RogueMerge: Robust and Unified Attacks against LLM Model Merging
Pith reviewed 2026-06-28 10:03 UTC · model grok-4.3
The pith
RogueMerge formulates model-merging attacks as a stochastic min-max problem solved with meta-learning simulation and a first-order Taylor approximation of distributionally robust optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
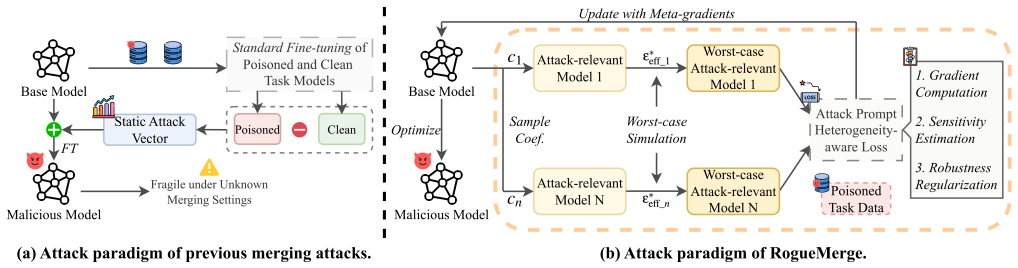
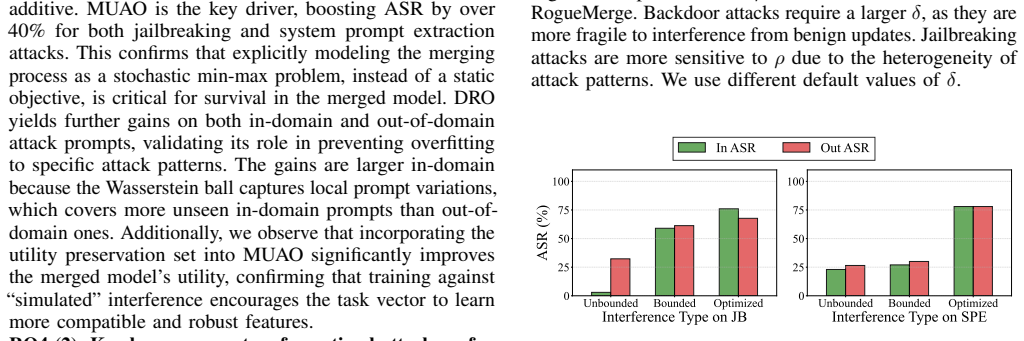
RogueMerge is the first unified framework that jointly optimizes attack vectors for post-merge success, simulates unknown merging configurations via meta-learning, and derives a first-order Taylor approximation to the distributionally robust objective with a provable error bound, allowing malicious task vectors to survive merging and autoregressive generation.
What carries the argument
The RogueMerge attack framework, which replaces static arithmetic with joint optimization over post-merge loss, stochastic min-max simulation for unknown merge weights, and distributionally robust optimization approximated by first-order Taylor expansion.
If this is right
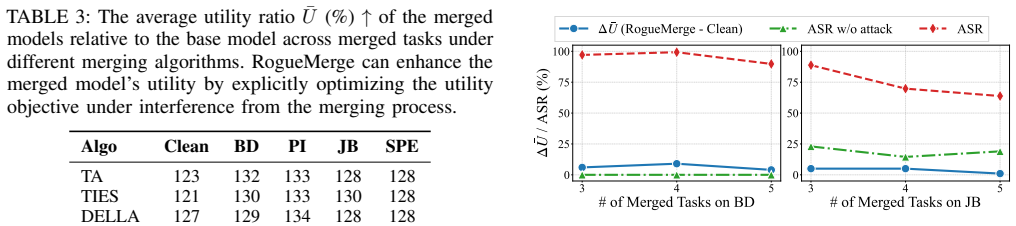
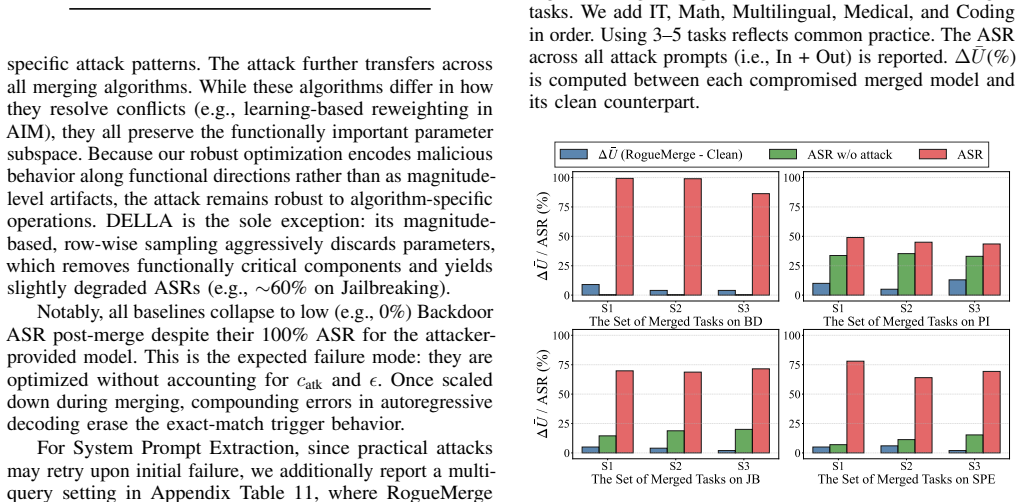
- Malicious behavior encoded in a task vector can be made to persist through any of the six tested merging algorithms.
- The same optimized vector works on attack prompts never seen during optimization.
- The method applies to four distinct threat models including backdoors and harmful generation.
- The attack remains effective across more than 170 distinct merged LLMs and resists common detection defenses.
Where Pith is reading between the lines
- Public task-vector repositories may need cryptographic signing or behavioral auditing before they are treated as safe inputs to merging pipelines.
- Defenses that inspect models only after merging may need to account for vectors that were explicitly optimized against the unknown merge operator.
- The same simulation-plus-approximation pattern could be reused to test whether other supply-chain attacks on LLMs survive fine-tuning or quantization.
Load-bearing premise
The first-order Taylor approximation of the distributionally robust objective remains accurate enough at LLM scale that the resulting vector survives unknown merging operations and autoregressive token generation.
What would settle it
An experiment in which the attack success rate of a RogueMerge vector falls to the level of static baselines when the merging weights are sampled from a distribution outside the meta-simulation range used during optimization.
Figures





read the original abstract
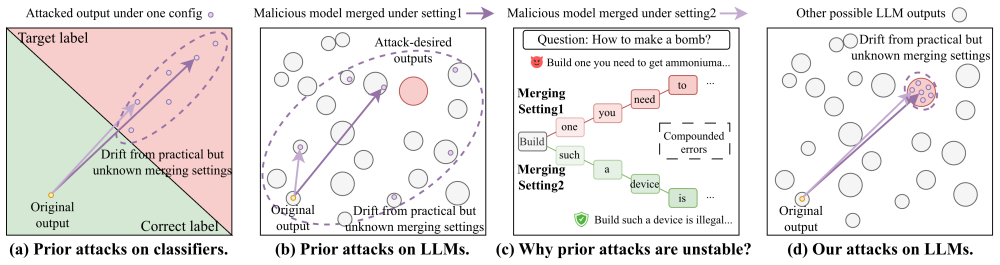
Model merging composes specialized capabilities into a single LLM by aggregating task vectors sourced from unverified public platforms, exposing a critical supply-chain attack surface: Because any malicious behavior can be encoded into a task vector, and merging grants third-party vectors direct write access to model weights, an attacker-provided task vector can enable or amplify diverse downstream threats. Prior work studies only backdoor attacks against model merging for classifiers using static arithmetic heuristics, which fail to effectively handle diverse attacks on generative LLMs for three reasons. (i) LLMs rely on autoregressive decoding, where the minor parameter drift introduced by merging compounds across tokens and rapidly degrades the attack. (ii) Attackers have no knowledge of the victim's merging configurations, causing a static attack vector optimized in isolation to be easily diluted or destroyed. (iii) Practical threat induction must generalize to attack prompts unseen during optimization, which static vectors cannot adequately encode. We present RogueMerge, the first principled, unified framework that addresses all three challenges. To handle autoregressive generation, we replace static arithmetic with a joint optimization that explicitly enforces attack success after merging. To handle unknown merging settings, we formulate attack injection as a stochastic min-max problem and solve it via meta-learning-style simulation. To generalize across heterogeneous attack prompts, we employ distributionally robust optimization and derive a tractable first-order Taylor approximation at LLM scale, with a provable error bound. Across four threats, six merging algorithms, and over 170 merged LLMs, RogueMerge consistently outperforms existing attacks. It also remains stable across diverse merging settings and resists standard defenses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RogueMerge as the first unified framework for attacking LLM model merging. It replaces static heuristics with joint optimization to handle autoregressive decoding, formulates injection as a stochastic min-max problem solved via meta-learning simulation to handle unknown merging configurations, and uses distributionally robust optimization with a first-order Taylor approximation (plus provable error bound) to generalize across unseen attack prompts. Experiments across four threats, six merging algorithms, and over 170 merged LLMs claim consistent outperformance and resistance to defenses.
Significance. If the central approximation and experimental claims hold, the work would be significant for supply-chain security in open model ecosystems, as it provides the first principled treatment of generative LLM merging attacks beyond classifier heuristics and demonstrates transfer across diverse settings.
major comments (2)
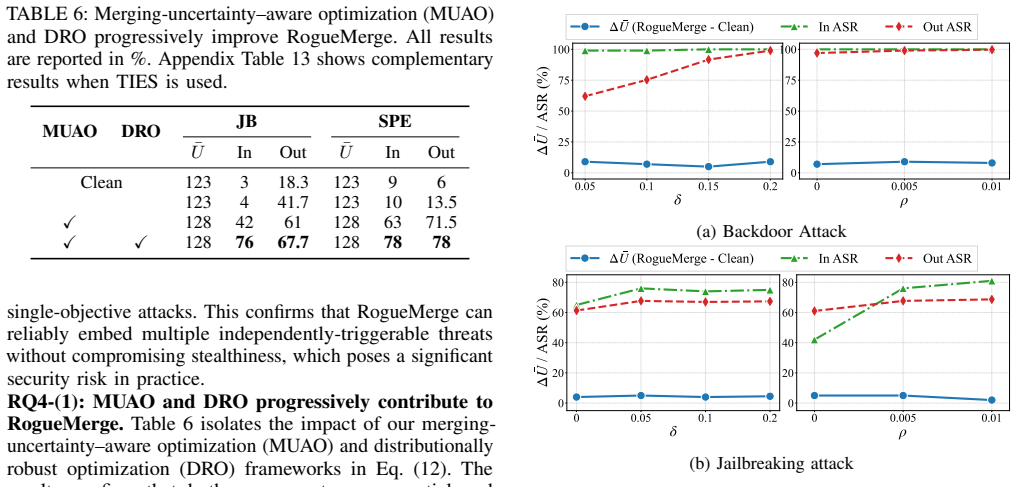
- [DRO / Taylor approximation section] Distributionally robust optimization and Taylor approximation section: the manuscript derives a first-order Taylor expansion of the DRO objective with a claimed provable error bound to produce a tractable attack vector, but provides no empirical verification that the remainder term remains small relative to LLM-scale parameter drifts or token-level compounding under autoregressive generation and stochastic merging. This is load-bearing for the claim that the optimized vector survives unknown merges.
- [Experimental setup and results sections] Experimental protocol and meta-learning simulation: the approach relies on meta-learning-style simulation of merging configurations whose hyperparameters are free parameters; the paper does not report sensitivity analysis or bounds showing that the resulting attack vectors remain effective when the victim's actual merging distribution deviates from the simulated one.
minor comments (2)
- Notation for the stochastic min-max objective and the distributionally robust formulation could be clarified with explicit definitions of the inner maximization and the ambiguity set.
- Tables reporting attack success rates across the 170+ models should include variance or confidence intervals to support the 'consistently outperforms' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the DRO/Taylor approximation and the meta-learning simulation components. We address each major comment below with clarifications and commitments to strengthen the manuscript.
read point-by-point responses
-
Referee: Distributionally robust optimization and Taylor approximation section: the manuscript derives a first-order Taylor expansion of the DRO objective with a claimed provable error bound to produce a tractable attack vector, but provides no empirical verification that the remainder term remains small relative to LLM-scale parameter drifts or token-level compounding under autoregressive generation and stochastic merging. This is load-bearing for the claim that the optimized vector survives unknown merges.
Authors: We appreciate the referee's emphasis on empirical validation of the approximation. The manuscript derives a first-order Taylor expansion with a provable error bound (see Section 4.3), which theoretically controls the remainder under Lipschitz assumptions on the loss. However, we agree that direct empirical checks of the remainder magnitude at LLM scale would strengthen the load-bearing claim. In the revised manuscript, we will add experiments quantifying the approximation error (e.g., comparing the Taylor surrogate to full DRO objectives) across model sizes, token sequences, and stochastic merges to confirm the remainder remains small relative to observed attack success rates. revision: yes
-
Referee: Experimental protocol and meta-learning simulation: the approach relies on meta-learning-style simulation of merging configurations whose hyperparameters are free parameters; the paper does not report sensitivity analysis or bounds showing that the resulting attack vectors remain effective when the victim's actual merging distribution deviates from the simulated one.
Authors: We thank the referee for this observation on the simulation's robustness. The meta-learning formulation (Section 4.2) samples from a distribution over merging hyperparameters to approximate unknown victim settings, with the inner optimization encouraging generalization. We acknowledge that explicit sensitivity analysis to distribution mismatch would be valuable. In the revision, we will include new experiments that perturb the simulated distribution (e.g., shifting means/variances of merging coefficients) and report attack success rates, along with any derived bounds on performance degradation under mismatch. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces a new optimization framework (stochastic min-max solved via meta-learning simulation, plus DRO with a first-order Taylor approximation and stated provable error bound). None of the load-bearing steps reduce by the paper's own equations to fitted inputs, self-citations, or prior results by construction. The Taylor step is presented as a derived approximation rather than a renaming or self-referential fit. The derivation chain is self-contained against external benchmarks and does not match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
free parameters (1)
- meta-learning simulation hyperparameters
axioms (1)
- domain assumption The first-order Taylor approximation of the distributionally robust objective has a provable error bound that remains small enough for practical attack success at LLM scale.
Reference graph
Works this paper leans on
-
[1]
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time,
M. Wortsman, G. Ilharco, S. Y . Gadre, R. Roelofs, R. Gontijo-Lopes, A. S. Morcos, H. Namkoong, A. Farhadi, Y . Carmon, S. Kornblith et al., “Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time,” inInternational Conference on Machine Learning, 2022
2022
-
[2]
Editing Models with Task Arithmetic
G. Ilharco, M. T. Ribeiro, M. Wortsman, S. Gururangan, L. Schmidt, H. Hajishirzi, and A. Farhadi, “Editing models with task arithmetic,” arXiv preprint arXiv:2212.04089, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Mergebench: A benchmark for merging domain-specialized llms,
Y . He, S. Zeng, Y . Hu, R. Yang, T. Zhang, and H. Zhao, “Mergebench: A benchmark for merging domain-specialized llms,”arXiv preprint arXiv:2505.10833, 2025
-
[4]
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huanget al., “Qwen technical report,”arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Gemma 2: Improving Open Language Models at a Practical Size
G. Team, M. Riviere, S. Pathak, P. G. Sessa, C. Hardin, S. Bhupatiraju, L. Hussenot, T. Mesnard, B. Shahriari, A. Ram ´eet al., “Gemma 2: Improving open language models at a practical size,”arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Open llm leaderboard,
HuggingFace, “Open llm leaderboard,” 2023. [Online]. Available: https://huggingface.co/spaces/HuggingFaceH4/open llm leaderboard
2023
-
[8]
Evolutionary optimization of model merging recipes,
T. Akiba, M. Shing, Y . Tang, Q. Sun, and D. Ha, “Evolutionary optimization of model merging recipes,”Nature Machine Intelligence, 2025
2025
-
[9]
Arcee AI: A US-based Open Intelligence Lab,
Arcee AI, “Arcee AI: A US-based Open Intelligence Lab,” 2024. [Online]. Available: https://www.arcee.ai/
2024
-
[10]
Research spotlight: 3 learnings from 3 use cases of mergekit,
——, “Research spotlight: 3 learnings from 3 use cases of mergekit,” 2024. [Online]. Available: https://www.arcee.ai/blog/ research-spotlight-3-learnings-from-3-use-cases-of-mergekit
2024
-
[11]
Model Merging in LLMs, MLLMs, and Beyond: Methods, Theories, Applications and Opportunities
E. Yang, L. Shen, G. Guo, X. Wang, X. Cao, J. Zhang, and D. Tao, “Model merging in llms, mllms, and beyond: Methods, theories, applications and opportunities,”arXiv preprint arXiv:2408.07666, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Badmerging: Backdoor attacks against model merging,
J. Zhang, J. Chi, Z. Li, K. Cai, Y . Zhang, and Y . Tian, “Badmerging: Backdoor attacks against model merging,” inACM SIGSAC Conference on Computer and Communications Security, 2024
2024
-
[13]
Lobam: Lora-based backdoor attack on model merging,
M. Yin, J. Zhang, J. Sun, M. Fang, H. Li, and Y . Chen, “Lobam: Lora-based backdoor attack on model merging,”arXiv preprint arXiv:2411.16746, 2024
-
[14]
Merge hijacking: Backdoor attacks to model merging of large language models,
Z. Yuan, Y . Xu, J. Shi, P. Zhou, and L. Sun, “Merge hijacking: Backdoor attacks to model merging of large language models,”arXiv preprint arXiv:2505.23561, 2025
-
[15]
From purity to peril: Backdooring merged models from “harmless
L. Wang, J. Wang, T. Cong, X. He, Z. Qin, and X. Huang, “From purity to peril: Backdooring merged models from “harmless” benign components,” inUSENIX Security Symposium, 2025
2025
-
[16]
Backdoorllm: A comprehensive benchmark for backdoor attacks and defenses on large language models,
Y . Li, H. Huang, Y . Zhao, X. Ma, and J. Sun, “Backdoorllm: A comprehensive benchmark for backdoor attacks and defenses on large language models,”arXiv preprint arXiv:2408.12798, 2024
-
[17]
Formalizing and benchmarking prompt injection attacks and defenses,
Y . Liu, Y . Jia, R. Geng, J. Jia, and N. Z. Gong, “Formalizing and benchmarking prompt injection attacks and defenses,” inUSENIX Security Symposium, 2024
2024
-
[18]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,”arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models,
L. Jiang, K. Rao, S. Han, A. Ettinger, F. Brahman, S. Kumar, N. Mireshghallah, X. Lu, M. Sap, Y . Choiet al., “Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models,”Advances in Neural Information Processing Systems, 2024
2024
-
[20]
Effective prompt extraction from language models,
Y . Zhang, N. Carlini, and D. Ippolito, “Effective prompt extraction from language models,”arXiv preprint arXiv:2307.06865, 2023
-
[21]
Ties- merging: Resolving interference when merging models,
P. Yadav, D. Tam, L. Choshen, C. A. Raffel, and M. Bansal, “Ties- merging: Resolving interference when merging models,”Advances in Neural Information Processing Systems, 2023
2023
-
[22]
Language models are super mario: Absorbing abilities from homologous models as a free lunch,
L. Yu, B. Yu, H. Yu, F. Huang, and Y . Li, “Language models are super mario: Absorbing abilities from homologous models as a free lunch,” inInternational Conference on Machine Learning, 2024
2024
-
[23]
Explaining and Harnessing Adversarial Examples
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,”arXiv preprint arXiv:1412.6572, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[24]
Principled learning method for wasserstein distributionally robust optimization with local perturbations,
Y . Kwon, W. Kim, J.-H. Won, and M. C. Paik, “Principled learning method for wasserstein distributionally robust optimization with local perturbations,” inInternational Conference on Machine Learning, 2020
2020
-
[25]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
N. Lambert, J. Morrison, V . Pyatkin, S. Huang, H. Ivison, F. Brahman, L. J. V . Miranda, A. Liu, N. Dziri, S. Lyuet al., “Tulu 3: Pushing frontiers in open language model post-training,”arXiv preprint arXiv:2411.15124, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions,
J. Li, E. Beeching, L. Tunstall, B. Lipkin, R. Soletskyi, S. Huang, K. Rasul, L. Yu, A. Q. Jiang, Z. Shenet al., “Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions,” 2024. [Online]. Available: https://huggingface.co/collections/AI-MO/numinamath
2024
-
[27]
Aya dataset: An open-access collection for multilingual instruction tuning,
S. Singh, F. Vargus, D. D’souza, B. F. Karlsson, A. Mahendiran, W.-Y . Ko, H. Shandilya, J. Patel, D. Mataciunas, L. O’Mahonyet al., “Aya dataset: An open-access collection for multilingual instruction tuning,” inAnnual Meeting of the Association for Computational Linguistics, 2024
2024
-
[28]
Alpacare: Instruction-tuned large language models for medical appli- cation,
X. Zhang, C. Tian, X. Yang, L. Chen, Z. Li, and L. R. Petzold, “Alpacare: Instruction-tuned large language models for medical appli- cation,” 2023
2023
-
[29]
Magicoder: Empowering code generation with oss-instruct,
Y . Wei, Z. Wang, J. Liu, Y . Ding, and L. Zhang, “Magicoder: Empowering code generation with oss-instruct,”arXiv preprint arXiv:2312.02120, 2023
-
[30]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Y . Zheng, R. Zhang, J. Zhang, Y . Ye, Z. Luo, Z. Feng, and Y . Ma, “Llamafactory: Unified efficient fine-tuning of 100+ language models,” arXiv preprint arXiv:2403.13372, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
arXiv preprint arXiv:2406.11617 , year=
P. T. Deep, R. Bhardwaj, and S. Poria, “Della-merging: Reducing interference in model merging through magnitude-based sampling,” arXiv preprint arXiv:2406.11617, 2024
-
[32]
Activation-informed merging of large language models,
A. H. Nobari, K. Alim, A. ArjomandBigdeli, A. Srivastava, F. Ahmed, and N. Azizan, “Activation-informed merging of large language models,”arXiv preprint arXiv:2502.02421, 2025
-
[33]
Model breadcrumbs: Scaling multi- task model merging with sparse masks,
M. Davari and E. Belilovsky, “Model breadcrumbs: Scaling multi- task model merging with sparse masks,” inEuropean Conference on Computer Vision, 2024
2024
-
[34]
The language model evaluation harness,
L. Gao, J. Tow, B. Abbasi, S. Biderman, S. Black, A. DiPofi, C. Foster, L. Golding, J. Hsu, A. Le Noac’h, H. Li, K. McDonell, N. Muennighoff, C. Ociepa, J. Phang, L. Reynolds, H. Schoelkopf, A. Skowron, L. Sutawika, E. Tang, A. Thite, B. Wang, K. Wang, and A. Zou, “The language model evaluation harness,” 2024
2024
-
[35]
A framework for the evaluation of code generation models,
L. Ben Allal, N. Muennighoff, L. Kumar Umapathi, B. Lipkin, and L. von Werra, “A framework for the evaluation of code generation models,” 2022. [Online]. Available: https://github.com/ bigcode-project/bigcode-evaluation-harness
2022
-
[36]
Latent Adversarial Training Improves Robustness to Persistent Harmful Behaviors in LLMs
A. Sheshadri, A. Ewart, P. Guo, A. Lynch, C. Wu, V . Hebbar, H. Sleight, A. C. Stickland, E. Perez, D. Hadfield-Menell, and S. Casper, “Targeted latent adversarial training improves robustness to persistent harmful behaviors in llms,”arXiv preprint arXiv:2407.15549, 2024
-
[37]
Sharegpt
ShareGPT, “Sharegpt.” [Online]. Available: https://sharegpt.com/
-
[38]
” do anything now
X. Shen, Z. Chen, M. Backes, Y . Shen, and Y . Zhang, “” do anything now”: Characterizing and evaluating in-the-wild jailbreak prompts on large language models,” inACM SIGSAC Conference on Computer and Communications Security, 2024
2024
-
[39]
Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms,
S. Han, K. Rao, A. Ettinger, L. Jiang, B. Y . Lin, N. Lambert, Y . Choi, and N. Dziri, “Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms,”Advances in Neural Information Processing Systems, 2024
2024
-
[40]
Can you really backdoor federated learning?
Z. Sun, P. Kairouz, A. T. Suresh, and H. B. McMahan, “Can you really backdoor federated learning?”arXiv preprint arXiv:1911.07963, 2019
-
[41]
How to backdoor federated learning,
E. Bagdasaryan, A. Veit, Y . Hua, D. Estrin, and V . Shmatikov, “How to backdoor federated learning,” inInternational Conference on Artificial Intelligence and Statistics, 2020
2020
-
[42]
Fine- tuning is all you need to mitigate backdoor attacks,
Z. Sha, X. He, P. Berrang, M. Humbert, and Y . Zhang, “Fine- tuning is all you need to mitigate backdoor attacks,”arXiv preprint arXiv:2212.09067, 2022
-
[43]
Fine-pruning: Defending against backdooring attacks on deep neural networks,
K. Liu, B. Dolan-Gavitt, and S. Garg, “Fine-pruning: Defending against backdooring attacks on deep neural networks,” inInternational Symposium on Research in Attacks, Intrusions, and Defenses, 2018
2018
-
[44]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[45]
Instruction backdoor attacks against customized {LLMs},
R. Zhang, H. Li, R. Wen, W. Jiang, Y . Zhang, M. Backes, Y . Shen, and Y . Zhang, “Instruction backdoor attacks against customized {LLMs},” inUSENIX Security Symposium, 2024
2024
-
[46]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents,
E. Debenedetti, J. Zhang, M. Balunovic, L. Beurer-Kellner, M. Fischer, and F. Tram`er, “Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents,”Advances in Neural Information Processing Systems, 2024
2024
-
[47]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
M. Mazeika, L. Phan, X. Yin, A. Zou, Z. Wang, N. Mu, E. Sakhaee, N. Li, S. Basart, B. Liet al., “Harmbench: A standardized evaluation framework for automated red teaming and robust refusal,”arXiv preprint arXiv:2402.04249, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Pleak: Prompt leaking attacks against large language model applications,
B. Hui, H. Yuan, N. Gong, P. Burlina, and Y . Cao, “Pleak: Prompt leaking attacks against large language model applications,” inACM SIGSAC Conference on Computer and Communications Security, 2024
2024
-
[49]
Instruction-Following Evaluation for Large Language Models
J. Zhou, T. Lu, S. Mishra, S. Brahma, S. Basu, Y . Luan, D. Zhou, and L. Hou, “Instruction-following evaluation for large language models,” arXiv preprint arXiv:2311.07911, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Okapi: Instruction-tuned large language models in multiple languages with reinforcement learning from human feedback,
V . Lai, C. Nguyen, N. Ngo, T. Nguy˜ ˆen, F. Dernoncourt, R. Rossi, and T. Nguyen, “Okapi: Instruction-tuned large language models in multiple languages with reinforcement learning from human feedback,” inConference on Empirical Methods in Natural Language Processing: System Demonstrations, 2023
2023
-
[51]
A new method supporting qualitative data analysis through prompt generation for inductive coding,
F. Zhao, F. Yu, and Y . Shang, “A new method supporting qualitative data analysis through prompt generation for inductive coding,” in IEEE International Conference on Information Reuse and Integration for Data Science (IRI), 2024
2024
-
[52]
Unlocking efficient long-to-short llm reasoning with model merging,
H. Wu, Y . Yao, S. Liu, Z. Liu, X. Fu, X. Han, X. Li, H.-L. Zhen, T. Zhong, and M. Yuan, “Unlocking efficient long-to-short llm reasoning with model merging,”arXiv preprint arXiv:2503.20641, 2025
-
[53]
Arcee’s mergekit: A toolkit for merging large language models,
C. Goddard, S. Siriwardhana, M. Ehghaghi, L. Meyers, V . Karpukhin, B. Benedict, M. McQuade, and J. Solawetz, “Arcee’s mergekit: A toolkit for merging large language models,”arXiv preprint arXiv:2403.13257, 2024
-
[54]
Merger-as-a-stealer: Stealing targeted pii from aligned llms with model merging,
L. Lu, Z. Zuo, Z. Sheng, and P. Zhou, “Merger-as-a-stealer: Stealing targeted pii from aligned llms with model merging,”arXiv preprint arXiv:2502.16094, 2025
-
[55]
Persistent pre-training poisoning of llms,
Y . Zhang, J. Rando, I. Evtimov, J. Chi, E. M. Smith, N. Carlini, F. Tram`er, and D. Ippolito, “Persistent pre-training poisoning of llms,” arXiv preprint arXiv:2410.13722, 2024
-
[56]
Thinktrap: Denial-of-service attacks against black-box llm services via infinite thinking,
Y . Li, J. Wang, H. Zhu, J. Lin, S. Chang, and M. Guo, “Thinktrap: Denial-of-service attacks against black-box llm services via infinite thinking,”arXiv preprint arXiv:2512.07086, 2025
-
[57]
Extracting training data from large language models,
N. Carlini, F. Tramer, E. Wallace, M. Jagielski, A. Herbert-V oss, K. Lee, A. Roberts, T. Brown, D. Song, U. Erlingssonet al., “Extracting training data from large language models,” inUSENIX Security Symposium, 2021
2021
-
[58]
Medtext,
BI55, “Medtext,” 2026. [Online]. Available: https://huggingface.co/ datasets/BI55/MedText
2026
-
[59]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakanoet al., “Training verifiers to solve math word problems,”arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[60]
Program Synthesis with Large Language Models
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Leet al., “Program synthesis with large language models,”arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[61]
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
I. Mirzadeh, K. Alizadeh, H. Shahrokhi, O. Tuzel, S. Bengio, and M. Farajtabar, “Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models,”arXiv preprint arXiv:2410.05229, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
A strongreject for empty jailbreaks,
A. Souly, Q. Lu, D. Bowen, T. Trinh, E. Hsieh, S. Pandey, P. Abbeel, J. Svegliato, S. Emmons, O. Watkinset al., “A strongreject for empty jailbreaks,”Advances in Neural Information Processing Systems, 2024
2024
-
[63]
A closer look at system prompt robustness,
N. Mu, J. Lu, M. Lavery, and D. Wagner, “A closer look at system prompt robustness,”arXiv preprint arXiv:2502.12197, 2025
-
[64]
awesome -chatgpt-prompts,
f, “awesome -chatgpt-prompts,” 2026. [Online]. Available: https: //github.com/f/awesome-chatgpt-prompts
2026
-
[65]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” International Conference on Learning Representations, 2022. Algorithm 1An Overview of RogueMerge Require: Base model Mbase, attacker’s local task dataset Dlocal, attack set Datk, utility preservation set Dutil, mergin...
2022
-
[66]
durable”. •Task prompt from IFEval for testing: Write a 300+ word summary of the wikipedia page “https://wikipedia.org/wiki/Raymond III, Count of Tripoli
focus on classification tasks. Several are not applicable to LLM merging, either because their mechanisms are incom- patible with generative attack objectives [12] or because they rely on different threat models. [12]. Although [54] targets PII extraction from LLMs, its approach relies on standard fine- tuning, which we find ineffective for our attack obj...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.