Do Value Vectors in Deep Layers Need Context from the Residual Stream?
Pith reviewed 2026-06-28 14:33 UTC · model grok-4.3
The pith
Value vectors in deep layers need little context from the residual stream for good benchmark performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
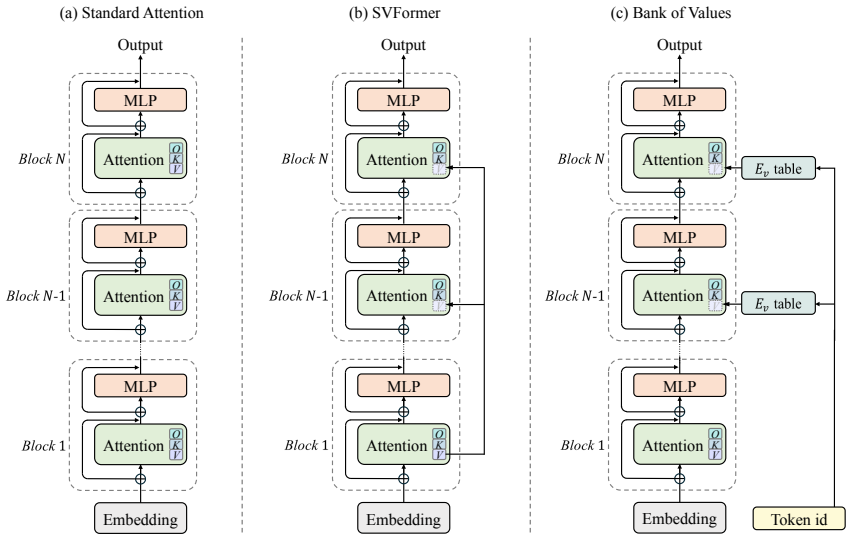
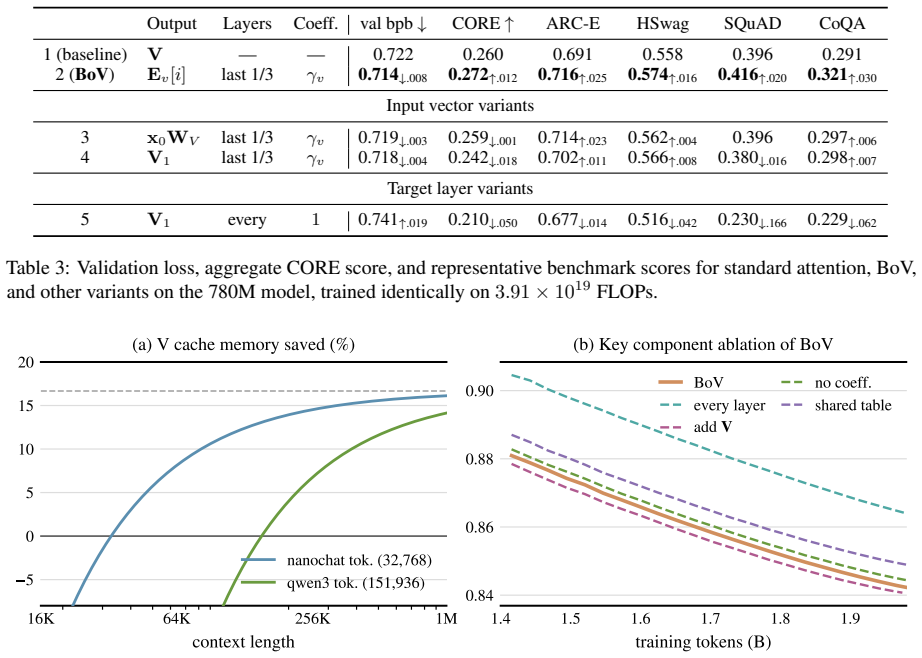
The paper claims that context-free value vectors for the last third of layers preserve sufficient original token information, making the context-dependent component from the residual stream largely redundant for aggregate performance. By replacing standard value computation with a learned lookup table called Bank of Values in those layers, models achieve lower validation loss and competitive benchmark scores with reduced overhead.
What carries the argument
Bank of Values (BoV), a lookup table of token-specific value vectors learned for the last third of layers instead of computing context-dependent ones from the residual stream.
If this is right
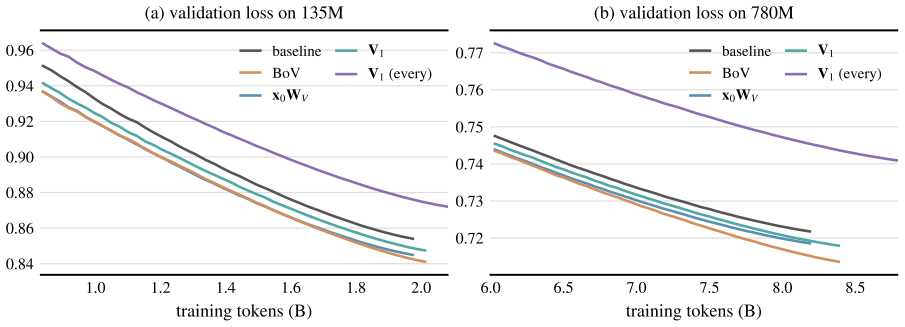
- BoV improves validation loss compared to standard attention in both 135M and 780M parameter models.
- At the 780M scale, BoV achieves the same average score across 21 benchmarks as the prior best method for adding token information to values.
- Context-free value vectors can be stored as sparse parameters, removing the need to recompute or cache them during inference.
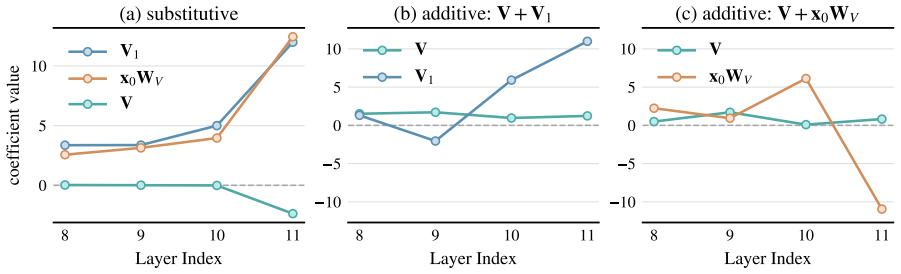
- Systematic ablations confirm the effectiveness of design choices for these context-free vectors.
Where Pith is reading between the lines
- If true, this suggests that deeper layers primarily use value vectors to recall token identities rather than integrate new contextual information.
- Similar lookup tables could be explored for query or key vectors in late layers to further optimize compute.
- Training dynamics might change if value vectors are decoupled from the residual stream, potentially affecting how information flows through the network.
Load-bearing premise
Context-free value vectors learned for the last third of layers preserve sufficient original token information without requiring residual stream context for the tasks evaluated.
What would settle it
Observing a substantial drop in aggregate benchmark performance when using only the context-free value vectors without the context-dependent component in the last third of layers would falsify the central claim.
Figures

read the original abstract
The success of the transformer architecture as the backbone of modern LLMs is in large part due to its use of attention layers. An attention layer follows the standard neural network paradigm: it takes the residual stream as input and thereby produces context-dependent query, key, and value vectors. However, we find that model performance meaningfully improves when deeper layers learn only a context-free value vector to preserve the original token information, without drawing on any context from the residual stream. When the model has access to this context-free value vector, adding back the context-dependent component provides little additional benefit for aggregate benchmark performance. Such context-free value vectors can be stored as sparse model parameters, eliminating the need to recompute or persistently cache these values. Through systematic ablations on the key design choices for such context-free value vectors, we propose Bank of Values (BoV), a new way of computing value vectors in attention by learning a lookup table of token-specific value vectors for each of the last third of layers. Across 135M and 780M models, BoV improves validation loss over standard attention and, at 780M, the average score across 21 benchmarks, matching the previous best method that adds token information to the value vector with less compute and memory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in the last third of transformer layers, value vectors can be replaced by context-free token-specific lookup tables (Bank of Values, BoV) learned as sparse parameters. This yields lower validation loss than standard attention on 135M and 780M models and matches the best prior token-information method on the average of 21 benchmarks while using less compute and memory; adding a context-dependent residual-stream component on top of BoV provides little additional aggregate benefit.
Significance. If the empirical results hold after full verification of methods and controls, the finding would indicate that deep-layer attention can offload token identity to static per-token vectors, reducing the need for residual-stream context in value computation. This could lower KV-cache pressure and suggest architectural simplifications for efficient inference, while providing a concrete ablation-based test of what information deep layers actually require from the residual stream.
major comments (2)
- [Ablations and benchmark results (likely §4–5)] The headline result that context-free BoV suffices and context-dependent addition yields little extra benefit rests on the 21-benchmark aggregate; the manuscript must demonstrate that the evaluation distribution includes tasks stressing context-dependent token roles (polysemy, coreference, long-range dependencies) rather than being dominated by tasks where static token identity is sufficient. Without such disaggregation, the 'little additional benefit' observation risks being an artifact of benchmark choice.
- [Methods and experimental setup (likely §3)] The claim of improvement 'across 135M and 780M models' and 'matching the previous best method' requires explicit reporting of training details, hyperparameter controls, and variance across seeds for both the BoV models and the baselines; the abstract alone does not allow verification that the reported gains are not due to differences in optimization or data.
minor comments (2)
- [§3] Notation for the BoV lookup table and its integration into the attention equation should be introduced with an explicit equation early in the methods section to avoid ambiguity when comparing to standard Q/K/V computation.
- [Figures in §4] Figure captions for ablation plots should state the exact number of runs and error bars (or lack thereof) so readers can assess reliability of the 'little additional benefit' curves.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Ablations and benchmark results (likely §4–5)] The headline result that context-free BoV suffices and context-dependent addition yields little extra benefit rests on the 21-benchmark aggregate; the manuscript must demonstrate that the evaluation distribution includes tasks stressing context-dependent token roles (polysemy, coreference, long-range dependencies) rather than being dominated by tasks where static token identity is sufficient. Without such disaggregation, the 'little additional benefit' observation risks being an artifact of benchmark choice.
Authors: We agree that disaggregation would strengthen the interpretation. In the revised manuscript we will add a categorized breakdown of the 21 benchmarks, separating tasks that require context-dependent processing (coreference, long-range dependencies, polysemy) from those that can be solved largely by static token identity. This will show whether the limited benefit of the context-dependent residual-stream component persists on the context-sensitive subset. revision: yes
-
Referee: [Methods and experimental setup (likely §3)] The claim of improvement 'across 135M and 780M models' and 'matching the previous best method' requires explicit reporting of training details, hyperparameter controls, and variance across seeds for both the BoV models and the baselines; the abstract alone does not allow verification that the reported gains are not due to differences in optimization or data.
Authors: We acknowledge that the current version does not provide sufficient experimental detail for independent verification. We will expand the methods section and add an appendix that reports all training hyperparameters, data mixture, optimization settings, and performance with standard deviations across at least three random seeds for both BoV models and all baselines. revision: yes
Circularity Check
No circularity: empirical ablation of context-free value vectors
full rationale
The paper's central result—that context-free value vectors (via BoV lookup table) in the last third of layers match or exceed standard attention on 21 benchmarks with less compute—is obtained by training 135M/780M models and measuring validation loss plus aggregate scores. No equation or claim reduces a prediction to a fitted input by construction, nor does any load-bearing premise rest on a self-citation chain. The design choice is tested experimentally rather than derived from prior author work invoked as uniqueness. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
2019 , url =
Radford, Alec and Wu, Jeff and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya , journal =. 2019 , url =
2019
-
[3]
and Vinyals, Oriol and Sifre, Laurent , booktitle =
Hoffmann, Jordan and Borgeaud, Sebastian and Mensch, Arthur and Buchatskaya, Elena and Cai, Trevor and Rutherford, Eliza and de Las Casas, Diego and Hendricks, Lisa Anne and Welbl, Johannes and Clark, Aidan and Hennigan, Tom and Noland, Eric and Millican, Katie and van den Driessche, George and Damoc, Bogdan and Guy, Aurelia and Osindero, Simon and Simony...
2022
-
[4]
Karpathy, Andrej , year =
-
[6]
Jordan, Keller and contributors , year =
-
[9]
and Ermon, Stefano and Rudra, Atri and R
Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R. Advances in Neural Information Processing Systems , year =
-
[10]
and Zhang, Hao and Stoica, Ion , booktitle =
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph E. and Zhang, Hao and Stoica, Ion , booktitle =. 2023 , url =
2023
-
[12]
and Kaiser,
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser,. Advances in Neural Information Processing Systems , year =
-
[13]
2019 , url =
Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin , booktitle =. 2019 , url =
2019
-
[14]
2019 , url =
Sakaguchi, Keisuke and Le Bras, Ronan and Bhagavatula, Chandra and Choi, Yejin , journal =. 2019 , url =
2019
-
[16]
2020 , url =
Bisk, Yonatan and Zellers, Rowan and Le Bras, Ronan and Gao, Jianfeng and Choi, Yejin , booktitle =. 2020 , url =
2020
-
[17]
2019 , url =
Talmor, Alon and Herzig, Jonathan and Lourie, Nicholas and Berant, Jonathan , booktitle =. 2019 , url =
2019
-
[18]
2021 , url =
Hendrycks, Dan and Burns, Collin and Basart, Steven and Zou, Andy and Mazeika, Mantas and Song, Dawn and Steinhardt, Jacob , booktitle =. 2021 , url =
2021
-
[19]
Cobbe, Karl and Kosaraju, Vineet and Bavarian, Mohammad and Chen, Mark and Jun, Heewoo and Kaiser, Lukasz and Plappert, Matthias and Tworek, Jerry and Hilton, Jacob and Nakano, Reiichiro and Hesse, Christopher and Schulman, John , year =. 2110.14168 , archivePrefix =
-
[20]
Rein, David and Hou, Betty Li and Stickland, Asa Cooper and Petty, Jackson and Pang, Richard Yuanzhe and Dirani, Julien and Michael, Julian and Bowman, Samuel R. , year =. 2311.12022 , archivePrefix =
-
[23]
Zadouri, Ted and Hoehnerbach, Markus and Shah, Jay and Liu, Timmy and Thakkar, Vijay and Dao, Tri , year =. 2603.05451 , archivePrefix =
-
[24]
Figliolia, Tomas and Alonso, Nicholas and Iyer, Rishi and Anthony, Quentin and Millidge, Beren , year =. 2510.04476 , archivePrefix =
-
[26]
2021 , eprint =
Schlag, Imanol and Irie, Kazuki and Schmidhuber, J. 2021 , eprint =
2021
-
[27]
Yang, Songlin and Kautz, Jan and Hatamizadeh, Ali , year =. 2412.06464 , archivePrefix =
-
[29]
2024 , eprint =
Pagliardini, Matteo and Mohtashami, Amirkeivan and Fleuret, Fran. 2024 , eprint =
2024
-
[30]
2025 , url =
Zhu, Defa and Huang, Hongzhi and Huang, Zihao and Zeng, Yutao and Mao, Yunyao and Wu, Banggu and Min, Qiyang and Zhou, Xun , booktitle =. 2025 , url =
2025
-
[33]
2024 , url =
Liu, Zirui and Yuan, Jiayi and Jin, Hongye and Zhong, Shaochen and Xu, Zhaozhuo and Braverman, Vladimir and Chen, Beidi and Hu, Xia , booktitle =. 2024 , url =
2024
-
[34]
and Shao, Yakun Sophia and Keutzer, Kurt and Gholami, Amir , booktitle =
Hooper, Coleman and Kim, Sehoon and Mohammadzadeh, Hiva and Mahoney, Michael W. and Shao, Yakun Sophia and Keutzer, Kurt and Gholami, Amir , booktitle =. 2024 , url =
2024
-
[35]
Duvvuri, Sai Surya and Ekbote, Chanakya and Bansal, Rachit and Tiwari, Rishabh and Khatri, Devvrit and Brandfonbrener, David and Liang, Paul and Dhillon, Inderjit and Zaheer, Manzil , year =. 2602.21371 , archivePrefix =
- [36]
-
[38]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[39]
2024 , url =
Li, Jeffrey and Fang, Alex and Smyrnis, Georgios and Ivgi, Maor and Jordan, Matt and Gadre, Samir and others , booktitle =. 2024 , url =
2024
-
[40]
, booktitle =
Roemmele, Melissa and Bejan, Cosmin Adrian and Gordon, Andrew S. , booktitle =
-
[41]
2018 , url =
Mihaylov, Todor and Clark, Peter and Khot, Tushar and Sabharwal, Ashish , booktitle =. 2018 , url =
2018
-
[42]
Proceedings of the Annual Meeting of the Association for Computational Linguistics , year =
Paperno, Denis and Kruszewski, Germ. Proceedings of the Annual Meeting of the Association for Computational Linguistics , year =
-
[43]
and Davis, Ernest and Morgenstern, Leora , booktitle =
Levesque, Hector J. and Davis, Ernest and Morgenstern, Leora , booktitle =
-
[45]
2016 , url =
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy , booktitle =. 2016 , url =
2016
-
[46]
, journal =
Reddy, Siva and Chen, Danqi and Manning, Christopher D. , journal =. 2019 , url =
2019
-
[47]
2019 , url =
Clark, Christopher and Lee, Kenton and Chang, Ming-Wei and Kwiatkowski, Tom and Collins, Michael and Toutanova, Kristina , booktitle =. 2019 , url =
2019
-
[49]
Proceedings of EMNLP , year=
Ainslie, Joshua and Lee-Thorp, James and de Jong, Michiel and Zemlyanskiy, Yury and Lebr. Proceedings of EMNLP , year=
-
[50]
2024 , eprint=
You Only Cache Once: Decoder-Decoder Architectures for Language Models , author=. 2024 , eprint=
2024
-
[51]
Layer-Condensed
Wu, Haoyi and Tu, Kewei , booktitle=. Layer-Condensed. 2024 , url=
2024
-
[52]
Proceedings of EMNLP , year=
Training Deeper Neural Machine Translation Models with Transparent Attention , author=. Proceedings of EMNLP , year=
-
[53]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Reducing Transformer Key-Value Cache Size with Cross-Layer Attention , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[54]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Deep Residual Learning for Image Recognition , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[55]
Proceedings of the International Conference on Machine Learning (ICML) , year=
Patchscopes: A Unifying Framework for Inspecting Hidden Representations of Language Models , author=. Proceedings of the International Conference on Machine Learning (ICML) , year=
-
[56]
2019 , eprint=
Augmenting Self-attention with Persistent Memory , author=. 2019 , eprint=
2019
-
[57]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Large Memory Layers with Product Keys , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[59]
2025 , eprint=
Key and Value Weights Are Probably All You Need: On the Necessity of the Query, Key, Value Weight Triplet in Self-Attention Transformers , author=. 2025 , eprint=
2025
-
[61]
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebr \'o n, and Sumit Sanghai. 2023. https://arxiv.org/abs/2305.13245 GQA : Training generalized multi-query transformer models from multi-head checkpoints . In Proceedings of EMNLP
Pith/arXiv arXiv 2023
-
[62]
Ankur Bapna, Mia Xu Chen, Orhan Firat, Yuan Cao, and Yonghui Wu. 2018. https://arxiv.org/abs/1808.07561 Training deeper neural machine translation models with transparent attention . In Proceedings of EMNLP
Pith/arXiv arXiv 2018
-
[63]
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. 2020. https://arxiv.org/abs/1911.11641 PIQA: Reasoning about Physical Commonsense in Natural Language . In Proceedings of the AAAI Conference on Artificial Intelligence
Pith/arXiv arXiv 2020
-
[64]
William Brandon, Mayank Mishra, Aniruddha Nrusimha, Rameswar Panda, and Jonathan Ragan-Kelly. 2024. https://arxiv.org/abs/2405.12981 Reducing transformer key-value cache size with cross-layer attention . In Advances in Neural Information Processing Systems (NeurIPS)
arXiv 2024
-
[65]
Xin Cheng, Wangding Zeng, Damai Dai, Qinyu Chen, Bingxuan Wang, Zhenda Xie, Kezhao Huang, Xingkai Yu, Zhewen Hao, Yukun Li, Han Zhang, Huishuai Zhang, Dongyan Zhao, and Wenfeng Liang. 2026. https://arxiv.org/abs/2601.07372 Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models . Preprint, arXiv:2601.07372
Pith/arXiv arXiv 2026
-
[66]
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. https://arxiv.org/abs/1905.10044 BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions . In Proceedings of NAACL-HLT
Pith/arXiv arXiv 2019
-
[67]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. https://arxiv.org/abs/1803.05457 Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge . Preprint, arXiv:1803.05457
Pith/arXiv arXiv 2018
-
[68]
Tri Dao. 2023. https://arxiv.org/abs/2307.08691 FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning . Preprint, arXiv:2307.08691
Pith/arXiv arXiv 2023
-
[69]
Fu, Stefano Ermon, Atri Rudra, and Christopher R \'e
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher R \'e . 2022. https://arxiv.org/abs/2205.14135 FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness . In Advances in Neural Information Processing Systems
Pith/arXiv arXiv 2022
-
[70]
DeepSeek-AI . 2024. https://arxiv.org/abs/2405.04434 DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model . Preprint, arXiv:2405.04434
Pith/arXiv arXiv 2024
-
[71]
DeepSeek-AI . 2025. https://arxiv.org/abs/2512.02556 DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models . Preprint, arXiv:2512.02556
Pith/arXiv arXiv 2025
-
[72]
Shizhe Diao, Yu Yang, Yonggan Fu, Xin Dong, Dan Su, Markus Kliegl, Zijia Chen, Peter Belcak, Yoshi Suhara, Hongxu Yin, Mostofa Patwary, Yingyan Lin, Jan Kautz, and Pavlo Molchanov. 2025. https://arxiv.org/abs/2504.13161 CLIMB: CLustering-based Iterative Data Mixture Bootstrapping for Language Model Pre-training . Preprint, arXiv:2504.13161
Pith/arXiv arXiv 2025
-
[73]
Ning Ding, Yehui Tang, Haochen Qin, Zhenli Zhou, Chao Xu, Lin Li, Kai Han, Heng Liao, and Yunhe Wang. 2024. https://arxiv.org/abs/2411.12992 MemoryFormer : Minimize transformer computation by removing fully-connected layers . Preprint, arXiv:2411.12992
arXiv 2024
-
[74]
Asma Ghandeharioun, Avi Caciularu, Adam Pearce, Lucas Dixon, and Mor Geva. 2024. https://arxiv.org/abs/2401.06102 Patchscopes: A unifying framework for inspecting hidden representations of language models . In Proceedings of the International Conference on Machine Learning (ICML)
arXiv 2024
-
[75]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. https://arxiv.org/abs/1512.03385 Deep residual learning for image recognition . In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Pith/arXiv arXiv 2016
-
[76]
Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami. 2024. https://arxiv.org/abs/2401.18079 KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization . In Advances in Neural Information Processing Systems
arXiv 2024
-
[77]
Keller Jordan and contributors. 2024. https://github.com/KellerJordan/modded-nanogpt modded-nanogpt . GitHub repository
2024
-
[78]
Marko Karbevski and Antonij Mijoski. 2025. https://arxiv.org/abs/2510.23912 Key and value weights are probably all you need: On the necessity of the query, key, value weight triplet in self-attention transformers . Preprint, arXiv:2510.23912
Pith/arXiv arXiv 2025
-
[79]
Andrej Karpathy. 2025. https://github.com/karpathy/nanochat nanochat: The best ChatGPT that \ 100 can buy . GitHub repository
2025
-
[80]
Kimi Team , Guangyu Chen, Yu Zhang, Jianlin Su, Weixin Xu, Siyuan Pan, Yaoyu Wang, Yucheng Wang, Guanduo Chen, Bohong Yin, and 1 others. 2026. https://arxiv.org/abs/2603.15031 Attention Residuals . Preprint, arXiv:2603.15031
Pith/arXiv arXiv 2026
-
[81]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. https://arxiv.org/abs/2309.06180 Efficient Memory Management for Large Language Model Serving with PagedAttention . In Proceedings of the ACM Symposium on Operating Systems Principles
Pith/arXiv arXiv 2023
-
[82]
Guillaume Lample, Alexandre Sablayrolles, Marc'Aurelio Ranzato, Ludovic Denoyer, and Herv \'e J \'e gou. 2019. https://arxiv.org/abs/1907.05242 Large memory layers with product keys . In Advances in Neural Information Processing Systems (NeurIPS)
arXiv 2019
-
[83]
Levesque, Ernest Davis, and Leora Morgenstern
Hector J. Levesque, Ernest Davis, and Leora Morgenstern. 2012. The Winograd Schema Challenge . In Proceedings of the International Conference on Principles of Knowledge Representation and Reasoning
2012
-
[84]
Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, and 1 others. 2024. https://arxiv.org/abs/2406.11794 DataComp-LM: In Search of the Next Generation of Training Sets for Language Models . In Advances in Neural Information Processing Systems
Pith/arXiv arXiv 2024
-
[85]
Yangyan Li. 2026. https://arxiv.org/abs/2601.22887 MoVE: Mixture of Value Embeddings -- A New Axis for Scaling Parametric Memory in Autoregressive Models . Preprint, arXiv:2601.22887
arXiv 2026
-
[86]
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. 2024. https://arxiv.org/abs/2402.02750 KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache . In International Conference on Machine Learning
Pith/arXiv arXiv 2024
-
[87]
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. 2018. https://arxiv.org/abs/1809.02789 Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering . In Proceedings of the Conference on Empirical Methods in Natural Language Processing
Pith/arXiv arXiv 2018
-
[88]
Tam Nguyen, Tan M. Nguyen, and Stanley J. Osher. 2023. https://arxiv.org/abs/2312.00751 Mitigating Over-smoothing in Transformers via Regularized Nonlocal Functionals . Preprint, arXiv:2312.00751
arXiv 2023
-
[89]
Matteo Pagliardini, Amirkeivan Mohtashami, Fran c ois Fleuret, and Martin Jaggi. 2024. https://arxiv.org/abs/2402.02622 DenseFormer: Enhancing Information Flow in Transformers via Depth Weighted Averaging . Preprint, arXiv:2402.02622
arXiv 2024
-
[90]
Denis Paperno, Germ \'a n Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fern \'a ndez. 2016. https://arxiv.org/abs/1606.06031 The LAMBADA Dataset: Word Prediction Requiring a Broad Discourse Context . In Proceedings of the Annual Meeting of the Association for Computational Linguistics
Pith/arXiv arXiv 2016
-
[91]
Kaleem Ullah Qasim, Jiashu Zhang, Muhammad Kafeel Shaheen, Razan Alharith, and Heying Zhang. 2026. https://arxiv.org/abs/2603.19664 The residual stream is all you need: On the redundancy of the KV cache in transformer inference . Preprint, arXiv:2603.19664
arXiv 2026
-
[92]
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf Language Models are Unsupervised Multitask Learners . OpenAI Technical Report
2019
-
[93]
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. https://arxiv.org/abs/1606.05250 SQuAD: 100,000+ Questions for Machine Comprehension of Text . In Proceedings of the Conference on Empirical Methods in Natural Language Processing
Pith/arXiv arXiv 2016
-
[94]
Siva Reddy, Danqi Chen, and Christopher D. Manning. 2019. https://arxiv.org/abs/1808.07042 CoQA: A Conversational Question Answering Challenge . Transactions of the Association for Computational Linguistics
Pith/arXiv arXiv 2019
-
[95]
Melissa Roemmele, Cosmin Adrian Bejan, and Andrew S. Gordon. 2011. Choice of Plausible Alternatives: An Evaluation of Commonsense Causal Reasoning . In AAAI Spring Symposium on Logical Formalizations of Commonsense Reasoning
2011
-
[96]
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2019. https://arxiv.org/abs/1907.10641 WinoGrande: An Adversarial Winograd Schema Challenge at Scale . Communications of the ACM
Pith/arXiv arXiv 2019
-
[97]
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. 2024. https://arxiv.org/abs/2407.08608 FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-Precision . Preprint, arXiv:2407.08608
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.