Reliability-Guided Depth Fusion for Glare-Resilient Navigation Costmaps
Pith reviewed 2026-06-28 09:27 UTC · model grok-4.3
The pith
Modeling per-pixel depth reliability lets robots fuse RGB-D data into glare-resilient costmaps without accumulating phantom obstacles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
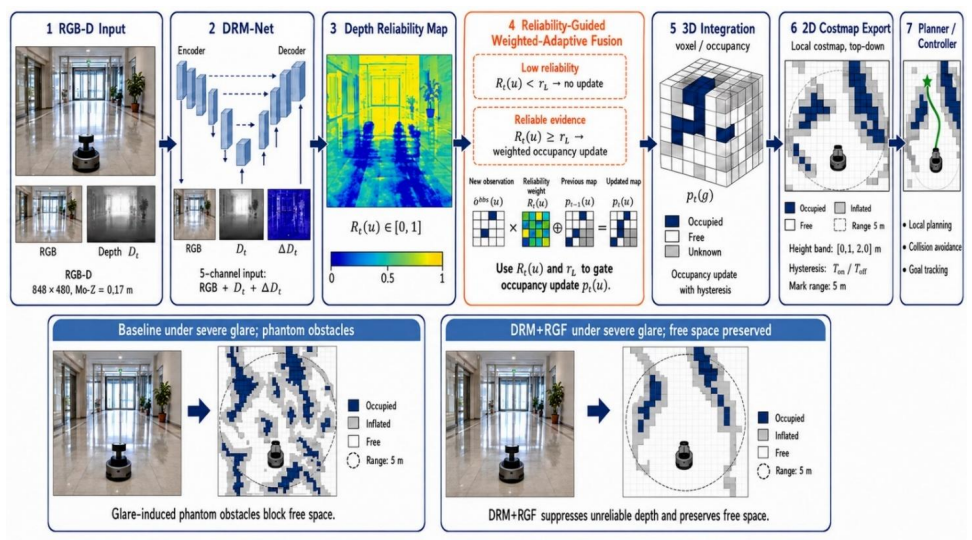
Explicit per-pixel reliability prediction via DRM-Net combined with reliability-guided weighted-and-gated fusion produces occupancy costmaps that reduce false obstacle insertion and preserve free space under specular glare, using pose-aligned multi-view reference depth to train without circular bias.
What carries the argument
DRM-Net (Depth Reliability Map network) that outputs per-pixel trustworthiness scores, used inside the RGF (reliability-guided weighted-and-gated fusion) mechanism to modulate occupancy updates.
If this is right
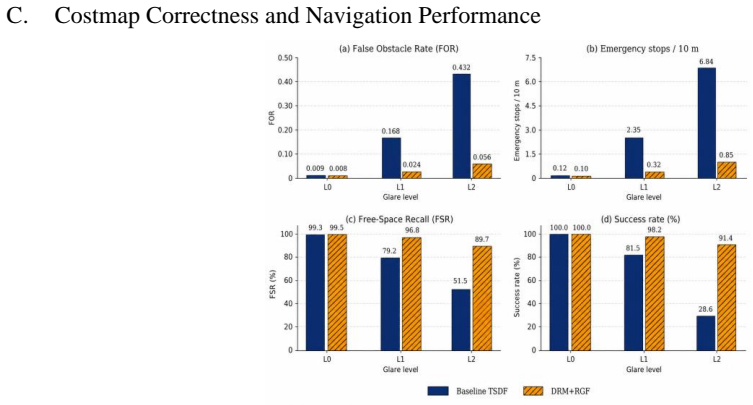
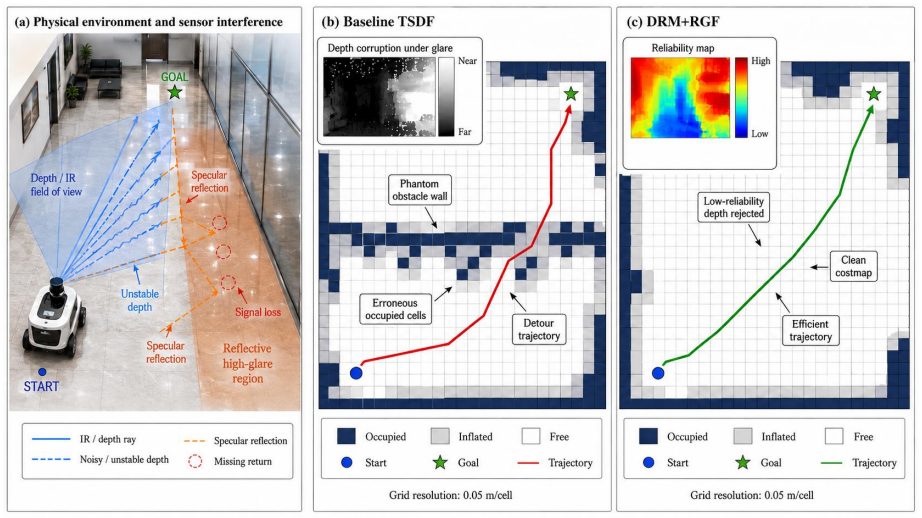
- False obstacle insertion drops while free-space regions stay intact across reflective-floor, glass-wall, and natural-light glare.
- Real-time throughput is preserved on Jetson Orin Nano hardware with the Intel RealSense D435.
- Occupancy updates are modulated before corruption accumulates rather than repaired afterward.
- The method is evaluated via fusion ablations, parameter sweeps, cross-condition tests, and reliability-map metrics.
Where Pith is reading between the lines
- The same reliability gate could be applied to other transient sensor corruptions such as motion blur or lens flare without retraining the full pipeline.
- Navigation stacks could drop separate dense depth-completion stages if reliability scores already prevent bad measurements from reaching the map.
- If the reference-depth construction generalizes, the approach might transfer to new camera placements or multi-robot mapping without new labeled data.
Load-bearing premise
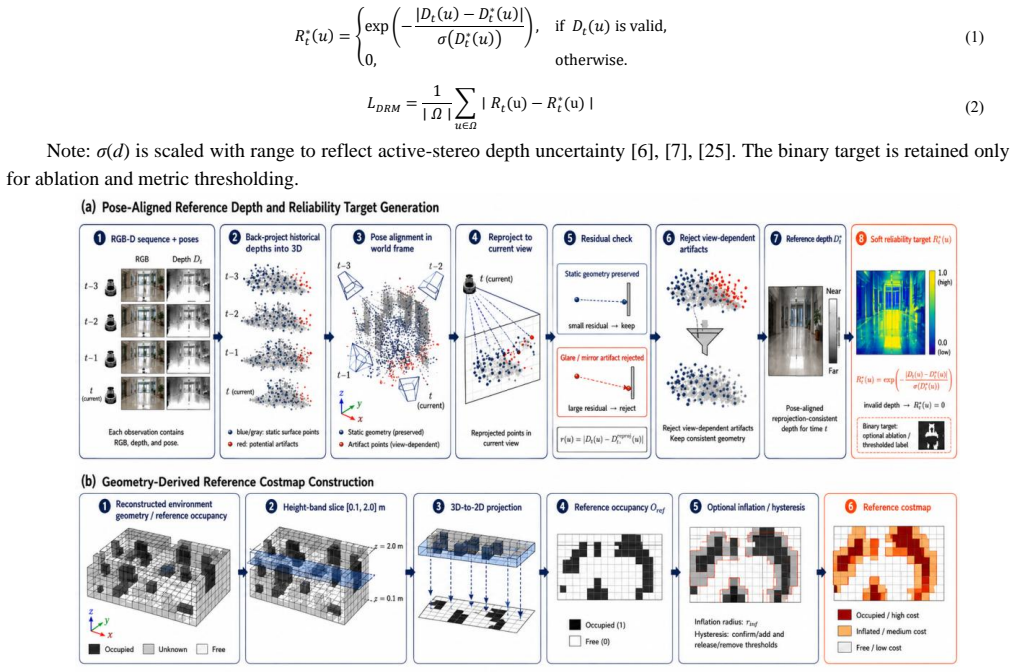
The pose-aligned multi-view reference depths used for supervision are themselves free of the specular corruption the method is meant to fix.
What would settle it
A side-by-side run on the same robot and glare scenes where the reliability-guided costmaps still insert phantom obstacles at the same rate as the baseline fusion method.
Figures
read the original abstract
Specular glare on reflective floors, glass boundaries, and glossy indoor surfaces frequently corrupts active-stereo RGB-D depth measurements, producing holes and spikes that accumulate as persistent phantom obstacles in occupancy-grid costmaps. This paper presents a glare-resilient costmap construction method based on explicit depth-reliability modeling. A lightweight Depth Reliability Map network (DRM-Net) predicts per-pixel measurement trustworthiness under specular interference, and a reliability-guided weighted-and-gated fusion (RGF) mechanism modulates occupancy updates before corrupted measurements are accumulated into the map. To support robust training and evaluation, the method uses pose-aligned multi-view reference-depth construction to reduce circular-supervision bias and is evaluated through fusion-variant ablations, parameter-sensitivity analysis, cross-condition tests, paired navigation comparisons, reliability-map metrics, and embedded runtime profiling. Experiments on a real mobile robotic platform equipped with an Intel RealSense D435 and a Jetson Orin Nano show that the proposed method reduces false obstacle insertion, improves free-space preservation, and maintains real-time throughput under reflective-floor, glass-wall, and natural-light glare conditions. These results support treating glare as a measurement-reliability problem rather than as a dense depth-completion problem for safety-critical indoor navigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DRM-Net, a lightweight network that predicts per-pixel depth reliability under specular glare, paired with a reliability-guided weighted-and-gated fusion (RGF) step that modulates occupancy-grid updates. Training and evaluation rely on pose-aligned multi-view reference-depth construction to reduce circular-supervision bias. Experiments on a RealSense D435 + Jetson Orin Nano platform report reduced false-obstacle insertion, better free-space preservation, and real-time performance across reflective-floor, glass-wall, and natural-light conditions; the work frames glare as a reliability rather than dense-completion problem.
Significance. If the multi-view reference construction supplies an unbiased supervisory signal, the explicit reliability modeling plus real-robot ablations, cross-condition tests, navigation comparisons, and embedded profiling would constitute a practical contribution to glare-resilient costmap construction for indoor mobile robots.
major comments (2)
- [training-support description (abstract and method section on reference-depth construction)] The central training support (pose-aligned multi-view reference-depth construction) is described as reducing circular-supervision bias, yet the manuscript provides no quantitative check that the fused reference remains free of the same holes and spikes on specular surfaces that DRM-Net is trained to detect. If reference views share the identical active-stereo sensor and glare conditions, the constructed target may itself contain the artifacts, making it impossible to attribute reported reductions in false-obstacle insertion to learned reliability rather than to the reference itself.
- [abstract and experimental-results summary] No numerical metrics, error bars, or statistical tests accompany the abstract's claims of reduced false-obstacle insertion and improved free-space preservation; without these, the strength of the experimental outcomes cannot be assessed from the provided summary.
minor comments (1)
- [abstract] The abstract lists multiple evaluation axes (fusion ablations, parameter sensitivity, cross-condition tests, reliability-map metrics, runtime profiling) but does not indicate which tables or figures report the quantitative outcomes for each axis.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and note the revisions we will incorporate.
read point-by-point responses
-
Referee: [training-support description (abstract and method section on reference-depth construction)] The central training support (pose-aligned multi-view reference-depth construction) is described as reducing circular-supervision bias, yet the manuscript provides no quantitative check that the fused reference remains free of the same holes and spikes on specular surfaces that DRM-Net is trained to detect. If reference views share the identical active-stereo sensor and glare conditions, the constructed target may itself contain the artifacts, making it impossible to attribute reported reductions in false-obstacle insertion to learned reliability rather than to the reference itself.
Authors: Different robot poses produce distinct specular reflection patterns because incidence angles and surface normals change relative to the fixed sensor. The pose-aligned fusion therefore aggregates measurements whose artifact locations are largely uncorrelated, yielding a reference with fewer persistent holes and spikes than any individual view. The manuscript does not contain an explicit quantitative artifact-count comparison between fused and single-view references on glare regions. We will add this analysis (including a table of hole/spike statistics before and after fusion) to the method and results sections of the revised manuscript. revision: yes
-
Referee: [abstract and experimental-results summary] No numerical metrics, error bars, or statistical tests accompany the abstract's claims of reduced false-obstacle insertion and improved free-space preservation; without these, the strength of the experimental outcomes cannot be assessed from the provided summary.
Authors: The abstract is written as a high-level summary; the full quantitative results (false-obstacle insertion rates, free-space preservation percentages, standard deviations across trials, and statistical tests) appear in Section 5 with tables and figures. To make the abstract self-contained, we will insert the principal numerical improvements (e.g., percentage reductions with error bars) into the abstract in the revised version. revision: yes
Circularity Check
No circularity: method relies on external multi-view reference construction without self-referential fitting or definition loops
full rationale
The provided abstract and description contain no equations, fitted parameters renamed as predictions, or self-citations that bear the central claim. The pose-aligned multi-view reference-depth construction is presented as an independent supervisory technique to reduce bias, not as a quantity derived from or equivalent to the DRM-Net outputs by construction. The reliability modeling and fusion steps are described as learned and modulated mechanisms evaluated via ablations and real-robot tests, with no reduction of the reported performance gains to the inputs themselves. This is a standard non-circular empirical robotics paper.
Axiom & Free-Parameter Ledger
invented entities (1)
-
DRM-Net
no independent evidence
Reference graph
Works this paper leans on
-
[1]
P. Foster, C. Johnson, and B. Kuipers, “The reflectance field map: Mapping glass and specular surfaces in dynamic environment s,” in Proc. IEEE Int. Conf. Robot. Autom. (ICRA), London, U.K., 2023, pp. 8393–8399, doi: 10.1109/ICRA48891.2023.10161520
-
[2]
Leveraging 3 -D data for whole object shape and reflection -aware 2 -D map building,
A. Mora, R. Barber, and L. Moreno, “Leveraging 3 -D data for whole object shape and reflection -aware 2 -D map building,” IEEE Sensors Journal, vol. 24, no. 14, pp. 21941–21948, Jul. 15, 2024, doi: 10.1109/JSEN.2023.3321936
-
[3]
A robust RGB-D SLAM system for indoor environments with reflective ground,
N. Zhou, H. Yao, C. Zhai, Z. Zhao, and X. Zhu, “A robust RGB-D SLAM system for indoor environments with reflective ground,” IEEE Sensors Journal, vol. 25, no. 20, pp. 38258–38270, Oct. 15, 2025, doi: 10.1109/JSEN.2025.3600569
-
[4]
Glass recognition and map optimization method for mobile robot based on boundary guidance,
C. He, H. Zhao, X. Zhang, J. Li, and Z. Dong, “Glass recognition and map optimization method for mobile robot based on boundary guidance,” Chin. J. Mech. Eng., vol. 36, Art. no. 88, Jun. 2023, doi: 10.1186/s10033 -023-00902-9
-
[5]
Accurate intrinsic and extrinsic calibration of RGB -D cameras with GP- based depth correction,
G. Chen, G. Cui, Z. Jin, F. Wu, and X. Chen, “Accurate intrinsic and extrinsic calibration of RGB -D cameras with GP- based depth correction,” IEEE Sensors Journal, vol. 19, no. 7, pp. 2685–2694, 2019, doi: 10.1109/JSEN.2018.2889805
-
[6]
Accuracy and resolution of Kinect depth data for indoor mapping applications,
K. Khoshelham and S. O. Elberink, “Accuracy and resolution of Kinect depth data for indoor mapping applications,” Sensors, vol. 12, no. 2, pp. 1437–1454, 2012
2012
-
[7]
Intel RealSense D400 series product family datasheet,
Intel Corp., “Intel RealSense D400 series product family datasheet,” Doc. 337029 -005. [Online]. Available: https://www.intelrealsense.com/wp- content/uploads/2019/09/Intel_RealSense_D400_Series_Product_Family_Datasheet. Accessed: Feb. 2, 2026
2019
-
[8]
Polarization structured light 3D depth image sensor for scenes with reflective surfaces,
X. Huang, C. Wu, X. Xu, B. Wang, S. Zhang, C. Shen, C. Yu, J. Wang, N. Chi, S. Yu, and C. J. Chang -Hasnain, “Polarization structured light 3D depth image sensor for scenes with reflective surfaces,” Nat. Commun., vol. 14, Art. no. 6855, 2023, doi: 10.1038/s41467-023-42678-5
-
[9]
3DRef: 3D dataset and benchmark for reflection detection in RGB and LiDAR data,
X. Zhao and S. Schwertfeger, “3DRef: 3D dataset and benchmark for reflection detection in RGB and LiDAR data,” arXiv preprint arXiv:2403.06538, 2024, doi: 10.48550/arXiv.2403.06538
-
[10]
Onlyflow: Optical flow based motion conditioning for video diffusion models
P. Z. Ramirez et al., “NTIRE 2025 challenge on HR depth from images of specular and transparent surfaces,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), Nashville, TN, USA, 2025, pp. 978 –992, doi: 10.1109/CVPRW67362.2025.00098
-
[11]
TDCNet: Transparent objects depth completion with CNN -transformer dual-branch parallel network,
X. Fan et al., “TDCNet: Transparent objects depth completion with CNN -transformer dual-branch parallel network,” IEEE Sensors Journal, vol. 25, no. 19, pp. 36629–36641, Oct. 1, 2025, doi: 10.1109/JSEN.2025.3599381
-
[12]
HDCNet: A hybrid depth completion network for grasping transparent and reflective objects,
G. Xie et al., “HDCNet: A hybrid depth completion network for grasping transparent and reflective objects,” arXiv preprint arXiv:2511.07081, Nov. 10, 2025. [Online]. Available: https://arxiv.org/abs/2511.07081
-
[13]
Geometry -aware sparse depth sampling for high -fidelity RGB-D depth completion in robotic systems,
T. Salloom, D. Zhou, and X. Sun, “Geometry -aware sparse depth sampling for high -fidelity RGB-D depth completion in robotic systems,” arXiv preprint arXiv:2512.08229, Dec. 9, 2025. [Online]. Available: https://arxiv.org/abs/2512.08229
-
[14]
TRICKY 2025 challenge on monocula r depth from images of specular and transparent surfaces,
P. Z. Ramirez, A. Costanzino, F. Tosi, M. Poggi, L. Di Stefano, J. -B. Weibel, D. Antensteiner, M. Vincze, B. Busam, G. Zhai, W. Li, J. Huang, H. Jung, M. Lavreniuk, P. Sun, Y. Luo, H. Wang, M. Gao, K. Jiang, and J. Jiang, “TRICKY 2025 challenge on monocula r depth from images of specular and transparent surfaces,” in Proc. IEEE/CVF Int. Conf. Comput. Vis...
2025
-
[15]
Seeing and seeing through the glass: Real and synthetic data for multi -layer depth estimation,
H. Wen, X. Yan, W. Tian, and J. Deng, “Seeing and seeing through the glass: Real and synthetic data for multi -layer depth estimation,” arXiv preprint arXiv:2503.11633, Mar. 14, 2025. [Online]. Available: https://arxiv.org/abs/2503.11633
-
[16]
doi:10.1109/DCC.2019.00022 , Pages =
T. Schöps, T. Sattler, and M. Pollefeys, “BAD SLAM: Bundle adjusted direct RGB-D SLAM,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Long Beach, CA, USA, 2019, pp. 134 –144, doi: 10.1109/CVPR.2019.00022
-
[17]
Stereo -GS: Online 3D Gaussian splatting mapping using stereo depth estimation,
J. Park, B. Lee, S. Lee, and S. Son, “Stereo -GS: Online 3D Gaussian splatting mapping using stereo depth estimation,” Electronics, vol. 14, no. 22, Art. no. 4436, 2025, doi: 10.3390/electronics14224436
-
[18]
Transformer-based sensor fusion for autonomous vehicles: A comprehensive review,
A. Abdulmaksoud and R. Ahmed, “Transformer-based sensor fusion for autonomous vehicles: A comprehensive review,” IEEE Access, vol. 13, pp. 41822–41838, 2025, doi: 10.1109/ACCESS.2025.3545032
-
[19]
High resolution maps from wide angle sonar,
H. Moravec and A. Elfes, “High resolution maps from wide angle sonar,” in Proc. 1985 IEEE Int. Conf. Robot. Autom., St. Louis, MO, USA, 1985, pp. 116–121, doi: 10.1109/ROBOT.1985.1087316
-
[20]
Using occupancy grids for mobile robot perception and navigation,
A. Elfes, “Using occupancy grids for mobile robot perception and navigation,” Computer, vol. 22, no. 6, pp. 46–57, Jun. 1989, doi: 10.1109/2.30720
-
[21]
A volumetric method for building complex models from range images,
B. Curless and M. Levoy, “A volumetric method for building complex models from range images,” in Proc. 23rd Annu. Conf. Comput. Graph. Interactive Techn. (SIGGRAPH), New Orleans, LA, USA, 1996, pp. 303 –312, doi: 10.1145/237170.237269
-
[22]
OctoMap: An efficient probabilistic 3d mapping framework based on octrees
A. Hornung, K. M. Wurm, M. Bennewitz, C. Stachniss, and W. Burgard, “OctoMap: An efficient probabilistic 3D mapping framework based on octrees,” Autonomous Robots, vol. 34, no. 3, pp. 189 –206, Apr. 2013, doi: 10.1007/s10514-012-9321-0
-
[23]
RGB-D video mirror detection,
M. Xu, P. Herbert, Y.-K. Lai, Z. Ji, and J. Wu, “RGB-D video mirror detection,” in Proc. IEEE/CVF Winter Conf. Appl. Comput. Vis. (WACV), 2025, pp. 9622–9631. [Online]. Available: https://github.com/UpChenF/DVMDNet. Accessed: Feb. 2, 2026
2025
-
[24]
Out-of-distribution detection for monocular depth estimation,
J. Hornauer, A. Holzbock, and V. Belagiannis, “Out-of-distribution detection for monocular depth estimation,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2023, pp. 1911–1921
2023
-
[25]
Comparison of Kinect v1 and v2 depth images in terms of accuracy and precision,
O. Wasenmüller and D. Stricker, “Comparison of Kinect v1 and v2 depth images in terms of accuracy and precision,” in Proc. Asian Conf. Comput. Vis. Workshops (ACCV Workshops), 2016, pp. 34 –45
2016
-
[26]
KinectFusion: Real -time dense surface mapping and tracking,
R. A. Newcombe et al., “KinectFusion: Real -time dense surface mapping and tracking,” in Proc. 10th IEEE Int. Symp. Mixed and Augmented Reality (ISMAR), Basel, Switzerland, 2011, pp. 127 –136, doi: 10.1109/ISMAR.2011.6092378
-
[27]
A. Millane, H. Oleynikova, E. Wirbel, R. Steiner, V. Ramasamy, D. Tingdahl, and R. Siegwart, “nvblox: GPU - accelerated incremental signed distance field mapping,” in Proc. IEEE Int. Conf. Robot. Autom. (ICRA), Yokohama, Japan, May 2024, pp. 2698–2705, doi: 10.1109/ICRA57147.2024.10611532
-
[28]
Costmap 2D,
Navigation2, “Costmap 2D,” Navigation2 Documentation. [Online]. Available: https://docs.nav2.org/configuration/packages/configuring-costmaps.html. Accessed: Feb. 2, 2026
2026
-
[29]
costmap_2d/Inflation
ROS Wiki, “costmap_2d/Inflation.” [Online]. Available: https://wiki.ros.org/costmap_2d/hydro/inflation. Accessed: Feb. 2, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.