Forgetting is Not Erasure: Recovering Latent Knowledge via Transport Keys
Pith reviewed 2026-06-28 15:27 UTC · model grok-4.3
The pith
Apparent catastrophic forgetting often reflects interface drift between network stages rather than erasure of earlier computations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
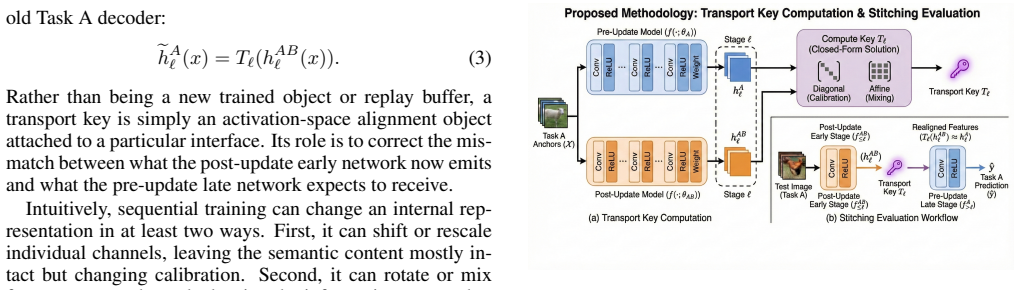
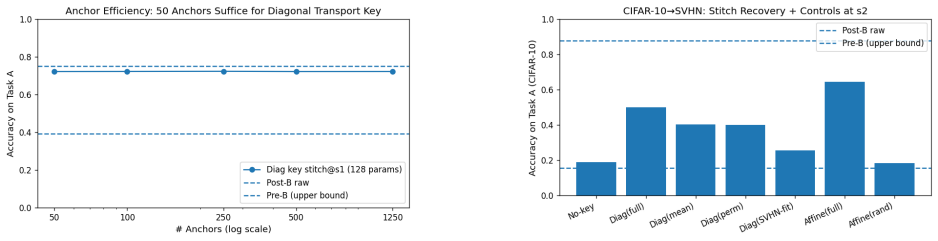
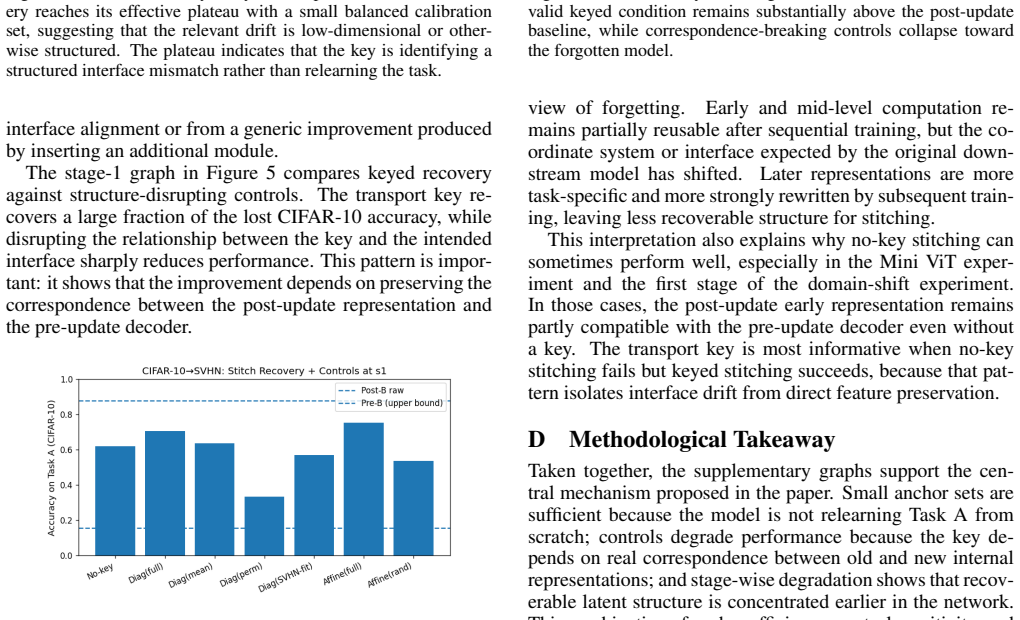
Across controlled continual-learning settings, a significant portion of apparent forgetting can be attributed to interface drift between internal stages rather than permanent erasure of task-relevant computation. Transport keys, described as compact interface-alignment operators estimated from a small set of paired anchor activations, enable recovery of most Task A performance after training on Task B when early computation from the post-update network is combined with late computation from its predecessor via model stitching.
What carries the argument
Transport keys: compact interface-alignment operators estimated from paired anchor activations and applied through model stitching to realign drifted stages.
If this is right
- On split CIFAR-100 with a ResNet-style network, transport keys recover most of the original Task A performance after sequential training on Task B.
- A compact vision transformer exhibits a similar recovery pattern when early and late stages are realigned with transport keys.
- Continual learning may benefit more from mechanisms that index and re-access latent computations than from methods focused only on preventing weight change.
Where Pith is reading between the lines
- If interface drift dominates, continual-learning systems could maintain performance by learning or estimating transport keys on the fly without full retraining.
- The same stitching approach might be tested on language models to check whether apparent forgetting there is likewise mostly an interface issue.
- Varying the selection or number of anchor activations used to estimate each transport key would test how sensitive the recovery is to that choice.
Load-bearing premise
Recovery of performance by stitching with a transport key estimated from anchor activations shows that task-relevant computation remains intact rather than the key or stitching protocol itself creating the recovered capability.
What would settle it
An experiment in which early layers are replaced by random weights yet transport keys still produce the same recovery would falsify the claim that the keys are merely restoring access to preserved latent computation.
Figures


read the original abstract
Catastrophic forgetting is often framed as a representational problem: after sequential training, a model appears to lose the features that supported performance on earlier tasks. We challenge the stronger form of this view. Across controlled continual-learning settings, we find that a significant portion of apparent forgetting can be attributed to interface drift between internal stages rather than permanent erasure of task-relevant computation. We study this phenomenon through a stitched evaluation protocol that combines early computation from a post-update network with late computation from its predecessor, optionally mediated by a compact, task-specific transport key. We describe transport keys at a systems level as compact interface-alignment operators estimated from a small set of paired anchor activations and evaluated through model stitching. On split CIFAR-100 with a ResNet-style network, transport keys recover most of the original Task A performance after sequential training on Task B. On a compact vision transformer, we observe a similar recovery pattern. These results suggest that continual learning may require better mechanisms for indexing and re-accessing latent computations, not only methods that prevent weight change.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that catastrophic forgetting in continual learning is largely attributable to interface drift between internal stages of a network rather than permanent erasure of task-relevant computations. It introduces 'transport keys' as compact, task-specific interface-alignment operators estimated from small sets of paired anchor activations, and uses a model-stitching protocol (early layers from post-update network + late layers from predecessor, optionally with the key) to recover most original Task A performance after sequential training on Task B. Results are reported on split CIFAR-100 using a ResNet-style network and a compact vision transformer.
Significance. If the central claim holds after rigorous controls, the work would meaningfully reframe continual-learning research away from purely representational accounts of forgetting toward interface management and re-access mechanisms. The stitching protocol itself could become a useful diagnostic tool. The manuscript does not yet supply the quantitative controls or baselines needed to establish this reframing.
major comments (3)
- [§3] §3 (transport-key estimation): The key is fitted on paired anchor activations drawn from the same Task A inputs used to evaluate recovery. This setup risks the learned mapping encoding task-conditioned corrections or partial task features rather than performing pure interface alignment; without an ablation that replaces the key with a mapping estimated from shuffled, random, or cross-task activations, it is impossible to separate drift correction from information injection.
- [§4] §4 (experimental results): The abstract states that transport keys 'recover most of the original Task A performance,' yet the provided text supplies no numerical values, error bars, number of anchor examples, or comparisons against trivial baselines (e.g., direct use of the predecessor late stages, identity mapping, or random linear probes). These omissions make it impossible to judge whether the reported recovery exceeds what would be expected from the stitching protocol itself.
- [§4.1] §4.1 (stitching protocol): The claim that recovered performance demonstrates 'intact latent task-relevant computation' in the post-update early stages assumes the transport key supplies no task-specific computation. This assumption is load-bearing for the central thesis but is not tested by any control that isolates the information content of the key (e.g., zero-shot stitching without a learned key or keys trained on unrelated data).
minor comments (2)
- [§3] Notation for the transport key (size, parameterization, optimization objective) should be formalized with an equation in §3 to allow replication.
- [§4] The manuscript should report the exact number of anchor examples used for key estimation and any sensitivity analysis with respect to that hyperparameter.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments correctly identify gaps in controls and reporting that limit the strength of the current evidence. We will revise the manuscript to address each point.
read point-by-point responses
-
Referee: [§3] §3 (transport-key estimation): The key is fitted on paired anchor activations drawn from the same Task A inputs used to evaluate recovery. This setup risks the learned mapping encoding task-conditioned corrections or partial task features rather than performing pure interface alignment; without an ablation that replaces the key with a mapping estimated from shuffled, random, or cross-task activations, it is impossible to separate drift correction from information injection.
Authors: We agree that estimation on Task A activations leaves open the possibility that the key captures task-specific information. In revision we will add the requested ablations: keys estimated from shuffled activations, random pairings, and cross-task activations, and report the resulting stitching performance to isolate the contribution of interface alignment. revision: yes
-
Referee: [§4] §4 (experimental results): The abstract states that transport keys 'recover most of the original Task A performance,' yet the provided text supplies no numerical values, error bars, number of anchor examples, or comparisons against trivial baselines (e.g., direct use of the predecessor late stages, identity mapping, or random linear probes). These omissions make it impossible to judge whether the reported recovery exceeds what would be expected from the stitching protocol itself.
Authors: We will expand §4 with the missing quantitative details: exact recovery percentages and standard deviations across multiple runs, the precise number of anchor examples, and direct comparisons against the listed baselines (predecessor late stages alone, identity mapping, and random linear probes). revision: yes
-
Referee: [§4.1] §4.1 (stitching protocol): The claim that recovered performance demonstrates 'intact latent task-relevant computation' in the post-update early stages assumes the transport key supplies no task-specific computation. This assumption is load-bearing for the central thesis but is not tested by any control that isolates the information content of the key (e.g., zero-shot stitching without a learned key or keys trained on unrelated data).
Authors: We will add the suggested controls: zero-shot stitching (no learned key) and transport keys estimated from unrelated tasks or random data. These experiments will quantify how much performance gain is attributable to the key versus the stitching protocol itself. revision: yes
Circularity Check
No circularity: empirical recovery protocol does not reduce to input by construction
full rationale
The paper presents an empirical protocol using stitched networks and transport keys estimated from anchor activations to demonstrate performance recovery on split CIFAR-100 and vision transformers. No equations, self-citations, or uniqueness theorems are provided in the text that would make the recovery result equivalent to the fitting procedure by definition. The transport key is described as an estimated alignment operator whose effect is measured on task performance; this is a standard fitted-component evaluation rather than a self-definitional or load-bearing self-citation reduction. The central claim remains an interpretation of observed recovery rather than a mathematical identity forced by the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Stitched evaluation with a transport key estimated from anchor activations reveals the presence of task-relevant computation that would otherwise be inaccessible due to interface drift.
invented entities (1)
-
transport key
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Git re-basin: Merging models modulo permutation symmetries
[Ainsworthet al., 2023 ] Samuel K Ainsworth, Jonathan Hayase, and Siddhartha Srinivasa. Git re-basin: Merging models modulo permutation symmetries. InInternational Conference on Learning Representations (ICLR),
2023
-
[2]
Memory aware synapses: Learning what (not) to forget
[Aljundiet al., 2018 ] Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny, Marcus Rohrbach, and Tinne Tuyte- laars. Memory aware synapses: Learning what (not) to forget. InProceedings of the European Conference on Computer Vision (ECCV), pages 139–154,
2018
-
[3]
Revisiting model stitching to compare neural representations
[Bansalet al., 2021 ] Yamini Bansal, Gal Kaplun, Jing Yang, Preetum Raghavan, Shreya Medipally, Doina Precup, and Irina Rish. Revisiting model stitching to compare neural representations. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), volume 34, pages 225–236,
2021
-
[4]
Efficient lifelong learning with a-gem
[Chaudhryet al., 2019 ] Arslan Chaudhry, Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient lifelong learning with a-gem. InInternational Conference on Learning Representations (ICLR),
2019
-
[5]
The role of permutation invariance in linear mode connectivity of neural networks
[Entezariet al., 2022 ] Rahim Entezari, Hanie Sedghi, Olga Saukh, and Neyshabur Behnam. The role of permutation invariance in linear mode connectivity of neural networks. InInternational Conference on Learning Representations (ICLR),
2022
-
[6]
[French, 1999] Robert M. French. Catastrophic forgetting in connectionist networks.Trends in Cognitive Sciences, 3(4):128–135,
1999
-
[7]
Parameter-efficient transfer learning for nlp
[Houlsbyet al., 2019 ] Neil Houlsby, Andrei Giurgiu, Stanis- law Jastrzebski, Bruna Brunslo, Anna Degtyareva, Gal Kaplyn, et al. Parameter-efficient transfer learning for nlp. Proceedings of the 36th International Conference on Ma- chine Learning (ICML),
2019
-
[8]
Overcom- ing catastrophic forgetting in neural networks
[Kirkpatricket al., 2017 ] James Kirkpatrick, Razvan Pas- canu, Neil Rabinowitz, Joel Veness, Guillaume Des- jardins, Andrei A Rusu, Pashapi Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcom- ing catastrophic forgetting in neural networks. InProceed- ings of the National Academy of Sciences (PNAS), volume 114, pages 3521–3526,
2017
-
[9]
Understanding image representations by measuring their equivariance and equivalence
[Lenc and Vedaldi, 2015] Karel Lenc and Andrea Vedaldi. Understanding image representations by measuring their equivariance and equivalence. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 991–999,
2015
-
[10]
Gradient episodic memory for continual learning
[Lopez-Paz and Ranzato, 2017] David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. InAdvances in Neural Information Processing Systems (NeurIPS), volume 30,
2017
-
[11]
Packnet: Adding multiple tasks to a single net- work by iterative pruning
[Mallya and Lazebnik, 2018] Arun Mallya and Svetlana Lazebnik. Packnet: Adding multiple tasks to a single net- work by iterative pruning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 7765–7773,
2018
-
[12]
[McCloskey and Cohen, 1989] Michael McCloskey and Neal J. Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. volume 24 of Psychology of Learning and Motivation, pages 109–165. Academic Press,
1989
-
[13]
icarl: Incremental classifier and representation learning
[Rebuffiet al., 2017 ] Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. InPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2001–2010,
2017
-
[14]
Experience replay for continual learning
[Rolnicket al., 2019 ] David Rolnick, Arun Ahuja, Jonathan Schwarz, Timothy Wayne, David Saxton, Timothy Lilli- crap, and Greg Wayne. Experience replay for continual learning. InAdvances in Neural Information Processing Systems (NeurIPS), volume 32,
2019
-
[15]
[Rusuet al., 2016 ] Andrei A Rusu, Neil C Rabinowitz, Guillaume Desjardins, Soyer Hubert, Kirkpatrick James, Kavukcuoglu Koray, Pascanu Razvan, and Hadsell Raia. Progressive neural networks. InarXiv preprint arXiv:1606.04671,
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[16]
A comprehensive survey of continual learning: Theory, method and application,
[Wanget al., 2024 ] Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application,
2024
-
[17]
Continual learning through synaptic in- telligence
[Zenkeet al., 2017 ] Friedemann Zenke, Ben Poole, and Ganguli Surya. Continual learning through synaptic in- telligence. InProceedings of the 34th International Con- ference on Machine Learning (ICML), pages 3987–3995,
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.