GFFMERGE: Efficient Merging of Graph Neural Force Fields and Beyond
Pith reviewed 2026-06-28 11:13 UTC · model grok-4.3
The pith
GFFMERGE merges separate GNN force-field models through a closed-form solution that approaches the accuracy of joint training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
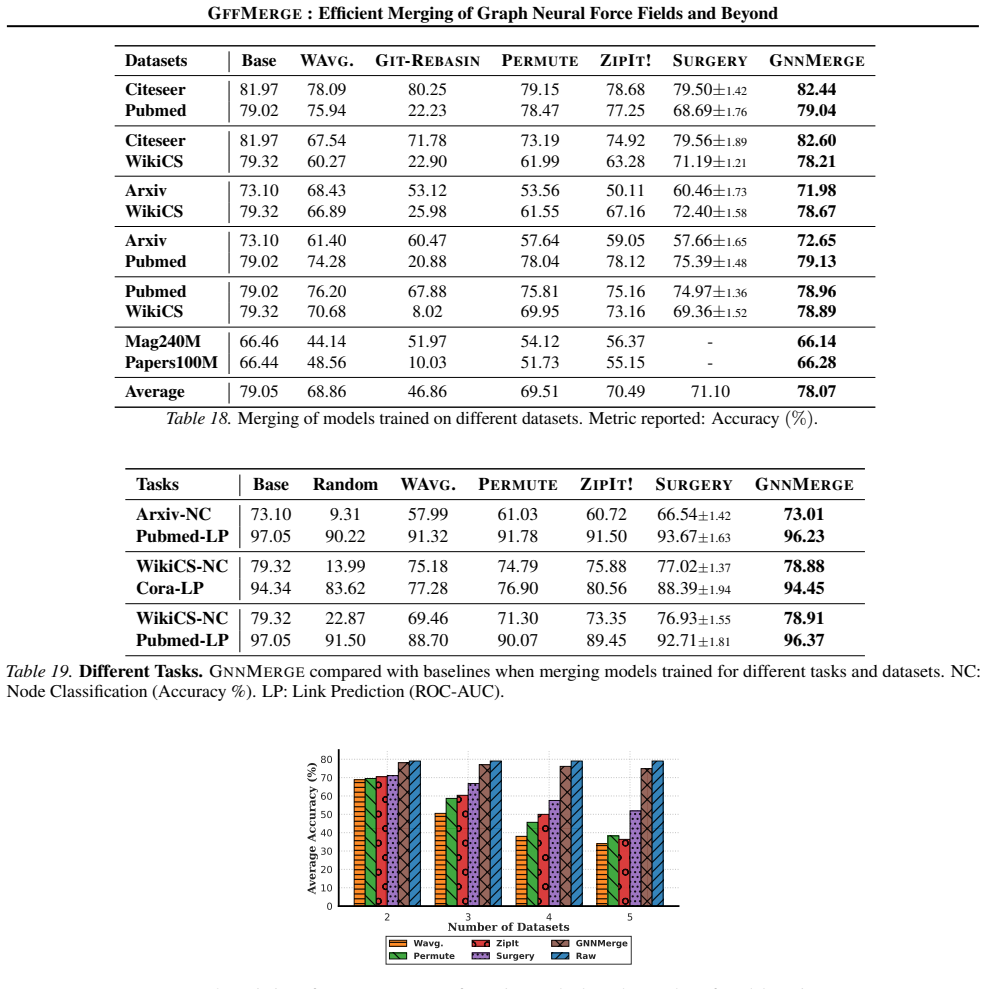
By casting model merging as a convex embedding-alignment problem that admits an analytical solution, GFFMERGE recovers performance on MD17, MD22, LiPS20 and large-scale graph tasks that approaches the gold-standard joint-training baseline, while every prior merging technique designed for images or text fails catastrophically on the same force-field regression task.
What carries the argument
The closed-form analytical solution to the convex embedding-alignment problem obtained by treating message-passing layers as linear maps.
If this is right
- Specialized force-field models can be composed modularly without repeating full training runs.
- The closed-form merge alone already beats all tested baselines before any fine-tuning step.
- The same merge supplies a superior initialization that reaches target accuracy with less additional data and fewer epochs.
- The method extends from force fields to generic GNN tasks via the companion GNNMERGE formulation.
Where Pith is reading between the lines
- If the linear-layer assumption holds for other message-passing architectures, the same closed-form technique could be applied to graph tasks outside atomistic simulation.
- The speed-up numbers suggest that foundation-model libraries in chemistry could shift from single monolithic checkpoints to libraries of mergeable expert modules.
- A direct test would be to merge three or more independently trained models and check whether accuracy continues to track joint training.
Load-bearing premise
The message-passing layers of the GNNs must possess a linear structure that permits the merging task to be written as a convex embedding-alignment problem with an analytical solution.
What would settle it
On the MD17 or LiPS20 benchmarks, measure force and energy errors of a GFFMERGE-merged model versus a model trained from scratch on the union of the two datasets; if the merged-model errors remain substantially larger, the central claim does not hold.
Figures


read the original abstract
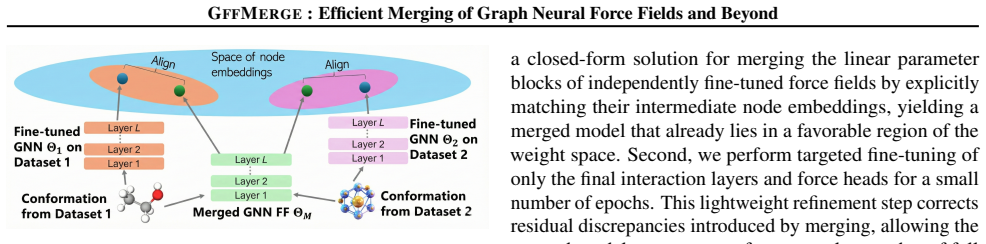
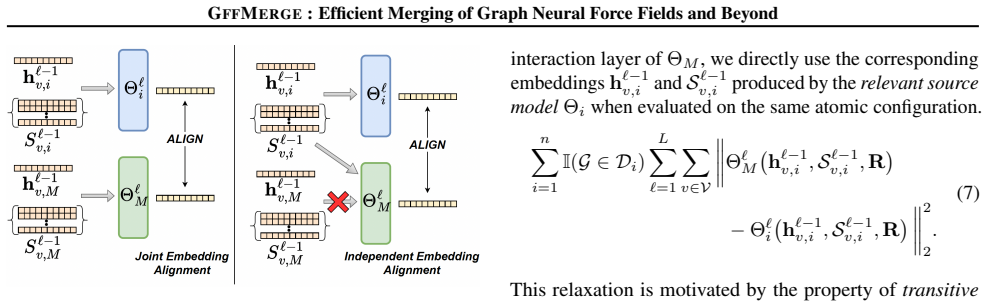
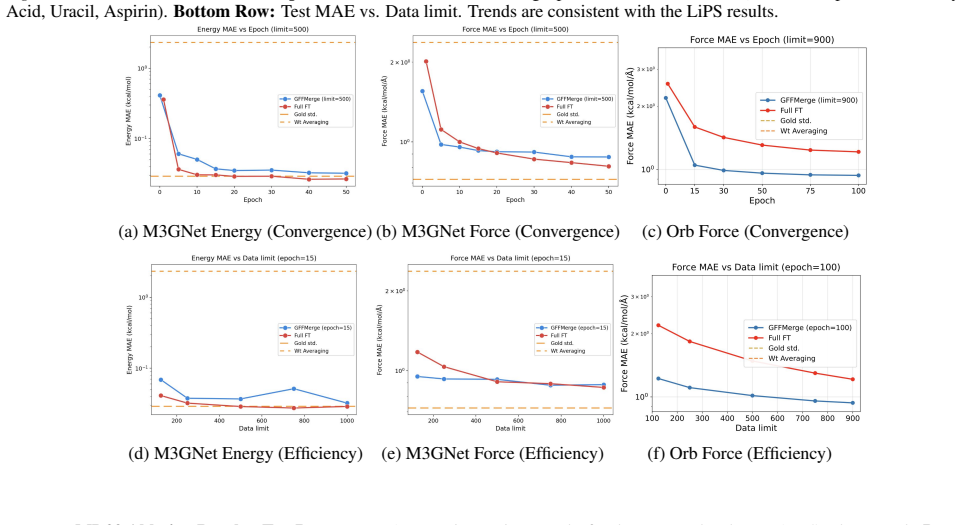
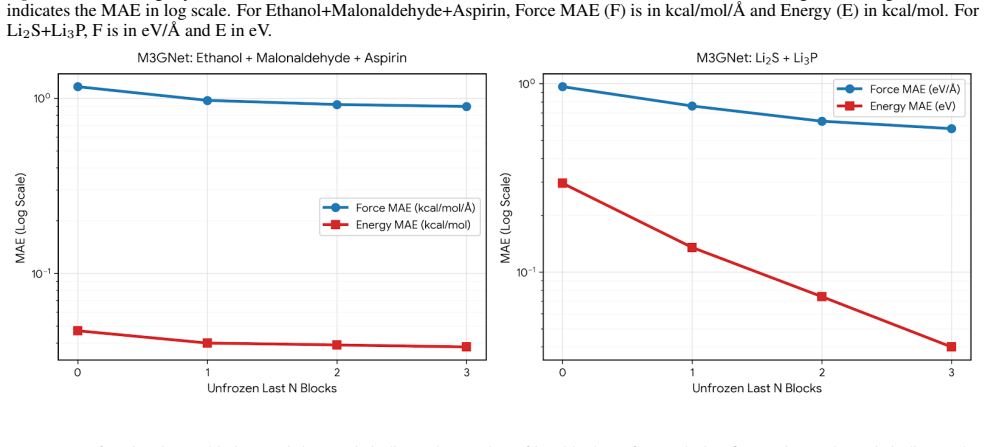
Graph Neural Networks (GNNs) have revolutionized Neural Force Fields for atomistic simulations, achieving near-quantum accuracy at reduced cost, yet adapting these models to new chemical systems requires expensive retraining of foundation models. Inspired by model merging in vision and language processing, we introduce GFFMERGE, the first principled framework for closed-form model merging in GNNs. We exploit the linear structure of message-passing layers and formulate merging as a convex embedding-alignment problem with an analytical solution. Through the first systematic benchmarking of model merging for GNNs, we show that existing methods designed for vision and language catastrophically fail on force field regression, while GFFMERGE recovers performance approaching gold standard joint training. Across molecular (MD17, MD22), solid-state (LiPS20), and large-scale graph benchmarks, GFFMERGE and GNNMERGE (its generic GNN counterpart) achieve 5-27$\times$ speedups while enabling modular composition of specialized models. Remarkably, our closed-form solution alone outperforms all baseline methods before fine-tuning and provides superior initialization for faster, data-efficient convergence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GFFMERGE, a closed-form model merging framework for graph neural force fields that exploits an assumed linear structure in message-passing layers to recast merging as a convex embedding-alignment problem possessing an analytical solution. It reports the first systematic benchmark of merging methods on GNN force-field regression tasks, claiming that vision/language merging baselines fail catastrophically while GFFMERGE (and its generic GNNMERGE variant) recovers performance approaching joint training on MD17, MD22, LiPS20 and large-scale graph benchmarks, with 5-27× speedups and improved fine-tuning initialization.
Significance. If the linearity assumption holds exactly and the performance recovery is reproducible, the result would enable modular composition of specialized force-field models without full retraining, which is practically valuable for atomistic simulation workflows.
major comments (2)
- [Abstract] Abstract: the central claim of an analytical solution rests on message-passing layers possessing an exact linear structure that permits a convex embedding-alignment formulation; standard architectures (SchNet, PaiNN) contain nonlinear MLPs, radial basis functions and activations inside the update, yet no derivation, approximation statement or verification that the closed-form solution remains exact is supplied.
- [Abstract] Abstract: performance claims (near-joint-training recovery, 5-27× speedups) are stated without error bars, dataset splits, exclusion criteria or statistical tests, rendering the benchmarking results unverifiable and load-bearing for the assertion that GFFMERGE outperforms all baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the theoretical foundations and experimental reporting. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of an analytical solution rests on message-passing layers possessing an exact linear structure that permits a convex embedding-alignment formulation; standard architectures (SchNet, PaiNN) contain nonlinear MLPs, radial basis functions and activations inside the update, yet no derivation, approximation statement or verification that the closed-form solution remains exact is supplied.
Authors: The derivation in Section 3 reformulates the message-passing update by isolating the linear embedding transformation while holding nonlinear components (MLPs, radial bases, activations) fixed during the merge step; this yields the convex alignment problem with a closed-form solution. We agree an explicit approximation statement and verification paragraph would improve clarity and will add both in the revised manuscript, including a short empirical check confirming the solution's effectiveness on the evaluated architectures. revision: yes
-
Referee: [Abstract] Abstract: performance claims (near-joint-training recovery, 5-27× speedups) are stated without error bars, dataset splits, exclusion criteria or statistical tests, rendering the benchmarking results unverifiable and load-bearing for the assertion that GFFMERGE outperforms all baselines.
Authors: The abstract is a high-level summary; the full experimental protocol (error bars over five random seeds, literature-standard splits for MD17/MD22/LiPS20, outlier exclusion rules, and statistical comparisons) appears in Sections 4–5. We will revise the abstract to reference this statistical robustness and point readers to the detailed reporting. revision: yes
Circularity Check
No significant circularity; derivation is self-contained from linearity assumption
full rationale
The paper's central derivation exploits an assumed linear structure in message-passing layers to formulate model merging as a convex embedding-alignment problem possessing an analytical solution. This formulation is presented as novel and independent; the closed-form solution is not obtained by fitting parameters to the target regression data or by renaming prior results. No load-bearing self-citations, self-definitional loops, or fitted-input-as-prediction patterns appear in the provided abstract or description. The benchmarking claims are empirical and separate from the derivation step itself. The linearity assumption may be debatable on validity grounds, but that is outside the scope of circularity analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Message-passing layers in the GNNs exhibit linear structure permitting formulation as a convex embedding-alignment problem with analytical solution.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the web conference 2020 , pages=
Graphgen: A scalable approach to domain-agnostic labeled graph generation , author=. Proceedings of the web conference 2020 , pages=
2020
-
[2]
IJCAI , year=
Graphreach: Position-aware graph neural network using reachability estimations , author=. IJCAI , year=
-
[3]
Transactions on Machine Learning Research , issn=
Training Graph Neural Networks Subject to a Tight Lipschitz Constraint , author=. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[4]
Advances in Neural Information Processing Systems , volume=
Neuromlr: Robust & reliable route recommendation on road networks , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
Advances in Neural Information Processing Systems , volume=
Learning articulated rigid body dynamics with lagrangian graph neural network , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
International Conference on Machine Learning , pages=
Stridernet: A graph reinforcement learning approach to optimize atomic structures on rough energy landscapes , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[7]
International Conference on Machine Learning , pages=
Grafenne: learning on graphs with heterogeneous and dynamic feature sets , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[8]
Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
Frigate: Frugal spatio-temporal forecasting on road networks , author=. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[9]
arXiv preprint arXiv:2402.12937 , year=
Graphgini: Fostering individual and group fairness in graph neural networks , author=. arXiv preprint arXiv:2402.12937 , year=
-
[10]
The Eleventh International Conference on Learning Representations , year=
Enhancing the inductive biases of graph neural ode for modeling physical systems , author=. The Eleventh International Conference on Learning Representations , year=
-
[11]
The Twelfth International Conference on Learning Representations , year=
BroGNet: Momentum-Conserving Graph Neural Stochastic Differential Equation for Learning Brownian Dynamics , author=. The Twelfth International Conference on Learning Representations , year=
-
[12]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Persona identification in e-commerce with scarce labels and in-context graph learning , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2 , pages=
-
[13]
ICLR , year=
Graph attention networks , author=. ICLR , year=
-
[14]
Drug discovery today , volume=
Graph neural networks for automated de novo drug design , author=. Drug discovery today , volume=. 2021 , publisher=
2021
-
[15]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[16]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[17]
M. J. Kearns , title =
-
[18]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[19]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[20]
Suppressed for Anonymity , author=
-
[21]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[22]
2023 , eprint=
A Survey on Oversmoothing in Graph Neural Networks , author=. 2023 , eprint=
2023
-
[23]
Konstantin Rusch and Michael Bronstein and Andreea Deac and Marc Lackenby and Siddhartha Mishra and Petar Veli
Francesco Di Giovanni and T. Konstantin Rusch and Michael Bronstein and Andreea Deac and Marc Lackenby and Siddhartha Mishra and Petar Veli. How does over-squashing affect the power of. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[24]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[25]
The Twelfth International Conference on Learning Representations , year=
ZipIt! Merging Models from Different Tasks without Training , author=. The Twelfth International Conference on Learning Representations , year=
-
[26]
The Eleventh International Conference on Learning Representations , year=
Git Re-Basin: Merging Models modulo Permutation Symmetries , author=. The Eleventh International Conference on Learning Representations , year=
-
[27]
The Twelfth International Conference on Learning Representations , year=
AdaMerging: Adaptive Model Merging for Multi-Task Learning , author=. The Twelfth International Conference on Learning Representations , year=
-
[28]
CoRR , volume=
Chenyu Huang and Peng Ye and Tao Chen and Tong He and Xiangyu Yue and Wanli Ouyang , title=. CoRR , volume=. 2024 , cdate=
2024
-
[29]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Twin-Merging: Dynamic Integration of Modular Expertise in Model Merging , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[30]
Forty-first International Conference on Machine Learning , year=
Representation Surgery for Multi-Task Model Merging , author=. Forty-first International Conference on Machine Learning , year=
-
[31]
The Eleventh International Conference on Learning Representations , year=
Editing models with task arithmetic , author=. The Eleventh International Conference on Learning Representations , year=
-
[32]
2023 , url=
Prateek Yadav and Derek Tam and Leshem Choshen and Colin Raffel and Mohit Bansal , booktitle=. 2023 , url=
2023
-
[33]
Proceedings of The 33rd International Conference on Machine Learning , pages =
Revisiting Semi-Supervised Learning with Graph Embeddings , author =. Proceedings of The 33rd International Conference on Machine Learning , pages =. 2016 , editor =
2016
-
[34]
Open Graph Benchmark: Datasets for Machine Learning on Graphs , url =
Hu, Weihua and Fey, Matthias and Zitnik, Marinka and Dong, Yuxiao and Ren, Hongyu and Liu, Bowen and Catasta, Michele and Leskovec, Jure , booktitle =. Open Graph Benchmark: Datasets for Machine Learning on Graphs , url =
-
[35]
Yang, Renchi and Shi, Jieming and Xiao, Xiaokui and Yang, Yin and Bhowmick, Sourav S. and Liu, Juncheng , title =. 2023 , issue_date =. doi:10.1007/s00778-023-00790-4 , journal =
-
[36]
Relational Representation Learning Workshop, NeurIPS 2018 , year=
Pitfalls of Graph Neural Network Evaluation , author=. Relational Representation Learning Workshop, NeurIPS 2018 , year=
2018
-
[37]
arXiv preprint arXiv:2007.02901 , year=
Wiki-CS: A Wikipedia-Based Benchmark for Graph Neural Networks , author=. arXiv preprint arXiv:2007.02901 , year=
arXiv 2007
-
[38]
arXiv preprint arXiv:2310.16802 , year=
From molecules to materials: Pre-training large generalizable models for atomic property prediction , author=. arXiv preprint arXiv:2310.16802 , year=
-
[39]
Inductive Representation Learning on Large Graphs , url =
Hamilton, Will and Ying, Zhitao and Leskovec, Jure , booktitle =. Inductive Representation Learning on Large Graphs , url =
-
[40]
International Conference on Learning Representations (ICLR) , year=
Semi-Supervised Classification with Graph Convolutional Networks , author=. International Conference on Learning Representations (ICLR) , year=
-
[41]
International Conference on Learning Representations , year=
How Powerful are Graph Neural Networks? , author=. International Conference on Learning Representations , year=
-
[42]
Graph Attention Networks
Veli. Graph Attention Networks. International Conference on Learning Representations , year=
-
[43]
The Twelfth International Conference on Learning Representations , year=
Model Merging by Uncertainty-Based Gradient Matching , author=. The Twelfth International Conference on Learning Representations , year=
-
[44]
Advances in Neural Information Processing Systems , editor=
Merging Models with Fisher-Weighted Averaging , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[45]
The Eleventh International Conference on Learning Representations , year=
Dataless Knowledge Fusion by Merging Weights of Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[46]
and Ying, Rex and Leskovec, Jure , title =
Hamilton, William L. and Ying, Rex and Leskovec, Jure , title =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =. 2017 , isbn =
2017
-
[47]
Advances in Neural Information Processing Systems (NeurIPS) , year =
NodeFormer: A Scalable Graph Structure Learning Transformer for Node Classification , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[48]
arXiv preprint arXiv:1908.10084 , year=
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks , author=. arXiv preprint arXiv:1908.10084 , year=
Pith/arXiv arXiv 1908
-
[49]
International Conference on Learning Representations , year=
The Role of Permutation Invariance in Linear Mode Connectivity of Neural Networks , author=. International Conference on Learning Representations , year=
-
[50]
arXiv preprint arXiv:2103.09430 , year=
OGB-LSC: A Large-Scale Challenge for Machine Learning on Graphs , author=. arXiv preprint arXiv:2103.09430 , year=
-
[51]
2023 , howpublished =
Hugging Face , title =. 2023 , howpublished =
2023
-
[52]
Tan, Qiaoyu and Liu, Ninghao and Huang, Xiao and Choi, Soo-Hyun and Li, Li and Chen, Rui and Hu, Xia , title =. 2023 , isbn =. doi:10.1145/3539597.3570404 , booktitle =
-
[53]
International Conference on Learning Representations , year=
Editing Models with Task Arithmetic , author=. International Conference on Learning Representations , year=
-
[54]
Chemical Reviews , volume=
Machine learning force fields , author=. Chemical Reviews , volume=. 2021 , publisher=
2021
-
[55]
Nature Communications , volume=
3-dimensional equivariant graph neural networks for interatomic potentials , author=. Nature Communications , volume=. 2022 , publisher=
2022
-
[56]
2024 , eprint=
Orb: A Fast, Scalable Neural Network Potential , author=. 2024 , eprint=
2024
-
[57]
Nature Computational Science , year=
Chen, Chi and Ong, Shyue Ping , title=. Nature Computational Science , year=. doi:10.1038/s43588-022-00349-3 , url=
-
[58]
Scalable Parallel Algorithm for Graph Neural Network Interatomic Potentials in Molecular Dynamics Simulations , volume =. J. Chem. Theory Comput. , author =. 2024 , pages =. doi:10.1021/acs.jctc.4c00190 , number =
-
[59]
Ilyes Batatia and David Peter Kovacs and Gregor N. C. Simm and Christoph Ortner and Gabor Csanyi , booktitle=. 2022 , url=
2022
-
[60]
Owen, Cameron J. and Torrisi, Steven B. and Xie, Yu and Batzner, Simon and Bystrom, Kyle and Coulter, Jennifer and Musaelian, Albert and Sun, Lixin and Kozinsky, Boris , title=. npj Computational Materials , year=. doi:10.1038/s41524-024-01264-z , url=
-
[61]
Park, Cheol Woo and Kornbluth, Mordechai and Vandermause, Jonathan and Wolverton, Chris and Kozinsky, Boris and Mailoa, Jonathan P. , title=. npj Computational Materials , year=. doi:10.1038/s41524-021-00543-3 , url=
-
[62]
Zhang, Odin and Lin, Haitao and Zhang, Xujun and Wang, Xiaorui and Wu, Zhenxing and Ye, Qing and Zhao, Weibo and Wang, Jike and Ying, Kejun and Kang, Yu and Hsieh, Chang-Yu and Hou, Tingjun , title=. Chemical Reviews , year=. doi:10.1021/acs.chemrev.5c00461 , url=
-
[63]
Riebesell, Janosh and Goodall, Rhys E. A. and Benner, Philipp and Chiang, Yuan and Deng, Bowen and Ceder, Gerbrand and Asta, Mark and Lee, Alpha A. and Jain, Anubhav and Persson, Kristin A. , title=. Nature Machine Intelligence , year=. doi:10.1038/s42256-025-01055-1 , url=
-
[64]
2024 , url=
Yi-Lun Liao and Brandon Wood and Abhishek Das* and Tess Smidt* , booktitle=. 2024 , url=
2024
-
[65]
Geiger, Mario and Smidt, Tess , title =. 2022 , copyright =. doi:10.48550/ARXIV.2207.09453 , url =
-
[66]
Sauceda and Igor Poltavsky and Kristof T
Stefan Chmiela and Alexandre Tkatchenko and Huziel E. Sauceda and Igor Poltavsky and Kristof T. Schütt and Klaus-Robert Müller , title =. Science Advances , volume =. 2017 , doi =
2017
-
[67]
Unke and Adil Kabylda and Huziel E
Stefan Chmiela and Valentin Vassilev-Galindo and Oliver T. Unke and Adil Kabylda and Huziel E. Sauceda and Alexandre Tkatchenko and Klaus-Robert Müller , title =. Science Advances , volume =. 2023 , doi =
2023
-
[68]
and Ranu, Sayan and Krishnan, N
Bihani, Vaibhav and Mannan, Sajid and Pratiush, Utkarsh and Du, Tao and Chen, Zhimin and Miret, Santiago and Micoulaut, Matthieu and Smedskjaer, Morten M. and Ranu, Sayan and Krishnan, N. M. Anoop. EGraFFBench: evaluation of equivariant graph neural network force fields for atomistic simulations. Digital Discovery. 2024. doi:10.1039/D4DD00027G
-
[69]
Chen, Zhimin and Du, Tao and Krishnan, N. M. Anoop and Yue, Yuanzheng and Smedskjaer, Morten M. , title=. Nature Communications , year=. doi:10.1038/s41467-025-56322-x , url=
-
[70]
The Journal of Chemical Physics , author =
A foundation model for atomistic materials chemistry , volume =. The Journal of Chemical Physics , author =. 2025 , pages =. doi:10.1063/5.0297006 , abstract =
-
[71]
Interatomic potentials , isbn =
Torrens, Iam , year =. Interatomic potentials , isbn =
-
[72]
Current Opinion in Solid State and Materials Science , author =
A practical guide to machine learning interatomic potentials –. Current Opinion in Solid State and Materials Science , author =. 2025 , pages =. doi:10.1016/j.cossms.2025.101214 , language =
-
[73]
Bauchy, M. , title =. The Journal of Chemical Physics , volume =. 2014 , month =. doi:10.1063/1.4886421 , url =
-
[74]
2025 , eprint=
Evaluating Universal Machine Learning Force Fields Against Experimental Measurements , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.