ProtoAda: Prototype-Guided Adaptive Adapter Expansion and Geometric Consolidation for Multimodal Continual Instruction Tuning
Pith reviewed 2026-06-28 15:07 UTC · model grok-4.3
The pith
Format-aware task prototypes route multimodal tasks by both semantics and response structure to reduce interference in continual tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
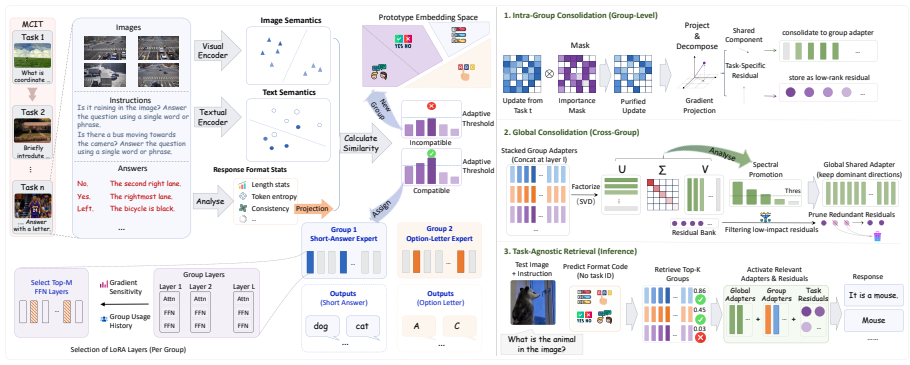
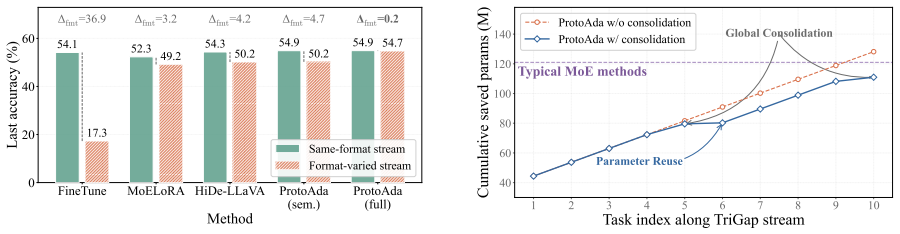
ProtoAda introduces format-aware task prototypes to align task assignment and routing with both task semantics and output structure, and further consolidates format-compatible updates in a geometry-aware manner to effectively reuse and progressively refine existing parameters.
What carries the argument
format-aware task prototypes that capture semantics plus output structure for routing, together with geometry-aware consolidation of parameter updates
If this is right
- Tasks sharing visual-linguistic content but requiring distinct response formats are assigned to separate experts rather than shared ones.
- Gradient interference arising from heterogeneous response types in the same parameters is reduced.
- Compatible updates are reused and refined without overwriting prior knowledge.
- Performance improves on multiple benchmarks, with the largest gains on tasks whose answer structures are vulnerable to corruption.
Where Pith is reading between the lines
- Output format may function as an independent axis for task separation that semantic similarity alone cannot capture.
- The routing principle could apply to continual learning settings outside multimodal models where response types vary.
- Independent checks on whether format-aware prototypes actually produce the claimed routing reliability would clarify the method's robustness.
Load-bearing premise
That adding format awareness to task prototypes will produce reliable routing decisions that avoid gradient interference between tasks with incompatible response types.
What would settle it
An experiment in which tasks with similar semantics but different output formats are still frequently routed together, or in which performance gains disappear on structure-sensitive tasks.
Figures
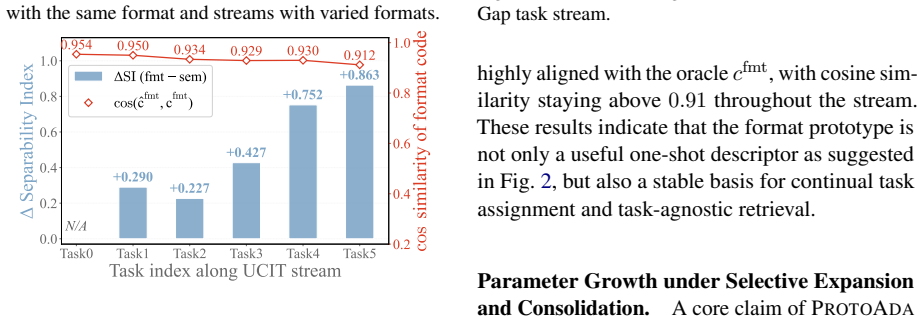
read the original abstract
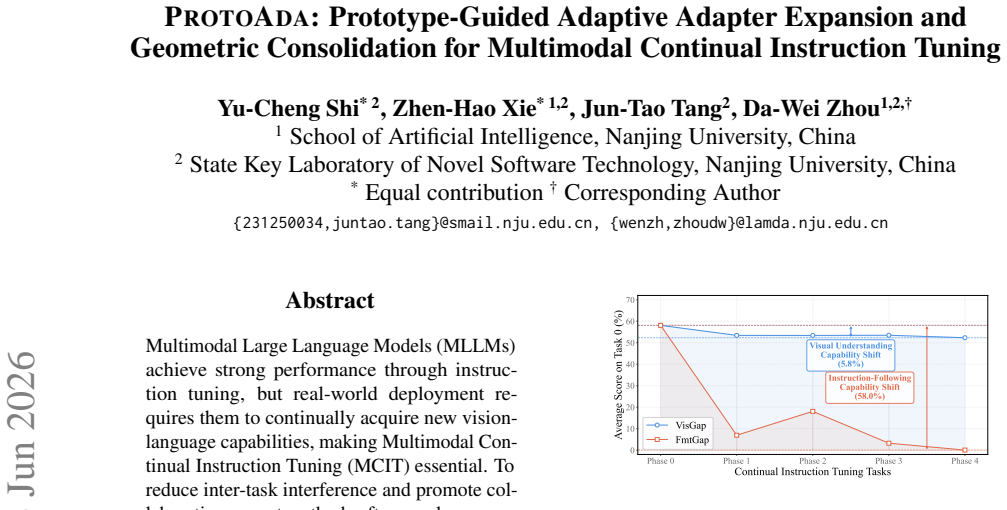
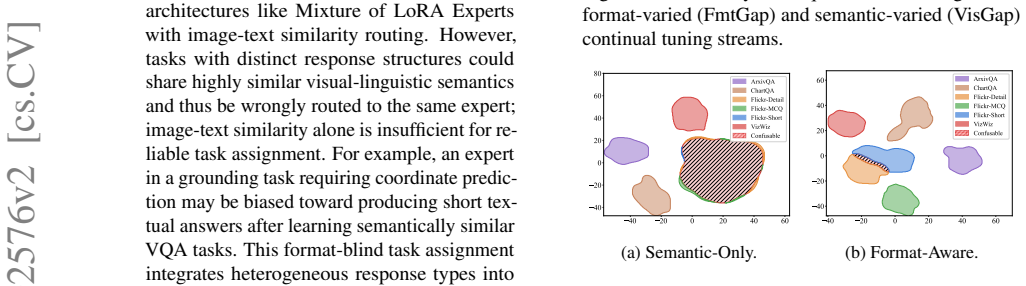
Multimodal Large Language Models (MLLMs) achieve strong performance through instruction tuning, but real-world deployment requires them to continually acquire new vision-language capabilities, making Multimodal Continual Instruction Tuning (MCIT) essential. To reduce inter-task interference and promote collaboration, recent methods often employ sparse architectures like Mixture of LoRA Experts with image-text similarity routing. However, tasks with distinct response structures could share highly similar visual-linguistic semantics and thus be wrongly routed to the same expert; image-text similarity alone is insufficient for reliable task assignment. For example, an expert in a grounding task requiring coordinate prediction may be biased toward producing short textual answers after learning semantically similar VQA tasks. This format-blind task assignment integrates heterogeneous response types into shared parameters, inducing gradient interference and ineffective expert collaboration. To address this problem, we propose ProtoAda, a prototype-guided adaptive tuning framework. ProtoAda introduces format-aware task prototypes to align task assignment and routing with both task semantics and output structure, and further consolidates format-compatible updates in a geometry-aware manner to effectively reuse and progressively refine existing parameters. Extensive experiments on multiple benchmarks demonstrate that ProtoAda achieves superior performance, especially on tasks whose answer structures are easily corrupted by sequential tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ProtoAda, a prototype-guided adaptive tuning framework for Multimodal Continual Instruction Tuning (MCIT) of MLLMs. It diagnoses that image-text similarity routing in sparse MoLoRA architectures fails for tasks sharing semantics but differing in output format (e.g., coordinate prediction vs. free-text VQA), causing gradient interference. ProtoAda adds format-aware task prototypes to align routing with both semantics and output structure, plus geometry-aware consolidation to reuse and refine parameters. Experiments on multiple benchmarks are reported to show superior performance, particularly on tasks with easily corrupted answer structures.
Significance. If the routing mechanism and performance gains hold under scrutiny, the work addresses a practical interference issue in continual multimodal tuning that standard semantic routing overlooks. The explicit incorporation of output format into prototypes and the geometry-aware consolidation step represent targeted contributions that could improve expert collaboration in sparse architectures. Credit is due for identifying a concrete failure mode (format-blind assignment) and proposing a mechanism to mitigate it, though independent validation of the routing fix is needed to establish the result's robustness.
major comments (2)
- [Abstract] Abstract: The central claim that format-aware prototypes 'align task assignment and routing with both task semantics and output structure' and thereby reduce gradient interference is load-bearing for the contribution, yet the text provides no routing statistics, prototype visualizations, or ablation isolating the format-awareness component from the geometry-aware consolidation. Superior benchmark numbers could arise from consolidation alone.
- [Abstract] Abstract (problem diagnosis paragraph): The example of a grounding expert being biased toward short textual answers after VQA tuning is presented as evidence of format-induced misrouting, but no quantitative measure (e.g., pre/post routing accuracy on format-differing task pairs or interference metrics) is supplied to show that the proposed prototypes actually alter assignment decisions.
minor comments (1)
- [Abstract] The abstract states 'extensive experiments on multiple benchmarks' but does not name the benchmarks or report error bars, making it impossible to assess the magnitude or consistency of the claimed gains.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments correctly identify that the abstract (and by extension the current presentation) lacks direct empirical support for the routing mechanism's impact. We will revise the manuscript to incorporate the requested evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that format-aware prototypes 'align task assignment and routing with both task semantics and output structure' and thereby reduce gradient interference is load-bearing for the contribution, yet the text provides no routing statistics, prototype visualizations, or ablation isolating the format-awareness component from the geometry-aware consolidation. Superior benchmark numbers could arise from consolidation alone.
Authors: We agree that the current abstract and main text do not supply routing statistics, prototype visualizations, or an ablation that isolates format-awareness from geometry-aware consolidation. In the revision we will add (1) routing accuracy and assignment distribution statistics on format-differing task pairs, (2) t-SNE or similar visualizations of the learned prototypes, and (3) an explicit ablation that removes only the format component while retaining geometry-aware consolidation. These additions will be placed in the main experimental section or a dedicated analysis subsection. revision: yes
-
Referee: [Abstract] Abstract (problem diagnosis paragraph): The example of a grounding expert being biased toward short textual answers after VQA tuning is presented as evidence of format-induced misrouting, but no quantitative measure (e.g., pre/post routing accuracy on format-differing task pairs or interference metrics) is supplied to show that the proposed prototypes actually alter assignment decisions.
Authors: We acknowledge the absence of quantitative support for the motivating example. The revised version will include pre- and post-prototype routing accuracy numbers on pairs of tasks that share semantics but differ in output format, together with a simple interference metric (gradient cosine similarity or output-format consistency) measured before and after the format-aware routing is enabled. This will directly demonstrate that the prototypes change assignment decisions. revision: yes
Circularity Check
No circularity: method proposal relies on experimental validation rather than self-referential definitions or fitted predictions.
full rationale
The abstract and description present ProtoAda as a new framework using format-aware prototypes for routing and geometry-aware consolidation. No equations, parameter fits, or derivations are shown that reduce claims to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems. Performance superiority is asserted via benchmark experiments, which are independent of any internal circular reduction. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , pages=
Coin: A benchmark of continual instruction tuning for multimodel large language models , author=. Advances in Neural Information Processing Systems , pages=
-
[2]
Proceedings of the Annual Meeting of the Association for Computational Linguistics , pages=
Hide-llava: Hierarchical decoupling for continual instruction tuning of multimodal large language model , author=. Proceedings of the Annual Meeting of the Association for Computational Linguistics , pages=
-
[3]
Jinpeng Chen and Runmin Cong and Yuzhi Zhao and Hongzheng Yang and Guangneng Hu and Horace Ip and Sam Kwong , booktitle=
-
[4]
Proceedings of the Conference on Empirical Methods in Natural Language Processing , pages=
Modalprompt: Towards efficient multimodal continual instruction tuning with dual-modality guided prompt , author=. Proceedings of the Conference on Empirical Methods in Natural Language Processing , pages=
-
[5]
arXiv preprint arXiv:2411.02564 , year=
Continual llava: Continual instruction tuning in large vision-language models , author=. arXiv preprint arXiv:2411.02564 , year=
-
[6]
arXiv preprint arXiv:2503.21227 , year=
LLaVA-CMoE: Towards Continual Mixture of Experts for Large Vision-Language Models , author=. arXiv preprint arXiv:2503.21227 , year=
-
[7]
Proceedings of the Annual Meeting of the Association for Computational Linguistics , pages=
Progressive lora for multimodal continual instruction tuning , author=. Proceedings of the Annual Meeting of the Association for Computational Linguistics , pages=
-
[8]
Advances in Neural Information Processing Systems , volume=
Learn to explain: Multimodal reasoning via thought chains for science question answering , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference , pages=
Towards vqa models that can read , author=. Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference , pages=
-
[10]
Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference , pages=
Imagenet: A large-scale hierarchical image database , author=. Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference , pages=
-
[11]
Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference , pages=
Gqa: A new dataset for real-world visual reasoning and compositional question answering , author=. Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference , pages=
-
[12]
Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference , pages=
Vizwiz grand challenge: Answering visual questions from blind people , author=. Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference , pages=
-
[13]
Proceedings of the Conference on Empirical Methods in Natural Language Processing , pages=
Referitgame: Referring to objects in photographs of natural scenes , author=. Proceedings of the Conference on Empirical Methods in Natural Language Processing , pages=
-
[14]
Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference , pages=
Making the v in vqa matter: Elevating the role of image understanding in visual question answering , author=. Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference , pages=
-
[15]
International Conference on Document Analysis and Recognition , pages=
Ocr-vqa: Visual question answering by reading text in images , author=. International Conference on Document Analysis and Recognition , pages=. 2019 , organization=
2019
-
[16]
International Conference on Machine Learning , pages=
Learning transferable visual models from natural language supervision , author=. International Conference on Machine Learning , pages=
-
[17]
arXiv preprint arXiv:2510.08564 , year=
How to Teach Large Multimodal Models New Skills , author=. arXiv preprint arXiv:2510.08564 , year=
-
[18]
Advances in Neural Information Processing Systems , pages =
Visual Instruction Tuning , author=. Advances in Neural Information Processing Systems , pages =
-
[19]
Findings of the Association for Computational Linguistics: EMNLP , pages=
Orthogonal subspace learning for language model continual learning , author=. Findings of the Association for Computational Linguistics: EMNLP , pages=
-
[20]
2025 , journal=
Hierarchical Representation Matching for CLIP-based Class-Incremental Learning , author=. 2025 , journal=
2025
-
[22]
arXiv preprint arXiv:2304.10592 , year=
Minigpt-4: Enhancing vision-language understanding with advanced large language models , author=. arXiv preprint arXiv:2304.10592 , year=
-
[23]
Advances in Neural Information Processing Systems , volume=
Instructblip: Towards general-purpose vision-language models with instruction tuning , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
ACM Computing Surveys , year=
Instruction tuning for large language models: A survey , author=. ACM Computing Surveys , year=
-
[25]
arXiv preprint arXiv:2310.02255 , year=
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts , author=. arXiv preprint arXiv:2310.02255 , year=
-
[26]
Proceedings of the IEEE international conference on computer vision , pages=
Unit: Multimodal multitask learning with a unified transformer , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[27]
International Conference on Machine Learning , pages =
Overcoming catastrophic forgetting with hard attention to the task , author =. International Conference on Machine Learning , pages =
-
[28]
International Conference on Learning Representations , year =
Effect of scale on catastrophic forgetting in neural networks , author =. International Conference on Learning Representations , year =
-
[29]
, author=
Lora: Low-rank adaptation of large language models. , author=. International Conference on Learning Representations , year=
-
[30]
Advances in Neural Information Processing Systems , year =
Nested Learning: The Illusion of Deep Learning Architectures , author =. Advances in Neural Information Processing Systems , year =
-
[31]
Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference , pages=
CL-MoE: Enhancing Multimodal Large Language Model with Dual Momentum Mixture-of-Experts for Continual Visual Question Answering , author=. Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference , pages=
-
[32]
Neural computation , year=
Adaptive mixtures of local experts , author=. Neural computation , year=
-
[33]
arXiv preprint arXiv:2410.10868 , year=
Large Continual Instruction Assistant , author=. arXiv preprint arXiv:2410.10868 , year=
-
[34]
arXiv preprint arXiv:2505.22120 , year=
LoKI: Low-damage Knowledge Implanting of Large Language Models , author=. arXiv preprint arXiv:2505.22120 , year=
-
[35]
Magic-vqa: Multimodal and grounded inference with commonsense knowledge for visual question answering , author=. Findings of the Proceedings of the Annual Meeting of the Association for Computational Linguistics: Proceedings of the Annual Meeting of the Association for Computational Linguistics , pages=
-
[36]
arXiv preprint arXiv:2512.23447 , year=
Coupling Experts and Routers in Mixture-of-Experts via an Auxiliary Loss , author=. arXiv preprint arXiv:2512.23447 , year=
-
[37]
Proceedings of the IEEE international conference on computer vision , pages=
SMoLoRA: Exploring and Defying Dual Catastrophic Forgetting in Continual Visual Instruction Tuning , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[38]
arXiv preprint arXiv:2302.13971 , year=
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
-
[39]
Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference , pages=
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning , author=. Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference , pages=
-
[40]
Advances in Neural Information Processing Systems , volume=
A benchmark for compositional visual reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
arXiv preprint arXiv:2311.07911 , year=
Instruction-following evaluation for large language models , author=. arXiv preprint arXiv:2311.07911 , year=
-
[42]
arXiv preprint arXiv:2508.05580 , year=
Follow-your-instruction: A comprehensive mllm agent for world data synthesis , author=. arXiv preprint arXiv:2508.05580 , year=
-
[43]
Advances in Neural Information Processing Systems , volume =
Overcoming catastrophic forgetting in incremental few-shot learning by finding flat minima , author =. Advances in Neural Information Processing Systems , volume =
-
[44]
International Conference on Machine Learning , pages=
The flan collection: Designing data and methods for effective instruction tuning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[45]
arXiv preprint arXiv:2511.15164 , year=
Multimodal Continual Instruction Tuning with Dynamic Gradient Guidance , author=. arXiv preprint arXiv:2511.15164 , year=
-
[46]
arXiv preprint arXiv:2506.02011 , year=
OASIS: Online Sample Selection for Continual Visual Instruction Tuning , author=. arXiv preprint arXiv:2506.02011 , year=
-
[47]
arXiv preprint arXiv:2508.04227 , year=
Continual learning for VLMs: A survey and taxonomy beyond forgetting , author=. arXiv preprint arXiv:2508.04227 , year=
-
[48]
arXiv preprint arXiv:2506.08666 , year=
LLaVA-c: Continual Improved Visual Instruction Tuning , author=. arXiv preprint arXiv:2506.08666 , year=
-
[49]
Science , volume =
Adityanarayanan Radhakrishnan and Daniel Beaglehole and Parthe Pandit and Mikhail Belkin , title =. Science , volume =
-
[50]
Proceedings of the IEEE international conference on computer vision , pages=
Metamorph: Multimodal understanding and generation via instruction tuning , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[51]
Proceedings of the Annual Meeting of the Association for Computational Linguistics , pages=
Mammoth-vl: Eliciting multimodal reasoning with instruction tuning at scale , author=. Proceedings of the Annual Meeting of the Association for Computational Linguistics , pages=
-
[52]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Otter: A multi-modal model with in-context instruction tuning , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[53]
Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference , pages=
Thinking in space: How multimodal large language models see, remember, and recall spaces , author=. Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference , pages=
-
[54]
Proceedings of the Annual Meeting of the Association for Computational Linguistics , pages=
Multimodal arxiv: A dataset for improving scientific comprehension of large vision-language models , author=. Proceedings of the Annual Meeting of the Association for Computational Linguistics , pages=
-
[55]
arXiv preprint arXiv:2208.05358 , year =
Clevr-math: A dataset for compositional language, visual and mathematical reasoning , author =. arXiv preprint arXiv:2208.05358 , year =
-
[56]
arXiv preprint arXiv:2110.13214 , year=
Iconqa: A new benchmark for abstract diagram understanding and visual language reasoning , author=. arXiv preprint arXiv:2110.13214 , year=
-
[57]
Proceedings of the IEEE international conference on computer vision , pages =
The many faces of robustness: A critical analysis of out-of-distribution generalization , author =. Proceedings of the IEEE international conference on computer vision , pages =
-
[58]
Proceedings of the IEEE international conference on computer vision , pages=
Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[59]
2023 , journal=
PMC-VQA: Visual Instruction Tuning for Medical Visual Question Answering , author=. 2023 , journal=
2023
-
[60]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
Docvqa: A dataset for vqa on document images , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[61]
Findings of the association for computational linguistics , pages=
Chartqa: A benchmark for question answering about charts with visual and logical reasoning , author=. Findings of the association for computational linguistics , pages=
-
[62]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Infographicvqa , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[63]
Proceedings of the AAAI Conference on Artificial Intelligence , pages=
RoadSceneVQA: Benchmarking Visual Question Answering in Roadside Perception Systems for Intelligent Transportation System , author=. Proceedings of the AAAI Conference on Artificial Intelligence , pages=
-
[64]
IEEE Transactions on Visualization and Computer Graphics , volume=
ChemVA: interactive visual analysis of chemical compound similarity in virtual screening , author=. IEEE Transactions on Visualization and Computer Graphics , volume=
-
[65]
IEEE Access , volume=
Floodnet: A high resolution aerial imagery dataset for post flood scene understanding , author=. IEEE Access , volume=
-
[66]
arXiv preprint arXiv:2602.01990 , year=
SAME: Stabilized Mixture-of-Experts for Multimodal Continual Instruction Tuning , author=. arXiv preprint arXiv:2602.01990 , year=
-
[67]
Proceedings of the IEEE international conference on computer vision , pages=
Federated continual instruction tuning , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[68]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Ask and remember: A questions-only replay strategy for continual visual question answering , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[69]
arXiv preprint arXiv:2408.14471 , year=
A Practitioner's Guide to Continual Multimodal Pretraining , author=. arXiv preprint arXiv:2408.14471 , year=
-
[70]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Instruction-Grounded Visual Projectors for Continual Learning of Generative Vision-Language Models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[71]
arXiv preprint arXiv:2503.01887 , year=
When continue learning meets multimodal large language model: A survey , author=. arXiv preprint arXiv:2503.01887 , year=
-
[72]
Proceedings of the AAAI Conference on Artificial Intelligence , pages=
LoRA in LoRA: Towards parameter-efficient architecture expansion for continual visual instruction tuning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , pages=
-
[73]
arXiv preprint arXiv:2506.11672 , year=
Dynamic mixture of curriculum lora experts for continual multimodal instruction tuning , author=. arXiv preprint arXiv:2506.11672 , year=
-
[74]
IJCAI , pages=
Continual learning with pre-trained models: a survey , author=. IJCAI , pages=
-
[75]
Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference , pages=
icarl: Incremental classifier and representation learning , author=. Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference , pages=
-
[76]
PNAS , volume=
Overcoming catastrophic forgetting in neural networks , author=. PNAS , volume=
-
[77]
Proceedings of the Workshop on Towards Knowledgeable Foundation Models (KnowFM) , pages=
MLAN: Language-Based Instruction Tuning Preserves and Transfers Knowledge in Multimodal Language Models , author=. Proceedings of the Workshop on Towards Knowledgeable Foundation Models (KnowFM) , pages=
-
[78]
arXiv preprint arXiv:2508.07307 , year=
Mcitlib: Multimodal continual instruction tuning library and benchmark , author=. arXiv preprint arXiv:2508.07307 , year=
-
[79]
International Conference on Learning Representations , year=
Quantized Gradient Projection for Memory-Efficient Continual Learning , author=. International Conference on Learning Representations , year=
-
[80]
arXiv preprint arXiv:2506.05453 , year=
Mllm-cl: Continual learning for multimodal large language models , author=. arXiv preprint arXiv:2506.05453 , year=
-
[81]
International Conference on Learning Representations , year=
When Large Multimodal Models Confront Evolving Knowledge: Challenges and Explorations , author=. International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.