing regions while anchoring them to the valid data manifold. Our method serves as an inference-time diversity enhancement compatible with both diffusion and flow matching models.
What carries the argument
The guidance potential posterior over initial noise, sampled by Langevin dynamics inside DivIn to steer away from mode-collapse basins.
If this is right
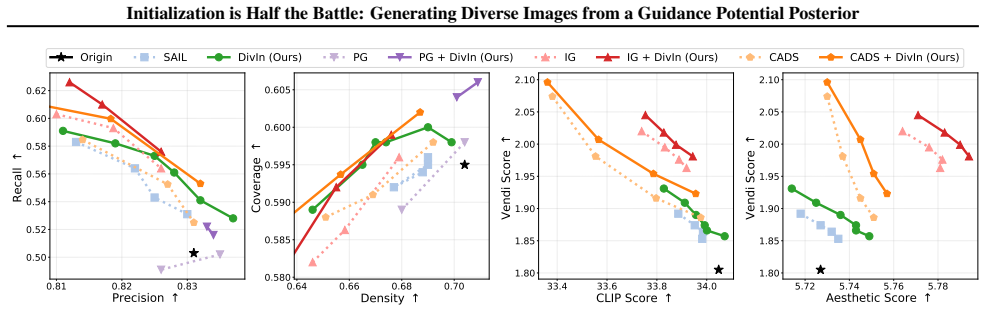
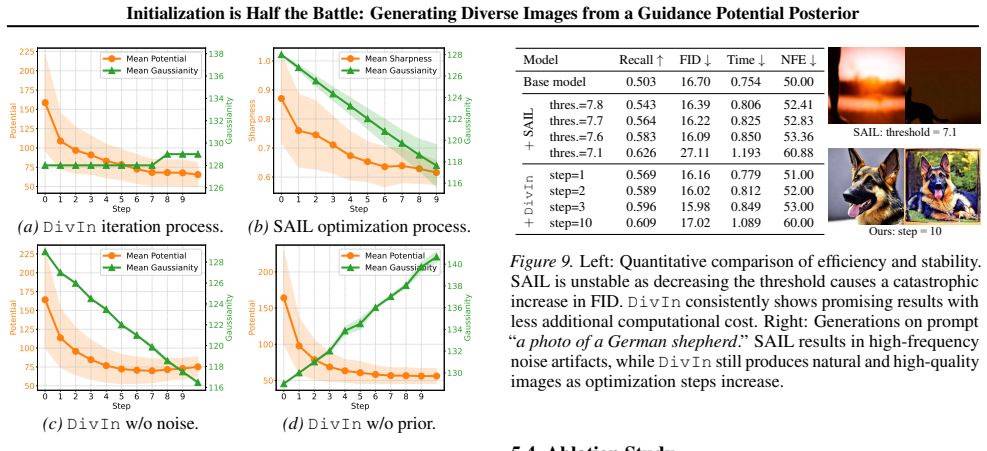
- DivIn raises diversity scores in both class-conditional and text-conditional image generation while preserving sample quality.
- The method applies unchanged to both diffusion and flow-matching generators.
- Because DivIn acts only at initialization, it can be stacked with any trajectory-level diversity technique to expand the achievable diversity-quality frontier.
- The re-weighting effect is achieved without retraining the underlying generative model.
Where Pith is reading between the lines
- If the guidance potential can be estimated from a small number of forward passes, DivIn could be made cheaper for very large models.
- The same initialization logic might apply to other iterative generative processes whose early steps determine later mode selection.
- Measuring the correlation between guidance potential values and empirical mode frequencies would give a direct diagnostic for when the method is most needed.
Load-bearing premise
Standard Gaussian initialization is agnostic to the guidance potential landscape and therefore drives trajectories into a small number of dominant modes.
What would settle it
Generate a large set of images with DivIn and the baseline Gaussian start on the same model and prompts; if the number of distinct modes or recall metric shows no reliable increase while fidelity metrics stay comparable, the central claim is falsified.
Figures




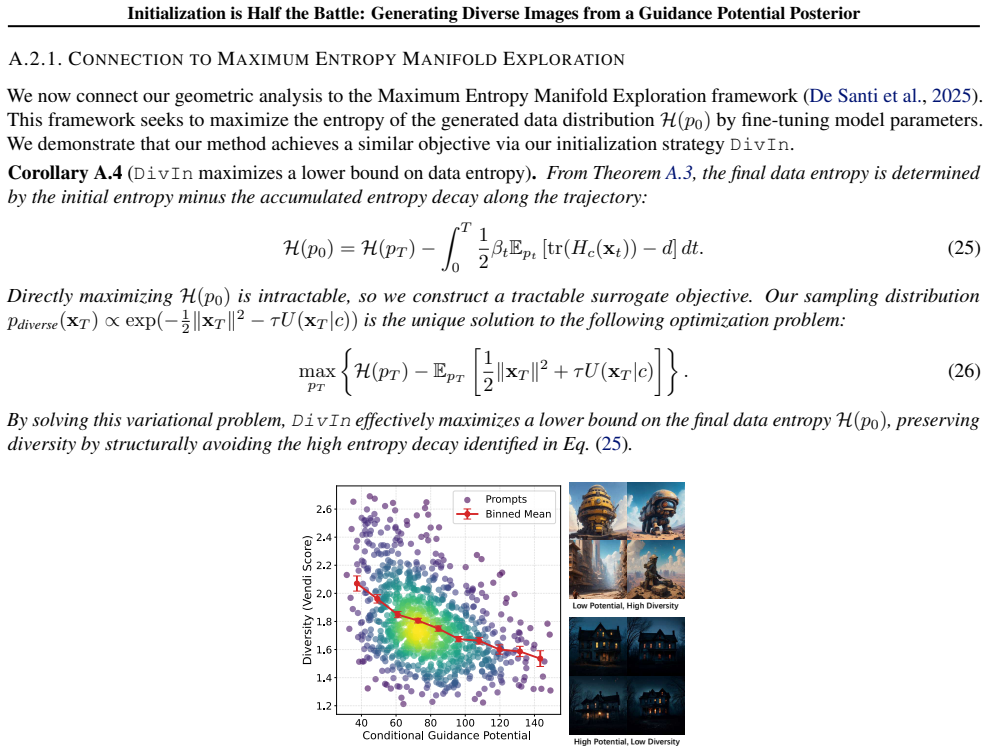
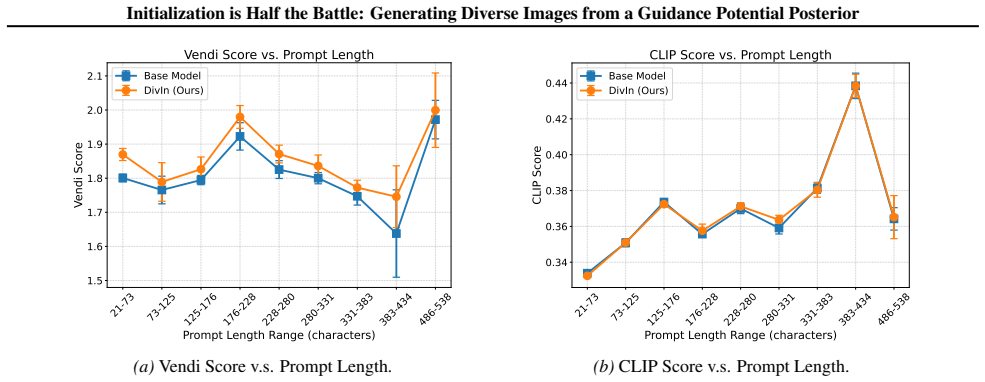
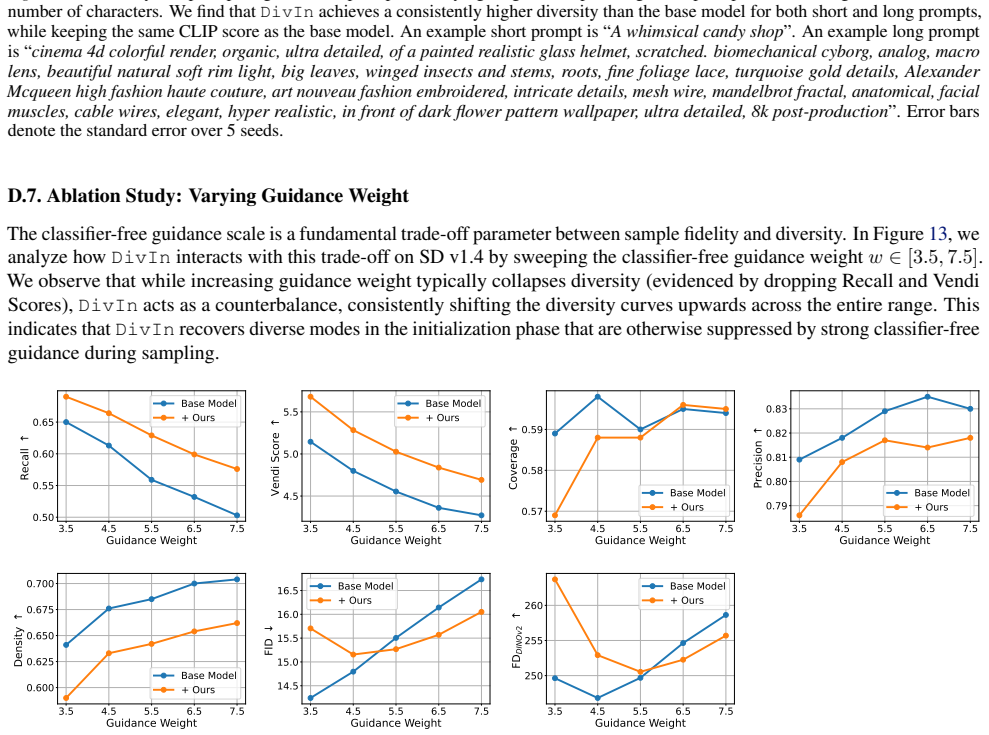

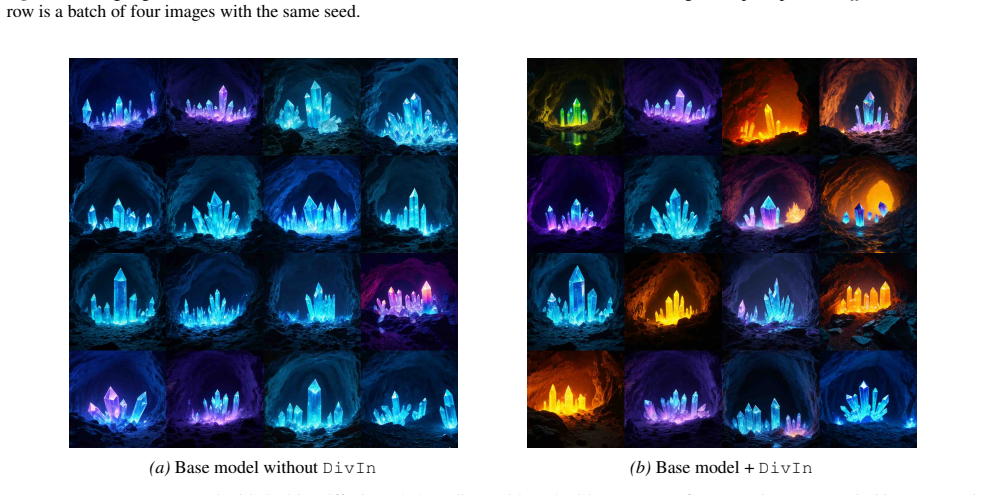






read the original abstract
Despite the remarkable fidelity of generative models, they frequently suffer from mode collapse. Existing strategies for enhancing diversity predominantly focus on intervening during the generation trajectory. We identify a critical oversight that the standard Gaussian initialization often causes trajectories to collapse into dominant modes because it is agnostic to the guidance potential landscape. In this work, we formulate selecting the initial noise from a guidance potential posterior, which effectively re-weights the prior towards diversity-rich regions. To sample from this distribution efficiently, we introduce Diversity-inducing Initialization (DivIn), which leverages Langevin dynamics to actively navigate the initialization landscape, steering initial noise away from collapsing regions while anchoring them to the valid data manifold. Our method serves as an inference-time diversity enhancement compatible with both diffusion and flow matching models. Extensive experiments show that DivIn exhibits a superior performance in both class-to-image and text-to-image scenarios. Furthermore, we highlight that as DivIn is orthogonal to trajectory-based methods, combining them significantly expands the diversity-quality Pareto frontier beyond what either achieves in isolation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard Gaussian initialization in diffusion and flow matching models leads to mode collapse because it ignores the guidance potential landscape. It proposes sampling initial noise from a guidance potential posterior via Langevin dynamics in the DivIn method to re-weight the prior toward diversity-rich regions while remaining on the data manifold. The approach is presented as an inference-time technique orthogonal to trajectory-based diversity methods, compatible with both diffusion and flow matching, and supported by experiments showing superior performance in class-to-image and text-to-image generation, with combinations expanding the diversity-quality Pareto frontier.
Significance. If the empirical results hold, this provides a practical, orthogonal inference-time lever for diversity that can be combined with existing trajectory interventions. The compatibility with both diffusion and flow matching frameworks and the explicit focus on initialization as a source of mode collapse are strengths. The use of Langevin dynamics for navigating the initialization landscape is a coherent application of established sampling tools.
minor comments (2)
- [Abstract] Abstract: the high-level description of the guidance potential posterior and DivIn does not include even a brief equation or pseudocode sketch, which would help readers immediately grasp the re-weighting mechanism.
- The manuscript would benefit from an explicit statement of the computational cost of the Langevin sampling step relative to standard initialization, as this is relevant for practical adoption.
Simulated Author's Rebuttal
We thank the referee for their thoughtful summary and positive assessment of our work, including recognition of DivIn as an orthogonal inference-time approach compatible with both diffusion and flow matching. We appreciate the recommendation for minor revision.
Circularity Check
No significant circularity identified
full rationale
The paper presents a methodological proposal for re-weighting initial noise via a guidance potential posterior sampled by Langevin dynamics (DivIn). No equations, fitted parameters, or derivations are visible in the provided text that reduce the claimed diversity improvement to a self-definition, a renamed input, or a self-citation chain. The central claim is framed as an empirical inference-time technique whose validity rests on external experiments rather than tautological reduction to its own inputs. The derivation chain is therefore self-contained against the listed circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Selective amnesia: A continual learning approach to forgetting in deep generative models , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Erasing concepts from diffusion models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[3]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Ablating concepts in text-to-image diffusion models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[4]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Unified concept editing in diffusion models , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[5]
The Twelfth International Conference on Learning Representations , year=
SalUn: Empowering Machine Unlearning via Gradient-based Weight Saliency in Both Image Classification and Generation , author=. The Twelfth International Conference on Learning Representations , year=
-
[6]
arXiv preprint arXiv:2405.15234 , year=
Defensive Unlearning with Adversarial Training for Robust Concept Erasure in Diffusion Models , author=. arXiv preprint arXiv:2405.15234 , year=
-
[7]
arXiv preprint arXiv:2402.11846 , year=
UnlearnCanvas: A Stylized Image Dataset to Benchmark Machine Unlearning for Diffusion Models , author=. arXiv preprint arXiv:2402.11846 , year=
-
[8]
arXiv preprint arXiv:2404.15146 , year=
Rethinking llm memorization through the lens of adversarial compression , author=. arXiv preprint arXiv:2404.15146 , year=
-
[9]
arXiv preprint arXiv:2405.03097 , year=
To Each (Textual Sequence) Its Own: Improving Memorized-Data Unlearning in Large Language Models , author=. arXiv preprint arXiv:2405.03097 , year=
-
[10]
arXiv preprint arXiv:2406.01257 , year=
What makes unlearning hard and what to do about it , author=. arXiv preprint arXiv:2406.01257 , year=
-
[11]
arXiv preprint arXiv:2406.07698 , year=
Label Smoothing Improves Machine Unlearning , author=. arXiv preprint arXiv:2406.07698 , year=
-
[12]
Advances in Neural Information Processing Systems , volume=
Doremi: Optimizing data mixtures speeds up language model pretraining , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[14]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[15]
Information , volume=
Fastai: a layered API for deep learning , author=. Information , volume=. 2020 , publisher=
2020
-
[16]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[17]
Learning multiple layers of features from tiny images , author=
-
[18]
Reading digits in natural images with unsupervised feature learning , author=
-
[19]
arXiv preprint arXiv:2108.11577 , year=
Machine unlearning of features and labels , author=. arXiv preprint arXiv:2108.11577 , year=
-
[20]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Eternal sunshine of the spotless net: Selective forgetting in deep networks , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[21]
2022 IEEE 7th European Symposium on Security and Privacy (EuroS&P) , pages=
Unrolling sgd: Understanding factors influencing machine unlearning , author=. 2022 IEEE 7th European Symposium on Security and Privacy (EuroS&P) , pages=. 2022 , organization=
2022
-
[22]
International conference on machine learning , pages=
Understanding black-box predictions via influence functions , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[23]
International Conference on Artificial Intelligence and Statistics , pages=
Approximate data deletion from machine learning models , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2021 , organization=
2021
-
[24]
arXiv preprint arXiv:2303.17591 , year=
Forget-me-not: Learning to forget in text-to-image diffusion models , author=. arXiv preprint arXiv:2303.17591 , year=
-
[25]
arXiv preprint arXiv:2403.07362 , year=
Fan, Chongyu and Liu, Jiancheng and Hero, Alfred and Liu, Sijia , title=. arXiv preprint arXiv:2403.07362 , year=
-
[26]
2021 IEEE Symposium on Security and Privacy (SP) , pages=
Machine unlearning , author=. 2021 IEEE Symposium on Security and Privacy (SP) , pages=. 2021 , organization=
2021
-
[27]
32nd USENIX Security Symposium (USENIX Security 23) , pages=
Extracting training data from diffusion models , author=. 32nd USENIX Security Symposium (USENIX Security 23) , pages=
-
[28]
In���� �������� ���������� �� �������� ������ ��� ������� ����������� ������
Gowthami Somepalli and Vasu Singla and Micah Goldblum and Jonas Geiping and Tom Goldstein , title =. 2023 , url =. doi:10.1109/CVPR52729.2023.00586 , timestamp =
-
[29]
32nd USENIX Security Symposium (USENIX Security 23) , pages=
Glaze: Protecting artists from style mimicry by \ Text-to-Image \ models , author=. 32nd USENIX Security Symposium (USENIX Security 23) , pages=
-
[30]
arXiv preprint arXiv:2210.04610 , year=
Red-teaming the stable diffusion safety filter , author=. arXiv preprint arXiv:2210.04610 , year=
-
[31]
Advances in Neural Information Processing Systems , volume=
Laion-5b: An open large-scale dataset for training next generation image-text models , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Advances in neural information processing systems , volume=
Making ai forget you: Data deletion in machine learning , author=. Advances in neural information processing systems , volume=
-
[33]
Algorithmic Learning Theory , pages=
Descent-to-delete: Gradient-based methods for machine unlearning , author=. Algorithmic Learning Theory , pages=. 2021 , organization=
2021
-
[34]
Conference on Learning Theory , pages=
Machine unlearning via algorithmic stability , author=. Conference on Learning Theory , pages=. 2021 , organization=
2021
-
[35]
Advances in Neural Information Processing Systems , volume=
Remember what you want to forget: Algorithms for machine unlearning , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
arXiv preprint arXiv:1911.03030 , year=
Certified data removal from machine learning models , author=. arXiv preprint arXiv:1911.03030 , year=
arXiv 1911
-
[37]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Boundary unlearning: Rapid forgetting of deep networks via shifting the decision boundary , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[38]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[39]
Advances in Neural Information Processing Systems , volume=
Model sparsity can simplify machine unlearning , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
International Conference on Machine Learning , pages=
On provable copyright protection for generative models , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[41]
Adversarial Example Does Good: Preventing Painting Imitation from Diffusion Models via Adversarial Examples , booktitle =
Chumeng Liang and Xiaoyu Wu and Yang Hua and Jiaru Zhang and Yiming Xue and Tao Song and Zhengui Xue and Ruhui Ma and Haibing Guan , editor =. Adversarial Example Does Good: Preventing Painting Imitation from Diffusion Models via Adversarial Examples , booktitle =. 2023 , url =
2023
-
[42]
arXiv preprint arXiv:2305.12683 , year=
Mist: Towards Improved Adversarial Examples for Diffusion Models , author=. arXiv preprint arXiv:2305.12683 , year=
-
[43]
Raising the Cost of Malicious AI-Powered Image Editing , booktitle =
Hadi Salman and Alaa Khaddaj and Guillaume Leclerc and Andrew Ilyas and Aleksander Madry , editor =. Raising the Cost of Malicious AI-Powered Image Editing , booktitle =. 2023 , url =
2023
-
[44]
International Conference on Machine Learning , pages=
Certified Data Removal from Machine Learning Models , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[45]
Nudenet: Neural nets for nudity classification, detection and selective censoring , author=
-
[46]
2022 IEEE Symposium on Security and Privacy (SP) , pages=
Membership Inference Attacks From First Principles , author=. 2022 IEEE Symposium on Security and Privacy (SP) , pages=. 2022 , organization=
2022
-
[47]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Amnesiac machine learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[48]
arXiv preprint arXiv:2310.02238 , year=
Who's Harry Potter? Approximate Unlearning in LLMs , author=. arXiv preprint arXiv:2310.02238 , year=
-
[49]
Can Sensitive Information Be Deleted From
Vaidehi Patil and Peter Hase and Mohit Bansal , booktitle=. Can Sensitive Information Be Deleted From. 2024 , url=
2024
-
[50]
arXiv preprint arXiv:2310.10683 , year=
Large language model unlearning , author=. arXiv preprint arXiv:2310.10683 , year=
-
[51]
Nathaniel Li and Alexander Pan and Anjali Gopal and Summer Yue and Daniel Berrios and Alice Gatti and Justin D. Li and Ann-Kathrin Dombrowski and Shashwat Goel and Gabriel Mukobi and Nathan Helm-Burger and Rassin Lababidi and Lennart Justen and Andrew Bo Liu and Michael Chen and Isabelle Barrass and Oliver Zhang and Xiaoyuan Zhu and Rishub Tamirisa and Bh...
2024
-
[52]
Forty-first International Conference on Machine Learning , year=
In-Context Unlearning: Language Models as Few-Shot Unlearners , author=. Forty-first International Conference on Machine Learning , year=
-
[53]
For Now , author=
To Generate or Not? Safety-Driven Unlearned Diffusion Models Are Still Easy to Generate Unsafe Images... For Now , author=. European Conference on Computer Vision , pages=
-
[54]
Computer vision--ECCV 2014: 13th European conference, zurich, Switzerland, September 6-12, 2014, proceedings, part v 13 , pages=
Microsoft coco: Common objects in context , author=. Computer vision--ECCV 2014: 13th European conference, zurich, Switzerland, September 6-12, 2014, proceedings, part v 13 , pages=. 2014 , organization=
2014
-
[55]
The Thirteenth International Conference on Learning Representations , year=
Dynamic Loss-Based Sample Reweighting for Improved Large Language Model Pretraining , author=. The Thirteenth International Conference on Learning Representations , year=
-
[56]
Proceedings of the 35th International Conference on Machine Learning , pages =
Learning to Reweight Examples for Robust Deep Learning , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[57]
Proceedings of the IEEE international conference on computer vision , pages=
Focal loss for dense object detection , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[58]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Not All Tokens Are What You Need for Pretraining , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[59]
2024 , editor =
Fan, Simin and Pagliardini, Matteo and Jaggi, Martin , booktitle =. 2024 , editor =
2024
-
[60]
arXiv preprint arXiv:1910.00762 , year=
Accelerating deep learning by focusing on the biggest losers , author=. arXiv preprint arXiv:1910.00762 , year=
arXiv 1910
-
[61]
arXiv preprint arXiv:1511.06343 , year=
Online batch selection for faster training of neural networks , author=. arXiv preprint arXiv:1511.06343 , year=
-
[62]
International conference on machine learning , pages=
Not all samples are created equal: Deep learning with importance sampling , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[63]
International Conference on Learning Representations , year=
Geometry-aware Instance-reweighted Adversarial Training , author=. International Conference on Learning Representations , year=
-
[64]
Advances in Neural Information Processing Systems , volume=
Probabilistic margins for instance reweighting in adversarial training , author=. Advances in Neural Information Processing Systems , volume=
-
[65]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Are adversarial examples created equal? a learnable weighted minimax risk for robustness under non-uniform attacks , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[66]
Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics , pages=
Instance Weighting for Domain Adaptation in NLP , author=. Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics , pages=
-
[67]
Advances in neural information processing systems , volume=
Rethinking importance weighting for deep learning under distribution shift , author=. Advances in neural information processing systems , volume=
-
[68]
International Conference on Learning Representations , year=
Reweighting Augmented Samples by Minimizing the Maximal Expected Loss , author=. International Conference on Learning Representations , year=
-
[69]
CS 231N , volume=
Tiny imagenet visual recognition challenge , author=. CS 231N , volume=
-
[70]
The Twelfth International Conference on Learning Representations , year=
CADS: Unleashing the Diversity of Diffusion Models through Condition-Annealed Sampling , author=. The Twelfth International Conference on Learning Representations , year=
-
[71]
The Twelfth International Conference on Learning Representations , year=
Particle Guidance: non-IID Diverse Sampling with Diffusion Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[72]
Advances in Neural Information Processing Systems , volume=
Applying guidance in a limited interval improves sample and distribution quality in diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[73]
The Twelfth International Conference on Learning Representations , year=
Detecting, explaining, and mitigating memorization in diffusion models , author=. The Twelfth International Conference on Learning Representations , year=
-
[74]
Forty-second International Conference on Machine Learning , year=
Shielded Diffusion: Generating Novel and Diverse Images using Sparse Repellency , author=. Forty-second International Conference on Machine Learning , year=
-
[75]
Forty-second International Conference on Machine Learning , year=
Understanding and Mitigating Memorization in Generative Models via Sharpness of Probability Landscapes , author=. Forty-second International Conference on Machine Learning , year=
-
[76]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
DiverseFlow: Sample-Efficient Diverse Mode Coverage in Flows , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[77]
Forty-first international conference on machine learning , year=
Scaling rectified flow transformers for high-resolution image synthesis , author=. Forty-first international conference on machine learning , year=
-
[78]
Advances in neural information processing systems , volume=
Improved precision and recall metric for assessing generative models , author=. Advances in neural information processing systems , volume=
-
[79]
International conference on machine learning , pages=
Reliable fidelity and diversity metrics for generative models , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[80]
Advances in neural information processing systems , volume=
Gans trained by a two time-scale update rule converge to a local nash equilibrium , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.