Do Neural Retrievers Prefer Certain Documents? Evidence of Learned Relevance Priors
Pith reviewed 2026-06-28 12:19 UTC · model grok-4.3
The pith
Supervised neural retrievers encode query-independent relevance priors from annotation biases that create a findability gap for less favored documents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Supervised bi-encoder retrievers implicitly learn a document-level relevance prior encoded in their representation space as a side effect of training on annotated data. This prior is estimated by training simple classifiers on frozen document embeddings, generalizes to unseen documents, and proves consistent across models and benchmarks. It creates a findability gap where documents with lower prior are systematically harder to retrieve even when relevant, an effect that persists under matched-document controls. LLM-based explanations show that judged-relevant documents tend to be comprehensive self-contained summaries of mainstream topics while niche or technical content is often left unjudg
What carries the argument
The query-independent relevance prior, isolated by training classifiers on frozen document embeddings from the retriever representation space.
If this is right
- Documents with lower relevance prior are systematically ranked lower even when genuinely relevant.
- The bias appears consistently across multiple state-of-the-art supervised retrievers and IR benchmarks.
- The effect is weaker and less consistent in BM25 than in dense retrievers.
- Annotation selection favors comprehensive mainstream documents over niche or fragmentary ones.
- Retrievers rank documents according to these learned features independently of actual query relevance.
Where Pith is reading between the lines
- Future training pipelines could mitigate the gap by deliberately including more diverse unjudged documents in annotation pools.
- Standard IR evaluation may need separate metrics for document findability to isolate this effect from relevance.
- The same annotation-induced priors could appear in other supervised embedding models outside retrieval.
- Long-tail or technical queries may suffer disproportionately from the findability gap.
Load-bearing premise
Training simple classifiers on frozen document embeddings isolates a query-independent relevance prior caused by annotation selection bias rather than other embedding properties.
What would settle it
A test in which documents matched for relevance but differing in prior score show no systematic difference in retrieval rank across the models would falsify the claim.
Figures
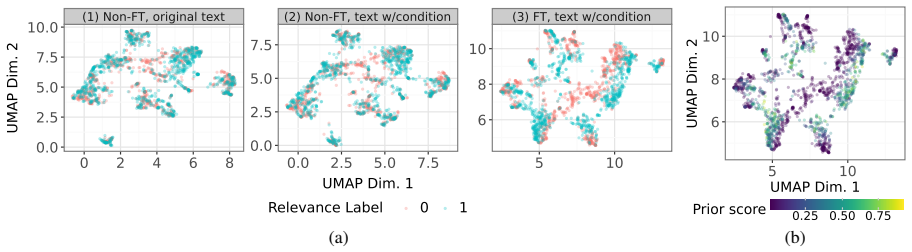


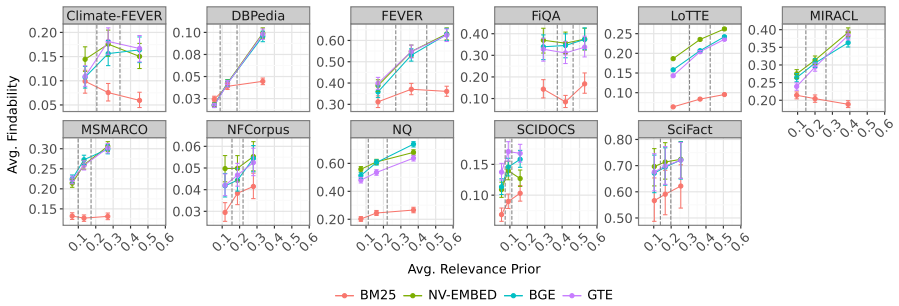

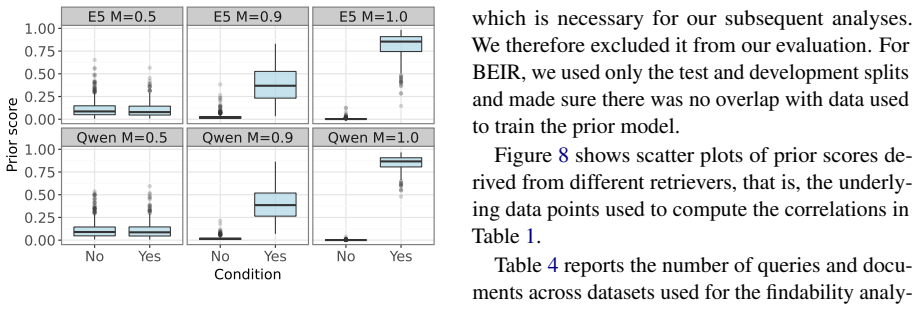
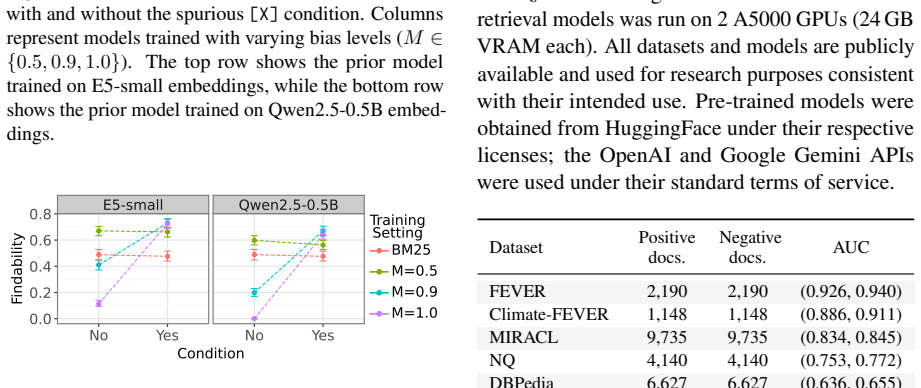
read the original abstract
Neural retrievers are trained to estimate query-document relevance from annotated query-document pairs. Yet annotation protocols may not purely reflect relevance: they select only a subset of documents for labeling, and this selection can favor certain document types over others. We investigate whether supervised bi-encoder retrievers implicitly learn a document-level relevance prior: a query-independent signal encoded in their representation space as a side effect of training on annotated data. We estimate this prior by training simple classifiers on frozen document embeddings and evaluate three state-of-the-art retrievers across multiple IR benchmarks. We find that supervised neural retrievers encode relevance priors that generalize to unseen documents and are consistent across models. These priors create a findability gap: documents with lower prior are systematically harder to retrieve, even when genuinely relevant. This effect appears in supervised dense retrievers but is weaker and less consistent in BM25, and it persists under controlled matched-document comparisons. Using LLM-based explanations, we find that judged-relevant documents tend to be comprehensive, self-contained summaries of mainstream topics, while niche, fragmentary, or highly technical content is often left unjudged. Retrievers internalize this bias, ranking documents with these favored features higher than documents that lack them, independently of their actual relevance. Our findings expose a structural limitation of supervised retrieval: models trained on annotated data do not just learn relevance, but also the implicit document preferences in their training data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that supervised bi-encoder retrievers implicitly learn query-independent relevance priors as a side effect of training on annotated data, where annotation selection favors certain document types. These priors are recovered by training simple classifiers on frozen document embeddings, generalize to unseen documents, are consistent across three state-of-the-art retrievers, and produce a measurable findability gap (documents with lower prior scores are harder to retrieve even when relevant). The effect is weaker and less consistent for BM25, persists under matched-document controls, and is supported by LLM-based qualitative analysis showing preference for comprehensive, mainstream documents over niche or technical ones.
Significance. If the empirical findings hold, the work is significant for information retrieval because it identifies a structural limitation of supervised retrieval: models internalize annotation biases rather than learning pure relevance. This has implications for fairness, robustness, and evaluation practices. Strengths include the multi-retriever, multi-benchmark design, matched-document controls that hold other properties fixed, cross-model consistency checks, and the combination of quantitative retrieval metrics with qualitative LLM explanations. The approach avoids circularity by using frozen embeddings and simple classifiers.
minor comments (3)
- [Methods / Experiments] The abstract and described method indicate use of held-out documents and matched controls, but the manuscript should explicitly report the exact data splits, number of documents per benchmark, and any statistical tests (e.g., significance of the findability gap) to allow full assessment of generalizability.
- [Evaluation] Clarify the precise definition and computation of the 'findability gap' metric (e.g., how retrieval performance is compared for high- vs. low-prior documents under matched conditions) to ensure the quantitative claim is unambiguous.
- [Qualitative Analysis] The LLM-based explanations are presented as supporting evidence; include inter-annotator agreement or validation steps for the qualitative categories (comprehensive vs. niche) to strengthen that component.
Simulated Author's Rebuttal
We thank the referee for their thorough and supportive review, which accurately captures the core claims, methodology, and implications of our work. The recommendation for minor revision is appreciated. Since no specific major comments were raised, we have no point-by-point rebuttals to provide and will incorporate minor clarifications in the revised manuscript where they improve readability.
Circularity Check
No significant circularity identified
full rationale
The paper presents an empirical investigation that estimates a query-independent relevance prior by training simple classifiers on frozen document embeddings from supervised bi-encoders, then measures consistency across models, generalization to held-out documents, and a findability gap under matched-document controls. These steps rely on standard probing accuracy, retrieval metrics (e.g., ranking performance differences), and qualitative LLM explanations rather than any derivation, equation, or self-citation that reduces a claimed result to a fitted parameter defined from the target quantity itself. The central findings are falsifiable via external benchmarks and do not invoke uniqueness theorems or ansatzes from prior author work as load-bearing premises.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In Proceedings of the fourth ACM international confer- ence on Web search and data mining, WSDM ’11, pages 95–104, New York, NY , USA
Quality-biased ranking of web documents. In Proceedings of the fourth ACM international confer- ence on Web search and data mining, WSDM ’11, pages 95–104, New York, NY , USA. Association for Computing Machinery. Adam Berger and John Lafferty. 1999. Information re- trieval as statistical translation. InProceedings of the 22nd annual international ACM SIGI...
1999
-
[2]
Climate-fever: A Dataset for Verification of Real-World Climate Claims. NeurIPS. Varun Dogra, Sahil Verma, Kavita, Marcin Wo´ zniak, Jana Shafi, and Muhammad Fazal Ijaz. 2024. Short- cut Learning Explanations for Deep Natural Lan- guage Processing: A Survey on Dataset Biases.IEEE Access, 12:26183–26195. Martin Fajcik, Martin Docekal, Karel Ondrej, and Pav...
-
[3]
InProceedings of the 25th International Conference on World Wide Web, WWW ’16, pages 391–400, Republic and Canton of Geneva, CHE
Learning Global Term Weights for Content- based Recommender Systems. InProceedings of the 25th International Conference on World Wide Web, WWW ’16, pages 391–400, Republic and Canton of Geneva, CHE. International World Wide Web Con- ferences Steering Committee. Suchin Gururangan, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel Bowman, and Noah A. Smith
-
[4]
Annotation Artifacts in Natural Language In- ference Data. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies, Volume 2 (Short Papers), pages 107–112, New Orleans, Louisiana. Association for Computa- tional Linguistics. Claudia Hauff and Leif Azzopardi. 2005. A...
-
[5]
InProceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval, SIGIR ’02, pages 27–34, New York, NY , USA
The Importance of Prior Probabilities for Entry Page Search. InProceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval, SIGIR ’02, pages 27–34, New York, NY , USA. Association for Computing Machinery. Tom Kwiatkowski, Jennimaria Palomaki, Olivia Red- field, Michael Collins, Ankur Parikh, Chris...
2019
-
[6]
Towards General Text Embeddings with Multi-stage Contrastive Learning
Making Text Embedders Few-Shot Learners. 10 InThe Thirteenth International Conference on Learn- ing Representations. Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. 2023. Towards General Text Embeddings with Multi-stage Con- trastive Learning.arXiv preprint. ArXiv:2308.03281 [cs]. Jimmy Lin, Rodrigo Nogueira, and Andrew Y...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Sean MacAvaney, Sergey Feldman, Nazli Goharian, Doug Downey, and Arman Cohan
Tevatron 2.0: Unified document retrieval toolkit across scale, language, and modality.arXiv preprint arXiv:2505.02466. Sean MacAvaney, Sergey Feldman, Nazli Goharian, Doug Downey, and Arman Cohan. 2022. ABNIRML: Analyzing the Behavior of Neural IR Models.Trans- actions of the Association for Computational Linguis- tics, 10:224–239. Edgar Meij and Maarten ...
-
[8]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Findability: A Novel Measure of Information Accessibility. InProceedings of the 32nd ACM Inter- national Conference on Information and Knowledge Management, CIKM ’23, pages 4289–4293, New York, NY , USA. Association for Computing Machin- ery. Nandan Thakur, Nils Reimers, Andreas Rücklé, Ab- hishek Srivastava, and Iryna Gurevych. 2021. BEIR: A Heterogeneou...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
What are the main features of Class X documents?
-
[10]
What are the main features of Class Y documents?
-
[11]
What do they have in common?
-
[12]
Class X” (low-prior or unjudged) and “Class Y
What are the main differences? Keep your answer clear and well-organized. The goal is to help someone distinguish between Class X and Class Y documents based on their characteristics. Table 9: Prompt used for LLM-based explanation gen- eration (M1). Class labels are anonymized as “Class X” (low-prior or unjudged) and “Class Y” (high-prior or relevant) to ...
2000
-
[13]
The following is the filmography of
Main features of Class X documents * Short and Fragmented: They are typically very brief, often consisting of just one or two sentences, a single bullet point, or even just a section heading. * Highly Specific or Trivia-focused: They tend to focus on hyper-specific details, minor trivia, or raw data (e.g., specific census demographics, a single quote from...
-
[14]
* Narrative and Descriptive: They are written in a continuous, narrative style that flows logically from one sentence to the next
Main features of Class Y documents * Longer and Well-Developed: They are generally much longer, consisting of fully fleshed-out, multi-sentence paragraphs. * Narrative and Descriptive: They are written in a continuous, narrative style that flows logically from one sentence to the next. * Comprehensive Context: They provide substantive background informati...
-
[15]
Topic Name. Text goes here
What they have in common * Source and Tone: Both classes are clearly excerpts from an encyclopedia (specifically Wikipedia). They share a neutral, informative, and objective tone. * Formatting: Both classes follow the exact same formatting convention: they begin with the title or subject of the article, followed by a period, and then the text (e.g., *"Top...
-
[16]
Take a look at your syslog configuration,
Main differences * Completeness: Class Y documents are complete, self-contained thoughts that explain a topic, whereas Class X documents are often incomplete fragments, list items, or isolated facts pulled out of a larger text. * Length: Class Y documents are consistently longer and denser in word count compared to the brief, stub-like nature of Class X. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.