ClinEnv: An Interactive Multi-Stage Long Horizon EHR Environment for Agents
Pith reviewed 2026-06-28 14:31 UTC · model grok-4.3
The pith
Language models reach only 0.31 decision F1 when acting as physicians in an interactive multi-stage simulation of real inpatient admissions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
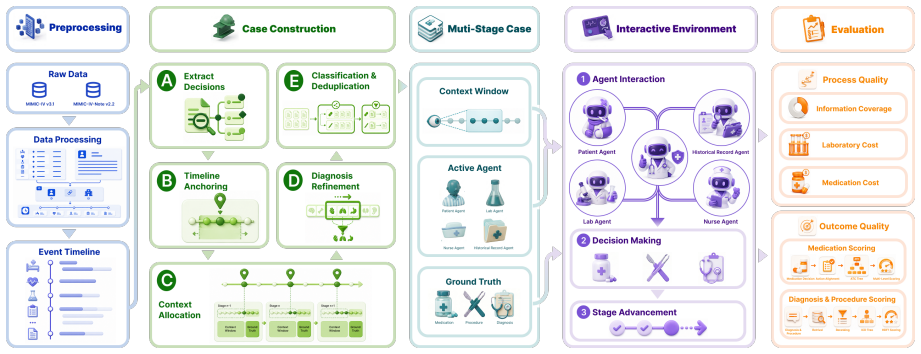
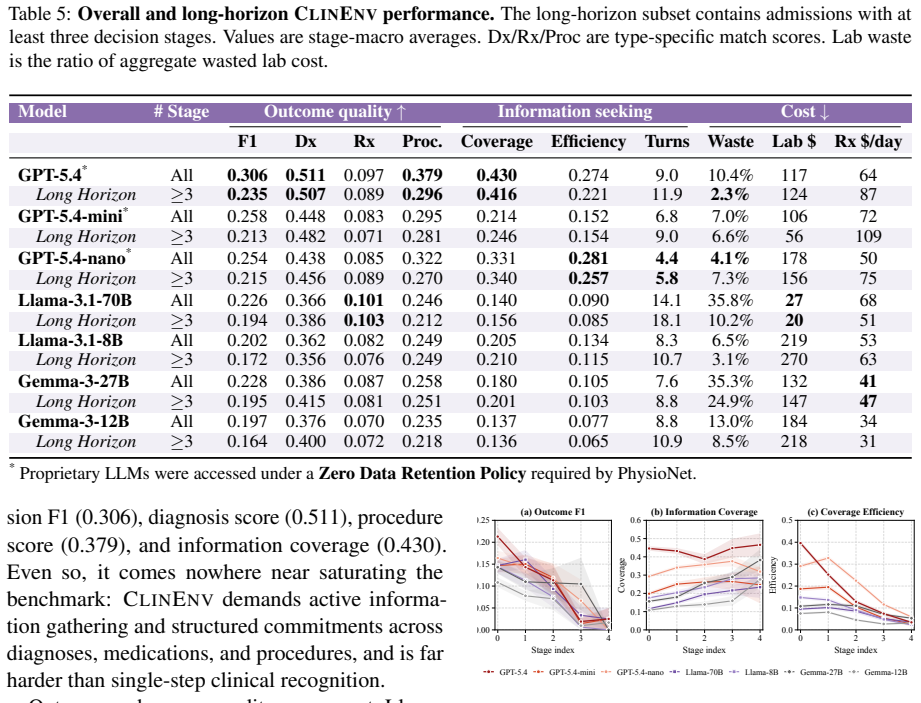
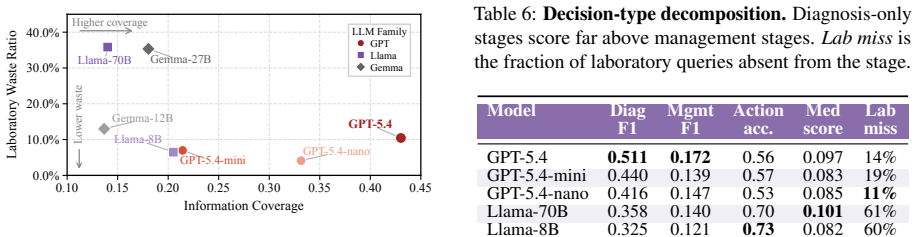
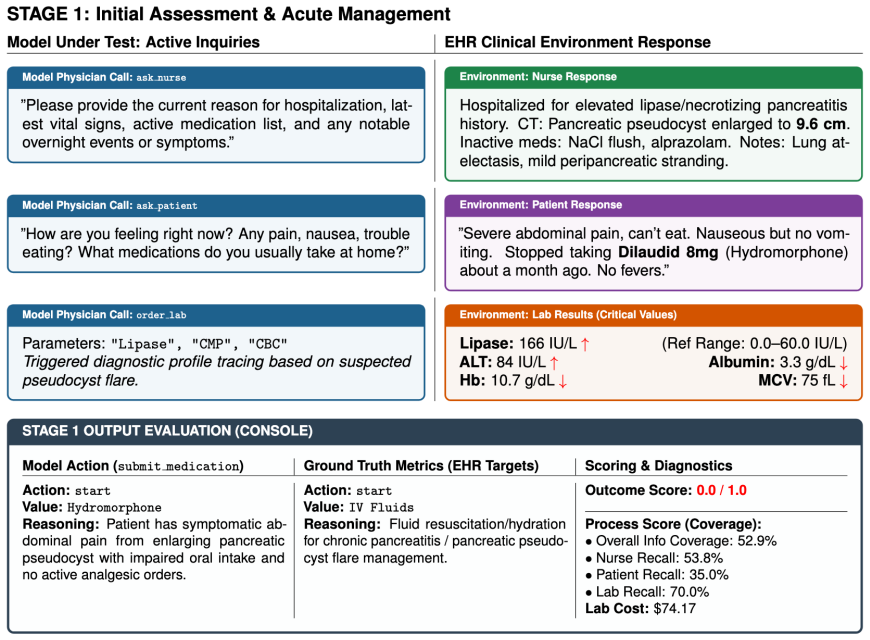
ClinEnv converts real inpatient admissions into ordered sequences of decision stages under the Longitudinal Inpatient Simulation paradigm. At each stage the model must actively query four specialized agents before selecting medications, procedures, and diagnoses. Decisions are scored by deterministic ontology-grounded matching while information-gathering behavior is tracked separately. Across seven models the strongest reaches 0.31 decision F1; outcome quality decouples from process quality; models recover discharge diagnoses at 0.51 F1 but management actions at only 0.17 F1; and redundant queries persist as cases progress.
What carries the argument
Longitudinal Inpatient Simulation, the construction of each admission as an ordered sequence of decision stages that forces active querying of four specialized agents before any commitment to action.
If this is right
- Models recover discharge diagnoses more reliably than they select management actions.
- Performance declines in later stages of each admission.
- Outcome quality remains sharply decoupled from the quality of information-gathering process.
- Models continue issuing redundant queries even as cases advance.
Where Pith is reading between the lines
- The observed decoupling implies that training regimes focused solely on final diagnosis prediction will not automatically produce better sequential decision behavior.
- The persistent redundant queries suggest that current models lack mechanisms to track already-acquired information across long horizons.
- Extending the agent set beyond the current four specializations could reveal additional gaps in how models allocate queries under uncertainty.
Load-bearing premise
Real inpatient admissions can be automatically turned into ordered sequences of decision stages that faithfully represent clinical practice without introducing artifacts from the construction process or the choice of four specialized agents.
What would settle it
If the same models achieve substantially higher management-action F1 in later stages when the stage sequences are rebuilt by clinicians rather than generated automatically, the reported concentration of difficulty would be challenged.
Figures
read the original abstract
Clinical practice is not the selection of an answer from enumerated options: a physician gathers heterogeneous information incrementally and commits to sequential, irreversible decisions under uncertainty. Static benchmarks cannot probe and existing interactive medical benchmarks each compromise on at least one of them. We present ClinEnv, an interactive benchmark that evaluates LLMs as attending physicians over real inpatient admissions under a paradigm we term Longitudinal Inpatient Simulation. Each case is automatically constructed into an ordered sequence of decision stages; at every stage the model must actively query four specialized agents before committing to medications, procedures, and diagnoses. ClinEnv scores both what the model decides, through deterministic ontology-grounded matching, and how it gathers information. Across seven models, the strongest reaches only 0.31 decision F1, and outcome quality is sharply decoupled from process quality. Difficulty concentrates in management decisions and later stages, where models recover discharge diagnoses far more reliably than management actions (0.51 vs. 0.17 F1) and continue to issue redundant queries as cases progress. ClinEnv makes this information-acquisition gap, invisible to outcome-only evaluation, directly measurable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ClinEnv, an interactive benchmark for LLMs acting as attending physicians under a Longitudinal Inpatient Simulation paradigm. Real EHR admissions are automatically segmented into ordered decision stages; at each stage the model must query four specialized agents before committing to medications, procedures, and diagnoses. Decisions are scored via deterministic ontology-grounded matching, and the process of information gathering is also evaluated. Across seven models the best decision F1 is 0.31, with sharp decoupling between outcome and process quality; management decisions prove especially difficult (0.17 F1) relative to discharge-diagnosis recovery (0.51 F1), and models continue issuing redundant queries in later stages.
Significance. If the automatic stage construction and four-agent routing faithfully reproduce clinical information-gathering without systematic artifacts, ClinEnv supplies a reproducible, falsifiable testbed that exposes limitations invisible to static or outcome-only medical benchmarks. The explicit separation of process and outcome metrics, together with the reported concentration of difficulty in management actions and later stages, would constitute a concrete advance for long-horizon agent evaluation in medicine.
major comments (2)
- [Methods] Methods (Longitudinal Inpatient Simulation construction): the automatic segmentation of admissions into ordered stages and the routing of queries through four fixed specialized agents are load-bearing for all reported F1 numbers; the manuscript must supply the precise segmentation rules, information-availability logic, and any external validation against clinician judgment, otherwise the observed patterns (0.51 vs. 0.17 F1, redundant queries) cannot be attributed to model limitations rather than construction artifacts.
- [Results] Results (decoupling claim): the assertion that outcome quality is “sharply decoupled” from process quality requires quantitative support (e.g., correlation coefficients or regression controls across stages); without these the headline 0.31 F1 and the management/diagnosis split remain descriptive rather than evidence of a systematic gap.
minor comments (2)
- [Abstract] Abstract and §4: the ontology-matching procedure used for deterministic scoring should be referenced or briefly summarized so readers can assess reproducibility.
- Table or figure captions: clarify how the seven models were selected and whether any hyper-parameter tuning was performed on the benchmark itself.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The two major comments highlight important areas for improving transparency and evidential support. We address each below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Methods] Methods (Longitudinal Inpatient Simulation construction): the automatic segmentation of admissions into ordered stages and the routing of queries through four fixed specialized agents are load-bearing for all reported F1 numbers; the manuscript must supply the precise segmentation rules, information-availability logic, and any external validation against clinician judgment, otherwise the observed patterns (0.51 vs. 0.17 F1, redundant queries) cannot be attributed to model limitations rather than construction artifacts.
Authors: We agree that explicit documentation of the segmentation and routing logic is required for reproducibility and to support attribution of results to model behavior. The revised manuscript will add a dedicated subsection with pseudocode, exact decision criteria for stage boundaries (based on temporal ordering of EHR events), and the information-availability rules that determine which data each of the four agents can return at each stage. We do not possess external clinician validation of the resulting stages; the construction relies on deterministic, ontology-grounded rules derived directly from the EHR schema to maximize reproducibility across institutions. We will add a limitations paragraph acknowledging this design choice. revision: partial
-
Referee: [Results] Results (decoupling claim): the assertion that outcome quality is “sharply decoupled” from process quality requires quantitative support (e.g., correlation coefficients or regression controls across stages); without these the headline 0.31 F1 and the management/diagnosis split remain descriptive rather than evidence of a systematic gap.
Authors: We accept that the decoupling statement would be strengthened by quantitative measures. In the revision we will report Pearson and Spearman correlations between process metrics (query redundancy rate, cumulative information coverage) and decision F1, computed both across models and within stages. We will also include a simple regression controlling for stage number to test whether the observed separation persists after accounting for progression effects. revision: yes
- External validation of the automatic stage segmentation against independent clinician judgment
Circularity Check
No circularity; empirical benchmark construction with no derivation chain
full rationale
The paper constructs an interactive EHR benchmark by automatically segmenting real admissions into ordered decision stages and routing queries through four fixed agents. No equations, fitted parameters, predictions, or first-principles derivations are present. Performance numbers (e.g., 0.31 decision F1) are direct empirical measurements from the constructed environment rather than outputs that reduce by construction to any input fit or self-citation. The methodology is presented as a design choice without invoking uniqueness theorems, ansatzes from prior self-work, or renaming of known results. The central claims rest on the benchmark's observable behavior, which is externally falsifiable via the released environment and does not collapse into its own construction inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real inpatient admissions can be automatically constructed into ordered sequences of decision stages that preserve clinical realism.
invented entities (1)
-
ClinEnv
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. Yixing Jiang, Kameron C Black, Gloria Geng, Danny Park, James Zou, Andrew Y Ng, and Jonathan H Chen. 2025. Medagentbench: a virtual ehr environ- ment to benchmark medical llm agents.Nejm Ai, 2(9):AIdbp2500144. Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Ke...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[2]
arXiv preprint arXiv:2401.05654 , year=
Towards conversational diagnostic ai.arXiv preprint arXiv:2401.05654. Ping Wang, Tian Shi, and Chandan K Reddy. 2020. Text-to-sql generation for question answering on elec- tronic medical records. InProceedings of The Web Conference 2020, pages 350–361. Ran Xu, Yuchen Zhuang, Yishan Zhong, Yue Yu, Zifeng Wang, Xiangru Tang, Hang Wu, May D Wang, Peifeng Ru...
-
[3]
All are static multiple-choice or short-answer formats with fully specified vignettes
contains 12,723 USMLE-style multiple- choice questions; MedMCQA (Pal et al., 2022) provides 194k questions from Indian medical en- trance exams; PubMedQA (Jin et al., 2019) con- tains 273k yes / no / maybe questions derived from PubMed abstracts; MMLU-Health (Hendrycks et al., 2020) covers approximately 2k items across clinical knowledge, anatomy, college...
2022
-
[4]
Tasks are single-shot translations from natural lan- guage to structured queries, scored by execution match against the EHR database
provides 24k natural-language questions paired with SQL queries over MIMIC-III and eICU; MIMIC-SQL (Wang et al., 2020) contains 10k sim- ilar pairs over MIMIC-III; FHIR-AgentBench (Lee et al., 2025) provides 2,931 questions over MIMIC- IV-FHIR with both SQL and FHIR-API answers. Tasks are single-shot translations from natural lan- guage to structured quer...
2020
-
[5]
The envi- ronment exposes a FHIR-compliant API matching modern EMR systems, and success is scored by post-action database state
provides 300 physician-authored tasks across 10 categories (chart review, order placement, result retrieval, among others) operating on 100 patient profiles drawn from Stanford STARR. The envi- ronment exposes a FHIR-compliant API matching modern EMR systems, and success is scored by post-action database state. Tasks are atomic and pre-specified rather th...
-
[6]
Cases are derived from MedQA and NEJM Image Chal- lenges; the doctor agent must converge on a single diagnosis through bounded dialogue turns
composes a doctor agent with an LLM- played patient agent, a measurement agent that re- turns test results, and optionally a moderator. Cases are derived from MedQA and NEJM Image Chal- lenges; the doctor agent must converge on a single diagnosis through bounded dialogue turns. Evalua- tion covers diagnostic accuracy and patient-centric metrics such as co...
2026
-
[7]
Coding-style executable benchmarks
is a diagnostic dialogue system evaluated in randomized OSCE-style consultations against primary-care physicians. Coding-style executable benchmarks. MedCalc-Env (Mao et al., 2025) is an RL environment built on the InternBootcamp frame- work for multi-step medical calculation, covering 700+ tasks across specialties. MedAgentGym (Xu et al., 2025) provides ...
2025
-
[8]
discover the selected structured and note CSV files and stream them in chunks
-
[9]
normalize subject_id and hadm_id, then drop rows missing either key
-
[10]
assign a canonical event_time using the first available timestamp in this priority or- der: charttime, starttime, admittime, chartdate,stoptime,endtime
-
[11]
serialize each row as an event with source_table, event_time when avail- able, and table-specific payload fields, while removing identifiers and internal processing columns
-
[12]
Performed esophagogastroduodenoscopy (EGD)
group events by admission and sort them by timestamp, source_table, and original row or- der for deterministic tie breaking. The preprocessor writes one JSON timeline per admission under subject/admission-specific directo- ries. Each file is a JSON array of ordered events. In the preprocessing release used by this work, the re- sulting timeline collection...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.