Efficient Hyperparameter Optimization for LLM Reinforcement Learning
Pith reviewed 2026-06-28 11:06 UTC · model grok-4.3
The pith
JF-HPO speeds up hyperparameter optimization for LLM reinforcement learning by up to 14.9 times using joint fidelity on proxy models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
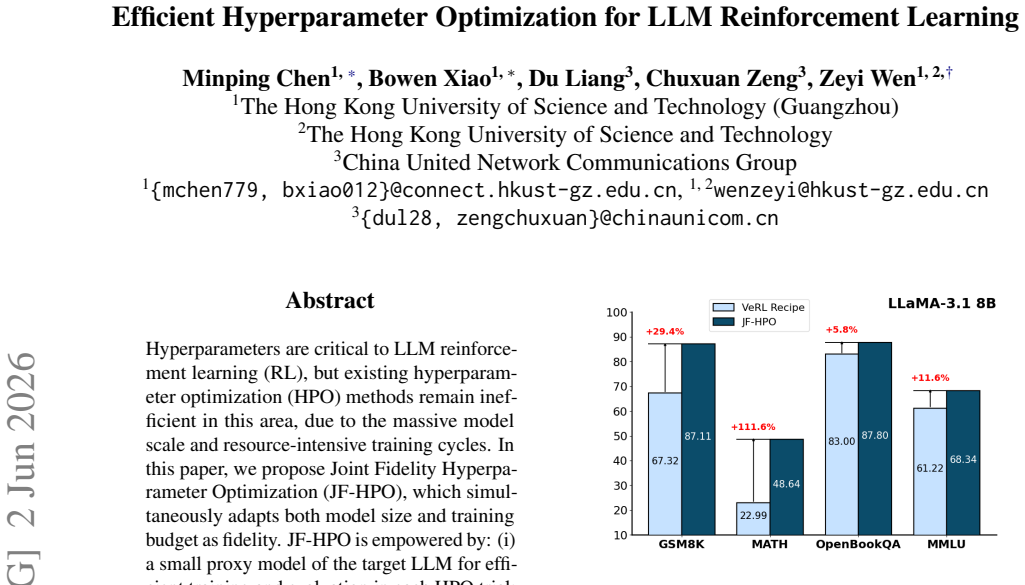
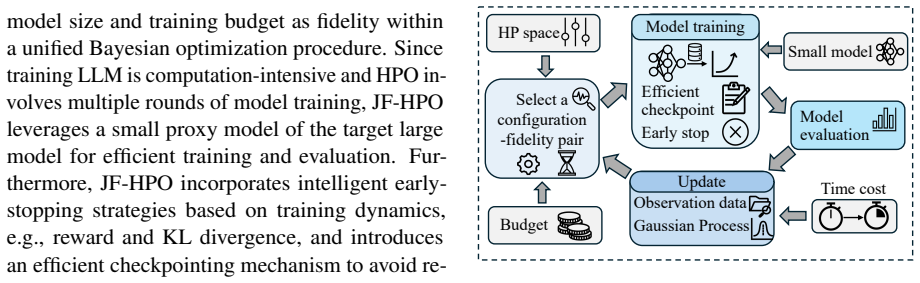
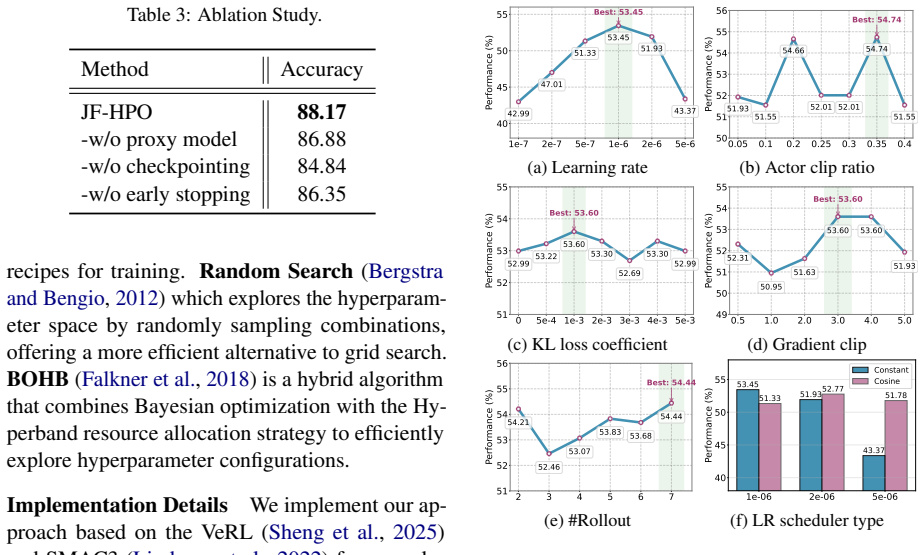
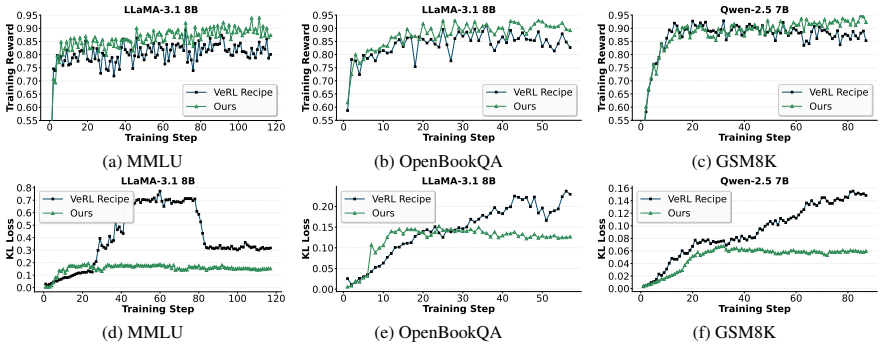
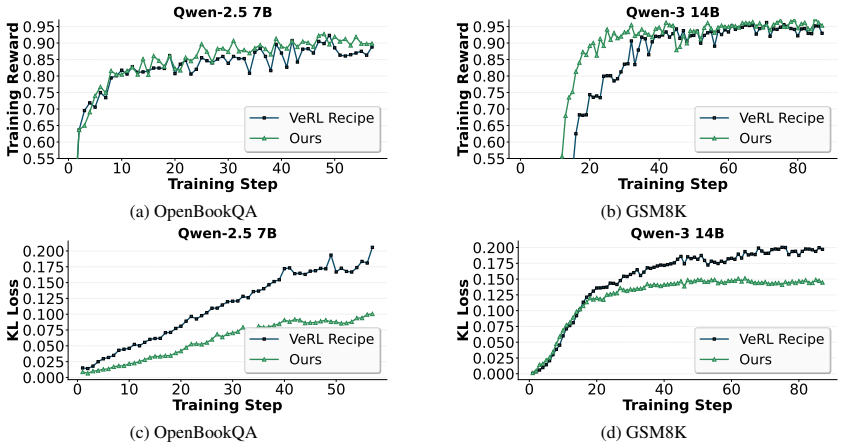
JF-HPO jointly adapts model size and training budget as fidelity for hyperparameter optimization in LLM reinforcement learning. It runs each trial on a small proxy model, stops early based on observed dynamics, and eliminates redundant computation via checkpointing. The method delivers up to 14.9 times higher efficiency per trial while matching or exceeding the accuracy of prior HPO techniques under the same time limit, and it improves over VeRL Recipe configurations by 5.8 percent to 111.6 percent.
What carries the argument
Joint Fidelity Hyperparameter Optimization (JF-HPO), which simultaneously adapts model size and training budget as fidelity levels, supported by proxy-model trials, training-dynamics early stopping, and checkpoint reuse.
If this is right
- Each HPO trial consumes far less compute, allowing more trials inside a fixed wall-clock budget.
- Final RL-trained LLMs reach better or competitive task performance compared with previous HPO methods.
- Hyperparameter configurations found this way outperform the VeRL Recipe by large margins on multiple benchmarks.
- Multi-fidelity search becomes practical for models whose full training cycles are otherwise prohibitive.
Where Pith is reading between the lines
- The same joint-fidelity idea could be tested on non-LLM reinforcement learning tasks where proxy models are cheap to create.
- If proxy rankings prove stable across architectures, the method might generalize beyond the specific LLMs studied here.
- Teams with limited compute could use JF-HPO to explore wider hyperparameter ranges than previously feasible.
Load-bearing premise
Hyperparameter performance rankings measured on small proxy models and short runs will transfer reliably to the full-scale target LLM without systematic bias.
What would settle it
Selecting the top configuration from JF-HPO and then training the full target LLM with it yields worse final performance than configurations chosen by a standard HPO baseline on the same downstream task.
Figures

read the original abstract
Reinforcement learning (RL) for large language models (LLMs) is highly sensitive to hyperparameter configurations, making hyperparameter optimization (HPO) essential yet computationally expensive. Existing multi-fidelity HPO methods remain inefficient for LLM RL due to the massive model scale and resource-intensive training cycles. In this paper, we propose Joint Fidelity Hyperparameter Optimization (JF-HPO), which simultaneously adapts both model size and training budget as fidelity. JF-HPO is empowered by: (i) it leverages a small proxy model of the target LLM for efficient training and evaluation in each HPO trial; (ii) it integrates carefully designed early-stopping strategies based on training dynamics; (iii) it introduces an efficient checkpointing mechanism to eliminate redundant computations. Compared with existing HPO methods, JF-HPO significantly improves the computational efficiency of each trial (up to 14.9 times), while achieving better or competitive predictive accuracy under the same time budget. Notably, compared with utilizing hyperparameter configurations from the VeRL Recipe, JF-HPO delivers performance improvements ranging from 5.8% to 111.6%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Joint Fidelity Hyperparameter Optimization (JF-HPO) for reinforcement learning of large language models. It jointly varies model size (via proxy models) and training budget as fidelity levels, augmented by early-stopping based on training dynamics and an efficient checkpointing scheme. The central empirical claims are that JF-HPO yields up to 14.9× efficiency gains per HPO trial relative to existing methods while delivering better or competitive accuracy under fixed time budgets, and that it improves over the VeRL Recipe by 5.8–111.6 % on the target LLM.
Significance. If the proxy-to-target transfer is shown to be unbiased, the approach would materially reduce the cost of hyperparameter search for LLM RL, a domain where configuration sensitivity is acute and full-scale trials are prohibitive. The joint-fidelity design and the combination of early stopping with checkpointing are pragmatic extensions of multi-fidelity HPO; credit is due for focusing on end-to-end wall-clock efficiency rather than proxy-only metrics.
major comments (2)
- [Abstract] Abstract: the headline claims of 14.9× per-trial efficiency and 5.8–111.6 % accuracy gains over VeRL are presented without any reference to the number of independent runs, statistical tests, variance estimates, or precise definition of “same time budget,” rendering the central empirical assertions unverifiable from the supplied text.
- [Experimental Evaluation] Experimental section (implicit in the accuracy and efficiency results): the manuscript reports target-LLM gains from proxy-selected configurations but supplies no direct control that compares (a) the proxy-optimized hyper-parameters against (b) hyper-parameters obtained by running the same HPO budget directly on the target model or (c) the VeRL defaults under identical target training conditions. Absent this comparison, efficiency measured on the proxy does not entail the claimed end-to-end accuracy improvement on the target.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claims of 14.9× per-trial efficiency and 5.8–111.6 % accuracy gains over VeRL are presented without any reference to the number of independent runs, statistical tests, variance estimates, or precise definition of “same time budget,” rendering the central empirical assertions unverifiable from the supplied text.
Authors: We agree that the abstract lacks these details. In the revision we will update the abstract to reference the number of independent runs (detailed in the experimental section), note that variance estimates and statistical comparisons appear in the main text, and define the time budget explicitly as wall-clock time for target-model training under equivalent resource allocation. This will make the claims more verifiable while preserving conciseness. revision: yes
-
Referee: [Experimental Evaluation] Experimental section (implicit in the accuracy and efficiency results): the manuscript reports target-LLM gains from proxy-selected configurations but supplies no direct control that compares (a) the proxy-optimized hyper-parameters against (b) hyper-parameters obtained by running the same HPO budget directly on the target model or (c) the VeRL defaults under identical target training conditions. Absent this comparison, efficiency measured on the proxy does not entail the claimed end-to-end accuracy improvement on the target.
Authors: Our experiments already apply proxy-selected hyperparameters to the target LLM and compare resulting performance against VeRL defaults under identical target training conditions, which directly supports the end-to-end accuracy claims. A control performing full HPO on the target with equivalent budget is omitted because it is computationally prohibitive—the exact scenario our method seeks to avoid. We will revise the experimental section to state this comparison explicitly and add discussion of proxy-to-target transfer validity based on the observed gains. revision: partial
Circularity Check
No circularity: purely empirical HPO method with no derivation chain
full rationale
The paper introduces JF-HPO as an algorithmic procedure combining proxy models, early stopping, and checkpointing for hyperparameter optimization in LLM RL. All claims of efficiency (up to 14.9×) and accuracy gains are presented as outcomes of experimental comparisons rather than mathematical predictions or first-principles derivations. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text. The work is self-contained as an empirical engineering contribution; performance rankings and transfer assumptions are tested (or assumed) via direct runs, not reduced to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Small proxy models preserve relative hyperparameter rankings for the target LLM
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[9]
Measuring Mathematical Problem Solving With the MATH Dataset , author=
-
[10]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering , author=. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages=
2018
-
[11]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[12]
LLaMA: Open and Efficient Foundation Language Models
Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth. 2023 , month = feb, number =. doi:10.48550/arXiv.2302.13971 , archiveprefix =. 2302.13971 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971 2023
-
[13]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[14]
Journal of Machine Learning Research , year =
Marius Lindauer and Katharina Eggensperger and Matthias Feurer and André Biedenkapp and Difan Deng and Carolin Benjamins and Tim Ruhkopf and René Sass and Frank Hutter , title =. Journal of Machine Learning Research , year =
-
[15]
Proceedings of the Twentieth European Conference on Computer Systems , pages=
Hybridflow: A flexible and efficient rlhf framework , author=. Proceedings of the Twentieth European Conference on Computer Systems , pages=
-
[16]
1998 , publisher=
Reinforcement learning: An introduction , author=. 1998 , publisher=
1998
-
[17]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[18]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[19]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[20]
Advances in Neural Information Processing Systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
5: Scaling reinforcement learning with llms , author=
Kimi k1. 5: Scaling reinforcement learning with llms , author=. arXiv preprint arXiv:2501.12599 , year=
-
[22]
arXiv preprint arXiv:2410.15115 , year=
On designing effective rl reward at training time for llm reasoning , author=. arXiv preprint arXiv:2410.15115 , year=
-
[23]
arXiv preprint arXiv:2503.14476 , year=
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
-
[24]
arXiv preprint arXiv:2501.03262 , year=
Reinforce++: A simple and efficient approach for aligning large language models , author=. arXiv preprint arXiv:2501.03262 , year=
-
[25]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[26]
arXiv preprint arXiv:1506.02438 , year=
High-dimensional continuous control using generalized advantage estimation , author=. arXiv preprint arXiv:1506.02438 , year=
-
[27]
The Journal of Machine Learning Research , volume=
Random search for hyper-parameter optimization , author=. The Journal of Machine Learning Research , volume=. 2012 , publisher=
2012
-
[28]
Advances in Neural Information Processing Systems , volume=
Practical bayesian optimization of machine learning algorithms , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
Evolving Systems , volume=
Automatic tuning of hyperparameters using Bayesian optimization , author=. Evolving Systems , volume=. 2021 , publisher=
2021
-
[30]
Journal of Electronic Science and Technology , volume=
Hyperparameter optimization for machine learning models based on Bayesian optimization , author=. Journal of Electronic Science and Technology , volume=. 2019 , publisher=
2019
-
[31]
International Conference on Machine Learning , pages=
BOHB: Robust and efficient hyperparameter optimization at scale , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Efficient hyperparameter optimization with adaptive fidelity identification , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[33]
Journal of Machine Learning Research , volume=
Hyperband: A novel bandit-based approach to hyperparameter optimization , author=. Journal of Machine Learning Research , volume=
-
[34]
Advances in Neural Information Processing Systems , volume=
Evograd: Efficient gradient-based meta-learning and hyperparameter optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
International Conference on Machine Learning , pages=
Gradient-based hyperparameter optimization through reversible learning , author=. International Conference on Machine Learning , pages=. 2015 , organization=
2015
-
[36]
Advances in Neural Information Processing Systems , volume=
Gradient-based hyperparameter optimization over long horizons , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Artificial Intelligence and Statistics , pages=
Non-stochastic best arm identification and hyperparameter optimization , author=. Artificial Intelligence and Statistics , pages=. 2016 , organization=
2016
-
[38]
2024 , url=
Learning to reason with llms , author=. 2024 , url=
2024
-
[39]
arXiv preprint arXiv:2204.05862 , year=
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
-
[40]
Advances in Neural Information Processing Systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
International Conference on Machine Learning , pages=
Hyperparameters in reinforcement learning and how to tune them , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[42]
Hugging Face repository , volume=
Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions , author=. Hugging Face repository , volume=
-
[43]
2025 , url=
American Invitational Mathematics Examination (AIME) 2025 , author=. 2025 , url=
2025
-
[44]
The Annals of mathematical statistics , volume=
On information and sufficiency , author=. The Annals of mathematical statistics , volume=. 1951 , publisher=
1951
-
[45]
arXiv preprint arXiv:2402.06196 , year=
Large language models: A survey , author=. arXiv preprint arXiv:2402.06196 , year=
-
[46]
IFIP Technical Conference on Optimization Techniques , pages=
On Bayesian methods for seeking the extremum , author=. IFIP Technical Conference on Optimization Techniques , pages=. 1974 , organization=
1974
-
[47]
System Modeling and Optimization: Proceedings of the 10th IFIP Conference New York City, USA, August 31--September 4, 1981 , pages=
The Bayesian approach to global optimization , author=. System Modeling and Optimization: Proceedings of the 10th IFIP Conference New York City, USA, August 31--September 4, 1981 , pages=. 2005 , organization=
1981
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.