IdEst: Assessing Self-Supervised Learning Representations via Intrinsic Dimension
Pith reviewed 2026-06-28 11:14 UTC · model grok-4.3
The pith
The intrinsic dimension of self-supervised representations estimated via minimum spanning tree correlates with downstream linear probe performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
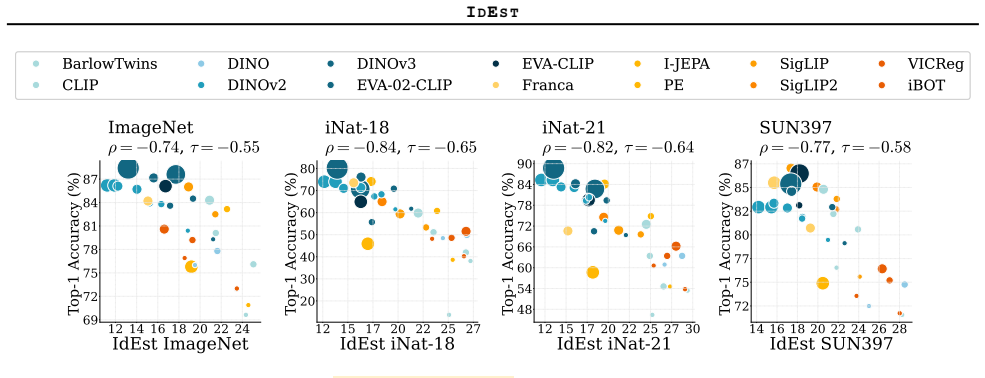
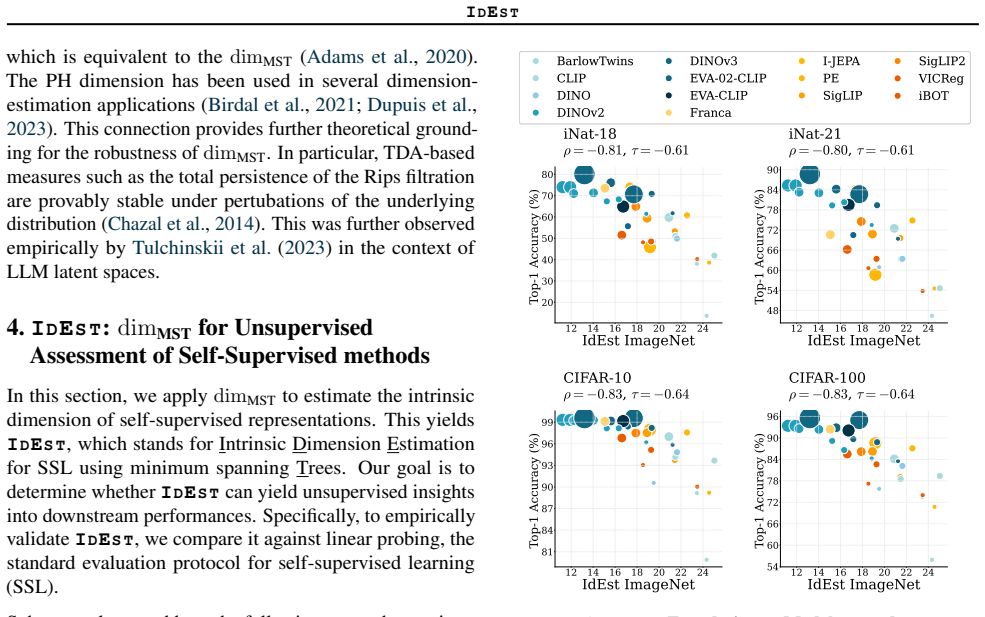
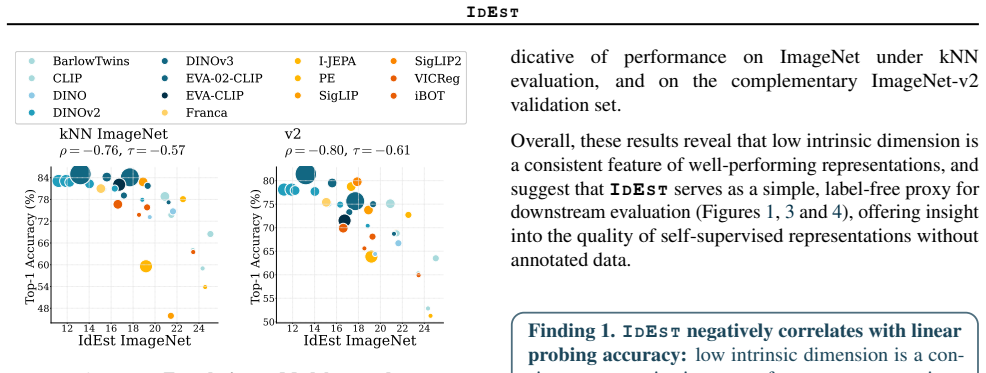
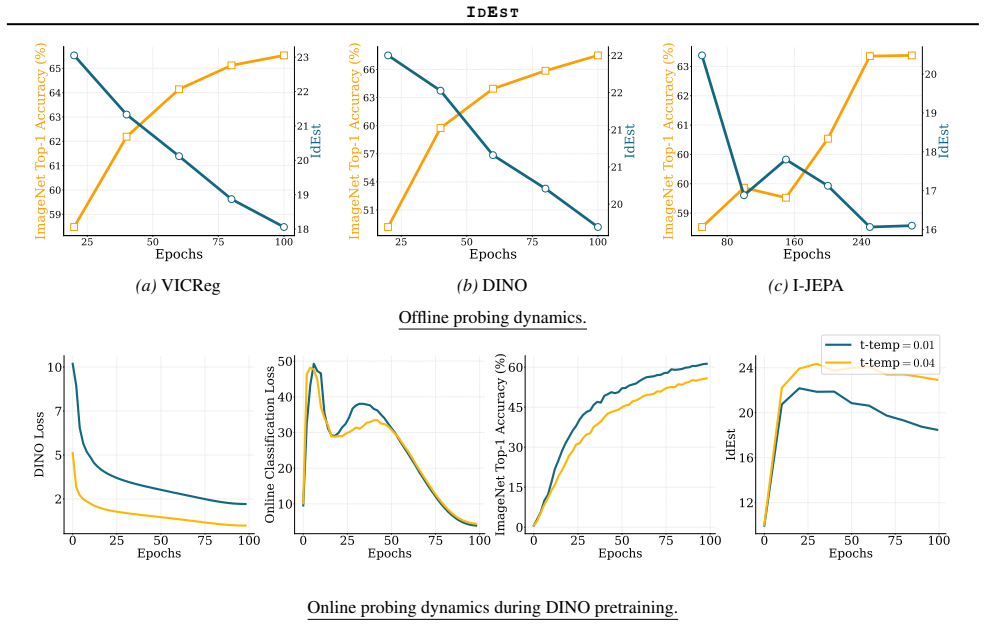
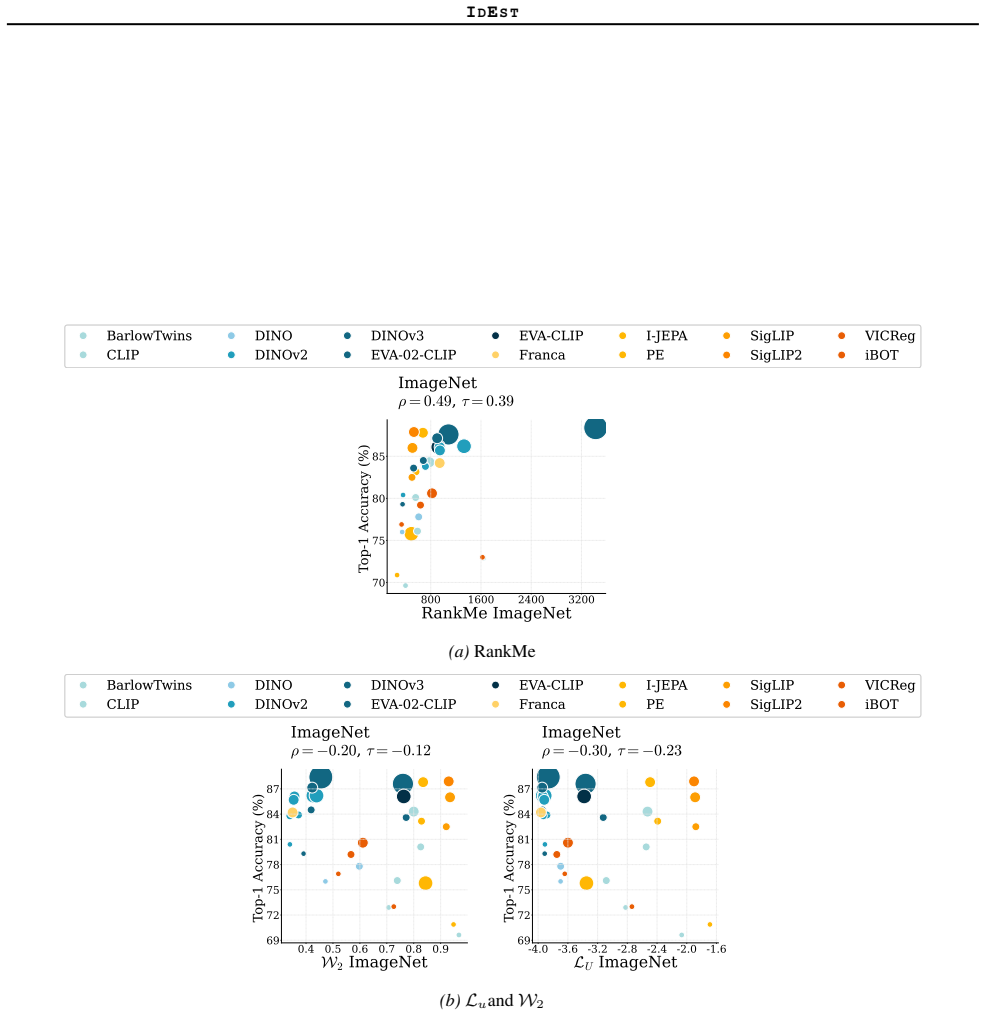
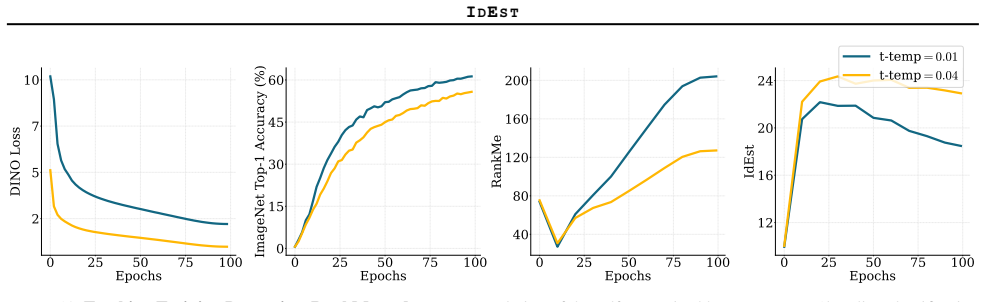
IdEst applies the Minimum Spanning Tree dimension estimator to SSL representation spaces and finds that the resulting intrinsic dimension values correlate strongly with downstream linear probe performances, providing a geometric proxy that reduces reliance on supervised evaluation for model assessment and tuning.
What carries the argument
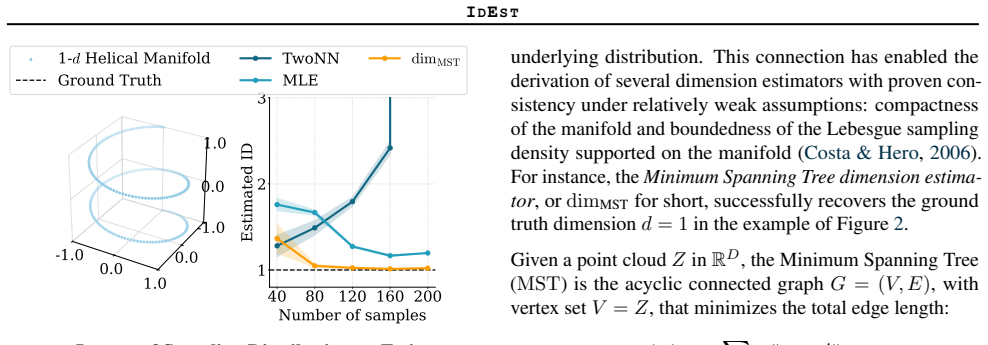
The Minimum Spanning Tree dimension estimator (dim_MST) applied to the embedding space produced by SSL models.
If this is right
- IdEst can serve as a cheaper complement or alternative to linear probing for ranking SSL representations.
- Hyperparameter search in SSL pretraining can proceed with lower computational cost by using IdEst scores.
- Intrinsic dimension functions as a geometric indicator of how well an SSL representation will transfer to supervised tasks.
- The correlation between estimated dimension and probe performance holds across varied datasets, models, and objectives.
Where Pith is reading between the lines
- If intrinsic dimension reflects manifold complexity, representations whose dimension better matches the underlying data structure may support stronger generalization.
- The same MST-based estimator could be tested on representations from supervised or other unsupervised methods to check whether the correlation pattern generalizes.
- Optimizing pretraining objectives explicitly toward target intrinsic dimension values might yield representations that perform better on linear probes.
Load-bearing premise
The Minimum Spanning Tree dimension estimator captures the geometric properties of the representation space that determine downstream generalization performance.
What would settle it
Finding a dataset, architecture, or SSL objective where the correlation between dim_MST estimates and linear probe accuracy is weak or absent would falsify the central claim.
Figures

read the original abstract
Self-supervised learning (SSL) has emerged as a powerful paradigm for learning meaningful representations from unlabeled data. However, the standard protocol for evaluating these representations, linear probing, is computationally expensive, sensitive to hyperparameters, and provides limited insight into the geometric structure of the representation space. In this work, motivated by connections between neural network generalization and intrinsic dimension (ID) we propose IdEst, a method for estimating the ID of SSL representations via the Minimum Spanning Tree dimension estimator ($\mathrm{dim}_\mathrm{MST}$). Across diverse datasets, architectures, and SSL pretraining objectives, we show that IdEst strongly correlates with downstream linear probe performances. Furthermore, we demonstrate that IdEst enables efficient hyperparameter selection, significantly reducing the computational cost compared to supervised alternatives. Our results highlight intrinsic dimensionality as a principled geometric proxy for assessing SSL representations, complementing standard supervised probing protocols.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes IdEst, which estimates the intrinsic dimension (ID) of SSL representations using the Minimum Spanning Tree dimension estimator (dim_MST). It reports that this ID estimate exhibits strong correlation with downstream linear-probe accuracy across multiple datasets, architectures, and pretraining objectives, and further shows that IdEst can be used for efficient hyperparameter selection without requiring labeled data or full supervised evaluation.
Significance. If the reported correlations are robust, the work supplies a computationally cheap geometric diagnostic that complements linear probing and could accelerate SSL model selection. The approach builds on established ID estimators and provides an empirical link between representation geometry and generalization that is directly testable. Reproducibility of the correlation experiments and the hyperparameter-selection results would be the primary source of impact.
major comments (3)
- [§4.2, Table 2] §4.2, Table 2: the reported Pearson correlations between dim_MST and linear-probe accuracy are given without error bars or bootstrap intervals; it is therefore impossible to assess whether the claimed 'strong correlation' is statistically distinguishable from moderate values once variability across random seeds and data splits is accounted for.
- [§3.1, Eq. (3)] §3.1, Eq. (3): the definition of dim_MST is taken from the literature without re-derivation; however, the paper does not verify that the finite-sample bias correction remains valid for the high-dimensional, non-uniform distributions typical of SSL embeddings, which could systematically affect the reported ID values.
- [§4.3] §4.3: the hyperparameter-selection experiment compares IdEst-based selection against random search but does not include a supervised linear-probe baseline with the same computational budget; without this control it is unclear whether the reported efficiency gain is specific to the ID estimator or simply a consequence of any cheap proxy.
minor comments (3)
- [Figure 3] Figure 3 caption: the color scale for the correlation heatmaps is not labeled with numerical values, making it difficult to read the exact correlation magnitudes.
- [§2] §2: the related-work discussion of intrinsic-dimension estimators omits the recent MST-based refinements that include explicit concentration bounds; adding these references would strengthen the methodological grounding.
- [Appendix A.1] Appendix A.1: the list of SSL objectives and datasets is complete, but the exact random seeds and data-split indices used for each experiment are not provided, hindering exact reproduction.
Simulated Author's Rebuttal
Thank you for the constructive comments and the positive overall assessment. We address each major comment point by point below.
read point-by-point responses
-
Referee: [§4.2, Table 2] the reported Pearson correlations between dim_MST and linear-probe accuracy are given without error bars or bootstrap intervals; it is therefore impossible to assess whether the claimed 'strong correlation' is statistically distinguishable from moderate values once variability across random seeds and data splits is accounted for.
Authors: We agree that bootstrap intervals would strengthen the statistical interpretation. In the revised manuscript we will recompute the Pearson correlations with bootstrap confidence intervals over multiple random seeds and data splits to confirm that the reported correlations remain robustly strong. revision: yes
-
Referee: [§3.1, Eq. (3)] the definition of dim_MST is taken from the literature without re-derivation; however, the paper does not verify that the finite-sample bias correction remains valid for the high-dimensional, non-uniform distributions typical of SSL embeddings, which could systematically affect the reported ID values.
Authors: Eq. (3) reproduces the standard dim_MST definition from the literature; the paper's focus is its empirical use on SSL representations. We will add a short discussion noting the assumptions of the bias correction and that its behavior on high-dimensional non-uniform embeddings remains an open question for future study. revision: partial
-
Referee: [§4.3] the hyperparameter-selection experiment compares IdEst-based selection against random search but does not include a supervised linear-probe baseline with the same computational budget; without this control it is unclear whether the reported efficiency gain is specific to the ID estimator or simply a consequence of any cheap proxy.
Authors: The experiment demonstrates label-free hyperparameter selection. A supervised linear-probe baseline requires labels and therefore cannot operate under the same (label-free) constraints; random search is the appropriate unsupervised control. We will revise the text to emphasize this distinction more clearly. revision: no
Circularity Check
No significant circularity
full rationale
The paper's central claim is an empirical correlation between IdEst (dim_MST-based intrinsic dimension estimates) and linear probe accuracy, observed across datasets, architectures, and SSL objectives. No derivation, equation, or fitting procedure is described that reduces a claimed prediction to its own inputs by construction. The method adopts the existing Minimum Spanning Tree estimator without re-deriving it from the target correlation, and no self-citation chain or ansatz smuggling is invoked to justify the core result. The reported correlation is therefore an independent empirical finding rather than a tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On the notion of entropy , author =. Publ. Math. Inst. Hungarian Acad. Sci. , volume =. 1956 , note =
1956
-
[2]
Hentschel and Itamar Procaccia , abstract =
H.G.E. Hentschel and Itamar Procaccia , abstract =. The infinite number of generalized dimensions of fractals and strange attractors , journal =. 1983 , issn =. doi:https://doi.org/10.1016/0167-2789(83)90235-X , url =
-
[3]
Colorful image colorization , author=
-
[4]
Split-brain autoencoders: Unsupervised learning by cross-channel prediction , author=
-
[5]
Unsupervised Representation Learning by Predicting Image Rotations , author=
-
[6]
VICReg: Variance-Invariance-Covariance Regularization For Self-Supervised Learning , author=
-
[7]
A simple framework for contrastive learning of visual representations , author=
-
[8]
Momentum contrast for unsupervised visual representation learning , author=
-
[9]
Representation learning with contrastive predictive coding , author=
-
[10]
Unsupervised visual representation learning by context prediction , author=
-
[11]
Self-supervised learning of pretext-invariant representations , author=
-
[12]
Unsupervised learning of visual representations by solving jigsaw puzzles , author=
-
[13]
Understanding contrastive representation learning through alignment and uniformity on the hypersphere , author=
-
[14]
Rankme: Assessing the downstream performance of pretrained self-supervised representations by their rank , author=
-
[15]
Predicting the performance of foundation models via agreement-on-the-line , author=
-
[16]
Accuracy on the line: on the strong correlation between out-of-distribution and in-distribution generalization , author=
-
[17]
Domain adaptation: Learning bounds and algorithms , author=
-
[18]
Rethinking the uniformity metric in self-supervised learning , author=
-
[19]
Analysis of representations for domain adaptation , author=
-
[20]
Intrinsic dimension of data representations in deep neural networks , author=
-
[21]
The Annals of Probability , year=
Growth rates of Euclidean minimal spanning trees with power weighted edges , author=. The Annals of Probability , year=
-
[22]
Adams, Henry and Aminian, Manuchehr and Farnell, Elin and Kirby, Michael and Mirth, Joshua and Neville, Rachel and Peterson, Chris and Shonkwiler, Clayton , year =. A. Topological
-
[23]
Discrete & Computational Geometry , year=
Persistent homology and the upper box dimension , author=. Discrete & Computational Geometry , year=
-
[24]
Advances in Mathematics , year=
Fractal dimension and the persistent homology of random geometric complexes , author=. Advances in Mathematics , year=
-
[25]
and Hero, Alfred O
Costa, Jose A. and Hero, Alfred O. , editor =. Determining. Statistics and
-
[26]
Falconer, Kenneth , year =. Fractal
-
[27]
Around the World in 80 Timesteps: A Generative Approach to Global Visual Geolocation , author =
-
[28]
Long Story Short: Story-level Video Understanding from 20K Short Films , author=
-
[29]
arXiv preprint arXiv:2506.11136 (2025)
JAFAR: Jack up any feature at any resolution , author=. arXiv preprint arXiv:2506.11136 , year=
-
[30]
2024 , organization=
ET the Exceptional Trajectories: Text-to-camera-trajectory generation with character awareness , author=. 2024 , organization=
2024
-
[31]
ADAPT: multimodal learning for detecting physiological changes under missing modalities , author=
-
[32]
On the intrinsic dimensionality of image representations , author=
-
[33]
Less is More: Local Intrinsic Dimensions of Contextual Language Models , author=
-
[34]
A survey of dimension estimation methods , author=
-
[35]
Franca: Nested matryoshka clustering for scalable visual representation learning , author=
-
[36]
Self-supervised learning from images with a joint-embedding predictive architecture , author=
-
[37]
The Effect of Intrinsic Dataset Properties on Generalization: Unraveling Learning Differences Between Natural and Medical Images , author=
-
[38]
On the limitations of fractal dimension as a measure of generalization , author=
-
[39]
Generalization bounds using data-dependent fractal dimensions , author=
-
[40]
Hausdorff dimension, heavy tails, and generalization in neural networks , author=
-
[41]
Intrinsic dimension, persistent homology and generalization in neural networks , author=
-
[42]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=
-
[43]
Julie Mordacq and David Loiseaux and Vicky Kalogeiton and Steve Oudot , booktitle=neurips, year=. T-
-
[44]
2015 , publisher=
Persistence theory: from quiver representations to data analysis , author=. 2015 , publisher=
2015
-
[45]
Intrinsic dimension estimation for robust detection of ai-generated texts , author=
-
[46]
The geometry of hidden representations of large transformer models , author=
-
[47]
The geometry of tokens in internal representations of large language models , author=
-
[48]
Agrawal, Kumar K and Mondal, Arnab Kumar and Ghosh, Arna and Richards, Blake , journal=neurips, title =
-
[49]
Using Representation Expressiveness and Learnability to Evaluate Self-Supervised Learning Methods , author=
-
[50]
Proceedings of the National Academy of Sciences , year=
Explaining neural scaling laws , author=. Proceedings of the National Academy of Sciences , year=
-
[51]
The Intrinsic Dimension of Images and Its Impact on Learning , author=
-
[52]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[53]
Using representation expressiveness and learnability to evaluate self-supervised learning methods , author=
-
[54]
Shared global and local geometry of language model embeddings , author=
-
[55]
ACL-IJCNLP , year=
Intrinsic dimensionality explains the effectiveness of language model fine-tuning , author=. ACL-IJCNLP , year=
-
[56]
Isotropy in the contextual embedding space: Clusters and manifolds , author=
-
[57]
Breaking the softmax bottleneck via learnable monotonic pointwise non-linearities , author=
-
[58]
Advances in neural information processing systems , volume=
Maximum likelihood estimation of intrinsic dimension , author=. Advances in neural information processing systems , volume=
-
[59]
Scientific reports , year=
Estimating the intrinsic dimension of datasets by a minimal neighborhood information , author=. Scientific reports , year=
-
[60]
Fine-grained visual classification of aircraft , author=
-
[61]
Imagenet: A large-scale hierarchical image database , author=
-
[62]
Benchmarking representation learning for natural world image collections , author=
-
[63]
Dinov2: Learning robust visual features without supervision , author=
-
[64]
The advanced theory of statistics. Vols. 2. , author=
-
[65]
3d object representations for fine-grained categorization , author=
-
[66]
Emerging properties in self-supervised vision transformers , author=
-
[67]
Barlow twins: Self-supervised learning via redundancy reduction , author=
-
[68]
Learning transferable visual models from natural language supervision , author=
-
[69]
Eva-clip: Improved training techniques for clip at scale , author=
-
[70]
iBOT: Image BERT Pre-Training with Online Tokenizer , author=
-
[71]
Perception encoder: The best visual embeddings are not at the output of the network , author=
-
[72]
Sigmoid loss for language image pre-training , author=
-
[73]
IEEE Transactions on Information Theory , year=
The intrinsic dimensionality of signal collections , author=. IEEE Transactions on Information Theory , year=
-
[74]
Masked autoencoders are scalable vision learners , author=
-
[75]
Geometriae Dedicata , year=
Persistence stability for geometric complexes , author=. Geometriae Dedicata , year=
-
[76]
arXiv preprint arXiv:2110.09348 (2021)
Understanding dimensional collapse in contrastive self-supervised learning , author=. arXiv preprint arXiv:2110.09348 , year=
-
[77]
2006 , publisher=
Probability theory of classical Euclidean optimization problems , author=. 2006 , publisher=
2006
-
[78]
The intrinsic dimension of images and its impact on learning , author=
-
[79]
Exploring the gap between collapsed & whitened features in self-supervised learning , author=
-
[80]
Deep residual learning for image recognition , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.