IdiomX A Multilingual Benchmark for Idiom Understanding, Retrieval, and Interpretation
Pith reviewed 2026-07-04 14:45 UTC · model glm-5.2
The pith
New 190K-Example Multilingual Benchmark Tests Idiom Understanding
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper's central contribution is the demonstration that idiom understanding decomposes into a progression of tasks—detection, monolingual retrieval, cross-lingual retrieval, and interpretation—each of which benefits from progressively different architectural choices. Detection is well-served by contextual transformers. Monolingual retrieval requires hybrid dense-lexical matching with task-specific reranking. Cross-lingual retrieval demands targeted contrastive fine-tuning of multilingual embeddings, with generic multilingual embeddings performing poorly (15.9–19.1% Top-1) but fine-tuned E5 reaching 57.8% Top-1. Interpretation, formulated as retrieval over a multilingual meaning bank, is可行
What carries the argument
The benchmark's four-task progression (detection → retrieval → cross-lingual retrieval → interpretation) is the central organizing structure. The retrieval formulation casts each task as ranking over a fixed inventory: argmax over idioms or meanings using cosine similarity in a shared embedding space. The hybrid retrieve-then-rerank paradigm (MiniLM dense retrieval + BM25 lexical matching + cross-encoder reranking with hard-negative fine-tuning) is the architecture that carries the retrieval results. The dataset construction pipeline (Kaikki/WordNet extraction + OpenSubtitles/Urban Dictionary slang collection + GPT-4 synthetic generation + LLM enrichment with automated validation) is the数据处理
If this is right
- Idiom understanding can be systematically decomposed into discrete evaluable stages, allowing researchers to pinpoint exactly where figurative language processing breaks down—whether at disambiguation, retrieval, cross-lingual alignment, or interpretation.
- The large gap between zero-shot and fine-tuned cross-lingual retrieval (19.1% vs. 57.8% Top-1) suggests that generic multilingual embeddings do not naturally align figurative expressions across languages, and that targeted contrastive supervision is essential for cross-lingual idiom tasks.
- Modeling idiom interpretation as retrieval over a meaning bank, rather than as free-form generation, provides a controllable and evaluable framework that could be extended to other non-compositional language phenomena like metaphor or irony.
- The modular pipeline design means additional languages and figurative reasoning tasks can be added without restructuring the benchmark, making it extensible to broader multilingual figurative language research.
Load-bearing premise
The benchmark's ground truth—contextual examples, idiomatic/literal labels, multilingual translations, and semantic explanations—is generated and validated by GPT-4-class models through an automated pipeline. No human inter-annotator agreement scores are reported, and the quality metrics presented are themselves produced by the same automated system. If the LLM-generated data contains systematic errors, stylistic biases, or incorrect translations, all baseline results measure
What would settle it
Human annotation of a representative sample of IdiomX examples would test whether the LLM-generated labels, translations, and contextual examples match human judgments. If human annotators disagree with the idiomatic/literal labels at rates significantly higher than typical inter-annotator agreement for figurative language (often 80-90%+), or if the Arabic and French translations contain systematic errors, the benchmark's validity would be undermined.
Figures
read the original abstract
Idiomatic expressions remain a persistent challenge for natural language processing because their meanings are often non-compositional, context-dependent, and difficult to align across languages. Existing idiom resources are often limited in scale, contextual diversity, or multilingual coverage, restricting their utility for modern language models. We introduce IdiomX, a large-scale multilingual benchmark for idiom understanding, retrieval, and interpretation, constructed through a reproducible multi-stage pipeline combining lexical resource extraction, large-scale normalization, controlled large language model enrichment, and structured validation. The resulting dataset contains over 190K contextualized examples spanning 12K+ idioms, with aligned English, Arabic, and French semantic representations, idiomatic and literal usage labels, and rich linguistic metadata. Building on this resource, we define a unified four-task benchmark covering idiom detection, context-to-idiom retrieval, Arabic-to-English idiom retrieval, and idiom interpretation, extending evaluation from figurative recognition to semantic grounding and explainable meaning retrieval. Experiments show that contextual transformer models substantially improve idiom detection, while hybrid retrieval and reranking architectures significantly strengthen both monolingual and cross-lingual idiom retrieval. Results further demonstrate that idiom interpretation can be effectively modeled as a semantic retrieval task, introducing interpretability as a complementary benchmark dimension. Overall, IdiomX provides a scalable benchmark for studying idiomatic language as a progression from detection to retrieval and semantic interpretation, and offers a modular framework extensible to additional languages and figurative reasoning tasks
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IdiomX, a large-scale multilingual benchmark for idiom understanding spanning four tasks: idiom detection (binary classification), context-to-idiom retrieval (monolingual), Arabic-to-English idiom retrieval (cross-lingual), and idiom interpretation (multilingual meaning retrieval). The dataset contains over 190K contextualized examples covering 12K+ idioms, constructed through a multi-stage pipeline combining lexical resource extraction (Kaikki, WordNet, OpenSubtitles, Urban Dictionary), LLM-based enrichment (GPT-4-class models), and automated validation. Baseline experiments show RoBERTa achieving 92.6% detection accuracy, a fine-tuned hybrid reranker achieving 88.5% Top-1 retrieval, fine-tuned multilingual E5 achieving 57.8% Top-1 cross-lingual retrieval, and a hybrid reranker achieving 67.4% Top-1 on interpretation. All dataset, code, and model resources are publicly released.
Significance. The paper addresses a genuine gap: existing idiom resources (VNC-Tokens, SemEval-2013, IDIX, MAGPIE, PIE) are predominantly monolingual and single-task, while IdiomX offers unified four-task evaluation with multilingual coverage (English, Arabic, French). The scale (190K+ examples, 12K+ idioms) substantially exceeds prior resources. The progression from detection through retrieval to semantic interpretation is a thoughtful benchmark design. The paper ships fully reproducible resources: dataset on Hugging Face, construction pipeline and benchmark code on GitHub, and an interactive demo (IdiomX Studio). The cross-lingual Arabic-English idiom retrieval task (Task 3) is particularly novel and addresses an underrepresented language pair in figurative language NLP. However, the benchmark's validity is currently undermined by the absence of independent human validation of LLM-generated labels, which is a load-bearing gap for a benchmark paper.
major comments (4)
- §III.B and §IV.B: The benchmark's ground-truth labels (idiomatic vs. literal usage, multilingual translations, semantic explanations) are generated by GPT-4-class models, and the quality assurance pipeline ('structured prompt constraints, automated semantic verification, rule-based correction, and statistical validation') is itself automated. Figure 3's 'semantic quality distribution' is produced by this same pipeline, making it self-referential — it cannot independently detect systematic biases in GPT-4's labeling. No human inter-annotator agreement scores or manual validation rates are reported anywhere. For a benchmark paper, this is load-bearing: if the labels contain systematic errors or stylistic biases, all baseline results measure performance on LLM-generated text rather than on natural idiom usage. The paper should include at minimum a human validation study on a representative,
- §VI.C.1: Task 3 (Arabic-to-English idiom retrieval) uses example-level splitting rather than idiom-level splitting. This means the same idiom can appear in both train and test splits (in different contextual realizations), so the model may learn idiom-specific mappings rather than demonstrating genuine cross-lingual generalization. The paper acknowledges this design choice ('to preserve a realistic fixed candidate inventory while testing contextual generalization') but does not report results under idiom-level splitting for comparison. Given that Task 2 uses query-level splitting (§VI.B.1), the inconsistency in split strategy across tasks weakens the benchmark's unified framing. An idiom-level split experiment (or at minimum a discussion of the performance gap) should be reported to clarify whether the 57.8% Top-1 result reflects genuine cross-lingual idiom understanding or idiom memoriz
- §III.D: The paper claims 'balanced idiomatic versus literal supervision' but does not report the exact class distribution. Figure 4 ('Label Distribution') is referenced but the actual proportions are not stated in text. For a benchmark where class balance is a stated design feature, the precise idiomatic/literal/borderline percentages should be reported numerically. Additionally, the 'near-balanced distribution' language in §IV.B is vague — the paper should state whether balance was achieved by construction (e.g., stratified sampling) or emerged from the generation process, and what the borderline proportion is, since borderline cases are the most challenging and most informative for evaluating model capability.
- §VI.A.2 and Table 2: The idiom detection results (RoBERTa 92.6% accuracy) may be inflated relative to real-world performance if GPT-4 generates contextual sentences with stronger disambiguating cues than natural text. The paper does not compare detection performance on naturally-occurring idiom usage (e.g., from MAGPIE or PIE) versus LLM-generated examples. A cross-dataset comparison — even on a small sample — would help calibrate whether the 92.6% reflects genuine idiom disambiguation capability or artifactually clear contexts. This is load-bearing for the benchmark's ecological validity.
minor comments (8)
- §VI.C.1: The mathematical formulation of cosine similarity contains garbled characters (appears to be an encoding issue with the Arabic text rendering). The equation should be typeset cleanly.
- §IV.A: The compositionality distribution (Figure 2) is described qualitatively ('most idioms are semi-opaque, followed by opaque and transparent') but no numerical breakdown is given. Adding percentages would strengthen the analysis.
- Table 1: The 'Bi' (balanced) column shows 'N' for all prior datasets and 'Y' for IdiomX, but the balance criterion is not defined in the table caption. A footnote or caption note explaining what 'balanced' means would help readers.
- §VI.B.2: The fine-tuned reranker's hard-negative mining strategy is mentioned but not specified. The number of hard negatives, selection criteria, and training data should be documented for reproducibility.
- §VI.C.2: The fine-tuning setup for multilingual E5 mentions 'contrastive learning' but does not specify key hyperparameters (learning rate, epochs, batch size, negative sampling strategy). These should be reported alongside the Task 1 hyperparameters.
- References [22], [23], [31] are dated 2026, which appears to be a typo and should be corrected.
- §II.C: The paper states IdiomX 'substantially extends prior idiom resources in scale, multilingual coverage, and support for a unified four-task benchmark' but does not discuss the tradeoff that LLM-generated data may lack the distributional properties of naturally occurring idiom usage. A brief discussion of this tradeoff would strengthen the positioning relative to MAGPIE and PIE, which use naturally occurring text.
- §IX: The limitations section mentions 'residual synthetic biases' but does not discuss the potential for GPT-4 contamination in models evaluated on the benchmark (e.g., if RoBERTa or E5 were pretrained on data that includes GPT-4 outputs). This is a relevant concern for benchmark validity.
Simulated Author's Rebuttal
We thank the referee for a thorough and constructive report. The referee raises four major concerns, all of which are substantive. We agree that the absence of human validation is the most important gap and will address it with a new annotation study. We also agree on the need for idiom-level split experiments for Task 3, numerical class balance reporting, and cross-dataset calibration for Task 1. We outline our planned revisions below.
read point-by-point responses
-
Referee: §III.B and §IV.B: The benchmark's ground-truth labels are generated by GPT-4-class models, and the quality assurance pipeline is itself automated, making Figure 3 self-referential. No human inter-annotator agreement or manual validation rates are reported. For a benchmark paper, this is load-bearing.
Authors: The referee is correct that the current manuscript lacks independent human validation, and we agree this is the most important issue to address. In the revision, we will conduct a human validation study on a representative stratified sample (at least 500 examples spanning idiomatic, literal, and borderline labels across all three languages). Two annotators with linguistics expertise will independently label the sample, and we will report inter-annotator agreement (Cohen's kappa) and agreement-with-GPT-labels rates. We will also add a discussion of observed systematic biases, if any. We acknowledge that Figure 3's quality distribution is produced by the same automated pipeline and will clearly label it as an internal consistency check rather than independent validation. The human study will provide the external calibration the referee requests. revision: yes
-
Referee: §VI.C.1: Task 3 uses example-level splitting rather than idiom-level splitting, so the same idiom can appear in both train and test. The paper does not report idiom-level split results for comparison. This is inconsistent with Task 2's query-level splitting and weakens the benchmark's unified framing.
Authors: We agree that the inconsistency in split strategy across tasks should be addressed empirically. In the revision, we will run an idiom-level split experiment for Task 3 and report the performance gap alongside the example-level results. This will clarify whether the 57.8% Top-1 result reflects genuine cross-lingual generalization or partial idiom memorization. We will also add a brief discussion justifying the example-level split as the primary configuration (to preserve a realistic fixed candidate inventory) while presenting the idiom-level results as a stricter generalization condition. The referee's concern about unified framing is valid, and we will make the split rationale and comparison explicit. revision: yes
-
Referee: §III.D: The paper claims 'balanced idiomatic versus literal supervision' but does not report exact class distribution. Figure 4 is referenced but proportions are not stated in text. The 'near-balanced distribution' language is vague; the paper should state whether balance was achieved by construction or emerged from generation, and what the borderline proportion is.
Authors: This is a fair point. In the revision, we will report the exact idiomatic/literal/borderline percentages numerically in the text alongside Figure 4. We will also clarify that balance was achieved through stratified sampling during dataset construction rather than emerging naturally from the generation process, and we will state the borderline proportion explicitly. The 'near-balanced' language will be replaced with precise numbers. revision: yes
-
Referee: §VI.A.2 and Table 2: The 92.6% RoBERTa detection accuracy may be inflated if GPT-4 generates contexts with stronger disambiguating cues than natural text. No cross-dataset comparison with naturally-occurring idiom usage (e.g., MAGPIE or PIE) is reported. This is load-bearing for ecological validity.
Authors: The referee raises a legitimate concern about ecological validity. We will address this by running RoBERTa on a sample from MAGPIE (which contains naturally-occurring idiom usage) and reporting the comparison alongside our IdiomX results. If performance drops on natural text, this would confirm the referee's hypothesis about disambiguation cue strength and we will discuss it transparently. We will also sample a subset of MAGPIE idioms that overlap with IdiomX's idiom inventory to enable a more controlled comparison. We acknowledge that this cross-dataset calibration is important for interpreting the benchmark's detection results and will include it in the revision. revision: yes
Circularity Check
No significant circularity in the derivation chain; the GPT-4 label-generation concern is a validity risk, not a construction-level circularity.
full rationale
This is a benchmark/dataset paper, not a theoretical derivation. The central claims (baseline results on four tasks) are obtained by training and evaluating standard models (RoBERTa, DistilBERT, MiniLM, E5, BM25) on held-out splits of the IdiomX dataset. These models are architecturally distinct from the GPT-4-class models used to generate the dataset labels, so the evaluation results are not equivalent to the generation pipeline by construction. The self-citations ([22], [23], [31]) point to released resources (GitHub repos, Hugging Face datasets, demo studio) and do not form a load-bearing theoretical chain. The concern that GPT-4-generated labels are validated by an automated pipeline (§III.B, Figure 3) is a legitimate dataset-validity risk — the quality distribution in Figure 3 is produced by the same pipeline that generated the data — but the paper does not claim this as a 'prediction' or 'first-principles result'; it is a descriptive statistic. No equation or derivation step reduces to its own inputs by construction. The paper acknowledges residual synthetic biases in §IX as a limitation. Score 1 reflects the minor self-referential quality assessment without any load-bearing circularity in the benchmark's experimental claims.
Axiom & Free-Parameter Ledger
free parameters (4)
- LLM enrichment prompt constraints =
unspecified
- Semantic quality threshold =
unspecified
- Compositionality classification criteria =
unspecified
- Fine-tuning hard-negative mining strategy =
unspecified
axioms (4)
- ad hoc to paper GPT-4-class models can generate high-quality contextual idiom examples, labels, and multilingual translations suitable for benchmark ground truth
- ad hoc to paper Automated semantic verification and rule-based correction can reliably filter LLM-generated idiom data
- domain assumption Example-level splitting is appropriate for cross-lingual retrieval evaluation
- domain assumption Cosine similarity in a shared multilingual embedding space is an appropriate metric for cross-lingual idiom alignment
Reference graph
Works this paper leans on
-
[1]
IdiomX, a large -scale multilingual benchmark for idiom understanding with aligned semantic representations across English, Arabic, and French
-
[2]
A reproducible multi-stage data construction and enrichment pipeline for generating high-quality idiomatic examples with structured validation
-
[3]
A unified benchmark spanning four tasks covering idiom detection, retrieval, cross -lingual retrieval, and idiom interpretation
-
[4]
Extensive experiments and analyses establishing strong baselines and demonstrating IdiomX as a scalable benchmark for figurative language research. Overall, IdiomX bridges dataset construction and task - oriented evaluation, providing a foundation for research on figurative reasoning, multilingual semantic retrieval, and idiom interpretation. II. RELATED ...
2013
-
[5]
Core Idioms Pipeline (Kaikki + WordNet) This pipeline extracts idioms from structured lexical resources and applies filtering, normalization, and merging to construct a high-precision idiom inventory
-
[6]
Modern Idioms and Slang Pipeline (OpenSubtitles + Urban + Wiktionary) To capture contemporary usage, modern idioms and slang are collected from informal and conversational sources, then normalized and merged through the same quality -controlled pipeline
-
[7]
He finally kicked the bucket after a long illness
Synthetic Idiom Generation Pipeline (LLM -based) To extend coverage beyond existing resources, additional idioms are generated using GPT-4-class models [24], followed by filtering, normalization, and deduplication . After independent processing, outputs from all pipelines are merged into a unified canonical idiom representation . B. LLM Enrichment, Valida...
-
[8]
We formulate this as a binary classification task where each input sentence is assigned one of two labels (Idiomatic, Literal)
Problem Definition Idiom detection evaluates whether an expression in context is used figuratively or literally, a classical challenge in figurative language understanding [1], [2]. We formulate this as a binary classification task where each input sentence is assigned one of two labels (Idiomatic, Literal). This task measures contextual disambiguation ab...
-
[9]
RoBERTa [15] as a stronger contextual encoder
Experimental Setup We evaluate three increasingly powerful contextual models: TF-IDF + Logistic Regression as a lexical baseline DistilBERT [29] as lightweight contextual transformer baseline. RoBERTa [15] as a stronger contextual encoder. The dataset is nearly balanced (≈50% idiomatic / 50% literal) and split into train, validation, and test sets u...
-
[10]
Results Table 2 presents idiom detection results. Model Accuracy F1-score TF-IDF + Logistic Regression 0.865 0.865 DistilBERT [29] 0.919 0.919 RoBERTa [15] 0.926 0.926 Table 2: Model Performance on Idiom Detection Task Figure 6: Idiom detection performance across models Transformer-based models substantially outperform the lexical baseline, confirming the...
-
[11]
(2) Idiom Bias Frequent idioms may be incorrectly predicted as figurative even in literal contexts
Error Analysis and Calibration Despite strong overall performance, several recurring failure modes remain: (1) Limited Context Short or context-poor sentences can obscure whether an expression is literal or figurative. (2) Idiom Bias Frequent idioms may be incorrectly predicted as figurative even in literal contexts. False positives are slightly more freq...
-
[12]
He finally kicked the bucket after a long illness
Qualitative Examples Representative examples illustrate both strengths and limitations: Correct: “He finally kicked the bucket after a long illness.” Prediction: Idiomatic Figure 7: Confusion matrix for RoBERTa on the test set. Figure 8: ROC curve for RoBERTa (AUC = 0.979). Figure 9: Confidence distribution for correct vs incorrect predictions . Figure 10...
-
[13]
While detection accuracy is high, remaining errors highlight persistent challenges involving ambiguity, implicit meaning, and idiom memorization bias
Summary Results show that idiom detection benefits substantially from contextual transformer models, with RoBERTa [15] achieving the strongest performance. While detection accuracy is high, remaining errors highlight persistent challenges involving ambiguity, implicit meaning, and idiom memorization bias. Overall, Task 1 establishes a strong classificatio...
-
[14]
A query-level split is used to avoid sentence leakage while allowing the same idiom to appear across splits in different contextual realizations
Benchmark Construction The benchmark is derived from the IdiomX high -quality subset using only examples that are : (1) idiomatic in usage (2) validation-approved (3) high semantic quality The resulting benchmark contains 54,469 examples and 13,803 canonical idioms. A query-level split is used to avoid sentence leakage while allowing the same idiom to app...
-
[15]
Retrieval Architecture We evaluate four progressively stronger retrieval settings. MiniLM Dense Retrieval using sentence embeddings [28] Hybrid Retrieval combining MiniLM and BM25 [26] Hybrid + Cross-Encoder Reranker [28] Hybrid + Fine-Tuned Reranker, using task-specific hard- negative training. This staged architecture follows a standard retrieve...
-
[16]
Mean Reciprocal Rank (MRR)
-
[17]
Results Table 4 reports retrieval performance . Model Top-1 Top-3 Top-5 MRR MiniLM 0.640 0.748 0.787 0.707 Hybrid (MiniLM + BM25) 0.761 0.857 0.882 0.817 Hybrid + reranker 0.838 0.901 0.906 0.869 Hybrid + Fine- Tuned Reranker 0.885 0.909 0.909 0.897 Table 4: Main Task 2 retrieval results on the closed-set benchmark. Results show monotonic improvement as r...
-
[18]
Hybrid retrieval significantly improves recall
-
[19]
Reranking improves precision among top candidates
-
[20]
Fine-tuning provides the largest gains for semantically similar idioms
-
[21]
Representative errors fall into four categories:
Error Analysis Despite strong performance, approximately 11.5% of test queries remain incorrectly ranked . Representative errors fall into four categories:
-
[22]
Semantically Similar Idioms Near-miss predictions where plausible alternatives outrank the gold idiom
-
[23]
Frequency Bias Common idioms may be preferred over less frequent but correct expressions
-
[24]
Surface Lexical Bias Strong lexical overlap can sometimes override deeper semantic matching
-
[25]
Figure 14: Distribution of correct and incorrect predictions for Task 2 on the test set
Ambiguous and Long-Tail Cases Short contexts and rare idioms remain challenging. Figure 14: Distribution of correct and incorrect predictions for Task 2 on the test set. These findings suggest that remaining errors stem primarily from ambiguity, frequency effects, and long -tail idioms
-
[26]
Bone apple tea… bon appétit
Qualitative Examples Representative examples from Table 6 illustrate both successful retrieval and common failure modes. Query (shortened) True Idiom Top-1 Top-3 (shortened) ✓ “Bone apple tea… bon appétit” bon appétit throw a bone to throw a bone…; wise apple; contrary… ✗ “…finally broke the ice…” break the ice break the ice break the ice; ease tension; s...
-
[27]
Hybrid retrieval, reranking, and task -specific fine -tuning substantially improve idiom recovery, with the fine -tuned reranker achieving the strongest performance
Summary Task 2 shows that idiom understanding can be effectively modeled as a retrieval problem, but high performance requires more than semantic embeddings alone . Hybrid retrieval, reranking, and task -specific fine -tuning substantially improve idiom recovery, with the fine -tuned reranker achieving the strongest performance . Overall, Task 2 establish...
-
[28]
Formulation ݕݐ݅ݎ݈ܽ݅݉݅ܵ ݏ݅ ݀݁ݐݑ݉ܿ ݃݊݅ݏݑ ݁݊݅ݏܿ ݕݐ݅ݎ݈ܽ݅݉݅ݏ [5]: ݉݅ݏ(ݔ,݅ )= ℎ௫ . ℎ ‖ℎ௫‖. ‖ℎ‖
-
[29]
To preserve a realistic fixed candidate inventory while testing contextual gene ralization, we adopt example -level splitting rather than idiom-level splitting
Experimental Setup The final benchmark uses idiomatic examples only, where the Arabic query is taken from idiom -in-context Arabic examples and the retrieval target is the canonical English idiom. To preserve a realistic fixed candidate inventory while testing contextual gene ralization, we adopt example -level splitting rather than idiom-level splitting....
-
[30]
Top-ܭ accuracy measures whether the correct idiom appears within the top ܭretrieved candidates
Quantitative Results Performance is evaluated using standard ranking metrics, including Top-1 and Top-5 accuracy. Top-ܭ accuracy measures whether the correct idiom appears within the top ܭretrieved candidates. Table 7 presents retrieval results. Model Embedding Dim Top-1 Top-5 MiniLM-L12-v2 [27] 384 0.159 0.254 E5-base (zero-shot) 768 0.191 0.310 E5-base ...
-
[31]
Figure 16: Error distribution across prediction outcomes
Error and Calibration Analysis Error analysis reveals three major outcomes: Top-1 correct: 57.8% Correct idiom retrieved but misranked: 18.3% Fully incorrect: 23.9% As shown in Figure 16, many failures arise from ranking errors rather than retrieval failures, since the correct idiom often appears within Top-5 candidates. Figure 16: Error distributio...
-
[32]
اﻧﺘﮭﻰ ﻛﻞ ﺷﻲء ﻓﻲ اﻟﻨﮭﺎﯾﺔ
Qualitative Cross-Lingual Analysis To better understand model behavior, we present representative examples illustrating both successful predictions and typical failure cases. The model performs well when the Arabic context provides clear semantic signals. For example: Arabic: "اﻧﺘﮭﻰ ﻛﻞ ﺷﻲء ﻓﻲ اﻟﻨﮭﺎﯾﺔ" Prediction: come to an end Arabic: "ﺷﺎرك ھﻤﻮﻣﻚ ﻣﻊ ...
-
[33]
Results show that multilingual pretrained embeddings alone are insufficient, while task -specific fine - tuning substantially improves performance
Summary Task 3 establishes a challenging benchmark for cross-lingual figurative retrieval. Results show that multilingual pretrained embeddings alone are insufficient, while task -specific fine - tuning substantially improves performance . Although retrieval coverage is strong, remaining errors largely stem from ranking ambiguity among semantically simila...
-
[34]
Task Formulation Given an idiom query ݔprediction is defined as: ݉∗ = arg max ∈ெ ݉݅ݏ(ݔ,݉ ) where ܯdenotes the meaning inventory and ݉݅ݏ(⋅)is cosine similarity in a shared embedding space . Each retrieved result returns: Canonical idiom English meaning Arabic meaning French meaning (when available) This formulation evaluates semantic grounding rat...
-
[35]
Performance is evaluated using Top -1 and Top -5 retrieval accuracy together with Mean Reciprocal Rank (MRR), following the retrieval setup used in Tasks 2 and 3
Experimental Setup We construct the meaning retrieval bank from aligned semantic fields in IdiomX, combining: canonical idioms idiom-level meanings contextual meaning paraphrases multilingual aligned meanings We evaluate dense semantic retrieval using multilingual sentence embeddings and retrieval -based semantic matching methods inspired by Sente...
-
[36]
Table 8 reports Task 4 results
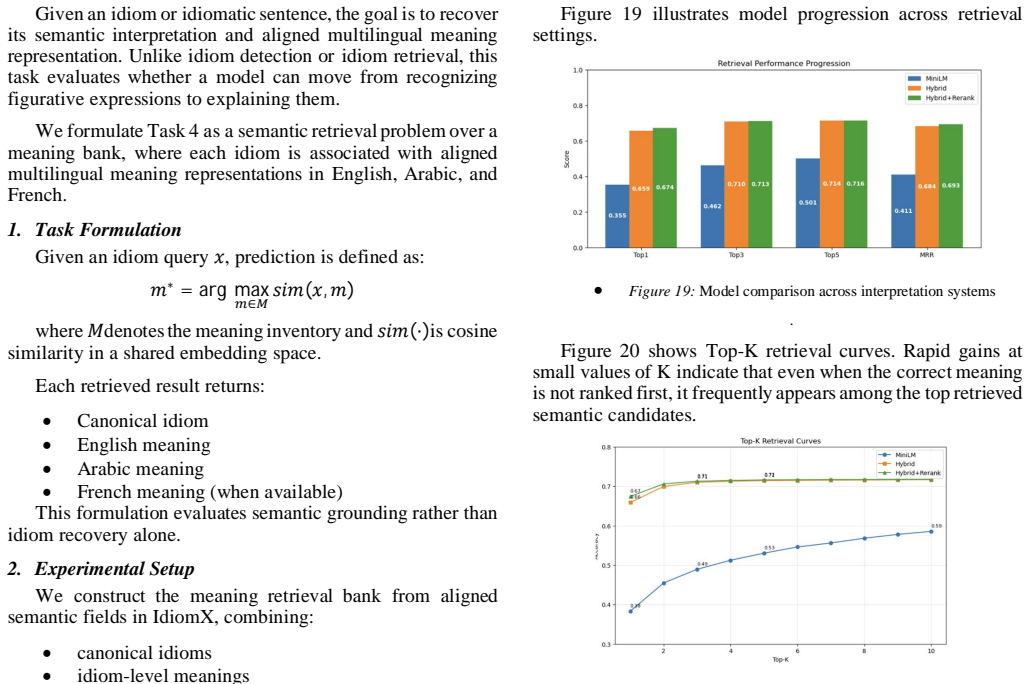
Quantitative Results Performance is evaluated using Top -1, Top -3, Top -5 retrieval accuracy and Mean Reciprocal Rank (MRR), following the retrieval protocol used in Tasks 2 and 3. Table 8 reports Task 4 results. Model Top-1 Top-3 Top-5 MRR Dense Retriever (MiniLM) 0.355 0.462 0.501 0.411 Hybrid Retrieval 0.659 0.710 0.714 0.684 Hybrid + Reranker 0.674 0...
-
[37]
Error Analysis Remaining failures largely fall into three categories:
-
[38]
Short or ambiguous idioms with underspecified context
-
[39]
Lexical confusion between semantically related paraphrases
-
[40]
Figure 21: distribution of these failure modes
Semantic confusion among near -neighbor idiomatic meanings Figure 21 shows the distribution of these failure modes. Figure 21: distribution of these failure modes. Unlike retrieval failures in Tasks 2 –3, many Task 4 errors involve semantically plausible interpretations rather than entirely incorrect predictions, suggesting ranking precision rather than r...
-
[41]
Qualitative Examples Representative examples illustrate the interpretation capability: Input: spill the tea Retrieved meaning: reveal gossip or personal secrets Arabic: ﻛﺸﻒ اﻟﺸﺎﺋﻌﺎت أو اﻷﺳﺮار French: révéler des potins ou des secrets Input: break the ice Retrieved meaning: reduce social tension and start conversation Arabic: ﻛﺴﺮ اﻟﺠﻤﻮد وﺑﺪء اﻟﺤﺪﯾﺚ French:...
-
[42]
Discussion Task 4 extends idiom understanding beyond detection and retrieval into semantic interpretation, introducing an explainability-oriented benchmark dimension absent from prior idiom benchmarks [1]–[5]. This task is particularly relevant for: language learning systems multilingual semantic search explainable NLP systems machine translation ...
-
[43]
Summary Results show that idiom interpretation can be effectively modeled as semantic retrieval, with hybrid retrieval and reranking achieving strong performance. Task 4 introduces a new benchmark dimension focused on semantic grounding and interpretability, extending IdiomX beyond idiom recognition toward explainable figurative language understanding. Ta...
-
[44]
The VNC -Tokens Dataset,
P. Cook, A. Fazly, and S. Stevenson, “The VNC -Tokens Dataset,” in Proc. LREC Workshop on Multiword Expressions, 2008
2008
-
[45]
SemEval -2013 Task 5b: Automatic Annotation and Classification of Idiomatic Expressions,
I. Korkontzelos et al., “SemEval -2013 Task 5b: Automatic Annotation and Classification of Idiomatic Expressions,” *SEM, 2013
2013
-
[46]
The PIE Corpus: A Large Dataset for Idiomatic and Literal Expressions,
H. Haagsma et al., “The PIE Corpus: A Large Dataset for Idiomatic and Literal Expressions,” in Proc. LREC, 2020
2020
-
[47]
MAGPIE: A Large Corpus of Potentially Idiomatic Expressions,
H. Haagsma et al., “MAGPIE: A Large Corpus of Potentially Idiomatic Expressions,” in Proc. LREC, 2020
2020
-
[48]
Predicting Human Metaphor Paraphrase Judgments with Deep Neural Networks,
Y. Bizzoni and S. Lappin, “Predicting Human Metaphor Paraphrase Judgments with Deep Neural Networks,” in Proc. ACL, 2018
2018
-
[49]
Unsupervised Cross -lingual Representation Learning at Scale,
A. Conneau et al., “Unsupervised Cross -lingual Representation Learning at Scale,” in Proc. ACL, 2020
2020
-
[50]
Kaikki.org Dictionary Project
Kaikki.org, “Kaikki.org Dictionary Project.” [Online]. Available: https://kaikki.org/
-
[51]
WordNet: A Lexical Database for English,
G. A. Miller, “WordNet: A Lexical Database for English,” Communications of the ACM, 1995
1995
-
[52]
Training Language Models to Follow Instructions with Human Feedback,
L. Ouyang et al., “Training Language Models to Follow Instructions with Human Feedback,” NeurIPS, 2022
2022
-
[53]
Self -Instruct: Aligning Language Models with Self - Generated Instructions,
Y. Wang et al., “Self -Instruct: Aligning Language Models with Self - Generated Instructions,” ACL, 2023
2023
-
[54]
Datasheets for Datasets,
T. Gebru et al., “Datasheets for Datasets,” Communications of the ACM, 2021
2021
-
[55]
Constitutional AI: Harmlessness from AI Feedback,
Y. Bai et al., “Constitutional AI: Harmlessness from AI Feedback,” arXiv, 2022
2022
-
[56]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,
J. Devlin et al., “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” NAACL, 2019
2019
-
[57]
Unsupervised Type and Token Identification of Idiomatic Expressions,
A. Fazly, P. Cook, and S. Stevenson, “Unsupervised Type and Token Identification of Idiomatic Expressions,” Computational Linguistics, 2009
2009
-
[58]
RoBERTa: A Robustly Optimized BERT Pretraining Approach,
Y. Liu et al., “RoBERTa: A Robustly Optimized BERT Pretraining Approach,” arXiv, 2019
2019
-
[59]
On Calibration of Modern Neural Networks,
C. Guo et al., “On Calibration of Modern Neural Networks,” ICML, 2017
2017
-
[60]
Sentence -BERT: Sentence Embeddings using Siamese BERT-Networks,
N. Reimers and I. Gurevych, “Sentence -BERT: Sentence Embeddings using Siamese BERT-Networks,” EMNLP, 2019
2019
-
[61]
Scaling Instruction -Finetuned Language Models,
C. Chung et al., “Scaling Instruction -Finetuned Language Models,” arXiv, 2022
2022
-
[62]
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer,
C. Raffel et al., “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer,” JMLR, 2020
2020
-
[63]
Idioms in Context: The IDIX Corpus,
C. Sporleder et al., “Idioms in Context: The IDIX Corpus,” LREC, 2010
2010
-
[64]
Idiom Token Classification using Sentential Distributed Semantics,
G. Salton et al., “Idiom Token Classification using Sentential Distributed Semantics,” ACL, 2016
2016
-
[65]
A. A. Sharara, IdiomX Dataset Construction and Benchmark Code, GitHub, 2026. [Online]. Available: https://github.com/aymanshar/idiomx -dataset
2026
-
[66]
A. A. Sharara, IdiomX Dataset and Benchmark Resources , Hugging Face, 2026. [Online]. Available: https://huggingface.co/datasets/aymansharara/IdiomX
2026
-
[67]
OpenAI, “GPT -4 Technical Report,” 2024. [Online]. Available: https://arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[68]
Data Statements for Natural Language Processing,
E. M. Bender and B. Friedman, “Data Statements for Natural Language Processing,” Transactions of the ACL, 2018
2018
-
[69]
The Probabilistic Relevance Framework: BM25 and Beyond,
S. Robertson and H. Zaragoza, “The Probabilistic Relevance Framework: BM25 and Beyond,” Foundations and Trends in Information Retrieval, vol. 3, no. 4, pp. 333–389, 2009
2009
-
[70]
MiniLM: Deep Self -Attention Distillation for Task - Agnostic Compression of Pre -Trained Transformers,
W. Wang et al., “MiniLM: Deep Self -Attention Distillation for Task - Agnostic Compression of Pre -Trained Transformers,” NeurIPS, 2020
2020
-
[71]
R. Nogueira and K. Cho, “Passage Re -ranking with BERT,” arXiv:1901.04085, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[72]
DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter,
V. Sanh, L. Debut, J. Chaumond, and T. Wolf, “DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter,” NeurIPS EMC2 Workshop, 2019
2019
-
[73]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
L. Wang et al., “Text Embeddings by Weakly -Supervised Contrastive Pre-training,” arXiv:2212.03533, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[74]
IdiomX Studio,
A. A. Sharara, “IdiomX Studio,” Hugging Face Spaces, 2026. https://huggingface.co/spaces/aymansharara/idiomx -studio
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.