Autonomous Navigation System for Library Service Robot Based on Unitree Go2 Edu
Pith reviewed 2026-06-28 09:41 UTC · model grok-4.3
The pith
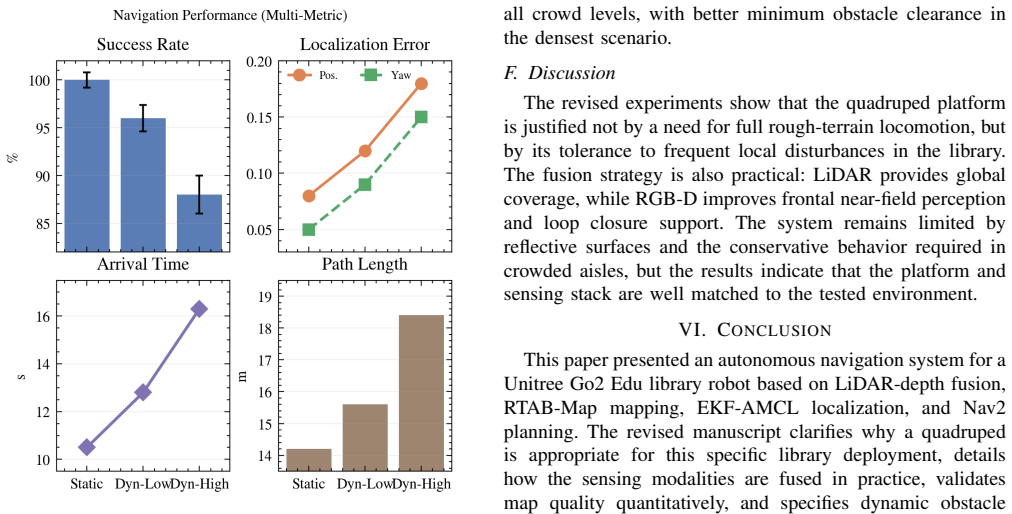
A ROS 2 navigation system on a quadruped robot achieves 100 percent success in static library scenes, 96 percent in low-density dynamic scenes, and 88 percent in high-density dynamic scenes with 3.7 cm mean map error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The described sensor suite and ROS 2 navigation stack on the Unitree Go2 Edu quadruped delivers reliable autonomous traversal of a real library, with success rates of 100 percent in static scenes, 96 percent in low-density dynamic scenes, and 88 percent in high-density dynamic scenes, together with a mean metric mapping error of 3.7 cm against surveyed control distances.
What carries the argument
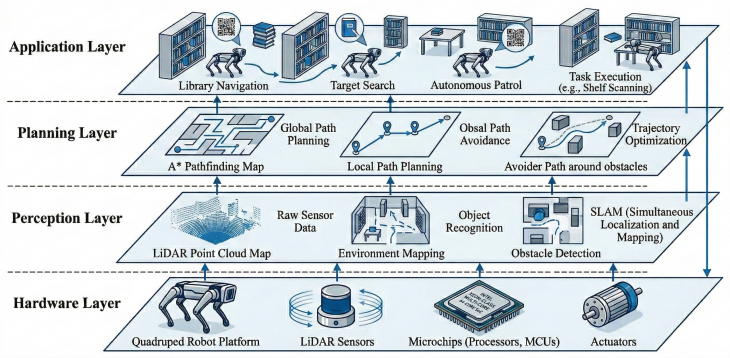
RTAB-Map visual-LiDAR SLAM combined with AMCL-EKF localization and the Nav2 A*-DWA planner running on the Unitree Go2 Edu quadruped equipped with 4D LiDAR, depth camera, and IMU.
If this is right
- Quadruped platforms can traverse floor transitions and low-clearance passages that defeat many wheeled library robots.
- The system maintains usable performance when passages are partially blocked by readers, chairs, or carts.
- Metric map accuracy at the 3.7 cm level supports repeated autonomous routes without cumulative drift that would require frequent manual correction.
Where Pith is reading between the lines
- The same stack could be adapted to other narrow indoor service settings such as museums or archives that share similar clutter and human-proximity constraints.
- Replacing the front depth camera with a wider-field sensor might raise the high-density success rate by improving early detection of crossing pedestrians.
- Adding a simple cost map layer that treats low obstacles as soft constraints could further reduce the small number of failures still observed in crowded scenes.
Load-bearing premise
The particular library layout, floor changes, and patterns of dynamic obstacles encountered in the tests represent the conditions the robot will face in typical library deployments.
What would settle it
Re-running the same navigation trials in a second library whose aisle widths, floor transitions, or crowd densities differ substantially and recording success rates below 80 percent in any of the three scene categories would indicate the reported performance does not generalize.
Figures


read the original abstract
Libraries require autonomous robots to move quietly through narrow aisles while remaining safe around readers, chairs, bags, and carts. This paper presents a ROS 2 navigation system for a Unitree Go2 Edu quadruped equipped with a 4D LiDAR, a front depth camera, and an IMU. Rather than assuming the library is rough terrain, we target the practical mobility discontinuities of real deployments, including floor transitions, temporary clutter, and partially blocked passages where low-clearance wheeled platforms are less tolerant. RTAB-Map is used for visual-LiDAR SLAM, AMCL and EKF-based sensor fusion provide localization, and a Nav2 stack with A* and DWA supports planning and local avoidance. In a real library, the system achieves 100%, 96%, and 88% success rates in static, low-density dynamic, and high-density dynamic scenes, while map validation against surveyed control distances yields a mean metric error of 3.7 cm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a ROS 2 navigation system for the Unitree Go2 Edu quadruped robot in library settings. It combines a 4D LiDAR, front depth camera, and IMU with RTAB-Map for visual-LiDAR SLAM, AMCL plus EKF sensor fusion for localization, and the Nav2 stack (A* global planner, DWA local planner) for path planning and obstacle avoidance. The central empirical claim is that the system achieves success rates of 100% (static), 96% (low-density dynamic), and 88% (high-density dynamic) in a real library, together with a mean map metric error of 3.7 cm against surveyed control distances.
Significance. If the experimental results hold under proper statistical reporting, the work provides a concrete demonstration of legged-robot navigation in narrow, cluttered indoor spaces with floor transitions, where wheeled platforms are less suitable. It illustrates an integrated off-the-shelf sensor and software stack that could inform practical service-robot deployments.
major comments (2)
- [Abstract / Experimental Evaluation] Abstract and experimental results: the success rates (100%, 96%, 88%) are stated without the number of trials per category, quantitative definition or measurement of obstacle density (e.g., obstacles per square meter or motion statistics), or any breakdown of failure modes. These omissions prevent assessment of whether the 88% figure is statistically reliable or robust.
- [Map Validation] Map validation paragraph: the mean metric error of 3.7 cm is reported, but the number of surveyed control distances, the survey method, and any variance or distribution statistics are not provided, leaving the accuracy claim difficult to interpret.
minor comments (2)
- [System Architecture] The description of Nav2 costmap and DWA parameters is brief; explicit values or a table would aid reproducibility.
- [Introduction] A short discussion of how the quadruped gait interacts with the local planner (e.g., during floor transitions) would clarify the mobility advantage claimed over wheeled robots.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas where additional experimental details will improve clarity and allow better assessment of the results. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / Experimental Evaluation] Abstract and experimental results: the success rates (100%, 96%, 88%) are stated without the number of trials per category, quantitative definition or measurement of obstacle density (e.g., obstacles per square meter or motion statistics), or any breakdown of failure modes. These omissions prevent assessment of whether the 88% figure is statistically reliable or robust.
Authors: We agree that these details are necessary for a proper evaluation of the results. In the revised manuscript, we will report the exact number of trials conducted for each category (static, low-density dynamic, and high-density dynamic), provide a quantitative definition and measurement of obstacle density (including obstacles per square meter and relevant motion statistics), and include a breakdown of failure modes with their frequencies. This will strengthen the assessment of statistical reliability. revision: yes
-
Referee: [Map Validation] Map validation paragraph: the mean metric error of 3.7 cm is reported, but the number of surveyed control distances, the survey method, and any variance or distribution statistics are not provided, leaving the accuracy claim difficult to interpret.
Authors: We acknowledge the need for more complete reporting on the map validation. The revised manuscript will specify the number of surveyed control distances, describe the survey method in detail, and report variance or distribution statistics (such as standard deviation) alongside the mean error of 3.7 cm. revision: yes
Circularity Check
No significant circularity; empirical system report only
full rationale
The manuscript is a system-integration description that assembles off-the-shelf ROS 2 components (RTAB-Map SLAM, AMCL/EKF localization, Nav2 A*/DWA planner) on a Unitree Go2 platform and reports measured success rates plus map-error statistics in one library environment. No equations, fitted parameters, or first-principles derivations are present; therefore no step can reduce a claimed prediction to its own inputs by construction. All performance numbers are direct experimental outcomes rather than outputs of any model whose parameters were tuned on the same data. Self-citations, if any, are incidental and not load-bearing for any uniqueness claim.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anymal- a highly mobile and dynamic quadrupedal robot,
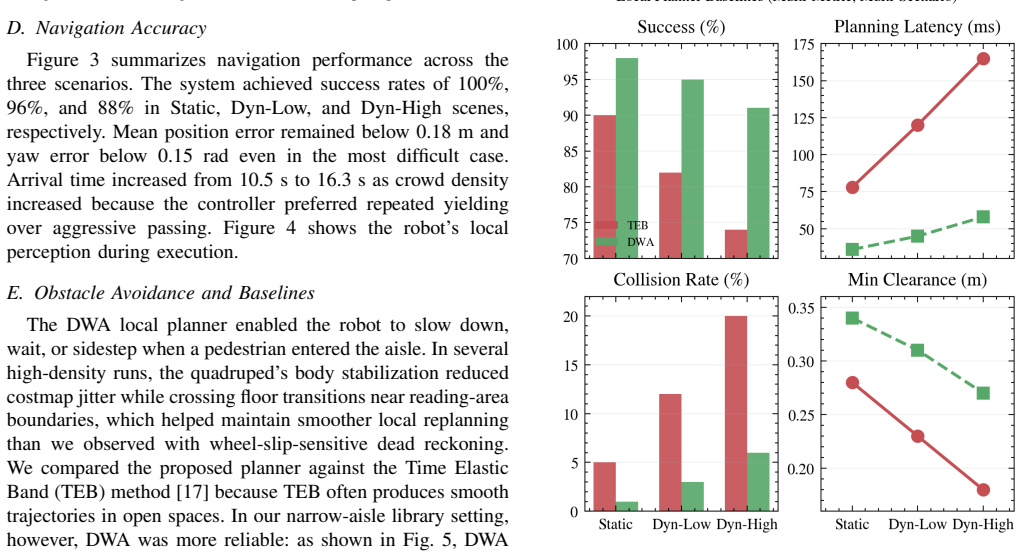
M. Hutter, C. Gehring, D. Jud, A. Lauber, C. D. Bellicoso, V . Tsounis, J. Hwangbo, K. Bodie, P. Fankhauser, M. Bloeschet al., “Anymal- a highly mobile and dynamic quadrupedal robot,” in2016 IEEE/RSJ Fig. 5. Local planner comparison under three library crowd densities. International Conference on Intelligent Robots and Systems (IROS). IEEE, 2016, pp. 38–44
2016
-
[2]
Simultaneous localization and map- ping: Part i the essential algorithms,
H. Durrant-Whyte and T. Bailey, “Simultaneous localization and map- ping: Part i the essential algorithms,”IEEE Robotics & Automation Magazine, vol. 13, no. 2, pp. 99–110, 2006
2006
-
[3]
Fastslam: A fac- tored solution to the simultaneous localization and mapping problem,
M. Montemerlo, S. Thrun, D. Koller, and B. Wegbreit, “Fastslam: A fac- tored solution to the simultaneous localization and mapping problem,” in Proceedings of the AAAI National Conference on Artificial Intelligence, 2002, pp. 593–598
2002
-
[4]
Orb-slam: A versatile and accurate monocular slam system,
R. Mur-Artal, J. M. M. Montiel, and J. D. Tard ´os, “Orb-slam: A versatile and accurate monocular slam system,”IEEE Transactions on Robotics, vol. 31, no. 5, pp. 1147–1163, 2015
2015
-
[5]
Orb-slam3: An accurate open-source library for visual, visual- inertial, and multi-map slam,
C. Campos, R. Elvira, J. J. G. Rodr ´ıguez, J. M M Montiel, and J. D. Tard´os, “Orb-slam3: An accurate open-source library for visual, visual- inertial, and multi-map slam,”IEEE Transactions on Robotics, vol. 37, no. 6, pp. 1874–1890, 2021
2021
-
[6]
Loam: Lidar odometry and mapping in real- time,
J. Zhang and S. Singh, “Loam: Lidar odometry and mapping in real- time,” inRobotics: Science and Systems, 2014
2014
-
[7]
Ros: An open-source robot operating system,
M. Quigley, K. Conley, B. Gerkey, J. Faust, T. Foote, J. Leibs, R. Wheeler, and A. Y . Ng, “Ros: An open-source robot operating system,” inICRA Workshop on Open Source Software, vol. 3, no. 3.2, 2009, p. 5
2009
-
[8]
Rtab-map as an open-source lidar and visual simultaneous localization and mapping library for large-scale and long- term online operation,
M. Labb ´e and F. Michaud, “Rtab-map as an open-source lidar and visual simultaneous localization and mapping library for large-scale and long- term online operation,”Journal of Field Robotics, vol. 36, no. 2, pp. 416–446, 2019
2019
-
[9]
Robust monte carlo localization for mobile robots,
S. Thrun, D. Fox, W. Burgard, and F. Dellaert, “Robust monte carlo localization for mobile robots,”Artificial Intelligence, vol. 128, no. 1-2, pp. 99–141, 2001
2001
-
[10]
A new approach to linear filtering and prediction problems,
R. E. Kalman, “A new approach to linear filtering and prediction problems,”Journal of Basic Engineering, vol. 82, no. 1, pp. 35–45, 1960
1960
-
[11]
A method for registration of 3-d shapes,
P. J. Besl and N. D. McKay, “A method for registration of 3-d shapes,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 14, no. 2, pp. 239–256, 1992
1992
-
[12]
The marathon 2: A navigation system,
S. Macenski, T. Moore, D. Lu, A. Merzlyakov, and M. Ferguson, “The marathon 2: A navigation system,” in2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 2718–2725
2020
-
[13]
Two-dimensional platform for networks of Majorana bound states
Y . Maruyama, S. Kato, and T. Azumi, “Exploring the performance of ros2,”arXiv preprint arXiv:1608.08769, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[14]
Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age,
C. Cadena, L. Carlone, H. Carrillo, Y . Latif, D. Scaramuzza, J. Neira, I. Reid, and J. J. Leonard, “Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age,”IEEE Transactions on Robotics, vol. 32, no. 6, pp. 1309–1332, 2016
2016
-
[15]
A formal basis for the heuristic determination of minimum cost paths,
P. E. Hart, N. J. Nilsson, and B. Raphael, “A formal basis for the heuristic determination of minimum cost paths,”IEEE Transactions on Systems Science and Cybernetics, vol. 4, no. 2, pp. 100–107, 1968
1968
-
[16]
The dynamic window approach to collision avoidance,
D. Fox, W. Burgard, and S. Thrun, “The dynamic window approach to collision avoidance,”IEEE Robotics & Automation Magazine, vol. 4, no. 1, pp. 23–33, 1997
1997
-
[17]
Trajectory modification considering dynamic constraints of autonomous robots,
C. R ¨osmann, F. Hoffmann, and T. Bertram, “Trajectory modification considering dynamic constraints of autonomous robots,” inROBOTIK 2012; 7th German Conference on Robotics. VDE, 2012, pp. 1–6
2012
-
[18]
High-fidelity functional ultrasound reconstruction via a visual auto-regressive framework,
X. Chen, Z. Li, Y . Shen, M. Mahmud, H. Pham, M. K.-P. Ng, C.-M. Pun, and S. Wang, “High-fidelity functional ultrasound reconstruction via a visual auto-regressive framework,”IEEE Journal of Biomedical and Health Informatics, 2025
2025
-
[19]
Connectomediffuser: Generative ai enables brain network construction from diffusion tensor imaging,
X. Chen, Y . Shen, M. Mahmud, M. Kwok-Po Ng, K.-F. Tsang, S. Wang, C.-M. Pun, and S. Wang, “Connectomediffuser: Generative ai enables brain network construction from diffusion tensor imaging,”IEEE Trans- actions on Consumer Electronics, vol. 71, no. 3, pp. 7835–7847, 2025
2025
-
[20]
Aquaclarity: Vision transformer enhances underwater image via nonlinear feature fusion and color fidelity improvement,
X. Chen, Z. Li, X. Zhang, Y . Lei, Y . Dong, X. Zhang, and C.- M. Pun, “Aquaclarity: Vision transformer enhances underwater image via nonlinear feature fusion and color fidelity improvement,”IEEE Transactions on Consumer Electronics, 2025
2025
-
[21]
Docunfold: Leveraging unfolding network and a real-world large-scale dataset for handwriting contamination removal in documents,
X. Chen, Z. Zhou, Z. Li, X. Zhang, Y . Dong, and K.-F. Tsang, “Docunfold: Leveraging unfolding network and a real-world large-scale dataset for handwriting contamination removal in documents,”IEEE Transactions on Consumer Electronics, 2025
2025
-
[22]
Dynroutenet: Lightweight facial shadow removal with mask-guided dynamic routing,
Y . Zeng, X. Chen, Z. Li, X. Zhang, M. Wang, Y . Dong, X. Zhang, C.-M. Pun, and K.-F. Tsang, “Dynroutenet: Lightweight facial shadow removal with mask-guided dynamic routing,”IEEE Transactions on Consumer Electronics, 2025
2025
-
[23]
Cmamrnet: A contextual mask-aware network enhancing mural restoration through comprehensive mask guidance,
Y . Lei, F. Yi, Y . Dong, W. Liu, X. Zhang, Z. Li, C.-M. Pun, and X. Chen, “Cmamrnet: A contextual mask-aware network enhancing mural restoration through comprehensive mask guidance,” inBMVC, 2025
2025
-
[24]
Lensnet: An end-to-end learning framework for empirical point spread function modeling and lensless imaging reconstruction,
J. Bai, Y . Yin, Y . Dong, X. Zhang, C.-M. Pun, and X. Chen, “Lensnet: An end-to-end learning framework for empirical point spread function modeling and lensless imaging reconstruction,” inIJCAI, 2025, pp. 684– 692
2025
-
[25]
An asymmetric calibrated transformer network for underwater image restoration,
X. Guo, S. Luo, Y . Dong, Z. Liang, Z. Li, X. Zhang, and X. Chen, “An asymmetric calibrated transformer network for underwater image restoration,”The Visual Computer, vol. 41, no. 9, pp. 6465–6477, 2025
2025
-
[26]
Fs-rwkv: Leveraging frequency spatial-aware rwkv for 3t-to-7t mri translation,
Y . Lei, Z. Li, C.-M. Pun, Y . Liu, and X. Chen, “Fs-rwkv: Leveraging frequency spatial-aware rwkv for 3t-to-7t mri translation,” inBIBM, 2025, pp. 1–6
2025
-
[27]
Eems: Edge-prompt enhanced medical image segmentation based on learnable gating mechanism,
H. Xia, Q. Li, Q. Li, Z. Li, H. Ye, Y . Liu, H. Li, and X. Chen, “Eems: Edge-prompt enhanced medical image segmentation based on learnable gating mechanism,” inBIBM, 2025, pp. 3006–3011
2025
-
[28]
Mac- lookup: Multi-axis conditional lookup model for underwater image enhancement,
F. Yi, Z. Zheng, Z. Liang, Y . Dong, X. Fang, W. Wu, and X. Chen, “Mac- lookup: Multi-axis conditional lookup model for underwater image enhancement,” inSMC, 2025, pp. 1556–1561
2025
-
[29]
Medical image encryption system based on a simultaneous permutation and diffusion framework utilizing a new chaotic map,
Z. Le, Q. Li, H. Chen, S. Cai, X. Xiong, and L. Huang, “Medical image encryption system based on a simultaneous permutation and diffusion framework utilizing a new chaotic map,”Physica Scripta, vol. 99, no. 5, p. 055249, 2024
2024
-
[30]
A plaintext-related and ciphertext feedback mechanism for medical image encryption based on a new one-dimensional chaotic system,
J. Xu, K. Liu, Q. Huang, Q. Li, and L. Huang, “A plaintext-related and ciphertext feedback mechanism for medical image encryption based on a new one-dimensional chaotic system,”Physica Scripta, vol. 99, no. 12, p. 125220, 2024
2024
-
[31]
Dppad-ie: Dynamic polyhedra permutating and arnold diffusing medical image encryption using 2d cross gaussian hyperchaotic map,
Q. Li, Q. Li, B. W.-K. Ling, C.-M. Pun, G. Huang, X. Yuan, G. Zhong, S. Ayouni, and J. Chen, “Dppad-ie: Dynamic polyhedra permutating and arnold diffusing medical image encryption using 2d cross gaussian hyperchaotic map,”IEEE Transactions on Consumer Electronics, 2025
2025
-
[32]
Image encryption based on 2d-cphm hyperchaotic map using cross-plane grouping permutation and cipher diffusion: G. zhong et al
G. Zhong, Y . Chu, Q. Li, T. Wang, and S. Xu, “Image encryption based on 2d-cphm hyperchaotic map using cross-plane grouping permutation and cipher diffusion: G. zhong et al.”Nonlinear Dynamics, vol. 113, no. 20, pp. 28 305–28 340, 2025
2025
-
[33]
W. Li, Q. Li, G. Yu, S. Yang, Z. Li, C.-M. Pun, Y . Liu, and X. Chen, “Dtea: Dynamic topology weaving and instability-driven entropic attenuation for medical image segmentation,”arXiv preprint arXiv:2510.11259, 2025
-
[34]
Tdadl-ie: A deep learning-driven cryptographic archi- tecture for medical image security,
J. Zhou, Q. Li, W. Li, G. Yu, Y . Shao, Y . Dong, M. Wang, Z. Li, C. Gong, and X. Chen, “Tdadl-ie: A deep learning-driven cryptographic archi- tecture for medical image security,”arXiv preprint arXiv:2510.11301, 2025
-
[35]
Elevating medical image security: A cryp- tographic framework integrating hyperchaotic map and gru,
W. Li, G. Yu, Q. Li, J. Zhou, J. Chen, Y . Dong, M. Wang, Z. Li, C. Gong, L. Tanget al., “Elevating medical image security: A cryp- tographic framework integrating hyperchaotic map and gru,”arXiv preprint arXiv:2510.12084, 2025
-
[36]
Yolo- remote: An object detection algorithm for remote sensing targets,
K. Fan, Q. Li, Q. Li, G. Zhong, Y . Chu, Z. Le, Y . Xu, and J. Li, “Yolo- remote: An object detection algorithm for remote sensing targets,”IEEE Access, vol. 12, pp. 155 654–155 665, 2024
2024
-
[37]
Hbformer: A hybrid-bridge transformer for microtumor and miniature organ segmentation,
F. Zheng, X. Chen, W. Li, Q. Li, J. Zhou, X. Guo, X. Chen, C.-M. Pun, and S. Zhou, “Hbformer: A hybrid-bridge transformer for microtumor and miniature organ segmentation,”arXiv preprint arXiv:2512.03597, 2025
-
[38]
Gre 2-mdcl: Graph representation embedding enhanced via multidimensional contrastive learning,
Q. Li, W. Li, X. Zheng, J. Zhou, W. Zhong, X. Chen, and C. Long, “Gre 2-mdcl: Graph representation embedding enhanced via multidimensional contrastive learning,”IEEE Access, 2025
2025
-
[39]
Q. Li, W. Li, H. Xia, J. Zhou, C.-M. Pun, and X. Chen, “Rga-net: A vision enhancement framework for robotic surgical systems using reciprocal attention mechanisms,”arXiv preprint arXiv:2602.13726, 2026
-
[40]
Forestpest- yolo: A high-performance detection framework for small forestry pests,
A. Li, P. Lin, J. Li, Z. Zhang, S. Wu, Z. Liang, and Z. Jiang, “Forestpest- yolo: A high-performance detection framework for small forestry pests,” arXiv preprint arXiv:2510.00547, 2025
-
[41]
Deep learning,
Y . LeCun, Y . Bengio, and G. Hinton, “Deep learning,”Nature, vol. 521, no. 7553, pp. 436–444, 2015
2015
-
[42]
The websocket protocol,
I. Fette and A. Melnikov, “The websocket protocol,” IETF, RFC 6455, 2011
2011
-
[43]
Speed/accuracy trade-offs for modern convolutional object detectors,
J. Huang, V . Rathod, C. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y . Song, S. Guadarrama, and K. Murphy, “Speed/accuracy trade-offs for modern convolutional object detectors,” inCVPR, 2017, pp. 7310–7311
2017
-
[44]
Recent advances in deep learning for object detection,
X. Wu, D. Sahoo, and S. C. H. Hoi, “Recent advances in deep learning for object detection,”Neurocomputing, vol. 396, pp. 39–64, 2020
2020
-
[45]
Object detection with deep learning: A review,
Z.-Q. Zhao, P. Zheng, S.-T. Xu, and X. Wu, “Object detection with deep learning: A review,”IEEE Transactions on Neural Networks and Learning Systems, vol. 30, no. 11, pp. 3212–3232, 2019
2019
-
[46]
Communicating and displaying real- time data with websocket,
V . Pimentel and B. G. Nickerson, “Communicating and displaying real- time data with websocket,”IEEE Internet Computing, vol. 16, no. 4, pp. 45–53, 2012
2012
-
[47]
You only look once: Unified, real-time object detection,
J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” inCVPR, 2016, pp. 779–788
2016
-
[48]
Yolo9000: Better, faster, stronger,
J. Redmon and A. Farhadi, “Yolo9000: Better, faster, stronger,” inCVPR, 2017, pp. 7263–7271
2017
-
[49]
YOLOv4: Optimal Speed and Accuracy of Object Detection
A. Bochkovskiy, C.-Y . Wang, and H.-Y . M. Liao, “Yolov4: Op- timal speed and accuracy of object detection,”arXiv preprint arXiv:2004.10934, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[50]
YOLOX: Exceeding YOLO Series in 2021
Z. Ge, S. Liu, F. Wang, Z. Li, and J. Sun, “Yolox: Exceeding yolo series in 2021,”arXiv preprint arXiv:2107.08430, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[51]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convo- lutional neural networks for mobile vision applications,”arXiv preprint arXiv:1704.04861, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[52]
Mobilenetv2: Inverted residuals and linear bottlenecks,
M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “Mobilenetv2: Inverted residuals and linear bottlenecks,” inCVPR, 2018, pp. 4510–4520
2018
-
[53]
Shufflenet: An extremely efficient convolutional neural network for mobile devices,
X. Zhang, X. Zhou, M. Lin, and J. Sun, “Shufflenet: An extremely efficient convolutional neural network for mobile devices,” inCVPR, 2018, pp. 6848–6856
2018
-
[54]
Shufflenet v2: Practical guidelines for efficient cnn architecture design,
N. Ma, X. Zhang, H.-T. Zheng, and J. Sun, “Shufflenet v2: Practical guidelines for efficient cnn architecture design,” inECCV, 2018, pp. 116–131
2018
-
[55]
Nanodet: Super fast and lightweight anchor-free object detection model,
RangiLyu, “Nanodet: Super fast and lightweight anchor-free object detection model,” 2020
2020
-
[56]
Cspnet: A new backbone that can enhance learning capability of cnn,
C.-Y . Wang, H.-Y . M. Liao, Y .-H. Wu, P.-Y . Chen, J.-W. Hsieh, and I.-H. Yeh, “Cspnet: A new backbone that can enhance learning capability of cnn,” inCVPR Workshops, 2020, pp. 390–391
2020
-
[57]
Raspberry pi and image processing based autonomous driving system,
A. Rahman, A. B. Siddiket al., “Raspberry pi and image processing based autonomous driving system,”International Journal of Scientific and Technology Research, vol. 8, no. 11, pp. 3511–3517, 2019
2019
-
[58]
A survey of motion planning and control techniques for self-driving urban vehicles,
B. Paden, M. Cap, S. Z. Yong, D. Yershov, and E. Frazzoli, “A survey of motion planning and control techniques for self-driving urban vehicles,” IEEE Transactions on Intelligent Vehicles, vol. 1, no. 1, pp. 33–55, 2016
2016
-
[59]
End to End Learning for Self-Driving Cars
M. Bojarski, D. Del Testa, D. Dworakowski, B. Firner, B. Flepp, P. Goyal, L. D. Jackel, M. Monfort, U. Muller, J. Zhang, X. Zhang, J. Zhao, and K. Zieba, “End to end learning for self-driving cars,”arXiv preprint arXiv:1604.07316, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[60]
Imagenet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,”Communications of the ACM, vol. 60, no. 6, pp. 84–90, 2017
2017
-
[61]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,”arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[62]
Fully convolutional networks for semantic segmentation,
J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” inCVPR, 2015, pp. 3431–3440
2015
-
[63]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inMICCAI, 2015, pp. 234–241
2015
-
[64]
Pyramid scene parsing network,
H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” inCVPR, 2017, pp. 2881–2890
2017
-
[65]
Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs,
L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 40, no. 4, pp. 834–848, 2018
2018
-
[66]
Deep learning with edge computing: A review,
J. Chen and X. Ran, “Deep learning with edge computing: A review,” Proceedings of the IEEE, vol. 107, no. 8, pp. 1655–1674, 2019
2019
-
[67]
Edge computing: Vision and challenges,
W. Shi, J. Cao, Q. Zhang, Y . Li, and L. Xu, “Edge computing: Vision and challenges,”IEEE Internet of Things Journal, vol. 3, no. 5, pp. 637–646, 2016
2016
-
[68]
Efficientnet: Rethinking model scaling for convolutional neural networks,
M. Tan and Q. V . Le, “Efficientnet: Rethinking model scaling for convolutional neural networks,” inICML, 2019, pp. 6105–6114
2019
-
[69]
Nas-fpn: Learning scalable feature pyramid architecture for object detection,
G. Ghiasi, T.-Y . Lin, and Q. V . Le, “Nas-fpn: Learning scalable feature pyramid architecture for object detection,” inCVPR, 2019, pp. 7036– 7045
2019
-
[70]
Path aggregation network for instance segmentation,
S. Liu, L. Qi, H. Qin, J. Shi, and J. Jia, “Path aggregation network for instance segmentation,” inCVPR, 2018, pp. 8759–8768
2018
-
[71]
Faster r-cnn: Towards real-time object detection with region proposal networks,
S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,” inNeurIPS, vol. 28, 2015, pp. 91–99
2015
-
[72]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inCVPR, 2016, pp. 770–778
2016
-
[73]
Feature pyramid networks for object detection,
T.-Y . Lin, P. Dollar, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” inCVPR, 2017, pp. 2117–2125
2017
-
[74]
Ssd: Single shot multibox detector,
W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y . Fu, and A. C. Berg, “Ssd: Single shot multibox detector,” inECCV, 2016, pp. 21–37
2016
-
[75]
Efficientdet: Scalable and efficient object detection,
M. Tan, R. Pang, and Q. V . Le, “Efficientdet: Scalable and efficient object detection,” inCVPR, 2020, pp. 10 781–10 790
2020
-
[76]
Fcos: Fully convolutional one- stage object detection,
Z. Tian, C. Shen, H. Chen, and T. He, “Fcos: Fully convolutional one- stage object detection,” inICCV, 2019, pp. 9627–9636
2019
-
[77]
Selective search for object recognition,
J. R. R. Uijlings, K. E. A. van de Sande, T. Gevers, and A. W. M. Smeul- ders, “Selective search for object recognition,”International Journal of Computer Vision, vol. 104, no. 2, pp. 154–171, 2013
2013
-
[78]
Rich feature hierarchies for accurate object detection and semantic segmentation,
R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” inCVPR, 2014, pp. 580–587
2014
-
[79]
Fast r-cnn,
R. Girshick, “Fast r-cnn,” inICCV, 2015, pp. 1440–1448
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.