Rethinking Molecular Text Representations for LLMs: An Empirical Study
Pith reviewed 2026-06-28 11:14 UTC · model grok-4.3
The pith
LLM performance on molecular tasks varies sharply with the choice of text representation for molecules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
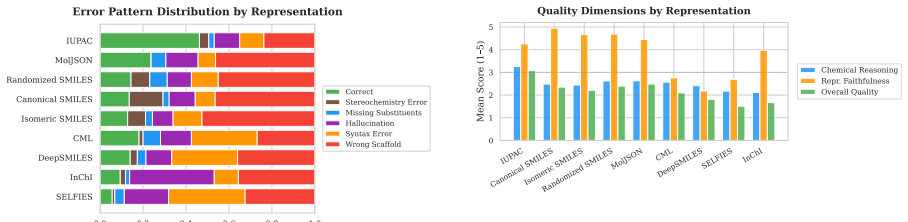
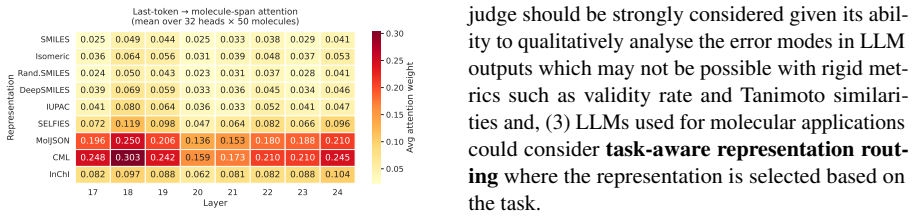
The authors establish through systematic evaluation that molecular text representation choice is a dominant factor in LLM competence on chemistry tasks. Explicit structured representations such as CML and MolJSON perform best on structural tasks, IUPAC names lead on semantic tasks including molecule retrieval for every model tested, and common SMILES variants are seldom the top choice. Chemistry-specialized models excel with SMILES but suffer notable drops with structured text, while tokenization and attention analyses indicate that different representations engage distinct internal mechanisms within the models.
What carries the argument
The benchmark comparing nine molecular text representations on eight tasks across sixteen LLMs, combined with mechanistic probes of tokenization, linear probes, and attention patterns.
Load-bearing premise
The selected eight tasks and nine representations adequately cover the variety of real-world molecular applications for LLMs.
What would settle it
Finding a molecular task or set of models where one representation, such as canonical SMILES, achieves the highest performance across all evaluated cases would challenge the dependence on representation.
Figures

read the original abstract
Large language models (LLMs) are increasingly used for molecular tasks, but it remains unclear which molecular representation to use. We present a systematic benchmark evaluating LLM molecular competence across nine representations and eight chemical tasks. We benchmark 16 LLMs across five model families, including reasoning and non-reasoning variants, chemistry-specialized LLMs, and closed frontier models. Performance is strongly representation-dependent and no single representation wins across tasks, though CML is the best, followed by MolJSON, InChI, and then canonical SMILES. Explicit structured text representations (CML and MolJSON) dominate structural tasks; IUPAC dominates semantic tasks, winning molecule retrieval for all 16 LLMs; and SMILES variants are rarely optimal despite their prevalence in pretraining. Chemistry-specialized models perform well with SMILES at the cost of large degradations with structured text representations, suggesting SMILES-only evaluation rewards specialization that does not generalize. Using LLM-as-a-judge, we find that IUPAC produces the highest fraction of correct molecule generations. A mechanistic study via tokenization audits, linear probes and attention shows that representations are encoded differently inside the model; for example, structured representations require higher attention across the molecular span. Our results argue against representation-invariant evaluation and motivate task-aware representation routing for LLM-based chemistry.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
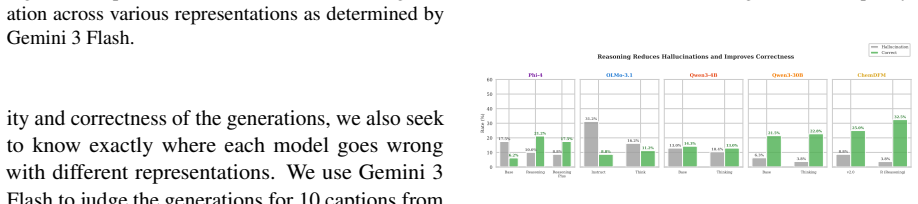
Summary. The manuscript reports a systematic empirical benchmark of nine molecular text representations (CML, MolJSON, InChI, canonical SMILES, and variants, plus IUPAC) across eight chemical tasks using sixteen LLMs spanning five families. It claims performance is strongly representation-dependent with no universal winner; CML ranks highest overall, followed by MolJSON, InChI, and canonical SMILES; explicit structured representations dominate structural tasks while IUPAC dominates semantic tasks (including perfect retrieval wins); SMILES variants are rarely optimal; chemistry-specialized models excel with SMILES but degrade sharply on structured text; LLM-as-a-judge favors IUPAC for generation correctness; and mechanistic probes (tokenization audits, linear probes, attention) reveal representation-specific internal encodings, e.g., higher attention span for structured reps. The work concludes against representation-invariant evaluation and for task-aware routing.
Significance. If the benchmark results and mechanistic findings hold under proper statistical controls, the paper makes a substantive contribution by demonstrating that representation choice is a first-order factor in molecular LLM performance and by providing concrete evidence for task-dependent routing. Credit is due for the breadth (16 models including closed frontier and specialized variants), the inclusion of both structural and semantic tasks, the LLM-as-a-judge analysis, and the mechanistic component that links surface performance to internal model behavior. The study supplies a useful reference point for future work on representation-aware chemistry LLMs.
major comments (2)
- [§4, Tables 1–3] §4 (Results) and Tables 1–3: Performance differences and rankings (e.g., CML best overall, structured reps dominating structural tasks) are reported without error bars, number of evaluation runs, random seeds, or statistical significance tests. This is load-bearing for the central claim that performance is “strongly representation-dependent” and that specific orderings hold.
- [§3] §3 (Benchmark Design): The selection of exactly eight tasks and nine representations is presented without an explicit argument or coverage analysis showing that these adequately sample the space of practical molecular LLM applications (e.g., multi-step synthesis planning, conformer generation, or large-molecule regimes). This directly affects the generalizability of the “no single winner” and “task-aware routing” conclusions.
minor comments (3)
- [Abstract] Abstract: “CML” is used without expansion on first occurrence.
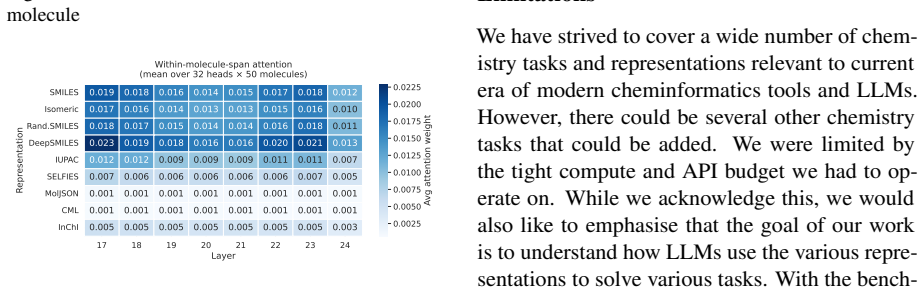
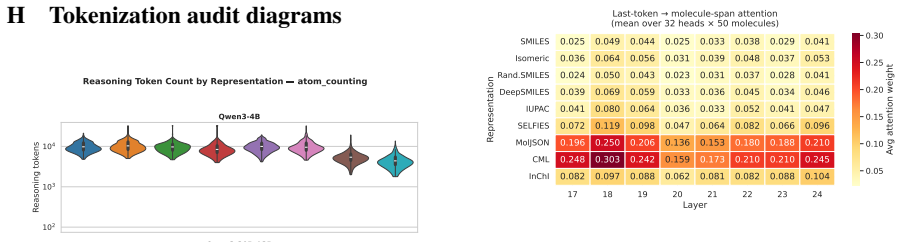
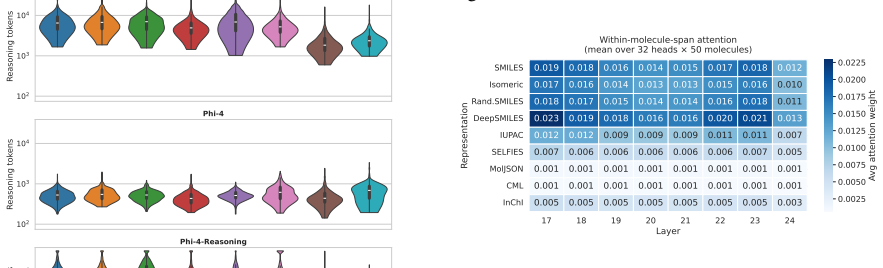
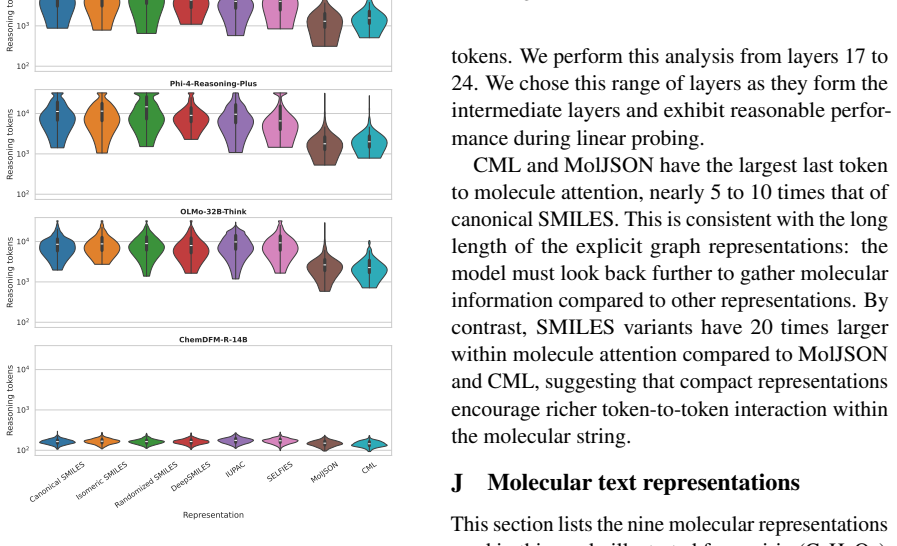
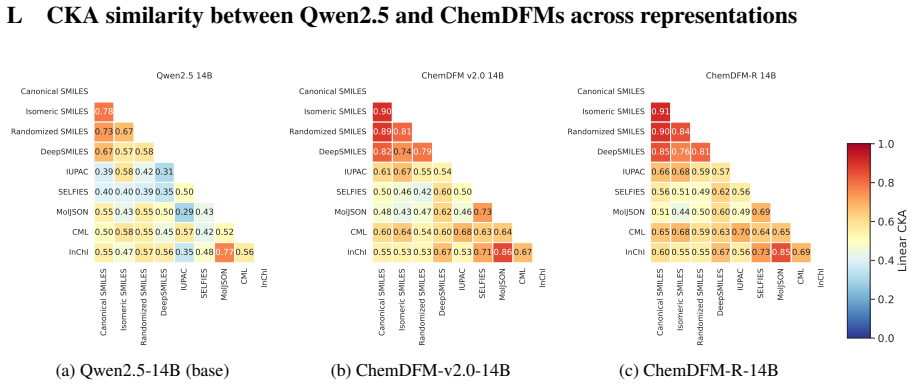
- [Figures 4–6] Figure captions and legends: Attention and probe figures would benefit from explicit scale bars and clearer indication of which model layers are shown.
- [§2] Related work section: Prior molecular representation benchmarks for LLMs are cited but could more explicitly contrast the current task set with those earlier studies.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help improve the rigor and clarity of our work. We address each major comment point by point below, indicating the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§4, Tables 1–3] §4 (Results) and Tables 1–3: Performance differences and rankings (e.g., CML best overall, structured reps dominating structural tasks) are reported without error bars, number of evaluation runs, random seeds, or statistical significance tests. This is load-bearing for the central claim that performance is “strongly representation-dependent” and that specific orderings hold.
Authors: We agree that the lack of error bars, run counts, seeds, and statistical tests weakens the support for our central claims on representation dependence and specific rankings. In the revised manuscript we will add these elements: results will be averaged over at least three independent runs with distinct random seeds where feasible, error bars will be included in Tables 1–3, and we will report statistical significance (e.g., paired Wilcoxon tests or bootstrap confidence intervals) for key comparisons. For closed-API models we will transparently note any practical constraints on repeated sampling while still providing variance estimates where multiple queries were performed. revision: yes
-
Referee: [§3] §3 (Benchmark Design): The selection of exactly eight tasks and nine representations is presented without an explicit argument or coverage analysis showing that these adequately sample the space of practical molecular LLM applications (e.g., multi-step synthesis planning, conformer generation, or large-molecule regimes). This directly affects the generalizability of the “no single winner” and “task-aware routing” conclusions.
Authors: We accept that an explicit coverage argument is needed to substantiate the generalizability of the “no single winner” and task-aware routing conclusions. In the revision we will expand §3 with a new subsection that (i) justifies the eight tasks by mapping them to core molecular LLM use-cases (structure, property, retrieval, generation), (ii) explains the choice of nine representations as spanning string, structured, and nomenclature families, and (iii) provides a coverage analysis together with an explicit limitations paragraph addressing multi-step synthesis, conformer generation, and large-molecule regimes. We will also qualify how the task-routing recommendation may or may not extend to those regimes. revision: yes
Circularity Check
No circularity: empirical benchmark with direct task measurements
full rationale
This is a pure empirical benchmark study evaluating nine representations on eight chemical tasks across 16 LLMs. No derivations, equations, fitted parameters renamed as predictions, or self-citations appear as load-bearing steps. All reported patterns (CML/MolJSON dominance on structural tasks, IUPAC on semantic tasks, etc.) are measured directly against external task performance and are falsifiable by independent replication. The central claims do not reduce to any input by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 40th International Conference on Machine Learning , pages =
Unifying Molecular and Textual Representations via Multi-task Language Modelling , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , volume =
2023
-
[2]
Nature Machine Intelligence , year=
Leveraging large language models for predictive chemistry , author=. Nature Machine Intelligence , year=
-
[3]
Journal of Cheminformatics , year=
Randomized SMILES strings improve the quality of molecular generative models , author=. Journal of Cheminformatics , year=
-
[4]
Nature Machine Intelligence , year=
Invalid SMILES are beneficial rather than detrimental to chemical language models , author=. Nature Machine Intelligence , year=
-
[5]
Krenn, Mario and Ai, Qianxiang and Barthel, Senja and Carson, Nessa and Frei, Angelo and Frey, Nathan C. and Friederich, Pascal and Gaudin, Théophile and Gayle, Alberto Alexander and Jablonka, Kevin Maik and Lameiro, Rafael F. and Lemm, Dominik and Lo, Alston and Moosavi, Seyed Mohamad and Nápoles-Duarte, José Manuel and Nigam, AkshatKumar and Pollice, Ro...
-
[6]
Li, Jiatong and Liu, Yunqing and Fan, Wenqi and Wei, Xiao-Yong and Liu, Hui and Tang, Jiliang and Li, Qing , year=. Empowering Molecule Discovery for Molecule-Caption Translation With Large Language Models: A ChatGPT Perspective , volume=. IEEE Transactions on Knowledge and Data Engineering , publisher=. doi:10.1109/tkde.2024.3393356 , number=
-
[7]
What can Large Language Models do in chemistry? A comprehensive benchmark on eight tasks , url =
Guo, Taicheng and Guo, kehan and Nan, Bozhao and Liang, Zhenwen and Guo, Zhichun and Chawla, Nitesh and Wiest, Olaf and Zhang, Xiangliang , booktitle =. What can Large Language Models do in chemistry? A comprehensive benchmark on eight tasks , url =
-
[8]
nach0: multimodal natural and chemical languages foundation model , volume=
Livne, Micha and Miftahutdinov, Zulfat and Tutubalina, Elena and Kuznetsov, Maksim and Polykovskiy, Daniil and Brundyn, Annika and Jhunjhunwala, Aastha and Costa, Anthony and Aliper, Alex and Aspuru-Guzik, Alán and Zhavoronkov, Alex , year=. nach0: multimodal natural and chemical languages foundation model , volume=. Chemical Science , publisher=. doi:10....
-
[9]
2022 , eprint=
Galactica: A Large Language Model for Science , author=. 2022 , eprint=
2022
-
[10]
Rawte, Vipula and Chakraborty, Swagata and Pathak, Agnibh and Sarkar, Anubhav and Tonmoy, S.M Towhidul Islam and Chadha, Aman and Sheth, Amit and Das, Amitava. The Troubling Emergence of Hallucination in Large Language Models - An Extensive Definition, Quantification, and Prescriptive Remediations. Proceedings of the 2023 Conference on Empirical Methods i...
-
[11]
Translation be- tween Molecules and Natural Language
Edwards, Carl and Lai, Tuan and Ros, Kevin and Honke, Garrett and Cho, Kyunghyun and Ji, Heng. Translation between Molecules and Natural Language. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.26
-
[12]
SMILES, a chemical language and information system. 1. Introduction to methodology and encoding rules , author=. J. Chem. Inf. Comput. Sci. , year=
-
[13]
Raghunathan, Shampa and Priyakumar, U. Deva , title =. International Journal of Quantum Chemistry , volume =. doi:https://doi.org/10.1002/qua.26870 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1002/qua.26870 , abstract =
-
[14]
Molecular representations in AI-driven drug discovery: a review and practical guide , volume =
David, Laurianne and Thakkar, Amol and Mercado, Rocío and Engkvist, Ola , year =. Molecular representations in AI-driven drug discovery: a review and practical guide , volume =. Journal of Cheminformatics , doi =
-
[15]
Wigh, Daniel S. and Goodman, Jonathan M. and Lapkin, Alexei A. , title =. WIREs Computational Molecular Science , volume =. doi:https://doi.org/10.1002/wcms.1603 , url =. https://wires.onlinelibrary.wiley.com/doi/pdf/10.1002/wcms.1603 , abstract =
-
[16]
Self-referencing embedded strings (SELFIES): A 100\ volume=
Krenn, Mario and Häse, Florian and Nigam, AkshatKumar and Friederich, Pascal and Aspuru-Guzik, Alan , year=. Self-referencing embedded strings (SELFIES): A 100\ volume=. Machine Learning: Science and Technology , publisher=. doi:10.1088/2632-2153/aba947 , number=
-
[17]
Chemistry international , year=
The IUPAC international chemical identifier: InChl-A new standard for molecular informatics , author=. Chemistry international , year=
-
[18]
ChemDoodle Web Components: HTML5 toolkit for chemical graphics, interfaces, and informatics , volume =
Burger, Melanie , year =. ChemDoodle Web Components: HTML5 toolkit for chemical graphics, interfaces, and informatics , volume =. Journal of cheminformatics , doi =
-
[19]
2026 , eprint=
In-Context Molecular Property Prediction with LLMs: A Blinding Study on Memorization and Knowledge Conflicts , author=. 2026 , eprint=
2026
-
[20]
2025 , eprint=
A Survey on Data Contamination for Large Language Models , author=. 2025 , eprint=
2025
-
[21]
NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark
Sainz, Oscar and Campos, Jon and Garc \'i a-Ferrero, Iker and Etxaniz, Julen and de Lacalle, Oier Lopez and Agirre, Eneko. NLP Evaluation in trouble: On the Need to Measure LLM Data Contamination for each Benchmark. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.722
-
[22]
Conference on Empirical Methods in Natural Language Processing , year=
Molecular String Representation Preferences in Pretrained LLMs: A Comparative Study in Zero- & Few-Shot Molecular Property Prediction , author=. Conference on Empirical Methods in Natural Language Processing , year=
-
[23]
ArXiv , year=
Benchmarking Large Language Models for Molecule Prediction Tasks , author=. ArXiv , year=
-
[24]
Benchmarking Large Language Models for Polymer Property Predictions , ISSN=
Gupta, Sonakshi and Mahmood, Akhlak and Shukla, Shivank and Ramprasad, Rampi , year=. Benchmarking Large Language Models for Polymer Property Predictions , ISSN=. doi:10.1002/marc.202500388 , journal=
-
[25]
Comparing Text Representations: A Theory-Driven Approach
Yauney, Gregory and Mimno, David. Comparing Text Representations: A Theory-Driven Approach. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.449
-
[26]
2025 , eprint=
RE-IMAGINE: Symbolic Benchmark Synthesis for Reasoning Evaluation , author=. 2025 , eprint=
2025
-
[27]
2018 , eprint=
MoleculeNet: A Benchmark for Molecular Machine Learning , author=. 2018 , eprint=
2018
-
[28]
Al-shaibani, Maged S. and Ahmad, Irfan. Consonant is all you need: a compact representation of E nglish text for efficient NLP. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.775
-
[29]
2026 , eprint=
Regression with Large Language Models for Materials and Molecular Property Prediction , author=. 2026 , eprint=
2026
-
[30]
ChemRxiv , year=
DeepSMILES: An Adaptation of SMILES for Use in Machine-Learning of Chemical Structures , author=. ChemRxiv , year=
-
[31]
Mol-Instructions: A Large-Scale Biomolecular Instruction Dataset for Large Language Models
Fang, Yin and Liang, Xiaozhuan and Zhang, Ningyu and Liu, Kangwei and Huang, Rui and Chen, Zhuo and Fan, Xiaohui and Chen, Huajun. Mol-Instructions: A Large-Scale Biomolecular Instruction Dataset for Large Language Models. arXiv preprint arXiv:2306.08018. 2023
arXiv 2023
-
[32]
2024 , eprint=
Are large language models superhuman chemists? , author=. 2024 , eprint=
2024
-
[33]
Multi-modal Molecule Structure-text Model for Text-based Retrieval and Editing
Liu, Shengchao and Nie, Weili and Wang, Chengpeng and Lu, Jiarui and Qiao, Zhuoran and Liu, Ling and Tang, Jian and Xiao, Chaowei and Anandkumar, Anima. Multi-modal Molecule Structure-text Model for Text-based Retrieval and Editing. Nature Machine Intelligence. 2023
2023
-
[34]
GIMLET : A Unified Graph-Text Model for Instruction-Based Molecule Zero-Shot Learning
Zhao, Haiteng and Liu, Shengchao and Ma, Chang and Xu, Hannan and Fu, Jie and Deng, Zhihong and Kong, Lingpeng and Liu, Qi. GIMLET : A Unified Graph-Text Model for Instruction-Based Molecule Zero-Shot Learning. Advances in Neural Information Processing Systems. 2023
2023
-
[35]
, author=
Nomenclature of organic chemistry: sections A, B, C, D, E, F and H - 1979 ed. , author=. 1979 , url=
1979
-
[36]
2013 , publisher=
Nomenclature of Organic Chemistry: IUPAC Recommendations and Preferred Names 2013 , author=. 2013 , publisher=
2013
-
[37]
A Deep-learning System Bridging Molecule Structure and Biomedical Text with Comprehension Comparable to Human Professionals
Zeng, Zheni and Yao, Yuan and Liu, Zhiyuan and Sun, Maosong. A Deep-learning System Bridging Molecule Structure and Biomedical Text with Comprehension Comparable to Human Professionals. Nature Communications. 2022
2022
-
[38]
Nature Machine Intelligence , year=
Chemical language models enable navigation in sparsely populated chemical space , author=. Nature Machine Intelligence , year=
-
[39]
2023 , eprint=
Language models can generate molecules, materials, and protein binding sites directly in three dimensions as XYZ, CIF, and PDB files , author=. 2023 , eprint=
2023
-
[40]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[41]
Publications Manual , year = "1983", publisher =
1983
-
[42]
Davies, Mark and Nowotka, Michał and Papadatos, George and Dedman, Nathan and Gaulton, Anna and Atkinson, Francis and Bellis, Louisa and Overington, John P. , title =. Nucleic Acids Research , volume =. 2015 , month =. doi:10.1093/nar/gkv352 , url =
-
[43]
2018 , eprint=
Fr\'echet ChemNet Distance: A metric for generative models for molecules in drug discovery , author=. 2018 , eprint=
2018
-
[44]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[45]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of. 2007 , url=
2007
-
[46]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[47]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =. 2005 , url=
2005
-
[48]
and Tukey, John W
Cooley, James W. and Tukey, John W. , journal=. An algorithm for the machine calculation of complex. 1965 , url=
1965
-
[49]
2026 , eprint=
Molecular Representations for Large Language Models , author=. 2026 , eprint=
2026
-
[50]
Table Meets
Sui, Yuan and Zhou, Mengyu and Zhou, Mingjie and Han, Shi and Zhang, Dongmei , booktitle=. Table Meets
-
[51]
Tabular Representation, Noisy Operators, and Impacts on Table Structure Understanding Tasks in
Singha, Ananya and Cambronero, Jos. Tabular Representation, Noisy Operators, and Impacts on Table Structure Understanding Tasks in. NeurIPS 2023 Second Table Representation Learning Workshop , year=
2023
-
[52]
Journal of Cheminformatics , year=
Open chemistry: RESTful web APIs, JSON, NWChem and the modern web application , author=. Journal of Cheminformatics , year=
-
[53]
Matthew Swain , title =
-
[54]
2025 , howpublished =
2025
-
[55]
2025 , eprint=
Training a Scientific Reasoning Model for Chemistry , author=. 2025 , eprint=
2025
-
[56]
Yu, Zhaoning and Xu, Xiangyang and Gao, Hongyang , journal=
-
[57]
2025 , month =
Anthropic , title =. 2025 , month =
2025
-
[58]
2025 , month = dec, url =
Gemini 3 Flash Model Card , institution =. 2025 , month = dec, url =
2025
-
[59]
The properties of known drugs. 1. Molecular frameworks. , author=. Journal of medicinal chemistry , year=
-
[60]
Journal of cheminformatics , volume=
Open Babel: An open chemical toolbox , author=. Journal of cheminformatics , volume=. 2011 , publisher=
2011
-
[61]
Chemical Markup, XML, and the Worldwide Web
Murray-Rust, Peter and Rzepa, Henry , year =. Chemical Markup, XML, and the Worldwide Web. 1. Basic Principles , volume =. Journal of Chemical Information and Computer Sciences , doi =
-
[62]
Chemical markup, XML, and the world wide web
Murray-Rust, Peter and Rzepa, Henry , year =. Chemical markup, XML, and the world wide web. 4. CML schema , volume =. Journal of chemical information and computer sciences , doi =
-
[63]
Nov , volume=
IBM internal report , author=. Nov , volume=
-
[64]
Exploring Forgetting in Large Language Model Pre-Training
Liao, Chonghua and Xie, Ruobing and Sun, Xingwu and Sun, Haowen and Kang, Zhanhui. Exploring Forgetting in Large Language Model Pre-Training. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.105
-
[65]
Belinkov, Yonatan , title =. Computational Linguistics , volume =. 2022 , month =. doi:10.1162/coli_a_00422 , url =
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[66]
Insights into LLM Long-Context Failures: When Transformers Know but Don ' t Tell
Gao, Muhan and Lu, TaiMing and Yu, Kuai and Byerly, Adam and Khashabi, Daniel. Insights into LLM Long-Context Failures: When Transformers Know but Don ' t Tell. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.447
-
[67]
Kirkpatrick, James and Pascanu, Razvan and Rabinowitz, Neil and Veness, Joel and Desjardins, Guillaume and Rusu, Andrei A. and Milan, Kieran and Quan, John and Ramalho, Tiago and Grabska-Barwinska, Agnieszka and Hassabis, Demis and Clopath, Claudia and Kumaran, Dharshan and Hadsell, Raia , year=. Overcoming catastrophic forgetting in neural networks , vol...
-
[68]
Journal of chemical information and computer sciences , year=
Reoptimization of MDL Keys for Use in Drug Discovery , author=. Journal of chemical information and computer sciences , year=
-
[69]
Journal of chemical information and modeling , year=
Extended-Connectivity Fingerprints , author=. Journal of chemical information and modeling , year=
-
[70]
Statistical Significance Tests for Machine Translation Evaluation
Koehn, Philipp. Statistical Significance Tests for Machine Translation Evaluation. Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing. 2004
2004
-
[71]
2024 , eprint=
LlaSMol: Advancing Large Language Models for Chemistry with a Large-Scale, Comprehensive, High-Quality Instruction Tuning Dataset , author=. 2024 , eprint=
2024
-
[72]
RDKit: Open-Source Cheminformatics Software , url =
Landrum, Greg , biburl =. RDKit: Open-Source Cheminformatics Software , url =
-
[73]
Chemical Name to Structure: OPSIN, an Open Source Solution , volume =
Lowe, Daniel and Corbett, Peter and Murray-Rust, Peter and Glen, Robert , year =. Chemical Name to Structure: OPSIN, an Open Source Solution , volume =. Journal of chemical information and modeling , doi =
-
[74]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[75]
arXiv preprint arXiv:2505.09388 , year =
Qwen3 Technical Report , author =. arXiv preprint arXiv:2505.09388 , year =
-
[76]
arXiv preprint arXiv:2412.08905 , year =
Abdin, Marah and Aneja, Jyoti and Behl, Harkirat and Bubeck, S. arXiv preprint arXiv:2412.08905 , year =
-
[77]
arXiv preprint arXiv:2504.21318 , year =
Abdin, Marah and Agarwal, Sahaj and Awadallah, Ahmed and Balachandran, Vidhisha and Behl, Harkirat and Chen, Lingjiao and de Rosa, Gustavo and Gunasekar, Suriya and Javaheripi, Mojan and Joshi, Neel and Kauffmann, Piero and Lara, Yash and Mendes, Caio C. arXiv preprint arXiv:2504.21318 , year =
-
[78]
2026 , eprint=
Olmo 3 , author=. 2026 , eprint=
2026
-
[79]
Developing
Zhao, Zihan and Ma, Da and Chen, Lu and Sun, Liangtai and Li, Zihao and Xia, Yi and Chen, Bo and Xu, Hongshen and Zhu, Zichen and Zhu, Su and Fan, Shuai and Shen, Guodong and Yu, Kai and Chen, Xin , journal=. Developing. 2024 , note =
2024
-
[80]
Zhao, Zihan and others , journal=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.