SynCred-Bench: Benchmarking Synthetic Credibility in AI-Generated Visual Misinformation
Pith reviewed 2026-06-28 11:14 UTC · model grok-4.3
The pith
Existing detectors and humans fail to spot most AI-generated images that mimic credible sources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
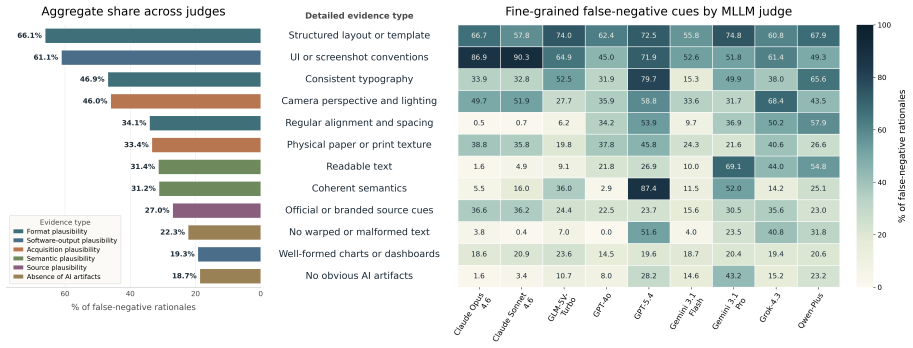
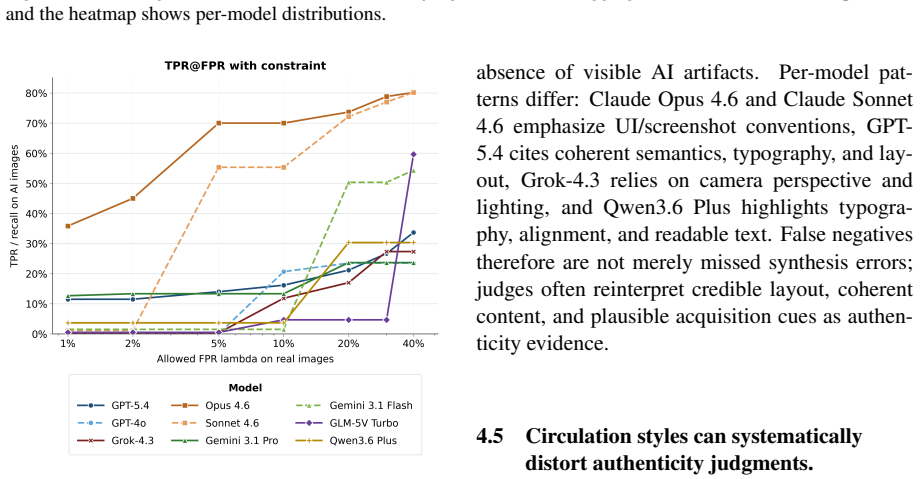
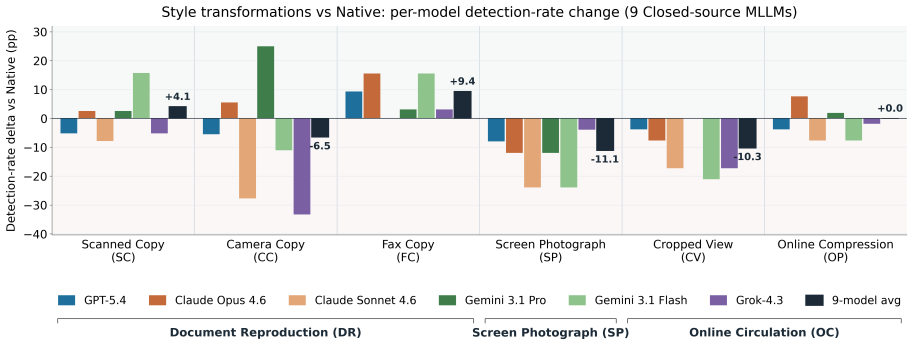
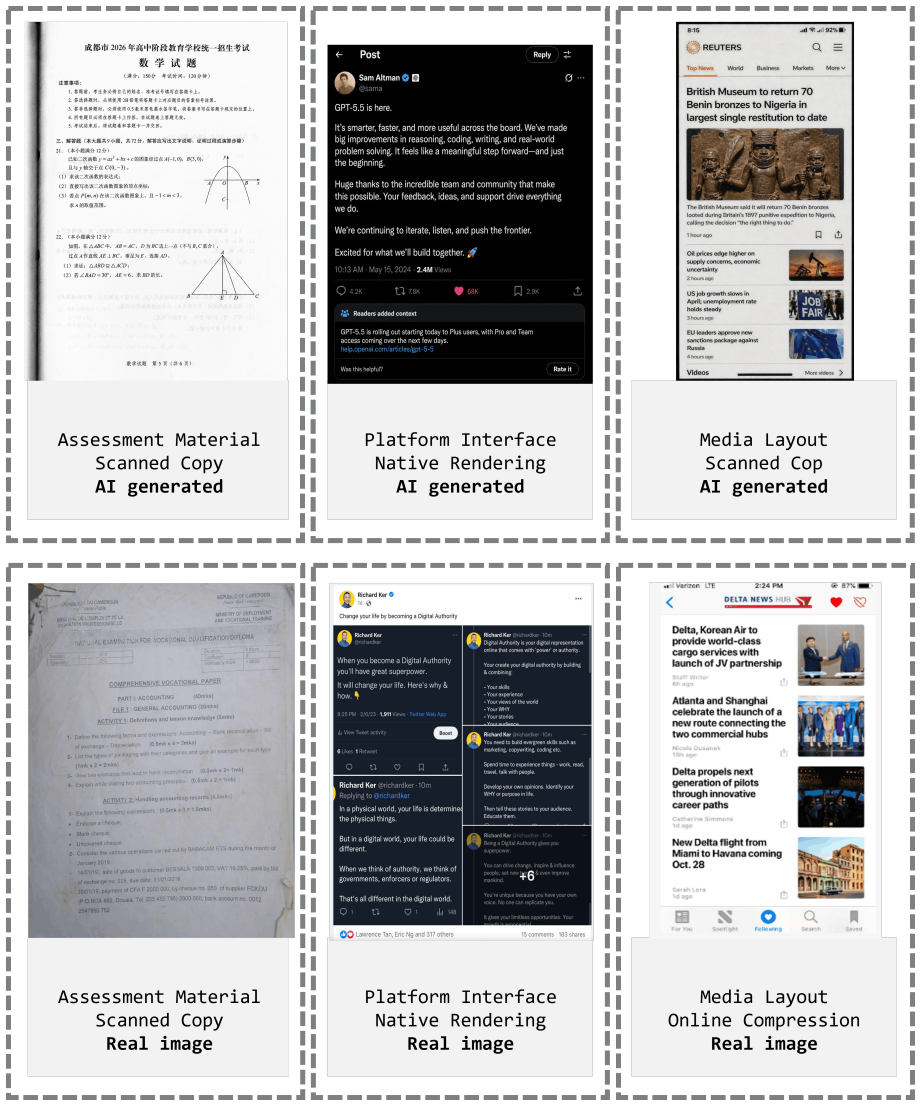
SYNCRED-Bench supplies 600 AI-generated misinformation images balanced across six credible-form categories and seven fine-grained circulation styles together with FP450 real-image negatives. Under a 5 percent false-positive-rate constraint the benchmark shows 15 MLLMs achieve only 10.5 percent true positive rate, open-source AIGC detectors less than 5 percent, commercial APIs 57.6 percent, and human annotators 63 percent, establishing synthetic credibility as a severe underexplored challenge that requires detectors able to reason beyond superficial cues.
What carries the argument
SYNCRED-Bench, a balanced collection of 600 AI-generated images across credible-form categories and circulation styles paired with real negative examples for false-positive control.
If this is right
- Current multimodal large language models remain inadequate for identifying synthetic credibility at practical false-positive levels.
- Open-source AIGC detectors perform markedly worse than commercial APIs on this task.
- Human annotators also fail to reach high accuracy, showing the difficulty is not limited to automated systems.
- Effective detectors will need to examine deeper credibility reasoning instead of relying on visual artifacts alone.
Where Pith is reading between the lines
- Widespread use of such images could increase the reach of misinformation formatted to resemble legitimate news sources.
- The benchmark's circulation styles point to risks in social-media and news-sharing environments where these fakes would appear.
- Development of new detectors focused on text-layout consistency and source plausibility becomes a direct next step.
Load-bearing premise
The 600 generated images and 450 real negatives form a representative and unbiased test of the synthetic credibility threat.
What would settle it
A detection method that reaches substantially above 57.6 percent true positive rate at 5 percent false positive rate on the SYNCRED-Bench set while remaining stable on additional real images.
Figures






read the original abstract
Recent generative models can now produce visual artifacts with realistic embedded text and layouts, creating a new misinformation threat: synthetic credibility. We introduce SYNCRED-Bench, a benchmark of 600 AI-generated misinformation images balanced across six credible-form categories and seven fine-grained circulation styles, together with FP450, a real-image negative set for measuring false positives. Extensive evaluation shows that existing systems remain unreliable: under a 5% false-positive-rate constraint, 15 MLLMs achieve only 10.5% true positive rate (TPR), open-source AIGC detectors achieve less than 5%, and commercial APIs reach 57.6%. Human annotators also struggled to identify synthetic credibility, reaching only 63% TPR. These findings establish synthetic credibility as a severe and underexplored visual misinformation challenge, and provide a benchmark for developing detectors that reason beyond superficial credibility cues.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SynCred-Bench, a benchmark consisting of 600 AI-generated misinformation images balanced across six credible-form categories and seven fine-grained circulation styles, paired with the FP450 real-image negative set. It evaluates 15 MLLMs, open-source AIGC detectors, commercial APIs, and human annotators for synthetic credibility detection, reporting TPRs of 10.5%, less than 5%, 57.6%, and 63% respectively under a fixed 5% FPR constraint, and concludes that this constitutes a severe and underexplored challenge for existing detection systems.
Significance. If the benchmark distribution is representative of real-world conditions, the low TPR results would demonstrate a meaningful gap in current detectors' ability to handle AI-generated images with realistic embedded text and layouts. The release of a new, publicly usable benchmark dataset with controlled category and style axes is a concrete contribution that can support future detector development.
major comments (2)
- [§3 (Benchmark Construction)] §3 (Benchmark Construction): The 600-image set is stated to be balanced across six credible-form categories and seven circulation styles, yet the manuscript supplies no frequency statistics drawn from real misinformation corpora, no external validation of category prevalence, and no ablation showing that the reported TPRs remain stable under re-weighting to observed real-world distributions. Because the central claim that existing detectors are unreliable on synthetic credibility (and that the threat is severe) rests on this set being representative, the absence of such grounding is load-bearing.
- [§4 (Evaluation Protocol)] §4 (Evaluation Protocol): The 5% FPR operating point is used to report all TPR numbers, but the manuscript does not detail how thresholds were chosen on the FP450 negative set or whether per-category or per-style calibration was performed; without this, it is unclear whether the aggregate 10.5% MLLM TPR (or the <5% open-source figure) could shift materially under different negative-set constructions.
minor comments (2)
- [Table 2] Table 2: The per-model TPR columns would be easier to interpret if they also reported the exact number of images per category on which each model was evaluated.
- The abstract's phrasing that the images are 'balanced across' categories would be strengthened by an explicit statement of the per-category count (e.g., 100 images each) in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Below we respond point-by-point to the two major comments, indicating planned revisions where appropriate. We have aimed to strengthen the manuscript without overstating what the current benchmark can claim.
read point-by-point responses
-
Referee: [§3 (Benchmark Construction)] The 600-image set is stated to be balanced across six credible-form categories and seven circulation styles, yet the manuscript supplies no frequency statistics drawn from real misinformation corpora, no external validation of category prevalence, and no ablation showing that the reported TPRs remain stable under re-weighting to observed real-world distributions. Because the central claim that existing detectors are unreliable on synthetic credibility (and that the threat is severe) rests on this set being representative, the absence of such grounding is load-bearing.
Authors: We agree that the manuscript lacks frequency statistics from real misinformation corpora and external validation of prevalence. The benchmark was constructed to ensure coverage across a diverse set of credible-form categories and circulation styles drawn from observed patterns in recent AI-generated misinformation, rather than to match empirical prevalence distributions. The central claim concerns the existence of a detection gap on images exhibiting synthetic credibility, which is demonstrated by the uniformly low TPRs across the balanced axes. In revision we will expand §3 to (1) cite the literature sources used for category and style selection, (2) explicitly state that the set is not prevalence-weighted, and (3) add a limitations paragraph together with a sensitivity analysis that re-weights the reported TPRs under several hypothetical real-world distributions. We cannot supply the requested frequency statistics, as they would require a separate large-scale corpus study outside the scope of this benchmark paper. revision: partial
-
Referee: [§4 (Evaluation Protocol)] The 5% FPR operating point is used to report all TPR numbers, but the manuscript does not detail how thresholds were chosen on the FP450 negative set or whether per-category or per-style calibration was performed; without this, it is unclear whether the aggregate 10.5% MLLM TPR (or the <5% open-source figure) could shift materially under different negative-set constructions.
Authors: The current manuscript does not provide the requested procedural details. Thresholds were selected globally on the full FP450 set to enforce exactly 5% FPR for each detector independently, without per-category or per-style stratification. In the revised manuscript we will expand §4 with (1) a precise description of the threshold-selection procedure (including the formula used), (2) per-category and per-style TPR tables evaluated at the global 5% FPR point, and (3) an additional experiment that subsamples FP450 to test sensitivity of the aggregate TPRs to negative-set composition. These additions will make the evaluation protocol fully reproducible and allow readers to assess potential shifts. revision: yes
- Providing quantitative frequency statistics drawn from real misinformation corpora and external validation of category prevalence
Circularity Check
Empirical benchmark with no derivations or fitted predictions
full rationale
The paper creates a benchmark of 600 generated images plus FP450 negatives and reports empirical TPR/FPR numbers for existing MLLMs, detectors, APIs, and humans. No equations, parameters, or derivations appear in the provided text. The six credible-form categories and seven circulation styles are used only to construct the test set; performance numbers are direct measurements on that set rather than predictions derived from fitted inputs. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are present. The skeptic concern about representativeness is a question of external validity, not circularity under the enumerated patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The six credible-form categories and seven circulation styles, plus the FP450 real-image set, constitute a valid and balanced test of synthetic credibility detection.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
High-Resolution Image Synthesis with Latent Diffusion Models , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =. 2022 , url =
2022
-
[2]
Hierarchical Text-Conditional Image Generation with CLIP Latents , author =. 2022 , url =. 2204.06125 , archivePrefix =
Pith/arXiv arXiv 2022
-
[3]
Advances in Neural Information Processing Systems , volume =
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
2022
-
[4]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
InstructPix2Pix: Learning to Follow Image Editing Instructions , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =. 2023 , url =
2023
-
[5]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
Adding Conditional Control to Text-to-Image Diffusion Models , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =. 2023 , url =
2023
-
[6]
Advances in Neural Information Processing Systems , volume =
TextDiffuser: Diffusion Models as Text Painters , author =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
2023
-
[7]
European Conference on Computer Vision , year =
TextDiffuser-2: Unleashing the Power of Language Models for Text Rendering , author =. European Conference on Computer Vision , year =
-
[8]
International Conference on Learning Representations , year =
AnyText: Multilingual Visual Text Generation and Editing , author =. International Conference on Learning Representations , year =
-
[9]
for Now , author =
CNN-Generated Images Are Surprisingly Easy to Spot... for Now , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =. 2020 , url =
2020
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Towards Universal Fake Image Detectors that Generalize Across Generative Models , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =. 2023 , url =
2023
-
[11]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
DIRE for Diffusion-Generated Image Detection , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =. 2023 , url =
2023
-
[12]
Zhu, Mingjian and Chen, Hanting and Yan, Qiangyu and Huang, Xudong and Lin, Guanyu and Li, Wei and Tu, Zhijun and Hu, Hailin and Hu, Jie and Wang, Yunhe , booktitle =. 2023 , url =. 2306.08571 , archivePrefix =
arXiv 2023
-
[13]
International Conference on Learning Representations , year =
A Sanity Check for AI-Generated Image Detection , author =. International Conference on Learning Representations , year =. 2406.19435 , archivePrefix =
-
[14]
Is Artificial Intelligence Generated Image Detection a Solved Problem? , author =. 2025 , url =. 2505.12335 , archivePrefix =
arXiv 2025
-
[15]
Pellegrini, Lorenzo and Cozzolino, Davide and Pandolfini, Serafino and Maltoni, Davide and Ferrara, Matteo and Verdoliva, Luisa and Prati, Marco and Ramilli, Marco , booktitle =. 2025 , doi =. 2504.20865 , archivePrefix =
arXiv 2025
-
[16]
DFBench: Benchmarking Deepfake Image Detection Capability of Large Multimodal Models , author =. 2025 , url =. 2506.03007 , archivePrefix =
arXiv 2025
-
[17]
ForensicHub: A Unified Benchmark & Codebase for All-Domain Fake Image Detection and Localization , author =. 2025 , url =. 2505.11003 , archivePrefix =
arXiv 2025
-
[18]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
FaceForensics++: Learning to Detect Manipulated Facial Images , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =. 2019 , url =
2019
-
[19]
Yan, Zhiyuan and Zhang, Yong and Yuan, Xinhang and Lyu, Siwei and Wu, Baoyuan , booktitle =. 2023 , url =. 2307.01426 , archivePrefix =
arXiv 2023
-
[20]
DF40: Toward Next-Generation Deepfake Detection , author =. 2024 , url =. 2406.13495 , archivePrefix =
arXiv 2024
-
[21]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
ManTra-Net: Manipulation Tracing Network for Detection and Localization of Image Forgeries with Anomalous Features , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =. 2019 , url =
2019
-
[22]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
Image Manipulation Detection by Multi-View Multi-Scale Supervision , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =. 2021 , url =
2021
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
TruFor: Leveraging All-Round Clues for Trustworthy Image Forgery Detection and Localization , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =. 2023 , url =
2023
-
[24]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Towards Robust Tampered Text Detection in Document Image: New Dataset and New Solution , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =. 2023 , url =
2023
-
[25]
AIForge-Doc: A Benchmark for Detecting AI-Forged Tampering in Financial and Form Documents , author =. 2026 , url =. 2602.20569 , archivePrefix =
arXiv 2026
-
[26]
DOCFORGE-BENCH: A Comprehensive 0-shot Benchmark for Document Forgery Detection and Analysis , author =. 2026 , url =. 2603.01433 , archivePrefix =
arXiv 2026
-
[27]
When the Forger Is the Judge: GPT-Image-2 Cannot Recognize Its Own Faked Documents , author =. 2026 , url =. 2604.25213 , archivePrefix =
Pith/arXiv arXiv 2026
-
[28]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages =
``Liar, Liar Pants on Fire'': A New Benchmark Dataset for Fake News Detection , author =. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages =. 2017 , doi =
2017
-
[29]
Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , pages =
FEVER: A Large-Scale Dataset for Fact Extraction and VERification , author =. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , pages =. 2018 , doi =
2018
-
[30]
2020 , publisher =
Nakamura, Kai and Levy, Sharon and Wang, William Yang , booktitle =. 2020 , publisher =
2020
-
[31]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages =
Visual News: Benchmark and Challenges in News Image Captioning , author =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages =. 2021 , doi =
2021
-
[32]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Aneja, Shivangi and Bregler, Chris and Nie. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2023 , doi =. 2101.06278 , archivePrefix =
arXiv 2023
-
[33]
Luo, Grace and Darrell, Trevor and Rohrbach, Anna , booktitle =. 2021 , publisher =. doi:10.18653/v1/2021.emnlp-main.545 , url =
-
[34]
International Journal of Multimedia Information Retrieval , volume =
VERITE: A Robust Benchmark for Multimodal Misinformation Detection Accounting for Unimodal Bias , author =. International Journal of Multimedia Information Retrieval , volume =. 2024 , doi =
2024
-
[35]
Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =
End-to-End Multimodal Fact-Checking and Explanation Generation: A Challenging Dataset and Models , author =. Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2023 , doi =
2023
-
[36]
Factify 2: A Multimodal Fake News and Satire News Dataset , author =. 2023 , url =. 2304.03897 , archivePrefix =
arXiv 2023
-
[37]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =
FACTIFY3M: A Benchmark for Multimodal Fact Verification with Explainability through 5W Question-Answering , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =. doi:10.18653/v1/2023.emnlp-main.945 , url =
-
[38]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Detecting and Grounding Multi-Modal Media Manipulation , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =. 2023 , url =
2023
-
[39]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models , author =. 2023 , url =. 2306.13394 , archivePrefix =
Pith/arXiv arXiv 2023
-
[40]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =
Evaluating Object Hallucination in Large Vision-Language Models , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =. 2023 , url =
2023
-
[41]
Findings of the Association for Computational Linguistics: ACL 2024 , year =
Aligning Large Multimodal Models with Factually Augmented RLHF , author =. Findings of the Association for Computational Linguistics: ACL 2024 , year =
2024
-
[42]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
HallusionBench: An Advanced Diagnostic Suite for Entangled Language Hallucination and Visual Illusion in Large Vision-Language Models , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[43]
European Conference on Computer Vision , pages =
MM-SafetyBench: A Benchmark for Safety Evaluation of Multimodal Large Language Models , author =. European Conference on Computer Vision , pages =. 2024 , publisher =. doi:10.1007/978-3-031-72992-8_22 , url =
-
[44]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
FigStep: Jailbreaking Large Vision-Language Models via Typographic Visual Prompts , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2025 , doi =
2025
-
[45]
International Journal of Computer Vision , year =
SafeBench: A Safety Evaluation Framework for Multimodal Large Language Models , author =. International Journal of Computer Vision , year =. doi:10.1007/s11263-025-02613-1 , url =
-
[46]
2025 , url =
C2PA Technical Specification, Version 2.4 , author =. 2025 , url =
2025
-
[47]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
The Stable Signature: Rooting Watermarks in Latent Diffusion Models , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =. 2023 , url =
2023
-
[48]
Advances in Neural Information Processing Systems , volume =
Tree-Ring Watermarks: Fingerprints for Diffusion Images that are Invisible and Robust , author =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
2023
-
[49]
SynthID-Image: Image Watermarking at Internet Scale , author =. 2025 , url =. 2510.09263 , archivePrefix =
arXiv 2025
-
[50]
He, Yinan and Gan, Bei and Chen, Siyu and Zhou, Yichun and Yin, Guojun and Song, Luchuan and Sheng, Lu and Shao, Jing and Liu, Ziwei , booktitle =
-
[51]
Bammey, Quentin , journal =
-
[52]
Ye, Junyan and Zhou, Baichuan and Huang, Zilong and Zhang, Junan and Bai, Tianyi and Kang, Hengrui and He, Jun and Lin, Honglin and Wang, Zihao and Wu, Tong and Wu, Zhizheng and Chen, Yiping and Lin, Dahua and He, Conghui and Li, Weijia , booktitle =
-
[53]
Wang, Jin and Lv, Chenghui and Li, Xian and Dong, Shichao and Li, Huadong and Yao, Kelu and Li, Chao and Shao, Wenqi and Luo, Ping , booktitle =
-
[54]
2025 , url =
Liu, Xuannan and Li, Zekun and Li, Pei Pei and Huang, Huaibo and Xia, Shuhan and Cui, Xing and Huang, Linzhi and Deng, Weihong and He, Zhaofeng , booktitle =. 2025 , url =
2025
-
[55]
Proceedings of the International AAAI Conference on Web and Social Media , volume =
Identifying Misinformation from Website Screenshots , author =. Proceedings of the International AAAI Conference on Web and Social Media , volume =. 2021 , doi =
2021
-
[56]
2018 , publisher =
Wang, Yaqing and Ma, Fenglong and Jin, Zhiwei and Yuan, Ye and Xun, Guangxu and Jha, Kishlay and Su, Lu and Gao, Jing , booktitle =. 2018 , publisher =
2018
-
[57]
Zhou, Xinyi and Wu, Jindi and Zafarani, Reza , booktitle =. 2020 , publisher =. doi:10.1007/978-3-030-47436-2_27 , series =
-
[58]
2020 , doi =
Shu, Kai and Mahudeswaran, Deepak and Wang, Suhang and Lee, Dongwon and Liu, Huan , journal =. 2020 , doi =
2020
-
[59]
Proceedings of the 33rd ACM International Conference on Information and Knowledge Management , pages =
Multimodal Misinformation Detection using Large Vision-Language Models , author =. Proceedings of the 33rd ACM International Conference on Information and Knowledge Management , pages =. 2024 , publisher =
2024
-
[60]
Multimodal Misinformation Detection by Learning from Synthetic Data with Multimodal
Zeng, Fengzhu and Li, Wenqian and Gao, Wei and Pang, Yan , booktitle =. Multimodal Misinformation Detection by Learning from Synthetic Data with Multimodal. 2024 , publisher =
2024
-
[61]
2024 , doi =
Liu, Xuannan and Li, Peipei and Huang, Huaibo and Li, Zekun and Cui, Xing and Liang, Jiahao and Qin, Lixiong and Deng, Weihong and He, Zhaofeng , journal =. 2024 , doi =
2024
-
[62]
Computer Vision -- ECCV 2022 , pages =
Detecting Tampered Scene Text in the Wild , author =. Computer Vision -- ECCV 2022 , pages =. 2022 , publisher =
2022
-
[63]
Revisiting Tampered Scene Text Detection in the Era of Generative
Qu, Chenfan and Zhong, Yiwu and Guo, Fengjun and Jin, Lianwen , booktitle =. Revisiting Tampered Scene Text Detection in the Era of Generative
-
[64]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
The Stable Signature: Rooting Watermarks in Latent Diffusion Models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
-
[65]
arXiv preprint arXiv:2309.14525 , year=
Aligning Large Multimodal Models with Factually Augmented RLHF , author=. arXiv preprint arXiv:2309.14525 , year=
-
[66]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
RLHF-V: Towards Trustworthy MLLMs via Behavior Alignment from Fine-grained Correctional Human Feedback , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[67]
2023 , url =
Improving Image Generation with Better Captions , author =. 2023 , url =
2023
-
[68]
2025 , month = mar, url =
Addendum to. 2025 , month = mar, url =
2025
-
[69]
Singh, Mandeep and Okcular, Emre , year =
-
[70]
Proceedings of the First Workshop on Writing Aids at the Crossroads of AI, Cognitive Science and NLP (WRAICOGS 2025). 2025
2025
-
[71]
Chain-of- M eta W riting: Linguistic and Textual Analysis of How Small Language Models Write Young Students Texts
Buhnila, Ioana and Cislaru, Georgeta and Todirascu, Amalia. Chain-of- M eta W riting: Linguistic and Textual Analysis of How Small Language Models Write Young Students Texts. 2025
2025
-
[72]
Semantic Masking in a Needle-in-a-haystack Test for Evaluating Large Language Model Long-Text Capabilities
Shi, Ken and Penn, Gerald. Semantic Masking in a Needle-in-a-haystack Test for Evaluating Large Language Model Long-Text Capabilities. 2025
2025
-
[73]
Reading Between the Lines: A dataset and a study on why some texts are tougher than others
Khallaf, Nouran and Eugeni, Carlo and Sharoff, Serge. Reading Between the Lines: A dataset and a study on why some texts are tougher than others. 2025
2025
-
[74]
P ara R ev : Building a dataset for Scientific Paragraph Revision annotated with revision instruction
Jourdan, L \'e ane and Boudin, Florian and Dufour, Richard and Hernandez, Nicolas and Aizawa, Akiko. P ara R ev : Building a dataset for Scientific Paragraph Revision annotated with revision instruction. 2025
2025
-
[75]
Towards an operative definition of creative writing: a preliminary assessment of creativeness in AI and human texts
Maggi, Chiara and Vitaletti, Andrea. Towards an operative definition of creative writing: a preliminary assessment of creativeness in AI and human texts. 2025
2025
-
[76]
Decoding Semantic Representations in the Brain Under Language Stimuli with Large Language Models
Sato, Anna and Kobayashi, Ichiro. Decoding Semantic Representations in the Brain Under Language Stimuli with Large Language Models. 2025
2025
-
[77]
Proceedings of the 4th Workshop on Arabic Corpus Linguistics (WACL-4). 2025
2025
-
[78]
A rabic S ense: A Benchmark for Evaluating Commonsense Reasoning in A rabic with Large Language Models
Lamsiyah, Salima and Zeinalipour, Kamyar and El amrany, Samir and Brust, Matthias and Maggini, Marco and Bouvry, Pascal and Schommer, Christoph. A rabic S ense: A Benchmark for Evaluating Commonsense Reasoning in A rabic with Large Language Models. 2025
2025
-
[79]
Lahjawi: A rabic Cross-Dialect Translator
Hamed, Mohamed Motasim and Hreden, Muhammad and Hennara, Khalil and Aldallal, Zeina and Chrouf, Sara and AlModhayan, Safwan. Lahjawi: A rabic Cross-Dialect Translator. 2025
2025
-
[80]
Lost in Variation: An Unsupervised Methodology for Mining Lexico-syntactic Patterns in Middle A rabic Texts
Bezan. Lost in Variation: An Unsupervised Methodology for Mining Lexico-syntactic Patterns in Middle A rabic Texts. 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.