Large Byte Model: Teaching Language Models About Compiled Code
Pith reviewed 2026-06-28 13:45 UTC · model grok-4.3
The pith
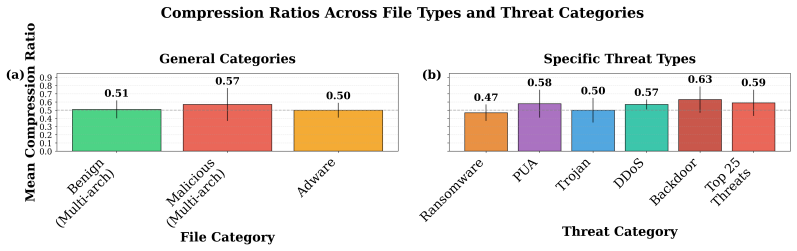
A byte-native LLM processes raw malware binaries directly and classifies their architecture at 98% accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present the first byte-native LLM. Based on a vocabulary expansion technique using a bespoke byte tokenizer, such a model is capable of responding to complex questions about malware binaries, with accuracies ranging from 69% for malware family classification to 98% for architecture classification. Our findings indicate that providing domain knowledge during training is essential for this application -- off-the-shelf models lack both accuracy and insight.
What carries the argument
bespoke byte tokenizer combined with vocabulary expansion that lets an LLM ingest and reason over raw byte sequences from binaries
If this is right
- The adapted model can respond to complex questions about malware binaries that standard models cannot handle.
- Domain knowledge must be supplied during training for both accuracy and insight to appear.
- Off-the-shelf models remain ineffective for direct byte-level binary analysis.
- The resulting system has already been placed with a limited group of analysts to gather usage feedback.
Where Pith is reading between the lines
- The same tokenizer approach could be tested on non-malware binaries such as firmware images or driver modules.
- If the accuracy holds at scale, analysts might begin to treat raw-byte models as a first-pass filter before invoking traditional disassemblers.
- The necessity of domain training suggests that similar adaptations will be required for other low-level code domains such as embedded systems or obfuscated scripts.
Load-bearing premise
The byte tokenizer plus domain-specific training is enough for the model to form useful internal representations directly from raw bytes that support malware analysis tasks.
What would settle it
Showing that a standard LLM without the byte tokenizer or domain-specific training reaches comparable accuracy on the same malware classification tasks would falsify the central claim.
Figures


read the original abstract
Malware analysis starts with the raw bytes of an executable program, and tools to "lift" these to higher-level representations, such as assembly, are expensive and subject to error. Large Language Models (LLMs) cannot process raw byte representations and answer questions about them. To this end, we present the first byte-native LLM. Based on a vocabulary expansion technique using a bespoke byte tokenizer, such a model is capable of responding to complex questions about malware binaries, with accuracies ranging from 69% for malware family classification to 98% for architecture classification. Our findings indicate that providing domain knowledge during training is essential for this application -- off-the-shelf models lack both accuracy and insight. We've deployed this emerging solution to a limited number of analysts to gather feedback for further improvements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to introduce the first byte-native LLM capable of directly processing and answering complex questions about raw bytes of malware binaries. It relies on a vocabulary expansion technique using a bespoke byte tokenizer, reports task accuracies ranging from 69% (malware family classification) to 98% (architecture classification), and concludes that domain-specific training is essential because off-the-shelf models lack both accuracy and insight. A limited deployment to analysts is mentioned for gathering feedback.
Significance. If the results hold under proper controls, the work would be significant for malware analysis and binary code understanding by demonstrating that LLMs can operate directly on raw bytes without error-prone lifting to assembly or other representations. It would also underscore the value of domain knowledge in training for specialized binary tasks.
major comments (2)
- [Abstract] Abstract: the reported accuracies (69% family classification to 98% architecture classification) are presented without any dataset description, baselines, experimental protocol, error bars, or ablation results, rendering it impossible to assess whether the data support the claim that the bespoke byte tokenizer enables meaningful raw-byte representations.
- [Abstract] Abstract: the load-bearing claim that the vocabulary expansion via bespoke byte tokenizer (rather than domain-specific training alone) produces representations sufficient for the reported performance is unsupported, as no control experiments isolating the tokenizer's contribution from standard-tokenizer fine-tuning on the same domain data are described.
minor comments (1)
- The abstract states that the model has been deployed to analysts for feedback but provides no information on the nature of that feedback or resulting improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where the abstract could better support the claims. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported accuracies (69% family classification to 98% architecture classification) are presented without any dataset description, baselines, experimental protocol, error bars, or ablation results, rendering it impossible to assess whether the data support the claim that the bespoke byte tokenizer enables meaningful raw-byte representations.
Authors: The abstract is a high-level summary; the full manuscript provides dataset descriptions (malware binary collections with family and architecture labels), baselines (standard LLMs and classical classifiers), experimental protocol (training and evaluation splits), error bars from repeated runs, and ablation results on tokenizer variants in dedicated sections. We will revise the abstract to include a concise reference to these elements (e.g., dataset scale and cross-validation) so readers can immediately assess the support for the claims. revision: yes
-
Referee: [Abstract] Abstract: the load-bearing claim that the vocabulary expansion via bespoke byte tokenizer (rather than domain-specific training alone) produces representations sufficient for the reported performance is unsupported, as no control experiments isolating the tokenizer's contribution from standard-tokenizer fine-tuning on the same domain data are described.
Authors: The manuscript compares the byte-native model against fine-tuned off-the-shelf models on the same domain data to highlight the tokenizer's role. However, we agree that explicit controls isolating vocabulary expansion from domain fine-tuning alone would strengthen the claim. We will add such ablation experiments in the revision. revision: yes
Circularity Check
No circularity: empirical model presentation with no derivations or self-referential reductions
full rationale
The paper presents an empirical construction of a byte-native LLM via vocabulary expansion and domain-specific training, reporting experimental accuracies on malware tasks. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described content. Claims rest on experimental outcomes rather than any chain that reduces by construction to inputs. The absence of mathematical structure precludes the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Crowdstrike 2025 global threat report
CrowdStrike. Crowdstrike 2025 global threat report. https://www.crowdstrike.com/ explore/2025-global-threat-report-en-gb
2025
-
[2]
Pengfei He, Ash Fox, Lesly Miculicich, Stefan Friedli, Daniel Fabian, Burak Gokturk, Jiliang Tang, Chen-Yu Lee, Tomas Pfister, and Long T. Le. Co-redteam: Orchestrated security discovery and exploitation with llm agents, 2026. URLhttps://arxiv.org/abs/2602.02164
arXiv 2026
-
[3]
Megabyte: Predicting million-byte sequences with multiscale transformers, 2023
Lili Yu, Dániel Simig, Colin Flaherty, Armen Aghajanyan, Luke Zettlemoyer, and Mike Lewis. Megabyte: Predicting million-byte sequences with multiscale transformers, 2023. URL https://arxiv.org/abs/2305.07185
arXiv 2023
-
[4]
Gemini for malware analysis
Bernardo Quintero. Gemini for malware analysis. https://cloud.google.com/blog/ topics/threat-intelligence/gemini-for-malware-analysis
-
[5]
Beyond language models: Byte models are digital world simulators, 2024
Shangda Wu, Xu Tan, Zili Wang, Rui Wang, Xiaobing Li, and Maosong Sun. Beyond language models: Byte models are digital world simulators, 2024. URL https://arxiv.org/abs/2402. 19155
2024
-
[6]
Byte latent transformer: Patches scale better than tokens, 2024
Artidoro Pagnoni, Ram Pasunuru, Pedro Rodriguez, John Nguyen, Benjamin Muller, Margaret Li, Chunting Zhou, Lili Yu, Jason Weston, Luke Zettlemoyer, Gargi Ghosh, Mike Lewis, Ari Holtzman, and Srinivasan Iyer. Byte latent transformer: Patches scale better than tokens, 2024. URLhttps://arxiv.org/abs/2412.09871
arXiv 2024
-
[7]
https://aiindex.stanford.edu/wp-content/uploads/2024/05/HAI_ AI-Index-Report-2024.pdf
Stanford ai index. https://aiindex.stanford.edu/wp-content/uploads/2024/05/HAI_ AI-Index-Report-2024.pdf
2024
-
[8]
Efficient and effective vocabulary expansion towards multilingual large language models, 2024
Seungduk Kim, Seungtaek Choi, and Myeongho Jeong. Efficient and effective vocabulary expansion towards multilingual large language models, 2024. URL https://arxiv.org/abs/ 2402.14714
arXiv 2024
-
[9]
Radare2 github repository.https://github.com/radare/radare2, 2026
Radare2 Team. Radare2 github repository.https://github.com/radare/radare2, 2026
2026
-
[10]
Binary code summarization: Benchmarking chatgpt/gpt-4 and other large language models, 2023
Xin Jin, Jonathan Larson, Weiwei Yang, and Zhiqiang Lin. Binary code summarization: Benchmarking chatgpt/gpt-4 and other large language models, 2023. URL https://arxiv. org/abs/2312.09601
arXiv 2023
-
[11]
Magpie: Alignment data synthesis from scratch by prompting aligned llms with nothing, 2024
Zhangchen Xu, Fengqing Jiang, Luyao Niu, Yuntian Deng, Radha Poovendran, Yejin Choi, and Bill Yuchen Lin. Magpie: Alignment data synthesis from scratch by prompting aligned llms with nothing, 2024. URLhttps://arxiv.org/abs/2406.08464
Pith/arXiv arXiv 2024
-
[12]
https://huggingface.co/datasets/Magpie-Align/ Magpie-Pro-300K-Filtered,
Magpie-pro-300k-filtered. https://huggingface.co/datasets/Magpie-Align/ Magpie-Pro-300K-Filtered,
-
[13]
https://huggingface.co/datasets/ise-uiuc/ Magicoder-Evol-Instruct-110K,
Magicoder-evol-instruct-110k. https://huggingface.co/datasets/ise-uiuc/ Magicoder-Evol-Instruct-110K,
-
[14]
Pytorch fsdp: Experiences on scaling fully sharded data parallel, 2023
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, Alban Desmaison, Can Balioglu, Pritam Damania, Bernard Nguyen, Geeta Chauhan, Yuchen Hao, Ajit Mathews, and Shen Li. Pytorch fsdp: Experiences on scaling fully sharded data parallel, 2023. URL https://arxiv.org/abs/ 2304.11277
Pith/arXiv arXiv 2023
-
[15]
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Shuaiwen Leon Song, Samyam Rajbhandari, and Yuxiong He. Deepspeed ulysses: System optimizations for enabling training of extreme long sequence transformer models.arXiv preprint arXiv:2309.14509, 2023
Pith/arXiv arXiv 2023
-
[16]
FlashAttention-2: Faster attention with better parallelism and work partitioning
Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. In International Conference on Learning Representations (ICLR), 2024. 10
2024
-
[17]
Nvidia/cudnn- frontend
Anerudhan Gopal, Emilien Macchi, Connor Baker, James Y Knight, Jun Zhang, Martin Valgur, Takeshi Watanabe, Tim Moon, Vedaanta Agarwalla, and swimvtec. Nvidia/cudnn- frontend. https://github.com/NVIDIA/cudnn-frontend, dec 20 2025. URL https://github. com/NVIDIA/cudnn-frontend
2025
-
[18]
Cut your losses in large-vocabulary language models, 2025
Erik Wijmans, Brody Huval, Alexander Hertzberg, Vladlen Koltun, and Philipp Krähenbühl. Cut your losses in large-vocabulary language models, 2025. URL https://arxiv.org/abs/ 2411.09009
arXiv 2025
-
[19]
Palmtree: Learning an assembly language model for instruction embedding
Xuezixiang Li, Yu Qu, and Heng Yin. Palmtree: Learning an assembly language model for instruction embedding. InProceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, CCS ’21, page 3236–3251, New York, NY , USA, 2021. Association for Computing Machinery. ISBN 9781450384544. doi: 10.1145/3460120.3484587. URL https://doi.org/1...
-
[20]
https://github.com/mosaicml/llm-foundry/blob/main/ scripts/train/benchmarking/README.md
Databricks mosaic ml. https://github.com/mosaicml/llm-foundry/blob/main/ scripts/train/benchmarking/README.md
-
[21]
Malware Detection by Eating a Whole EXE
Edward Raff, Jon Barker, Jared Sylvester, Robert Brandon, Bryan Catanzaro, and Charles Nicholas. Malware Detection by Eating a Whole EXE. InAAAI Workshop on Artificial Intelligence for Cyber Security, October 2018. URL http://arxiv.org/abs/1710.09435. arXiv: 1710.09435
Pith/arXiv arXiv 2018
-
[22]
Anderson, Bobby Filar, and Mark McLean
Edward Raff, William Fleshman, Richard Zak, Hyrum S. Anderson, Bobby Filar, and Mark McLean. Classifying Sequences of Extreme Length with Constant Memory Applied to Malware Detection. InThe Thirty-Fifth AAAI Conference on Artificial Intelligence, 2021. URL http: //arxiv.org/abs/2012.09390. arXiv: 2012.09390
arXiv 2021
-
[23]
Ethan M Rudd, Mohammad Saidur Rahman, and Philip Tully. Transformers for End-to-End InfoSec Tasks: A Feasibility Study. InProceedings of the 1st Workshop on Robust Malware Analysis, pages 21–31, New York, NY , USA, 2022. Association for Computing Machinery. ISBN 978-1-4503-9179-5. doi: 10.1145/3494110.3528242. URL https://doi.org/10.1145/ 3494110.3528242....
-
[24]
Emotet ",
Information Stealing Capabilities (Password Recovery: Targets multiple browsers, FTP Credentials, Email Clients, Messaging Apps), 2. Keylogging & Surveillance (Implements keyboard hook (kbHook_KeyDown, kbHook_KeyUp ), Captures clipboard data, Takes screenshots (SendScreen_Tick), Webcam capture functionality (Sendwebcam_Tick) ), 3. Persistence Mechanisms (...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.