Uncertainty-Aware Clarification in LLM Agents with Information Gain
Pith reviewed 2026-06-28 10:25 UTC · model grok-4.3
The pith
LLM agents improve task success by training clarifiers on information gain toward the user's true goal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A reward defined by the Bayesian belief update toward the ground-truth goal allows an LLM clarifier to be trained so that its questions reduce uncertainty enough to raise agent success rates in ambiguous tool-use settings.
What carries the argument
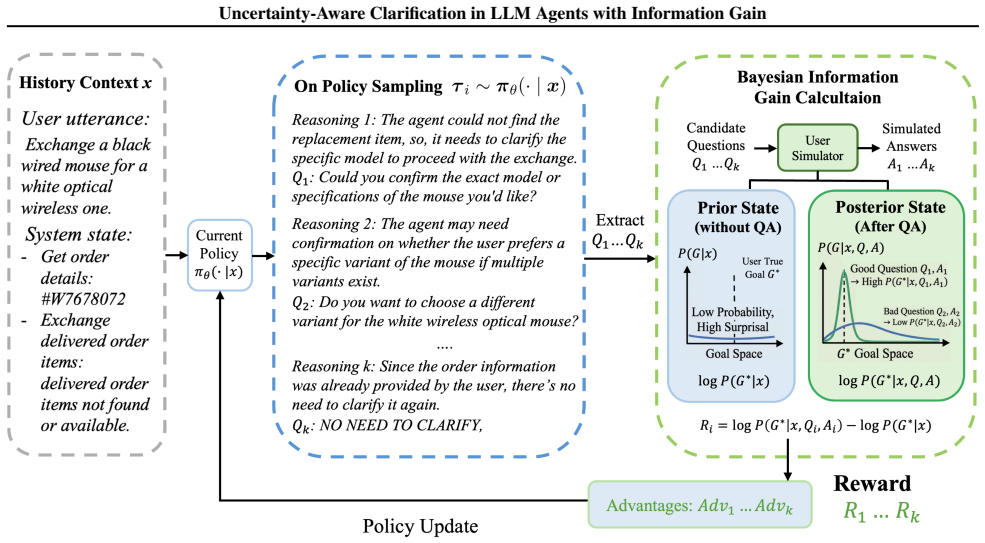
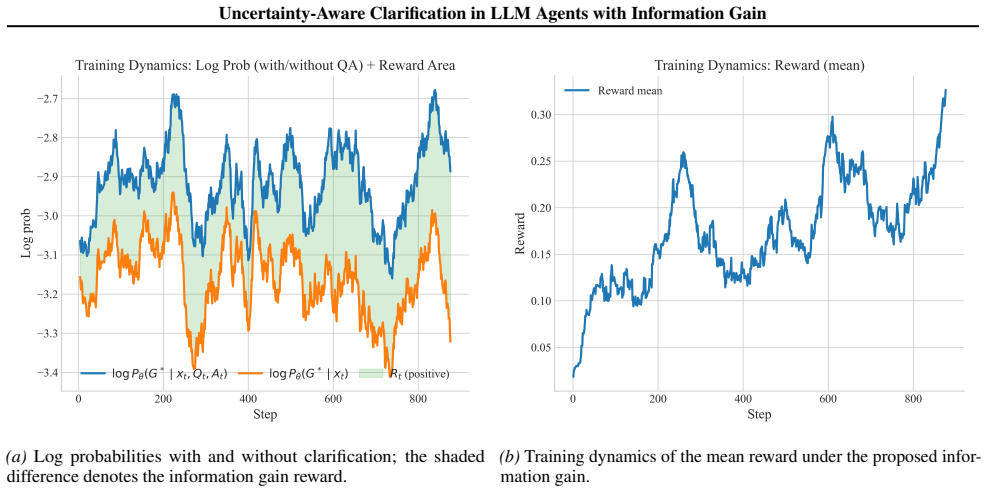
The Information Gain Reward, which scores each clarification exchange by the size of the Bayesian shift it produces in the agent's belief distribution over possible user goals.
If this is right
- Agents achieve higher completion rates on tasks whose instructions contain latent ambiguity.
- The performance gain holds across heterogeneous LLM backbones without per-model redesign.
- The added cost of clarification remains small, measured at roughly one-third of an extra turn on average.
- Clarification behavior becomes an optimizable component inside the agent-tool-user loop rather than a separate heuristic.
Where Pith is reading between the lines
- The same reward could be attached to other agent training loops that already use belief tracking.
- Real-world deployments might see fewer tool-call failures when instructions are vague.
- The method suggests that uncertainty measures derived from posterior updates can serve as general training signals for interactive agents.
Load-bearing premise
That the size of the Bayesian belief update produced by a clarification question reliably predicts whether that question will increase the agent's chance of completing the task.
What would settle it
An experiment in which agents using the information-gain-trained clarifier achieve equal or lower success rates than agents that never clarify, or in which the measured belief updates show no correlation with actual task outcomes.
Figures

read the original abstract
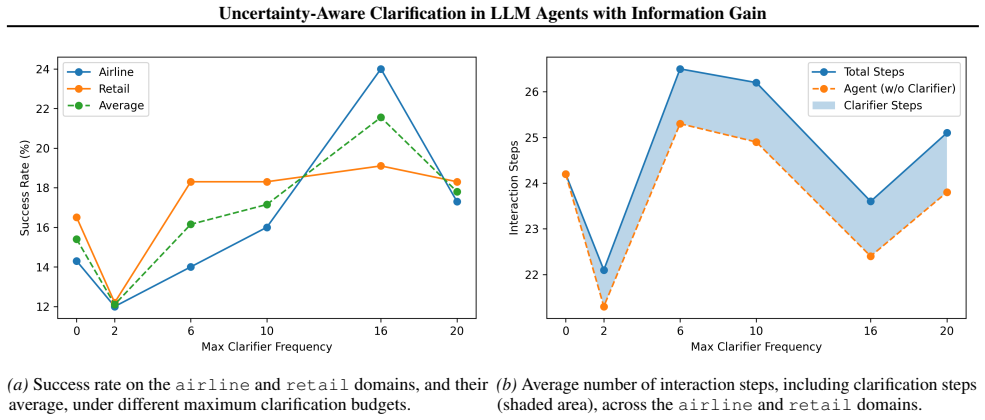
Large Language Model (LLM) agents often operate under underspecified user instructions, where latent uncertainty over user intent leads to erroneous tool actions. To address this challenge, we propose a goal-oriented clarification framework that aligns clarification behavior with ambiguity resolution. Central to our approach is the Information Gain Reward, a metric that quantifies the utility of clarification questions by measuring the Bayesian belief update towards the ground-truth goal induced by the clarification exchange. We train the clarifier (LLM) using this reward to optimize for high information gain, ensuring that clarifications effectively reduce uncertainty and improve task completion within the agent-tool-user environment. We validate our framework within a clarification-enhanced $\tau$-Bench environment, conducting cross-agent evaluations across five heterogeneous backbones. Empirical results demonstrate that our method consistently improves the success rate by 3.7\% over the no-clarification baseline, while adding only 0.3 total interaction steps on average.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a goal-oriented clarification framework for LLM agents that uses an Information Gain Reward, defined as the reduction in uncertainty over a ground-truth goal via Bayesian belief update, to train a clarifier LLM. It evaluates the approach in a clarification-enhanced τ-Bench environment across five heterogeneous agent backbones and reports a consistent 3.7% success-rate improvement over a no-clarification baseline while adding only 0.3 interaction steps on average.
Significance. If the Information Gain Reward is shown to correlate with downstream task success, the framework could offer a principled, uncertainty-aware method for handling underspecified instructions in LLM agents. The cross-backbone evaluation design is a positive feature that would strengthen generalizability claims if supported by detailed statistics.
major comments (3)
- [Abstract] Abstract: the central claim of a consistent 3.7% success-rate gain is presented without error bars, statistical tests, per-backbone breakdowns, or variance measures, preventing verification of whether the improvement is robust or attributable to the proposed reward.
- [Empirical results] Empirical results section: no ablation replaces the Information Gain Reward with random or heuristic rewards, and no per-question correlation is reported between achieved IG values and subsequent success deltas; without this, the performance gain cannot be attributed to the Bayesian-update objective rather than incidental effects of clarification.
- [Information Gain Reward definition] Information Gain Reward definition: the reward is computed toward a ground-truth goal available only during training; the manuscript does not demonstrate that the resulting clarifier generalizes when ground-truth is unavailable at inference time, which is required for the method to be applicable beyond simulation.
minor comments (2)
- [Methods] Clarify the exact form of the Bayesian update (prior, likelihood model, and posterior computation) and whether it assumes access to the agent's internal state.
- [Experimental setup] The τ-Bench environment modifications for clarification should be described with sufficient detail to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us identify areas to strengthen the paper. We provide point-by-point responses below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a consistent 3.7% success-rate gain is presented without error bars, statistical tests, per-backbone breakdowns, or variance measures, preventing verification of whether the improvement is robust or attributable to the proposed reward.
Authors: We agree that providing error bars, statistical tests, and per-backbone breakdowns would enhance the verifiability of our claims. In the revised manuscript, we will include these details in the empirical results section and update the abstract to reference the robustness of the improvement across models. We will also report variance measures and conduct appropriate statistical tests to confirm the significance of the 3.7% gain. revision: yes
-
Referee: [Empirical results] Empirical results section: no ablation replaces the Information Gain Reward with random or heuristic rewards, and no per-question correlation is reported between achieved IG values and subsequent success deltas; without this, the performance gain cannot be attributed to the Bayesian-update objective rather than incidental effects of clarification.
Authors: We recognize the importance of ablations to attribute the gains specifically to the Information Gain Reward. We will incorporate additional experiments in the revised version that replace the Information Gain Reward with random and heuristic alternatives. Furthermore, we will analyze and report correlations between achieved information gain values and success rate improvements on a per-question basis to strengthen the causal link to our proposed objective. revision: yes
-
Referee: [Information Gain Reward definition] Information Gain Reward definition: the reward is computed toward a ground-truth goal available only during training; the manuscript does not demonstrate that the resulting clarifier generalizes when ground-truth is unavailable at inference time, which is required for the method to be applicable beyond simulation.
Authors: The Information Gain Reward is utilized solely during the training of the clarifier to learn an effective policy. Once trained, the clarifier functions at inference time without requiring access to the ground-truth goal, as it has internalized the patterns for generating high-utility clarification questions. We will revise the manuscript to explicitly clarify this training-inference distinction and add an evaluation demonstrating the clarifier's effectiveness in scenarios where ground-truth information is not provided during inference, thereby addressing applicability beyond simulation. revision: yes
Circularity Check
No circularity; Information Gain Reward defined from standard external Bayesian update with independent empirical validation.
full rationale
The paper's central construction defines the Information Gain Reward directly via Bayesian belief update toward a ground-truth goal, a standard external concept with no reduction to the paper's fitted outputs or self-referential loop. Empirical success-rate gains are measured against an external no-clarification baseline in the τ-Bench environment across heterogeneous agents; no equations or claims reduce a prediction to a fitted parameter by construction, and no self-citation is invoked as load-bearing justification. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bayesian belief update toward a known ground-truth goal measures the value of a clarification exchange
invented entities (1)
-
Information Gain Reward
no independent evidence
Reference graph
Works this paper leans on
-
[1]
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Andriushchenko, M., Souly, A., Dziemian, M., Duenas, D., Lin, M., Wang, J., Hendrycks, D., Zou, A., Kolter, Z., Fredrikson, M., et al. Agentharm: A benchmark for measuring harmfulness of llm agents.arXiv preprint arXiv:2410.09024,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
BED-LLM: Intelligent Information Gathering with LLMs and Bayesian Experimental Design
Choudhury, D., Williamson, S., Goli ´nski, A., Miao, N., 9 Uncertainty-Aware Clarification in LLM Agents with Information Gain Smith, F. B., Kirchhof, M., Zhang, Y ., and Rainforth, T. Bed-llm: Intelligent information gathering with llms and bayesian experimental design.arXiv preprint arXiv:2508.21184,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Fu, B., Qiu, Y ., Tang, C., Li, Y ., Yu, H., and Sun, J. A survey on complex question answering over knowledge base: Recent advances and challenges.arXiv preprint arXiv:2007.13069,
-
[4]
AgentBench: Evaluating LLMs as Agents
Li, D., Zhang, Y ., Wang, Z., Tan, S., Kosugi, S., and Oku- mura, M. Active learning for abstractive text summa- rization via llm-determined curriculum and certainty gain maximization. InFindings of the Association for Com- putational Linguistics: EMNLP 2024, pp. 8959–8971, 2024a. Li, M., Zhao, S., Wang, Q., Wang, K., Zhou, Y ., Srivas- tava, S., Gokmen, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Qi, Y ., Peng, H., Wang, X., Xin, A., Liu, Y ., Xu, B., Hou, L., and Li, J. Agentif: Benchmarking instruction following of large language models in agentic scenarios.arXiv preprint arXiv:2505.16944,
-
[6]
Rao, S. and Daum ´e III, H. Learning to ask good ques- tions: Ranking clarification questions using neural ex- pected value of perfect information.arXiv preprint arXiv:1805.04655,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Liu, Z., Zhang, W., et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
HybridFlow: A Flexible and Efficient RLHF Framework
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y ., Lin, H., and Wu, C. Hybridflow: A flexi- ble and efficient rlhf framework.arXiv preprint arXiv: 2409.19256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Llm-as- a-judge & reward model: What they can and cannot do
Son, G., Ko, H., Lee, H., Kim, Y ., and Hong, S. Llm-as- a-judge & reward model: What they can and cannot do. arXiv preprint arXiv:2409.11239,
-
[10]
Structured Uncertainty guided Clarification for LLM Agents
Suri, M., Mathur, P., Lipka, N., Dernoncourt, F., Rossi, R. A., and Manocha, D. Structured uncertainty guided clarification for llm agents.arXiv preprint arXiv:2511.08798,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Wang, G., Dai, S., Ye, G., Gan, Z., Yao, W., Deng, Y ., Wu, X., and Ying, Z. Information gain-based policy optimization: A simple and effective approach for multi- turn llm agents.arXiv preprint arXiv:2510.14967, 2025a. Wang, J., Zerun, M., Li, Y ., Zhang, S., Chen, C., Chen, K., and Le, X. Gta: a benchmark for general tool agents. Advances in Neural Info...
-
[12]
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
Xu, F. F., Song, Y ., Li, B., Tang, Y ., Jain, K., Bao, M., Wang, Z. Z., Zhou, X., Guo, Z., Cao, M., et al. Theagentcom- pany: benchmarking llm agents on consequential real world tasks.arXiv preprint arXiv:2412.14161,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
ReAct: Synergizing Reasoning and Acting in Language Models
Yao, S., Yang, R.-Z., Cui, N., Narasimhan, K., et al. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Yao, S., Shinn, N., Razavi, P., and Narasimhan, K. τ-bench: A benchmark for tool-agent-user interaction in real-world domains, 2024.URL https://arxiv. org/abs/2406.12045,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Survey on Evaluation of LLM-based Agents
Yehudai, A., Eden, L., Li, A., Uziel, G., Zhao, Y ., Bar- Haim, R., Cohan, A., and Shmueli-Scheuer, M. Sur- vey on evaluation of llm-based agents.arXiv preprint arXiv:2503.16416,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Yizhou, C., Jessy, L., Kevin, L., and Dan, K. Clarinet: Aug- menting language models to ask clarification questions for retrieval.arXiv preprint arXiv: 2405.15784,
-
[17]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y ., Zuo, X., Yue, Y ., Fan, T., Liu, G., Liu, L., Liu, X., et al. Dapo: An open-source llm reinforcement learning system at scale, 2025.URL https://arxiv. org/abs/2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Easytool: Enhancing llm-based agents with concise tool instruction
Yuan, S., Song, K., Chen, J., Tan, X., Shen, Y ., Ren, K., Li, D., and Yang, D. Easytool: Enhancing llm-based agents with concise tool instruction. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 951–972,
2025
-
[19]
K., and Chua, T.- S
Zhang, X., Deng, Y ., Ren, Z., Ng, S. K., and Chua, T.- S. Ask-before-plan: Proactive language agents for real- world planning. InFindings of the Association for Com- putational Linguistics: EMNLP 2024, pp. 10836–10863,
2024
-
[20]
Zhou, Z., Feng, X., Zhu, Z., Yao, J., Koyejo, S., and Han, B. From passive to active reasoning: Can large language models ask the right questions under incomplete informa- tion?arXiv preprint arXiv:2506.08295,
-
[21]
Your name is
Can you do that with gift card 7711863? Analysis Redundant Confirmation: The user re-states known preferences. No new entities are introduced. Targeted Elicitation: The agent identifies the missing payment slot and asks for it directly. The user provides the gift card ID. Log Prob (xt) −3.2649 Log Prob (xt, Q, A) −3.3193(%↓) −2.6153(%↑) Reward (Rt) −0.054...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.