Echelon: Auditable Aggregate-Only Language-Model Adaptation Across Privacy Boundaries
Pith reviewed 2026-06-28 13:36 UTC · model grok-4.3
The pith
Echelon enables language-model adaptation across privacy boundaries by exchanging only aggregated boundary deltas.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
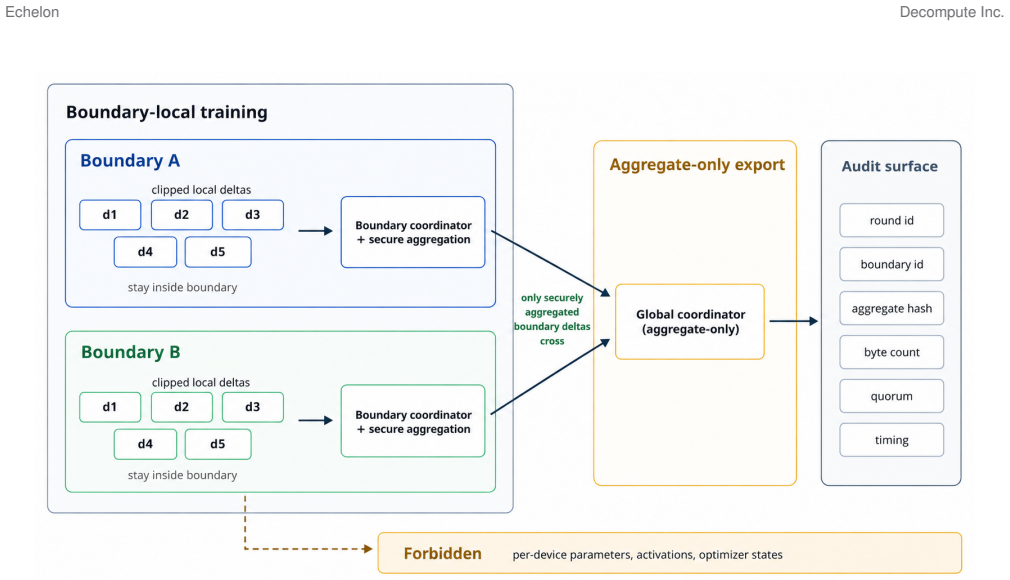
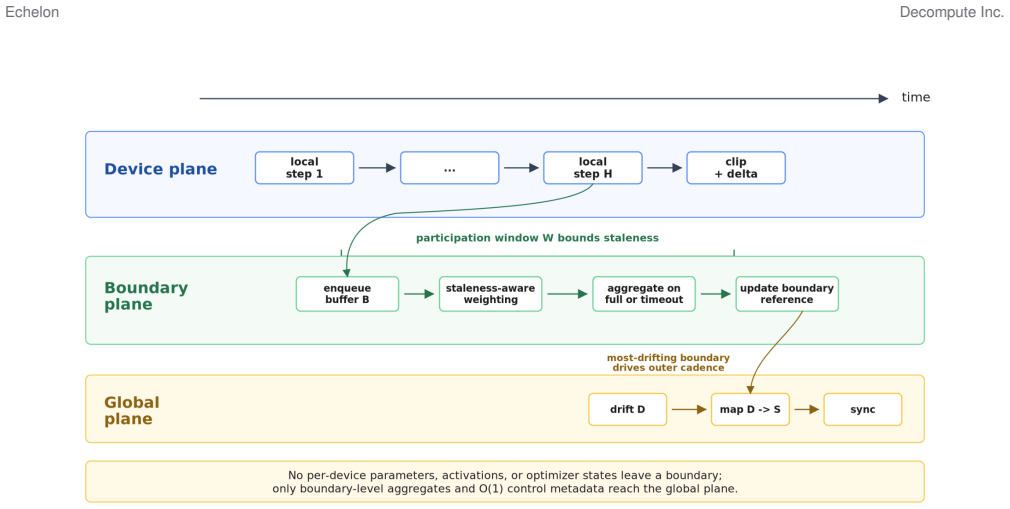
By restricting all cross-boundary communication to aggregates of boundary-level deltas, Echelon maintains optimization stability under WAN delay, heterogeneous participation, churn, and non-IID data distributions without ever exposing per-device updates to the global plane.
What carries the argument
Buffered semi-asynchronous secure aggregation combined with staleness-aware weighting, participation windows, proximal local objectives, and a drift-aware outer synchronization controller.
If this is right
- The approach supplies a concrete, auditable surface consisting solely of boundary aggregates.
- It sustains over 2100 tokens per second throughput in OpenWebText stress tests across WAN and non-IID conditions.
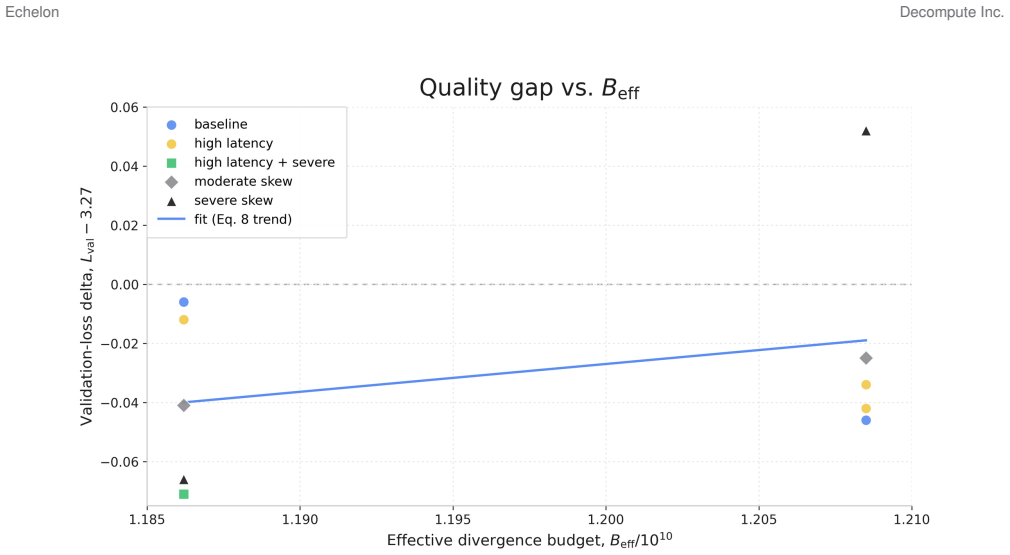
- Quality loss stays at most 2.2 percent under 200 ms emulated latency or severe non-IID partitioning.
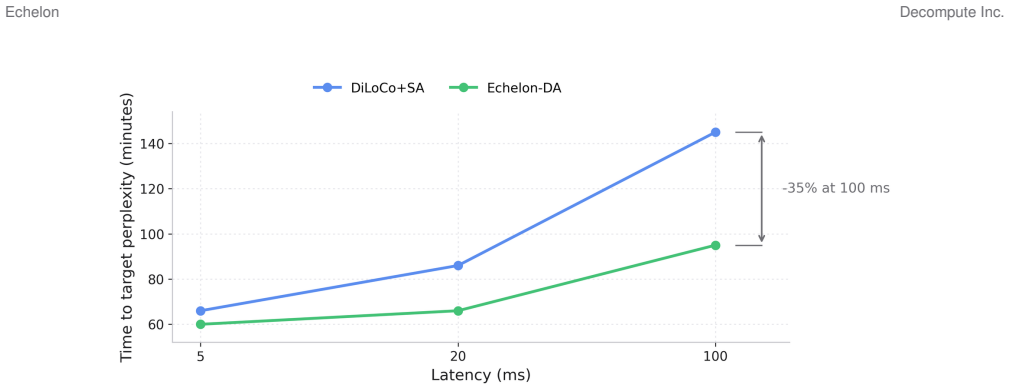
- Echelon-DA improves time-to-target relative to a privacy-parity DiLoCo plus secure-aggregation baseline under WAN latency.
Where Pith is reading between the lines
- The same aggregate-only controller could be tested on three or more boundaries to check whether drift correction continues to scale.
- The stability mechanisms may transfer to other distributed training settings that face similar export restrictions.
- Running the identical token budget on a larger base model would show whether the reported loss and throughput figures generalize beyond the 1B LoRA case.
Load-bearing premise
That the global optimizer can still converge when it receives only boundary aggregates rather than individual device updates, even under network delays and non-identical data.
What would settle it
A head-to-head run in which a baseline allowed to exchange per-device updates under identical token and byte budgets reaches materially lower validation loss or faster convergence than Echelon.
Figures

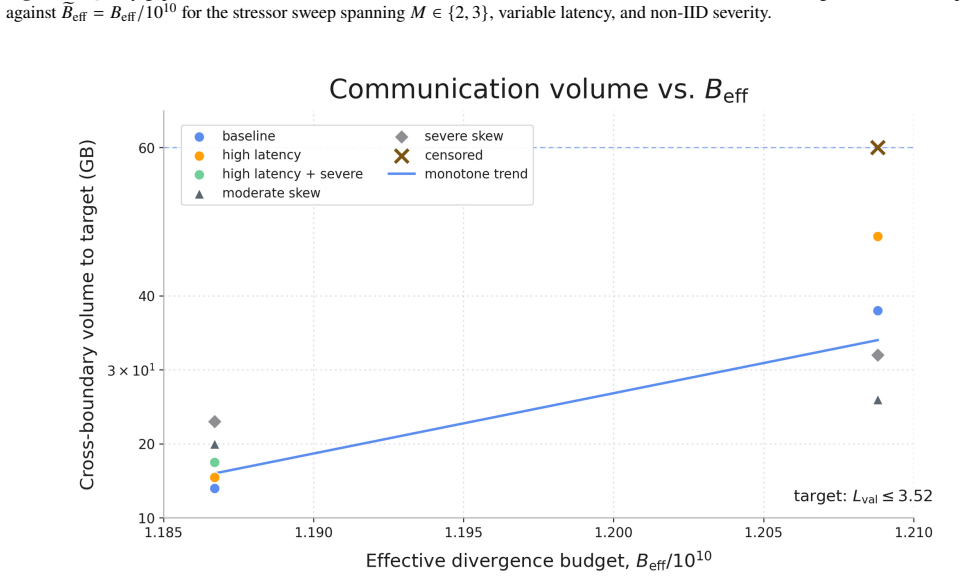


read the original abstract
Cross-organization language-model adaptation increasingly faces hard governance constraints: in many deployments, device-level model state-parameters, activations, optimizer state, and per-device updates-cannot be exported outside an administrative boundary. Existing distributed and federated stacks typically assume cross-site model exchange and then retrofit privacy mechanisms, which complicates compliance and makes auditing brittle. We present Echelon, a boundary-first training architecture that enforces device-level model-state non-export as a systems invariant. Devices train locally inside each boundary; the only cross-boundary payloads are securely aggregated boundary-level deltas plus O(1) coordination metadata, exposed through a concrete audit surface. Restricting exchange to aggregates changes the optimization problem: the system must remain stable under WAN delay, heterogeneous participation, churn, and non-IID data even though the global plane never sees per-device updates. Echelon combines buffered semi-asynchronous secure aggregation, staleness-aware weighting, participation windows, proximal local objectives, and a drift-aware outer synchronization controller. In 1B-parameter LoRA adaptation across M= 2 boundaries, a budget-matched contest over three seeds (24.88M tokens) reaches validation loss 3.887 +/-0.010 and is best or tied-best among tuned low-communication baselines under fixed-token, fixed-bytes, fixed-wall-clock, and fixed-sync-count budgets. In OpenWebText stress tests, Echelon sustains 2,139-2,176 tokens/s across evaluated WAN and non-IID treatments, Echelon-DA improves time-to-target under WAN latency relative to a privacy-parityDiLoCo+SA baseline, and quality degrades by at most 2.2% under 200ms emulated latency or severe non-IID partitioning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Echelon, a boundary-first architecture for cross-organization language-model adaptation that enforces non-export of per-device model state, optimizer state, and updates as an invariant. Only securely aggregated boundary-level deltas and O(1) metadata cross boundaries; the design combines buffered semi-asynchronous secure aggregation, staleness-aware weighting, participation windows, proximal objectives, and a drift-aware controller. Empirical results for 1B-parameter LoRA adaptation across M=2 boundaries show a validation loss of 3.887 +/-0.010 over three seeds (24.88M tokens) that is best or tied-best under four fixed budgets, with throughput of 2,139-2,176 tokens/s and at most 2.2% quality degradation under emulated WAN latency or severe non-IID partitioning.
Significance. If the stability claims hold, the work supplies a concrete systems approach to auditable aggregate-only adaptation under governance constraints that existing federated stacks do not satisfy by construction. The budget-matched contest and reported throughput numbers under WAN and non-IID treatments provide reproducible evidence of competitiveness against low-communication baselines.
major comments (2)
- [Abstract] Abstract: the central claim that 'restricting exchange to aggregates changes the optimization problem' such that the system 'must remain stable under WAN delay, heterogeneous participation, churn, and non-IID data' is load-bearing for extrapolating the 3.887 loss and budget-competitiveness results to realistic multi-boundary deployments, yet the reported experiments supply metrics and ablations only for emulated WAN latency and severe non-IID partitioning (max 2.2% drop) with no corresponding results, stress-test descriptions, or participation-rate ablations for device churn or heterogeneous participation.
- [Experiments] Experiments section (budget-matched contest): the claim that Echelon is 'best or tied-best among tuned low-communication baselines' under fixed-token, fixed-bytes, fixed-wall-clock, and fixed-sync-count budgets rests on the 3.887 +/-0.010 result, but the manuscript provides no details on baseline hyperparameter tuning methodology, data partitioning procedure, or statistical significance testing, which prevents independent verification that the reported ranking is robust rather than an artifact of untuned comparators.
minor comments (2)
- [Abstract] The abstract and introduction use the phrase 'O(1) coordination metadata' without specifying the exact metadata fields or their bit-width; a concrete enumeration would improve audit-surface clarity.
- [Figures] Figure captions for the throughput and degradation plots should explicitly state the number of independent runs and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and recommendation for major revision. Below we respond point-by-point to the major comments, proposing targeted revisions for clarity and reproducibility while preserving the manuscript's core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'restricting exchange to aggregates changes the optimization problem' such that the system 'must remain stable under WAN delay, heterogeneous participation, churn, and non-IID data' is load-bearing for extrapolating the 3.887 loss and budget-competitiveness results to realistic multi-boundary deployments, yet the reported experiments supply metrics and ablations only for emulated WAN latency and severe non-IID partitioning (max 2.2% drop) with no corresponding results, stress-test descriptions, or participation-rate ablations for device churn or heterogeneous participation.
Authors: We agree the abstract's stability claim is broader than the reported experiments. The OpenWebText stress tests evaluate emulated WAN latency and severe non-IID partitioning (at most 2.2% degradation), while the mechanisms (buffered semi-asynchronous secure aggregation, staleness-aware weighting, participation windows, proximal objectives, drift-aware controller) are explicitly designed to address heterogeneous participation and churn. We will revise the abstract to more precisely scope the empirical claims to the evaluated conditions and add a short discussion paragraph explaining how the design invariants target the untested factors without claiming new experimental coverage. revision: yes
-
Referee: [Experiments] Experiments section (budget-matched contest): the claim that Echelon is 'best or tied-best among tuned low-communication baselines' under fixed-token, fixed-bytes, fixed-wall-clock, and fixed-sync-count budgets rests on the 3.887 +/-0.010 result, but the manuscript provides no details on baseline hyperparameter tuning methodology, data partitioning procedure, or statistical significance testing, which prevents independent verification that the reported ranking is robust rather than an artifact of untuned comparators.
Authors: We accept that these methodological details are required for verification. The +/-0.010 reflects standard deviation across three random seeds. We will add an appendix subsection that specifies: (i) the hyperparameter ranges and search procedure applied to each baseline, (ii) the exact procedure used to induce non-IID partitioning across the two boundaries, and (iii) confirmation that no formal statistical significance tests beyond seed-wise mean and deviation were performed. revision: yes
Circularity Check
No significant circularity: empirical systems architecture with no derivations or fitted predictions
full rationale
The manuscript describes a boundary-first training architecture and reports empirical results from 1B-parameter LoRA experiments under fixed budgets. No equations, parameter-fitting procedures, uniqueness theorems, or ansatzes are presented that could reduce a claimed prediction or result to its own inputs by construction. The stability requirement under WAN delay, churn, and non-IID data is stated as a changed optimization problem but is not derived mathematically; it is addressed through described mechanisms whose effectiveness is evaluated experimentally. All load-bearing claims rest on measured validation loss and throughput numbers rather than self-referential definitions or self-citations that close a loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. Arcas. Communication-efficient learning of deep networks from decentralized data.AISTATS, 2017
2017
- [2]
-
[3]
S. P. Karimireddy, S. Kale, M. Mohri, S. Reddi, S. Stich, and A. T. Suresh. SCAFFOLD: Stochastic controlled averaging for federated learning.ICML, 2020
2020
-
[4]
Bonawitz, V
K. Bonawitz, V. Ivanov, B. Kreuter, et al. Practical secure aggregation for privacy-preserving machine learning.CCS, 2017
2017
-
[5]
X. Lian, H. Zhang, C. Zhang, and J. Liu. Asynchronous parallel stochastic gradient for nonconvex optimization.NeurIPS, 2015
2015
-
[6]
Rajbhandari, J
S. Rajbhandari, J. Rasley, O. Ruwase, and Y. He. ZeRO: Memory optimizations toward training trillion parameter models.SC, 2020
2020
-
[7]
Rasley, S
J. Rasley, S. Rajbhandari, O. Ruwase, and Y. He. DeepSpeed: System optimizations enable training deep learning models with over 100 billion parameters.KDD, 2020
2020
-
[8]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
M. Shoeybi, M. Patwary, R. Puri, et al. Megatron-LM: Training multi-billion parameter language models using model parallelism. arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[9]
Allen-Zhu, Y.Li, S.Wang, L.Wang, andW.Chen.LoRA:Low-rankadaptationoflargelanguagemodels
E.J.Hu, Y.Shen, P.Wallis, Z. Allen-Zhu, Y.Li, S.Wang, L.Wang, andW.Chen.LoRA:Low-rankadaptationoflargelanguagemodels. ICLR, 2022
2022
-
[10]
A. Douillard, Q. Feng, A. A. Rusu, R. Chhaparia, Y. Donchev, A. Kuncoro, M.-A. Ranzato, A. Szlam, and J. Shen. DiLoCo: Distributed low-communication training of language models. arXiv:2311.08105, 2023
-
[11]
S. Jaghouar, S. Boreiko, J. de la Cruz, N. Tong, and T. Dao. OpenDiLoCo: An open-source framework for globally distributed low-communication training. arXiv:2407.07852, 2024
-
[12]
A. Douillard, Y. Donchev, K. Rush, S. Kale, Z. Charles, Z. Garrett, G. Teston, D. Lacey, R. McIlroy, J. Shen, A. Rame, A. Szlam, M.-A. Ranzato, and P. Barham. Streaming DiLoCo with overlapping communication: Towards a distributed free lunch. arXiv:2501.18512, 2025
-
[13]
Z. Charles, G. Teston, L. Dery, K. Rush, N. Fallen, Z. Garrett, A. Szlam, and A. Douillard. Communication-efficient language model training scales reliably and robustly: Scaling laws for DiLoCo. arXiv:2503.09799, 2025
- [14]
- [15]
-
[16]
Confidential federated computations,
H. Eichner, D. Ramage, K. Bonawitz, D. Huba, T. Santoro, B. McLarnon, T. Van Overveldt, N. Fallen, P. Kairouz, A. Cheu, K. Daly, A. Gascon, M. Gruteser, and B. McMahan. Confidential Federated Computations. arXiv:2404.10764, 2024
-
[17]
Pasquini, G
D. Pasquini, G. Ateniese, M. Bernaschi, and M. Conti. Eluding secure aggregation in federated learning via model inconsistency.CCS, 2022
2022
- [18]
-
[19]
L. Pu, J. Gu, C. Lin, and X. Huang. Janus: Dual-server multi-round secure aggregation with verifiability for federated learning.ICML, 2025. 17 Echelon Decompute Inc. A Related Work Distributed and cross-region LLM training.Megatron-LM, ZeRO, and DeepSpeed optimized training on tightly coupled clusters, where model-state exchange is fundamental to the desi...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.