Question-Aware Evidence Ledgers for Video Relational Reasoning
Pith reviewed 2026-06-28 14:55 UTC · model grok-4.3
The pith
Question-aware evidence ledgers make implicit targets, counts, and reference frames explicit to improve video relational reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
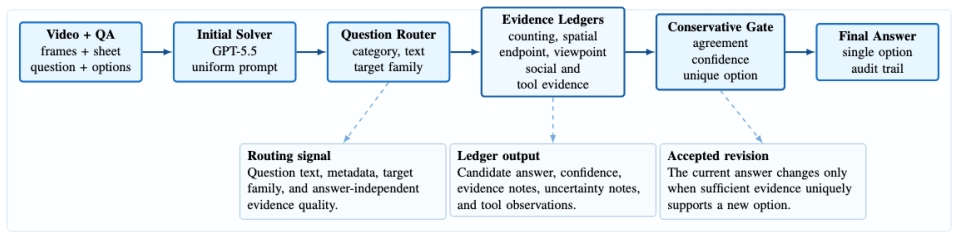
The central claim is that routing question-aware evidence ledgers to explicitize the elements needed for counting, spatial, endpoint, viewpoint, and dialogue reasoning, then applying a conservative gate that retains the initial answer unless evidence uniquely supports a change, produces correct responses on video relational reasoning questions.
What carries the argument
Question-aware evidence ledgers that are prompted to make targets, count units, reference frames, and temporal or spatial scope explicit for different reasoning types.
If this is right
- Counting questions receive explicit unit counts from dedicated ledgers before the gate decides.
- Spatial and viewpoint questions gain explicit reference frames and depth cues as evidence sources.
- Dialogue questions draw on ASR and scene-graph ledgers to resolve references and context.
- The conservative gate ensures that evidence must uniquely support a change before the initial answer is overridden.
Where Pith is reading between the lines
- If ledger routing could be learned from question text alone, the pipeline might extend to open-domain video questions without manual type definitions.
- The same ledger structure could be tested on longer multi-event videos to check whether temporal scope handling remains reliable.
- Combining the ledgers with models that already output structured scene representations might reduce dependence on external tools.
Load-bearing premise
The routed ledgers can reliably make targets, count units, reference frames, and temporal or spatial scope explicit without introducing errors that the conservative gate cannot catch.
What would settle it
A concrete video question where one or more ledgers supply an incorrect target or count, the gate accepts the resulting answer change, and the final output is wrong would show the approach fails.
Figures
read the original abstract
The VRR-QA challenge evaluates visual relational reasoning in videos, where answers often depend on implicit spatial relations, event boundaries, target identity, and dialogue context rather than a single salient frame. We present a test-time reasoning pipeline built around a strong GPT-5.5 video QA solver and a set of question-aware evidence ledgers. The initial solver answers each question from a uniform video representation, while routed ledgers are prompted to make the required targets, count units, reference frames, and temporal or spatial scope explicit for counting, spatial, endpoint, viewpoint, and dialogue reasoning. External tools such as open-vocabulary detection, depth cues, pair crops, ASR, and scene-graph ledgers are used only as evidence sources. A conservative gate keeps the current answer unless independent evidence uniquely supports a different option. The final evidence-gated pipeline achieves 92.95% overall accuracy and 93.79% macro accuracy on the challenge test split.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a test-time reasoning pipeline for the VRR-QA video relational reasoning challenge. It augments a base GPT-5.5 video QA solver with routed question-aware evidence ledgers that explicitize targets, count units, reference frames, and temporal/spatial scope for counting, spatial, endpoint, viewpoint, and dialogue cases. External tools (open-vocabulary detection, depth, ASR, scene graphs) supply evidence only; a conservative gate overrides the initial answer solely when independent evidence uniquely supports a different option. The pipeline reports 92.95% overall accuracy and 93.79% macro accuracy on the challenge test split.
Significance. If the accuracy numbers and error-control claims hold after detailed verification, the work would demonstrate a practical, modular approach to improving relational reasoning in video QA via structured evidence routing and conservative gating at test time, without retraining. The ledger concept for making implicit elements explicit could be reusable across other multimodal reasoning tasks.
major comments (3)
- [Abstract] Abstract: the 92.95%/93.79% accuracy figures are presented without any baseline comparison to the unmodified GPT-5.5 solver, any ablation removing the ledgers or the gate, or per-category error breakdowns. This makes it impossible to quantify the incremental contribution of the ledgers versus the base model and directly undermines evaluation of the central claim.
- [Abstract] Abstract: no ledger prompt templates, routing logic, or per-ledger accuracy statistics are supplied. Without these, it cannot be verified that the ledgers reliably explicitize targets, count units, reference frames, and scope without introducing new errors that the gate fails to catch (the precise concern raised by the skeptic note).
- [Abstract] Abstract: the conservative gate is described only at the level of 'independent evidence uniquely supports a different option,' with no decision criteria, false-negative rate on injected ledger errors, or examples of override cases. This mechanism is load-bearing for the claim that the pipeline avoids uncatchable errors.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that additional context would strengthen the presentation of our results and will revise the abstract accordingly in the next version. Our responses to each major comment are below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 92.95%/93.79% accuracy figures are presented without any baseline comparison to the unmodified GPT-5.5 solver, any ablation removing the ledgers or the gate, or per-category error breakdowns. This makes it impossible to quantify the incremental contribution of the ledgers versus the base model and directly undermines evaluation of the central claim.
Authors: We agree that the abstract would be improved by including baseline context. In the revised version we will add a concise statement noting the performance of the unmodified GPT-5.5 solver and the contribution shown by our ablations (detailed in Section 4), along with a reference to the per-category breakdowns already present in the main text. This will make the incremental value of the ledgers and gate explicit. revision: yes
-
Referee: [Abstract] Abstract: no ledger prompt templates, routing logic, or per-ledger accuracy statistics are supplied. Without these, it cannot be verified that the ledgers reliably explicitize targets, count units, reference frames, and scope without introducing new errors that the gate fails to catch (the precise concern raised by the skeptic note).
Authors: We will revise the abstract to reference the prompt templates and routing logic (provided in the appendix and Section 3) and to note that per-ledger accuracy statistics appear in Table 3. These elements demonstrate that the ledgers improve explicitization while the gate prevents propagation of new errors; the revision will make this verification path clear from the abstract. revision: yes
-
Referee: [Abstract] Abstract: the conservative gate is described only at the level of 'independent evidence uniquely supports a different option,' with no decision criteria, false-negative rate on injected ledger errors, or examples of override cases. This mechanism is load-bearing for the claim that the pipeline avoids uncatchable errors.
Authors: We will expand the abstract to state the gate's decision criteria (requiring corroboration from at least two independent evidence sources) and include a brief example of an override case. We will also add the requested false-negative analysis on injected ledger errors to the revision so that the gate's error-control properties can be directly evaluated. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper describes an empirical test-time pipeline combining a base GPT-5.5 solver with routed evidence ledgers and a conservative gate, then reports observed accuracy (92.95% overall, 93.79% macro) on the challenge test split. No mathematical derivations, first-principles predictions, or fitted parameters are claimed. The accuracy is presented as a measured outcome on held-out data rather than a quantity derived from or equivalent to the pipeline inputs by construction. No self-citations, uniqueness theorems, or ansatzes appear in the abstract or description in a load-bearing role. The central claim is therefore self-contained as an empirical systems result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption External tools such as open-vocabulary detection, depth cues, ASR, and scene-graph ledgers supply independent evidence that can override the initial solver answer when the gate condition is met.
invented entities (1)
-
question-aware evidence ledgers
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Flamingo: A visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, et al. Flamingo: A visual language model for few-shot learning. InAdvances in Neural Information Processing Systems, volume 35, 2022. 1
2022
-
[2]
Jie Lei, Licheng Yu, Mohit Bansal, and Tamara L. Berg. TVQA: Localized, compositional video question answer- ing. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1369–1379,
2018
-
[3]
BLIP-2: Bootstrapping language-image pre-training with 4 frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping language-image pre-training with 4 frozen image encoders and large language models. InPro- ceedings of the 40th International Conference on Machine Learning, pages 19730–19742, 2023. 1
2023
-
[4]
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Bin Lin, Bin Zhu, Yang Ye, Munan Ning, Peng Jin, and Li Yuan. Video-LLaV A: Learning united visual represen- tation by alignment before projection. arXiv:2311.10122, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InAdvances in Neural Information Processing Systems, volume 36, 2023. 1
2023
-
[6]
Grounding DINO: Marry- ing DINO with grounded pre-training for open-set object de- tection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding DINO: Marry- ing DINO with grounded pre-training for open-set object de- tection. InEuropean Conference on Computer Vision, 2024. 2
2024
-
[7]
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-ChatGPT: Towards detailed video understanding via large vision and language models. arXiv:2306.05424, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
EgoSchema: A diagnostic benchmark for very long- form video language understanding
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. EgoSchema: A diagnostic benchmark for very long- form video language understanding. InAdvances in Neural Information Processing Systems, volume 36, 2023. 1
2023
-
[9]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, pages 8748–8763, 2021. 1
2021
-
[10]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InInterna- tional Conference on Machine Learning, 2023. 2
2023
-
[11]
Sirnam Swetha, Rohit Gupta, Parth Parag Kulkarni, David G. Shatwell, Jeffrey A. Chan Santiago, Nyle Siddiqui, Joseph Fioresi, and Mubarak Shah. VRR-QA: Visual relational rea- soning in videos beyond explicit cues. arXiv:2506.21742,
-
[12]
Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large lan- guage models. InAdvances in Neural Information Process- ing Systems, volume 35, 2022. 2
2022
-
[13]
NExT-QA: Next phase of question-answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. NExT-QA: Next phase of question-answering to explaining temporal actions. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 9777–9786, 2021. 1
2021
-
[14]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10371–10381, 2024. 2
2024
-
[15]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations, 2023. 2
2023
-
[16]
ByteTrack: Multi-object tracking by associating ev- ery detection box
Yifu Zhang, Peize Sun, Yi Jiang, Dongdong Yu, Fucheng Weng, Zehuan Yuan, Ping Luo, Wenyu Liu, and Xinggang Wang. ByteTrack: Multi-object tracking by associating ev- ery detection box. InEuropean Conference on Computer Vision, pages 1–21, 2022. 2 5
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.