PSViT: A Methodology for Structurally Pruning Spiking Vision Transformers
Pith reviewed 2026-06-28 07:46 UTC · model grok-4.3
The pith
PSViT applies structured channel pruning to Spiking Vision Transformers for 22.4% memory reduction with accuracy within 3% of the baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
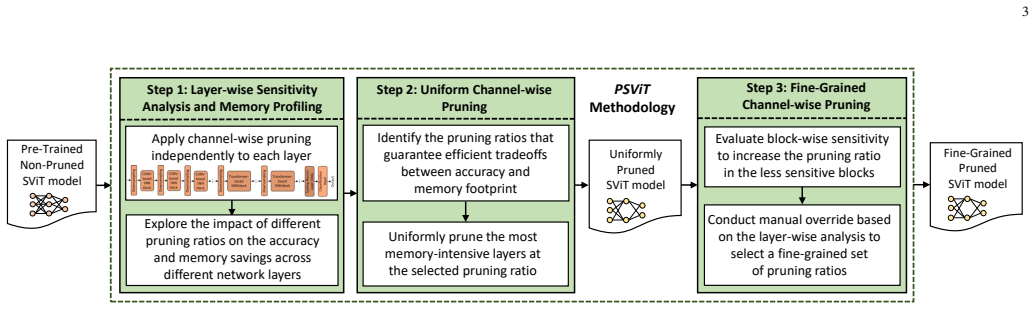
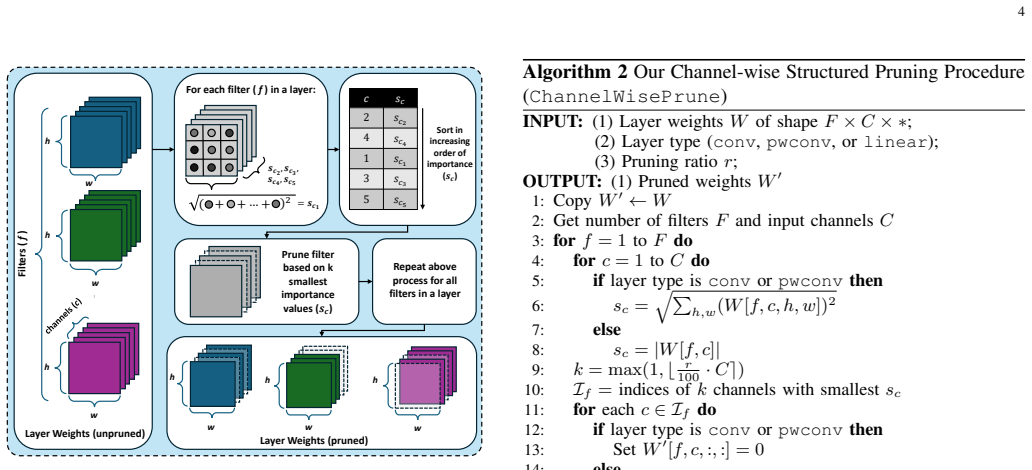
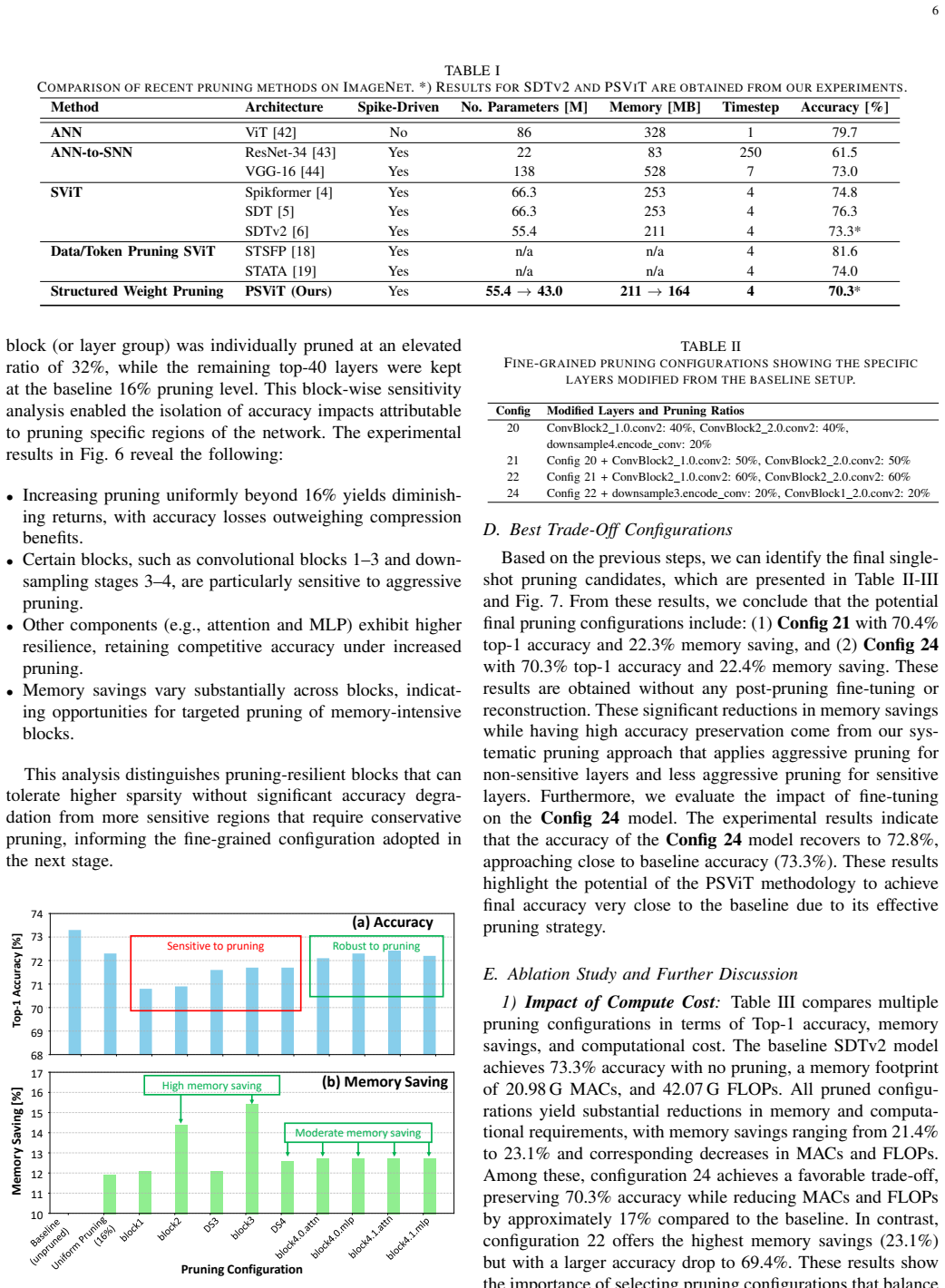
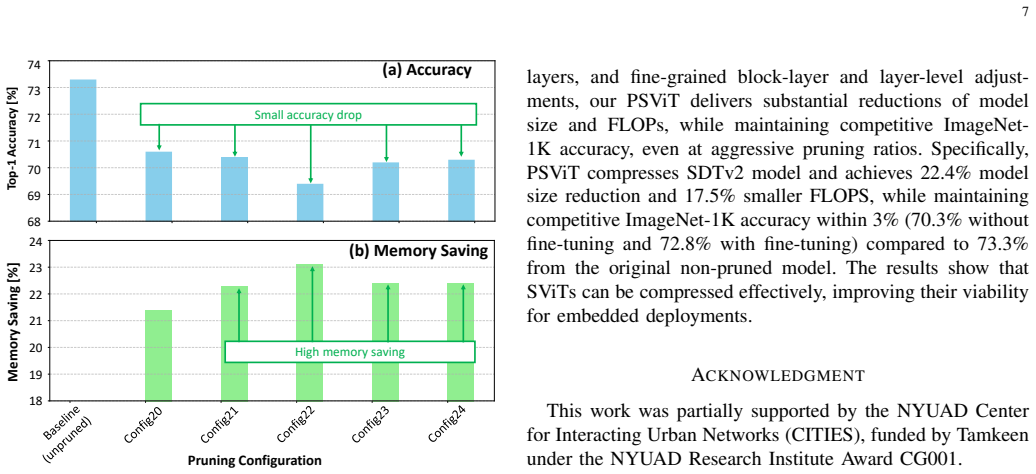
PSViT performs single-shot structured pruning on SViT models by first applying uniform channel-wise filter pruning, then using sensitivity analysis to gauge each layer's impact on accuracy and size, and finally executing fine-grained channel-wise pruning guided by that analysis and the given network structure, resulting in 22.4% memory savings while keeping top-1 accuracy at 70.3% without fine-tuning or 72.8% with fine-tuning versus the original 73.3%.
What carries the argument
The three-step PSViT pipeline of uniform channel-wise filter pruning followed by sensitivity analysis and architecture-aware fine-grained pruning.
If this is right
- Structured pruning removes the need for hardware that supports unstructured sparsity patterns.
- Single-shot pruning shortens the compression workflow for resource-limited platforms.
- Accuracy stays usable after pruning, with optional fine-tuning recovering most of the gap.
- The approach directly targets deployment barriers for spiking models on embedded devices.
Where Pith is reading between the lines
- The same sensitivity-guided channel pruning could transfer to other spiking architectures such as spiking CNNs.
- Combining PSViT with quantization might produce even smaller models without additional hardware changes.
- Testing the pruned models on edge hardware would confirm whether the claimed memory savings translate to actual latency or power gains.
Load-bearing premise
Sensitivity analysis of channel pruning per layer reliably forecasts the accuracy cost and that uniform pruning leaves the spiking network dynamics intact.
What would settle it
Apply the same pruning ratios without running sensitivity analysis and measure whether accuracy falls more than 3% on ImageNet-1K.
Figures


read the original abstract
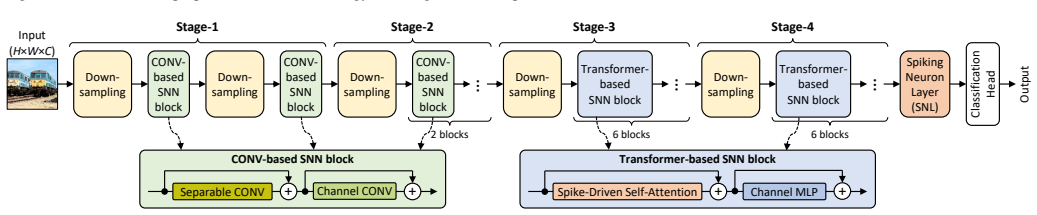
Spiking Vision Transformer (SViT) models are promising low-power ViT models for solving vision-based tasks with state-of-the-art performance. However, their large sizes limit their deployments for resource-constrained embedded platforms, underscoring the needs of model compression. One of prominent compression techniques is pruning, and the state-of-the-art works employ unstructured pruning techniques to compress SViT models. Such techniques require specialized hardware architectures tailored for the sparsity patterns to maximize their efficiency benefits, making this approach not scalable. To address this, we propose PSViT, a novel methodology to perform structured pruning on SViT models, hence making it possible to efficiently accelerate their inference using the existing and widely-used computing architectures. To do this, PSViT employs several key steps: uniform channel-wise filter pruning to structurally eliminate the non-significant weights, sensitivity analysis to evaluate the impact of channel-wise pruning of individual layer on accuracy and network size, as well as fine-grained channel-wise pruning based on the sensitivity analysis and the given network architecture. Experimental results show that PSViT effectively obtains 22.4% memory saving through single-shot pruning, while maintaining high accuracy within 3% (70.3% without fine-tuning and 72.8% with fine-tuning) from the original non-pruned SViT model (73.3%) on the ImageNet-1K. These results also show that the PSViT methodology advances the effort in enabling efficient SViT deployments on resource-constrained applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PSViT, a structured pruning methodology for Spiking Vision Transformers (SViT) that performs uniform channel-wise filter pruning guided by per-layer sensitivity analysis, followed by fine-grained pruning. On ImageNet-1K it reports a single-shot 22.4% memory reduction while keeping top-1 accuracy within 3% of the unpruned baseline (73.3% o 70.3% without fine-tuning, 72.8% with fine-tuning).
Significance. If the central empirical claim holds, the work would provide a practical route to deploy SViT models on commodity hardware without requiring sparsity-aware accelerators, extending structured pruning techniques to the spiking domain. The single-shot aspect and explicit memory metric are potentially useful if the sensitivity analysis and dynamics-preservation assumptions are substantiated.
major comments (2)
- [Abstract] Abstract: the reported accuracy and memory figures are presented without any description of the sensitivity metric (e.g., whether it is accuracy-based, weight-magnitude-based, or spike-rate-aware), the exact per-layer channel pruning ratios, or the baseline SViT architecture details, rendering the 22.4% memory saving and “within 3%” accuracy claim impossible to reproduce or verify from the given information.
- [Abstract] Abstract / methodology description: the central assumption that uniform channel-wise pruning preserves spiking network dynamics is unsupported; no post-pruning measurements of spike-rate histograms, inter-spike intervals, or energy-per-inference are reported, so it is unclear whether the pruned model still exhibits the temporal behavior that justifies the original SViT design.
minor comments (1)
- [Abstract] The abstract states “state-of-the-art performance” for the baseline SViT without citing the specific prior SViT results or datasets used for that comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate the planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported accuracy and memory figures are presented without any description of the sensitivity metric (e.g., whether it is accuracy-based, weight-magnitude-based, or spike-rate-aware), the exact per-layer channel pruning ratios, or the baseline SViT architecture details, rendering the 22.4% memory saving and “within 3%” accuracy claim impossible to reproduce or verify from the given information.
Authors: We agree that the abstract should contain more detail for immediate reproducibility. The sensitivity metric combines per-layer accuracy impact with network size reduction; pruning ratios are derived layer-wise from this analysis rather than being uniform across the model; the baseline is the standard SViT architecture referenced in Section 3. We will revise the abstract to state these elements explicitly while preserving its length. revision: yes
-
Referee: [Abstract] Abstract / methodology description: the central assumption that uniform channel-wise pruning preserves spiking network dynamics is unsupported; no post-pruning measurements of spike-rate histograms, inter-spike intervals, or energy-per-inference are reported, so it is unclear whether the pruned model still exhibits the temporal behavior that justifies the original SViT design.
Authors: The manuscript justifies the pruning approach through accuracy preservation after sensitivity-guided channel removal, treating accuracy as the primary indicator that core temporal computation is retained. Direct post-pruning spike-rate or energy measurements are not currently reported. We will expand the discussion section to clarify the assumption and its grounding in accuracy results; adding new empirical measurements would require additional experiments and is noted as future work. revision: partial
Circularity Check
No significant circularity; results are direct experimental measurements
full rationale
The paper describes a pruning methodology (uniform channel-wise filter pruning guided by sensitivity analysis) and reports measured outcomes (22.4% memory reduction, top-1 accuracy of 70.3%/72.8% vs. 73.3% baseline on ImageNet-1K). No equations, predictions, or first-principles derivations are presented that reduce to fitted parameters or self-citations by construction. The central claims rest on empirical evaluation rather than any self-referential loop, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An image is worth 16x16 words: Transformers for image recogni- tion at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, and et al., “An image is worth 16x16 words: Transformers for image recogni- tion at scale,” inInternational Conference on Learning Representations (ICLR), 2021
2021
-
[2]
Training data-efficient image transformers & distillation through attention,
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. J ´egou, “Training data-efficient image transformers & distillation through attention,” inInternational conference on machine learning. PMLR, 2021, pp. 10 347–10 357
2021
-
[3]
Transformers in vision: A survey,
S. Khan, M. Naseer, M. Hayat, S. W. Zamir, F. S. Khan, and M. Shah, “Transformers in vision: A survey,”ACM Computing Surveys (CSUR), vol. 54, no. 10s, pp. 1–41, 2022
2022
-
[4]
Spikformer: When spiking neural network meets transformer,
Z. Zhou, Y . Zhu, C. He, Y . Wang, S. Yan, Y . Tian, and L. Yuan, “Spikformer: When spiking neural network meets transformer,” in11th International Conference on Learning Representations (ICLR), 2023
2023
-
[5]
Spike- driven transformer,
M. Yao, J. Hu, Z. Zhou, L. Yuan, Y . Tian, B. XU, and G. Li, “Spike- driven transformer,” inThe 37th Conf. on Neural Information Processing Systems (NeurIPS), 2023
2023
-
[6]
Spike-driven transformer v2: Meta spiking neural network architecture inspiring the design of next-generation neuromorphic chips,
M. Yao, J. Hu, T. Hu, Y . Xu, Z. Zhou, Y . Tian, B. XU, and G. Li, “Spike-driven transformer v2: Meta spiking neural network architecture inspiring the design of next-generation neuromorphic chips,” inThe 12th Int. Conf. on Learning Representations (ICLR), 2024
2024
-
[7]
Fspinn: An optimization framework for memory-efficient and energy-efficient spiking neural networks,
R. V . W. Putra and M. Shafique, “Fspinn: An optimization framework for memory-efficient and energy-efficient spiking neural networks,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD), vol. 39, no. 11, pp. 3601–3613, 2020
2020
-
[8]
Stdp-based pruning of connections and weight quantization in spiking neural networks for energy-efficient recognition,
N. Rathi, P. Panda, and K. Roy, “Stdp-based pruning of connections and weight quantization in spiking neural networks for energy-efficient recognition,”IEEE Trans. on Computer-Aided Design of Integrated Circuits and Systems (TCAD), vol. 38, no. 4, pp. 668–677, April 2019
2019
-
[9]
Optimizing the energy consumption of spiking neural networks for neuromorphic applications,
M. Sorbaro, Q. Liu, M. Bortone, and S. Sheik, “Optimizing the energy consumption of spiking neural networks for neuromorphic applications,” Frontiers in Neuroscience (FNINS), vol. 14, p. 662, 2020
2020
-
[10]
A novel conversion method for spiking neural network using median quantization,
C. Zou, X. Cui, J. Ge, H. Ma, and X. Wang, “A novel conversion method for spiking neural network using median quantization,” inIEEE Int. Symp. on Circuits and Systems (ISCAS), 2020, pp. 1–5
2020
-
[11]
Q-spinn: A framework for quantizing spiking neural networks,
R. V . W. Putra and M. Shafique, “Q-spinn: A framework for quantizing spiking neural networks,” inInternational Joint Conference on Neural Networks (IJCNN), 2021, pp. 1–8
2021
-
[12]
Qsvit: A methodology for quantizing spiking vision transformers,
R. V . W. Putra, S. Iftikhar, and M. Shafique, “Qsvit: A methodology for quantizing spiking vision transformers,” in2025 International Joint Conference on Neural Networks (IJCNN), 2025, pp. 1–8
2025
-
[13]
S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,”arXiv preprint arXiv:1510.00149, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[14]
Pruning filters for efficient convnets,
H. Li, A. Kadav, I. Durdanovic, H. Samet, and H. P. Graf, “Pruning filters for efficient convnets,” inInternational Conference on Learning Representations (ICLR), 2017
2017
-
[15]
Prunet: Class- blind pruning method for deep neural networks,
A. Marchisio, M. A. Hanif, M. Martina, and M. Shafique, “Prunet: Class- blind pruning method for deep neural networks,” in2018 International Joint Conference on Neural Networks (IJCNN). IEEE, 2018, pp. 1–8. 8
2018
-
[16]
Savit: Structure-aware vision transformer pruning via collaborative optimization,
C. Zheng, K. Zhang, Z. Yang, W. Tan, J. Xiao, Y . Ren, S. Puet al., “Savit: Structure-aware vision transformer pruning via collaborative optimization,”Advances in Neural Information Processing Systems, vol. 35, pp. 9010–9023, 2022
2022
-
[17]
Width & depth pruning for vision transformers,
F. Yu, K. Huang, M. Wang, Y . Cheng, W. Chu, and L. Cui, “Width & depth pruning for vision transformers,” inProceedings of the AAAI conference on artificial intelligence, vol. 36, no. 3, 2022, pp. 3143–3151
2022
-
[18]
Spatial–temporal spiking feature pruning in spiking transformer,
Z. Zhou, K. Che, J. Niu, M. Yao, G. Li, L. Yuan, G. Luo, and Y . Zhu, “Spatial–temporal spiking feature pruning in spiking transformer,”IEEE Transactions on Cognitive and Developmental Systems (TCDS), vol. 17, no. 3, pp. 644–658, 2025
2025
-
[19]
Towards efficient spiking transformer: a token sparsification framework for training and inference acceleration,
Z. Zhuge, P. Wang, X. Yao, and J. Cheng, “Towards efficient spiking transformer: a token sparsification framework for training and inference acceleration,” inForty-first International Conference on Machine Learn- ing (ICML), 2024
2024
-
[20]
Sparsespikformer: A co-design framework for token and weight pruning in spiking transformer,
Y . Liu, S. Xiao, B. Li, and Z. Yu, “Sparsespikformer: A co-design framework for token and weight pruning in spiking transformer,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 6410–6414
2024
-
[21]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255
2009
-
[22]
Brainchip akida is a fast learner, spiking-neural-network processor identifies patterns in unlabeled data,
M. Demler, “Brainchip akida is a fast learner, spiking-neural-network processor identifies patterns in unlabeled data,”The Linley Group: Microprocessor Report, vol. 28, 2019
2019
-
[23]
What is the akida event domain neural processor?
B. M. Posey, “What is the akida event domain neural processor?” BrainChip, Inc., 2022
2022
-
[24]
Spiking neural network integrated circuits: A review of trends and future directions,
A. Basu, L. Deng, C. Frenkel, and X. Zhang, “Spiking neural network integrated circuits: A review of trends and future directions,” inCICC, 2022, pp. 1–8
2022
-
[25]
Softsnn: Low-cost fault tolerance for spiking neural network accelerators under soft errors,
R. V . W. Putra, M. A. Hanif, and M. Shafique, “Softsnn: Low-cost fault tolerance for spiking neural network accelerators under soft errors,” in The 59th ACM/IEEE Design Automation Conference (DAC), 2022, pp. 151–156
2022
-
[26]
Spikingjelly: An open-source machine learning infrastructure platform for spike-based intelligence,
W. Fang, Y . Chen, J. Ding, Z. Yu, T. Masquelier, D. Chen, L. Huang, H. Zhou, G. Li, and Y . Tian, “Spikingjelly: An open-source machine learning infrastructure platform for spike-based intelligence,”Science Advances, vol. 9, no. 40, 2023
2023
-
[27]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” inIEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2009, pp. 248–255
2009
-
[28]
Networks of spiking neurons: The third generation of neural network models,
W. Maass, “Networks of spiking neurons: The third generation of neural network models,”Neural networks, vol. 10, no. 9, pp. 1659–1671, 1997
1997
-
[29]
Spyketorch: Efficient simulation of convolutional spiking neural net- works with at most one spike per neuron,
M. Mozafari, M. Ganjtabesh, A. Nowzari-Dalini, and T. Masquelier, “Spyketorch: Efficient simulation of convolutional spiking neural net- works with at most one spike per neuron,”Frontiers in Neuroscience, vol. 13, p. 625, 2019
2019
-
[30]
Loihi: A neuromorphic manycore processor with on-chip learning,
M. Davies, N. Srinivasa, T. Lin, G. Chinya, Y . Cao, S. H. Choday, G. Dimou, P. Joshi, N. Imam, S. Jain, Y . Liao, C. Lin, A. Lines, R. Liu, D. Mathaikutty, S. McCoy, A. Paul, J. Tse, G. Venkataramanan, Y . Weng, A. Wild, Y . Yang, and H. Wang, “Loihi: A neuromorphic manycore processor with on-chip learning,”IEEE Micro, vol. 38, no. 1, pp. 82– 99, Jan 2018
2018
-
[31]
Truenorth: Design and tool flow of a 65 mw 1 million neuron programmable neurosynaptic chip,
F. Akopyan, J. Sawada, A. Cassidy, R. Alvarez-Icaza, J. Arthur, P. Merolla, N. Imam, Y . Nakamura, P. Datta, G. Nam, B. Taba, M. Beakes, B. Brezzo, J. B. Kuang, R. Manohar, W. P. Risk, B. Jackson, and D. S. Modha, “Truenorth: Design and tool flow of a 65 mw 1 million neuron programmable neurosynaptic chip,”IEEE Transactions on Computer-Aided Design of Int...
2015
-
[32]
Unsupervised learning of digit recognition using spike-timing-dependent plasticity,
P. Diehl and M. Cook, “Unsupervised learning of digit recognition using spike-timing-dependent plasticity,”Frontiers in Computational Neuroscience, vol. 9, p. 99, 2015
2015
-
[33]
Fast and efficient information transmission with burst spikes in deep spiking neural networks,
S. Park, S. Kim, H. Choe, and S. Yoon, “Fast and efficient information transmission with burst spikes in deep spiking neural networks,” inProc. of DAC, 2019, p. 53
2019
-
[34]
T2fsnn: Deep spiking neural networks with time-to-first-spike coding,
S. Park, S. Kim, B. Na, and S. Yoon, “T2fsnn: Deep spiking neural networks with time-to-first-spike coding,” inProc. of DAC, 2020
2020
-
[35]
Topspark: a timestep optimiza- tion methodology for energy-efficient spiking neural networks on au- tonomous mobile agents,
R. V . W. Putra and M. Shafique, “Topspark: a timestep optimiza- tion methodology for energy-efficient spiking neural networks on au- tonomous mobile agents,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 3561–3567
2023
-
[36]
Surrogate gradient learning in spiking neural networks: Bringing the power of gradient-based opti- mization to spiking neural networks,
E. O. Neftci, H. Mostafa, and F. Zenke, “Surrogate gradient learning in spiking neural networks: Bringing the power of gradient-based opti- mization to spiking neural networks,”IEEE Signal Processing Magazine, vol. 36, no. 6, pp. 51–63, 2019
2019
-
[37]
Spikenas: A fast memory-aware neural architecture search framework for spiking neural network-based embedded ai systems,
R. V . W. Putra and M. Shafique, “Spikenas: A fast memory-aware neural architecture search framework for spiking neural network-based embedded ai systems,”IEEE Transactions on Artificial Intelligence, vol. 7, no. 2, pp. 947–959, 2026
2026
-
[38]
Continual learning with neuromorphic computing: Foundations, meth- ods, and emerging applications,
M. F. Minhas, R. V . W. Putra, F. Awwad, O. Hasan, and M. Shafique, “Continual learning with neuromorphic computing: Foundations, meth- ods, and emerging applications,”IEEE Access, vol. 13, pp. 124 824– 124 873, 2025
2025
-
[39]
Spike-driven transformer v2: Meta spiking neural network architecture inspiring the design of next-generation neuromorphic chips,
M. Yao, J. Hu, T. Hu, Y . Xu, Z. Zhou, Y . Tian, B. XU, and G. Li, “Spike-driven transformer v2: Meta spiking neural network architecture inspiring the design of next-generation neuromorphic chips,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=1SIBN5Xyw7
2024
-
[40]
A survey on deep neural network pruning: Taxonomy, comparison, analysis, and recommendations,
H. Cheng, M. Zhang, and J. Q. Shi, “A survey on deep neural network pruning: Taxonomy, comparison, analysis, and recommendations,”IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 46, no. 12, pp. 10 558–10 578, 2024
2024
-
[41]
Unified data-free com- pression: Pruning and quantization without fine-tuning,
S. Bai, J. Chen, X. Shen, Y . Qian, and Y . Liu, “Unified data-free com- pression: Pruning and quantization without fine-tuning,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 5876–5885
2023
-
[42]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,” inInt. Conf. on Learning Representations (ICLR), 2021
2021
-
[43]
Enabling deep spiking neural networks with hybrid conversion and spike timing dependent backpropagation,
N. Rathi, G. Srinivasan, P. Panda, and K. Roy, “Enabling deep spiking neural networks with hybrid conversion and spike timing dependent backpropagation,” inInt. Conf. on Learning Representations (ICLR), 2020
2020
-
[44]
Fast-snn: fast spiking neural network by converting quantized ann,
Y . Hu, Q. Zheng, X. Jiang, and G. Pan, “Fast-snn: fast spiking neural network by converting quantized ann,”IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.