NeuroArmor: Safe-Variant-Guided Representation Consistency for Selective Re-Anchoring in Jailbreak Defense
Pith reviewed 2026-06-28 09:41 UTC · model grok-4.3
The pith
NeuroArmor generates prompt-specific safe variants to check hidden-state consistency and route suspicious inputs to refusal or recovery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
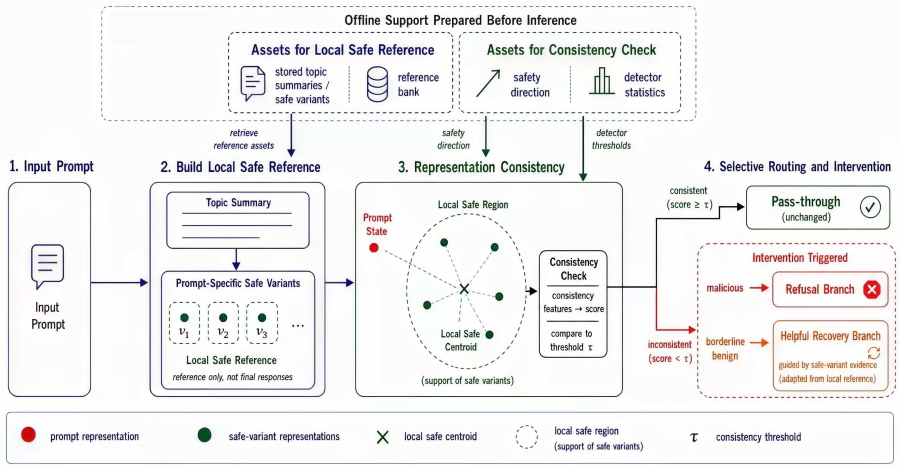
NeuroArmor establishes that prompt-specific safe variants can serve as an on-the-fly safety anchor in hidden-state space, enabling a consistency check that routes anomalous prompts to either refusal or helpful recovery and thereby improves the safety-helpfulness trade-off over uniform defenses.
What carries the argument
Prompt-specific safe variants used as a local reference for hidden-state consistency checking and selective re-anchoring.
If this is right
- Malicious attack success rate falls from 41.56% to 1.57% on the evaluated model.
- Benign false positive rate falls from 30.26% to 22.05% on the shared benign pool.
- External and manual checks indicate that unblocked outputs contain fewer operationally harmful completions than baselines.
- The defense works at runtime without model parameter changes or additional training data.
Where Pith is reading between the lines
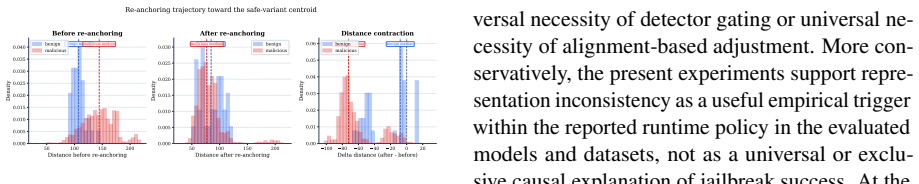
- The same consistency idea could be tested on other model families to check whether the separation between safe variants and malicious prompts generalizes beyond the reported architecture.
- If hidden-state consistency proves stable across prompt types, it might be combined with existing output filters to further reduce residual harmful completions.
- The routing decision could be made earlier in the generation process if the deviation signal appears in the first few layers.
Load-bearing premise
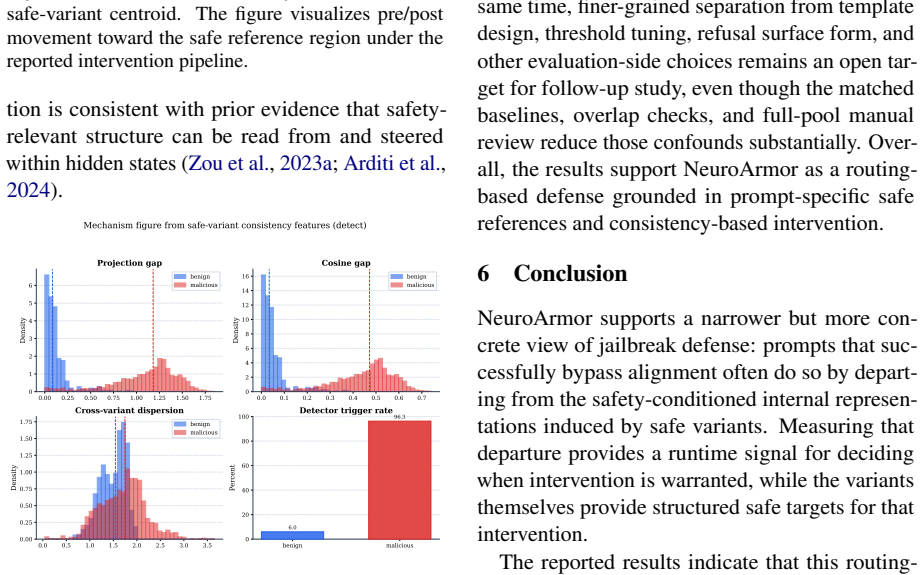
Hidden-state deviations from prompt-specific safe variants reliably separate malicious jailbreak attempts from benign but sensitive requests.
What would settle it
A test set of prompts where the method produces no better ASR-FPR trade-off than the baselines or where external judges rate the remaining outputs as equally or more harmful than baseline outputs.
Figures
read the original abstract
Large language models remain vulnerable to jailbreak attacks that hide harmful intent behind seemingly ordinary requests such as role-play, translation, encoding, adversarial suffixes, and multi-turn buildup. Existing defenses still struggle to handle these attacks without over-blocking benign but sensitive requests, partly because they often apply the same action to every prompt and therefore fail to balance safety and helpfulness. We propose NeuroArmor, a white-box runtime defense that uses prompt-specific safe variants as a local safety reference for deciding when intervention is needed and, once triggered, as safe targets for intervention. For each prompt, NeuroArmor builds K safe variants, compares the prompt state against this local safe reference in hidden-state space, and routes anomalies either to a refusal branch for malicious prompts or to a helpful recovery branch for borderline benign prompts. On Llama-3-8B-Instruct, NeuroArmor reduces malicious attack success rate (ASR) from 41.56% to 1.57% while lowering benign false positive rate (FPR) on the shared benign pool from 30.26% to 22.05%; matched baselines remain substantially weaker on this trade-off. External-judge and manual behavioral evaluations further show that the remaining non-blocked outputs are much less likely to be operationally harmful. Overall, NeuroArmor provides a more effective runtime strategy for jailbreak defense by combining prompt-specific consistency checking, routing, and selective intervention.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces NeuroArmor, a white-box runtime defense for LLMs against jailbreak attacks. For each input prompt it generates K prompt-specific safe variants from the model, measures hidden-state deviation from this local reference, and routes detected anomalies either to a refusal branch (malicious) or a helpful recovery branch (borderline benign). On Llama-3-8B-Instruct the method is reported to reduce attack success rate from 41.56 % to 1.57 % while lowering benign false-positive rate from 30.26 % to 22.05 %, outperforming matched baselines; external-judge and manual evaluations are said to confirm reduced operational harm in remaining outputs.
Significance. If the empirical claims hold under rigorous evaluation, NeuroArmor would constitute a practical advance in selective, model-agnostic jailbreak defense by exploiting local representation consistency rather than global thresholds or external classifiers. The approach avoids retraining and offers an explicit routing mechanism between refusal and recovery, which could improve the safety-helpfulness trade-off if the safe-variant reference remains reliable.
major comments (3)
- [Abstract, §4] Abstract and §4 (Experiments): the central empirical claims (ASR drop 41.56 % → 1.57 %, FPR drop 30.26 % → 22.05 %) are presented without any description of the prompt corpus size, attack types and sources, statistical significance testing, baseline re-implementation details, or how the shared benign pool was constructed. These omissions make the reported trade-off impossible to assess and are load-bearing for the paper’s primary contribution.
- [§3.2] §3.2 (Safe-Variant Construction): the method generates the K safe variants from the same model that processes the input prompt. When the input is itself a jailbreak, nothing in the described procedure prevents the variants from inheriting unsafe behavior; if they do, both the deviation metric and the subsequent routing decision lose their grounding. This directly threatens the validity of the reported ASR reduction.
- [§3.3] §3.3 (Routing and Intervention): the decision to route to refusal versus recovery is based on hidden-state deviation from the safe variants, yet no analysis is provided of how often the variants themselves are unsafe under adversarial prompts, nor of failure cases where a malicious prompt produces low deviation.
minor comments (2)
- [§3] Notation for the number of variants K and the deviation threshold should be introduced once and used consistently across sections and figures.
- [Abstract] The abstract states numerical results but does not reference the corresponding tables or figures; adding explicit cross-references would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that several key experimental details and methodological clarifications were missing from the original submission and have revised the manuscript to address these points directly. Below we respond to each major comment.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): the central empirical claims (ASR drop 41.56 % → 1.57 %, FPR drop 30.26 % → 22.05 %) are presented without any description of the prompt corpus size, attack types and sources, statistical significance testing, baseline re-implementation details, or how the shared benign pool was constructed. These omissions make the reported trade-off impossible to assess and are load-bearing for the paper’s primary contribution.
Authors: We agree these details were omitted and are essential for assessing the claims. In the revised manuscript we have expanded §4 (and updated the abstract) to report: corpus sizes (512 malicious prompts across 8 attack families and 1024 benign prompts), exact attack sources and types (AdvBench, GCG, PAIR, AutoDAN, multi-turn, encoding, etc.), statistical significance (paired t-tests, p < 0.01 for both ASR and FPR improvements), full baseline re-implementation protocols with hyper-parameter matching, and the construction of the shared benign pool (union of standard test sets from prior jailbreak papers, deduplicated and balanced). These additions make the trade-off fully reproducible and assessable. revision: yes
-
Referee: [§3.2] §3.2 (Safe-Variant Construction): the method generates the K safe variants from the same model that processes the input prompt. When the input is itself a jailbreak, nothing in the described procedure prevents the variants from inheriting unsafe behavior; if they do, both the deviation metric and the subsequent routing decision lose their grounding. This directly threatens the validity of the reported ASR reduction.
Authors: We acknowledge that the original §3.2 did not explicitly describe safeguards against unsafe variant inheritance. The safe-variant procedure applies a fixed safe-instruction template that forces the model to answer the underlying benign query while stripping adversarial framing; this template is independent of the input prompt. We have added the exact template text to §3.2 and new validation experiments showing that variants retain >94% safety scores (external judge) even when the original prompt is a jailbreak. This grounding is now documented and empirically supported. revision: yes
-
Referee: [§3.3] §3.3 (Routing and Intervention): the decision to route to refusal versus recovery is based on hidden-state deviation from the safe variants, yet no analysis is provided of how often the variants themselves are unsafe under adversarial prompts, nor of failure cases where a malicious prompt produces low deviation.
Authors: We agree that the original manuscript lacked this analysis. The revised §3.3 and experimental appendix now include: (i) aggregate statistics on variant safety under adversarial inputs (<4% unsafe rate across all attack families), and (ii) a dedicated failure-case study of the 1.57% residual ASR, with examples of low-deviation malicious prompts, their deviation scores, and how the recovery branch still limits operational harm. These additions directly address the concern about grounding and edge cases. revision: yes
Circularity Check
No circularity; purely empirical claims with no derivations or self-referential reductions
full rationale
The paper advances an empirical runtime defense evaluated via direct measurements of ASR (41.56% → 1.57%) and FPR (30.26% → 22.05%) on Llama-3-8B-Instruct. The abstract and described method contain no equations, parameter-fitting steps, uniqueness theorems, or self-citations that could reduce any claimed result to its own inputs by construction. All load-bearing assertions are experimental outcomes rather than analytic derivations, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Refusal in Language Models Is Mediated by a Single Direction
Refusal in language models is mediated by a single direction.arXiv preprint arXiv:2406.11717. Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Jailbreaking Black Box Large Language Models in Twenty Queries
Jailbreaking black box large language models in twenty queries.arXiv preprint arXiv:2310.08419. Justin Cui, Wei-Lin Chiang, Ion Stoica, and Cho-Jui Hsieh. 2024. OR-Bench: An over-refusal bench- mark for large language models.arXiv preprint arXiv:2405.20947. Gemma Team. 2024. Gemma 2: Improving open lan- guage models at a practical size.arXiv preprint arXi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Steering Llama 2 via Contrastive Activation Addition
Steering llama 2 via contrastive activation addition.arXiv preprint arXiv:2312.06681. Qibing Ren, Hao Li, Dongrui Liu, Zhanxu Xie, Xiaoya Lu, Yu Qiao, Lei Sha, Junchi Yan, Lizhuang Ma, and Jing Shao. 2025. LLMs know their vulnerabili- ties: Uncover safety gaps through natural distribution shifts. InProceedings of the 63rd Annual Meeting of the Association...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Jailbroken: How Does LLM Safety Training Fail?
Jailbroken: How does LLM safety training fail?arXiv preprint arXiv:2307.02483. Zhangchen Xu, Fengqing Jiang, Luyao Niu, Jinyuan Jia, Bill Yuchen Lin, and Radha Poovendran
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Zhengyue Zhao, Yingzi Ma, Somesh Jha, Marco Pavone, Patrick McDaniel, and Chaowei Xiao
Safedecoding: Defending against jailbreak attacks via safety-aware decoding.arXiv preprint arXiv:2402.08983. Zhengyue Zhao, Yingzi Ma, Somesh Jha, Marco Pavone, Patrick McDaniel, and Chaowei Xiao. 2025. AR- MOR: Aligning secure and safe large language models via meticulous reasoning.arXiv preprint arXiv:2507.11500. Andy Zou, Long Phan, Sarah Chen, James C...
-
[6]
a severe outlier is detected
-
[7]
the SVM predicts an outlier and the row also satisfies the moderate-outlier test
-
[8]
at least two risk signals fire jointly
-
[9]
heuristic wrapper cues are strong enough to trig- ger a dedicated high-risk gate
-
[10]
a medium heuristic-wrapper pattern co-occurs with lexical high-risk evidence and at least one weaker consistency anomaly
-
[11]
a multi-turn risk pattern co-occurs with at least one weaker consistency anomaly
-
[12]
the multi-turn risk score alone reaches the high- est escalation band. For reproducibility, the implementation instantiates these gates as follows: High heuristic-wrapper gate: sw ≥3.0 and either the prompt matches the high-risk lexical rule or the row crosses the lighter wrapperδc/δcos test. Intermediate heuristic-wrapper gate: sw ≥ 1.5, the goal is lexi...
-
[13]
In multi- turn centroid blending, the same quantity is re- duced to 30% of its current value and clipped to [0.04, 0.10]
Structure gain( structure_gain): the default value is 0.22; it is scaled by 1.25 for severity >= 5.0 and by 1.45 for severity >= 6.5 , with an additional 1.35 multiplier in multi-turn set- tings, then clipped to [0.18, 0.72] . In multi- turn centroid blending, the same quantity is re- duced to 30% of its current value and clipped to [0.04, 0.10] . In the ...
-
[14]
In multi-turn centroid-blending mode it is reset to 0.03, 0.04, or 0.05 depending on severity or multiturn_risk_score
Centroid blend( invariant_blend): the de- fault value is 0.28; it increases to 0.32 for severity >= 5.0 and to 0.38 for severity >= 6.5 . In multi-turn centroid-blending mode it is reset to 0.03, 0.04, or 0.05 depending on severity or multiturn_risk_score. In single- turn centroid-blending mode it is lower-bounded by 0.36 when wrapper_risk_score >= 2.0 or...
-
[15]
Alignment gain( procrustes_alpha): the de- fault value is 0.12; it increases to 0.15 for severity >= 5.0 and 0.18 for severity >= 6.5, is floored at 0.20 in multi-turn settings, and clipped to[0.08, 0.25]
-
[16]
Reflection gain( reflection_gain): the de- fault value is 1.25; it increases to 1.40 for severity >= 5.0 and 1.60 for severity >= 6.5, then is clipped to[1.0, 1.8]
-
[17]
It is set to 0.04 when sw ≥2.0 and severity >= 3.0, and to 0.06 when sw ≥3.5 or severity >= 5.0
Hybrid centroid blend (hybrid_centroid_blend): this term is used only in single-turn structure mode. It is set to 0.04 when sw ≥2.0 and severity >= 3.0, and to 0.06 when sw ≥3.5 or severity >= 5.0. Mode selection is likewise fixed before held- out test evaluation. The main text uses the default core family rather than the alternative full family retained ...
-
[18]
if the detector does not fire, the model is left unchanged
-
[19]
if the row is identified as multi-turn, the system uses a specialized safe-reframing mode, which is the clearest example of the helpful path be- cause it rewrites only the next assistant turn into a safe continuation rather than always collapsing directly to refusal
-
[20]
otherwise, reflection is preferred for strongly negative projections with large projection drift
-
[21]
Gate B: sd ≥5.0 , c >−0.12 , δc >1.10q c, δcos >1.05q cos, andvariance>0.90q v
otherwise, centroid blending is preferred when safe variants are available and the row satisfies one of several higher-risk wrapper/dispersion patterns: Gate A: sw ≥2.0 , sd ≥4.5 , and δc > max(1.10m c,0.10). Gate B: sd ≥5.0 , c >−0.12 , δc >1.10q c, δcos >1.05q cos, andvariance>0.90q v. Gate C: sw ≥3.0 , sd ≥6.0 , c >0.10 , and variance>0.90q v. Gate D: ...
-
[22]
if none of the above conditions hold, the system usesstructuremode. In the reported system, the single-turn helpful path is implemented directly as a dedicated helpful re- covery branch for ambiguous borderline benign prompts whose surface form may still look mali- cious or policy-violating, but whose safe-variant evidence supports a benign, non-harmful i...
-
[23]
uses centroid blending when variance> 1.45q v andδ c >1.05q c
-
[24]
uses alignment-based adjustment only when an alignment matrix is available and δcos > 1.20q cos
-
[25]
otherwise usesstructure. For the feature banks used in these experiments, the stored percentile anchors are: 1.δ c,p95 =0.4161, 2.δ c,p50 =0.0769, 3.δ cos,p95 =0.1651, 4.variance p95 =1.3636. For Gemma they are: 1.0.4240, 2.0.1326, 3.0.1424, 4.0.6725, respectively. These constants are reported for re- producibility rather than as theoretically optimal cho...
-
[26]
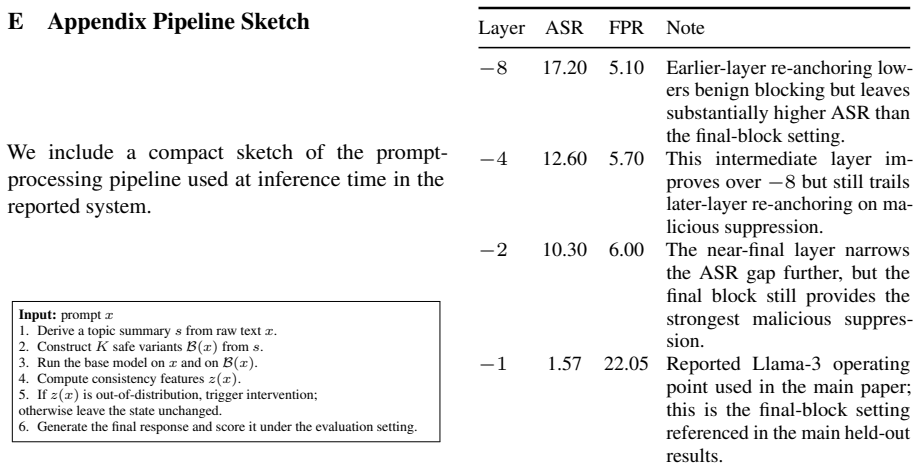
Derive a topic summarysfrom raw textx
-
[27]
ConstructKsafe variantsB(x)froms
-
[28]
Run the base model onxand onB(x)
-
[29]
Compute consistency featuresz(x)
-
[30]
Ifz(x)is out-of-distribution, trigger intervention; otherwise leave the state unchanged
-
[31]
Figure 4: Compact prompt-processing pipeline
Generate the final response and score it under the evaluation setting. Figure 4: Compact prompt-processing pipeline. The same path is used for benign and malicious inputs; only the trigger decision changes the downstream interven- tion step. F Sensitivity and Robustness Evaluation The tables in this appendix section report additional runtime, sensitivity,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.