SimSD: Simple Speculative Decoding in Diffusion Language Models
Pith reviewed 2026-06-28 14:55 UTC · model grok-4.3
The pith
A plug-and-play masking strategy makes speculative decoding work with diffusion language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
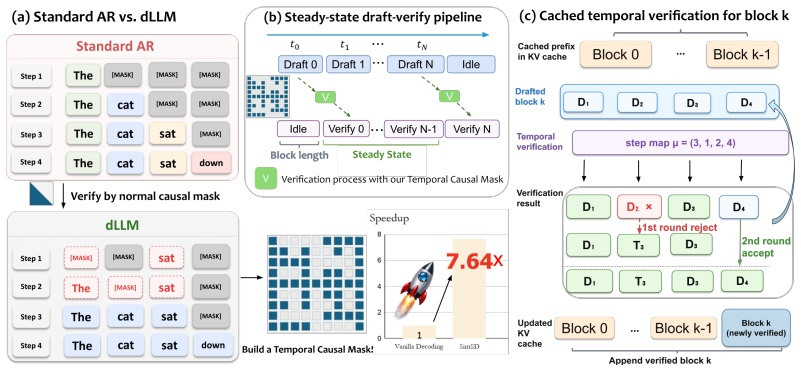
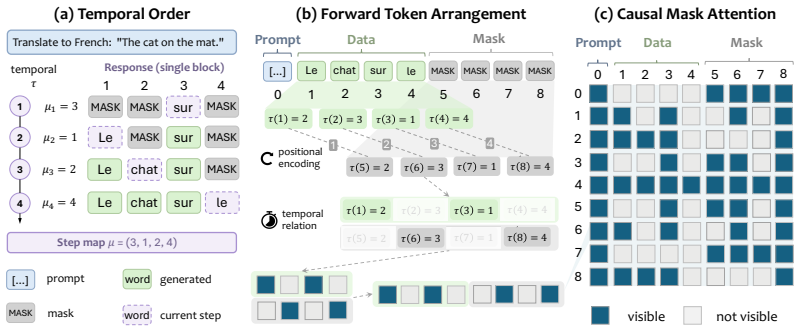
By explicitly introducing reference tokens from draft-model predictions and designing an attention mask that regulates their interaction with current-step tokens, dLLMs can compute valid logits for drafted tokens in a single forward pass. This restores the key verification ability provided by causal masking in AR models while preserving the parallel decoding advantages of dLLMs. The method is training-free and integrates with KV cache and blockwise decoding.
What carries the argument
The plug-and-play masking strategy that introduces reference tokens from draft predictions and applies an attention mask to produce temporally valid token-level contexts for verification.
If this is right
- SimSD works without any model retraining or fine-tuning.
- It integrates directly with KV cache and blockwise decoding for further gains.
- It produces up to 7.46x higher decoding throughput on SDAR-family dLLMs.
- Average generation quality is maintained or improved across four benchmarks.
- The same masking idea bridges the incompatibility between masked bidirectional attention and token-level speculative verification.
Where Pith is reading between the lines
- The masking approach could extend to other non-causal generative models that lack built-in causal context.
- If the logits remain unbiased, the technique may reduce the speed gap between diffusion and autoregressive language models in latency-sensitive settings.
- Attention masks that simulate causal properties without retraining might apply to additional bidirectional diffusion tasks beyond text.
Load-bearing premise
The introduced reference tokens and attention mask produce logits for drafted tokens that are valid for verification without changing the underlying diffusion denoising distribution or introducing systematic bias in the accepted tokens.
What would settle it
Generate the same prompts with standard dLLM decoding and with the SimSD mask; if the distribution of accepted tokens or final outputs shows systematic differences, the logits are not valid for unbiased verification.
Figures
read the original abstract
Diffusion large language models (dLLMs) have recently emerged as a promising alternative to autoregressive (AR) LLMs, offering faster inference through parallel or blockwise decoding. However, their masked language modeling formulation remains incompatible with standard token-level speculative decoding, one of the most effective acceleration techniques for AR models. In AR decoding, the causal mask preserves temporally valid token-level contexts, enabling a target model to verify multiple drafted tokens in a single forward pass. In contrast, dLLMs rely on mask tokens and bidirectional attention, causing the effective context to change across denoising steps and preventing direct token-level speculative verification. To bridge this gap, we propose a simple but effective speculative decoding algorithm for diffusion language models, named SimSD, which mainly adopts a plug-and-play masking strategy that equips dLLMs with temporally valid token-level contexts for speculative decoding. Our method explicitly introduces reference tokens from draft-model predictions and designs an attention mask that regulates their interaction with current-step tokens, allowing dLLMs to compute valid logits for drafted tokens in a single forward pass. This restores the key verification ability provided by causal masking in AR models while preserving the parallel decoding advantages of dLLMs. The proposed method is training-free and can be flexibly integrated with other acceleration techniques such as KV cache and blockwise decoding. Experiments on SDAR-family dLLMs across four benchmarks show that our method achieves up to 7.46x higher decoding throughput while maintaining and even improving average generation quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SimSD, a training-free speculative decoding algorithm for diffusion language models (dLLMs). It introduces reference tokens from a draft model and a custom attention mask to create temporally valid token-level contexts, enabling verification of multiple drafted tokens in a single forward pass while preserving dLLMs' parallel decoding. Experiments on SDAR-family dLLMs across four benchmarks report up to 7.46x higher decoding throughput with maintained or improved generation quality. The method is presented as plug-and-play and compatible with techniques such as KV cache and blockwise decoding.
Significance. If the custom masking strategy is shown to preserve the original denoising distribution, the work would meaningfully extend speculative decoding to dLLMs, offering a practical acceleration path that combines verification efficiency with bidirectional parallelism. The reported speedups and training-free integration are potentially impactful for inference in non-autoregressive models, though the absence of a supporting invariance argument limits the strength of the central claim.
major comments (2)
- [Abstract / Methods] Abstract and methods description of the attention mask: the claim that the mask 'regulates their interaction with current-step tokens' to yield logits 'usable for verification' without altering the diffusion denoising distribution lacks any derivation, invariance argument, or proof that the modified bidirectional context remains distributionally equivalent to standard dLLM inference. This is load-bearing for both the correctness of accepted tokens and the quality-maintenance result.
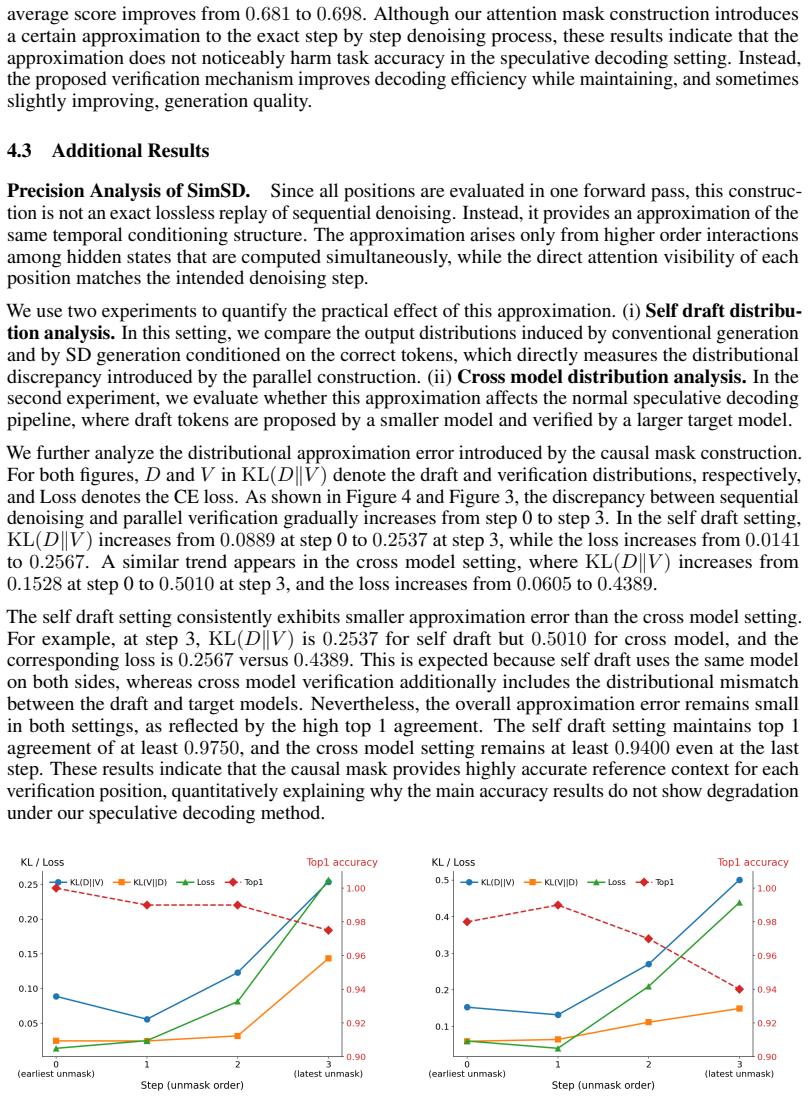
- [Experiments] Experiments section: the 7.46x throughput and quality claims are reported without error bars, variance across runs, details on the exact masking rules per denoising step, or ablations isolating the reference-token placement, preventing verification that results are robust rather than benchmark-specific.
minor comments (2)
- [Abstract] The abstract would be clearer if it briefly stated the number of denoising steps, model sizes, and exact benchmark datasets used in the reported experiments.
- [Methods] Notation for 'reference tokens' and the precise form of the custom attention mask should be formalized with an equation or pseudocode early in the methods to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key opportunities to strengthen the theoretical grounding and experimental reporting of SimSD. We address each major comment below and will make corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and methods description of the attention mask: the claim that the mask 'regulates their interaction with current-step tokens' to yield logits 'usable for verification' without altering the diffusion denoising distribution lacks any derivation, invariance argument, or proof that the modified bidirectional context remains distributionally equivalent to standard dLLM inference. This is load-bearing for both the correctness of accepted tokens and the quality-maintenance result.
Authors: We agree that the manuscript would be strengthened by an explicit argument establishing distributional equivalence. The current presentation relies on the design of the mask to enforce temporally valid contexts for reference tokens while retaining bidirectional attention for the active denoising step, together with empirical evidence of preserved quality. In revision we will add a dedicated subsection deriving the equivalence: we will show that, for each drafted token, the mask restricts attention exclusively to tokens that have already been denoised in prior steps (preventing leakage of future information) and that the resulting conditional distribution over the verification logits is identical to the one obtained under standard dLLM inference at the corresponding noise level. revision: yes
-
Referee: [Experiments] Experiments section: the 7.46x throughput and quality claims are reported without error bars, variance across runs, details on the exact masking rules per denoising step, or ablations isolating the reference-token placement, preventing verification that results are robust rather than benchmark-specific.
Authors: We accept that additional statistical and methodological detail is needed. In the revised Experiments section we will report means and standard deviations over multiple independent runs, supply the precise per-step masking rules (including how reference tokens are positioned relative to the current denoising mask), and include ablations that vary reference-token placement. These additions will substantiate the robustness of the reported throughput gains and quality metrics across the four benchmarks. revision: yes
Circularity Check
No circularity; claims rest on experimental results
full rationale
The paper introduces a training-free masking strategy (SimSD) to enable speculative decoding for dLLMs and validates performance via benchmark experiments reporting up to 7.46x throughput with maintained quality. No equations, fitted parameters, self-citations, or derivations are presented that reduce any central claim to its own inputs by construction. The method is described as a plug-and-play attention mask modification whose correctness is asserted through empirical outcomes rather than a self-referential chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Spiffy: Multiplying diffusion llm acceleration via lossless speculative decoding,
Sudhanshu Agrawal, Risheek Garrepalli, Raghavv Goel, Mingu Lee, Christopher Lott, and Fatih Porikli. Spiffy: Multiplying diffusion llm acceleration via lossless speculative decoding,
-
[2]
URLhttps://arxiv.org/abs/2509.18085
-
[3]
Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and V olodymyr Kuleshov
Marianne Arriola, Aaron Gokaslan, Justin T. Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and V olodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=tyEyYT267x
2025
-
[4]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Structured denoising diffusion models in discrete state-spaces. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 17981–17993. Curran Associates, Inc., 2021. URL htt...
2021
-
[5]
Program synthesis with large language models, 2021
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models, 2021. URLhttps://arxiv.org/abs/2108.07732
Pith/arXiv arXiv 2021
-
[6]
LLaDA2.0: Scaling up diffusion language models to 100b, 2025
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, Chengxi Li, Chongxuan Li, Jianguo Li, Zehuan Li, Huabin Liu, Lin Liu, Guoshan Lu, Xiaocheng Lu, Yuxin Ma, Jianfeng Tan, Lanning Wei, Ji-Rong Wen, Yipeng Xing, Xiaolu Zhang, Junbo Zhao, Da Zheng, Jun Zhou, Junlin Zhou, Zhanchao Zhou, Li...
Pith/arXiv arXiv 2025
-
[7]
Lee, Deming Chen, and Tri Dao
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. Medusa: Simple LLM inference acceleration framework with multiple decoding heads. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 5209–5235. PMLR, 2024. URL https://proceedings.mlr...
2024
-
[8]
Accelerating large language model decoding with speculative sampling, 2023
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling, 2023. URLhttps://arxiv.org/abs/2302.01318
Pith/arXiv arXiv 2023
-
[9]
DFlash: Block diffusion for flash speculative decoding, 2026
Jian Chen, Yesheng Liang, and Zhijian Liu. DFlash: Block diffusion for flash speculative decoding, 2026. URLhttps://arxiv.org/abs/2602.06036
Pith/arXiv arXiv 2026
-
[10]
SDAR: A synergistic diffusion- autoregression paradigm for scalable sequence generation, 2025
Shuang Cheng, Yihan Bian, Dawei Liu, Linfeng Zhang, Qian Yao, Zhongbo Tian, Wenhai Wang, Qipeng Guo, Kai Chen, Biqing Qi, and Bowen Zhou. SDAR: A synergistic diffusion- autoregression paradigm for scalable sequence generation, 2025. URL https://arxiv.org/ abs/2510.06303
arXiv 2025
-
[11]
PaLM: Scaling language modeling with pathways, 2022
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. PaLM: Scaling language modeling with pathways, 2022. URL https://arxiv.org/abs/2204. 02311
2022
-
[12]
and Ben-Nun, Tal and Cardei, Michael and Kailkhura, Bhavya and Fioretto, Ferdinando
Jacob K. Christopher, Brian R. Bartoldson, Tal Ben-Nun, Michael Cardei, Bhavya Kailkhura, and Ferdinando Fioretto. Speculative diffusion decoding: Accelerating language generation through diffusion. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies, pag...
-
[13]
Training verifiers to solve math word problems, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems, 2021. URLhttps://arxiv.org/abs/2110.14168
Pith/arXiv arXiv 2021
-
[14]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025. URLhttps://arxiv.org/abs/2507.06261
Pith/arXiv arXiv 2025
-
[15]
Opencompass: A universal evaluation platform for foundation models.https://github.com/open-compass/opencompass, 2023
OpenCompass Contributors. Opencompass: A universal evaluation platform for foundation models.https://github.com/open-compass/opencompass, 2023
2023
-
[16]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4171–4186. Association for Computational Linguistics,
2019
-
[17]
URLhttps://aclanthology.org/N19-1423
-
[18]
Break the sequential dependency of LLM inference using lookahead decoding
Yichao Fu, Peter Bailis, Ion Stoica, and Hao Zhang. Break the sequential dependency of LLM inference using lookahead decoding. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 14060–14079. PMLR, 2024. URL https://proceedings.mlr.press/v235/fu24a.html
2024
-
[19]
Self speculative decoding for diffusion large language models, 2025
Yifeng Gao, Ziang Ji, Yuxuan Wang, Biqing Qi, Hanlin Xu, and Linfeng Zhang. Self speculative decoding for diffusion large language models, 2025. URL https://arxiv.org/abs/2510. 04147
2025
-
[20]
Scaling diffusion language models via adaptation from autoregressive models
Shansan Gong, Shivam Agarwal, Yizhe Zhang, Jiacheng Ye, Lin Zheng, Mukai Li, Chenxin An, Peilin Zhao, Wei Bi, Jiawei Han, Hao Peng, and Lingpeng Kong. Scaling diffusion language models via adaptation from autoregressive models. InInternational Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=j1tSLYKwg8. arXiv:2410.17891
Pith/arXiv arXiv 2025
-
[21]
Gemini diffusion - google deepmind, 2025
Google DeepMind. Gemini diffusion - google deepmind, 2025. URL https://deepmind. google/models/gemini-diffusion/. Accessed: 2025-09-19
2025
-
[22]
S2D2: Fast decoding for diffusion llms via training-free self-speculation, 2026
Ligong Han, Hao Wang, Han Gao, Kai Xu, and Akash Srivastava. S2D2: Fast decoding for diffusion llms via training-free self-speculation, 2026. URL https://arxiv.org/abs/2603. 25702
2026
-
[23]
DiffusionBERT: Improving generative masked language models with diffusion models
Zhengfu He, Tianxiang Sun, Qiong Tang, Kuanning Wang, Xuanjing Huang, and Xipeng Qiu. DiffusionBERT: Improving generative masked language models with diffusion models. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 4521–...
2023
-
[24]
Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
Pith/arXiv arXiv 2009
-
[25]
Abdelfattah, Jae sun Seo, Zhiru Zhang, and Udit Gupta
Zhanqiu Hu, Jian Meng, Yash Akhauri, Mohamed S. Abdelfattah, Jae sun Seo, Zhiru Zhang, and Udit Gupta. FlashDLM: Accelerating diffusion language model inference via efficient kv caching and guided diffusion, 2025. URLhttps://arxiv.org/abs/2505.21467
arXiv 2025
-
[26]
Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. GPT-4o system card, 2024. URL https://arxiv.org/abs/2410.21276
Pith/arXiv arXiv 2024
-
[27]
T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. In Regina Barzilay and Min-Yen Kan, editors,Proceedings of the 55th Annual Meeting of the Association for Com- putational Linguistics (V olume 1: Long Papers), pages 1601–1611, Vancouver, Canada, 11 July 2...
-
[28]
Mercury: Ultra-fast language models based on diffusion, 2025
Inception Labs, Samar Khanna, Siddhant Kharbanda, Shufan Li, Harshit Varma, Eric Wang, Sawyer Birnbaum, Ziyang Luo, Yanis Miraoui, Akash Palrecha, et al. Mercury: Ultra-fast language models based on diffusion, 2025. URLhttps://arxiv.org/abs/2506.17298
Pith/arXiv arXiv 2025
-
[29]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 19274–19286. PMLR, 2023. URLhttps://proceedings.mlr.press/v202/leviathan23a.html
2023
-
[30]
DiffuSpec: Unlocking diffusion language models for speculative decoding, 2025
Guanghao Li, Zhihui Fu, Min Fang, Qibin Zhao, Ming Tang, Chun Yuan, and Jun Wang. DiffuSpec: Unlocking diffusion language models for speculative decoding, 2025. URL https: //arxiv.org/abs/2510.02358
arXiv 2025
-
[31]
Hashimoto
Xiang Li, John Thickstun, Ishaan Gulrajani, Percy Liang, and Tatsunori B. Hashimoto. Diffusion-LM improves controllable text generation. InProceed- ings of the 36th International Conference on Neural Information Processing Sys- tems, 2022. URL https://papers.nips.cc/paper_files/paper/2022/hash/ 1be5bc25d50895ee656b8c2d9eb89d6a-Abstract-Conference.html
2022
-
[32]
EAGLE: Speculative sampling requires rethinking feature uncertainty
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. EAGLE: Speculative sampling requires rethinking feature uncertainty. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 28935– 28948. PMLR, 2024. URLhttps://proceedings.mlr.press/v235/li24bt.html
2024
-
[33]
dLLM-Cache: Accelerating diffusion large language models with adaptive caching, 2025
Zhiyuan Liu, Yicun Yang, Yaojie Zhang, Junjie Chen, Chang Zou, Qingyuan Wei, Shaobo Wang, and Linfeng Zhang. dLLM-Cache: Accelerating diffusion large language models with adaptive caching, 2025. URLhttps://arxiv.org/abs/2506.06295
Pith/arXiv arXiv 2025
-
[34]
dKV-Cache: The cache for diffusion language models, 2025
Xinyin Ma, Runpeng Yu, Gongfan Fang, and Xinchao Wang. dKV-Cache: The cache for diffusion language models, 2025. URLhttps://arxiv.org/abs/2505.15781
arXiv 2025
-
[35]
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Zhengxin Zhang, Rae Ying Yee Wong, Alan Zhu, Lijie Yang, Xiaoxiang Shi, Chunan Shi, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, and Zhihao Jia. SpecInfer: Accelerating generative large language model serving with tree-based speculative inference and verification. InProceedings of the...
-
[36]
Large language models: A survey, 2024
Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, and Jianfeng Gao. Large language models: A survey, 2024. URL https://arxiv. org/abs/2402.06196
Pith/arXiv arXiv 2024
-
[37]
Large language diffusion models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models. InAdvances in Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id= KnqiC0znVF
2025
-
[38]
BlockSpec: Blockwise speculative decoding for diffusion llms, 2025
Tianxiang Pan, Baitao Gong, Mo Guang, Hongwei Yong, Tianpeng Jiang, Yaqian Li, Zheng Cao, and Kaiwen Long. BlockSpec: Blockwise speculative decoding for diffusion llms, 2025. URLhttps://openreview.net/forum?id=hmAviop5rm. OpenReview preprint
2025
-
[39]
Christopher, Thomas Hartvigsen, and Ferdinando Fioretto
Jameson Sandler, Jacob K. Christopher, Thomas Hartvigsen, and Ferdinando Fioretto. SpecDiff- 2: Scaling diffusion drafter alignment for faster speculative decoding, 2025. URL https: //arxiv.org/abs/2511.00606
arXiv 2025
-
[40]
RoFormer: Enhanced transformer with rotary position embedding, 2021
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding, 2021. URL https://arxiv.org/ abs/2104.09864. 12
Pith/arXiv arXiv 2021
-
[41]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAd- vances in Neural Information Processing Systems, volume 30. Curran Associates, Inc.,
-
[42]
URL https://proceedings.neurips.cc/paper_files/paper/2017/file/ 3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
2017
-
[43]
Fast-dllm: Training-free acceleration of diffusion llm by enabling KV cache and parallel decoding
Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. Fast-dllm: Training-free acceleration of diffusion llm by enabling KV cache and parallel decoding. InInternational Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=3Z3Is6hnOT
2026
-
[44]
Heming Xia, Zhe Yang, Qingxiu Dong, Peiyi Wang, Yongqi Li, Tao Ge, Tianyu Liu, Wenjie Li, and Zhifang Sui. Unlocking efficiency in large language model inference: A comprehensive survey of speculative decoding. InFindings of the Association for Computational Linguistics: ACL 2024, pages 7655–7671, Bangkok, Thailand, August 2024. Association for Computatio...
-
[45]
Dream-Coder 7B: An open diffusion language model for code, 2025
Zhihui Xie, Jiacheng Ye, Lin Zheng, Jiahui Gao, Jingwei Dong, Zirui Wu, Xueliang Zhao, Shansan Gong, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream-Coder 7B: An open diffusion language model for code, 2025. URLhttps://arxiv.org/abs/2509.01142
arXiv 2025
-
[46]
MMaDA: Multimodal large diffusion language models, 2025
Ling Yang, Ye Tian, Bowen Li, Xinchen Zhang, Ke Shen, Yunhai Tong, and Mengdi Wang. MMaDA: Multimodal large diffusion language models, 2025. URL https://arxiv.org/ abs/2505.15809
Pith/arXiv arXiv 2025
-
[47]
Dream 7B: Diffusion large language models, 2025
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7B: Diffusion large language models, 2025. URL https://arxiv.org/abs/ 2508.15487
Pith/arXiv arXiv 2025
-
[48]
A survey of large language models, 2023
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models, 2023. URLhttps://arxiv.org/abs/2303.18223. 13
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.