Hybrid Adaptive Kalman Filtering for Data-Efficient Joint Tracking and Classification
Pith reviewed 2026-06-28 13:56 UTC · model grok-4.3
The pith
A self-supervised hybrid adaptive Kalman filter learns structured corrections to system dynamics and process noise covariance from measurements alone while preserving probabilistic consistency for joint tracking and model classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Hybrid Adaptive Kalman Filter learns structured corrections to the system dynamics and process noise covariance from measurements alone while preserving the probabilistic structure of the filter. This preservation permits direct computation of the innovation likelihood, which is then employed for model classification through generalized Bayesian inference. The resulting estimator exhibits improved accuracy and maintains statistical consistency on both real-world and simulated datasets across low-data and large-data regimes.
What carries the argument
The self-supervised Hybrid Adaptive Kalman Filter that inserts learned corrections to dynamics and process noise covariance while retaining the original Kalman update equations and their probabilistic interpretation.
If this is right
- Estimation accuracy improves over untuned Kalman filters on both real and simulated data.
- Uncertainty estimates remain statistically consistent after the corrections are applied.
- Model classification becomes possible by treating the innovation likelihood as the observation model in generalized Bayesian inference.
- The same learned corrections support robust performance whether only a small number or a large number of measurements are available.
- Joint tracking and classification can be performed without requiring externally labeled training data.
Where Pith is reading between the lines
- The same self-supervised correction approach could be tested on other recursive estimators such as extended or unscented Kalman filters to check whether the consistency property generalizes.
- Because the method operates from measurements alone, it opens the possibility of continual online adaptation when the underlying system slowly changes.
- Combining the innovation likelihood with additional sensor modalities might strengthen classification in settings with ambiguous dynamics, such as multi-target tracking.
- If the learned corrections remain stable across operating regimes, the filter could serve as a drop-in module for existing navigation or control pipelines without retraining from scratch.
Load-bearing premise
That corrections to dynamics and noise learned from measurements alone will keep the filter's uncertainty estimates statistically consistent and make the innovation likelihood informative enough to distinguish models.
What would settle it
A controlled experiment in which the learned corrections produce innovation likelihoods that assign higher probability to an incorrect model than to the true one, or in which the filter's reported covariance no longer matches the observed squared error distribution.
Figures


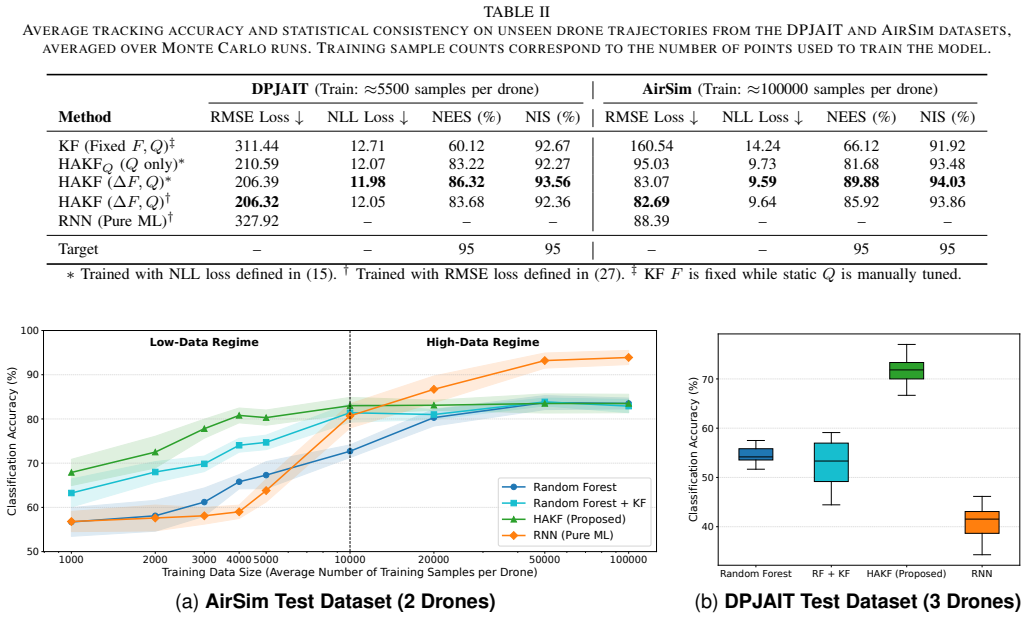
read the original abstract
Kalman filtering performance is highly sensitive to model mismatch and noise covariance tuning. Learning-based approaches address these limitations but typically rely on supervised training with large datasets and do not produce consistent uncertainty estimates. In this paper, we propose a self-supervised Hybrid Adaptive Kalman Filter that learns structured corrections to system dynamics and process noise covariance from measurements alone while preserving the probabilistic structure of the filter. This allows the innovation likelihood to be computed and subsequently used for model classification via generalized Bayesian inference. Experimental results on real-world and simulated datasets demonstrate improved estimation accuracy and statistical consistency as well as robust classification performance across both low-data and large-data scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a self-supervised Hybrid Adaptive Kalman Filter (HAKF) that learns structured corrections to system dynamics and process noise covariance directly from measurements while preserving the filter's probabilistic structure. This enables computation of innovation likelihoods for model classification via generalized Bayesian inference. Experiments on real-world and simulated datasets are reported to show gains in estimation accuracy, statistical consistency, and classification performance across low-data and large-data regimes.
Significance. If the preservation of zero-mean white Gaussian innovations holds, the approach could meaningfully advance data-efficient adaptive filtering for joint tracking and classification tasks in robotics, reducing reliance on large supervised datasets while retaining consistent uncertainty estimates. The self-supervised framing and direct use of innovation likelihoods for classification represent a potentially useful integration of learning and probabilistic filtering.
major comments (1)
- The load-bearing claim that self-supervised corrections preserve zero-mean white Gaussian innovations with correct covariance (required for valid likelihood-based classification) is not guaranteed by a generic prediction-error objective. The manuscript must demonstrate this explicitly, e.g., via innovation autocorrelation tests, whiteness checks, or covariance calibration plots in the experimental section; without such evidence the classification results rest on an unverified assumption.
minor comments (1)
- The abstract contains no equations, algorithm outline, or pseudocode, which hinders immediate assessment of the hybrid architecture and self-supervised loss; adding a high-level block diagram or key update equations in §2 or §3 would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The point about explicit verification of innovation statistics is important for supporting the classification claims, and we address it directly below.
read point-by-point responses
-
Referee: The load-bearing claim that self-supervised corrections preserve zero-mean white Gaussian innovations with correct covariance (required for valid likelihood-based classification) is not guaranteed by a generic prediction-error objective. The manuscript must demonstrate this explicitly, e.g., via innovation autocorrelation tests, whiteness checks, or covariance calibration plots in the experimental section; without such evidence the classification results rest on an unverified assumption.
Authors: We agree that the self-supervised objective does not automatically guarantee the innovation properties without additional structure or verification. Our formulation applies structured corrections (additive dynamics adjustment and positive semi-definite covariance scaling) that are intended to maintain the Kalman filter assumptions, but we acknowledge this must be shown empirically rather than assumed. In the revised manuscript we will add innovation autocorrelation tests, whiteness checks, and covariance calibration plots to the experimental section on both real-world and simulated datasets. These will quantify whether the innovations remain zero-mean and white with calibrated covariance after training. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The abstract presents a self-supervised learning procedure that derives structured corrections to dynamics and noise covariance directly from measurements, then separately uses the resulting innovation likelihood for classification. No equations or definitions are provided that would make the learned corrections equivalent to the classification output by construction, nor is any load-bearing premise justified solely via self-citation. The claimed preservation of probabilistic structure is asserted as an independent property of the method rather than a tautology. This is the most common honest finding for papers whose central contribution is an algorithmic construction whose validity can be checked against external data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
New Results in Linear Filtering and Prediction Theory,
R. E. Kalman and R. S. Bucy, “New Results in Linear Filtering and Prediction Theory,”Journal of Basic Engineering, vol. 83, no. 1, pp. 95–108, Mar. 1961. [Online]. Avail- able: https://asmedigitalcollection.asme.org/fluidsengineering/article/83/ 1/95/426820/New-Results-in-Linear-Filtering-and-Prediction
1961
-
[2]
Estimation with Applications to Tracking and Navigation: Theory, Algorithms and Software,
Y . Bar-Shalom, X. Li, and T. Kirubarajan, “Estimation with Applications to Tracking and Navigation: Theory, Algorithms and Software,”
-
[3]
Available: https://api.semanticscholar.org/CorpusID: 108666793
[Online]. Available: https://api.semanticscholar.org/CorpusID: 108666793
-
[4]
Simon,Optimal State Estimation: Kalman, H Infinity, and Nonlinear Approaches, 1st ed
D. Simon,Optimal State Estimation: Kalman, H Infinity, and Nonlinear Approaches, 1st ed. Wiley, May 2006. [Online]. Available: https://onlinelibrary.wiley.com/doi/book/10.1002/0470045345
-
[5]
The New Trend of State Estimation: From Model-Driven to Hybrid-Driven Methods,
X.-B. Jin, R. J. Robert Jeremiah, T.-L. Su, Y .-T. Bai, and J.-L. Kong, “The New Trend of State Estimation: From Model-Driven to Hybrid-Driven Methods,”Sensors, vol. 21, no. 6, p. 2085, Mar. 2021. [Online]. Available: https://www.mdpi.com/1424-8220/21/6/2085
2085
-
[6]
Approaches to adaptive filtering,
R. Mehra, “Approaches to adaptive filtering,”IEEE Transactions on Automatic Control, vol. 17, no. 5, pp. 693–698, Oct. 1972. [Online]. Available: http://ieeexplore.ieee.org/document/1100100/
-
[7]
L. Zhang, D. Sidoti, A. Bienkowski, K. R. Pattipati, Y . Bar-Shalom, and D. L. Kleinman, “On the Identification of Noise Covariances and Adaptive Kalman Filtering: A New Look at a 50 Year-Old Problem,” IEEE Access, vol. 8, pp. 59 362–59 388, 2020. [Online]. Available: https://ieeexplore.ieee.org/document/9044358/
-
[8]
Generalized Variational Inference: Three arguments for deriving new Posteriors,
J. Knoblauch, J. Jewson, and T. Damoulas, “Generalized Variational Inference: Three arguments for deriving new Posteriors,”arXiv: Machine Learning, 2019. [Online]. Available: https://api.semanticscholar.org/ CorpusID:212761273
2019
-
[9]
Multimodal dataset for indoor 3D drone tracking,
J. Rosner, T. Krzeszowski, A. ´Swito´nski, H. Josi ´nski, W. Lindenheim- Locher, M. Zieli ´nski, G. Paleta, M. Paszkuta, and K. Wojciechowski, “Multimodal dataset for indoor 3D drone tracking,”Scientific Data, vol. 12, no. 1, p. 257, Feb. 2025. [Online]. Available: https://www.nature.com/articles/s41597-025-04521-y
2025
-
[10]
AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles,
S. Shah, D. Dey, C. Lovett, and A. Kapoor, “AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles,” inField and Service Robotics, M. Hutter and R. Siegwart, Eds. Cham: Springer International Publishing, 2018, vol. 5, pp. 621–635, series Title: Springer Proceedings in Advanced Robotics. [Online]. Available: http://link.springer.com/1...
-
[11]
Optimal Estimation in the Presence of Unknown Parameters,
C. Hilborn and D. Lainiotis, “Optimal Estimation in the Presence of Unknown Parameters,”IEEE Transactions on Systems Science and Cybernetics, vol. 5, no. 1, pp. 38–43, 1969. [Online]. Available: http://ieeexplore.ieee.org/document/4082201/
-
[12]
Noise covariance estimation for Kalman filter tuning using Bayesian approach and Monte Carlo,
P. Matisko and V . Havlena, “Noise covariance estimation for Kalman filter tuning using Bayesian approach and Monte Carlo,” International Journal of Adaptive Control and Signal Processing, vol. 27, no. 11, pp. 957–973, Nov. 2013. [Online]. Available: https://onlinelibrary.wiley.com/doi/10.1002/acs.2369
-
[13]
On the identification of variances and adaptive Kalman filtering,
R. Mehra, “On the identification of variances and adaptive Kalman filtering,”IEEE Transactions on Automatic Control, vol. 15, no. 2, pp. 175–184, Apr. 1970. [Online]. Available: http://ieeexplore.ieee.org/ document/1099422/
-
[14]
Maximum Likelihood from Incomplete Data Via theEMAlgorithm,
A. P. Dempster, N. M. Laird, and D. B. Rubin, “Maximum Likelihood from Incomplete Data Via theEMAlgorithm,”Journal of the Royal Statistical Society Series B: Statistical Methodology, vol. 39, no. 1, pp. 1–22, Sep. 1977. [Online]. Available: https: //academic.oup.com/jrsssb/article/39/1/1/7027539
1977
-
[15]
An Approach To Time Series Smoothing And Forecasting Using The Em Algorithm,
R. H. Shumway and D. S. Stoffer, “An Approach To Time Series Smoothing And Forecasting Using The Em Algorithm,” Journal of Time Series Analysis, vol. 3, no. 4, pp. 253–264, Jul
-
[16]
Sanchez-Blazquez,et al., MILES: A Medium Resolution INT Library of Empirical Spectra
[Online]. Available: https://onlinelibrary.wiley.com/doi/10.1111/j. 1467-9892.1982.tb00349.x
work page doi:10.1111/j 1982
-
[17]
Weak in the NEES?: Auto-Tuning Kalman Filters with Bayesian Optimization,
Z. Chen, C. Heckman, S. Julier, and N. Ahmed, “Weak in the NEES?: Auto-Tuning Kalman Filters with Bayesian Optimization,” in 2018 21st International Conference on Information Fusion (FUSION). Cambridge: IEEE, Jul. 2018, pp. 1072–1079. [Online]. Available: https://ieeexplore.ieee.org/document/8454982/
-
[18]
Kalman Filter Auto-Tuning With Consistent and Robust Bayesian Optimization,
Z. Chen, H. Biggie, N. Ahmed, S. Julier, and C. Heckman, “Kalman Filter Auto-Tuning With Consistent and Robust Bayesian Optimization,”IEEE Transactions on Aerospace and Electronic Systems, vol. 60, no. 2, pp. 2236–2250, Apr. 2024. [Online]. Available: https://ieeexplore.ieee.org/document/10382621/
-
[19]
Multi- Sensor Fusion for Underwater Vehicle Localization by Augmentation of RBF Neural Network and Error-State Kalman Filter,
N. Shaukat, A. Ali, M. Javed Iqbal, M. Moinuddin, and P. Otero, “Multi- Sensor Fusion for Underwater Vehicle Localization by Augmentation of RBF Neural Network and Error-State Kalman Filter,”Sensors, vol. 21, no. 4, p. 1149, Feb. 2021. [Online]. Available: https: //www.mdpi.com/1424-8220/21/4/1149
2021
-
[20]
A calibration method for enhancing robot accuracy through integration of an extended Kalman filter algorithm and an artificial neural network,
H.-N. Nguyen, J. Zhou, and H.-J. Kang, “A calibration method for enhancing robot accuracy through integration of an extended Kalman filter algorithm and an artificial neural network,”Neurocomputing, vol. 151, pp. 996–1005, Mar. 2015. [Online]. Available: https: //linkinghub.elsevier.com/retrieve/pii/S0925231214013423
2015
-
[21]
A Disentangled Recognition and Nonlinear Dynamics Model for Unsupervised Learning
M. Fraccaro, S. Kamronn, U. Paquet, and O. Winther, “A Disentangled Recognition and Nonlinear Dynamics Model for Unsupervised Learning,” Oct. 2017, arXiv:1710.05741 [stat]. [Online]. Available: http://arxiv.org/abs/1710.05741
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Deep Variational Bayes Filters: Unsupervised Learning of State Space Models from Raw Data
M. Karl, M. Soelch, J. Bayer, and P. v. d. Smagt, “Deep Variational Bayes Filters: Unsupervised Learning of State Space Models from Raw Data,” Mar. 2017, arXiv:1605.06432 [stat]. [Online]. Available: http://arxiv.org/abs/1605.06432
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
R. G. Krishnan, U. Shalit, and D. Sontag, “Deep Kalman Filters,” Nov. 2015, arXiv:1511.05121 [stat]. [Online]. Available: http://arxiv.org/abs/ 1511.05121
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[24]
KalmanNet: Neural Network Aided Kalman Filtering for Partially Known Dynamics,
G. Revach, N. Shlezinger, X. Ni, A. L. Escoriza, R. J. G. v. Sloun, and Y . C. Eldar, “KalmanNet: Neural Network Aided Kalman Filtering for Partially Known Dynamics,”IEEE Transactions on Signal Processing, vol. 70, pp. 1532–1547, 2022, arXiv:2107.10043 [eess]. [Online]. Available: http://arxiv.org/abs/2107.10043
-
[25]
Bayesian KalmanNet: Quantifying Uncertainty in Deep Learning Augmented Kalman Filter,
Y . Dahan, G. Revach, J. Dunik, and N. Shlezinger, “Bayesian KalmanNet: Quantifying Uncertainty in Deep Learning Augmented Kalman Filter,”IEEE Transactions on Signal Processing, vol. 73, pp. 2558–2573, 2025. [Online]. Available: https://ieeexplore.ieee.org/ document/11048390/
-
[26]
Cholesky-KalmanNet: Model-Based Deep Learning With Positive Definite Error Covariance Structure,
M. Ko and A. Shafieezadeh, “Cholesky-KalmanNet: Model-Based Deep Learning With Positive Definite Error Covariance Structure,” IEEE Signal Processing Letters, vol. 32, pp. 326–330, 2025. [Online]. Available: https://ieeexplore.ieee.org/document/10804573/
-
[27]
H. Mortada, C. Falcon, Y . Kahil, M. Clavaud, and J.-P. Michel, “Recursive KalmanNet: Deep Learning-Augmented Kalman Filtering for State Estimation with Consistent Uncertainty Quantification,” Jun. 2025, arXiv:2506.11639 [eess]. [Online]. Available: http://arxiv.org/abs/ 2506.11639
-
[28]
Properties and first application of an error-statistics tuning method in variational assimilation,
B. Chapnik, G. Desroziers, F. Rabier, and O. Talagrand, “Properties and first application of an error-statistics tuning method in variational assimilation,”Quarterly Journal of the Royal Meteorological Society, vol. 130, no. 601, pp. 2253–2275, Jul. 2004. [Online]. Available: https://rmets.onlinelibrary.wiley.com/doi/10.1256/qj.03.26
-
[29]
P. Tandeo, P. Ailliot, M. Bocquet, A. Carrassi, T. Miyoshi, M. Pulido, and Y . Zhen, “A Review of Innovation-Based Methods to Jointly Estimate Model and Observation Error Covariance Matrices in Ensemble Data Assimilation,”Monthly Weather Review, vol. 148, no. 10, pp. 3973–3994, Oct. 2020, arXiv:1807.11221 [stat]. [Online]. Available: http://arxiv.org/abs/...
-
[30]
Assigning a value to a power likelihood in a general Bayesian model,
C. C. Holmes and S. G. Walker, “Assigning a value to a power likelihood in a general Bayesian model,”Biometrika, vol. 104, no. 2, pp. 497–503, Mar. 2017, _eprint: https://academic.oup.com/biomet/article- pdf/104/2/497/17239738/asx010.pdf. [Online]. Available: https://doi. org/10.1093/biomet/asx010
-
[31]
A comparison of learning rate selection methods in generalized Bayesian inference,
P.-S. Wu and R. Martin, “A comparison of learning rate selection methods in generalized Bayesian inference,”Bayesian Analysis, vol. 18, no. 1, Mar. 2023, arXiv:2012.11349 [stat]. [Online]. Available: http://arxiv.org/abs/2012.11349
-
[32]
R. S. Bucy and P. D. Joseph,Filtering for stochastic processes with applications to guidance, 2nd ed. Providence, R.I: AMS Chelsea Pub, 2005
2005
-
[33]
Unconstrained parametrizations for variance-covariance matrices,
J. C. Pinheiro and D. M. Bates, “Unconstrained parametrizations for variance-covariance matrices,”Statistics and Computing, vol. 6, no. 3, pp. 289–296, Sep. 1996. [Online]. Available: http://link.springer.com/ 10.1007/BF00140873
-
[34]
Optimization or Architecture: How to Hack Kalman Filtering,
I. Greenberg, N. Yannay, and S. Mannor, “Optimization or Architecture: How to Hack Kalman Filtering,” Oct. 2023, arXiv:2310.00675 [cs]. [Online]. Available: http://arxiv.org/abs/2310.00675
-
[35]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A Method for Stochastic Optimization,” Jan. 2017, arXiv:1412.6980 [cs]. [Online]. Available: http://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Goodfellow, Y
I. Goodfellow, Y . Bengio, and A. Courville,Deep learning, ser. Adaptive computation and machine learning. Cambridge, Mass: The MIT press, 2016
2016
-
[37]
Rich Caruana, Alexandru Niculescu-Mizil, Geoff Crew, and Alex Ksikes
L. Breiman, “Random Forests,”Machine Learning, vol. 45, no. 1, pp. 5– 32, Oct. 2001. [Online]. Available: https://link.springer.com/10.1023/A: 1010933404324
work page doi:10.1023/a: 2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.