Why Not Hyperparameter-Friendly Optimisation? A Monotonic Adaptive Norm Rescaling Approach For Long-Tailed Recognition
Pith reviewed 2026-06-28 14:45 UTC · model grok-4.3
The pith
Enforcing monotonicity on per-class weight norms via PAVA eliminates regularization hyperparameters in long-tailed recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
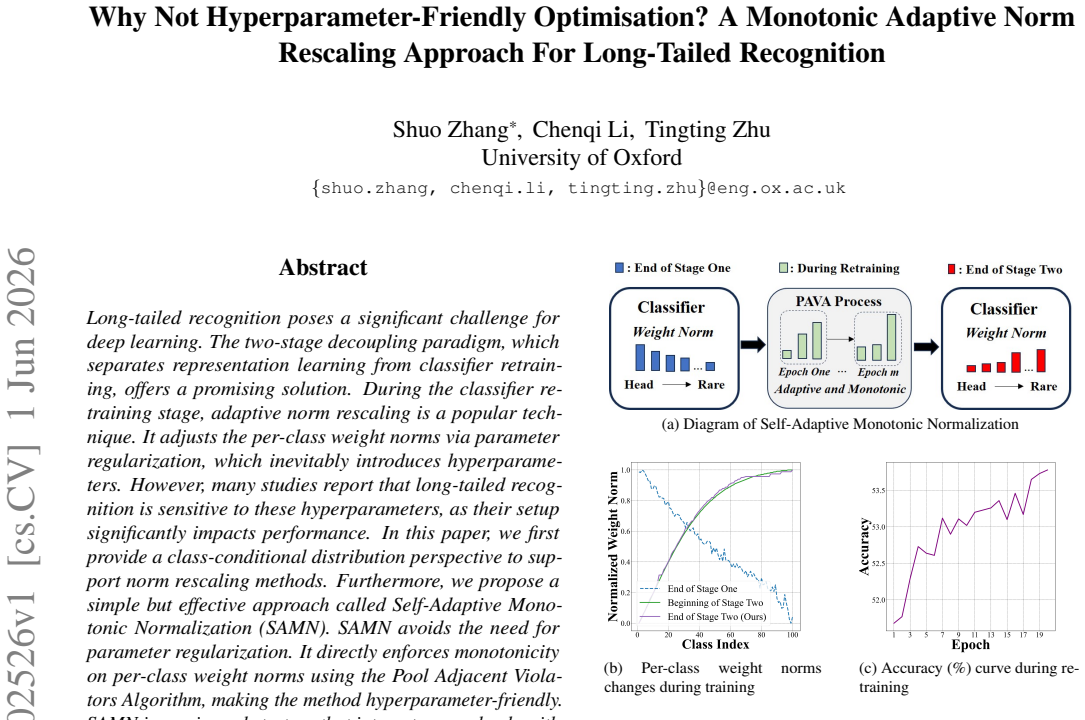
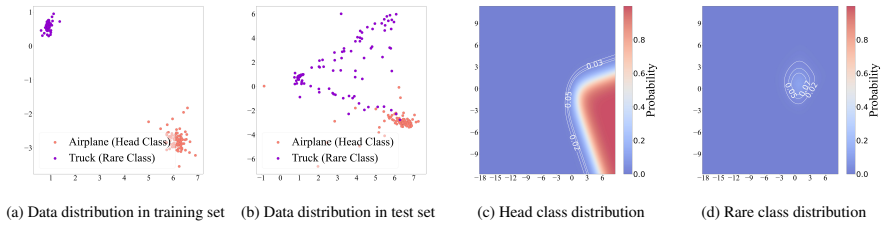
By applying the Pool Adjacent Violators Algorithm to enforce monotonicity directly on per-class weight norms, SAMN achieves the benefits of adaptive norm rescaling in a way that requires no parameter regularization or post-hoc tuning, as supported by the class-conditional distribution view, and acts as a universal enhancement for long-tailed recognition.
What carries the argument
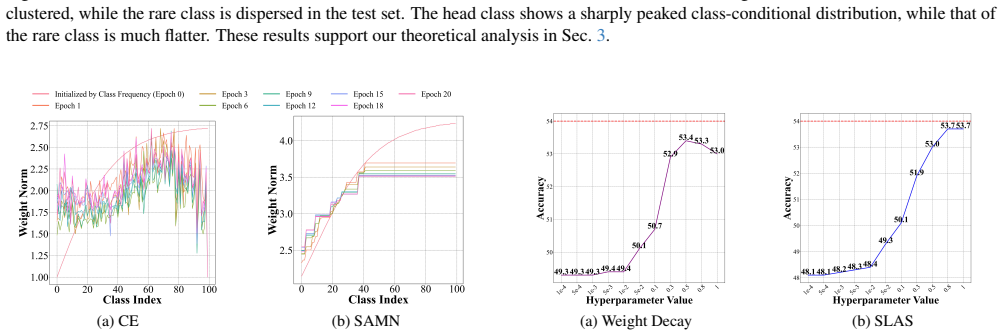
Self-Adaptive Monotonic Normalization (SAMN) that applies the Pool Adjacent Violators Algorithm to enforce monotonic per-class weight norms.
Load-bearing premise
That directly enforcing monotonic per-class weight norms via PAVA fully captures the benefits justified by the class-conditional distribution perspective without needing regularization.
What would settle it
An experiment demonstrating that SAMN fails to match or exceed the performance of carefully tuned regularization-based norm rescaling methods on multiple long-tailed datasets.
Figures
read the original abstract
Long-tailed recognition poses a significant challenge for deep learning. The two-stage decoupling paradigm, which separates representation learning from classifier retraining, offers a promising solution. During the classifier retraining stage, adaptive norm rescaling is a popular technique. It adjusts the per-class weight norms via parameter regularization, which inevitably introduces hyperparameters. However, many studies report that long-tailed recognition is sensitive to these hyperparameters, as their setup significantly impacts performance. In this paper, we first provide a class-conditional distribution perspective to support norm rescaling methods. Furthermore, we propose a simple but effective approach called Self-Adaptive Monotonic Normalization (SAMN). SAMN avoids the need for parameter regularization. It directly enforces monotonicity on per-class weight norms using the Pool Adjacent Violators Algorithm, making the method hyperparameter-friendly. SAMN is a universal strategy that integrates seamlessly with other methods for enhanced performance. Experiments on benchmark datasets demonstrate that our method significantly boosts long-tailed recognition performance, often achieving state-of-the-art results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that long-tailed recognition benefits from adaptive norm rescaling of per-class classifier weights during the second stage of the decoupling paradigm. It motivates this via a class-conditional distribution perspective, then replaces regularization-based rescaling (which requires hyperparameters) with Self-Adaptive Monotonic Normalization (SAMN): a direct projection onto the monotonic cone via the Pool Adjacent Violators Algorithm (PAVA). The resulting method is asserted to be hyperparameter-free, universal (integrates with other techniques), and empirically superior, often reaching SOTA on standard benchmarks.
Significance. If the central substitution is valid and the reported gains are reproducible, the contribution would be practically useful: it removes a known source of tuning sensitivity in long-tailed methods while preserving the norm-rescaling benefit. The universality claim, if substantiated by controlled ablations, would further increase impact.
major comments (2)
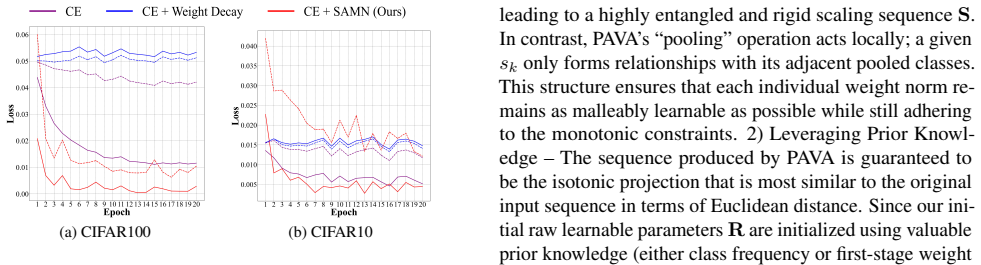
- [class-conditional distribution perspective and SAMN definition] The class-conditional distribution perspective is invoked to justify norm rescaling, yet the manuscript does not derive that the specific magnitudes produced by regularization are recovered (or even approximated) by the PAVA monotonic projection; only the ordering constraint is enforced. If magnitudes matter for matching the distribution-derived optimum, the claimed performance equivalence does not follow.
- [experimental section] No quantitative comparison is supplied showing that SAMN norms match or improve upon the regularization-derived norms on the same backbone and data; the experiments instead report end-to-end accuracy gains without isolating whether the monotonic projection alone accounts for the improvement or whether other factors (e.g., implicit regularization from PAVA) are at work.
minor comments (2)
- [abstract] The abstract states that SAMN 'often achieving state-of-the-art results' but supplies no dataset names, metrics, or baseline comparisons; the full experimental tables should be referenced already in the abstract for clarity.
- [method section] Notation for per-class weight norms and the precise input/output of the PAVA step should be defined with an equation before the algorithm description.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below with clarifications and indicate planned revisions.
read point-by-point responses
-
Referee: [class-conditional distribution perspective and SAMN definition] The class-conditional distribution perspective is invoked to justify norm rescaling, yet the manuscript does not derive that the specific magnitudes produced by regularization are recovered (or even approximated) by the PAVA monotonic projection; only the ordering constraint is enforced. If magnitudes matter for matching the distribution-derived optimum, the claimed performance equivalence does not follow.
Authors: The class-conditional distribution perspective is used to motivate why norm rescaling is beneficial, specifically by establishing that optimal per-class weight norms should increase monotonically with class frequency. Regularization-based methods achieve monotonicity indirectly via hyperparameter tuning. SAMN directly projects onto the monotonic cone with PAVA to enforce this ordering without hyperparameters. The manuscript does not claim that PAVA recovers the exact magnitudes from regularization; the emphasis is on the ordering constraint as the essential property. We will revise the text to make this distinction explicit and avoid any implication of magnitude equivalence. revision: partial
-
Referee: [experimental section] No quantitative comparison is supplied showing that SAMN norms match or improve upon the regularization-derived norms on the same backbone and data; the experiments instead report end-to-end accuracy gains without isolating whether the monotonic projection alone accounts for the improvement or whether other factors (e.g., implicit regularization from PAVA) are at work.
Authors: We agree that isolating the effect of the monotonic projection would strengthen the experimental section. In the revision we will add a quantitative comparison of the per-class weight norms produced by SAMN versus regularization-based rescaling on identical backbones and datasets, including tables or plots of the norms themselves. revision: yes
Circularity Check
No significant circularity; derivation self-contained against external benchmarks
full rationale
The paper motivates adaptive norm rescaling via a class-conditional distribution perspective, then substitutes a direct PAVA projection onto the monotonic cone for regularization. No quoted equation or step reduces the claimed optimum (or performance gain) by construction to a fitted parameter, self-cited prior result, or input quantity defined in terms of the output. The PAVA step is an independent algorithmic choice whose benefit is asserted via experiments on benchmarks, not definitional equivalence. Self-citations, if present, are not load-bearing for the central claim.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Class-conditional distributions provide a justification for norm rescaling that can be realized by monotonicity enforcement alone.
Reference graph
Works this paper leans on
-
[1]
CUDA: Curriculum of data augmentation for long-tailed recognition
Sumyeong Ahn, Jongwoo Ko, and Se-Young Yun. CUDA: Curriculum of data augmentation for long-tailed recognition. InThe Eleventh International Conference on Learning Repre- sentations, 2023. 1, 2, 7
2023
-
[2]
Long-tailed recognition via weight balancing
Shaden Alshammari, Yu-Xiong Wang, Deva Ramanan, and Shu Kong. Long-tailed recognition via weight balancing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 1, 2, 3, 4, 7
2022
-
[3]
Deep over-sampling frame- work for classifying imbalanced data
Shin Ando and Chun Yuan Huang. Deep over-sampling frame- work for classifying imbalanced data. InMachine Learning and Knowledge Discovery in Databases, 2017. 1, 2
2017
-
[4]
Miriam Ayer, H. D. Brunk, G. M. Ewing, W. T. Reid, and Edward Silverman. An empirical distribution function for sampling with incomplete information.The Annals of Mathe- matical Statistics, 26(4):641–647, 1955. 2, 4
1955
-
[5]
Learning imbalanced datasets with label- distribution-aware margin loss
Kaidi Cao, Colin Wei, Adrien Gaidon, Nikos Arechiga, and Tengyu Ma. Learning imbalanced datasets with label- distribution-aware margin loss. InAdvances in Neural Infor- mation Processing Systems, 2019. 7
2019
-
[6]
Chawla, Kevin W
Nitesh V . Chawla, Kevin W. Bowyer, Lawrence O. Hall, and W. Philip Kegelmeyer. Smote: synthetic minority over- sampling technique.Journal of Artificial Intelligence Re- search, 16(1):321–357, 2002. 1, 2
2002
-
[7]
Area: Adaptive reweighting via effective area for long-tailed classification
Xiaohua Chen, Yucan Zhou, Dayan Wu, Chule Yang, Bo Li, Qinghua Hu, and Weiping Wang. Area: Adaptive reweighting via effective area for long-tailed classification. InProceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023. 7
2023
-
[8]
Fea- ture space augmentation for long-tailed data.arXiv preprint arXiv:2008.03673, 2020
Peng Chu, Xiao Bian, Shaopeng Liu, and Haibin Ling. Fea- ture space augmentation for long-tailed data.arXiv preprint arXiv:2008.03673, 2020. 1, 2
-
[9]
Class-balanced loss based on effective number of samples
Yin Cui, Menglin Jia, Tsung-Yi Lin, Yang Song, and Serge Belongie. Class-balanced loss based on effective number of samples. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019. 1, 2
2019
-
[10]
Inverse weight-balancing for deep long-tailed learn- ing
Wenqi Dang, Zhou Yang, Weisheng Dong, Xin Li, and Guang- ming Shi. Inverse weight-balancing for deep long-tailed learn- ing. InProceedings of the AAAI Conference on Artificial Intelligence, 2024. 1, 2, 3, 4, 7
2024
-
[11]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. 12
2009
-
[12]
Global and local mixture consistency cumulative learning for long-tailed visual recognitions
Fei Du, Peng Yang, Qi Jia, Fengtao Nan, Xiaoting Chen, and Yun Yang. Global and local mixture consistency cumulative learning for long-tailed visual recognitions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 1, 2, 4, 7, 12
2023
-
[13]
Adaptive subgra- dient methods for online learning and stochastic optimization
John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgra- dient methods for online learning and stochastic optimization. The Journal of Machine Learning Research, page 2121–2159,
-
[14]
Comparing biases for minimal network construction with back-propagation
Stephen Hanson and Lorien Pratt. Comparing biases for minimal network construction with back-propagation. In Advances in Neural Information Processing Systems, 1988. 5, 6
1988
-
[15]
Naoya Hasegawa and Issei Sato. Exploring weight bal- ancing on long-tailed recognition problem.arXiv preprint arXiv:2305.16573, 2024. 7
-
[16]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. 5, 6, 7, 8, 12
2016
-
[17]
Distilling vir- tual examples for long-tailed recognition
Yin-Yin He, Jianxin Wu, and Xiu-Shen Wei. Distilling vir- tual examples for long-tailed recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021. 7
2021
-
[18]
Algorithms efficiency measurement on imbalanced data using geometric mean and cross vali- dation
Mustakim Al Helal, Mohammad Salman Haydar, and Seraj Al Mahmud Mostafa. Algorithms efficiency measurement on imbalanced data using geometric mean and cross vali- dation. In2016 International Workshop on Computational Intelligence (IWCI), 2016. 2, 3
2016
-
[19]
Decoupling representation and classifier for long-tailed recognition,
Bingyi Kang, Saining Xie, Marcus Rohrbach, Zhicheng Yan, Albert Gordo, Jiashi Feng, and Yannis Kalantidis. Decoupling representation and classifier for long-tailed recognition.arXiv preprint arXiv:1910.09217, 2019. 1, 2, 4, 7
-
[20]
Adjusting decision boundary for class imbalanced learning.IEEE Access, 8:81674–81685,
Byungju Kim and Junmo Kim. Adjusting decision boundary for class imbalanced learning.IEEE Access, 8:81674–81685,
-
[21]
Learning multiple lay- ers of features from tiny images.Master’s thesis, University of Tront, 2009
Alex Krizhevsky and Geoffrey Hinton. Learning multiple lay- ers of features from tiny images.Master’s thesis, University of Tront, 2009. 5, 8, 11
2009
-
[22]
Guillaume Lemaˆıtre, Fernando Nogueira, and Christos K. Aridas. Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning.Journal of Machine Learning Research, 18(17):1–5, 2017. 1, 2
2017
-
[23]
Jinyan Li, Simon Fong, Sabah Mohammed, Jinan Fiaidhi, Qian Chen, and Zhen Tan. Solving the under-fitting problem for decision tree algorithms by incremental swarm optimiza- tion in rare-event healthcare classification.Journal of Medical Imaging and Health Informatics, 6(4):1102–1110, 2016. 2, 3
2016
-
[24]
Wong, and Victor W
Jinyan Li, Simon Fong, Raymond K. Wong, and Victor W. Chu. Adaptive multi-objective swarm fusion for imbalanced data classification.Information Fusion, 39:1–24, 2018. 2, 3
2018
-
[25]
Long-tailed visual recognition via gaussian clouded logit adjustment
Mengke Li, Yiu-ming Cheung, and Yang Lu. Long-tailed visual recognition via gaussian clouded logit adjustment. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), 2022. 1, 2
2022
-
[26]
Metasaug: Meta semantic augmentation for long-tailed visual recognition
Shuang Li, Kaixiong Gong, Chi Harold Liu, Yulin Wang, Feng Qiao, and Xinjing Cheng. Metasaug: Meta semantic augmentation for long-tailed visual recognition. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021. 1, 2
2021
-
[27]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollar. Focal loss for dense object detection. InPro- ceedings of the IEEE International Conference on Computer Vision (ICCV), 2017. 1, 2, 7 9
2017
-
[28]
Exploratory undersampling for class-imbalance learning.IEEE Transac- tions on Systems, Man, and Cybernetics, Part B (Cybernetics), 39(2):539–550, 2009
Xu-Ying Liu, Jianxin Wu, and Zhi-Hua Zhou. Exploratory undersampling for class-imbalance learning.IEEE Transac- tions on Systems, Man, and Cybernetics, Part B (Cybernetics), 39(2):539–550, 2009. 1, 2
2009
-
[29]
Ziwei Liu, Zhongqi Miao, Xiaohang Zhan, Jiayun Wang, Bo- qing Gong, and Stella X. Yu. Large-scale long-tailed recogni- tion in an open world. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR),
-
[30]
SGDR: Stochastic Gradient Descent with Warm Restarts
Ilya Loshchilov and Frank Hutter. SGDR: stochastic gradient descent with restarts.arXiv preprint arXiv:1608.03983, 2016. 6, 12
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[31]
Long-tail learning via logit adjustment
Aditya Krishna Menon, Sadeep Jayasumana, Ankit Singh Rawat, Himanshu Jain, Andreas Veit, and Sanjiv Kumar. Long-tail learning via logit adjustment. InInternational Con- ference on Learning Representations, 2021. 7
2021
-
[32]
The majority can help the minority: Context-rich minority oversampling for long-tailed classi- fication
Seulki Park, Youngkyu Hong, Byeongho Heo, Sangdoo Yun, and Jin Young Choi. The majority can help the minority: Context-rich minority oversampling for long-tailed classi- fication. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 1, 2, 7
2022
-
[33]
Feature directions matter: Long-tailed learning via rotated balanced representa- tion
Gao Peifeng, Qianqian Xu, Peisong Wen, Zhiyong Yang, Huiyang Shao, and Qingming Huang. Feature directions matter: Long-tailed learning via rotated balanced representa- tion. InProceedings of the 40th International Conference on Machine Learning, 2023. 7
2023
-
[34]
Escaping saddle points for effective gen- eralization on class-imbalanced data
Harsh Rangwani, Sumukh K Aithal, Mayank Mishra, and Venkatesh Babu R. Escaping saddle points for effective gen- eralization on class-imbalanced data. InAdvances in Neural Information Processing Systems, 2022. 1, 2, 7
2022
-
[35]
Balanced meta-softmax for long- tailed visual recognition
Jiawei Ren, Cunjun Yu, shunan sheng, Xiao Ma, Haiyu Zhao, Shuai Yi, and hongsheng Li. Balanced meta-softmax for long- tailed visual recognition. InAdvances in Neural Information Processing Systems, 2020. 1, 2
2020
-
[36]
Diffult: How to make diffusion model useful for long-tail recognition
Jie Shao, Ke Zhu, Hanxiao Zhang, and Jianxin Wu. Diffult: How to make diffusion model useful for long-tail recognition. arXiv preprint arXiv:2403.05170, 2024. 1, 2, 7
-
[37]
How re-sampling helps for long-tail learning? InAdvances in Neural Information Processing Systems, 2023
Jiang-Xin Shi, Tong Wei, Yuke Xiang, and Yu-Feng Li. How re-sampling helps for long-tail learning? InAdvances in Neural Information Processing Systems, 2023. 1, 2, 7
2023
-
[38]
The inaturalist species classification and detection dataset
Grant Van Horn, Oisin Mac Aodha, Yang Song, Yin Cui, Chen Sun, Alex Shepard, Hartwig Adam, Pietro Perona, and Serge Belongie. The inaturalist species classification and detection dataset. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. 5, 11
2018
-
[39]
Long-tailed recognition by routing diverse distribution-aware experts
Xudong Wang, Long Lian, Zhongqi Miao, Ziwei Liu, and Stella Yu. Long-tailed recognition by routing diverse distribution-aware experts. InInternational Conference on Learning Representations, 2021. 1, 2, 7
2021
-
[40]
Margin calibration for long-tailed visual recognition
Yidong Wang, Bowen Zhang, Wenxin Hou, Zhen Wu, Jin- dong Wang, and Takahiro Shinozaki. Margin calibration for long-tailed visual recognition. InProceedings of The 14th Asian Conference on Machine Learning, 2023. 7
2023
-
[41]
A unified generalization analysis of re-weighting and logit-adjustment for imbalanced learning
Zitai Wang, Qianqian Xu, Zhiyong Yang, Yuan He, Xiaochun Cao, and Qingming Huang. A unified generalization analysis of re-weighting and logit-adjustment for imbalanced learning. InAdvances in Neural Information Processing Systems, 2023. 7
2023
-
[42]
Aggregated residual transformations for deep neural networks
Saining Xie, Ross Girshick, Piotr Dollar, Zhuowen Tu, and Kaiming He. Aggregated residual transformations for deep neural networks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. 7, 12
2017
-
[43]
Class-balanced regularization for long-tailed recognition.Neural Processing Letters, 56 (128):1–18, 2024
Yuge Xu and Chuanlong Lyu. Class-balanced regularization for long-tailed recognition.Neural Processing Letters, 56 (128):1–18, 2024. 1, 2, 3, 4
2024
-
[44]
Han-Jia Ye, Hong-You Chen, De-Chuan Zhan, and Wei-Lun Chao. Identifying and compensating for feature deviation in imbalanced deep learning.arXiv preprint arXiv:2001.01385,
-
[45]
Procrustean training for imbalanced deep learning
Han-Jia Ye, De-Chuan Zhan, and Wei-Lun Chao. Procrustean training for imbalanced deep learning. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021. 2, 3
2021
-
[46]
Bag of tricks for long-tailed visual recognition with deep convolutional neural networks
Yongshun Zhang, Xiu-Shen Wei, Boyan Zhou, and Jianxin Wu. Bag of tricks for long-tailed visual recognition with deep convolutional neural networks. InProceedings of the AAAI Conference on Artificial Intelligence, 2021. 7
2021
-
[47]
Self-supervised aggregation of diverse experts for test- agnostic long-tailed recognition
Yifan Zhang, Bryan Hooi, Lanqing Hong, and Jiashi Feng. Self-supervised aggregation of diverse experts for test- agnostic long-tailed recognition. InAdvances in Neural In- formation Processing Systems, 2022. 1, 2
2022
-
[48]
Deep long-tailed learning: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(9):10795–10816, 2023
Yifan Zhang, Bingyi Kang, Bryan Hooi, Shuicheng Yan, and Jiashi Feng. Deep long-tailed learning: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(9):10795–10816, 2023. 1
2023
-
[49]
Improv- ing calibration for long-tailed recognition
Zhisheng Zhong, Jiequan Cui, Shu Liu, and Jiaya Jia. Improv- ing calibration for long-tailed recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021. 1, 2, 4, 6, 7, 12
2021
-
[50]
Many” (nk > 100), “Medium
Boyan Zhou, Quan Cui, Xiu-Shen Wei, and Zhao-Min Chen. Bbn: Bilateral-branch network with cumulative learning for long-tailed visual recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 1, 2, 7 10 Why Not Hyperparameter-Friendly Optimisation? A Monotonic Adaptive Norm Rescaling Approach For Long-Ta...
2020
-
[51]
backbone, employing GLMC for first-stage training and SAMN for second-stage enhancement. Following [12], on ImageNet-LT, the first stage is trained for 135 epochs (batch size = 128, weight decay = 2e-4, learning rate = 0.1), and the second stage is finetuned for 20 epochs (batch size = 512, learning rate = 1e-5). On iNaturalist2018, the first stage is tra...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.