Are we really tilting? The mechanics of reward guidance in flow and diffusion models
Pith reviewed 2026-06-28 15:18 UTC · model grok-4.3
The pith
Reward hacking in diffusion models comes from finite-particle plug-in estimates of the Doob h-function, even for Gaussian targets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
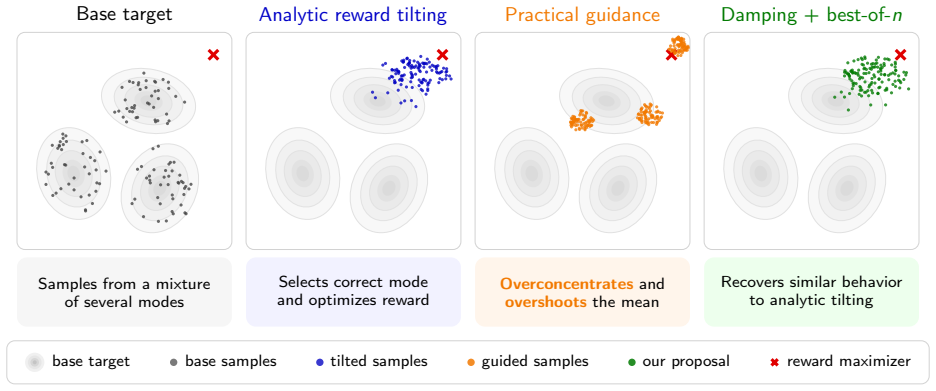
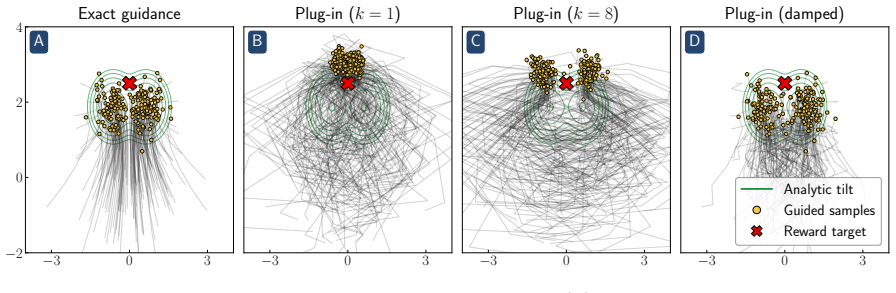
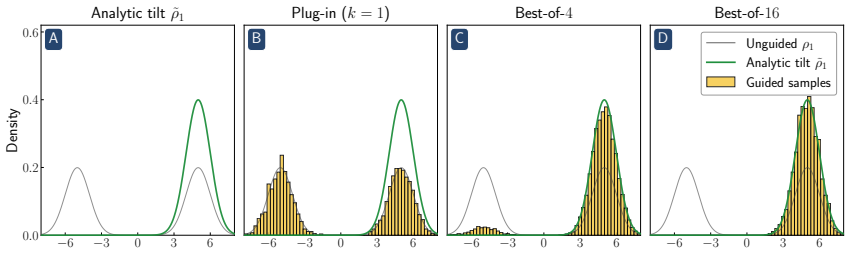
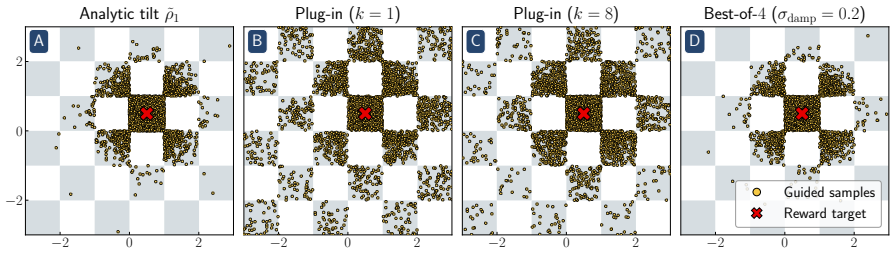
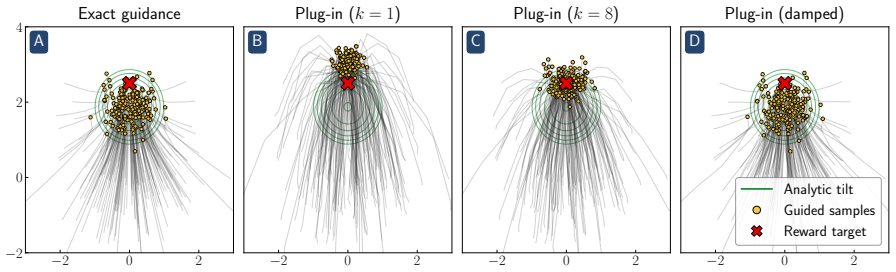
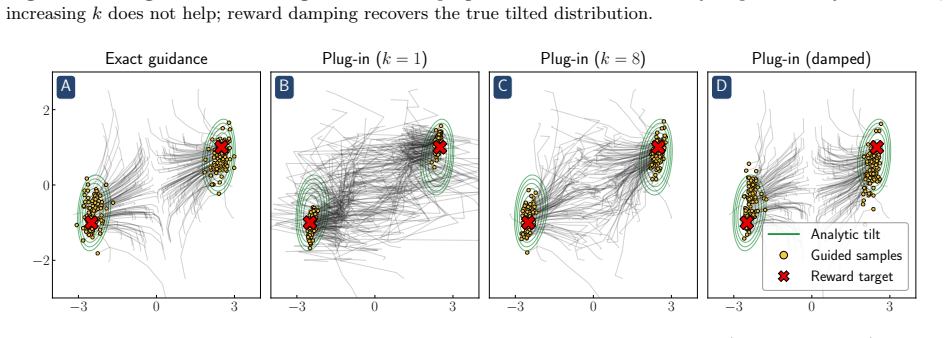
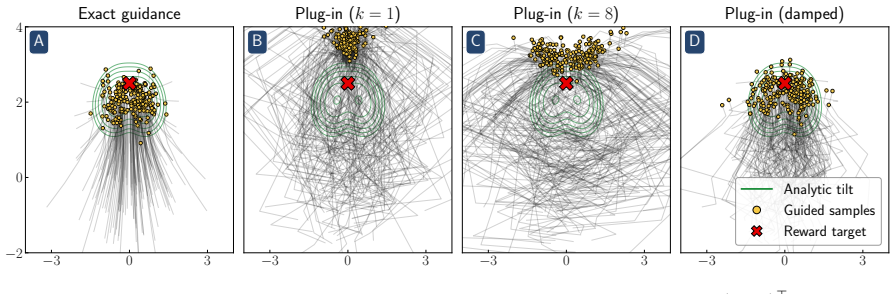
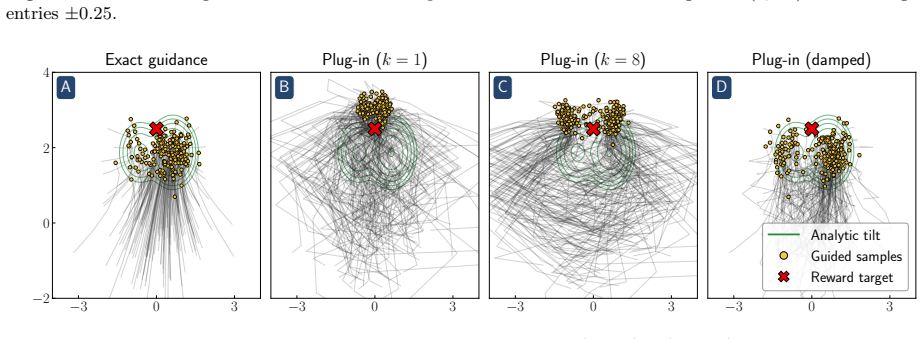
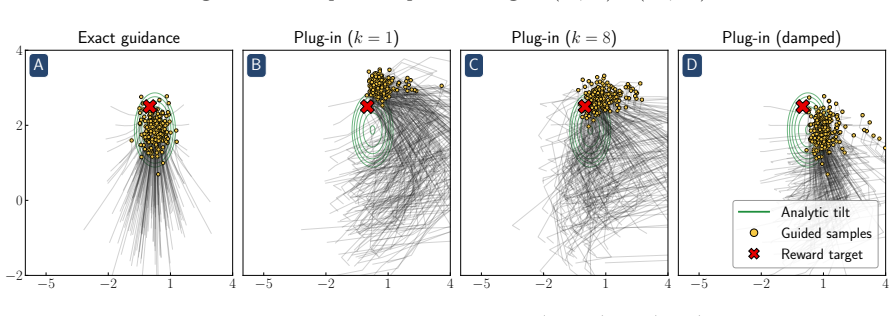
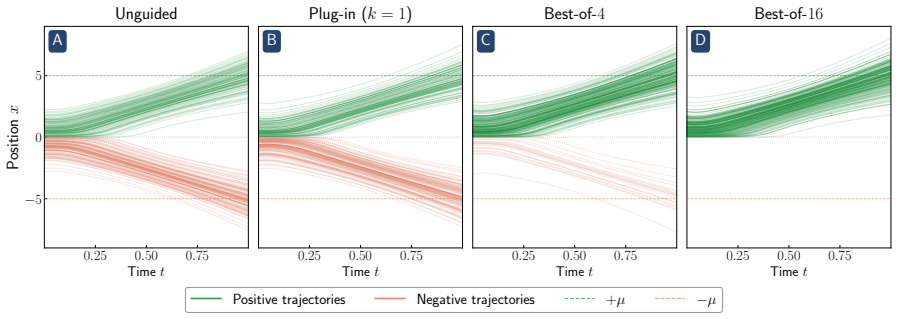
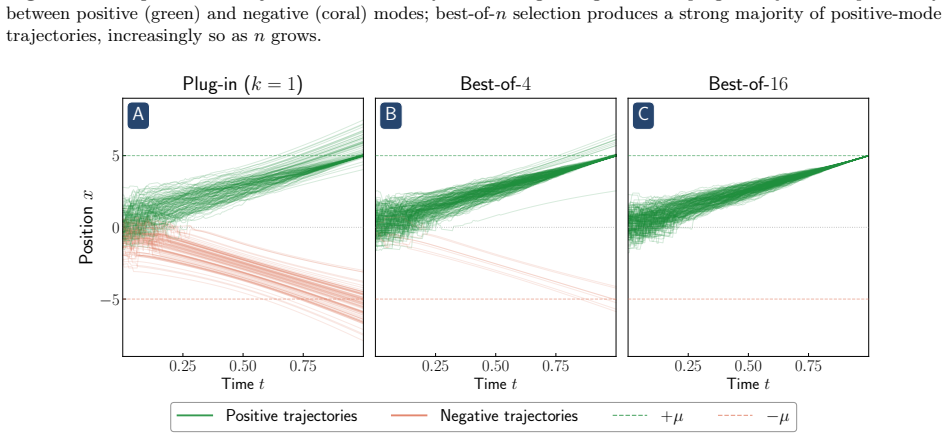
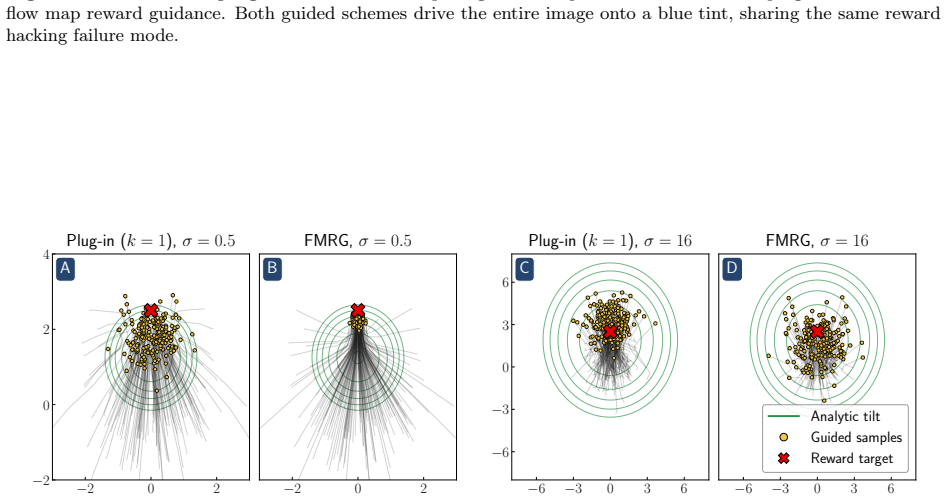
Reward hacking arises from an approximation made in most practical implementations of reward-guided diffusion -- finite-particle plug-in estimation of the Doob h-function -- even in the simplest non-trivial settings of Gaussian and Gaussian mixture targets with quadratic rewards. In closed form, two distinct failure modes of the plug-in estimator are isolated: it leads to reward hacking within each mode and it cannot select high-reward modes.
What carries the argument
Finite-particle plug-in estimator of the Doob h-function, which supplies the steering term that tilts the generative process toward the reward-weighted target measure.
If this is right
- A closed-form reward damping schedule removes the within-mode bias with no additional compute.
- Best-of-n sampling compensates for the inability to select high-reward modes.
- The same two mechanisms operate in both diffusion and flow models.
- The identified biases appear in FLUX.1 text-to-image generation and in 2-D checkerboard targets.
Where Pith is reading between the lines
- Replacing the plug-in estimator with a higher-fidelity approximation could reduce hacking without changing the reward function.
- The analysis suggests examining whether similar finite-particle biases appear in other guidance techniques that rely on score or velocity corrections.
- Hybrid methods that combine the proposed damping with adaptive particle counts may address both failure modes simultaneously.
Load-bearing premise
That the two failure modes isolated for Gaussian and Gaussian-mixture targets with quadratic rewards dominate reward hacking in high-dimensional practical models.
What would settle it
A direct calculation or simulation on a one-dimensional Gaussian target with quadratic reward showing that the finite-particle plug-in estimator produces samples whose reward distribution exactly matches the true tilted distribution with no within-mode shift or mode-selection error.
Figures










read the original abstract
Reward guidance algorithms steer a learned generative process toward the reward-tilted measure at inference time. While empirically powerful, these methods are prone to reward hacking: the guided model over-optimizes the reward at the cost of fidelity to the learned distribution. Prior work has attributed this to the complexity of neural reward functions or implicit biases in diffusion training, but its fundamental origins remain poorly understood. We show that reward hacking arises from an approximation made in most practical implementations of reward-guided diffusion -- finite-particle plug-in estimation of the Doob h-function -- even in the simplest non-trivial settings of Gaussian and Gaussian mixture targets with quadratic rewards. In closed form, we isolate two distinct failure modes of the plug-in estimator: it leads to reward hacking within each mode and it cannot select high-reward modes. We propose a closed-form reward damping schedule that corrects the within-mode bias with no additional compute, and clarify the role of best-of-n sampling in compensating for the mode selection failure. Experiments on Gaussian mixture targets, a 2D checkerboard, and FLUX.1 text-to-image generation confirm that our theoretical insights carry over to practical settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that reward hacking in reward-guided diffusion and flow models stems from the finite-particle plug-in estimation of the Doob h-function, even in simple Gaussian and Gaussian-mixture targets with quadratic rewards. Closed-form derivations isolate two failure modes: within-mode hacking and inability to select high-reward modes. A closed-form reward damping schedule is proposed to correct within-mode bias at no extra cost, and best-of-n sampling is clarified as compensating for mode selection. Experiments on GMM targets, a 2D checkerboard, and FLUX.1 text-to-image generation are presented to show the insights carry over to practical settings.
Significance. The closed-form derivations against standard Gaussian math constitute a clear strength, providing a parameter-free mechanistic account of reward hacking origins that does not rely on neural reward complexity. If the identified mechanisms prove dominant, the damping schedule offers an immediately usable correction, and the analysis shifts the field from empirical attribution to precise diagnosis of the plug-in approximation.
major comments (1)
- [FLUX.1 experiments] FLUX.1 experiments section: the claim that the two Gaussian-derived failure modes 'dominate in practical high-dimensional settings' is load-bearing for the paper's scope, yet the reported FLUX results demonstrate only correlation with particle count in the h-estimator; no ablations are described that hold neural reward model and training fixed while varying particle number (or vice versa) to isolate the plug-in estimator as the primary driver.
minor comments (1)
- The title and abstract reference both 'flow and diffusion models,' but the closed-form analysis is developed only for the diffusion (Doob h-function) case; a brief remark on whether the same plug-in failure modes apply verbatim to continuous normalizing flows would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their careful reading and valuable feedback on our manuscript. We address the major comment below and will make appropriate revisions to strengthen the paper.
read point-by-point responses
-
Referee: [FLUX.1 experiments] FLUX.1 experiments section: the claim that the two Gaussian-derived failure modes 'dominate in practical high-dimensional settings' is load-bearing for the paper's scope, yet the reported FLUX results demonstrate only correlation with particle count in the h-estimator; no ablations are described that hold neural reward model and training fixed while varying particle number (or vice versa) to isolate the plug-in estimator as the primary driver.
Authors: We agree that a stronger claim of dominance would require more rigorous isolation. However, the FLUX.1 experiments do hold the neural reward model and the base generative model fixed (as they are pre-trained components) while varying the number of particles in the finite-particle approximation of the Doob h-function. This directly tests the impact of the plug-in estimator in a practical setting. The results show that increasing the particle count reduces the observed reward hacking, consistent with our theoretical analysis. We acknowledge that this is correlational evidence in a complex model and does not rule out other contributing factors. To address the concern, we will revise the manuscript to clarify the experimental design, emphasize that the results demonstrate consistency with the identified mechanisms rather than proving they dominate, and add a limitations paragraph discussing the challenges of full ablations in high-dimensional pre-trained models. This will be a partial revision. revision: partial
Circularity Check
No circularity: closed-form derivations independent of inputs
full rationale
The paper's central derivations isolate two failure modes of finite-particle plug-in estimation of the Doob h-function for Gaussian and GMM targets with quadratic rewards, performed in closed form against standard Gaussian math. No step reduces a claimed prediction to a fitted parameter by construction, renames a known result, or relies on a self-citation chain that defines the target quantities. The FLUX.1 experiments serve as external confirmation rather than load-bearing inputs to the math. This satisfies the criteria for a self-contained derivation with no circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Targets are Gaussian or Gaussian mixtures with quadratic rewards
Reference graph
Works this paper leans on
-
[1]
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis.arXiv preprint arXiv:2403.03206, 2024...
Pith/arXiv arXiv 2024
-
[2]
ImageReward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. ImageReward: Learning and evaluating human preferences for text-to-image generation. InAdvances in Neural Information Processing Systems, volume 36, pages 15903–15935. Curran Associates, Inc., 2023. (pages 1, 2, 4, 9, and 10)
2023
-
[3]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems, 2020. (page 2)
2020
-
[4]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022. (page 2)
2022
-
[5]
Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, Jonathan Ho, David J
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L. Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, Jonathan Ho, David J. Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. InAdvances in Neural Information Processing Systems, 2022. (page 2)
2022
-
[6]
Equivariant diffusion for molecule generation in 3D
Emiel Hoogeboom, Victor Garcia Satorras, Clément Vignac, and Max Welling. Equivariant diffusion for molecule generation in 3D. InInternational Conference on Machine Learning, 2022. (page 2)
2022
-
[7]
GeoDiff: A geometric diffusion model for molecular conformation generation
Minkai Xu, Lantao Yu, Yang Song, Chence Shi, Stefano Ermon, and Jian Tang. GeoDiff: A geometric diffusion model for molecular conformation generation. InInternational Conference on Learning Representations, 2022. (page 2)
2022
-
[8]
3D equivariant diffusion for target-aware molecule generation and affinity prediction
Jiaqi Guan, Wesley Wei Qian, Xingang Peng, Yufeng Su, Jian Peng, and Jianzhu Ma. 3D equivariant diffusion for target-aware molecule generation and affinity prediction. InInternational Conference on Learning Representations, 2023. (page 2)
2023
-
[9]
Structure-based drug design with equivariant diffusion models.Nature Computational Science, 2024
Arne Schneuing, Charles Harris, Yuanqi Du, Kieran Didi, Arian Jamasb, Ilia Igashov, Weitao Du, Tom Blundell, Pietro Liò, Carla Gomes, Max Welling, Michael Bronstein, and Bruno Correia. Structure-based drug design with equivariant diffusion models.Nature Computational Science, 2024. doi: 10.1038/ s43588-024-00737-x. (page 2)
2024
-
[10]
Watson, David Juergens, Nathaniel R
Joseph L. Watson, David Juergens, Nathaniel R. Bennett, Brian L. Trippe, Jason Yim, Helen E. Eisenach, Woody Ahern, Andrew J. Borst, Robert J. Ragotte, Lukas F. Milles, et al. De novo design of protein structure and function with RFdiffusion.Nature, 2023. doi: 10.1038/s41586-023-06415-8. (pages 2 and 4)
-
[11]
Trippe, Valentin De Bortoli, Emile Mathieu, Arnaud Doucet, Regina Barzilay, and Tommi Jaakkola
Jason Yim, Brian L. Trippe, Valentin De Bortoli, Emile Mathieu, Arnaud Doucet, Regina Barzilay, and Tommi Jaakkola. SE(3) diffusion model with application to protein backbone generation. InInternational Conference on Machine Learning, 2023. (page 2)
2023
-
[12]
Ingraham, Max Baranov, Zak Costello, Karl W
John B. Ingraham, Max Baranov, Zak Costello, Karl W. Barber, Wujie Wang, Ahmed Ismail, Vincent Frappier, Dana M. Lord, Christopher Ng-Thow-Hing, Erik R. Van Vlack, et al. Illuminating protein space with a programmable generative model.Nature, 2023. doi: 10.1038/s41586-023-06728-8. (pages 2 and 4)
-
[13]
Nature communications15(1), 1059 (2024) https://doi.org/10.1038/s41467-024-45051-2
Kevin E. Wu, Kevin K. Yang, Rianne van den Berg, Sarah Alamdari, James Y. Zou, Alex X. Lu, and Ava P. Amini. Protein structure generation via folding diffusion.Nature Communications, 2024. doi: 10.1038/s41467-024-45051-2. (page 2) 14
-
[14]
Pick-a-Pic: An open dataset of user preferences for text-to-image generation.Advances in Neural Information Processing Systems, 2023
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-Pic: An open dataset of user preferences for text-to-image generation.Advances in Neural Information Processing Systems, 2023. (pages 2 and 4)
2023
-
[15]
Training diffusion models with reinforcement learning.International Conference on Learning Representations, 2024
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning.International Conference on Learning Representations, 2024. (page 2)
2024
-
[16]
Diffusion model alignment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024. (page 2)
2024
-
[17]
RewardDance: Reward scaling in visual generation.arXiv preprint arXiv:2509.08826, 2025
Jie Wu, Yu Gao, Zilyu Ye, Ming Li, Liang Li, Hanzhong Guo, Jie Liu, Zeyue Xue, Xiaoxia Hou, Wei Liu, Yan Zeng, and Weilin Huang. RewardDance: Reward scaling in visual generation.arXiv preprint arXiv:2509.08826, 2025. (page 2)
arXiv 2025
-
[18]
3D equivariant diffusion for target-aware molecule generation and affinity prediction.International Conference on Learning Representations, 2023
Jiaqi Guan, Wesley Wei Qian, Xingang Peng, Yufeng Su, Jian Peng, and Jianzhu Ma. 3D equivariant diffusion for target-aware molecule generation and affinity prediction.International Conference on Learning Representations, 2023. (pages 2 and 4)
2023
-
[19]
DecompDiff: Diffusion models with decomposed priors for structure-based drug design
Jiaqi Guan, Xiangxin Zhou, Yuwei Yang, Yu Bao, Jian Peng, Jianzhu Ma, Qiang Liu, Liang Wang, and Quanquan Gu. DecompDiff: Diffusion models with decomposed priors for structure-based drug design. InInternational Conference on Machine Learning, 2023. (pages 2 and 4)
2023
-
[20]
Yue Jian, Curtis Wu, Danny Reidenbach, and Aditi S. Krishnapriyan. General binding affinity guidance for diffusion models in structure-based drug design.arXiv preprint arXiv:2406.16821, 2024. (pages 2 and 4)
arXiv 2024
-
[21]
Nate Gruver, Samuel Stanton, Nathan Frey, Tim G. J. Rudner, Isidro Hotzel, Julien Lafrance-Vanasse, Arvind Rajpal, Kyunghyun Cho, and Andrew G. Wilson. Protein design with guided discrete diffusion. InAdvances in Neural Information Processing Systems, 2023. (pages 2 and 4)
2023
-
[22]
Diffusion models beat GANs on image synthesis.Advances in Neural Information Processing Systems, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat GANs on image synthesis.Advances in Neural Information Processing Systems, 2021. (page 2)
2021
-
[23]
Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598,
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598,
-
[24]
Masatoshi Uehara, Yulai Zhao, Kevin Black, Ehsan Hajiramezanali, Gabriele Scalia, Nathaniel Lee Diamant, Alex M Tseng, Tommaso Biancalani, and Sergey Levine. Fine-tuning of continuous-time diffusion models as entropy-regularized control.arXiv preprint arXiv:2402.15194, 2024. (pages 2 and 4)
arXiv 2024
-
[25]
Masatoshi Uehara, Yulai Zhao, Chenyu Wang, Xiner Li, Aviv Regev, Sergey Levine, and Tommaso Biancalani. Inference-time alignment in diffusion models with reward-guided generation: Tutorial and review.arXiv preprint arXiv:2501.09685, 2025. (pages 2, 3, and 4)
arXiv 2025
-
[26]
Scaling laws for reward model overoptimization
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. In International Conference on Machine Learning, pages 10835–10866. PMLR, 2023. (page 2)
2023
-
[27]
Helping or herding? Reward model ensembles mitigate but do not eliminate reward hacking
Jacob Eisenstein, Chirag Nagpal, Alekh Agarwal, Ahmad Beirami, Alex D’Amour, DJ Dvijotham, Adam Fisch, Katherine Heller, Stephen Pfohl, Deepak Ramachandran, Peter Shaw, and Jonathan Berant. Helping or herding? Reward model ensembles mitigate but do not eliminate reward hacking. In Conference on Language Modeling, 2024. (page 2)
2024
-
[28]
Bradley Knox, Chelsea Finn, and Scott Niekum
Rafael Rafailov, Yaswanth Chittepu, Ryan Park, Harshit Sikchi, Joey Hejna, W. Bradley Knox, Chelsea Finn, and Scott Niekum. Scaling laws for reward model overoptimization in direct alignment algorithms. InAdvances in Neural Information Processing Systems, volume 37, 2024. (page 2)
2024
-
[29]
Confronting reward overoptimization for diffusion models: A perspective of inductive and primacy biases
Ziyi Zhang, Sen Zhang, Yibing Zhan, Yong Luo, Yonggang Wen, and Dacheng Tao. Confronting reward overoptimization for diffusion models: A perspective of inductive and primacy biases. InInternational Conference on Machine Learning, pages 60396–60413. PMLR, 2024. (page 2) 15
2024
-
[30]
Flow matching for generative modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InInternational Conference on Learning Representations, 2023. (page 3)
2023
-
[31]
Stochastic interpolants: A unifying framework for flows and diffusions.Journal of Machine Learning Research, 2025
Michael Albergo, Nicholas M Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.Journal of Machine Learning Research, 2025. (pages 3 and 4)
2025
-
[32]
L. C. G. Rogers and David Williams.Diffusions, Markov Processes and Martingales. Cambridge Mathematical Library. Cambridge University Press, 2 edition, 2000. (page 3)
2000
-
[33]
Carles Domingo-Enrich, Michal Drozdzal, Brian Karrer, and Ricky T. Q. Chen. Adjoint matching: Fine- tuning flow and diffusion generative models with memoryless stochastic optimal control.International Conference on Learning Representations, 2025. (pages 3, 4, and 21)
2025
-
[34]
Peter Holderrieth, Uriel Singer, Tommi Jaakkola, Ricky T. Q. Chen, Yaron Lipman, and Brian Karrer. GLASS flows: Efficient inference for reward alignment of flow and diffusion models.International Conference on Learning Representations, 2026. (pages 3, 4, and 19)
2026
-
[35]
Peter Potaptchik, Adhi Saravanan, Abbas Mammadov, Alvaro Prat, Michael S. Albergo, and Yee Whye Teh. Meta Flow Maps enable scalable reward alignment.arXiv preprint arXiv:2601.14430, 2026. (pages 3 and 4)
Pith/arXiv arXiv 2026
-
[36]
Peter Holderrieth, Douglas Chen, Luca Eyring, Ishin Shah, Giri Anantharaman, Yutong He, Zeynep Akata, Tommi Jaakkola, Nicholas Matthew Boffi, and Max Simchowitz. Diamond maps: Efficient reward alignment via stochastic flow maps.arXiv preprint arXiv:2602.05993, 2026. (pages 3, 4, 9, 10, and 35)
Pith/arXiv arXiv 2026
-
[37]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341, 2023. (page 4)
Pith/arXiv arXiv 2023
-
[38]
How to build a consistency model: Learning flow maps via self-distillation.Advances in Neural Information Processing Systems, 2025
Nicholas M Boffi, Michael S Albergo, and Eric Vanden-Eijnden. How to build a consistency model: Learning flow maps via self-distillation.Advances in Neural Information Processing Systems, 2025. (page 4)
2025
-
[39]
Jerry Huang, Justin Lin, Sheel Shah, Kartik Nair, and Nicholas M. Boffi. How to guide your flow: Steering flow maps for rapid test-time alignment. InInternational Conference on Machine Learning,
-
[40]
(pages 4, 6, 35, 36, and 37)
-
[41]
What does guidance do? a fine-grained analysis in a simple setting.Advances in Neural Information Processing Systems, 2024
Muthu Chidambaram, Khashayar Gatmiry, Sitan Chen, Holden Lee, and Jianfeng Lu. What does guidance do? a fine-grained analysis in a simple setting.Advances in Neural Information Processing Systems, 2024. (page 4)
2024
-
[42]
Theoretical insights for diffusion guidance: A case study for Gaussian mixture models.International Conference on Machine Learning,
Yuchen Wu, Minshuo Chen, Zihao Li, Mengdi Wang, and Yuting Wei. Theoretical insights for diffusion guidance: A case study for Gaussian mixture models.International Conference on Machine Learning,
-
[43]
Krunoslav Lehman Pavasovic, Jakob Verbeek, Giulio Biroli, and Marc Mezard. Classifier-free guidance: From high-dimensional analysis to generalized guidance forms.arXiv preprint arXiv:2502.07849, 2025. (page 4)
arXiv 2025
-
[44]
Enrico Ventura, Beatrice Achilli, Luca Ambrogioni, and Carlo Lucibello. Emergence of distortions in high-dimensional guided diffusion models.arXiv preprint arXiv:2602.00716, 2026. (page 4)
Pith/arXiv arXiv 2026
-
[45]
Analysis of classifier-free guidance weight schedulers.Transactions on Machine Learning Research, 2024
Xi Wang, Nicolas Dufour, Nefeli Andreou, Marie-Paule Cani, Victoria Fernández Abrevaya, David Picard, and Vicky Kalogeiton. Analysis of classifier-free guidance weight schedulers.Transactions on Machine Learning Research, 2024. (page 4)
2024
-
[46]
Ankur Moitra, Andrej Risteski, and Dhruv Rohatgi. Steering diffusion models with quadratic rewards: a fine-grained analysis.arXiv preprint arXiv:2602.16570, 2026. (page 4)
arXiv 2026
-
[47]
Ankur Moitra, Andrej Risteski, and Dhruv Rohatgi. The tractability landscape of diffusion alignment: regularization, rewards, and computational primitives.arXiv preprint arXiv:2605.11361, 2026. (page 4) 16
Pith/arXiv arXiv 2026
-
[48]
Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923,
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-VL technical report.ar...
-
[49]
sup t∈[0,1] Z t 0 b(k) η(s)(¯xη(s))−b (k) s (¯xs) ds 2 # ≤Lh Z 1 0 B+ vuutE
Stéphane Boucheron, Gábor Lugosi, and Pascal Massart.Concentration Inequalities: a Nonasymptotic Theory of Independence. Oxford University Press, 2013. (page 29) 17 A Further background A.1 Forward SDE matches the probability flow time-marginals Proposition 7(Time-marginals of the forward SDE).The solution of the forward SDE(2) has the same time-marginal ...
2013
-
[50]
For (iii), note that then independent finite-k plug-in trajectories are i.i.d., so the probability that allntrajectories end up negative is(1/2)n. D Experimental details and ablations D.1 Damping for Gaussian target We use a single Gaussian targetρ1 = N (0, 0.5I2)with quadratic reward r(x) = −∥x−a∥ 2 2 centered at a = (0, 2.5)⊤ and λ = 3.0. By Proposition...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.