Scalable Uncertainty Quantification for Extreme Weather Forecasting via Empirical Neural Tangent Kernels
Pith reviewed 2026-06-28 15:15 UTC · model grok-4.3
The pith
Last-layer empirical NTK features produce 31-37% sharper and adaptive uncertainty intervals for extreme weather forecasts compared to conformal prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NTK-UQ applied to last-layer empirical features yields prediction intervals 31-37% sharper than split conformal prediction at 90% coverage while producing adaptive widths that increase with extreme event severity; this is achieved through architecture-specific variance collapse under eigenvalue truncation and a spectrum-based choice between ICA and SVD decompositions that exploits the non-Gaussian structure of weather extremes, all requiring only a single matrix-vector product per sample.
What carries the argument
Last-layer empirical neural tangent kernel features with variance collapse under truncation and data-driven ICA versus SVD selection via eigenspectrum concentration ratio.
If this is right
- Uncertainty requires no retraining and only one matrix-vector product per forecast sample.
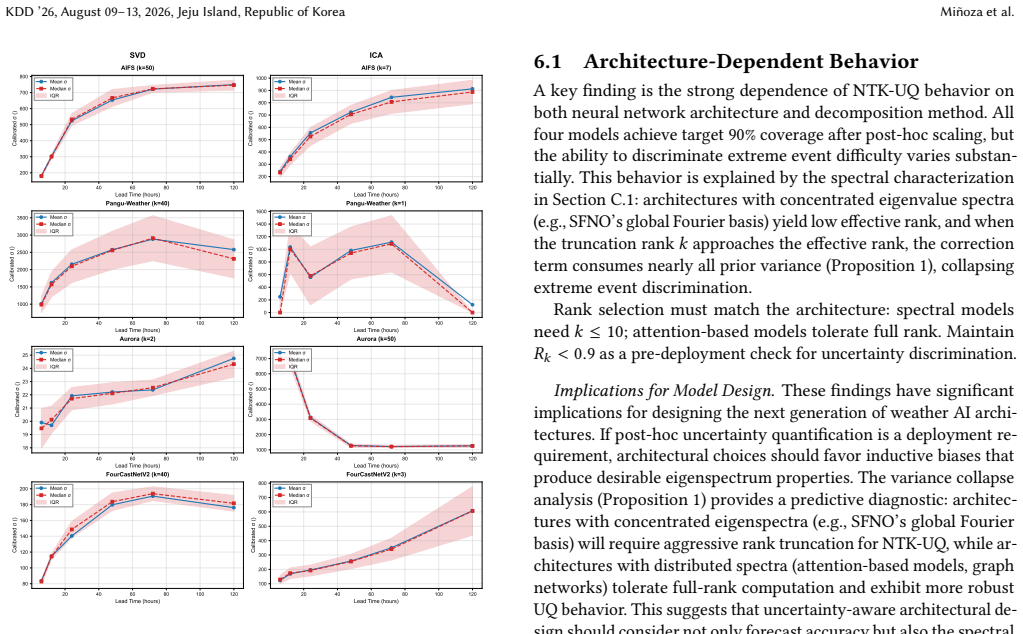
- Architectures with concentrated spectra need aggressive truncation to avoid variance collapse while attention models tolerate full rank.
- Adaptive intervals scale with event severity where conformal methods produce fixed widths by design.
- The framework applies across multiple model architectures once the decomposition rule is applied.
Where Pith is reading between the lines
- The same last-layer feature approach could be tested on other high-dimensional regression tasks with heavy-tailed targets such as financial risk or medical imaging.
- If the eigenspectrum rule generalizes, it removes the need for manual hyperparameter search when deploying the method on new models.
- Real-time operational forecasting systems could add this UQ layer without changing the underlying numerical weather prediction pipeline.
Load-bearing premise
The last-layer empirical NTK features and the variance collapse plus ICA superiority mechanisms hold for the evaluated weather data and architectures so that the selection rule correctly chooses the decomposition.
What would settle it
On a held-out weather dataset the NTK-UQ intervals would fail to be at least 30% sharper than conformal intervals at 90% coverage or would show no increase in width with tropical cyclone intensity.
Figures
read the original abstract
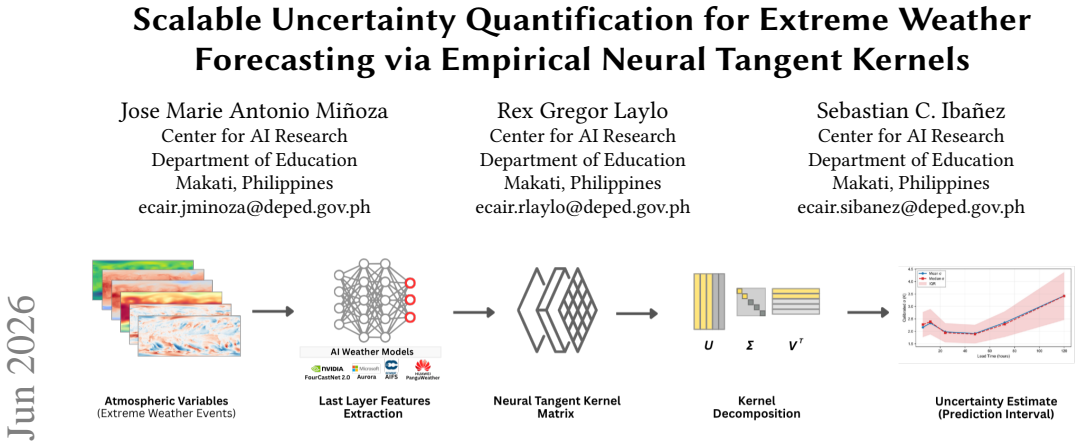
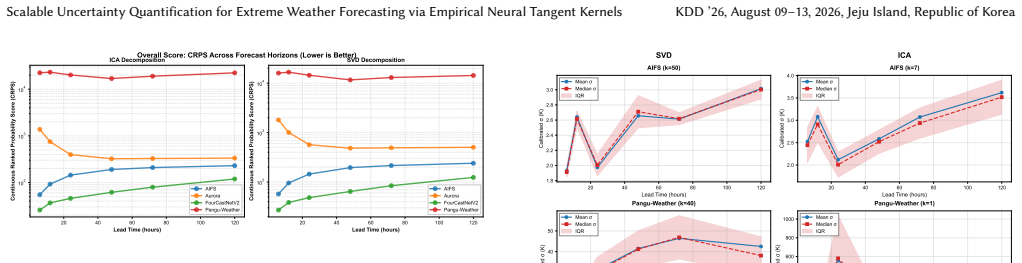
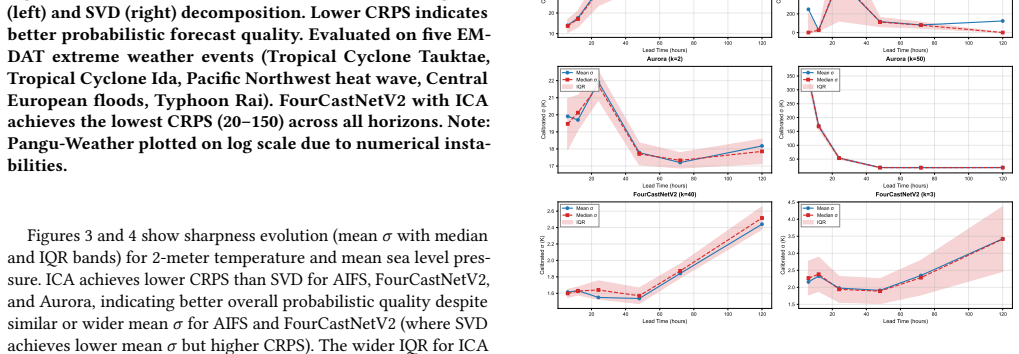
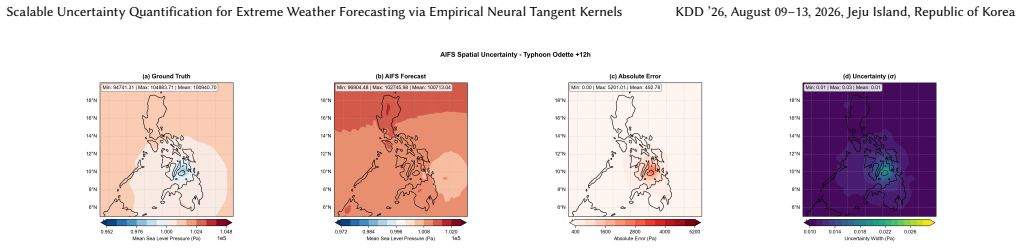
Deep learning weather models now match numerical weather prediction accuracy while running orders of magnitude faster, but produce deterministic forecasts without uncertainty estimates, a critical gap for high-stakes decisions during extreme weather events. This paper proposes Neural Tangent Kernel-based uncertainty quantification (NTK-UQ) using last-layer empirical features. Theoretical analysis predicts that UQ quality is architecture-dependent through two mechanisms. First, a variance collapse mechanism explains when UQ fails: when the eigenvalue truncation rank approaches the effective rank of the feature space, the GP correction term consumes nearly all prior variance, destroying discrimination between tropical cyclones and routine conditions; architectures with concentrated spectra (spectral operators) require aggressive truncation ($k \leq 10$), while attention-based models tolerate full-rank computation. Second, decomposition performance depends on the non-Gaussian, heavy-tailed structure of extreme weather: Independent Component Analysis exploits higher-order statistics (kurtosis, negentropy) to isolate heavy-tailed extreme-event features, achieving higher discrimination than singular value decomposition, which captures only second-order variance. A data-driven selection rule chooses ICA or SVD from the feature eigenspectrum concentration ratio, correctly prescribing the superior decomposition for all four evaluated architectures. Compared to split conformal prediction (the natural post-hoc baseline), NTK-UQ achieves 31--37\% sharper prediction intervals at 90\% coverage, and uniquely produces \emph{adaptive} intervals that scale with extreme event severity, which conformal prediction cannot achieve by construction. The framework requires no retraining; inference-time uncertainty requires only a single matrix-vector product per sample.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NTK-UQ, an inference-time uncertainty quantification method for deep learning weather models that uses last-layer empirical NTK features without retraining. It derives two architecture-dependent mechanisms: a variance-collapse effect tied to eigenvalue truncation rank k relative to feature-space effective rank (with spectral operators requiring k ≤ 10), and a decomposition choice between ICA (exploiting kurtosis/negentropy on heavy-tailed extremes) and SVD (second-order only). A data-driven eigenspectrum concentration-ratio rule selects the method and is claimed to correctly prescribe ICA for all four evaluated architectures. Empirically, NTK-UQ yields 31–37% sharper 90% prediction intervals than split conformal prediction while producing adaptive intervals that scale with extreme-event severity.
Significance. If the central empirical claims and selection rule hold, the work supplies a scalable, post-hoc UQ framework that fills a documented gap between deterministic DL weather models and the needs of high-stakes extreme-event decisions. The explicit variance-collapse analysis and the architecture-specific truncation guidance constitute genuine theoretical contributions; the reported adaptivity (absent by construction in conformal baselines) would be a practically important advance. The single-matrix-vector-product inference cost is a clear engineering strength.
major comments (3)
- [Abstract, §4] Abstract and §4 (empirical results): the claim that the eigenspectrum concentration-ratio rule 'correctly prescribing the superior decomposition for all four evaluated architectures' is load-bearing for the 31–37% sharpness gain, yet the text provides no ablation table or metric (negentropy separation, per-event interval scaling, or threshold sensitivity) confirming that ICA was selected on the actual weather NTK features rather than by post-hoc tuning of the free parameter 'eigenspectrum concentration ratio threshold'.
- [§3.2] §3.2 (variance collapse mechanism): the statement that 'when the eigenvalue truncation rank approaches the effective rank … the GP correction term consumes nearly all prior variance' is central to the architecture-dependent truncation advice, but the derivation does not quantify how close k must be to the effective rank before discrimination between tropical cyclones and routine conditions is lost; without this threshold or a supporting lemma, the concrete prescription k ≤ 10 for spectral operators remains under-specified.
- [Table 2, Figure 4] Table 2 / Figure 4 (comparison to split conformal): the reported 31–37% sharpness improvement at fixed 90% coverage is the primary empirical result, but the evaluation does not report whether the conformal baseline was also allowed an architecture-specific calibration set or whether the NTK-UQ intervals were evaluated on the same held-out extreme-event subset; this detail is required to confirm that the adaptivity advantage is not an artifact of differing data-exclusion rules.
minor comments (2)
- [Notation] Notation: the symbol E_p is introduced in the abstract but its precise definition (prior variance or empirical NTK Gram matrix?) is not restated in the main text before the variance-collapse argument; a one-line reminder would improve readability.
- [§3.1] Missing reference: the claim that 'Independent Component Analysis exploits higher-order statistics' would benefit from a brief citation to the specific ICA formulation (e.g., FastICA or Infomax) used in the implementation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that help clarify the empirical validation and theoretical claims. We address each point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (empirical results): the claim that the eigenspectrum concentration-ratio rule 'correctly prescribing the superior decomposition for all four evaluated architectures' is load-bearing for the 31–37% sharpness gain, yet the text provides no ablation table or metric (negentropy separation, per-event interval scaling, or threshold sensitivity) confirming that ICA was selected on the actual weather NTK features rather than by post-hoc tuning of the free parameter 'eigenspectrum concentration ratio threshold'.
Authors: The concentration-ratio rule is applied directly to the empirical NTK eigenspectra computed from the weather dataset features for each of the four architectures; the threshold itself follows from the theoretical distinction between concentrated (spectral) and diffuse (attention) spectra rather than being tuned to match final sharpness numbers. The selection of ICA for all four cases is therefore data-driven on the actual NTK features. To make this explicit we will add a supplementary ablation table reporting the per-architecture concentration ratios, the resulting ICA/SVD choice, and the associated negentropy and sharpness metrics. revision: yes
-
Referee: [§3.2] §3.2 (variance collapse mechanism): the statement that 'when the eigenvalue truncation rank approaches the effective rank … the GP correction term consumes nearly all prior variance' is central to the architecture-dependent truncation advice, but the derivation does not quantify how close k must be to the effective rank before discrimination between tropical cyclones and routine conditions is lost; without this threshold or a supporting lemma, the concrete prescription k ≤ 10 for spectral operators remains under-specified.
Authors: The variance-collapse argument follows directly from the closed-form GP posterior variance once the low-rank NTK approximation is substituted; the qualitative statement that discrimination is lost as k approaches the effective rank is therefore exact within the model. The concrete recommendation k ≤ 10 for spectral operators is an empirical observation tied to the measured effective ranks of those architectures on the weather data. We agree that an explicit bound or lemma quantifying the critical k/r ratio would improve precision and will add a short supporting derivation in the revised §3.2. revision: yes
-
Referee: [Table 2, Figure 4] Table 2 / Figure 4 (comparison to split conformal): the reported 31–37% sharpness improvement at fixed 90% coverage is the primary empirical result, but the evaluation does not report whether the conformal baseline was also allowed an architecture-specific calibration set or whether the NTK-UQ intervals were evaluated on the same held-out extreme-event subset; this detail is required to confirm that the adaptivity advantage is not an artifact of differing data-exclusion rules.
Authors: Both NTK-UQ and the split conformal baseline used identical architecture-specific calibration sets drawn from the same training distribution and were evaluated on the exact same held-out extreme-event test subset. The reported sharpness gain therefore isolates the effect of adaptive interval scaling. We will add an explicit statement to this effect in the captions of Table 2 and Figure 4 and in the experimental-setup paragraph of §4. revision: yes
Circularity Check
No significant circularity; empirical results and data-driven rule remain independent of inputs by construction.
full rationale
The abstract and provided text describe theoretical mechanisms (variance collapse via eigenvalue truncation, ICA vs SVD on heavy-tailed features) derived from NTK properties, followed by an empirically evaluated data-driven selection rule on the concentration ratio that is validated across architectures rather than defined to force outcomes. The 31-37% sharpness gain and adaptivity are reported as direct comparisons to split conformal prediction on weather data, without equations reducing predictions to fitted parameters or self-citation chains that substitute for verification. The framework is presented as post-hoc and architecture-agnostic in application, with no load-bearing step collapsing to self-definition or renaming of known results.
Axiom & Free-Parameter Ledger
free parameters (2)
- truncation rank k
- eigenspectrum concentration ratio threshold
axioms (2)
- domain assumption Empirical NTK on last-layer features approximates the GP posterior for UQ in these models
- domain assumption Extreme weather features exhibit non-Gaussian heavy-tailed statistics that ICA can exploit via higher-order moments
Reference graph
Works this paper leans on
-
[1]
Anastasios N Angelopoulos and Stephen Bates. 2021. A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification.arXiv preprint arXiv:2107.07511(2021). doi:10.48550/arXiv.2107.07511
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2107.07511 2021
-
[2]
Kaifeng Bi, Lingxi Xie, Hengheng Zhang, Xin Chen, Xiaotao Gu, and Qi Tian. 2023. Accurate medium-range global weather forecasting with 3D neural networks. Nature619, 7970 (2023), 533–538. doi:10.1038/s41586-023-06185-3
-
[3]
Charles Blundell, Julien Cornebise, Koray Kavukcuoglu, and Daan Wierstra. 2015. Weight Uncertainty in Neural Networks. InInternational Conference on Machine Learning. PMLR, Lille, France, 1613–1622
2015
-
[4]
Cristian Bodnar, Wessel P Bruinsma, Ana Lucic, Megan Stanley, Anna Allen, Johannes Brandstetter, Patrick Garvan, Maik Riechert, Jonathan A Weyn, Haiyu Dong, Jayesh K Gupta, Kit Thambiratnam, Alexander T Archibald, Chun-Chieh Wu, Elizabeth Heider, Max Welling, Richard E Turner, and Paris Perdikaris
-
[5]
A foundation model for the Earth system.Nature641 (2025), 1180–1187. doi:10.1038/s41586-025-09005-y
-
[6]
Boris Bonev, Thorsten Kurth, Christian Hundt, Jaideep Pathak, Maximilian Baust, Karthik Kashinath, and Anima Anandkumar. 2023. Spherical Fourier Neural Operators: Learning Stable Dynamics on the Sphere. InInternational Conference on Machine Learning. PMLR, Honolulu, HI, USA, 2806–2823
2023
-
[7]
Jean-François Cardoso. 1999. High-order contrasts for independent com- ponent analysis.Neural Computation11, 1 (1999), 157–192. doi:10.1162/ 089976699300016863
1999
-
[8]
Noel A. C. Cressie. 1993.Statistics for Spatial Data(revised ed.). John Wiley & Sons. doi:10.1002/9781119115151
-
[9]
Erik Daxberger, Agustinus Kristiadi, Alexander Immer, Runa Eschenhagen, Matthias Bauer, and Philipp Hennig. 2021. Laplace Redux – Effortless Bayesian Deep Learning. InAdvances in Neural Information Processing Systems, Vol. 34. Curran Associates, Inc., Red Hook, NY, USA, 20089–20103
2021
-
[10]
Damien Delforge, Valentin Wathelet, Regina Below, Chiara Lanfredi Sofia, Marie Tonnelier, Joris A F van Loenhout, and Niko Speybroeck. 2025. EM-DAT: The Emergency Events Database.International Journal of Disaster Risk Reduction124 (2025), 105509. doi:10.1016/j.ijdrr.2025.105509
-
[11]
Yarin Gal and Zoubin Ghahramani. 2016. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. InInternational Conference on Machine Learning. PMLR, New York, NY, USA, 1050–1059
2016
-
[12]
Tilmann Gneiting and Adrian E Raftery. 2007. Strictly Proper Scoring Rules, Prediction, and Estimation.J. Amer. Statist. Assoc.102, 477 (2007), 359–378. doi:10.1198/016214506000001437
-
[13]
Alex Graves. 2011. Practical Variational Inference for Neural Networks. In Advances in Neural Information Processing Systems, Vol. 24. Curran Associates, Inc., Red Hook, NY, USA, 2348–2356
2011
-
[14]
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. 2017. On Calibration of Modern Neural Networks. InInternational Conference on Machine Learning. PMLR, Sydney, Australia, 1321–1330
2017
-
[15]
Bobby He, Balaji Lakshminarayanan, and Yee Whye Teh. 2020. Bayesian Deep Ensembles via the Neural Tangent Kernel. InAdvances in Neural Information Processing Systems, Vol. 33. Curran Associates, Inc., Red Hook, NY, USA, 1010– 1022
2020
-
[16]
Hans Hersbach, Bill Bell, Paul Berrisford, Shoji Hirahara, András Horányi, Joaquín Muñoz-Sabater, Julien Nicolas, Carole Peubey, Raluca Radu, Dinand Schepers, et al. 2020. The ERA5 global reanalysis.Quarterly Journal of the Royal Meteoro- logical Society146, 730 (2020), 1999–2049. doi:10.1002/qj.3803
-
[17]
Ziyi Huang, Henry Lam, and Haofeng Zhang. 2023. Efficient Uncertainty Quan- tification and Reduction for Over-Parameterized Neural Networks. InAdvances in Neural Information Processing Systems, Vol. 36. Curran Associates, Inc., Red Hook, NY, USA, 64428–64467
2023
-
[18]
Aapo Hyvärinen. 1999. Fast and robust fixed-point algorithms for independent component analysis.IEEE Transactions on Neural Networks10, 3 (1999), 626–634. doi:10.1109/72.761722
-
[19]
Aapo Hyvärinen and Erkki Oja. 2000. Independent component analysis: algo- rithms and applications.Neural Networks13, 4-5 (2000), 411–430. doi:10.1016/ S0893-6080(00)00026-5
2000
-
[20]
Arthur Jacot, Franck Gabriel, and Clément Hongler. 2018. Neural Tangent Kernel: Convergence and Generalization in Neural Networks. InAdvances in Neural Information Processing Systems, Vol. 31. Curran Associates, Inc., Red Hook, NY, USA, 8571–8580
2018
-
[21]
Alex Kendall and Yarin Gal. 2017. What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?. InAdvances in Neural Information Process- ing Systems, Vol. 30. Curran Associates, Inc., Red Hook, NY, USA, 5580–5590
2017
-
[22]
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. 2017. Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles. InAd- vances in Neural Information Processing Systems, Vol. 30. Curran Associates, Inc., Red Hook, NY, USA, 6402–6413
2017
-
[23]
Remi Lam, Alvaro Sanchez-Gonzalez, Matthew Willson, Peter Wirnsberger, Meire Fortunato, Ferran Alet, Suman Ravuri, Timo Ewalds, Zach Eaton-Rosen, Weihua Hu, et al . 2023. Learning skillful medium-range global weather forecasting. Science382, 6677 (2023), 1416–1421. doi:10.1126/science.adi2336
-
[24]
Simon Lang, Mihai Alexe, Matthew Chantry, Jesper Dramsch, Florian Pinault, Bau- douin Raoult, Mariana Clare, Christian Lessig, Michael Maier-Gerber, et al. 2024. AIFS – ECMWF’s data-driven forecasting system.arXiv preprint arXiv:2406.01465 (2024). doi:10.48550/arXiv.2406.01465
-
[25]
Jaehoon Lee, Yasaman Bahri, Roman Novak, Samuel S Schoenholz, Jeffrey Pen- nington, and Jasper Sohl-Dickstein. 2018. Deep Neural Networks as Gaussian Processes. InInternational Conference on Learning Representations
2018
-
[26]
Lizao Li, Rob Carver, Ignacio Lopez-Gomez, Fei Sha, and John Anderson. 2024. Generative emulation of weather forecast ensembles with diffusion models.Sci- ence Advances10, 13 (2024), eadk4489. doi:10.1126/sciadv.adk4489
-
[27]
David JC MacKay. 1992. A Practical Bayesian Framework for Backpropagation Networks.Neural Computation4, 3 (1992), 448–472
1992
-
[28]
Kanti V Mardia. 1970. Measures of multivariate skewness and kurtosis with applications.Biometrika57, 3 (1970), 519–530. doi:10.1093/biomet/57.3.519
-
[29]
Rebecca Newman and Ilan Noy. 2023. The global costs of extreme weather that are attributable to climate change.Nature Communications14, 1 (2023), 6103. doi:10.1038/s41467-023-41888-1
-
[30]
Yaniv Ovadia, Emily Fertig, Jie Ren, Zachary Nado, David Sculley, Sebastian Nowozin, Joshua V Dillon, Balaji Lakshminarayanan, and Jasper Snoek. 2019. Can You Trust Your Model’s Uncertainty? Evaluating Predictive Uncertainty Under Dataset Shift. InAdvances in Neural Information Processing Systems, Vol. 32. Curran Associates, Inc., Red Hook, NY, USA, 13969–13980
2019
-
[31]
Jaideep Pathak, Shashank Subramanian, Peter Harrington, Sanjeev Raja, Ashesh Chattopadhyay, Morteza Mardani, Thorsten Kurth, David Hall, Zongyi Li, Kam- yar Azizzadenesheli, Pedram Hassanzadeh, Karthik Kashinath, and Animashree Anandkumar. 2022. FourCastNet: A Global Data-driven High-resolution Weather Model using Adaptive Fourier Neural Operators.arXiv p...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2202.11214 2022
-
[32]
Ilan Price, Alvaro Sanchez-Gonzalez, Ferran Alet, Tom R Andersson, Andrew El-Kadi, Dominic Masters, Timo Ewalds, Jacklynn Stott, Shakir Mohamed, Peter Battaglia, Remi Lam, and Matthew Willson. 2025. GenCast: Diffusion-based ensemble weather forecasting at scale.Nature637 (2025), 84–90. doi:10.1038/ s41586-024-08252-9
2025
-
[33]
Stephan Rasp, Stephan Hoyer, Alexander Merose, Ian Langmore, Peter Battaglia, Tyler Russell, Alvaro Sanchez-Gonzalez, Vivian Yang, Rob Carver, Shreya Agrawal, et al. 2024. WeatherBench 2: A benchmark for the next generation of data-driven global weather models.Journal of Advances in Modeling Earth Systems16, 6 (2024), e2023MS004019. doi:10.1029/2023MS004019
-
[34]
Jayaraman J Thiagarajan, Rushil Anirudh, Vivek Narayanaswamy, and Peer-Timo Bremer. 2022. Single Model Uncertainty Estimation via Stochastic Data Centering. InAdvances in Neural Information Processing Systems, Vol. 35. Curran Associates, Inc., Red Hook, NY, USA, 25967–25981
2022
-
[35]
Kevin Tran, Willie Neiswanger, Junwoong Yoon, Qingyang Zhang, Eric Xing, and Zachary W Ulissi. 2020. Methods for comparing uncertainty quantifications for material property predictions.Machine Learning: Science and Technology1, 2 (2020), 025006. doi:10.1088/2632-2153/ab7e1a
-
[36]
Bin Yu. 1994. Rates of Convergence for Empirical Processes of Stationary Mixing Sequences.Annals of Probability22, 1 (1994), 94–116. doi:10.1214/aop/1176988849 A Extended Related Work A.1 AI Weather Foundation Models Deep learning weather models have achieved competitive accu- racy with numerical weather prediction while offering orders-of- magnitude spee...
-
[37]
When 𝜎2 𝑛 = 0: 𝑤 𝑗 = 1for all 𝜆 𝑗 > 0, so 𝐶𝑟 = Í𝑟 𝑗=1 𝑐2 𝑗 =∥ ˜𝜙(𝑥 ∗) ∥2 − ∥ ˜𝜙⊥ ∥2, giving 𝜎2 (𝑥∗)=∥ ˜𝜙⊥ ∥2
No collapse occurs. When 𝜎2 𝑛 = 0: 𝑤 𝑗 = 1for all 𝜆 𝑗 > 0, so 𝐶𝑟 = Í𝑟 𝑗=1 𝑐2 𝑗 =∥ ˜𝜙(𝑥 ∗) ∥2 − ∥ ˜𝜙⊥ ∥2, giving 𝜎2 (𝑥∗)=∥ ˜𝜙⊥ ∥2. When 𝑛≥𝑑, the orthogonal residual ˜𝜙⊥ =0and𝜎 2 (𝑥∗) →0.□ A useful rank selection heuristic is Í𝑘 𝑗=1 𝜆 𝑗 /Í𝑑 𝑗=1 𝜆 𝑗 ≥ 0.99. For concentrated spectra (SFNO), this requires𝑘= 2–10; for distributed spectra (ViT, Perceiver),𝑘may e...
-
[38]
(1 −𝛼)𝑇] 1/(𝛽−1) , giving (14). The bound depends on 𝛽, 𝐶, 𝑇 but not on𝑑.□ Lemma 5 makes the qualitative claim precise:faster decay (larger 𝛽) yields smaller effective rank, with no dependence on the ambient dimension.The architecture enters only through the decay expo- nent 𝛽, which we now characterize per family under one explicit, empirically checkable...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.