AVTrack: Audio-Visual Tracking in Human-centric Complex Scenes
Pith reviewed 2026-06-28 14:58 UTC · model grok-4.3
The pith
A new dataset for audio-visual instance segmentation shows existing methods degrade sharply in scenes with camera motion and occlusions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AVTrack is a human-centric audio-visual instance segmentation dataset built for dynamic real-world conditions. Evaluations of current AVIS methods on this dataset produce large performance drops, demonstrating that prior benchmarks have overstated robustness by testing only on homogeneous scenes.
What carries the argument
The AVTrack dataset, which supplies fine-grained audio-visual instance segmentation annotations under camera motion, visual occlusions, and speaker position changes.
If this is right
- Methods must incorporate explicit handling of camera motion and occlusions to maintain tracking accuracy.
- Future benchmarks should prioritize dynamic, multi-speaker scenes over static co-occurrence settings.
- The provided baseline offers a starting point for developing models that reason jointly across audio and visual streams over time.
- Applications such as surveillance and video editing will require algorithms validated on conditions like those in AVTrack.
Where Pith is reading between the lines
- If the performance gap persists across multiple independent implementations, research attention will shift from single-frame detection to long-term cross-modal association.
- The dataset construction choices could be reused to create similar test sets for other multi-modal tasks such as audio-visual action recognition.
- Improved methods developed on AVTrack may transfer to related problems like multi-speaker diarization in video.
Load-bearing premise
The chosen conditions of camera motion, occlusions, and position changes are representative of real-world difficulty and that observed performance drops arise from these factors rather than from how the dataset or metrics were constructed.
What would settle it
A re-run of the same methods on AVTrack after correcting any annotation or evaluation artifacts that produces no significant accuracy drop relative to prior datasets.
Figures


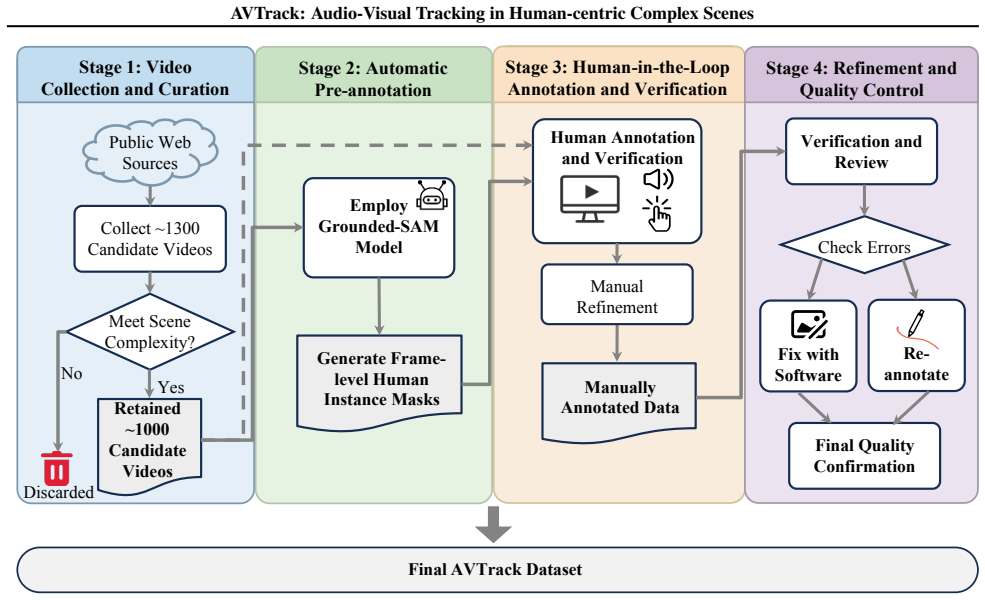
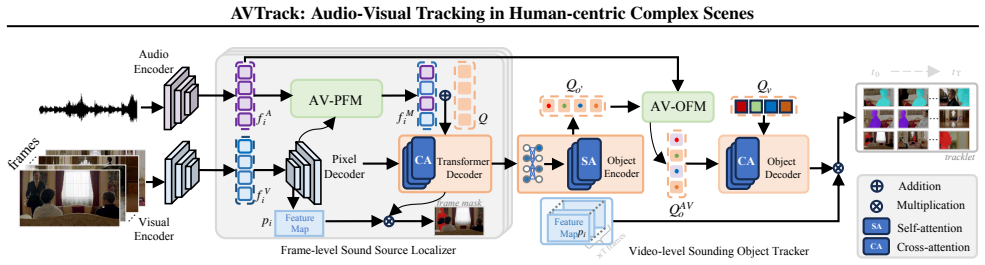
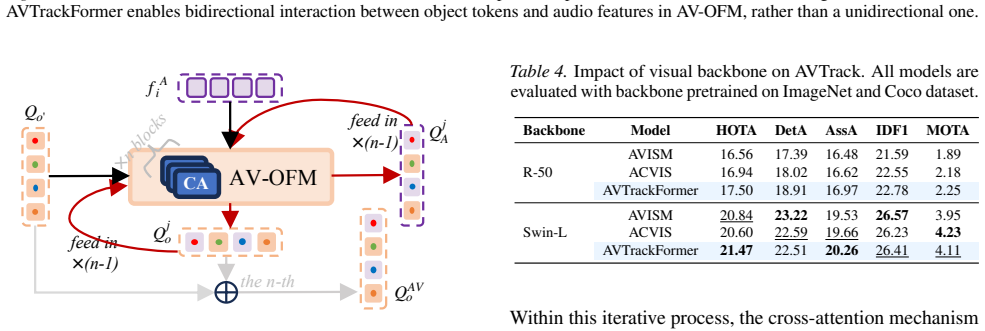

read the original abstract
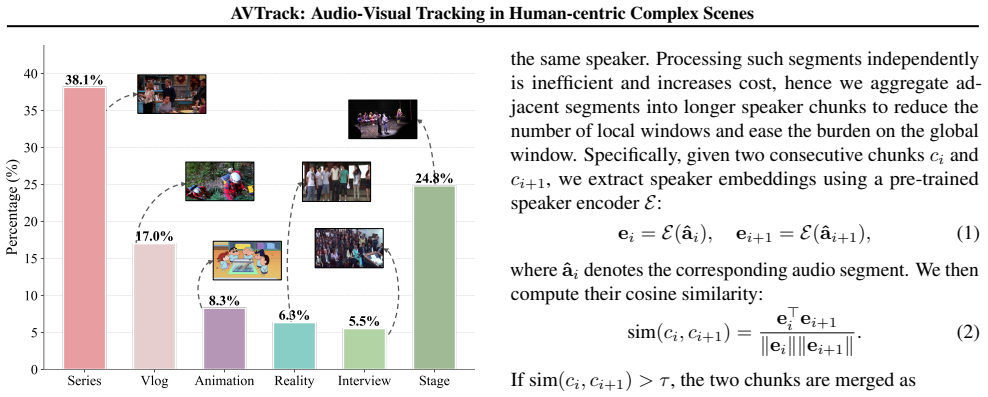
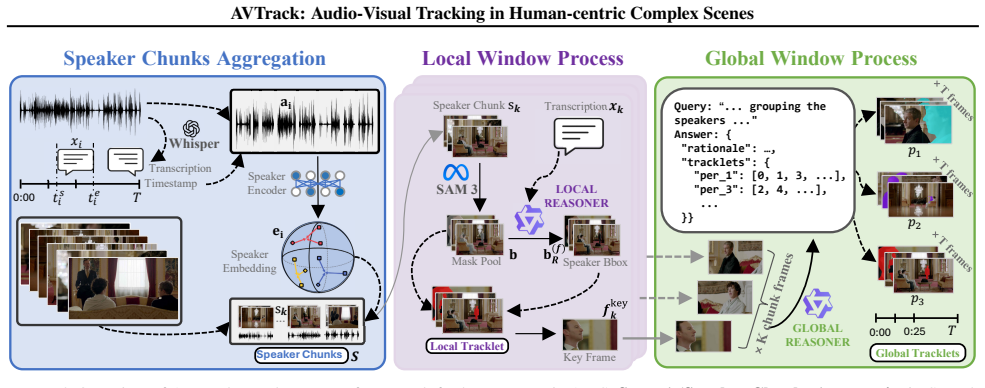
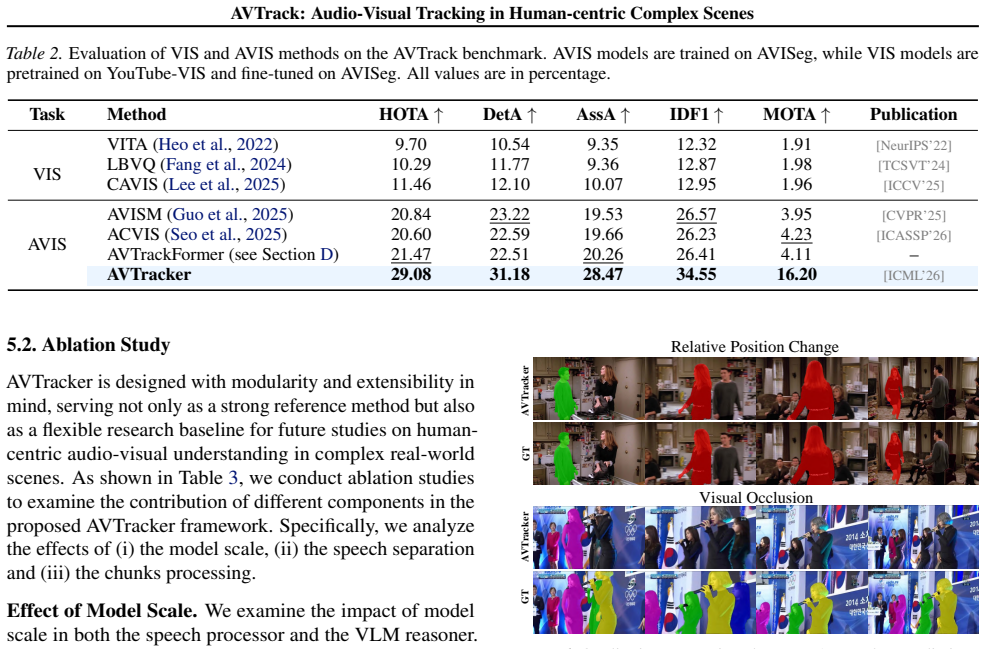
Audio-visual speaker tracking aims to localize and track active speakers by leveraging auditory and visual cues, enabling fine-grained, human-centric scene understanding. This capability is essential for real-world applications such as intelligent video editing, surveillance, and human-computer interaction. However, existing datasets are largely limited to simple or homogeneous audio-visual scenes with coarse annotations. Such oversimplified settings bias evaluation toward static audio-visual co-occurrence, rather than rigorously assessing robust spatiotemporal modeling and cross-modal reasoning in complex, dynamic scenes. To address these limitations, we introduce AVTrack, a human-centric audio-visual instance segmentation (AVIS) dataset designed for dynamic real-world scenarios. AVTrack features diverse and challenging conditions, including camera motion, visual occlusions, and position changes. Evaluations of representative AVIS methods on AVTrack reveal substantial performance degradation, establishing AVTrack as a challenging benchmark for robust human-centric audio-visual scene understanding in complex environments. We further provide a simple yet effective baseline to facilitate future research. Project website: https://FudanCVL.github.io/AVTrack/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AVTrack, a new dataset for human-centric audio-visual instance segmentation (AVIS) in complex dynamic scenes characterized by camera motion, visual occlusions, and position changes. It argues that existing datasets are too simple and bias evaluations toward static co-occurrence, evaluates representative AVIS methods on AVTrack to demonstrate substantial performance degradation, and supplies a simple baseline to support future work.
Significance. If the reported degradation holds under rigorous, artifact-free evaluation and the dataset conditions genuinely isolate real-world complexities, AVTrack would provide a valuable benchmark for advancing robust cross-modal spatiotemporal reasoning in audio-visual tracking. The inclusion of a baseline method is a constructive step for reproducibility and follow-on research.
major comments (2)
- [Abstract] Abstract: The central claim that 'evaluations of representative AVIS methods on AVTrack reveal substantial performance degradation' is load-bearing for positioning AVTrack as a challenging benchmark, yet the abstract supplies no quantitative results, specific methods or metrics, dataset statistics, or evaluation protocol details. This prevents verification that observed drops arise from the stated factors (camera motion, occlusions, position changes) rather than construction artifacts.
- [Dataset and Evaluation sections] Dataset and Evaluation sections: No information is given on the annotation process, train/test splits, controlled ablations isolating individual complexity factors, or comparisons against simpler subsets. Without these, it is impossible to confirm that the dataset faithfully represents real-world conditions or that performance drops are attributable to the intended challenges.
minor comments (1)
- The project website link is provided, but the manuscript should explicitly state data availability, licensing, and whether annotations follow standard formats for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that additional details are needed to strengthen the manuscript and will revise accordingly to address the concerns about the abstract and dataset/evaluation sections.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'evaluations of representative AVIS methods on AVTrack reveal substantial performance degradation' is load-bearing for positioning AVTrack as a challenging benchmark, yet the abstract supplies no quantitative results, specific methods or metrics, dataset statistics, or evaluation protocol details. This prevents verification that observed drops arise from the stated factors (camera motion, occlusions, position changes) rather than construction artifacts.
Authors: We agree that including quantitative highlights in the abstract would improve verifiability. In the revision, we will update the abstract to incorporate key dataset statistics (e.g., number of sequences and instances), the specific AVIS methods evaluated, main metrics used, and representative performance degradation numbers. This will allow readers to better assess the claims while maintaining the abstract's conciseness. revision: yes
-
Referee: [Dataset and Evaluation sections] Dataset and Evaluation sections: No information is given on the annotation process, train/test splits, controlled ablations isolating individual complexity factors, or comparisons against simpler subsets. Without these, it is impossible to confirm that the dataset faithfully represents real-world conditions or that performance drops are attributable to the intended challenges.
Authors: We acknowledge the absence of these details in the current version. We will expand the Dataset section to describe the annotation process (including tools, annotators, and quality control) and the train/test splits. In the Evaluation section, we will add controlled analyses or ablations isolating factors such as camera motion and occlusions, along with comparisons to simpler subsets where feasible. These additions will help attribute performance drops to the intended complexities. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a dataset contribution paper whose central claims concern the construction of AVTrack and the empirical observation that existing AVIS methods degrade under its conditions (camera motion, occlusions, position changes). No derivation chain, equations, fitted parameters, or predictions appear in the provided text. No self-citation is invoked as a uniqueness theorem or load-bearing premise, and the argument does not reduce any result to its own inputs by construction. The evaluation claim is therefore independent of the dataset design itself and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing datasets are limited to simple or homogeneous scenes with coarse annotations.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Audio-visual instance segmentation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[2]
Proceedings of the AAAI conference on artificial intelligence , volume=
Avsegformer: Audio-visual segmentation with transformer , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[3]
European Conference on Computer Vision , pages=
Audio--visual segmentation , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[4]
International Journal of Computer Vision , volume=
Audio-visual segmentation with semantics , author=. International Journal of Computer Vision , volume=. 2025 , publisher=
2025
-
[5]
European Conference on Computer Vision , pages=
Stepping stones: A progressive training strategy for audio-visual semantic segmentation , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[6]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Segment anything , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[7]
European Conference on Computer Vision , pages=
Ref-avs: Refer and segment objects in audio-visual scenes , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[8]
Wang, Yaoting and Liu, Weisong and Li, Guangyao and Ding, Jian and Hu, Di and Li, Xi , title =. 2024 , isbn =. doi:10.1609/aaai.v38i6.28378 , booktitle =
-
[9]
European Conference on Computer Vision , pages=
Can Textual Semantics Mitigate Sounding Object Segmentation Preference? , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[10]
Hao, Dawei and Mao, Yuxin and He, Bowen and Han, Xiaodong and Dai, Yuchao and Zhong, Yiran , title =. 2024 , isbn =. doi:10.1609/aaai.v38i3.27978 , booktitle =
-
[11]
ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Bi-directional modality fusion network for audio-visual event localization , author=. ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2022 , organization=
2022
-
[12]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Cooperation does matter: Exploring multi-order bilateral relations for audio-visual segmentation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[13]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Video instance segmentation , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[14]
European Conference on Computer Vision , pages=
Video mask transfiner for high-quality video instance segmentation , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[15]
International Journal of Computer Vision , volume=
Occluded video instance segmentation: A benchmark , author=. International Journal of Computer Vision , volume=. 2022 , publisher=
2022
-
[16]
European conference on computer vision , pages=
Stem-seg: Spatio-temporal embeddings for instance segmentation in videos , author=. European conference on computer vision , pages=. 2020 , organization=
2020
-
[17]
European Conference on Computer Vision , pages=
Sipmask: Spatial information preservation for fast image and video instance segmentation , author=. European Conference on Computer Vision , pages=. 2020 , organization=
2020
-
[18]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Sg-net: Spatial granularity network for one-stage video instance segmentation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[19]
proceedings of the IEEE/CVF international conference on computer vision , pages=
Crossover learning for fast online video instance segmentation , author=. proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[20]
Proceedings of the IEEE international conference on computer vision , pages=
Mask r-cnn , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[21]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Sotr: Segmenting objects with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[22]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
End-to-end video instance segmentation with transformers , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[23]
European Conference on Computer Vision , pages=
Seqformer: Sequential transformer for video instance segmentation , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[24]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Masked-attention mask transformer for universal image segmentation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[25]
Advances in Neural Information Processing Systems , volume=
Video instance segmentation using inter-frame communication transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Advances in neural information processing systems , volume=
Vita: Video instance segmentation via object token association , author=. Advances in neural information processing systems , volume=
-
[27]
IEEE Transactions on Image Processing , volume=
Toward achieving robust low-level and high-level scene parsing , author=. IEEE Transactions on Image Processing , volume=. 2018 , publisher=
2018
-
[28]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Learning instance occlusion for panoptic segmentation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[29]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Self-supervised scene de-occlusion , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[30]
International Journal of Computer Vision , volume=
Compositional convolutional neural networks: A robust and interpretable model for object recognition under occlusion , author=. International Journal of Computer Vision , volume=. 2021 , publisher=
2021
-
[31]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
MOSE: A new dataset for video object segmentation in complex scenes , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[32]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Implicit Counterfactual Learning for Audio-Visual Segmentation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[33]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Learning to localize sound source in visual scenes , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[34]
arXiv preprint arXiv:2310.14778 , year=
Audio-visual speaker tracking: Progress, challenges, and future directions , author=. arXiv preprint arXiv:2310.14778 , year=
-
[35]
Proceedings of the AAAI conference on artificial intelligence , year=
Multi-modal perception attention network with self-supervised learning for audio-visual speaker tracking , author=. Proceedings of the AAAI conference on artificial intelligence , year=
-
[36]
ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Multi-Stage Multimodal Distillation for Audio-Visual Speaker Tracking , author=. ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2025 , organization=
2025
-
[37]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
CAVIS: Context-Aware Video Instance Segmentation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[38]
3: An audio-visual corpus for speaker localization and tracking , author=
AV16. 3: An audio-visual corpus for speaker localization and tracking , author=. International Workshop on Machine Learning for Multimodal Interaction , pages=. 2004 , organization=
2004
-
[39]
IEEE Transactions on Multimedia , volume=
Multi-speaker tracking from an audio--visual sensing device , author=. IEEE Transactions on Multimedia , volume=. 2019 , publisher=
2019
-
[40]
IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=
Audio-visual cross-attention network for robotic speaker tracking , author=. IEEE/ACM Transactions on Audio, Speech, and Language Processing , volume=. 2022 , publisher=
2022
-
[41]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Deep multimodal clustering for unsupervised audiovisual learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[42]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Localizing visual sounds the hard way , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[43]
arXiv preprint arXiv:2401.14159 , year=
Grounded sam: Assembling open-world models for diverse visual tasks , author=. arXiv preprint arXiv:2401.14159 , year=
-
[44]
ICASSP 2020-2020 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=
Ava active speaker: An audio-visual dataset for active speaker detection , author=. ICASSP 2020-2020 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=. 2020 , organization=
2020
-
[45]
IEEE Transactions on Circuits and Systems for Video Technology , year=
Learning better video query with sam for video instance segmentation , author=. IEEE Transactions on Circuits and Systems for Video Technology , year=
-
[46]
arXiv preprint arXiv:2509.22740 , year=
Learning What To Hear: Boosting Sound-Source Association For Robust Audiovisual Instance Segmentation , author=. arXiv preprint arXiv:2509.22740 , year=
-
[47]
International journal of computer vision , volume=
Hota: A higher order metric for evaluating multi-object tracking , author=. International journal of computer vision , volume=. 2021 , publisher=
2021
-
[48]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Actor and action video segmentation from a sentence , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[49]
In: 2018 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition Workshops (CVPRW)
Giancola, Silvio and Amine, Mohieddine and Dghaily, Tarek and Ghanem, Bernard , year=. SoccerNet: A Scalable Dataset for Action Spotting in Soccer Videos , url=. doi:10.1109/cvprw.2018.00223 , booktitle=
-
[50]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Soccernet-v2: A dataset and benchmarks for holistic understanding of broadcast soccer videos , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[51]
In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
Cioppa, Anthony and Giancola, Silvio and Deliege, Adrien and Kang, Le and Zhou, Xin and Cheng, Zhiyu and Ghanem, Bernard and Van Droogenbroeck, Marc , year=. SoccerNet-Tracking: Multiple Object Tracking Dataset and Benchmark in Soccer Videos , url=. doi:10.1109/cvprw56347.2022.00393 , booktitle=
-
[52]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Youmvos: an actor-centric multi-shot video object segmentation dataset , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[53]
arXiv preprint arXiv:2504.10174 , year=
LLaVA-ReID: Selective Multi-image Questioner for Interactive Person Re-Identification , author=. arXiv preprint arXiv:2504.10174 , year=
-
[54]
Advances in Neural Information Processing Systems , volume=
Empowering visible-infrared person re-identification with large foundation models , author=. Advances in Neural Information Processing Systems , volume=
-
[55]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Harnessing the power of mllms for transferable text-to-image person reid , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[56]
arXiv preprint arXiv:2401.13201 , year=
MLLMReID: multimodal large language model-based person re-identification , author=. arXiv preprint arXiv:2401.13201 , year=
-
[57]
5-vl technical report , author=
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
-
[58]
International conference on machine learning , pages=
Robust speech recognition via large-scale weak supervision , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[59]
arXiv preprint arXiv:2005.07143 , year=
Ecapa-tdnn: Emphasized channel attention, propagation and aggregation in tdnn based speaker verification , author=. arXiv preprint arXiv:2005.07143 , year=
arXiv 2005
-
[60]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Mossformer2: Combining transformer and rnn-free recurrent network for enhanced time-domain monaural speech separation , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[61]
arXiv preprint arXiv:2511.16719 , year=
Sam 3: Segment anything with concepts , author=. arXiv preprint arXiv:2511.16719 , year=
-
[62]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Transreid: Transformer-based object re-identification , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[63]
2014 22nd international conference on pattern recognition , pages=
Deep metric learning for person re-identification , author=. 2014 22nd international conference on pattern recognition , pages=. 2014 , organization=
2014
-
[64]
Proceedings of the IEEE international conference on computer vision , pages=
Deeply-learned part-aligned representations for person re-identification , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[65]
Computer Vision and Image Understanding , volume=
Person re-identification with part prediction alignment , author=. Computer Vision and Image Understanding , volume=. 2021 , publisher=
2021
-
[66]
A benchmark of facial recognition pipelines and co-usability performances of modules , author=. Bili. 2024 , publisher=
2024
-
[67]
ACM Transactions on Information Systems , volume=
A survey on the memory mechanism of large language model-based agents , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
2025
-
[68]
arXiv preprint arXiv:2502.12110 , year=
A-mem: Agentic memory for llm agents , author=. arXiv preprint arXiv:2502.12110 , year=
-
[69]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[70]
arXiv preprint arXiv:2601.12538 , year=
Agentic Reasoning for Large Language Models , author=. arXiv preprint arXiv:2601.12538 , year=
-
[71]
arXiv preprint arXiv:2308.03188 , year=
Automatically correcting large language models: Surveying the landscape of diverse self-correction strategies , author=. arXiv preprint arXiv:2308.03188 , year=
-
[72]
arXiv preprint arXiv:2305.11738 , year=
Critic: Large language models can self-correct with tool-interactive critiquing , author=. arXiv preprint arXiv:2305.11738 , year=
-
[73]
Li, Hongsheng and Zhu, Guangming and Zhang, Liang and Jiang, Youliang and Dang, Yixuan and Hou, Haoran and Shen, Peiyi and Zhao, Xia and Shah, Syed Afaq Ali and Bennamoun, Mohammed , title =. 2024 , issue_date =. doi:10.1016/j.neucom.2023.127052 , journal =
-
[74]
arXiv preprint arXiv:2501.03230 , year=
Video-of-thought: Step-by-step video reasoning from perception to cognition , author=. arXiv preprint arXiv:2501.03230 , year=
-
[75]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Instance relation graph guided source-free domain adaptive object detection , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[76]
, booktitle=
VS, Vibashan and Oza, Poojan and Patel, Vishal M. , booktitle=. 2023 , doi=
2023
-
[77]
European conference on computer vision , pages=
End-to-end object detection with transformers , author=. European conference on computer vision , pages=. 2020 , organization=
2020
-
[78]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Swin transformer: Hierarchical vision transformer using shifted windows , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.