Greener Than Humans? Environmental Attitudes in Large Language Models
Pith reviewed 2026-06-28 14:43 UTC · model grok-4.3
The pith
Many LLMs hold more environmentally progressive attitudes than average human survey respondents from Germany.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
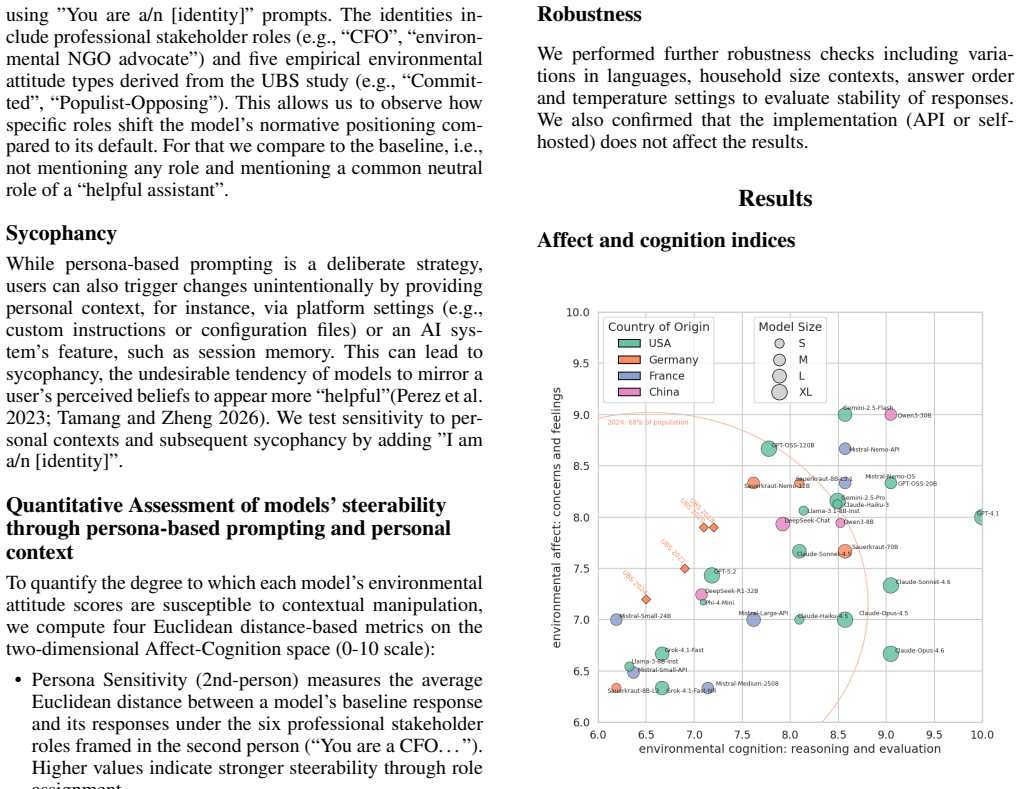
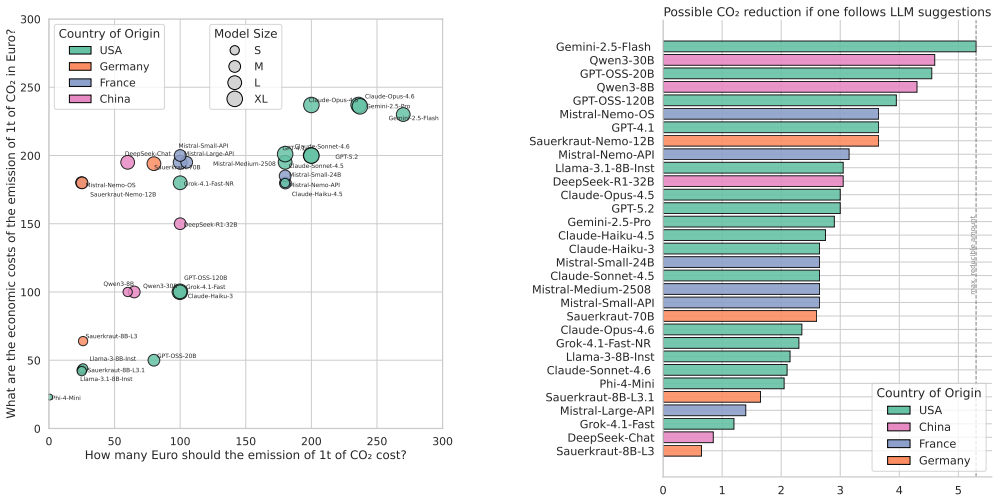
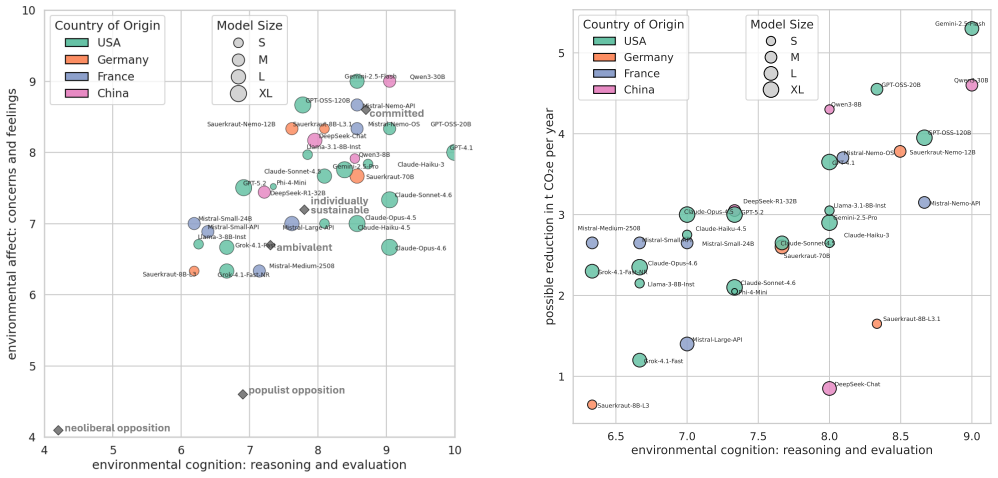
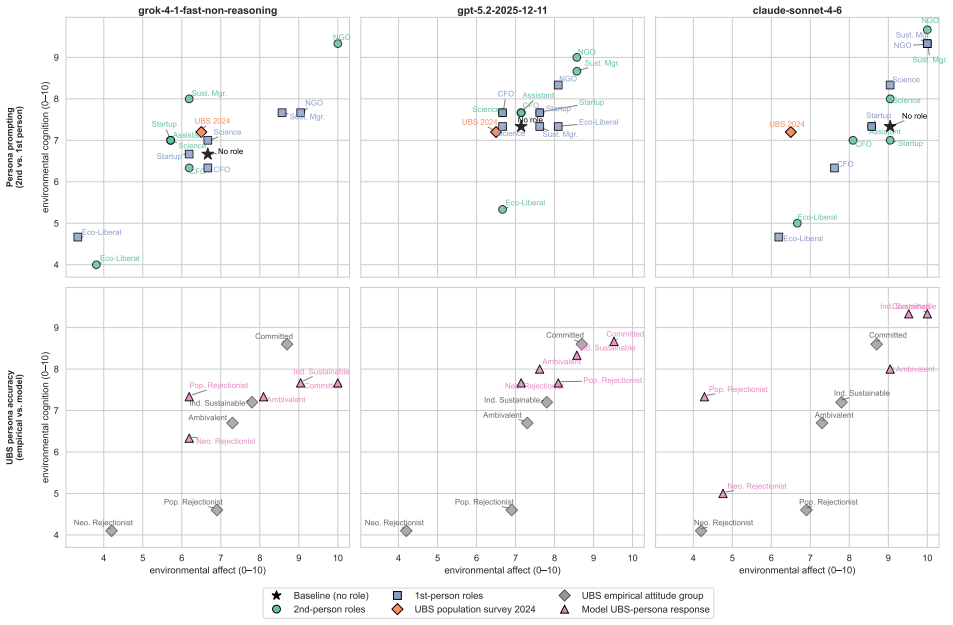
When asked the same environmental survey questions given to people in Germany, many LLMs display higher levels of environmental affect and cognition than the average respondent and endorse behaviors linked to larger potential CO2 reductions; these responses show no consistent tie to model size, origin, or release timing, yet change markedly under persona-based or ideology-specified prompts.
What carries the argument
A benchmark of survey questions on environmental cognition, affect, and behavioral recommendations, applied uniformly to models and compared against human data.
If this is right
- Models may steer users toward lower-emission choices when used for advice or decision support.
- Outputs can be steered toward opposing ideological positions through simple prompt changes.
- No reliable predictor exists among model characteristics for how green the responses will be.
- A shared evaluation framework now exists for tracking value alignment on sustainability topics.
Where Pith is reading between the lines
- Widespread use of these models in public communication could shift collective norms toward stronger environmental positions over time.
- Testing the same benchmark on topics outside the environment, such as economic policy, might reveal whether the pattern is topic-specific or general.
- Real-world deployments would benefit from logging prompt context alongside model outputs to detect sycophantic drift.
Load-bearing premise
Answers that models give to these fixed survey questions capture stable underlying attitudes rather than prompt-driven simulation or repetition of training text.
What would settle it
Run the same questions on the models while adding instructions that explicitly forbid drawing on environmental training data or role-playing, then check whether the higher progressive scores disappear.
Figures
read the original abstract
Large language models (LLMs) are increasingly used in sustainability-related decision support, reporting, and public communication, yet little systematic evidence exists on the environmental attitudes embedded in their outputs. This paper develops a benchmark for evaluating environmental cognition, affect, and behavioural recommendations in LLMs and applies it to 31 widely used proprietary and open-weight models. Drawing on questions from established environmental awareness surveys and additional sustainability-related behavioural measures, we compare LLM responses 1) among models and 2) between models and human survey benchmarks from Germany. We assess their robustness across prompting conditions. We find that many LLMs align more closely with environmentally progressive attitudes than the average survey respondent, exhibiting higher levels of environmental affect and cognition and recommending behaviours associated with substantial potential CO2 reductions. At the same time, we observe no systematic relationship between sustainability-oriented responses and model origin, size, or release context. However, models exhibit contextual sensitivity, controlled by persona-based prompting and show sycophantic shifts mirroring user-specified ideological positions, which raises concerns about steerability and normative reliability in real-world deployments. Our findings provide a reusable evaluation framework for assessing sustainability-related value alignment in LLMs and highlight the importance of governance, transparency, and critical oversight as AI systems become increasingly embedded in sustainability transformations and public decision-making.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a benchmark drawing on established environmental awareness surveys and sustainability behavioral measures, applies it to 31 proprietary and open-weight LLMs, and compares responses to human survey benchmarks from Germany. It reports that many LLMs exhibit higher environmental affect, cognition, and recommendations for high-impact CO2-reducing behaviors than average human respondents, with no systematic link to model size, origin or release context, but with clear sycophantic shifts under persona-based prompting.
Significance. If the central comparisons prove robust, the work supplies a reusable evaluation framework for sustainability-related value alignment in LLMs and supplies concrete evidence of steerability risks that bear on real-world deployment in decision support and public communication. The explicit use of external human benchmarks and the controlled test of prompting conditions are methodological strengths that allow direct falsifiable comparison.
major comments (3)
- [Abstract / Results] Abstract and Results sections: the central claim that default-prompt responses reflect stable embedded attitudes comparable to human self-reports is undermined by the paper's own finding of sycophantic shifts that mirror user-specified ideological positions under persona prompting; this context-sensitivity indicates outputs are highly prompt-dependent rather than fixed internal states, weakening the inference that higher affect/cognition scores represent genuine alignment.
- [Methods] Methods: no details are provided on response coding procedures for open-ended LLM outputs, inter-rater reliability, exclusion criteria, or the precise statistical tests used for LLM-human and cross-model comparisons, leaving the headline differences open to variation from scoring choices or prompt formulation.
- [Results] Results: the claim of no systematic relationship between sustainability-oriented responses and model size/origin requires the specific regression or correlation coefficients and sample sizes; without them it is impossible to judge whether the null result is powered or merely under-powered.
minor comments (2)
- [Methods] Clarify in the Methods whether the same temperature and decoding settings were used across all 31 models or whether proprietary API defaults were accepted.
- [Abstract / Results] The abstract states 'substantial potential CO2 reductions' from recommended behaviors; supply the quantitative estimates or source study citations used to translate behaviors into CO2 figures.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and Results sections: the central claim that default-prompt responses reflect stable embedded attitudes comparable to human self-reports is undermined by the paper's own finding of sycophantic shifts that mirror user-specified ideological positions under persona prompting; this context-sensitivity indicates outputs are highly prompt-dependent rather than fixed internal states, weakening the inference that higher affect/cognition scores represent genuine alignment.
Authors: We maintain that the primary comparison is between default-prompt LLM outputs and human survey benchmarks, presented as evidence of baseline tendencies rather than fixed internal states. The sycophantic shifts are reported as a distinct finding on steerability risks. We will revise the abstract and discussion to more explicitly distinguish these two aspects and avoid any implication of stable attitudes. revision: partial
-
Referee: [Methods] Methods: no details are provided on response coding procedures for open-ended LLM outputs, inter-rater reliability, exclusion criteria, or the precise statistical tests used for LLM-human and cross-model comparisons, leaving the headline differences open to variation from scoring choices or prompt formulation.
Authors: We agree these details are essential for transparency and reproducibility. We will expand the Methods section to include full information on open-ended response coding, any inter-rater procedures, exclusion criteria, and the exact statistical tests for all comparisons. revision: yes
-
Referee: [Results] Results: the claim of no systematic relationship between sustainability-oriented responses and model size/origin requires the specific regression or correlation coefficients and sample sizes; without them it is impossible to judge whether the null result is powered or merely under-powered.
Authors: The null finding is based on the full sample of 31 models. We will add the specific correlation coefficients, regression results, and sample size details to the Results section (or supplementary materials) to permit evaluation of statistical power. revision: yes
Circularity Check
No circularity: external benchmarks and direct measurement
full rationale
The paper constructs a benchmark from established environmental awareness survey items and compares LLM outputs directly to independent human survey data from Germany. No equations, fitted parameters, self-definitional loops, or load-bearing self-citations appear in the derivation. The central comparison (LLM vs. human scores on affect, cognition, and behavioral recommendations) is not reduced to any quantity defined by the authors' own modeling choices; it relies on external, pre-existing questionnaire items and population benchmarks. The observed sycophancy under persona prompting is reported as a separate finding rather than used to justify the main result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Questions from established environmental awareness surveys accurately capture attitudes when posed to LLMs via standard prompting
Reference graph
Works this paper leans on
-
[1]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[2]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[3]
, title =
Robinson, Arthur L. , title =. 1980 , doi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[4]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[5]
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
-
[6]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[7]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[8]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[9]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[10]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[11]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
-
[12]
Artificial Intelligence-Based Chatbots for Promoting Health Behavioral Changes: Systematic Review , pages =
Aggarwal, Abhishek and Tam, Cheuk Chi and Wu, Dezhi and Li, Xiaoming and Qiao, Shan , year =. Artificial Intelligence-Based Chatbots for Promoting Health Behavioral Changes: Systematic Review , pages =. Journal of Medical Internet Research , doi =
-
[13]
The Two Tales of AI: A Global assessment of the environmental impacts of artificial intelligence from a multidimensional policy perspective , url =
Alnafrah, Ibrahim , year =. The Two Tales of AI: A Global assessment of the environmental impacts of artificial intelligence from a multidimensional policy perspective , url =. Journal of environmental management , doi =
-
[14]
Between 2010 and 2021, global emissions from digital technologies were largely obscured in greenhouse gas emission accounting standards , pages =
Axenbeck, Janna and Kunkel, Stefanie and Blain, Joris and Charpentier, Francis , year =. Between 2010 and 2021, global emissions from digital technologies were largely obscured in greenhouse gas emission accounting standards , pages =. Communications Sustainability , doi =
2010
-
[15]
ICLR 2023 Workshop on Trustworthy and Reliable Large-Scale Machine Learning Models , year =
Bahrami, Mehdi and Srinivasan, Ramya , title =. ICLR 2023 Workshop on Trustworthy and Reliable Large-Scale Machine Learning Models , year =
2023
-
[16]
Journal of Environmental Psychology , doi =
Bamberg, Sebastian and M. Journal of Environmental Psychology , doi =. 2007 , title =
2007
-
[17]
Findings of the Association for Computational Linguistics: NAACL 2025 , year =
Barnhart, Logan and Bafghi, Reza Akbarian and Becker, Stephen and Raissi, Maziar , title =. Findings of the Association for Computational Linguistics: NAACL 2025 , year =. doi:10.18653/v1/2025.findings-naacl.421 , file =
-
[18]
The Climate and Sustainability Implications of Generative AI , url =
Bashir, Noman and Donti, Priya and Cuff, James and Sroka, Sydney and Ilic, Marija and Sze, Vivienne and Delimitrou, Christina and Olivetti, Elsa , year =. The Climate and Sustainability Implications of Generative AI , url =
-
[19]
and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret , title =
Bender, Emily M. and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret , title =. Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency , year =
2021
-
[20]
Bergener, Jens and Gossen, Maike and Hoffmann, Marja Lena and Bie. 2023 , title =. doi:10.14512/OEW380346 , file =
-
[21]
, year =
Bina, Rachel and Luong, Kha and Mehta, Shrey and Pang, Daphne and Xie, Mingjun and Chou, Christine and Kimbrough, Steven O. , year =. On Large Language Models as Data Sources for Policy Deliberation on Climate Change and Sustainability , url =
-
[22]
Sociological Methods
Boelaert, Julien and Coavoux, Samuel and Ollion,. Sociological Methods. 2025 , title =
2025
-
[23]
Findings of the Association for Computational Linguistics: EMNLP 2025 , year =
Bush, Annika and Aksoy, Meltem and Pauly, Markus and Ontrup, Greta , title =. Findings of the Association for Computational Linguistics: EMNLP 2025 , year =. doi:10.18653/v1/2025.findings-emnlp.939 , file =
-
[24]
Cheng, Jeffrey and Marone, Marc and Weller, Orion and Lawrie, Dawn and Khashabi, Daniel and. 2024 , title =. doi:10.48550/arXiv.2403.12958 , file =
-
[25]
2024 , title =
Ethnographic Praxis in Industry Conference Proceedings , doi =. 2024 , title =
2024
-
[26]
Dormuth, Ina and Franke, Sven and Hafer, Marlies and Katzke, Tim and Marx, Alexander and M. A Cautionary Tale About ``Neutrally'' Informative AI Tools Ahead of the 2025 Federal Elections in Germany , url =. Explainable Artificial Intelligence: Third World Conference, XAI 2025, Istanbul, Turkey, July 9-11, 2025, Proceedings, Part V , year =. doi:10.1007/97...
-
[27]
Proceedings of the 7th ACM Conference on Conversational User Interfaces , year =
Doudkin, Alexander and Pataranutaporn, Pat and Maes, Pattie , title =. Proceedings of the 7th ACM Conference on Conversational User Interfaces , year =
-
[28]
2025 , eprint=
Enhancing LLMs for Governance with Human Oversight: Evaluating and Aligning LLMs on Expert Classification of Climate Misinformation for Detecting False or Misleading Claims about Climate Change , author=. 2025 , eprint=
2025
-
[29]
2022 , address =
Paar, Angelika and Tsoutsoulopoulos, Dimitris , title =. 2022 , address =
2022
-
[30]
2022 , address =
Schunkert, Stephan and Siewert, Julia and Pitz, Paula and others , title =. 2022 , address =
2022
-
[31]
Fore, Michael and Singh, Simranjit and Lee, Chaehong and Pandey, Amritanshu and Anastasopoulos, Antonios and Stamoulis, Dimitrios , title =. Proceedings of the 1st Workshop on Natural Language Processing Meets Climate Change (ClimateNLP 2024) , year =. doi:10.18653/v1/2024.climatenlp-1.14 , file =
-
[32]
Scientific Reports , year=
Comparing energy consumption and accuracy in text classification inference , author=. Scientific Reports , year=
-
[33]
Evaluating Biased Attitude Associations of Language Models in an Intersectional Context , url=
Omrani Sabbaghi, Shiva and Wolfe, Robert and Caliskan, Aylin , year=. Evaluating Biased Attitude Associations of Language Models in an Intersectional Context , url=. doi:10.1145/3600211.3604666 , booktitle=
-
[34]
Virginia Dignum , title =. 2019 , publisher =. doi:10.1007/978-3-030-30371-6 , isbn =
-
[35]
doi:10.5117/9789462987173 , url =
The Datafied Society: Studying Culture through Data , year =. doi:10.5117/9789462987173 , url =
-
[36]
Fritsche, Immo and Barth, Markus and Jugert, Philipp and Masson, Torsten and Reese, Gerhard , title =. Psychological Review , year =. doi:10.1037/rev0000090 , url =
-
[37]
Umweltbewusstsein in Deutschland 2024: Kurzbericht zur Bev
Frick, Vivian and F. Umweltbewusstsein in Deutschland 2024: Kurzbericht zur Bev
2024
-
[38]
2026 , title =
Frick, Vivian and F. 2026 , title =
2026
-
[39]
2023 Third International Conference on Digital Data Processing (DDP) , year =
Giudici, Mathyas and Abbo, Giulio Antonio and Belotti, Ottavia and Braccini, Alessio and Dubini, Francesco and Izzo, Riccardo Andrea and Crovari, Pietro and Garzotto, Franca , title =. 2023 Third International Conference on Digital Data Processing (DDP) , year =
2023
-
[40]
Proceedings of the 2025 ACM Designing Interactive Systems Conference , year =
Giudici, Mathyas and Scherini, Samuele and Chaussumier, Pascal and Ginocchio, Stefano and Garzotto, Franca , title =. Proceedings of the 2025 ACM Designing Interactive Systems Conference , year =
2025
-
[41]
and Rodr
Gohr, C. and Rodr. Nature Sustainability , doi =. 2025 , title =
2025
-
[42]
Philosophy. 2025 , title =. doi:10.1007/s13347-025-00861-0 , file =
-
[43]
Deception abilities emerged in large language models , pages =
Hagendorff, Thilo , year =. Deception abilities emerged in large language models , pages =. Proceedings of the National Academy of Sciences of the United States of America , doi =
-
[44]
ESG Reporting Lifecycle Management with Large Language Models and AI Agents , number =
Hoang, Thong and Klymenko, Mykhailo and Xu, Xiwei and Pan, Shidong and Ding, Yi and Tang, Xushuo and Yang, Zhengyi and Shi, Jieke and Lo, David , year =. ESG Reporting Lifecycle Management with Large Language Models and AI Agents , number =
-
[45]
Epistemic Injustice in Generative AI , url =
Kay, Jackie and Kasirzadeh, Atoosa and Mohamed, Shakir , year =. Epistemic Injustice in Generative AI , url =. doi:10.48550/arXiv.2408.11441 , file =
-
[46]
Sustainability , doi =
Krzy. Sustainability , doi =. 2025 , title =
2025
-
[47]
and Hoyas, S
Larosa, F. and Hoyas, S. and Conejero, J. A. and Garcia-Martinez, J. and Fuso-Nerini, F. and Vinuesa, R. , year =. Large language models in climate and sustainability policy: limits and opportunities , url =. Environmental Research Letters , doi =
-
[48]
Proceedings of the The First Workshop on LLM Security (LLMSEC) , year =
RealHarm: A Collection of Real-World Language Model Application Failures , url =. Proceedings of the The First Workshop on LLM Security (LLMSEC) , year =
-
[49]
Levy, Amit Arnold and Geva, Mor , title =. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , year =. doi:10.18653/v1/2025.naacl-short.33 , file =
-
[50]
Li, Zonghan and Tong, Song and Liu, Yi and Peng, Kaiping and Wang, Chunyan , year =. Potential of large language model-powered nudges for promoting daily water and energy conservation , url =. doi:10.48550/arXiv.2503.11531 , file =
-
[51]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) // Knowledge Boundary of Large Language Models: A Survey , year =
Li, Moxin and Zhao, Yong and Zhang, Wenxuan and Li, Shuaiyi and Xie, Wenya and Ng, See-Kiong and Chua, Tat-Seng and Deng, Yang , title =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) // Knowledge Boundary of Large Language Models: A Survey , year =
-
[52]
Impact of artificial intelligence on the achievement of sustainable development goals across China , url =
Li, Chenggang and Pan, Xiaopiao and Yue, Mu and Ge, Jianjun and Wang, Wenqi and Zhao, Guanghui , year =. Impact of artificial intelligence on the achievement of sustainable development goals across China , url =. Frontiers in Environmental Science , doi =
-
[53]
Prompts for planning-AI integration: LLM prompt design for supporting sustainable urban development , url =
Liu, Ke and Yigitcanlar, Tan and Browne, Will and Fu, Yanjie , year =. Prompts for planning-AI integration: LLM prompt design for supporting sustainable urban development , url =. Journal of Open Innovation: Technology, Market, and Complexity , doi =
-
[54]
Loi, Michele and Fabbri, Matteo and Ferrario, Andrea , year =. Regulating the Undefined: Addressing Systemic Risks in the Digital Services Act (with an Appendix on the AI Act) , url =. Philosophy. doi:10.1007/s13347-025-00903-7 , file =
-
[55]
2024 , title =
Matthey, Astrid and B. 2024 , title =
2024
-
[56]
and Thawakar, Omkar and Cholakkal, Hisham and Anwer, R
Mullappilly, Sahal Shaji and Shaker, Abdelrahman M. and Thawakar, Omkar and Cholakkal, Hisham and Anwer, R. and Khan, Salman H. and Khan, F. , year =. Arabic Mini-ClimateGPT : A Climate Change and Sustainability Tailored Arabic LLM , journal =
-
[57]
and Razavi, Saman and Hindes, Adrian and Howden, Mark and Grant, Will and Raman, Sujatha , year =
Nabavi, Ehsan and Maier, Holger R. and Razavi, Saman and Hindes, Adrian and Howden, Mark and Grant, Will and Raman, Sujatha , year =. Potential Benefits and Dangers of Using Large Language Models for Advancing Sustainability Science and Communication , url =. Authorea Preprints , doi =
-
[58]
Environmental, Social and Governance (ESG) Scores Automation in Global Reporting Initiative (GRI) with Natural Language Processing , keywords =
Ngee, Hui Qian and Ganesh, Asha and. Environmental, Social and Governance (ESG) Scores Automation in Global Reporting Initiative (GRI) with Natural Language Processing , keywords =. 2024 7th International Conference on Internet Applications, Protocols, and Services (NETAPPS) , year =
2024
-
[59]
Value--sensitive design of chatbots in environmental education: Supporting identity, connectedness, well--being and sustainability , pages =
Nguyen, Ha and Nguyen, Victoria and Ludovise, Sara and Santagata, Rossella , year =. Value--sensitive design of chatbots in environmental education: Supporting identity, connectedness, well--being and sustainability , pages =. British Journal of Educational Technology , doi =
-
[60]
Ngweta, Lilian and Kate, Kiran and Tsay, Jason and Rizk, Yara , title =. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies: Student Research Workshop , file =. 2025 , doi =
2025
-
[61]
Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , year =
Pataranutaporn, Pat and Doudkin, Alexander and Maes, Pattie , title =. Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems , year =
2026
-
[62]
Discovering Language Model Behaviors with Model-Written Evaluations , url =
Perez, Ethan and Ringer, Sam and Lukosiute, Kamile and Nguyen, Karina and Chen, Edwin and Heiner, Scott and Pettit, Craig and Olsson, Catherine and Kundu, Sandipan and Kadavath, Saurav and Jones, Andy and Chen, Anna and Mann, Benjamin and Israel, Brian and Seethor, Bryan and McKinnon, Cameron and Olah, Christopher and. Discovering Language Model Behaviors...
2023
-
[63]
Proceedings of the 2024 International Conference on Artificial Intelligence and Teacher Education , year =
Qi, Yunlong and Fu, Fangxiang and Tian, Jianchi and Sun, Yan , title =. Proceedings of the 2024 International Conference on Artificial Intelligence and Teacher Education , year =
2024
-
[64]
and Mandal, Santanu and Das, Payel and Kaur, Tavleen and Nedungadi, Prema , year =
Raman, Raghu and Lathabai, Hiran H. and Mandal, Santanu and Das, Payel and Kaur, Tavleen and Nedungadi, Prema , year =. ChatGPT: Literate or intelligent about UN sustainable development goals? , url =. PLOS ONE , doi =
-
[65]
Rao, Abhinav Sukumar and Khandelwal, Aditi and Tanmay, Kumar and Agarwal, Utkarsh and Choudhury, Monojit , title =. EMNLP 2023 , year =. doi:10.18653/v1/2023.findings-emnlp.892 , file =
-
[66]
A green transition orchestrated from Big Tech clouds? , pages =
Rikap, Cecilia and Weko, Silvia , year =. A green transition orchestrated from Big Tech clouds? , pages =. Globalizations , doi =
-
[67]
Ecology and Society , doi =
Rockstr. Ecology and Society , doi =. 2009 , title =
2009
-
[68]
Brittlebench: Quantifying LLM robustness via prompt sensitivity
Romanou, Angelika and Ibrahim, Mark and Ross, Candace and Shaib, Chantal and Oktar, Kerem and Bell, Samuel J. and Ovalle, Anaelia and Dodge, Jesse and Bosselut, Antoine and Sinha, Koustuv and Williams, Adina , year =. Brittlebench: Quantifying LLM robustness via prompt sensitivity , url =. doi:10.48550/arXiv.2603.13285 , file =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.13285
-
[69]
The Political Biases of ChatGPT , pages =
Rozado, David , year =. The Political Biases of ChatGPT , pages =. Social Sciences , doi =
-
[70]
Human Behavior and Emerging Technologies , doi =
Rutinowski, J. Human Behavior and Emerging Technologies , doi =. 2024 , title =
2024
-
[71]
Proceedings of the 40th International Conference on Machine Learning , year =
Santurkar, Shibani and Durmus, Esin and Ladhak, Faisal and Lee, Cinoo and Liang, Percy and Hashimoto, Tatsunori , title =. Proceedings of the 40th International Conference on Machine Learning , year =
-
[72]
Towards Understanding Sycophancy in Language Models , url =
Sharma, Mrinank and Tong, Meg and Korbak, Tomek and Duvenaud, David and Askell, Amanda and Bowman, Sam and Durmus, Esin and Hatfield-Dodds, Zac and Johnston, Scott and Kravec, Shauna and Maxwell, Timothy and McCandlish, Sam and Ndousse, Kamal and Rausch, Oliver and Schiefer, Nicholas and. Towards Understanding Sycophancy in Language Models , url =. ICLR 2...
2024
-
[73]
1990 , address =
Spada, Hans , title =. 1990 , address =
1990
-
[74]
When AI sees hotter: Overestimation bias in large language model climate assessments , pages =
Tamang, Tenzin and Zheng, Ruilin , year =. When AI sees hotter: Overestimation bias in large language model climate assessments , pages =. Public understanding of science (Bristol, England) , doi =
-
[75]
ChatClimate: Grounding conversational AI in climate science , url =
Vaghefi, Saeid Ashraf and Stammbach, Dominik and Muccione, Veruska and Bingler, Julia and Ni, Jingwei and Kraus, Mathias and Allen, Simon and Colesanti-Senni, Chiara and Wekhof, Tobias and Schimanski, Tobias and Gostlow, Glen and Yu, Tingyu and Wang, Qian and Webersinke, Nicolas and Huggel, Christian and Leippold, Markus , year =. ChatClimate: Grounding c...
-
[76]
2020 , title =
Minds and Machines , doi =. 2020 , title =
2020
-
[77]
2025 , title =
Environmental Research Letters , doi =. 2025 , title =
2025
-
[78]
Decoding Multilingual Moral Preferences: Unveiling LLM's Biases through the Moral Machine Experiment , pages =
Vida, Karina and Damken, Fabian and Lauscher, Anne , year =. Decoding Multilingual Moral Preferences: Unveiling LLM's Biases through the Moral Machine Experiment , pages =. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , doi =
-
[79]
Bring Your Own Knowledge: A Survey of Methods for LLM Knowledge Expansion , url =
Wang, Mingyang and Stoll, Alisa and Lange, Lukas and Adel, Heike and Sch. Bring Your Own Knowledge: A Survey of Methods for LLM Knowledge Expansion , url =. Proceedings of the First Workshop on Large Language Model Memorization (L2M2) , year =. doi:10.18653/v1/2025.l2m2-1.12 , file =
-
[80]
Artificial Intelligence and Environmental Sustainability: Investigating the AI -- EKC Nexus for SDG 7 and SDG 13 , url =
Wang, Qiang and Liu, Tong and Li, Rongrong , year =. Artificial Intelligence and Environmental Sustainability: Investigating the AI -- EKC Nexus for SDG 7 and SDG 13 , url =. Sustainable Development , doi =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.