Do Matching Mechanisms Work with LLM Agents?
Pith reviewed 2026-06-28 08:28 UTC · model grok-4.3
The pith
Matching mechanisms produce more stable and efficient outcomes than free negotiation when LLM agents make allocation decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
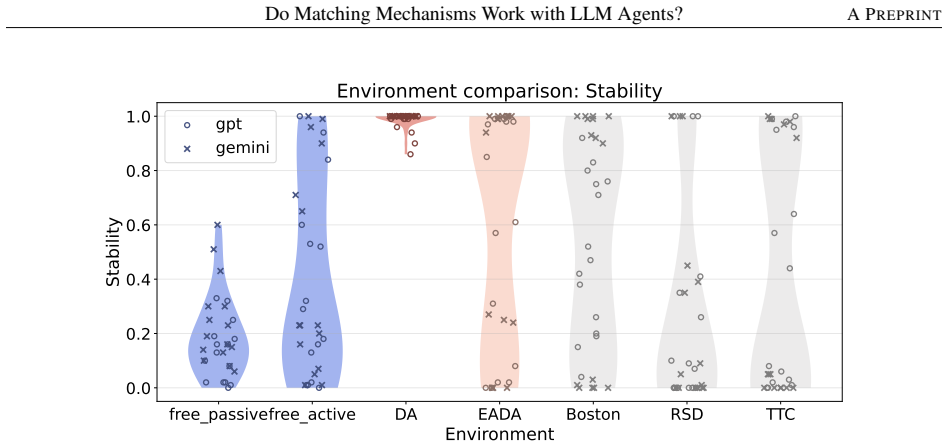
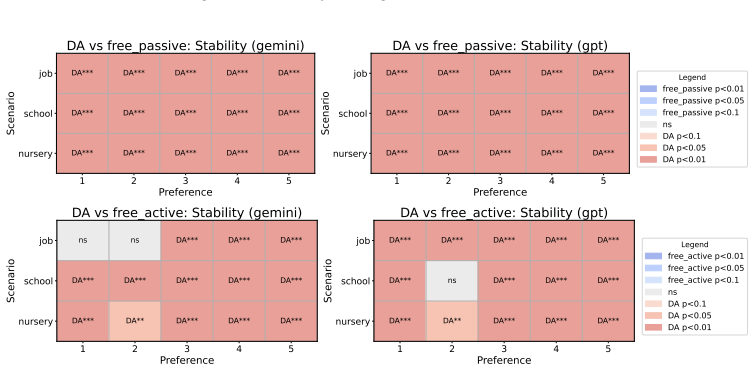
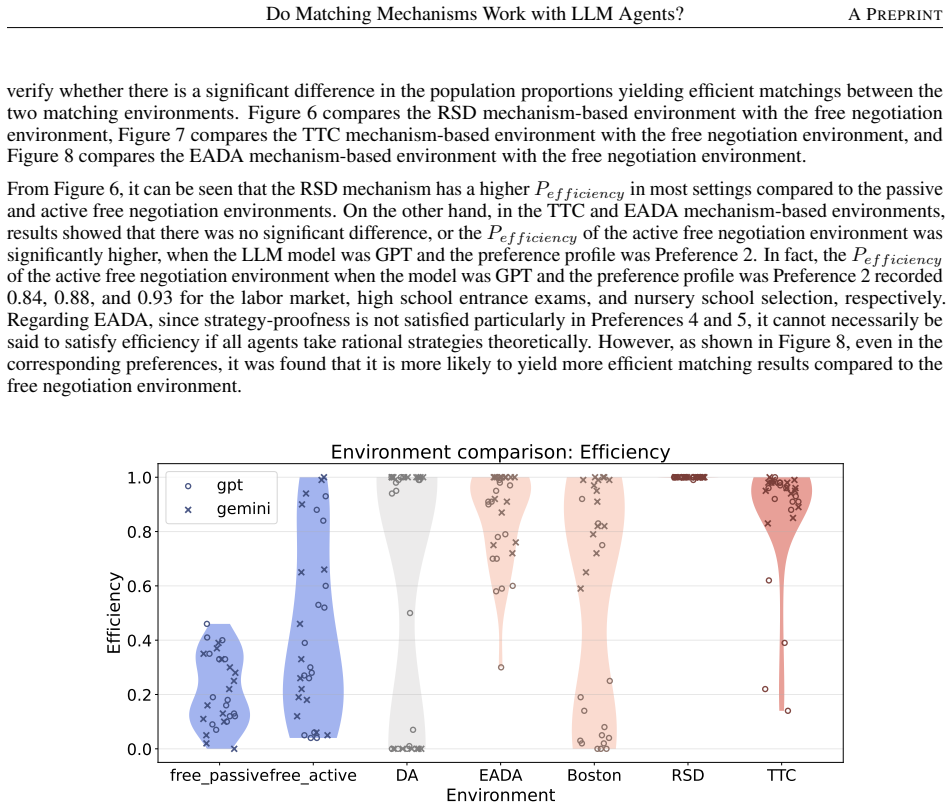
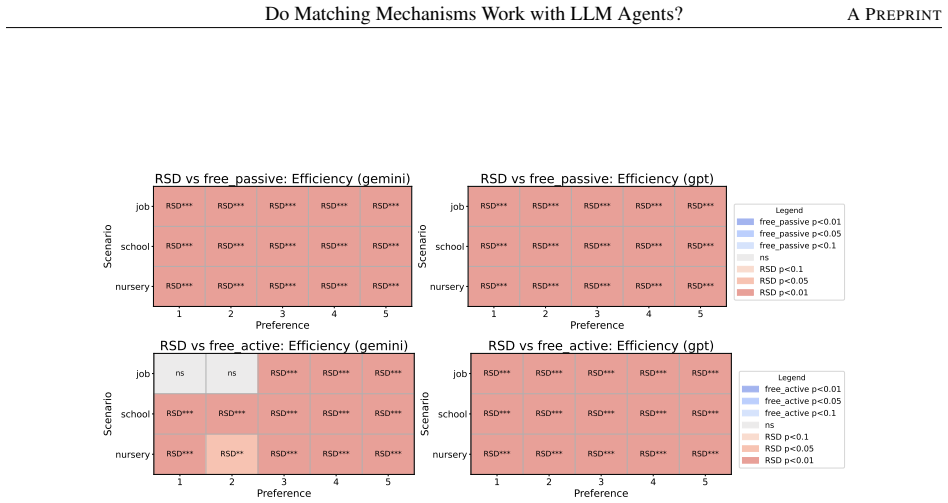
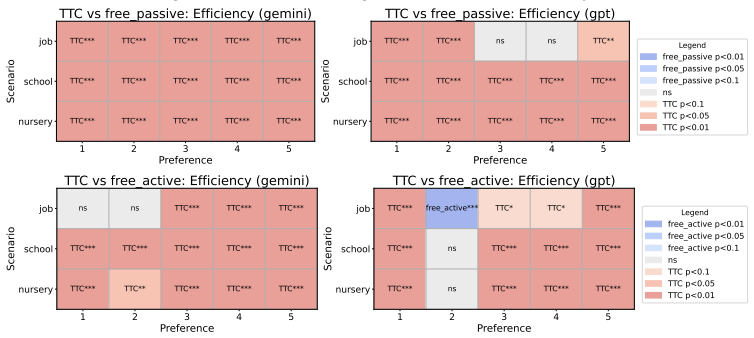
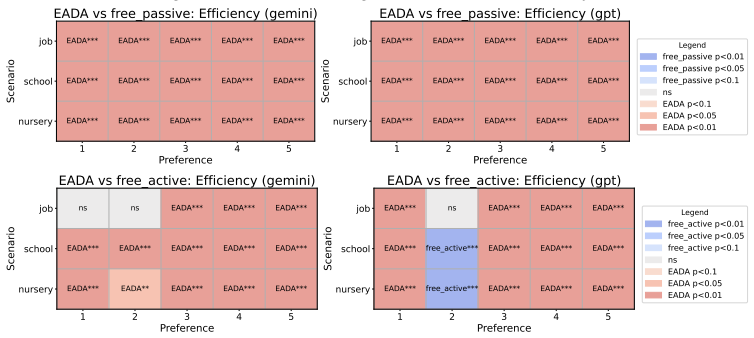
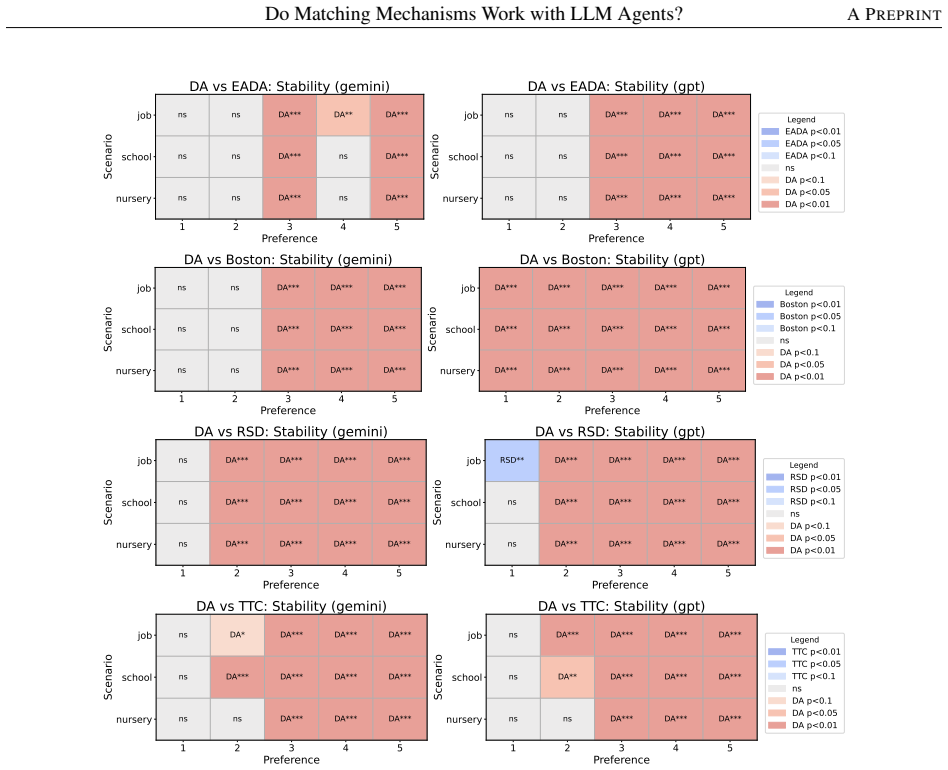
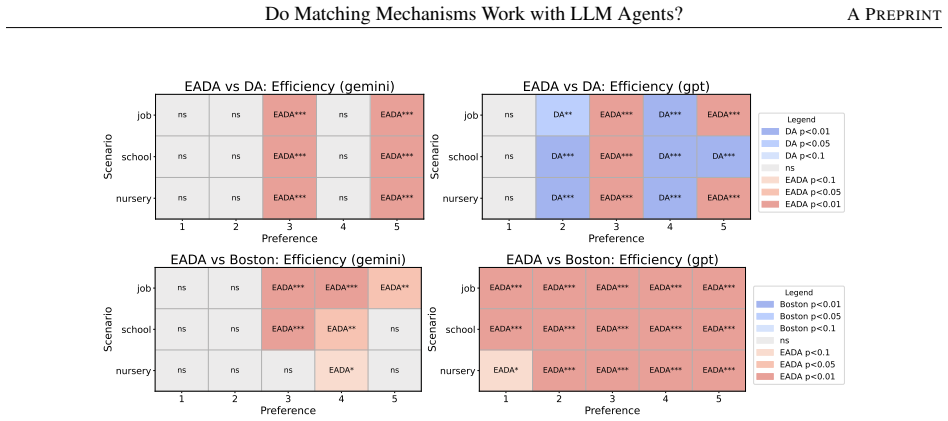
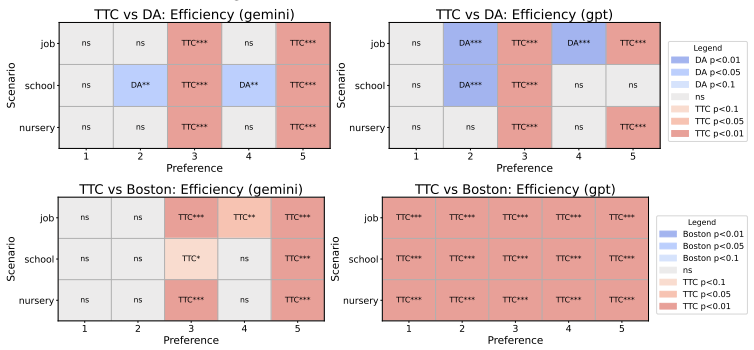
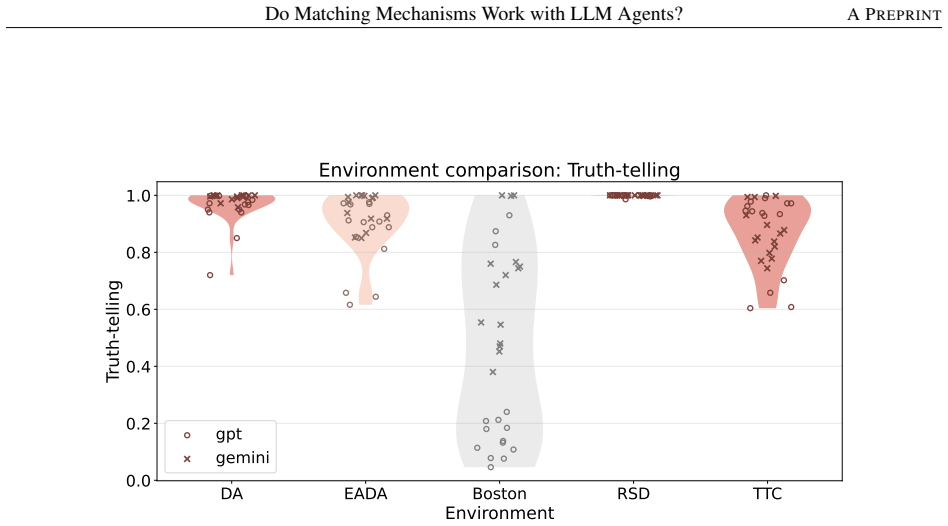
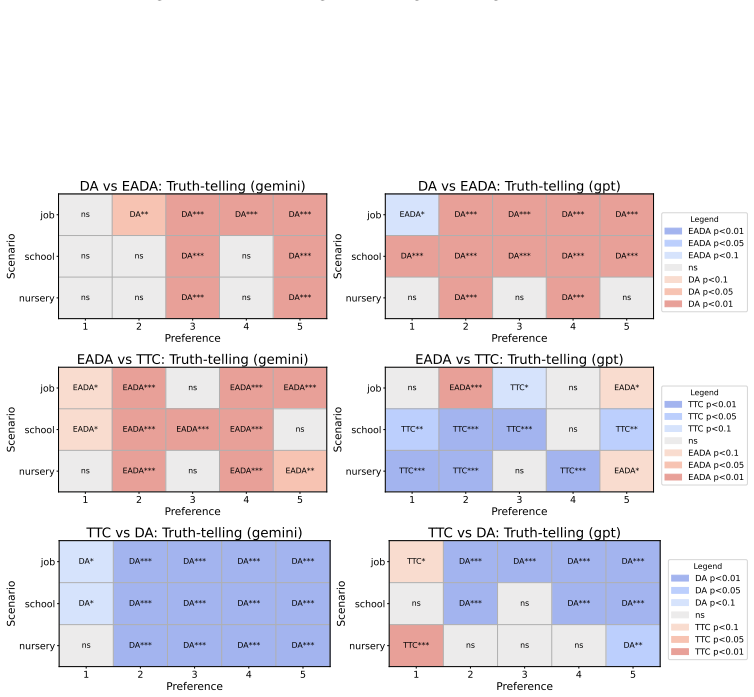
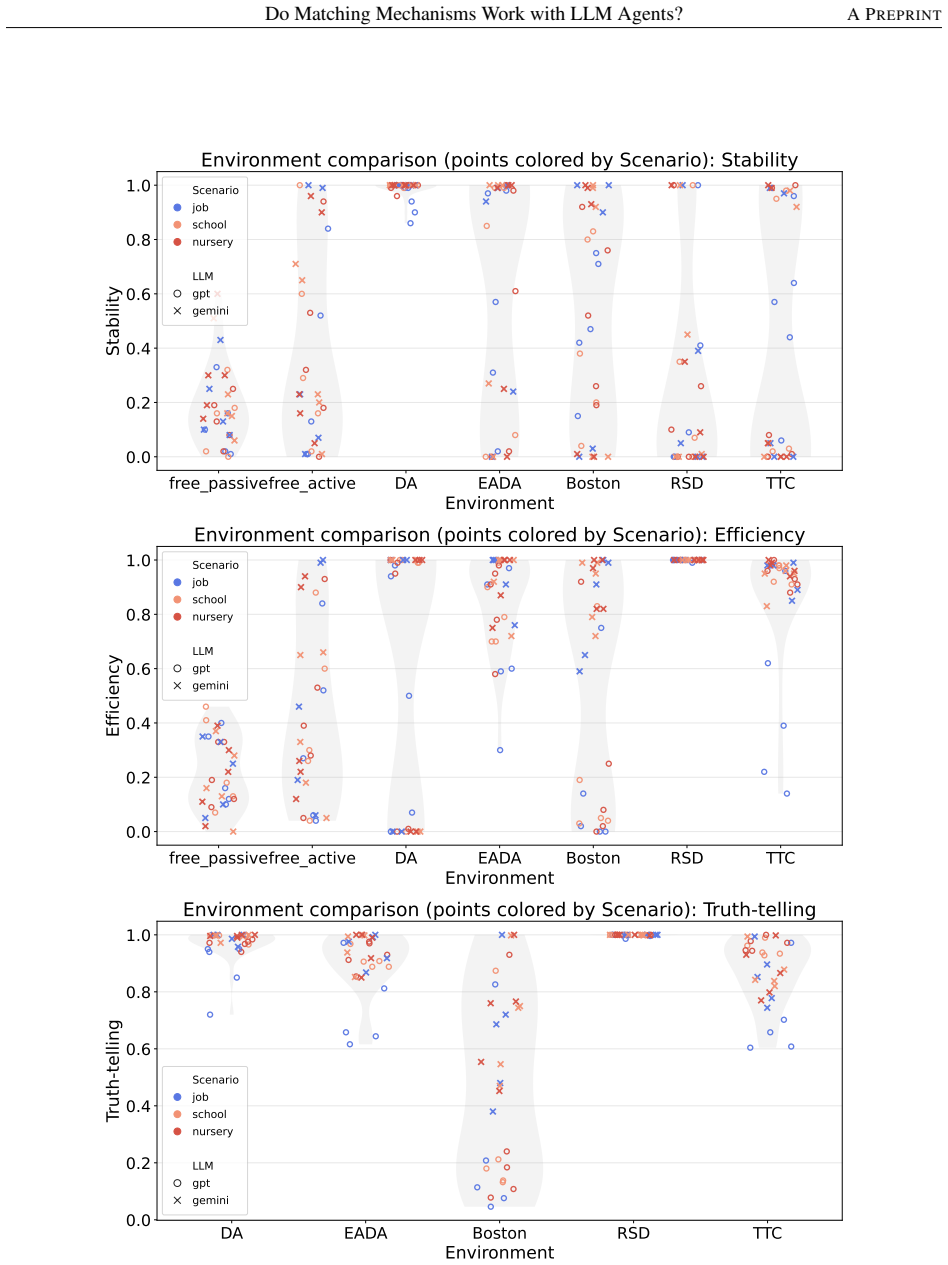
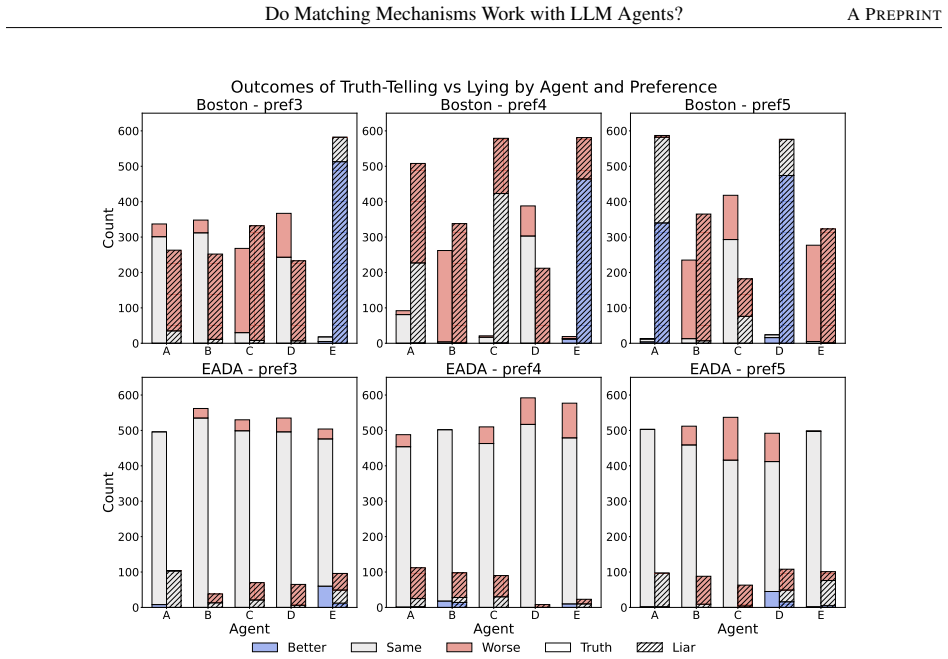
Across controlled one-to-one matching environments, mechanism-based markets generally outperform free negotiation in terms of stability and efficiency. LLM agents report preferences truthfully at substantially higher rates than human subjects in comparable DA and EADA environments, yet truth-telling is not uniformly aligned with formal strategy-proofness across all mechanisms.
What carries the argument
Direct experimental comparison of decentralized free-negotiation markets against centralized mechanisms (DA, EADA, TTC) when LLM agents report preferences and execute allocations in one-to-one assignment problems.
If this is right
- Centralized mechanisms deliver higher stability and efficiency than free negotiation in LLM-agent markets.
- LLM agents report preferences truthfully more often than human subjects in DA and EADA environments.
- Strategy-proofness does not reliably predict the highest observed truth-telling rates across mechanisms.
- Matching theory offers a partial but not complete guide for institution design in LLM-agent settings.
Where Pith is reading between the lines
- Designers of future AI-mediated markets may need to run empirical tests rather than rely solely on theoretical strategy-proofness.
- Observed truth-telling gaps could widen or narrow as LLM capabilities or prompting methods change.
- The advantage of mechanisms may or may not hold in multi-sided or repeated-interaction markets not examined here.
Load-bearing premise
The specific LLM agents and controlled one-to-one environments used in the experiments represent how LLM agents would behave in real-world delegated matching markets.
What would settle it
Re-running the same protocol with different LLM models or in larger real-world matching instances and finding that free negotiation matches or exceeds mechanism performance on stability and efficiency would falsify the central result.
Figures

read the original abstract
This study examines whether standard matching mechanisms function as intended in LLM-agent markets, where LLM agents make allocation-related decisions as delegated decision-makers. We compare decentralized free-negotiation markets with centralized mechanism-based markets including several representative mechanisms. Across controlled one-to-one matching environments, mechanism-based markets generally outperform free negotiation in terms of stability and efficiency. We also find that LLM agents report preferences truthfully at substantially higher rates than human subjects in comparable DA and EADA environments. However, truth-telling is not uniformly aligned with formal strategy-proofness across all mechanisms: TTC, despite being strategy-proof, does not always elicit higher truth-telling than EADA. These results suggest that matching theory provides a useful but incomplete guide for designing institutions in LLM-agent markets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper examines the behavior of LLM agents in one-to-one matching markets. It compares decentralized free-negotiation markets against centralized mechanisms (including DA, EADA, and TTC) in controlled environments, claiming that mechanism-based markets generally outperform free negotiation on stability and efficiency. It further claims that LLM agents report preferences truthfully at substantially higher rates than human subjects in comparable DA and EADA settings, though truth-telling rates are not uniformly higher for strategy-proof mechanisms such as TTC relative to EADA. The abstract concludes that matching theory provides a useful but incomplete guide for LLM-agent markets.
Significance. If the empirical results prove robust after addressing methodological gaps, the work would provide initial evidence on how standard matching mechanisms perform when decision-making is delegated to LLM agents. This could inform institutional design for AI-mediated markets. The paper receives credit for conducting controlled comparisons between free negotiation and multiple mechanisms and for benchmarking LLM truth-telling rates against existing human-subject data.
major comments (2)
- [Abstract] Abstract and experimental methods: the abstract states general performance differences and higher truth-telling rates but supplies no information on number of trials, statistical tests, specific models used, temperature settings, or controls for prompt variation. Without these details the degree to which the data support the central claims cannot be assessed.
- [Abstract] The central claims require that behavior observed with the authors' chosen LLM agents and one-to-one environments generalizes to other frontier models, larger instances, and preference distributions drawn from actual delegated markets. No evidence or robustness checks addressing sensitivity to model version, prompt phrasing, or market complexity are described.
minor comments (1)
- Clarify the exact set of mechanisms tested and the precise definitions of stability and efficiency used in the LLM-agent setting.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental methods: the abstract states general performance differences and higher truth-telling rates but supplies no information on number of trials, statistical tests, specific models used, temperature settings, or controls for prompt variation. Without these details the degree to which the data support the central claims cannot be assessed.
Authors: We agree that the abstract would benefit from greater methodological transparency. In the revised manuscript we will expand the abstract to report the number of trials per condition, the statistical tests used for comparisons, the specific LLM models and versions, the temperature settings, and the controls employed for prompt variation (including use of standardized templates). Corresponding details will also be added or clarified in the methods section. revision: yes
-
Referee: [Abstract] The central claims require that behavior observed with the authors' chosen LLM agents and one-to-one environments generalizes to other frontier models, larger instances, and preference distributions drawn from actual delegated markets. No evidence or robustness checks addressing sensitivity to model version, prompt phrasing, or market complexity are described.
Authors: Our study is explicitly framed as an initial investigation in controlled one-to-one settings; the manuscript does not assert broad generalization. We will revise the abstract and add a limitations section that clearly delineates the scope of the findings and notes the absence of robustness checks across model versions, prompt phrasings, and larger or real-world preference distributions. Additional experiments on these dimensions are beyond the scope of the present revision. revision: partial
Circularity Check
No circularity: empirical study with direct experimental comparisons
full rationale
The paper reports controlled experiments comparing free negotiation against mechanism-based markets (DA, EADA, TTC) using LLM agents in one-to-one matching settings. Central claims concern observed stability, efficiency, and truth-telling rates; these rest on direct measurement rather than any derivation, prediction, or first-principles result that reduces to fitted inputs or self-referential definitions. No equations, ansatzes, or uniqueness theorems are invoked whose validity depends on the present results. Self-citations to matching theory are external and non-load-bearing for the empirical findings. The work is self-contained against its stated benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption One-to-one matching environments with agents reporting preferences.
Reference graph
Works this paper leans on
-
[1]
Random serial dictatorship and the core from random endowments in house allocation problems.Econometrica, 66(3):689–701, 1998
Atila Abdulkadiro˘glu and Tayfun Sönmez. Random serial dictatorship and the core from random endowments in house allocation problems.Econometrica, 66(3):689–701, 1998
1998
-
[2]
School choice: A mechanism design approach.American Economic Review, 93(3):729–747, 2003
Atila Abdulkadiro˘glu and Tayfun Sönmez. School choice: A mechanism design approach.American Economic Review, 93(3):729–747, 2003. doi:10.1257/000282803322157061
-
[3]
Atila Abdulkadiro˘glu, Parag A. Pathak, and Alvin E. Roth. The new york city high school match.American Economic Review, 95(2):364–367, 2005. doi:10.1257/000282805774670167
-
[4]
Roth, and Tayfun Sonmez
Atila Abdulkadiro˘glu, Parag Pathak, Alvin E. Roth, and Tayfun Sonmez. Changing the boston school choice mechanism. NBER Working Papers 11965, National Bureau of Economic Research, Inc, 2006
2006
-
[5]
Pathak, and Alvin E
Atila Abdulkadiro˘glu, Parag A. Pathak, and Alvin E. Roth. Strategy-proofness versus efficiency in matching with indifferences: Redesigning the NYC high school match.American Economic Review, 99(5):1954–1978,
1954
-
[6]
doi:10.1257/aer.99.5.1954
-
[7]
Atila Abdulkadiro ˘glu, Yeon-Koo Che, and Yosuke Yasuda. Resolving conflicting preferences in school choice: The “boston mechanism” reconsidered.American Economic Review, 101(1):399–410, 2011. doi:10.1257/aer.101.1.399
-
[8]
Atila Abdulkadiro˘glu, Yeon-Koo Che, Parag A. Pathak, Alvin E. Roth, and Olivier Tercieux. Efficiency, justified envy, and incentives in priority-based matching.American Economic Review: Insights, 2(4):425–442, 2020. doi:10.1257/aeri.20190307
-
[9]
Arriaga, and Adam Tauman Kalai
Gati Aher, Rosa I. Arriaga, and Adam Tauman Kalai. Using large language models to simulate multiple humans and replicate human subject studies. InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
2023
-
[10]
Playing repeated games with large language models.Nature Human Behaviour, 9(7):1380–1390, 2025
Elif Akata, Lion Schulz, Julian Coda-Forno, Seong Joon Oh, Matthias Bethge, and Eric Schulz. Playing repeated games with large language models.Nature Human Behaviour, 9(7):1380–1390, 2025. doi:10.1038/s41562-025- 02172-y
-
[11]
Figueroa, Yash Kanoria, and Akshit Kumar
Amine Allouah, Omar Besbes, Josué D. Figueroa, Yash Kanoria, and Akshit Kumar. What is your AI agent buying? evaluation, biases, model dependence, & emerging implications of agentic e-commerce. InProceedings of the ACM Web Conference 2026, pages 8697–8700, 2026. doi:10.1145/3774904.3792943
-
[12]
Modeling human decisions in coupled human and natural systems: Review of agent-based models
Li An. Modeling human decisions in coupled human and natural systems: Review of agent-based models. Ecological Modelling, 229:25–36, 2012. doi:10.1016/j.ecolmodel.2011.07.010
-
[13]
Language models as agent models
Jacob Andreas. Language models as agent models. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors,Findings of the Association for Computational Linguistics: EMNLP 2022, pages 5769–5779, 2022. doi:10.18653/v1/2022.findings-emnlp.423
-
[14]
Lisa P. Argyle, Ethan C. Busby, Nancy Fulda, Joshua R. Gubler, Christopher Rytting, and David Wingate. Out of one, many: Using language models to simulate human samples.Political Analysis, 31(3):337–351, 2023. doi:10.1017/pan.2023.2
-
[15]
Arrow and Gerard Debreu
Kenneth J. Arrow and Gerard Debreu. Existence of an equilibrium for a competitive economy.Econometrica, 22 (3):265–290, 1954
1954
-
[16]
Stable matching mechanisms are not obviously strategy-proof.Journal of Economic Theory, 177:405–425, 2018
Itai Ashlagi and Yannai A Gonczarowski. Stable matching mechanisms are not obviously strategy-proof.Journal of Economic Theory, 177:405–425, 2018
2018
-
[17]
The dissemination of culture: A model with local convergence and global polarization.The Journal of Conflict Resolution, 41(2):203–226, 1997
Robert Axelrod. The dissemination of culture: A model with local convergence and global polarization.The Journal of Conflict Resolution, 41(2):203–226, 1997. 30 Do Matching Mechanisms Work with LLM Agents?A PREPRINT
1997
-
[18]
A guide for newcomers to agent-based modeling in the social sciences
Robert Axelrod and Leigh Tesfatsion. A guide for newcomers to agent-based modeling in the social sciences. Staff General Research Papers Archive 12515, Iowa State University, Department of Economics, 2006
2006
-
[19]
How well can LLMs negotiate? negotiationarena platform and analysis
Federico Bianchi, Patrick John Chia, Mert Yuksekgonul, Jacopo Tagliabue, Dan Jurafsky, and James Zou. How well can LLMs negotiate? negotiationarena platform and analysis. InForty-first International Conference on Machine Learning, 2024
2024
-
[20]
James Bisbee, Joshua Clinton, Cassy Dorff, Brenton Kenkel, and Jennifer Larson. Synthetic replacements for hu- man survey data? the perils of large language models.Political Analysis, 32:1–16, 2024. doi:10.1017/pan.2024.5
-
[21]
Iterative versus standard deferred acceptance: Experimental evidence.The Economic Journal, 130(626):356–392, 2020
Inácio Bó and Rustamdjan Hakimov. Iterative versus standard deferred acceptance: Experimental evidence.The Economic Journal, 130(626):356–392, 2020
2020
-
[22]
A new solution to the random assignment problem.Journal of Economic Theory, 100(2):295–328, 2001
Anna Bogomolnaia and Hervé Moulin. A new solution to the random assignment problem.Journal of Economic Theory, 100(2):295–328, 2001. doi:10.1006/jeth.2000.2710
-
[23]
Agent-based modeling: Methods and techniques for simulating human systems.Proceedings of the National Academy of Sciences of the United States of America, 99(10):7280–7287, 2002
Eric Bonabeau. Agent-based modeling: Methods and techniques for simulating human systems.Proceedings of the National Academy of Sciences of the United States of America, 99(10):7280–7287, 2002
2002
-
[24]
Citysim: Modeling urban behaviors and city dynamics with large-scale llm-driven agent simulation
Nicolas Bougie and Narimawa Watanabe. Citysim: Modeling urban behaviors and city dynamics with large-scale llm-driven agent simulation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 215–229, 2025
2025
-
[25]
Constrained school choice: An experimental study
Caterina Calsamiglia, Guillaume Haeringer, and Flip Klijn. Constrained school choice: An experimental study. American Economic Review, 100(4):1860–1874, 2010. doi:10.1257/aer.100.4.1860
-
[26]
Cindy Candrian and Anne Scherer. Rise of the machines: Delegating decisions to autonomous AI.Computers in Human Behavior, 134:107308, 2022. doi:10.1016/j.chb.2022.107308
-
[27]
Specializing large language models to simulate survey response distributions for global populations
Yong Cao, Haijiang Liu, Arnav Arora, Isabelle Augenstein, Paul Röttger, and Daniel Hershcovich. Specializing large language models to simulate survey response distributions for global populations. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volum...
-
[28]
Guarantees for autonomy in cognitive agent architecture
Cristiano Castelfranchi. Guarantees for autonomy in cognitive agent architecture. InProceedings of the Workshop on Agent Theories, Architectures, and Languages on Intelligent Agents, pages 56–70, 1995
1995
-
[29]
School choice with consent: an experiment.The Economic Journal, 134(661):1760–1805, 2024
Claudia Cerrone, Yoan Hermstrüwer, and Onur Kesten. School choice with consent: an experiment.The Economic Journal, 134(661):1760–1805, 2024. doi:10.1093/ej/uead120
-
[30]
Put your money where your mouth is: Evaluating strategic planning and execution of LLM agents in an auction arena
Jiangjie Chen, Siyu Yuan, Rong Ye, Bodhisattwa Prasad Majumder, and Kyle Richardson. Put your money where your mouth is: Evaluating strategic planning and execution of LLM agents in an auction arena. InNeurIPS 2024 Workshop on Open-World Agents, 2024
2024
-
[31]
Chinese college admissions and school choice reforms: An experimental study
Yan Chen and Onur Kesten. Chinese college admissions and school choice reforms: An experimental study. Games and Economic Behavior, 115:83–100, 2019. doi:10.1016/j.geb.2019.02.003
-
[32]
School choice: an experimental study.Journal of Economic Theory, 127(1): 202–231, 2006
Yan Chen and Tayfun Sönmez. School choice: an experimental study.Journal of Economic Theory, 127(1): 202–231, 2006. doi:10.1016/j.jet.2004.10.006
-
[33]
Kirshner, Anton Ovchinnikov, Meena Andiappan, and Tracy Jenkin
Yang Chen, Samuel N. Kirshner, Anton Ovchinnikov, Meena Andiappan, and Tracy Jenkin. A manager and an AI walk into a bar: Does chatGPT make biased decisions like we do?Manufacturing & Service Operations Management, 27(2):354–368, 2025. doi:10.1287/msom.2023.0279
-
[34]
The emergence of economic rationality of GPT
Yiting Chen, Tracy Xiao Liu, You Shan, and Songfa Zhong. The emergence of economic rationality of GPT. Proceedings of the National Academy of Sciences, 120(51):e2316205120, 2023. doi:10.1073/pnas.2316205120
-
[35]
Christopher Chiu, Simpson Zhang, and Mihaela van der Schaar. Strategic self-improvement for competitive agents in AI labour markets.arXiv preprint arXiv:2512.04988, 2025
arXiv 2025
-
[36]
Edward H. Clarke. Multipart pricing of public goods.Public Choice, 11:17–33, 1971
1971
-
[37]
Coleman.Microfoundations and Macrosocial Behavior, pages 153–176
James S. Coleman.Microfoundations and Macrosocial Behavior, pages 153–176. University of California Press, 1987
1987
-
[38]
Statistical comparisons of classifiers over multiple data sets.J
Janez Demšar. Statistical comparisons of classifiers over multiple data sets.J. Mach. Learn. Res., 7:1–30, 2006
2006
-
[39]
LLMs at the bargaining table
Yuan Deng, Vahab Mirrokni, Renato Paes Leme, Hanrui Zhang, and Song Zuo. LLMs at the bargaining table. In Agentic Markets Workshop at ICML 2024, 2024
2024
-
[40]
Can AI language models replace human participants? Trends in Cognitive Sciences, 27(7):597–600, 2023
Danica Dillion, Niket Tandon, Yuling Gu, and Kurt Gray. Can AI language models replace human participants? Trends in Cognitive Sciences, 27(7):597–600, 2023. doi:10.1016/j.tics.2023.04.008. 31 Do Matching Mechanisms Work with LLM Agents?A PREPRINT
-
[41]
Questioning the survey responses of large language models
Ricardo Dominguez-Olmedo, Moritz Hardt, and Celestine Mendler-Dünner. Questioning the survey responses of large language models. InProceedings of the 38th International Conference on Neural Information Processing Systems, 2024
2024
-
[42]
L. E. Dubins and D. A. Freedman. Machiavelli and the gale-shapley algorithm.The American Mathematical Monthly, 88(7):485–494, 1981. doi:10.1080/00029890.1981.11995301
-
[43]
Fabian Dvorak, Regina Stumpf, Sebastian Fehrler, and Urs Fischbacher. Adverse reactions to the use of large language models in social interactions.PNAS Nexus, 4(4):pgaf112, 2025. doi:10.1093/pnasnexus/pgaf112
-
[44]
An experimental study of decentralized matching.Quantitative Economics, 16(2):497–533, 2025
Federico Echenique, Alejandro Robinson-Cortés, and Leeat Yariv. An experimental study of decentralized matching.Quantitative Economics, 16(2):497–533, 2025. doi:10.3982/QE2316
-
[45]
From KISS to KIDS – an ‘anti-simplistic’ modelling approach
Bruce Edmonds and Scott Moss. From KISS to KIDS – an ‘anti-simplistic’ modelling approach. In Paul Davidsson, Brian Logan, and Keiki Takadama, editors,Multi-Agent and Multi-Agent-Based Simulation, pages 130–144, Berlin, Heidelberg, 2005. Springer Berlin Heidelberg
2005
-
[46]
Joshua M. Epstein and Robert L. Axtell.Growing Artificial Societies: Social Science from the Bottom Up. The MIT Press, 1996. doi:10.7551/mitpress/3374.001.0001
-
[47]
Games of school choice under the boston mechanism.Journal of Public Economics, 90(1):215–237, 2006
Haluk Ergin and Tayfun Sönmez. Games of school choice under the boston mechanism.Journal of Public Economics, 90(1):215–237, 2006. doi:10.1016/j.jpubeco.2005.02.002
-
[48]
Featherstone and Muriel Niederle
Clayton R. Featherstone and Muriel Niederle. Boston versus deferred acceptance in an interim setting: An experimental investigation.Games and Economic Behavior, 100:353–375, 2016. doi:10.1016/j.geb.2016.10.005
-
[49]
Yeqi Feng, Yucheng Lu, Hongyu Su, and Tianxing He. Simcity: Multi-agent urban development simulation with rich interactions.arXiv preprint arXiv:2510.01297, 2025
Pith/arXiv arXiv 2025
-
[50]
Sara Fish, Yannai A. Gonczarowski, and Ran I. Shorrer. Algorithmic collusion by large language models.arXiv preprint arXiv:2404.00806, 2025
arXiv 2025
-
[51]
Yao Fu, Hao Peng, Tushar Khot, and Mirella Lapata. Improving language model negotiation with self-play and in-context learning from AI feedback.arXiv preprint arXiv:2305.10142, 2023
arXiv 2023
-
[52]
Gale and L
D. Gale and L. S. Shapley. College admissions and the stability of marriage.The American Mathematical Monthly, 69(1):9–15, 1962
1962
-
[53]
Chen Gao, Xiaochong Lan, Nian Li, Yuan Yuan, Jingtao Ding, Zhilun Zhou, Fengli Xu, and Yong Li. Large language models empowered agent-based modeling and simulation: a survey and perspectives.Humanities and Social Sciences Communications, 11(1):1–24, 2024. doi:10.1057/s41599-024-03611-3
-
[54]
Manipulation of voting schemes: A general result.Econometrica, 41(4):587–601, 1973
Allan Gibbard. Manipulation of voting schemes: A general result.Econometrica, 41(4):587–601, 1973
1973
-
[55]
Sofie Goethals, Johannes Luther, and Sandra Matz. Words reveal wants: How well can simple LLM- based AI agents replicate people’s choices based on their social media posts. InAdjunct Proceedings of the 33rd ACM Conference on User Modeling, Adaptation and Personalization, pages 126–131, 2025. doi:10.1145/3708319.3733689
-
[56]
Emergence as a construct: History and issues.Emergence, 1:49–72, 1999
Jeffrey Goldstein. Emergence as a construct: History and issues.Emergence, 1:49–72, 1999. doi:10.1207/s15327000em0101_4
-
[57]
Frontiers: Can large language models capture human preferences?Marketing Science, 43(4):709–722, 2024
Ali Goli and Amandeep Singh. Frontiers: Can large language models capture human preferences?Marketing Science, 43(4):709–722, 2024
2024
-
[58]
Jing Gong. The impact of it-enabled globalization: A structural two-sided matching model of online labor market.SSRN Electronic Journal, 2016. doi:10.2139/ssrn.2745450
-
[59]
Igor Grossmann, Matthew Feinberg, Dawn C. Parker, Nicholas A. Christakis, Philip E. Tetlock, and William A. Cunningham. AI and the transformation of social science research.Science, 380(6650):1108–1109, 2023. doi:10.1126/science.adi1778
-
[60]
Incentives in teams.Econometrica, 41(4):617–631, 1973
Theodore Groves. Incentives in teams.Econometrica, 41(4):617–631, 1973
1973
-
[61]
Pablo Guillen and Rustamdjan Hakimov. The effectiveness of top-down advice in strategy-proof mechanisms: A field experiment.European Economic Review, 101:505–511, 2018. doi:10.1016/j.euroecorev.2017.10.020
-
[62]
Strategy-proofness in experimental matching markets.Experimental Economics, 24(2):650–668, 2021
Pablo Guillen and Róbert F Veszteg. Strategy-proofness in experimental matching markets.Experimental Economics, 24(2):650–668, 2021. doi:10.1007/s10683-020-09665-9
-
[63]
Embodied LLM agents learn to cooperate in organized teams.IEEE Transactions on Computational Social Systems, 2026
Xudong Guo, Kaixuan Huang, Jiale Liu, Wenhui Fan, Natalia Vélez, Qingyun Wu, Huazheng Wang, Thomas L Griffiths, and Mengdi Wang. Embodied LLM agents learn to cooperate in organized teams.IEEE Transactions on Computational Social Systems, 2026. 32 Do Matching Mechanisms Work with LLM Agents?A PREPRINT
2026
-
[64]
Rustamdjan Hakimov and Onur Kesten. The equitable top trading cycles mechanism for school choice.Interna- tional Economic Review, 59(4):2219–2258, 2018. doi:10.1111/iere.12335
-
[65]
A survey of agent-based modeling practices (January 1998 to July 2008).Journal of Artificial Societies and Social Simulation, 12(4):9, 2009
Brian Heath, Raymond Hill, and Frank Ciarallo. A survey of agent-based modeling practices (January 1998 to July 2008).Journal of Artificial Societies and Social Simulation, 12(4):9, 2009
1998
-
[66]
Joseph L. Hodges Jr and Erich L. Lehmann. Estimates of Location Based on Rank Tests.The Annals of Mathematical Statistics, 34(2):598–611, 1963. doi:10.1214/aoms/1177704172
-
[67]
Friederike Holderried, Christian Stegemann-Philipps, Lea Herschbach, Julia-Astrid Moldt, Andrew Nevins, Jan Griewatz, Martin Holderried, Anne Herrmann-Werner, Teresa Festl-Wietek, and Moritz Mahling. A generative pretrained transformer (GPT)-powered chatbot as a simulated patient to practice history taking: Prospective, mixed methods study.JMIR Medical Ed...
2024
-
[68]
Large language models as simulated economic agents: What can we learn from homo silicus? Working Paper 31122, National Bureau of Economic Research, 2023
John J Horton, Apostolos Filippas, and Benjamin S Manning. Large language models as simulated economic agents: What can we learn from homo silicus? Working Paper 31122, National Bureau of Economic Research, 2023
2023
-
[69]
The design of mechanisms for resource allocation.The American Economic Review, 63(2): 1–30, 1973
Leonid Hurwicz. The design of mechanisms for resource allocation.The American Economic Review, 63(2): 1–30, 1973
1973
-
[70]
Michael C. Jensen and William H. Meckling. Theory of the firm: Managerial behavior, agency costs and ownership structure.Journal of Financial Economics, 3(4):305–360, 1976. doi:10.1016/0304-405X(76)90026- X
-
[71]
Jingru Jia and Zehua Yuan. An experimental study of competitive market behavior through LLMs.arXiv preprint arXiv:2409.08357, 2024
arXiv 2024
-
[72]
Shapeng Jiang, Lijia Wei, and Chen Zhang. Donald trumps in the virtual polls: Simulating and predicting public opinions in surveys using large language models.arXiv preprint arXiv:2411.01582, 2025
arXiv 2025
-
[73]
Efficient matching under distributional constraints: Theory and applications
Yuichiro Kamada and Fuhito Kojima. Efficient matching under distributional constraints: Theory and applications. American Economic Review, 105(1):67–99, 2015. doi:10.1257/aer.20101552
-
[74]
‘Simulacrum of Stories’: Examining large language models as qualitative research participants
Shivani Kapania, William Agnew, Motahhare Eslami, Hoda Heidari, and Sarah E Fox. ‘Simulacrum of Stories’: Examining large language models as qualitative research participants. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–17, 2025
2025
-
[75]
John Kennes, Daniel Monte, and Norovsambuu Tumennasan. The day care assignment: A dynamic matching problem.American Economic Journal: Microeconomics, 6(4):362–406, 2014. doi:10.1257/mic.6.4.362
-
[76]
School choice with consent.The Quarterly Journal of Economics, 125(3):1297–1348, 2010
Onur Kesten. School choice with consent.The Quarterly Journal of Economics, 125(3):1297–1348, 2010
2010
-
[77]
Jeongbin Kim, Matthew Kovach, Kyu-Min Lee, Euncheol Shin, and Hector Tzavellas. Learning to be homo economicus: Can an LLM learn preferences from choice.arXiv preprint arXiv:2401.07345, 2024
Pith/arXiv arXiv 2024
-
[78]
Kirshner, Yiwen Pan, Jason Xianghua Wu, and Alex Gould
Samuel N. Kirshner, Yiwen Pan, Jason Xianghua Wu, and Alex Gould. Talking terms: Agent information in LLM supply chain bargaining.Decision Sciences, 2025. doi:10.1111/deci.70010
-
[79]
Ayato Kitadai, Sinndy Dayana Rico Lugo, Yudai Tsurusaki, Yusuke Fukasawa, and Nariaki Nishino. Can AI with high reasoning ability replicate human-like decision making in economic experiments?Group Decision and Negotiation, 34(6):1303–1326, 2025. doi:10.1007/s10726-025-09946-9
-
[80]
Andrew Kloosterman and Peter Troyan. School choice with asymmetric information: Priority design and the curse of acceptance.Theoretical Economics, 15(3):1095–1133, 2020. doi:10.3982/TE3621
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.