PrimeSVT: An Automated Memory-aware Pruning Framework with Prioritized Compression Policy for Spiking Vision Transformers
Pith reviewed 2026-06-28 07:40 UTC · model grok-4.3
The pith
PrimeSVT automates structured pruning of spiking vision transformers by sorting layers from largest to smallest and applying sequential L2-norm channel pruning to meet accuracy and memory goals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
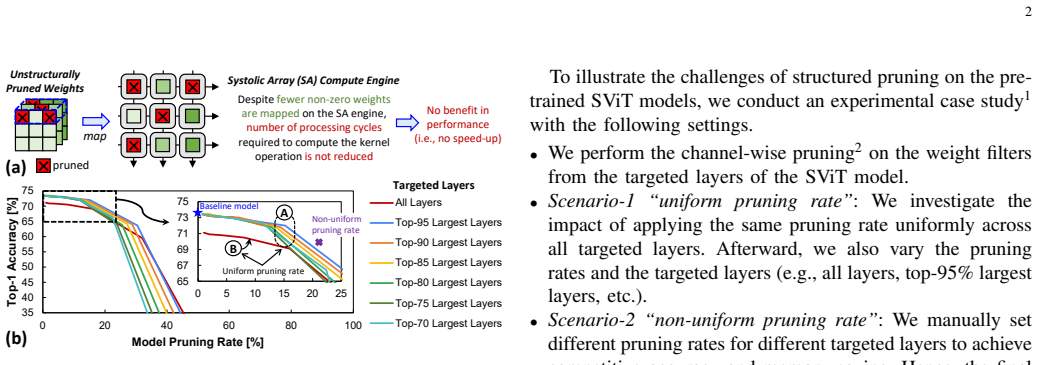
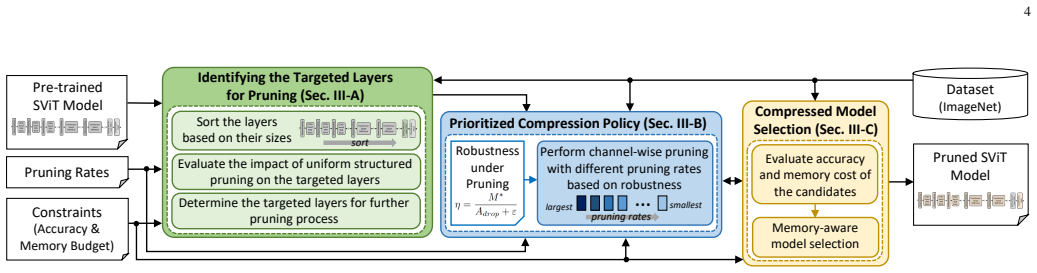
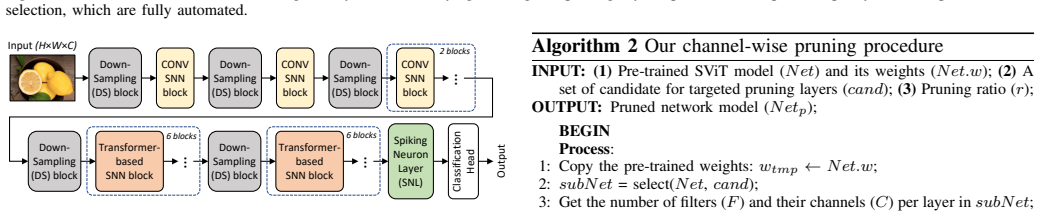
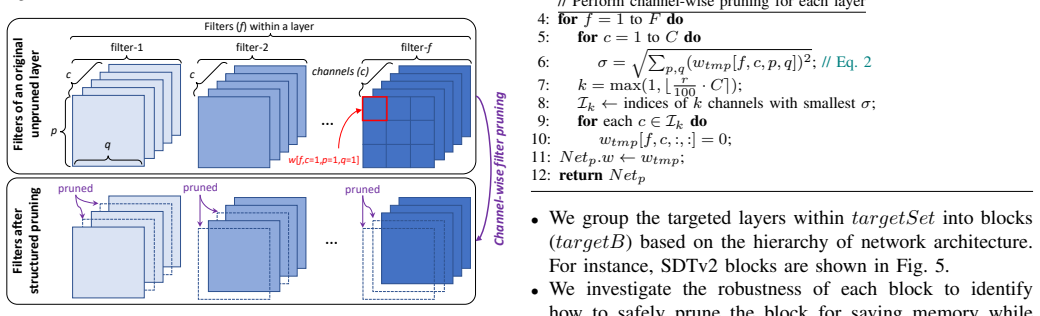
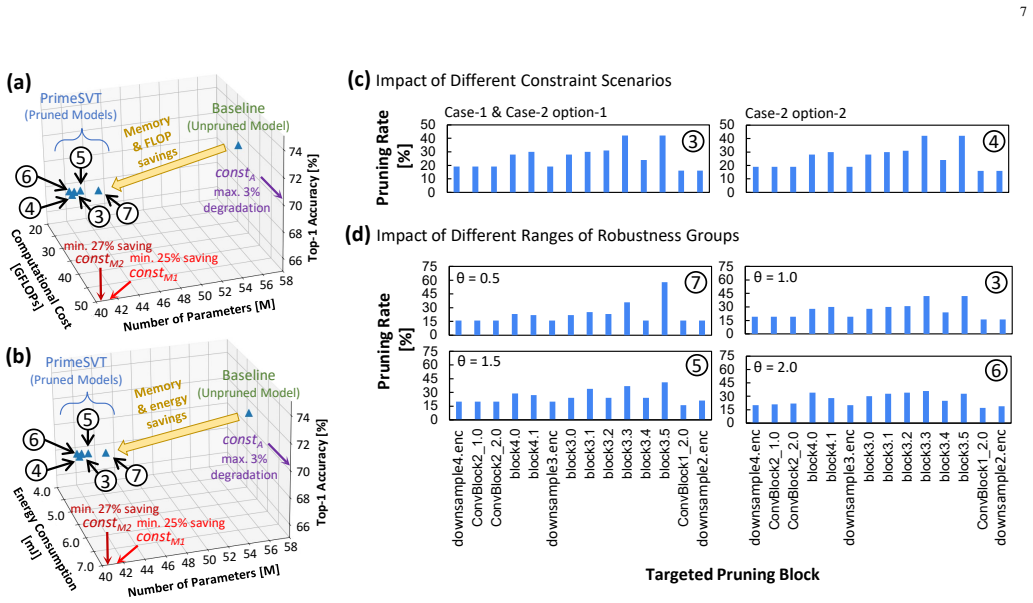
PrimeSVT sorts the SViT layers based on their sizes (number of parameters), identifies the targeted pruning layers based on their robustness under different pruning rates, then leverages this order for compressing the model layer-by-layer sequentially from the largest one to the smallest one (prioritized compression policy), while considering the user-defined constraints on acceptable accuracy and memory saving. In each layer it employs channel-wise filter pruning based on L2-norm values to structurally remove non-significant weights. Experiments show this yields 26.68% memory savings with accuracy staying within 3% of the original unpruned model's 73.3% (70.3% without fine-tuning, 72.9% wit
What carries the argument
The prioritized compression policy, which orders layers by parameter count, tests layer robustness to pruning rates, and then applies L2-norm channel pruning sequentially from largest to smallest layers while enforcing accuracy and memory constraints.
If this is right
- Structured pruning becomes feasible on standard computing hardware without specialized accelerators for unstructured sparsity.
- Design time for finding pruning settings drops because the process is automated and single-shot rather than manual per network.
- SViT models can reach embedded deployment while staying inside user-specified accuracy and memory budgets.
- Sequential layer-by-layer compression respects the user constraints at each step instead of requiring post-hoc adjustments.
Where Pith is reading between the lines
- The same sorting-plus-robustness ordering might reduce search effort in pruning frameworks for other spiking or non-spiking transformer architectures.
- If the robustness test reliably predicts final accuracy, the method could be combined with existing fine-tuning schedules to push accuracy recovery further.
- Testing the policy on datasets or tasks beyond the reported SViT experiments would show whether layer-size ordering generalizes.
Load-bearing premise
That sorting layers by parameter count and testing their robustness under different pruning rates will produce a compression order that satisfies the accuracy constraint when L2-norm channel pruning is applied sequentially.
What would settle it
Applying the same total pruning budget to the SViT model but using a reversed layer order (smallest to largest) or a different importance metric and measuring whether accuracy drops below the 3% tolerance at the 26.68% memory saving point.
Figures



read the original abstract
The large sizes of Spiking Vision Transformers (SViTs) still hinder their embedded implementation, highlighting the need for model compression. State-of-the-art works compress SViT models through unstructured pruning, which needs specialized hardware accelerators for their specific sparsity patterns to maximize efficiency gains. Moreover, their manual approach requires a huge design time to find an appropriate pruning setting for each network, thus making this approach not scalable. To address this limitation, we propose PrimeSVT, a novel framework that performs automated memory-aware structured pruning on pre-trained SViT models, thereby maximizing their efficiency gains during inference amenable to widely-used computing architectures. To achieve this, PrimeSVT first sorts the SViT layers based on their sizes (i.e., number of parameters), identifies the targeted pruning layers based on their robustness under different pruning rates, then leverages this order for compressing the model layer-by-layer sequentially from the largest one to the smallest one (i.e., so-called prioritized compression policy), while considering the user-defined constraints (i.e., acceptable accuracy and memory saving). In each layer, PrimeSVT employs channel-wise filter pruning based on their L2-norm values to structurally remove the non-significant weights. Experimental results show that PrimeSVT saves 26.68% memory through automated single-shot pruning, while preserving accuracy within 3% (70.3% without fine-tuning and 72.9% with fine-tuning) from the original unpruned SViT model (73.3%), thus meeting the accuracy and memory constraints. These show that our PrimeSVT framework enables design automation for SViTs and their embedded implementation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PrimeSVT, an automated framework for memory-aware structured pruning of pre-trained Spiking Vision Transformers (SViTs). Layers are sorted by parameter count; prune targets are identified via per-layer robustness tests under varying rates; L2-norm channel pruning is then applied sequentially from largest to smallest layers (prioritized compression policy) subject to user accuracy and memory constraints. The central empirical claim is a 26.68% memory reduction while keeping accuracy within 3% of the unpruned baseline (73.3% o 70.3% without fine-tuning, 72.9% with fine-tuning) via single-shot pruning.
Significance. If validated, the result would be significant for enabling hardware-friendly compression of SViTs on standard architectures without manual per-layer tuning or unstructured sparsity. The single-shot automated procedure and explicit incorporation of user constraints are concrete strengths that address scalability issues in prior manual pruning approaches for spiking models.
major comments (2)
- [Abstract / §3] Abstract and method description (prioritized compression policy): the claim that sorting by parameter count, robustness-based target identification, and largest-to-smallest sequential L2-norm pruning is what enables the reported memory/accuracy outcome lacks supporting ablations; no comparisons are shown to alternative orderings (smallest-first, random) or metrics, so it is unclear whether the specific policy is load-bearing or if any reasonable sequential schedule would suffice.
- [§4] Experimental results: the headline figures (26.68% memory, 70.3%/72.9% accuracy) are presented without protocol details, baseline comparisons, number of trials, or error bars, which directly affects assessment of whether the central performance claim is reproducible and robust.
minor comments (1)
- [Abstract] The abstract states that constraints are 'user-defined' but does not specify the exact accuracy/memory targets used in the reported experiment; adding this would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate additional supporting material where appropriate.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and method description (prioritized compression policy): the claim that sorting by parameter count, robustness-based target identification, and largest-to-smallest sequential L2-norm pruning is what enables the reported memory/accuracy outcome lacks supporting ablations; no comparisons are shown to alternative orderings (smallest-first, random) or metrics, so it is unclear whether the specific policy is load-bearing or if any reasonable sequential schedule would suffice.
Authors: We agree that explicit ablations would strengthen the justification for the prioritized (largest-to-smallest) policy. While the policy is motivated by the goal of achieving larger memory reductions by addressing high-parameter layers first under the robustness-guided targets, we will add comparisons against smallest-first and random orderings (plus alternative metrics) in the revised §3 and §4 to demonstrate that the chosen ordering is load-bearing for the reported outcome. revision: yes
-
Referee: [§4] Experimental results: the headline figures (26.68% memory, 70.3%/72.9% accuracy) are presented without protocol details, baseline comparisons, number of trials, or error bars, which directly affects assessment of whether the central performance claim is reproducible and robust.
Authors: We will expand §4 to include the full experimental protocol (including training and pruning hyperparameters), explicit baseline comparisons to prior SViT pruning methods, the number of independent trials performed, and error bars or standard deviations on the accuracy and memory metrics to support reproducibility and robustness claims. revision: yes
Circularity Check
No circularity: explicit empirical procedure on fixed pre-trained model
full rationale
The paper presents PrimeSVT as a sequence of concrete steps—sorting layers by parameter count, identifying prune targets via per-layer robustness tests under varying rates, then applying sequential L2-norm channel pruning from largest to smallest—executed on a fixed pre-trained SViT model subject to user accuracy/memory constraints. The 26.68% memory saving and accuracy figures are reported as direct experimental outcomes of this procedure, with no equations, fitted parameters, or self-citations that reduce the result to its own inputs by construction. No self-definitional loops, fitted-input predictions, uniqueness theorems, or ansatz smuggling appear in the described chain. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption L2-norm of channel weights is a reliable proxy for importance when pruning SViT layers
Reference graph
Works this paper leans on
-
[1]
An image is worth 16x16 words: Trans- formers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Trans- formers for image recognition at scale,” inInternational Conference on Learning Representations (ICLR), 2021
2021
-
[2]
Training data-efficient image transformers & distillation through attention,
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. J ´egou, “Training data-efficient image transformers & distillation through attention,” inInternational Conference on Machine Learning (ICML). PMLR, 2021, pp. 10 347–10 357. 8
2021
-
[3]
Transformers in vision: A survey,
S. Khan, M. Naseer, M. Hayat, S. W. Zamir, F. S. Khan, and M. Shah, “Transformers in vision: A survey,”ACM Computing Surveys (CSUR), vol. 54, no. 10s, pp. 1–41, 2022
2022
-
[4]
A survey on vision transformer,
K. Han, Y . Wang, H. Chen, X. Chen, J. Guo, Z. Liu, Y . Tang, A. Xiao, C. Xu, Y . Xu, Z. Yang, Y . Zhang, and D. Tao, “A survey on vision transformer,”IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 45, no. 1, pp. 87–110, 2023
2023
-
[5]
Spikformer: When spiking neural network meets transformer,
Z. Zhou, Y . Zhu, C. He, Y . Wang, S. Yan, Y . Tian, and L. Yuan, “Spikformer: When spiking neural network meets transformer,” in International Conference on Learning Representations (ICLR), 2023
2023
-
[6]
Spike- driven transformer,
M. Yao, J. Hu, Z. Zhou, L. Yuan, Y . Tian, B. XU, and G. Li, “Spike- driven transformer,” inThe 37th Conference on Neural Information Processing Systems (NeurIPS), 2023
2023
-
[7]
Spike-driven transformer v2: Meta spiking neural network architecture inspiring the design of next-generation neuromorphic chips,
M. Yao, J. Hu, T. Hu, Y . Xu, Z. Zhou, Y . Tian, B. XU, and G. Li, “Spike-driven transformer v2: Meta spiking neural network architecture inspiring the design of next-generation neuromorphic chips,” inThe 12th International Conference on Learning Representations (ICLR), 2024
2024
-
[8]
Stdp-based pruning of connections and weight quantization in spiking neural networks for energy-efficient recognition,
N. Rathi, P. Panda, and K. Roy, “Stdp-based pruning of connections and weight quantization in spiking neural networks for energy-efficient recognition,”IEEE Transactions on Computer-Aided Design of Inte- grated Circuits and Systems (TCAD), vol. 38, no. 4, pp. 668–677, April 2019
2019
-
[9]
Fspinn: An optimization framework for memory-efficient and energy-efficient spiking neural networks,
R. V . W. Putra and M. Shafique, “Fspinn: An optimization framework for memory-efficient and energy-efficient spiking neural networks,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD), vol. 39, no. 11, pp. 3601–3613, 2020
2020
-
[10]
Optimizing the energy consumption of spiking neural networks for neuromorphic applications,
M. Sorbaro, Q. Liu, M. Bortone, and S. Sheik, “Optimizing the energy consumption of spiking neural networks for neuromorphic applications,” Frontiers in Neuroscience (FNINS), vol. 14, p. 662, 2020
2020
-
[11]
A novel conversion method for spiking neural network using median quantization,
C. Zou, X. Cui, J. Ge, H. Ma, and X. Wang, “A novel conversion method for spiking neural network using median quantization,” inIEEE International Symposium on Circuits and Systems (ISCAS), 2020, pp. 1–5
2020
-
[12]
Q-spinn: A framework for quantizing spiking neural networks,
R. V . W. Putra and M. Shafique, “Q-spinn: A framework for quantizing spiking neural networks,” inInternational Joint Conference on Neural Networks (IJCNN), 2021, pp. 1–8
2021
-
[13]
Qsvit: A methodology for quantizing spiking vision transformers,
R. V . W. Putra, S. Iftikhar, and M. Shafique, “Qsvit: A methodology for quantizing spiking vision transformers,” in2025 International Joint Conference on Neural Networks (IJCNN), 2025, pp. 1–8
2025
-
[14]
S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,”arXiv preprint arXiv:1510.00149, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[15]
Pruning filters for efficient convnets,
H. Li, A. Kadav, I. Durdanovic, H. Samet, and H. P. Graf, “Pruning filters for efficient convnets,” inInternational Conference on Learning Representations (ICLR), 2017
2017
-
[16]
Prunet: Class- blind pruning method for deep neural networks,
A. Marchisio, M. A. Hanif, M. Martina, and M. Shafique, “Prunet: Class- blind pruning method for deep neural networks,” inInternational Joint Conference on Neural Networks (IJCNN). IEEE, 2018, pp. 1–8
2018
-
[17]
Savit: Structure-aware vision transformer pruning via collaborative optimization,
C. Zheng, K. Zhang, Z. Yang, W. Tan, J. Xiao, Y . Ren, S. Puet al., “Savit: Structure-aware vision transformer pruning via collaborative optimization,”Advances in Neural Information Processing Systems (NeurIPS), vol. 35, pp. 9010–9023, 2022
2022
-
[18]
Width & depth pruning for vision transformers,
F. Yu, K. Huang, M. Wang, Y . Cheng, W. Chu, and L. Cui, “Width & depth pruning for vision transformers,” inAAAI Conference on Artificial Intelligence (AAAI), vol. 36, no. 3, 2022, pp. 3143–3151
2022
-
[19]
Spatial–temporal spiking feature pruning in spiking transformer,
Z. Zhou, K. Che, J. Niu, M. Yao, G. Li, L. Yuan, G. Luo, and Y . Zhu, “Spatial–temporal spiking feature pruning in spiking transformer,”IEEE Transactions on Cognitive and Developmental Systems (TCDS), vol. 17, no. 3, pp. 644–658, 2025
2025
-
[20]
Towards efficient spiking transformer: a token sparsification framework for training and inference acceleration,
Z. Zhuge, P. Wang, X. Yao, and J. Cheng, “Towards efficient spiking transformer: a token sparsification framework for training and inference acceleration,” inInternational Conference on Machine Learning (ICML), 2024
2024
-
[21]
Sparsespikformer: A co-design frame- work for token and weight pruning in spiking transformer,
Y . Liu, S. Xiao, B. Li, and Z. Yu, “Sparsespikformer: A co-design frame- work for token and weight pruning in spiking transformer,” inIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024
2024
-
[22]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2009, pp. 248–255
2009
-
[23]
Spiking neural network integrated circuits: A review of trends and future directions,
A. Basu, L. Deng, C. Frenkel, and X. Zhang, “Spiking neural network integrated circuits: A review of trends and future directions,” in2022 IEEE Custom Integrated Circuits Conference (CICC), 2022, pp. 1–8
2022
-
[24]
In-datacenter performance analysis of a tensor processing unit,
N. P. Jouppiet al., “In-datacenter performance analysis of a tensor processing unit,” in44th Annual International Symposium on Computer Architecture (ISCA), 2017, p. 1–12
2017
-
[25]
Networks of spiking neurons: The third generation of neural network models,
W. Maass, “Networks of spiking neurons: The third generation of neural network models,”Neural Networks, vol. 10, no. 9, pp. 1659–1671, 1997
1997
-
[26]
Spyketorch: Efficient simulation of convolutional spiking neural net- works with at most one spike per neuron,
M. Mozafari, M. Ganjtabesh, A. Nowzari-Dalini, and T. Masquelier, “Spyketorch: Efficient simulation of convolutional spiking neural net- works with at most one spike per neuron,”Frontiers in Neuroscience (FNINS), vol. 13, p. 625, 2019
2019
-
[27]
Replay4ncl: An efficient memory replay-based methodology for neu- romorphic continual learning in embedded ai systems,
M. F. Minhas, R. V . W. Putra, F. Awwad, O. Hasan, and M. Shafique, “Replay4ncl: An efficient memory replay-based methodology for neu- romorphic continual learning in embedded ai systems,” in2025 62nd ACM/IEEE Design Automation Conference (DAC), 2025, pp. 1–7
2025
-
[28]
Towards ultra low latency spiking neural networks for vision and sequential tasks using tempo- ral pruning,
S. S. Chowdhury, N. Rathi, and K. Roy, “Towards ultra low latency spiking neural networks for vision and sequential tasks using tempo- ral pruning,” inEuropean Conference on Computer Vision (ECCV). Springer, 2022, pp. 709–726
2022
-
[29]
Continual learning with neuromorphic computing: Foundations, meth- ods, and emerging applications,
M. F. Minhas, R. V . W. Putra, F. Awwad, O. Hasan, and M. Shafique, “Continual learning with neuromorphic computing: Foundations, meth- ods, and emerging applications,”IEEE Access, vol. 13, pp. 124 824– 124 873, 2025
2025
-
[30]
Truenorth: Design and tool flow of a 65 mw 1 million neuron programmable neurosynaptic chip,
F. Akopyan, J. Sawada, A. Cassidy, R. Alvarez-Icaza, J. Arthur, P. Merolla, N. Imam, Y . Nakamura, P. Datta, G. Nam, B. Taba, M. Beakes, B. Brezzo, J. B. Kuang, R. Manohar, W. P. Risk, B. Jackson, and D. S. Modha, “Truenorth: Design and tool flow of a 65 mw 1 million neuron programmable neurosynaptic chip,”IEEE Transactions on Computer-Aided Design of Int...
2015
-
[31]
Loihi: A neuromorphic manycore processor with on-chip learning,
M. Davies, N. Srinivasa, T. Lin, G. Chinya, Y . Cao, S. H. Choday, G. Dimou, P. Joshi, N. Imam, S. Jain, Y . Liao, C. Lin, A. Lines, R. Liu, D. Mathaikutty, S. McCoy, A. Paul, J. Tse, G. Venkataramanan, Y . Weng, A. Wild, Y . Yang, and H. Wang, “Loihi: A neuromorphic manycore processor with on-chip learning,”IEEE Micro, vol. 38, no. 1, pp. 82– 99, Jan 2018
2018
-
[32]
A 0.086-mm 2 12.7- pj/sop 64k-synapse 256-neuron online-learning digital spiking neuro- morphic processor in 28-nm cmos,
C. Frenkel, M. Lefebvre, J. Legat, and D. Bol, “A 0.086-mm 2 12.7- pj/sop 64k-synapse 256-neuron online-learning digital spiking neuro- morphic processor in 28-nm cmos,”IEEE Transactions on Biomedical Circuits and Systems (TBCAS), vol. 13, no. 1, pp. 145–158, Feb 2019
2019
-
[33]
Braindrop: A mixed-signal neuromorphic architecture with a dynamical systems-based programming model,
A. Neckar, S. Fok, B. V . Benjamin, T. C. Stewart, N. N. Oza, A. R. V oelker, C. Eliasmith, R. Manohar, and K. Boahen, “Braindrop: A mixed-signal neuromorphic architecture with a dynamical systems-based programming model,”Proceedings of the IEEE, vol. 107, no. 1, pp. 144– 164, 2019
2019
-
[34]
Dynap-cnn: The world’s first fully scalable, event- driven neuromorphic processor with up to 1m configurable spiking neurons and direct interface with external dvs
SynSense. Dynap-cnn: The world’s first fully scalable, event- driven neuromorphic processor with up to 1m configurable spiking neurons and direct interface with external dvs. [Online]. Available: https://www.synsense.ai/products/dynap-cnn/
-
[35]
Akida neural processor soc
BrainChip. Akida neural processor soc. [Online]. Available: https: //brainchip.com/akida-neural-processor-soc/
-
[36]
Respawn: Energy- efficient fault-tolerance for spiking neural networks considering un- reliable memories,
R. V . W. Putra, M. A. Hanif, and M. Shafique, “Respawn: Energy- efficient fault-tolerance for spiking neural networks considering un- reliable memories,” in2021 IEEE/ACM International Conference On Computer Aided Design (ICCAD), 2021, pp. 1–9
2021
-
[37]
Exploring neuromorphic computing based on spiking neural networks: Algorithms to hardware,
N. Rathi, I. Chakraborty, A. Kosta, A. Sengupta, A. Ankit, P. Panda, and K. Roy, “Exploring neuromorphic computing based on spiking neural networks: Algorithms to hardware,”ACM Computing Surveys, vol. 55, no. 12, 2023
2023
-
[38]
Softsnn: Low-cost fault tolerance for spiking neural network accelerators under soft errors,
R. V . W. Putra, M. A. Hanif, and M. Shafique, “Softsnn: Low-cost fault tolerance for spiking neural network accelerators under soft errors,” in The 59th ACM/IEEE Design Automation Conference (DAC), 2022, pp. 151–156
2022
-
[39]
Spikenas: A fast memory-aware neural architecture search framework for spiking neural network-based embedded ai systems,
R. V . W. Putra and M. Shafique, “Spikenas: A fast memory-aware neural architecture search framework for spiking neural network-based embedded ai systems,”IEEE Transactions on Artificial Intelligence, vol. 7, no. 2, pp. 947–959, 2026
2026
-
[40]
Spikingjelly: An open-source machine learning infrastructure platform for spike-based intelligence,
W. Fang, Y . Chen, J. Ding, Z. Yu, T. Masquelier, D. Chen, L. Huang, H. Zhou, G. Li, and Y . Tian, “Spikingjelly: An open-source machine learning infrastructure platform for spike-based intelligence,”Science Advances, vol. 9, no. 40, 2023
2023
-
[41]
An analytical estimation of spiking neural networks energy efficiency,
E. Lemaire, L. Cordone, A. Castagnetti, P.-E. Novac, J. Courtois, and B. Miramond, “An analytical estimation of spiking neural networks energy efficiency,” inInternational Conference on Neural Information Processing (ICONIP). Springer, 2022, pp. 574–587
2022
-
[42]
Ten lessons from three genera- tions shaped google’s tpuv4i : Industrial product,
N. P. Jouppi, D. Hyun Yoon, M. Ashcraft, M. Gottscho, T. B. Jablin, G. Kurian, J. Laudon, S. Li, P. Ma, X. Ma, T. Norrie, N. Patil, S. Prasad, C. Young, Z. Zhou, and D. Patterson, “Ten lessons from three genera- tions shaped google’s tpuv4i : Industrial product,” in2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), 2021, pp. 1–14
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.