Selective Token-Level Cryptographic Redaction for Privacy-Preserving Clinical Deployment of Large Language Models
Pith reviewed 2026-06-28 10:17 UTC · model grok-4.3
The pith
HERALD selectively encrypts sensitive clinical tokens while recovering near-plaintext LLM performance
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
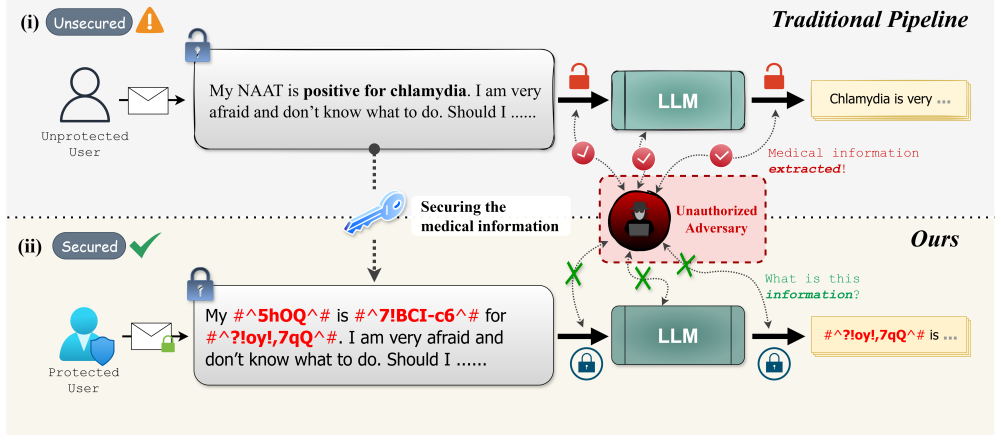
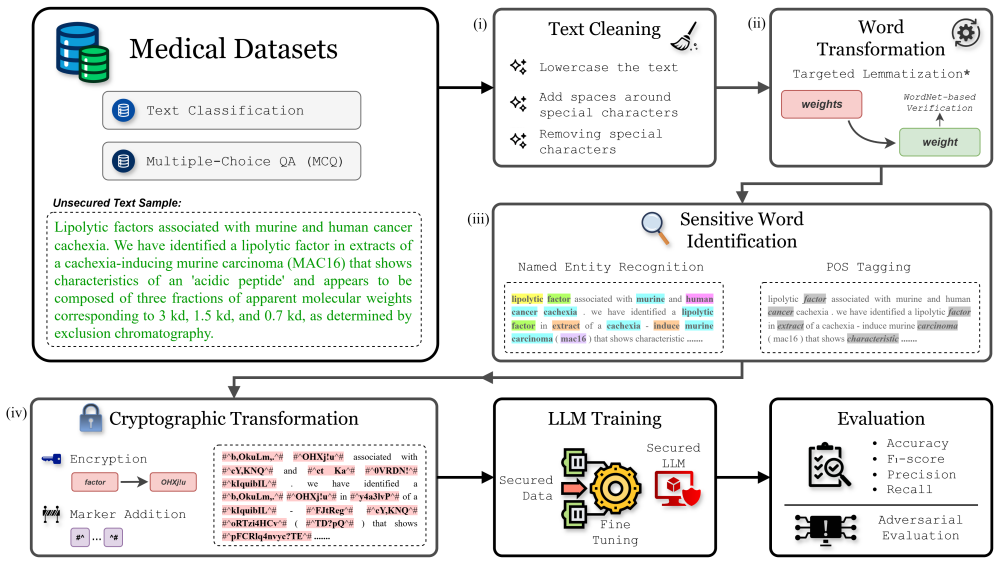
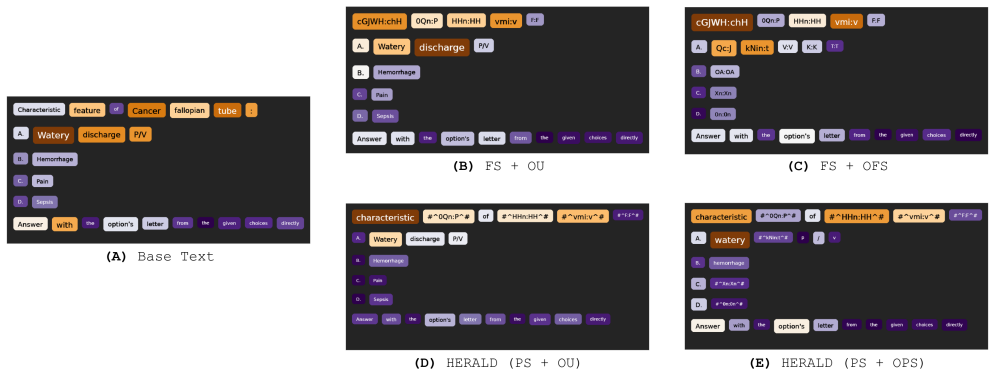
HERALD uses medical named-entity recognizer combined with part-of-speech driven policies to select candidate tokens for protection, performs targeted lemmatization to stabilize surface forms, and substitutes each protected token with a deterministic ciphertext wrapped in explicit delimiters, resulting in performance close to plaintext on classification and medical question answering tasks while fully securing sensitive tokens.
What carries the argument
The HERALD framework, which performs targeted token selection via medical NER and POS policies followed by lemmatization and delimited ciphertext substitution for redaction.
If this is right
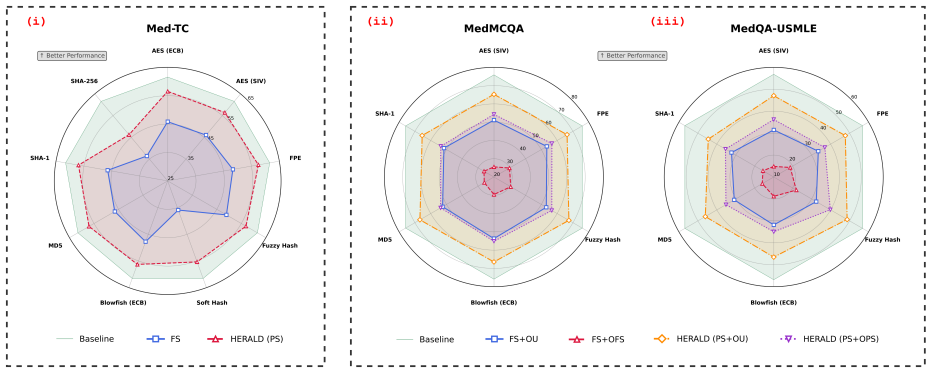
- Recovers performance close to plaintext across classification and medical QA tasks.
- Fully secured baselines suffer significant utility loss.
- Sensitive tokens remain fully encrypted during storage, transmission, and processing.
- Operates entirely on the client side without requiring changes to downstream models.
- Provides a practical utilization pipeline for privacy-preserving clinical LLM deployment.
Where Pith is reading between the lines
- This selective approach could apply to other domains with sensitive text like legal or financial data.
- Future work might explore adaptive policies that learn from model feedback on utility.
- Combining with homomorphic encryption for the encrypted parts could allow some computation without decryption.
- Deployment in real hospitals would require validation on de-identified but realistic patient notes.
Load-bearing premise
The combination of medical NER and POS-driven policies will correctly identify all sensitive tokens without missing critical private information or over-redacting context that the LLM needs for utility.
What would settle it
Observing either leakage of a sensitive token in plaintext or a performance drop exceeding 5-10% relative to plaintext on held-out clinical datasets would falsify the claim of effective balance.
Figures


read the original abstract
While large language models (LLMs) are increasingly used for clinical applications, many existing pipelines require sending raw sensitive health information to remote servers for processing, which heightens the risk of privacy leakage. A natural approach to mitigate this risk is to encrypt the data before transmission. However, straightforward solutions such as encrypting the entire dataset introduce prohibitive computational, alignment, and communication overheads, rendering large-scale practical deployment infeasible. To preserve privacy while maintaining usability, we present Healthcare Encryption & Redaction via Adaptive Linguistic Decomposition (HERALD), a token-level cryptographic redaction framework designed to achieve this balance by encrypting only sensitive tokens while preserving the surrounding context for downstream model utility. HERALD combines medical named-entity recognizer (NER) with part-of-speech (POS) driven policies to select candidate tokens, performs targeted lemmatization to stabilize surface forms, and substitutes each protected token with a deterministic ciphertext wrapped in explicit delimiters. Notably, HERALD is model-agnostic and operates entirely on the client side, ensuring that sensitive content remains encrypted throughout storage, transmission, and processing without requiring changes to downstream models. We evaluated HERALD on both classification and medical question answering (MQA) tasks on public datasets. Across different tasks, experiments illustrate that fully secured baselines suffer significant utility loss, whereas HERALD consistently recovers performance close to plaintext. Overall, HERALD provides a novel utilization pipeline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HERALD, a client-side token-level cryptographic redaction framework for privacy-preserving clinical LLM use. It combines medical named-entity recognition (NER) with part-of-speech (POS) driven policies to select and encrypt only sensitive tokens via deterministic ciphertext substitution after lemmatization, while leaving surrounding context intact. The central claim is that, on classification and medical question-answering tasks over public datasets, HERALD recovers performance close to plaintext levels, whereas fully secured baselines incur significant utility loss; the method is presented as model-agnostic and requiring no downstream model changes.
Significance. If the token-selection component is shown to be accurate and the experimental results are reproducible, the work would provide a practical, low-overhead pipeline for deploying LLMs on sensitive clinical data without server-side modifications or full encryption costs. The client-side, model-agnostic design is a clear strength that aligns with real deployment constraints.
major comments (2)
- [Abstract and evaluation sections] Abstract and evaluation sections: both the privacy guarantee ('fully securing sensitive tokens') and the utility-recovery claim rest on the medical NER + POS-driven policies correctly identifying exactly the sensitive tokens. The manuscript supplies no precision, recall, or error analysis for this selection step on the evaluation datasets, nor any quantification of missed private entities or context loss; downstream task results alone cannot distinguish correct redaction from coincidental robustness.
- [Abstract] Abstract: the claim that 'experiments illustrate that ... HERALD consistently recovers performance close to plaintext' is unsupported by any named datasets, metrics (accuracy, F1, etc.), baseline descriptions, number of runs, or error bars. Without these details the reported performance gap cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for explicit validation of the token-selection pipeline and clearer experimental reporting. We address each major comment below and will revise the manuscript to strengthen these aspects.
read point-by-point responses
-
Referee: [Abstract and evaluation sections] Abstract and evaluation sections: both the privacy guarantee ('fully securing sensitive tokens') and the utility-recovery claim rest on the medical NER + POS-driven policies correctly identifying exactly the sensitive tokens. The manuscript supplies no precision, recall, or error analysis for this selection step on the evaluation datasets, nor any quantification of missed private entities or context loss; downstream task results alone cannot distinguish correct redaction from coincidental robustness.
Authors: We agree that the accuracy of the NER + POS token-selection step is foundational to the privacy and utility claims, and that downstream task performance alone is insufficient to validate it. The current manuscript does not report precision, recall, or error analysis for this component on the evaluation datasets, nor does it quantify missed private entities or context loss. In the revised version we will add a dedicated subsection in the evaluation section that measures token-selection performance (precision/recall/F1) against gold annotations on the same public datasets used for the main experiments, together with an analysis of any missed entities and resulting context impact. revision: yes
-
Referee: [Abstract] Abstract: the claim that 'experiments illustrate that ... HERALD consistently recovers performance close to plaintext' is unsupported by any named datasets, metrics (accuracy, F1, etc.), baseline descriptions, number of runs, or error bars. Without these details the reported performance gap cannot be assessed.
Authors: The abstract is intentionally concise, while the full evaluation section names the specific public datasets, reports accuracy/F1 scores, describes the fully-secured baselines, states the number of runs, and includes error bars or variance measures. To address the referee's concern we will expand the abstract to explicitly reference the datasets, metrics, and key quantitative results (with pointers to the detailed tables and sections) so that the performance claims are self-contained at the abstract level. revision: yes
Circularity Check
No circularity; method is an independent client-side pipeline
full rationale
The paper presents HERALD as a descriptive engineering pipeline combining off-the-shelf medical NER with POS-driven policies for token selection, followed by deterministic encryption. No equations, fitted parameters, or predictions appear in the provided text. No self-citations are invoked as load-bearing premises, and the central claims rest on external tool performance rather than any reduction to the paper's own inputs by construction. This matches the default expectation of a non-circular methods paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- NER and POS selection policies
axioms (1)
- domain assumption Existing medical NER tools can reliably detect sensitive clinical entities
Reference graph
Works this paper leans on
-
[1]
Large language models in medicine,
A. J. Thirunavukarasu, D. S. J. Ting, K. Elangovan, L. Gutier- rez, T. F. Tan, and D. S. W. Ting, “Large language models in medicine,”Nature medicine, vol. 29, no. 8, pp. 1930–1940,
1930
-
[2]
H. Xiao, F. Zhou, X. Liu, T. Liu, Z. Li, X. Liu, and X. Huang, “A comprehensive survey of large language models and mul- 17 timodal large language models in medicine,”arXiv preprint arXiv:2405.08603, 2024
-
[3]
Large language models in healthcare and medical domain: A review,
Z. A. Nazi and W. Peng, “Large language models in healthcare and medical domain: A review,” inInformatics, vol. 11, p. 57, MDPI, 2024
2024
-
[4]
Evaluating large language model workflows in clinical decision support for triage and referral and diagnosis,
F. Gaber, M. Shaik, F. Allega, A. J. Bilecz, F. Busch, K. Goon, V . Franke, and A. Akalin, “Evaluating large language model workflows in clinical decision support for triage and referral and diagnosis,”npj Digital Medicine, vol. 8, no. 1, p. 263, 2025
2025
-
[5]
A critical assessment of using chatgpt for extracting structured data from clinical notes,
J. Huang, D. M. Yang, R. Rong, K. Nezafati, C. Treager, Z. Chi, S. Wang, X. Cheng, Y . Guo, L. J. Klesse,et al., “A critical assessment of using chatgpt for extracting structured data from clinical notes,”NPJ digital medicine, vol. 7, no. 1, p. 106, 2024. 1, 8
2024
-
[6]
ChatGPT (July 2025 version)
OpenAI, “ChatGPT (July 2025 version).” [Large language model], 2025. Accessed via chat.openai.com. 1
2025
-
[7]
Gemini: A Family of Highly Capable Multimodal Models
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Sori- cut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millican,et al., “Gemini: a family of highly capable multimodal models,” arXiv preprint arXiv:2312.11805, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Privacy preserving strate- gies for electronic health records in the era of large language models,
J. Jonnagaddala and Z. S.-Y . Wong, “Privacy preserving strate- gies for electronic health records in the era of large language models,”npj Digital Medicine, vol. 8, no. 1, p. 34, 2025. 1
2025
-
[9]
Beyond memorization: Violating privacy via inference with large language models,
R. Staab, M. Vero, M. Balunovi´c, and M. Vechev, “Beyond memorization: Violating privacy via inference with large language models,”arXiv preprint arXiv:2310.07298, 2023. 1
-
[10]
Training data extraction from pre-trained lan- guage models: A survey,
S. Ishihara, “Training data extraction from pre-trained lan- guage models: A survey,”arXiv preprint arXiv:2305.16157, 2023
-
[11]
Jailbreaking and Mitigation of Vulnerabilities in Large Language Models
B. Peng, K. Chen, Q. Niu, Z. Bi, M. Liu, P. Feng, T. Wang, L. K. Yan, Y . Wen, Y . Zhang,et al., “Jailbreaking and mit- igation of vulnerabilities in large language models,”arXiv preprint arXiv:2410.15236, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Artificial intelligence and the hipaa privacy rule: A primer,
S. A. Tovino, “Artificial intelligence and the hipaa privacy rule: A primer,”Houston Journal of Health Law & Policy, vol. 24, no. 1, pp. 77–126, 2025. 2
2025
-
[13]
Bal- ancing innovation and privacy: The intersection of data pro- tection and artificial intelligence,
A. K. Y . Yanamala, S. Suryadevara, and V . D. R. Kalli, “Bal- ancing innovation and privacy: The intersection of data pro- tection and artificial intelligence,”International Journal of Machine Learning Research in Cybersecurity and Artificial Intelligence, vol. 15, no. 1, pp. 1–43, 2024. 2
2024
-
[14]
Privacy-preserving large language models: Mechanisms, applications, and future directions,
G. Zhao and E. Song, “Privacy-preserving large language models: Mechanisms, applications, and future directions,” arXiv preprint arXiv:2412.06113, 2024. 2, 14
-
[15]
Cryptonets: Applying neu- ral networks to encrypted data with high throughput and ac- curacy,
R. Gilad-Bachrach, N. Dowlin, K. Laine, K. Lauter, M. Naehrig, and J. Wernsing, “Cryptonets: Applying neu- ral networks to encrypted data with high throughput and ac- curacy,” inInternational conference on machine learning, pp. 201–210, PMLR, 2016. 15
2016
-
[16]
EncryptedLLM: Privacy-preserving large language model inference via GPU-accelerated fully homo- morphic encryption,
L. de Castro, D. Escudero, A. Agrawal, A. Polychroniadou, and M. Veloso, “EncryptedLLM: Privacy-preserving large language model inference via GPU-accelerated fully homo- morphic encryption,” inForty-second International Confer- ence on Machine Learning, 2025
2025
-
[17]
Encryption-friendly llm architecture,
D. Rho, T. Kim, M. Park, J. W. Kim, H. Chae, E. K. Ryu, and J. H. Cheon, “Encryption-friendly llm architecture,”arXiv preprint arXiv:2410.02486, 2024. 2
-
[18]
Differentially private decoding in large language models,
J. Majmudar, C. Dupuy, C. Peris, S. Smaili, R. Gupta, and R. Zemel, “Differentially private decoding in large language models,”arXiv preprint arXiv:2205.13621, 2022. 2
-
[19]
A survey of secure computation using trusted execution envi- ronments,
X. Li, B. Zhao, G. Yang, T. Xiang, J. Weng, and R. H. Deng, “A survey of secure computation using trusted execution envi- ronments,”arXiv preprint arXiv:2302.12150, 2023
-
[20]
Machine learning with confidential computing: A systematization of knowledge,
F. Mo, Z. Tarkhani, and H. Haddadi, “Machine learning with confidential computing: A systematization of knowledge,” ACM computing surveys, vol. 56, no. 11, pp. 1–40, 2024. 2
2024
-
[21]
An in-depth evaluation of federated learning on biomedical natural language processing for information ex- traction,
L. Peng, G. Luo, S. Zhou, J. Chen, Z. Xu, J. Sun, and R. Zhang, “An in-depth evaluation of federated learning on biomedical natural language processing for information ex- traction,”NPJ Digital Medicine, vol. 7, no. 1, p. 127, 2024. 2
2024
-
[22]
Z. Kan, L. Qiao, H. Yu, L. Peng, Y . Gao, and D. Li, “Pro- tecting user privacy in remote conversational systems: A privacy-preserving framework based on text sanitization,” arXiv preprint arXiv:2306.08223, 2023. 2
-
[23]
Pr ϵϵmpt: Sanitizing sensitive prompts for llms,
A. R. Chowdhury, D. Glukhov, D. Anshumaan, P. Chalasani, N. Papernot, S. Jha, and M. Bellare, “Pr ϵϵmpt: Sanitizing sensitive prompts for llms,” 2025
2025
-
[24]
Sentinellms: encrypted input adaptation and fine-tuning of language models for private and secure inference,
A. Mishra, M. Li, and S. Deo, “Sentinellms: encrypted input adaptation and fine-tuning of language models for private and secure inference,” inProceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Confer- ence on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Ar...
2024
-
[25]
EmojiPrompt: Generative prompt obfuscation for privacy- preserving communication with cloud-based LLMs,
S. Lin, W. Hua, Z. Wang, M. Jin, L. Fan, and Y . Zhang, “EmojiPrompt: Generative prompt obfuscation for privacy- preserving communication with cloud-based LLMs,” inPro- ceedings of the 2025 Conference of the Nations of the Ameri- cas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) (L. Chiruzzo,...
2025
-
[26]
Protected health information filter (philter): ac- curately and securely de-identifying free-text clinical notes,
B. Norgeot, K. Muenzen, T. A. Peterson, X. Fan, B. S. Glicks- berg, G. Schenk, E. Rutenberg, B. Oskotsky, M. Sirota, J. Yaz- dany,et al., “Protected health information filter (philter): ac- curately and securely de-identifying free-text clinical notes,” NPJ digital medicine, vol. 3, no. 1, p. 57, 2020
2020
-
[27]
A discrete mathematical model and cryptogra- phy for secure medical image analysis : Encrypted chest x-ray classification,
A. Noonia, D. Thakral, P. Mathur, F. Sheth, H. Shaikh, and A. K. Gupta, “A discrete mathematical model and cryptogra- phy for secure medical image analysis : Encrypted chest x-ray classification,”Journal of Discrete Mathematical Sciences and Cryptography, vol. 28, no. 5-A, p. 1473–1486, 2025. 2
2025
-
[28]
A novel privacy-enhancing framework for low-dose ct denoising,
Z. Yang, H. Huangfu, M. Ran, Z. Wang, H. Yu, M. Sun, and Y . Zhang, “A novel privacy-enhancing framework for low-dose ct denoising,”IEEE Transactions on Artificial Intel- ligence, 2025. 2
2025
-
[29]
An interpretation of lemmatization and stemming in natural lan- guage processing,
D. Khyani, B. Siddhartha, N. Niveditha, and B. Divya, “An interpretation of lemmatization and stemming in natural lan- guage processing,”Journal of University of Shanghai for Science and Technology, vol. 22, no. 10, pp. 350–357, 2021. 4 18
2021
-
[30]
Wordnet: a lexical database for english,
G. A. Miller, “Wordnet: a lexical database for english,”Com- munications of the ACM, vol. 38, no. 11, pp. 39–41, 1995. 5
1995
-
[31]
A. Paul, D. Shaji, L. Han, W. Del-Pinto, and G. Nenadic, “Deidclinic: A multi-layered framework for de-identification of clinical free-text data,”arXiv preprint arXiv:2410.01648,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
spaCy: Industrial-strength natural language processing in python,
M. Honnibal, I. Montani, S. Van Landeghem, and A. Boyd, “spaCy: Industrial-strength natural language processing in python,” 2020. 5
2020
-
[33]
Encrypted large model inference: The equivariant encryption paradigm,
J. Buban, H. Zhang, C. Angione, H. Yang, A. Farhan, S. Sul- tanov, M. Du, X. Ma, Z. Wang, Y . Zhao,et al., “Encrypted large model inference: The equivariant encryption paradigm,” arXiv preprint arXiv:2502.01013, 2025. 6
-
[34]
Natural language understanding with privacy- preserving bert,
C. Qu, W. Kong, L. Yang, M. Zhang, M. Bendersky, and M. Najork, “Natural language understanding with privacy- preserving bert,” inProceedings of the 30th ACM Interna- tional Conference on Information & Knowledge Management, pp. 1488–1497, 2021. 6
2021
-
[35]
A study of encryption algorithms (rsa, des, 3des and aes) for information security,
G. Singh, “A study of encryption algorithms (rsa, des, 3des and aes) for information security,”International Journal of Computer Applications, vol. 67, no. 19, 2013. 6
2013
-
[36]
Large language models can be strong differentially private learners,
X. Li, F. Tramer, P. Liang, and T. Hashimoto, “Large language models can be strong differentially private learners,”arXiv preprint arXiv:2110.05679, 2021. 7
-
[37]
Privacy-preserving large language models for struc- tured medical information retrieval,
I. C. Wiest, D. Ferber, J. Zhu, M. van Treeck, S. K. Meyer, R. Juglan, Z. I. Carrero, D. Paech, J. Kleesiek, M. P. Ebert, et al., “Privacy-preserving large language models for struc- tured medical information retrieval,”NPJ Digital Medicine, vol. 7, no. 1, p. 257, 2024. 8
2024
-
[38]
Large language models encode clinical knowledge,
K. Singhal, S. Azizi, T. Tu, S. S. Mahdavi, J. Wei, H. W. Chung, N. Scales, A. Tanwani, H. Cole-Lewis, S. Pfohl,et al., “Large language models encode clinical knowledge,”Nature, vol. 620, no. 7972, pp. 172–180, 2023. 8
2023
-
[39]
Capabilities of GPT-4 on Medical Challenge Problems
H. Nori, N. King, S. M. McKinney, D. Carignan, and E. Horvitz, “Capabilities of gpt-4 on medical challenge prob- lems,”arXiv preprint arXiv:2303.13375, 2023. 8
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Trans- formative potential of ai in healthcare: definitions, applica- tions, and navigating the ethical landscape and public perspec- tives,
M. Bekbolatova, J. Mayer, C. W. Ong, and M. Toma, “Trans- formative potential of ai in healthcare: definitions, applica- tions, and navigating the ethical landscape and public perspec- tives,” inHealthcare, vol. 12, p. 125, MDPI, 2024. 8
2024
-
[41]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” inProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186, 2019. 8
2019
-
[42]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Y . Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V . Stoyanov, “Roberta: A robustly optimized bert pretraining approach,”arXiv preprint arXiv:1907.11692, 2019. 8
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[43]
P. He, J. Gao, and W. Chen, “Debertav3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing,”arXiv preprint arXiv:2111.09543, 2021. 8
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[44]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,” 2019. 8
2019
-
[45]
Biobert: a pre-trained biomedical language repre- sentation model for biomedical text mining,
J. Lee, W. Yoon, S. Kim, D. Kim, S. Kim, C. H. So, and J. Kang, “Biobert: a pre-trained biomedical language repre- sentation model for biomedical text mining,”Bioinformatics, vol. 36, no. 4, pp. 1234–1240, 2020. 8
2020
-
[46]
Optimized glycemic control of type 2 diabetes with reinforcement learning: a proof-of- concept trial,
G. Wang, X. Liu, Z. Ying, G. Yang, Z. Chen, Z. Liu, M. Zhang, H. Yan, Y . Lu, Y . Gao,et al., “Optimized glycemic control of type 2 diabetes with reinforcement learning: a proof-of- concept trial,”Nature Medicine, vol. 29, no. 10, pp. 2633– 2642, 2023. 8
2023
-
[47]
BioGPT: generative pre-trained transformer for biomed- ical text generation and mining,
R. Luo, L. Sun, Y . Xia, T. Qin, S. Zhang, H. Poon, and T.-Y . Liu, “BioGPT: generative pre-trained transformer for biomed- ical text generation and mining,”Briefings in Bioinformatics, vol. 23, 09 2022. bbac409. 8
2022
-
[48]
Qwen2.5 technical report,
Qwen, :, A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y . Fan, Y . Su, Y . Zhang, Y . Wan, Y . Liu, Z. Cui, Z. Zhang, ...
2025
-
[49]
Mis- tral 7b,
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mis- tral 7b,” 2023. 8
2023
-
[50]
Introducing llama 3.1: Our most capable models to date
Meta AI, “Introducing llama 3.1: Our most capable models to date.”https://ai.meta.com/blog/meta-llama-3-1/ , July 2024. Accessed: 2025-08-10. 8
2024
-
[51]
The aloe family recipe for open and specialized health- care llms,
D. Garcia-Gasulla, J. Bayarri-Planas, A. K. Gururajan, E. Lopez-Cuena, A. Tormos, D. Hinjos, P. Bernabeu-Perez, A. Arias-Duart, P. A. Martin-Torres, M. Gonzalez-Mallo, et al., “The aloe family recipe for open and specialized health- care llms,”arXiv preprint arXiv:2505.04388, 2025. 8
-
[52]
Med42-v2: A suite of clinical llms,
C. Christophe, P. K. Kanithi, T. Raha, S. Khan, and M. A. Pimentel, “Med42-v2: A suite of clinical llms,”arXiv preprint arXiv:2408.06142, 2024. 8
-
[53]
Evaluating unsuper- vised text classification: Zero-shot and similarity-based ap- proaches,
T. Schopf, D. Braun, and F. Matthes, “Evaluating unsuper- vised text classification: Zero-shot and similarity-based ap- proaches,” inProceedings of the 2022 6th International Con- ference on Natural Language Processing and Information Retrieval, NLPIR ’22, (New York, NY , USA), p. 6–15, Asso- ciation for Computing Machinery, 2023. 8
2022
-
[54]
Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering,
A. Pal, L. K. Umapathi, and M. Sankarasubbu, “Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering,” inProceedings of the Confer- ence on Health, Inference, and Learning(G. Flores, G. H. Chen, T. Pollard, J. C. Ho, and T. Naumann, eds.), vol. 174 ofProceedings of Machine Learning Research, pp. 248–260, PMLR, 07–0...
2022
-
[55]
What disease does this patient have? a large- scale open domain question answering dataset from medical exams,
D. Jin, E. Pan, N. Oufattole, W.-H. Weng, H. Fang, and P. Szolovits, “What disease does this patient have? a large- scale open domain question answering dataset from medical exams,”Applied Sciences, vol. 11, no. 14, p. 6421, 2021. 9
2021
-
[56]
Measuring Massive Multitask Language Understanding
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language understanding,”arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[57]
Advanced encryption standard (aes),
N. I. of Standards, T. (NIST), M. J. Dworkin, E. Barker, J. Nechvatal, J. Foti, L. E. Bassham, E. Roback, and J. D. Jr., “Advanced encryption standard (aes),” 2001-11-26 00:11:00
2001
-
[58]
Mouha,Review of the advanced encryption standard
N. Mouha,Review of the advanced encryption standard. US Department of Commerce, National Institute of Standards and Technology, 2021. 21
2021
-
[59]
A comparative analysis of aes common modes of operation,
S. Almuhammadi and I. Al-Hejri, “A comparative analysis of aes common modes of operation,” in2017 IEEE 30th Cana- dian Conference on Electrical and Computer Engineering (CCECE), pp. 1–4, 2017. 21
2017
-
[60]
Cryptanalysis via machine learning based information theoretic metrics,
B. D. Kim, V . A. Vasudevan, R. G. D’Oliveira, A. Cohen, T. Stahlbuhk, and M. Médard, “Cryptanalysis via machine learning based information theoretic metrics,”arXiv preprint arXiv:2501.15076, 2025. 21
-
[61]
A provable-security treatment of the key-wrap problem,
P. Rogaway and T. Shrimpton, “A provable-security treatment of the key-wrap problem,” inAnnual international conference on the theory and applications of cryptographic techniques, pp. 373–390, Springer, 2006. 21
2006
-
[62]
Gcm-siv: full nonce misuse- resistant authenticated encryption at under one cycle per byte,
S. Gueron and Y . Lindell, “Gcm-siv: full nonce misuse- resistant authenticated encryption at under one cycle per byte,” inProceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, pp. 109–119, 2015. 21
2015
-
[63]
The siv mode of operation for deterministic authenticated-encryption (key wrap) and misuse-resistant nonce-based authenticated-encryption,
P. Rogaway and T. Shrimpton, “The siv mode of operation for deterministic authenticated-encryption (key wrap) and misuse-resistant nonce-based authenticated-encryption,”Aug, vol. 20, p. 3, 2007. 21
2007
-
[64]
The blowfish encryption algorithm,
B. Schneier, “The blowfish encryption algorithm,”Dr Dobb’s Journal-Software Tools for the Professional Programmer, vol. 19, no. 4, pp. 38–43, 1994. 21
1994
-
[65]
Description of a new variable-length key, 64-bit block cipher (blowfish),
B. Schneier, “Description of a new variable-length key, 64-bit block cipher (blowfish),” inInternational workshop on fast software encryption, pp. 191–204, Springer, 1993. 21
1993
-
[66]
The ffx mode of op- eration for format-preserving encryption,
M. Bellare, P. Rogaway, and T. Spies, “The ffx mode of op- eration for format-preserving encryption,”NIST submission, vol. 20, no. 19, pp. 1–18, 2010. 21
2010
-
[67]
Recommendation for block cipher modes of operation,
M. Dworkin, “Recommendation for block cipher modes of operation,”NIST special publication, vol. 800, p. 38B, 2001. 21
2001
-
[68]
Similarity estimation techniques from round- ing algorithms,
M. S. Charikar, “Similarity estimation techniques from round- ing algorithms,” inProceedings of the thiry-fourth annual ACM symposium on Theory of computing, pp. 380–388, 2002. 21, 22
2002
-
[69]
Identifying almost identical files using context triggered piecewise hashing,
J. Kornblum, “Identifying almost identical files using context triggered piecewise hashing,”Digital investigation, vol. 3, pp. 91–97, 2006. 22
2006
-
[70]
Detecting near- duplicates for web crawling,
G. S. Manku, A. Jain, and A. Das Sarma, “Detecting near- duplicates for web crawling,” inProceedings of the 16th international conference on World Wide Web, pp. 141–150,
-
[71]
How to break md5 and other hash functions,
X. Wang and H. Yu, “How to break md5 and other hash functions,” inAnnual international conference on the the- ory and applications of cryptographic techniques, pp. 19–35, Springer, 2005. 22
2005
-
[72]
The md5 message-digest algorithm,
R. Rivest, “The md5 message-digest algorithm,” tech. rep.,
-
[73]
A study of the md5 attacks: Insights and improvements,
J. Black, M. Cochran, and T. Highland, “A study of the md5 attacks: Insights and improvements,” inInternational Work- shop on Fast Software Encryption, pp. 262–277, Springer,
-
[74]
Finding sha-1 charac- teristics: General results and applications,
C. De Canniere and C. Rechberger, “Finding sha-1 charac- teristics: General results and applications,” inInternational conference on the theory and application of cryptology and information security, pp. 1–20, Springer, 2006. 22
2006
-
[75]
The first collision for full sha-1,
M. Stevens, E. Bursztein, P. Karpman, A. Albertini, and Y . Markov, “The first collision for full sha-1,” inAnnual international cryptology conference, pp. 570–596, Springer,
-
[76]
Secure hash standard (shs),
F. Pub, “Secure hash standard (shs),”Fips pub, vol. 180, no. 4, p. 2012, 2012. 22 20 A. Supplementary Information A.1. Encryption-Based Methods A.1.1. Symmetric-Key Encryption We use two secret-key block ciphers,Advanced Encryption Standard (AES)andBlowfish, to obtain reversible one-to- one mappings from plaintext tokens to ciphertext tokens under a share...
2012
-
[77]
(iv) Empirical GPU measurements usually track token growth: peak memory rises from 6.84 GB (plaintext) to 9.15–10.61 GB for marked stems and 10.81 GB for FS+OFS (+51%). Overall, delimiter count—hence the number of secured spans—drives both sequence length and memory. In practice, PS+OU (w/ markers) balances privacy with tractable memory; omitting markers ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.