BaltiVoice: A Speech Corpus and Fine-tuned Whisper ASR System for the Balti Language
Pith reviewed 2026-06-28 10:09 UTC · model grok-4.3
The pith
Fine-tuning a pre-trained ASR model on the new BaltiVoice corpus reduces word error rate to 26.74 percent from a zero-shot baseline of 159.19 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
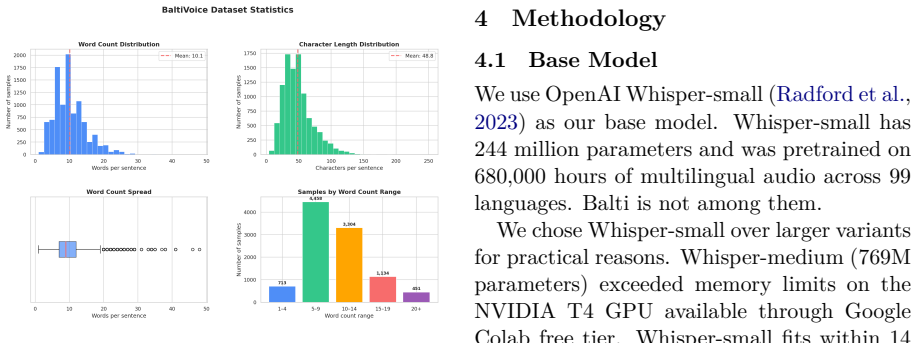
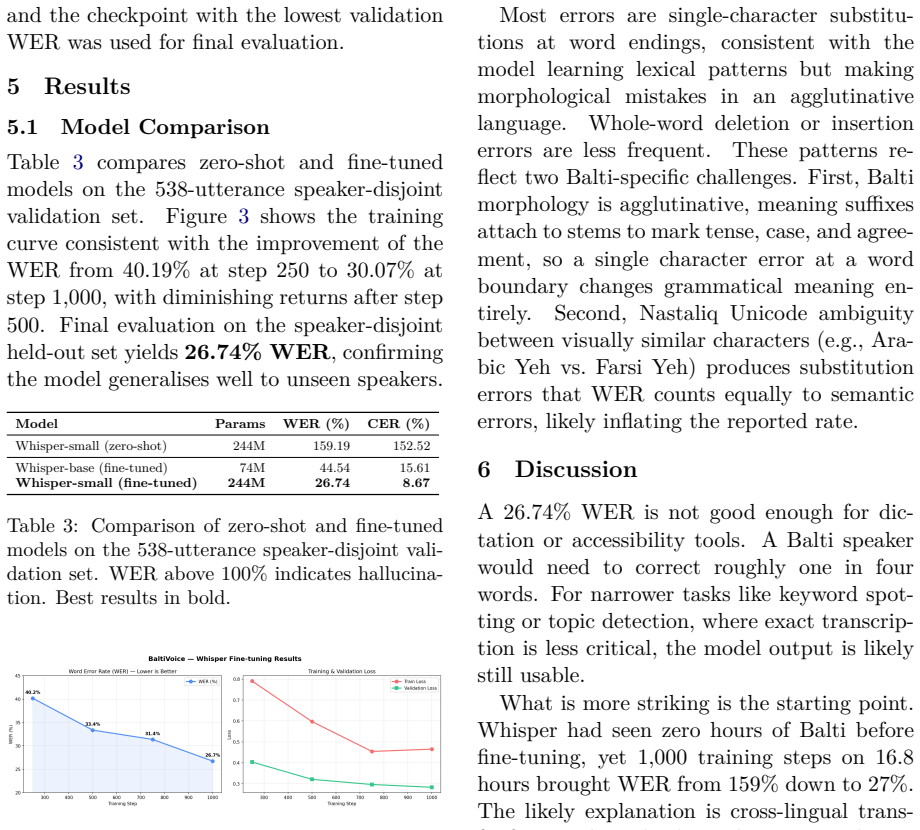
BaltiVoice supplies 10,060 validated utterances in native script totaling 16.8 hours of read speech for a language with no prior public ASR resources. Fine-tuning the small pre-trained model on these data produces 26.74 percent word error rate and 8.67 percent character error rate on the 538-utterance validation set, compared with 159.19 percent WER and 152.52 percent CER for the untuned baseline. The base model reaches 44.54 percent WER and 15.61 percent CER after identical fine-tuning.
What carries the argument
The BaltiVoice corpus of 10,060 validated read-speech utterances used to fine-tune a pre-trained small ASR model for improved transcription accuracy.
If this is right
- Balti now possesses a publicly released ASR system that achieves moderate transcription accuracy on read speech.
- Larger model capacity produces better results than smaller capacity when fine-tuned on the same limited data for this language.
- The method of adapting an existing pre-trained model to a new language via a modest read-speech corpus can be repeated for other unsupported languages.
- Public release of both the corpus and the tuned models allows direct use and further development by others.
Where Pith is reading between the lines
- Voice interfaces and accessibility tools for Balti speakers could now be built on top of the released model.
- Collecting additional spontaneous speech data beyond the current read-speech corpus would likely be needed to reach usable accuracy in everyday conversation.
- The same fine-tuning recipe may transfer to other Tibetic languages that also lack dedicated speech resources.
Load-bearing premise
The utterances drawn from existing recordings are representative of natural Balti speech and free of systematic transcription or recording artifacts that would exaggerate the measured performance gains.
What would settle it
Running the fine-tuned model on a fresh collection of Balti speech recordings gathered independently from the source used to build the corpus and measuring whether the error rates remain near the reported levels.
Figures

read the original abstract
We present BaltiVoice, a 16.8-hour read-speech corpus for Balti (ISO 639-3: bft), a Tibetic language spoken in Gilgit-Baltistan, Pakistan, with no prior publicly available ASR resources. The corpus contains 10,060 validated utterances in native Nastaliq script, derived from Mozilla Common Voice recordings. Fine-tuning OpenAI Whisper-small yields a Word Error Rate (WER) of 26.74% and a Character Error Rate (CER) of 8.67% on a 538-utterance speaker-disjoint validation set, down from a zero-shot baseline of 159.19% WER and 152.52% CER. A Whisper-base fine-tuned on the same data achieves 44.54% WER and 15.61% CER, confirming that model capacity matters for this low-resource setting. The dataset, fine-tuned model, and a live transcription demo are publicly available on HuggingFace.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents BaltiVoice, a 16.8-hour read-speech corpus for Balti (ISO 639-3: bft) derived from Mozilla Common Voice, containing 10,060 validated utterances in Nastaliq script. It reports that fine-tuning Whisper-small on this data yields 26.74% WER and 8.67% CER on a 538-utterance speaker-disjoint validation set (improving from zero-shot baselines of 159.19% WER and 152.52% CER), with a Whisper-base comparison at 44.54% WER; the dataset, models, and demo are released publicly on Hugging Face.
Significance. If the empirical claims hold, this supplies the first public ASR resources for a previously unsupported low-resource Tibetic language and demonstrates the value of Whisper fine-tuning in such settings when model capacity is adequate. The public release of the corpus, fine-tuned models, and live demo constitutes a clear strength for reproducibility and community follow-up work.
major comments (3)
- [§3 (Corpus Construction)] §3 (Corpus Construction): The 10,060 utterances are described as 'validated' with no details provided on validation criteria, number of validators, acceptance thresholds, or inter-annotator agreement; this is load-bearing because the headline WER reduction from 159% to 26.74% assumes reliable Nastaliq ground-truth labels, and residual Common Voice transcription mismatches could produce spurious gains by fitting label noise rather than acoustic patterns.
- [§4 (Experiments)] §4 (Experiments): No error-type breakdown (substitutions, deletions, insertions), qualitative error examples, or analysis of remaining errors on the 538-utterance set is reported, and the 26.74% WER figure lacks confidence intervals or statistical significance testing; these omissions prevent assessment of whether the result reflects usable Balti ASR or systematic artifacts.
- [§4 (Experiments)] §4 (Experiments): The speaker-disjoint split is asserted but no verification of speaker metadata completeness or handling of potential speaker-label errors in the source Common Voice recordings is described, which directly affects the validity of the reported generalization claim.
minor comments (2)
- Ensure all tables or result summaries explicitly state the exact train/validation/test utterance counts and total hours alongside the WER/CER values.
- [Abstract] The abstract and introduction could briefly note the read-speech nature of the corpus as a limitation for conversational ASR applications.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for improving the clarity and rigor of our presentation. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§3 (Corpus Construction)] The 10,060 utterances are described as 'validated' with no details provided on validation criteria, number of validators, acceptance thresholds, or inter-annotator agreement; this is load-bearing because the headline WER reduction from 159% to 26.74% assumes reliable Nastaliq ground-truth labels, and residual Common Voice transcription mismatches could produce spurious gains by fitting label noise rather than acoustic patterns.
Authors: We agree that additional transparency on label quality is required. The utterances were drawn exclusively from the validated subset of the Mozilla Common Voice Balti collection. We will revise §3 to describe Common Voice's community validation protocol, including the standard requirement for multiple independent validators and the acceptance thresholds as specified in the Common Voice documentation. We will also note that language-specific inter-annotator agreement figures are not released by the platform; the validated designation reflects consensus among validators. These additions will directly address concerns about potential label noise. revision: yes
-
Referee: [§4 (Experiments)] No error-type breakdown (substitutions, deletions, insertions), qualitative error examples, or analysis of remaining errors on the 538-utterance set is reported, and the 26.74% WER figure lacks confidence intervals or statistical significance testing; these omissions prevent assessment of whether the result reflects usable Balti ASR or systematic artifacts.
Authors: We accept that the current experimental section lacks sufficient diagnostic detail. In the revised manuscript we will add an error analysis subsection reporting the breakdown of substitutions, deletions, and insertions, together with qualitative examples of recurring error patterns. We will also compute and report bootstrap 95% confidence intervals for WER and CER, and include statistical significance tests comparing the fine-tuned models against the zero-shot baselines. These changes will enable readers to evaluate whether the reported performance represents genuine acoustic modeling gains. revision: yes
-
Referee: [§4 (Experiments)] The speaker-disjoint split is asserted but no verification of speaker metadata completeness or handling of potential speaker-label errors in the source Common Voice recordings is described, which directly affects the validity of the reported generalization claim.
Authors: The speaker-disjoint split was performed using the speaker identifiers supplied in the public Common Voice metadata. We will expand the experimental description to detail the partitioning procedure and the resulting speaker counts per split. We did not perform an independent verification of speaker-label accuracy beyond the provided metadata, as the original recordings do not include additional provenance information. We will add an explicit limitation statement acknowledging reliance on the source metadata and the possibility of residual speaker-label noise. revision: partial
Circularity Check
No significant circularity; results are direct empirical measurements
full rationale
The paper presents an empirical contribution: creation of the BaltiVoice corpus from Common Voice recordings and fine-tuning of Whisper models, with WER/CER reported on a speaker-disjoint held-out validation set. No equations, predictions, or derivations are present that reduce to fitted inputs or self-referential quantities. No self-citations are used to justify load-bearing claims. The central results are falsifiable measurements on external data splits and do not rely on any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 12th Language Resources and Evaluation Conference (LREC 2020) , pages =
Common Voice: A Massively-Multilingual Speech Corpus , author =. Proceedings of the 12th Language Resources and Evaluation Conference (LREC 2020) , pages =. 2020 , address =
2020
-
[2]
Proceedings of the 40th International Conference on Machine Learning (ICML 2023) , pages =
Robust Speech Recognition via Large-Scale Weak Supervision , author =. Proceedings of the 40th International Conference on Machine Learning (ICML 2023) , pages =. 2023 , publisher =
2023
-
[3]
2022 , publisher =
Babu, Arun and Wang, Changhan and Tjandra, Andros and Lakhotia, Kushal and Xu, Qiantong and Goyal, Naman and Singh, Kritika and von Platen, Patrick and Saraf, Yatharth and Pino, Juan and Baevski, Alexei and Joulin, Armand and Auli, Michael , booktitle =. 2022 , publisher =
2022
-
[4]
Whisper-Based
Shon, Suwon and Bali, Kalika and Singh, Sunayana and Sitaram, Sunayana , booktitle =. Whisper-Based. 2023 , publisher =
2023
-
[5]
Low-Resource
Gandhe, Aditya and Levow, Gina-Anne and Fung, Pascale , booktitle =. Low-Resource. 2023 , publisher =
2023
-
[6]
, booktitle =
Nyima, Tashi and Mortensen, David R. , booktitle =. A. 2022 , address =
2022
-
[7]
Highland
Shi, Xiaodong and Yue, Yang and Zhang, Jiawei and Liu, Wei and Yu, Kai , journal =. Highland. 2021 , publisher =
2021
-
[8]
Quantifying the Carbon Emissions of Machine Learning
Quantifying the Carbon Emissions of Machine Learning , author =. arXiv preprint arXiv:1910.09700 , year =
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[9]
arXiv preprint arXiv:2409.16317 , year =
A Literature Review of Keyword Spotting Technologies for Urdu , author =. arXiv preprint arXiv:2409.16317 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.