Large AI Models in Dental Healthcare: From General-Purpose Systems to Domain-Specific Foundation Models
Pith reviewed 2026-06-28 14:03 UTC · model grok-4.3
The pith
General-purpose and dental-specific AI models complement each other, with their combination in structured pipelines yielding the best results for dental tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
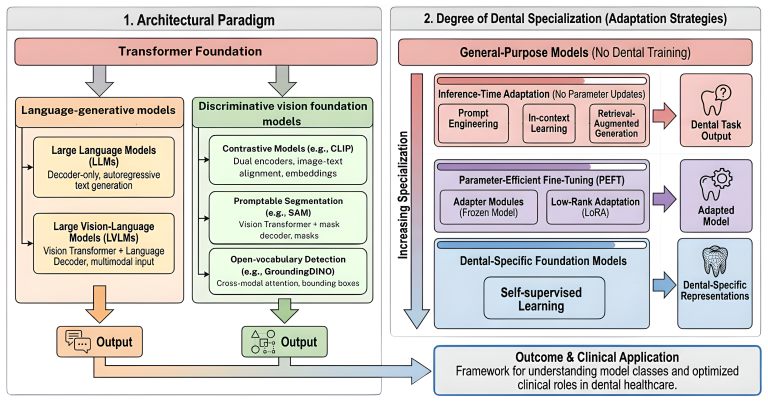
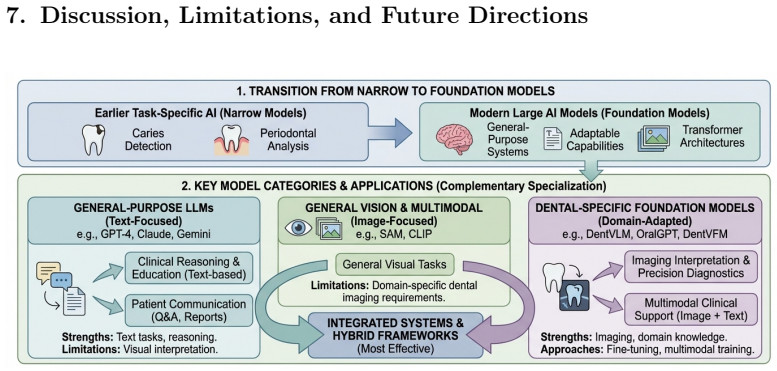
Three distinct model categories have emerged in dentistry: language-generative models, discriminative vision foundation models, and dental-specific foundation models. Using a proposed two-dimensional classification framework based on architectural paradigm and dental specialization degree, the review finds that general-purpose models excel in text-based tasks but are inconsistent on image diagnostics, adapted general vision models achieve strong results in segmentation and detection, and dental-specific models perform best on complex multimodal tasks. Integrated pipelines outperform single-model approaches, though dental-specific pretraining is heavily skewed toward vision due to scarce text
What carries the argument
The two-dimensional classification framework that organizes large AI models by architectural paradigm and degree of dental specialization.
If this is right
- Integrated pipelines consistently outperform single-model approaches.
- Dental-specific models demonstrate the strongest performance on complex multimodal tasks.
- Language-generative models excel at text-based tasks but show inconsistent performance on image-dependent diagnostics.
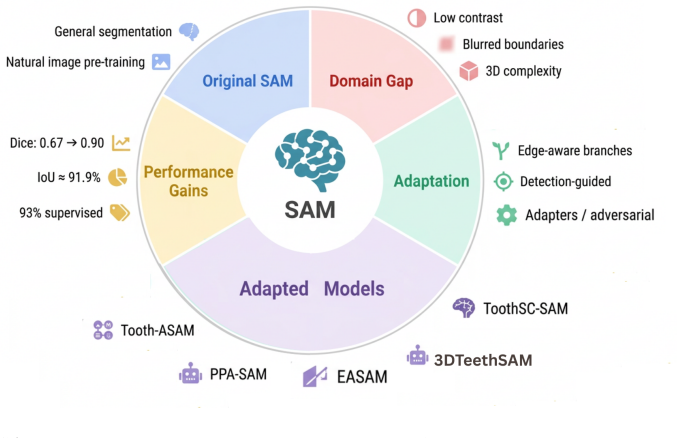
- Adapted general vision models like SAM and CLIP variants achieve strong results in tooth segmentation and lesion detection.
- A data asymmetry exists where dental-specific pretraining concentrates almost entirely in the vision domain.
Where Pith is reading between the lines
- Future work could test whether creating more dental text data would reduce the observed asymmetry and improve multimodal performance.
- Establishing standardized benchmarks might enable clearer comparisons and faster iteration across different model types.
- Hybrid systems that route tasks to the most suitable model type could become a practical deployment strategy in clinics.
- Addressing hallucination might involve combining generative models with verification steps from discriminative models.
Load-bearing premise
The 97 studies identified through database searches with dual screening form a comprehensive and unbiased sample of the literature.
What would settle it
Discovery of many additional relevant studies from 2020-2026 not captured by the searches in PubMed, Google Scholar, Scopus, and arXiv, or demonstration that models do not fit the proposed two-dimensional classification framework.
Figures


read the original abstract
Background: Oral diseases affect nearly 3.5 billion people worldwide, yet the comparative clinical potential of large-scale AI models in dentistry remains poorly understood. Three distinct model categories have emerged: language-generative models, discriminative vision foundation models, and dental-specific foundation models, with no unified review examining their relationships and collective limitations. Methods: Following PRISMA-ScR guidelines, we systematically searched four databases (PubMed, Google Scholar, Scopus, arXiv), screened independently by two reviewers. After applying inclusion/exclusion criteria, 97 studies (2020-2026) were included. We propose a two-dimensional classification framework organizing models by architectural paradigm and dental specialization degree. Results: Language-generative models excel at text-based tasks (clinical reasoning, licensing exams, patient communication) but show inconsistent performance on image-dependent diagnostics. Adapted SAM and CLIP variants achieve strong tooth segmentation and lesion detection results. Dental-specific models (DentVFM, DentVLM, OralGPT) demonstrate strongest performance on complex multimodal tasks. Integrated pipelines consistently outperform single-model approaches. A data asymmetry is observed: dental-specific pretraining concentrates almost entirely in the vision domain, reflecting scarce large-scale dental text corpora. Conclusions: General-purpose and dental-specific models play complementary roles; the most effective systems combine both within structured pipelines. Safe autonomous deployment requires resolving three persistent barriers: hallucination in generative models, limited annotated dental datasets, and absent standardized clinical evaluation benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a PRISMA-ScR scoping review that searched PubMed, Google Scholar, Scopus, and arXiv, applied dual independent screening, and included 97 studies (2020-2026) on large AI models in dentistry. It introduces a two-dimensional classification framework (architectural paradigm × dental specialization degree) to organize language-generative models, discriminative vision foundation models (e.g., adapted SAM/CLIP), and dental-specific models (DentVFM, DentVLM, OralGPT). The central claims are that general-purpose and domain-specific models are complementary, integrated pipelines outperform single models, a vision-text data asymmetry exists, and three barriers (hallucination, limited annotated datasets, absent clinical benchmarks) must be resolved for safe deployment.
Significance. If the 97-study sample proves representative and the framework reproducible, the review would usefully synthesize an emerging literature and supply a practical organizing lens for multimodal dental AI. The explicit ranking of three deployment barriers and the complementarity finding could guide both model development and regulatory discussion; the data-asymmetry observation is a concrete, falsifiable observation that future work can test.
major comments (2)
- [Methods] Methods: the description of the search strategy supplies only the four databases and the PRISMA-ScR label; no Boolean strings, date filters, or exact inclusion/exclusion criteria are reproduced. Without these, it is impossible to verify whether the 97-study corpus is unbiased or complete, directly affecting the reliability of the complementarity and barrier-ranking conclusions.
- [Results] Results / Framework: the two-dimensional taxonomy is introduced without reported inter-rater reliability for model binning, without a sensitivity analysis on alternative categorizations, and without comparison to existing AI taxonomies. The claim that dental-specific models show “strongest performance on complex multimodal tasks” therefore rests on an unvalidated partitioning whose stability is unknown.
minor comments (2)
- [Abstract / Methods] The date range “2020-2026” in the abstract and methods appears to project into the future; clarify whether this is a typographical error or an intended forward-looking inclusion rule.
- [Results] Table or figure presenting the 97 studies should include a column for the two-dimensional classification labels so readers can inspect the binning decisions.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our PRISMA-ScR scoping review. We address each major comment below, indicating planned revisions to improve transparency and reproducibility.
read point-by-point responses
-
Referee: [Methods] Methods: the description of the search strategy supplies only the four databases and the PRISMA-ScR label; no Boolean strings, date filters, or exact inclusion/exclusion criteria are reproduced. Without these, it is impossible to verify whether the 97-study corpus is unbiased or complete, directly affecting the reliability of the complementarity and barrier-ranking conclusions.
Authors: We agree that the Methods section requires greater specificity for full reproducibility. The current text summarizes the approach at a high level to meet journal constraints, but the full Boolean strings, date filters (2020-2026), and exact inclusion/exclusion criteria were applied during screening by two independent reviewers. In the revised manuscript we will expand the Methods section (or add a supplementary table) to reproduce these details verbatim. This will allow direct verification of corpus selection and strengthen confidence in the synthesized findings on model complementarity and barriers. revision: yes
-
Referee: [Results] Results / Framework: the two-dimensional taxonomy is introduced without reported inter-rater reliability for model binning, without a sensitivity analysis on alternative categorizations, and without comparison to existing AI taxonomies. The claim that dental-specific models show “strongest performance on complex multimodal tasks” therefore rests on an unvalidated partitioning whose stability is unknown.
Authors: The two-dimensional framework (architectural paradigm × dental specialization degree) is offered as a novel descriptive lens derived directly from patterns in the 97 included studies, with explicit categorization rules stated in the Methods. Because the binning was performed by the author team rather than as an independent multi-rater annotation task, inter-rater reliability statistics were not computed. We will revise the manuscript to (1) add an explicit comparison to prior AI taxonomies in the Discussion and (2) elaborate the categorization criteria for greater transparency. A post-hoc sensitivity analysis on alternative partitions is not feasible without re-screening all studies and would not change the primary descriptive observations; we will instead qualify the framework as exploratory and note this as a limitation. The performance statements are aggregated from the primary studies’ own reported results and will be rephrased to reflect this source. revision: partial
Circularity Check
No circularity: scoping review synthesizes external literature
full rationale
This scoping review follows PRISMA-ScR to identify and classify 97 external studies from 2020-2026. The proposed two-dimensional framework (architectural paradigm × specialization degree) is an organizational taxonomy, not a derivation that reduces to fitted inputs or self-definitions. Central claims about model complementarity and three barriers are synthesized from the reviewed papers rather than generated by internal equations, predictions, or self-citation chains. No load-bearing step equates outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math PRISMA-ScR guidelines constitute an appropriate and sufficient standard for conducting and reporting scoping reviews in health sciences.
Reference graph
Works this paper leans on
-
[1]
rep., World Health Organization, Geneva (2022)
World Health Organization, Global oral health status report: Towards universal health coverage for oral health by 2030, Tech. rep., World Health Organization, Geneva (2022). URLhttps://www.who.int/publications/i/item/9789240061484
arXiv 2030
-
[2]
S. Lee, S. I. Oh, J. Jo, S. Kang, Y. Shin, J. W. Park, Deep learning for early dental caries detection in bitewing radiographs, Scientific Reports 11 (1) (2021) 16807.doi:10.1038/s41598-021-96368-7
-
[3]
Virupaiah, A
G. Virupaiah, A. Sathyanarayana, Analysis of image enhancement techniques for dental caries detection using texture analysis and sup- port vector machine, International Journal of Applied Science and En- gineering 17 (2020) 75–86. URLhttps://api.semanticscholar.org/CorpusID:231800088 48
2020
-
[4]
N. Bashir, Z. Ur Rahman, S. Chen, Systematic comparison of ma- chine learning algorithms to develop and validate predictive models for periodontitis, Journal of Clinical Periodontology 49 (07 2022). doi:10.1111/jcpe.13692
-
[5]
D. V. Tuzoff, et al., Tooth detection and numbering in panoramic ra- diographs using convolutional neural networks, Dento Maxillofacial Ra- diology 48 (4) (2019) 20180051.doi:10.1259/dmfr.20180051
-
[6]
C.-W. Li, et al., Detection of dental apical lesions using cnns on periapi- cal radiograph, Sensors 21 (21) (2021) 7049.doi:10.3390/s21217049
-
[7]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, I. Polosukhin, Attention is all you need, Advances in Neural Information Processing Systems 30 (2017)
2017
-
[8]
Brown, B
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhari- wal, A. Neelakantan, et al., Language models are few-shot learners, Advances in Neural Information Processing Systems 33 (2020) 1877– 1901
2020
-
[9]
F. Fanelli, M. Saleh, P. Santamaria, K. Zhurakivska, L. Nibali, G. Troiano, Development and comparative evaluation of a reinstructed gpt-4o model specialized in periodontology, Journal of Clinical Peri- odontology 52 (5) (2025) 707–716.doi:10.1111/jcpe.14101
- [10]
-
[11]
URLhttps://doi.org/10.1007/s11760-025-04208-2
J.Zhang, M.Lin, H.Hou, B.Sun, F.Hu, Y.Yu, M.Li, Easam: anedge- aware sam-based paradigm for tooth segmentation, Signal, Image and Video Processing 19 (2025) 673.doi:10.1007/s11760-025-04208-2. URLhttps://doi.org/10.1007/s11760-025-04208-2
-
[12]
Z. Meng, J. Hao, X. Dai, Y. Feng, J. Liu, B. Feng, et al., Dentvlm: A multimodal vision-language model for comprehensive dental diagnosis andenhancedclinicalpractice, arXivpreprintarXiv:2509.23344(2025). 49
arXiv 2025
- [13]
-
[14]
M. J. Page, et al., The prisma 2020 statement: an updated guideline for reporting systematic reviews, BMJ 372 (2021) n71.doi:10.1136/ bmj.n71
2020
-
[15]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, N. Houlsby, et al., An image is worth 16x16 words: Transformers for image recognition at scale, arXiv preprint arXiv:2010.11929 (2020)
Pith/arXiv arXiv 2010
-
[16]
H. Liu, C. Li, Q. Wu, Y. J. Lee, Visual instruction tuning, Advances in neural information processing systems 36 (2023) 34892–34916
2023
-
[17]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford, et al., Gpt-4o system card, arXiv preprint arXiv:2410.21276 (2024)
Pith/arXiv arXiv 2024
-
[18]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, I. Sutskever, Learning transferable visual models from natural language supervision, in: M. Meila, T. Zhang (Eds.), Proceedings of the 38th International Conference on Machine Learning, Vol. 139 of Proceedings of Machine Learning Resea...
2021
-
[19]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, P. Dollár, R. Girshick, Segment anything, Proceedings of the IEEE/CVF International Con- ference on Computer Vision (ICCV) (2023) 3992–4003doi:10.1109/ ICCV51070.2023.00371
arXiv 2023
-
[20]
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, others, L. Zhang, Grounding dino: Marrying dino with grounded pre-training for open- set object detection, in: European Conference on Computer Vision, Springer Nature Switzerland, 2024, pp. 38–55
2024
-
[21]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al., Chain-of-thought prompting elicits reasoning in large 50 language models, Advances in neural information processing systems 35 (2022) 24824–24837
2022
-
[22]
Lewis, E
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, et al., Retrieval- augmented generation for knowledge-intensive nlp tasks, Advances in neural information processing systems 33 (2020) 9459–9474
2020
-
[23]
Houlsby, A
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Larous- silhe, A. Gesmundo, M. Attariyan, S. Gelly, Parameter-efficient trans- fer learning for nlp, in: International conference on machine learning, PMLR, 2019, pp. 2790–2799
2019
-
[24]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, W. Chen, et al., Lora: Low-rank adaptation of large language models., Iclr 1 (2) (2022) 3
2022
-
[25]
P. Wang, H. Gu, Y. Sun, Tooth segmentation on multimodal images using adapted segment anything model, Scientific Reports 15 (2025) 13874.doi:10.1038/s41598-025-96301-2
-
[26]
K. He, X. Chen, S. Xie, Y. Li, P. Dollár, R. Girshick, Masked autoen- coders are scalable vision learners, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 16000–16009
2022
-
[27]
Ouyang, J
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al., Training language models to follow instructions with human feedback, Advances in neural information processing systems 35 (2022) 27730–27744
2022
-
[28]
S. Tomo, J. R. Lechien, H. S. Bueno, D. F. Cantieri-Debortoli, L. E. Simonato, Accuracy and consistency of chatgpt-3.5 and -4 in providing differential diagnoses in oral and maxillofacial diseases: a comparative diagnostic performance analysis, Clinical Oral Investigations 28 (10) (2024) 544.doi:10.1007/s00784-024-05939-1
-
[29]
A. Suárez, Y. Freire, M. Suárez, V. Díaz-Flores García, C. Andreu- Vázquez, I. J. Thuissard Vasallo, A. I. Castillo Varón, C. Martín, Diagnostic performance of multimodal large language models in the 51 analysis of oral pathology, Oral Diseases 31 (12) (2025) 3344–3354. doi:10.1111/odi.70009
-
[30]
P. Rewthamrongsris, J. Burapacheep, E. Phattarataratip, P. Kulthanaamondhita, A. Tichy, F. Schwendicke, T. Osathanon, K. Sappayatosok, Image-based diagnostic performance of llms vs cnns for oral lichen planus: Example-guided and differential diagnosis, International Dental Journal 75 (4) (2025) 100848. doi:10.1016/j.identj.2025.100848
-
[31]
D. P. Bubna, N. H. R. Mattos, L. B. D. P. Luiz, F. Baratto-Filho, M. T. Mattos-Calil, Y. T. C. Silva-Sousa, E. C. Küchler, Â. G. D. Schroder, C. M. Araujo, B. M. M. Araujo, Can large language models detect periapical lesions in anterior teeth? a comparative study, Brazilian Dental Journal 36 (2026) e256861.doi:10.1590/0103-644020256861
-
[32]
M. Büker, M. Sümbüllü, H. Arslan, Comparative performance of chat- bots in endodontic clinical decision support: A 4-day accuracy and consistency study, International Dental Journal 75 (5) (2025) 100920. doi:10.1016/j.identj.2025.100920
-
[33]
Y. Özbay, D. Erdoğan, G. A. Dinçer, Evaluation of the performance of large language models in clinical decision-making in endodontics, BMC Oral Health 25 (2025) 648.doi:10.1186/s12903-025-06050-x
-
[34]
L. P. de Araújo, L. B. Moreno, B. C. C. de Araújo, E. T. Chaves, T. M. Botero, V. H. D. Romero, From evidence-based endodontics to generative ai: A comparative study of 11 large language models, Journal of Endodontics (2026) S0099–2399(26)00010–5Advance online publication.doi:10.1016/j.joen.2026.01.009
-
[35]
A. Qutieshat, A. Al Rusheidi, S. Al Ghammari, A. Alarabi, A. Salem, M. Zelihic, Comparative analysis of diagnostic accuracy in endodontic assessments: dental students vs. artificial intelligence, Diagnosis 11 (3) (2024) 259–265.doi:10.1515/dx-2024-0034
-
[36]
I. Amador Barbosa, M. Sergio Almeida Alves, P. Rayse Zagalo de Almeida, P. de Almeida Rodrigues, R. Pimentel de Oliveira, S. Au- gusto Fernades de Menezes, J. D. Mendonça de Moura, R. Roberto de Souza Fonseca, Assessing the diagnostic and treatment accuracy of 52 large language models (llms) in peri-implant diseases: A clinical ex- perimental study, Journ...
-
[37]
G. S. Chatzopoulos, V. P. Koidou, L. Tsalikis, E. G. Kaklamanos, Large language models in periodontology: Assessing their performance in clinically relevant questions, The Journal of Prosthetic Dentistry 134 (6) (2025) 2328–2336.doi:10.1016/j.prosdent.2024.10.020
-
[38]
E. M. Aşar, İ. İpek, K. Bilge, Customized gpt-4v(ision) for ra- diographic diagnosis: can large language model detect supernumer- ary teeth?, BMC Oral Health 25 (1) (2025) 756.doi:10.1186/ s12903-025-06163-3
2025
-
[39]
M. G. Kanmaz, G. Agani Sabah, Diagnostic accuracy of large language models in the classification of superior labial frenulum attachments, Odontology (2025).doi:10.1007/s10266-025-01283-2
-
[40]
B. Sezer, T. Aydoğdu, Performance of advanced artificial intelligence models in traumatic dental injuries in primary dentition: A compar- ative evaluation of chatgpt-4 omni, deepseek, gemini advanced, and claude 3.7 in terms of accuracy, completeness, response time, and read- ability, Applied Sciences 15 (14) (2025).doi:10.3390/app15147778. URLhttps://www...
-
[41]
Küçük Keleş, Z
Ö. Küçük Keleş, Z. B. Arslan, Performance of artificial intelligence chatbots in the diagnosis and management of simulated dental trauma cases: an evaluation based on iadt guidelines, Clinical Oral Investi- gationsPublished online: 23 December 2025 (2026).doi:10.1007/ s00784-025-06716-4
2025
-
[42]
Termteerapornpimol, S
K. Termteerapornpimol, S. Kulvitit, S. Prommanee, Z. Khurshid, T. Porntaveetus, Comparative benchmark of seven large language models for traumatic dental injury knowledge, European Jour- nal of DentistryAdvance online publication (2025).doi:10.1055/ s-0045-1812064
2025
-
[43]
X. Wu, G. Cai, B. Guo, L. Ma, S. Shao, J. Yu, Y. Zheng, L. Wang, F. Yang, A multi-dimensional performance evaluation of large language models in dental implantology: comparison of chatgpt, deepseek, grok, 53 gemini and qwen across diverse clinical scenarios, BMC Oral Health 25 (1) (2025) 1272.doi:10.1186/s12903-025-06619-6. URLhttps://doi.org/10.1186/s129...
-
[44]
Y. Wu, Y. Zhang, M. Xu, C. Jinzhi, Y. Xue, Y. Zheng, Effectiveness of various general large language models in clinical consensus and case analysis in dental implantology: A comparative study, BMC Medical Informatics and Decision Making 25 (1) (2025) 147.doi:10.1186/ s12911-025-02972-2. URLhttps://doi.org/10.1186/s12911-025-02972-2
-
[45]
Y. Mine, T. Taji, S. Takeda, S. Okazaki, T. Y. Peng, N. Kakimoto, T. Murayama, Assessing multimodal large language models for lo- calizing dental implant fixtures on panoramic radiographs, Journal of Dentistry 168 (2026) 106580, advance online publication.doi: 10.1016/j.jdent.2026.106580. URLhttps://doi.org/10.1016/j.jdent.2026.106580
-
[46]
M. B. Erden, M. G. Kanmaz, G. A. Sabah, Can chatbots re- place experts? diagnostic accuracy of ai models in classifying im- pacted mandibular third molars, OdontologyAdvance online publica- tion (2025).doi:10.1007/s10266-025-01214-1. URLhttps://doi.org/10.1007/s10266-025-01214-1
-
[47]
K. Ji, Z. Wu, J. Han, G. Zhai, J. Liu, Evaluating chatgpt-4’s per- formance on oral and maxillofacial queries: Chain of thought and standard method, Frontiers in Oral Health 6 (2025) 1541976.doi: 10.3389/froh.2025.1541976. URLhttps://doi.org/10.3389/froh.2025.1541976
-
[48]
O. B. Kandaz, T. Teksoz, C. Avlayici, et al., Using ai large language models to assess dental history in systemic conditions, Discover Artifi- cial Intelligence 6 (2026) 103.doi:10.1007/s44163-025-00816-6
-
[49]
S. Tayeb, C. Barausse, G. Pellegrino, M. Sansavini, R. Pistilli, P. Fe- lice, Comparing artificial intelligence (chatgpt, gemini, deepseek) and oral surgeons in detecting clinically relevant drug–drug interactions in dental therapy, Applied Sciences 15 (23) (2025) 12851.doi: 10.3390/app152312851. 54
-
[50]
P. Rewthamrongsris, V. Thongchotchat, J. Burapacheep, V. Tra- choo, Z. Khurshid, T. Porntaveetus, Evaluating retrieval-augmented generation-large language models for infective endocarditis prophy- laxis: Clinical accuracy and efficiency, International Dental Journal 76 (1) (2026) 109344.doi:10.1016/j.identj.2025.109344
-
[51]
B. Tosun, Z. Öztürk, Performance of five large language models in managing acute dental pain: A comprehensive analysis, Turk Endod J 10 (1) (2025) 39–49, doi: 10.14744/TEJ.2025.27147.arXiv:https:// dx.doi.org/10.14744/TEJ.2025.27147,doi:10.14744/TEJ.2025. 27147. URLhttps://dx.doi.org/10.14744/TEJ.2025.27147
-
[52]
M. Shirani, M. Emami, Performance comparison of large language models in treatment planning for the restoration of endodontically treated teeth over time, Journal of Dentistry 161 (2025) 105998. doi:10.1016/j.jdent.2025.105998
-
[53]
E. S. Song, G. H. Kim, S.-P. Lee, Evaluation of gpt-4o and gemini ad- vanced on the korean national dental licensing examination: Accuracy, consistency, and question generation, Journal of Dental Sciences 21 (1) (2026) 96–102.doi:10.1016/j.jds.2025.07.020
-
[54]
M. Dashti, S. Ghasemi, N. Ghadimi, D. Hefzi, A. Karimian, N. Zare, A. Fahimipour, Z. Khurshid, M. M. Chafjiri, S. Ghaedsharaf, Perfor- mance of chatgpt 3.5 and 4 on u.s. dental examinations: the inbde, adat, and dat, Imaging science in dentistry 54 (3) (2024) 271–275. doi:10.5624/isd.20240037
-
[55]
H. C. Nguyen, H. P. Dang, T. L. Nguyen, V. Hoang, V. A. Nguyen, Accuracy of latest large language models in answering multiple choice questions in dentistry: A comparative study, PLOS ONE 20 (1) (2025) e0317423.doi:10.1371/journal.pone.0317423
-
[56]
C. C.-C. Lin, J.-S. Sun, C.-H. Chang, Y.-H. Chang, J. Z.-C. Chang, Performance of artificial intelligence chatbots in national dental licens- ing examination, Journal of Dental Sciences 20 (4) (2025) 2307–2314. doi:10.1016/j.jds.2025.05.012. 55
-
[57]
Y. Mine, S. Okazaki, T. Taji, H. Kawaguchi, N. Kakimoto, T. Mu- rayama, Benchmarking multimodal large language models on the den- tal licensing examination: Challenges with clinical image interpre- tation, Journal of Dental Sciences 20 (4) (2025) 2427–2435.doi: 10.1016/j.jds.2025.03.018
-
[58]
H. Watanabe, O. Uehara, T. Morikawa, T. Kojima, T. Suga, A. Toyofuku, S. Takada, Y. Abiko, Performance of large language models on image-based oral pathology questions from the japanese national dental examination, Journal of Dental Sciences (2025). doi:10.1016/j.jds.2025.08.037. URLhttps://www.sciencedirect.com/science/article/pii/ S1991790225003113
-
[59]
M. B. Dundar Sari, B. Sezer, Comparative performance evaluation of chatgpt-4 omni and gemini advanced in the turkish dentistry special- ization exam, BMC Medical Education 26 (2026) 251.doi:10.1186/ s12909-026-08621-0. URLhttps://doi.org/10.1186/s12909-026-08621-0
-
[60]
M. Haberal, D. Hançerlioğulları, Can artificial intelligence chatbots think like dentists? a comparative analysis based on dental specialty examinationquestionsinrestorativedentistry, BMCOralHealth26(1) (2026) 231.doi:10.1186/s12903-025-07612-9. URLhttps://doi.org/10.1186/s12903-025-07612-9
-
[61]
B. E. Yilmaz, B. N. Gokkurt Yilmaz, F. Ozbey, Artificial intelligence performance in answering multiple-choice oral pathology questions: a comparative analysis, BMC Oral Health 25 (1) (2025) 573.doi:10. 1186/s12903-025-05926-2. URLhttps://doi.org/10.1186/s12903-025-05926-2
-
[62]
B. Çakmak, T. Sökmen, B. Baloş Tuncer, Artificial intelligence- powered chatbots’ responses to orthodontic questions from the den- tistry specialization examination: Accuracy and source evaluation, Journal of Dental Sciences (2025).doi:10.1016/j.jds.2025.11.027. URLhttps://doi.org/10.1016/j.jds.2025.11.027
-
[63]
M. Tassoker, Chatgpt-4 omni’s superiority in answering multiple-choice 56 oral radiology questions, BMC Oral Health 25 (1) (2025) 173.doi: 10.1186/s12903-025-05554-w
-
[64]
Y.-H. Wu, K.-Y. Tso, C.-P. Chiang, Performance of chatgpt in an- swering the oral pathology questions of various types or subjects from taiwan national dental licensing examinations, Journal of Dental Sci- ences 20 (3) (2025) 1709–1715.doi:10.1016/j.jds.2025.03.030
-
[65]
Akkoca, M
F. Akkoca, M. Özdede, G. İlhan, E. Koyuncu, H. Ellidokuz, Assessing the success of chatgpt-4o in oral radiology education and practice: A pioneering research, Cumhuriyet Dental Journal 28 (2) (2025) 210–215
2025
-
[66]
C.-Y. Huang, Y.-P. Lee, A. Sun, C.-P. Chiang, Performance of chatgpt- 4, gemini, and deepseek-v3 on answering the multiple choice questions fromtaiwannationaldentaltechnicianlicensingexaminationsandtheir self-learning abilities over a three-week period, Journal of Dental Sci- ences 20 (4) (2025) 2154–2162.doi:10.1016/j.jds.2025.07.011
-
[67]
H. Fukuda, M. Morishita, K. Muraoka, S. Yamaguchi, T. Nakamura, M. Habu, I. Yoshioka, S. Awano, K. Ono, Evaluating the accuracy and performance of chatgpt-4o in solving japanese national dental techni- cian examination, International Dental Journal 75 (4) (2025) 100847. doi:10.1016/j.identj.2025.100847
-
[68]
S. Sismanoglu, B. S. Capan, Performance of artificial intelligence on turkish dental specialization exam: can chatgpt-4.0 and gemini ad- vanced achieve comparable results to humans?, BMC Medical Educa- tion 25 (1) (2025) 214.doi:10.1186/s12909-024-06389-9
-
[69]
H. Alqahtani, Assessment of artificial intelligence chatbots in respond- ing to dental occlusion questions: a comparative study, BMC Oral Health 26 (1) (2025) 201.doi:10.1186/s12903-025-07573-z
-
[70]
E. Arılı Öztürk, C. Turan Gökduman, B. C. Çanakçi, Evaluation of the performance of chatgpt-4 and chatgpt-4o as a learning tool in en- dodontics, International Endodontic JournalAdvance online publica- tion (2025).doi:10.1111/iej.14217
-
[71]
P. M. Durmazpinar, E. Ekmekci, Comparing diagnostic skills in en- dodontic cases: dental students versus chatgpt-4o, BMC Oral Health 25 (1) (2025) 457.doi:10.1186/s12903-025-05857-y. 57
-
[72]
A. A. Azhari, W. M. Ahmed, A. Alhamadani, A. Alfaraj, M. Zhang, C. T. Lu, Assessing the efficacy of artificial intelligence platforms in answeringdentalcariesmultiple-choicequestions: Acomparativestudy of chatgpt and google gemini language models, Dentistry Journal 14 (2) (2026) 72.doi:10.3390/dj14020072
-
[73]
M. Llorente de Pedro, A. Suárez, J. Algar, V. Díaz-Flores García, C. Andreu-Vázquez, Y. Freire, Assessing chatgpt’s reliability in en- dodontics: Implications for ai-enhanced clinical learning, Applied Sci- ences 15 (10) (2025) 5231.doi:10.3390/app15105231
-
[74]
Ö. Kurt, E. Şimsek, Knowledge-level comparison in pulpal and pe- riapical diseases: dental students versus artificial intelligence models (gemini, microsoft copilot, chatgpt-3.5, chatgpt-4o): cross-sectional study, BMC Medical Education 25 (1) (2025) 1657.doi:10.1186/ s12909-025-08263-8
2025
-
[75]
H. Sağlam, G. P. Sezgin, T. Kaplan, S. S. Kaplan, Artificial intelligence chatbots versus dentists: a comparative knowledge assessment on trau- matic dental injury management, BMC Oral Health 26 (1) (2026) 313. doi:10.1186/s12903-026-07728-6
-
[76]
H. E. Kuru, A. Aşık, D. M. Demir, Can artificial intelligence language models effectively address dental trauma questions?, Dental Trauma- tology 41 (5) (2025) 567–580.doi:10.1111/edt.13063
-
[77]
P. Rodrigues-Pereira, M. A. P. Dias-Calças, A. Moreira Mélo, M. O. Melchior, L. Gaspar Ribeiro, A. Pazin-Filho, J. F. Mazzi-Chaves, L. V. Magri, Generative artificial intelligence-driven clinical case simulation in temporomandibular disorder education: Chatgpt versus real pa- tients, Journal of Dental EducationAdvance online publication (2025). doi:10.100...
-
[78]
M. Brondani, C. Alves, C. Ribeiro, M. M. Braga, R. C. M. Gar- cia, T. Ardenghi, K. Pattanaporn, Artificial intelligence, chatgpt, and dental education: Implications for reflective assignments and qualita- tive research, Journal of Dental Education 88 (12) (2024) 1671–1680. doi:10.1002/jdd.13663. 58
-
[79]
A. Dermata, A. Arhakis, M. A. Makrygiannakis, K. Giannakopoulos, E. G. Kaklamanos, Evaluating the evidence-based potential of six large language models in paediatric dentistry: a comparative study on gener- ative artificial intelligence, European Archives of Paediatric Dentistry 26 (3) (2025) 527–535.doi:10.1007/s40368-025-01012-x
-
[80]
Z. Hakami, S. A. K. Saheb, O. A. Bawazeer, Orthodontic knowledge assessment: A comparison of five ai chatbots, Saudi Dental Journal 38 (2026) 20.doi:10.1007/s44445-025-00091-2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.