SAGE: A Quantitative Evaluation of Socialized Evolution in Agent Ecosystems
Pith reviewed 2026-06-28 10:00 UTC · model grok-4.3
The pith
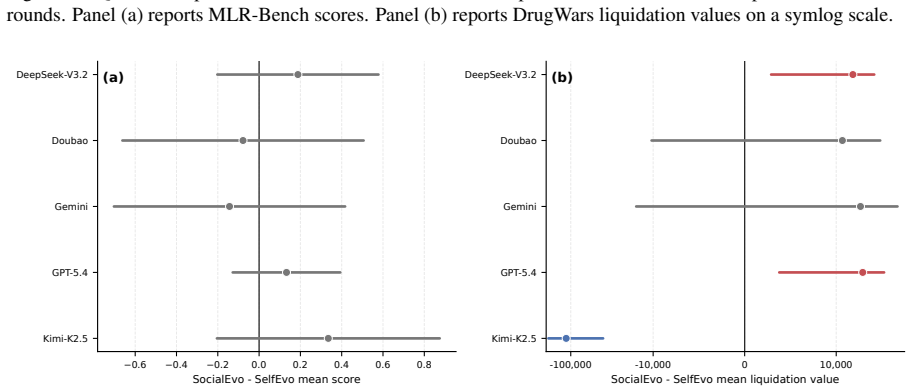
Peer histories allow plateauing agents to break through but leave the strongest agents at their self-evolution ceiling
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
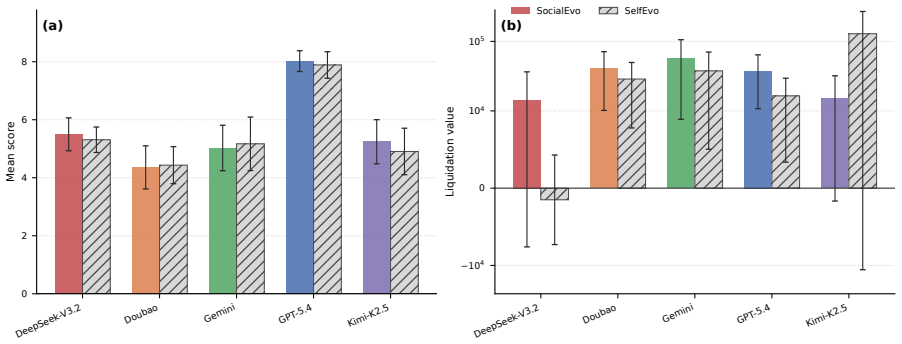
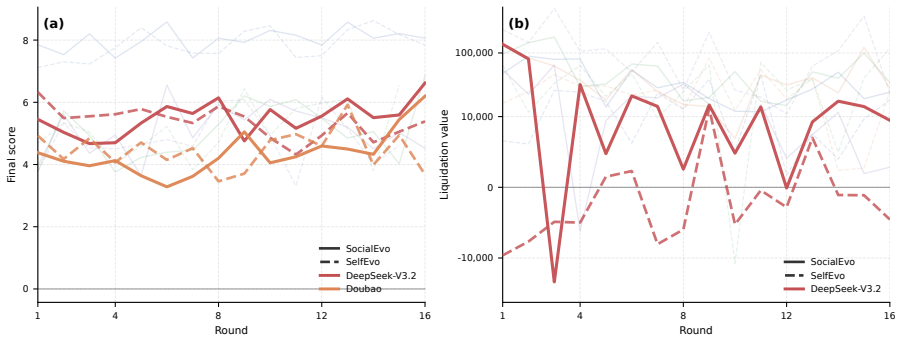
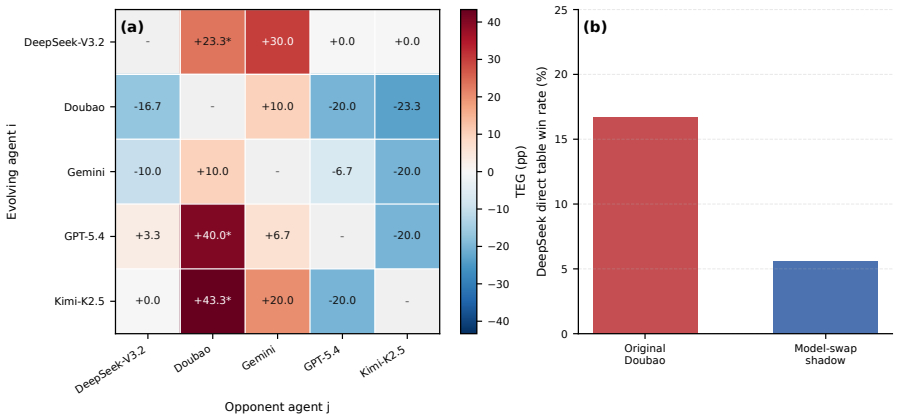
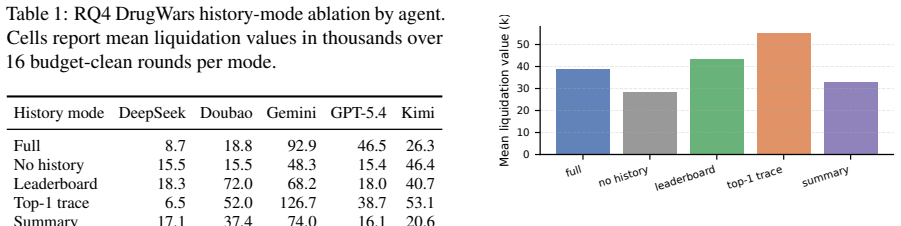
The central finding is that group history is not a universal amplifier of performance. While agents that plateau under self-improvement achieve significant breakthroughs when peer experience is available, the strongest agent does not exceed its self-evolution ceiling. In competitive settings, agents improve in general ways rather than developing strategies specific to particular opponents. Across different forms of shared history, filtered peer traces and reflective summaries often outperform raw logs, indicating that social gains depend on abstraction rather than exposure volume. These patterns show that peer-history gains are agent-specific, arena-dependent, and contingent on the capacity
What carries the argument
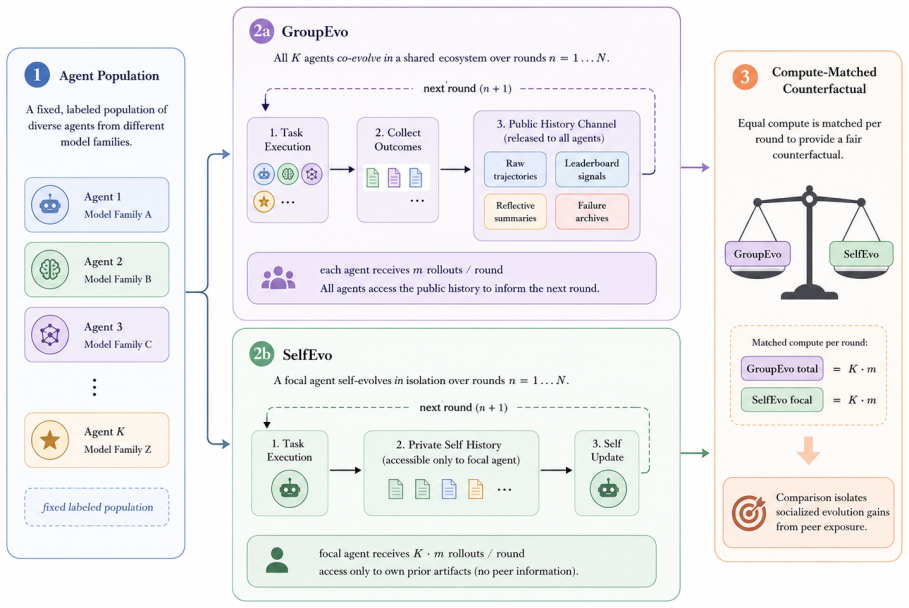
SAGE framework comparing SocialEvo condition, where agents co-evolve with access to all peers' histories, against SelfEvo condition, where agents see only their own histories, across multiple evolutionary rounds.
If this is right
- Agents stuck at a performance level through solo refinement can advance further by incorporating peer histories.
- The leading agent in any group gains nothing additional from seeing others' work.
- Improvements from social exposure tend to be broadly applicable rather than tailored to individual opponents.
- Processing peer data into summaries or filtered traces yields better results than using unprocessed logs.
- Whether social evolution provides an edge depends on the specific agent and the nature of the arena.
Where Pith is reading between the lines
- Future agent training systems could selectively share curated histories among lower-performing instances to boost overall group capability without burdening the best performers.
- Methods for automatically abstracting and filtering peer traces may be more important for realizing social gains than simply increasing the amount of shared data.
- The arena-dependence suggests that the value of social evolution could be tested in additional domains such as scientific discovery or creative tasks to map where it applies.
Load-bearing premise
The three chosen arenas and the five model families are sufficient to generalize the claim that social gains are agent-specific and arena-dependent rather than universal.
What would settle it
Finding that the strongest agent exceeds its self-evolution ceiling when given access to peer histories in one of the tested arenas or in a new arena would contradict the reported pattern.
Figures
read the original abstract
Self-improving language agents are typically evaluated in isolation: an agent attempts a task, receives feedback, and iteratively refines its own behavior. Yet agents increasingly operate alongside peers whose strategies and outcomes are publicly visible. This raises an under-studied question: when does shared experience produce improvements that self-improvement alone cannot achieve? We introduce SAGE (Social Agent Group Evolution),an evaluation framework that compares two compute-matched conditions: SocialEvo, where agents from five distinct model families co-evolve with access to all peers' histories; and SelfEvo, where each agent receives the same number of task attempts but sees only its own past, which is conventional in self-improving agent studies. We instantiate SAGE in three arenas: open-ended ML research, long-horizon economic planning, and strategic multiplayer play, evaluated across multiple evolutionary rounds. We find that group history is not a universal amplifier: the strongest agent does not exceed its self-evolution ceiling. However, agents that plateau under self-improvement can achieve significant breakthroughs when peer experience is available. In competitive settings, counterfactual controls reveal that agents improve generally rather than developing opponent-specific strategies. Across different forms of shared history, filtered peer traces and reflective summaries often outperform raw logs, indicating that social gains depend on abstraction rather than exposure volume. These findings reveal that peer-history gains are agent-specific, arena-dependent, and contingent on the capacity to abstract transferable knowledge from public traces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the SAGE evaluation framework comparing SocialEvo (five model families co-evolving with full access to peers' histories) against compute-matched SelfEvo (isolated self-improvement) across three arenas: open-ended ML research, long-horizon economic planning, and strategic multiplayer play. Central claims are that shared peer history is not a universal amplifier—the strongest agent does not exceed its self-evolution ceiling—while plateauing agents achieve significant breakthroughs; gains are agent-specific and arena-dependent; and filtered/reflective traces outperform raw logs, indicating dependence on abstraction capacity rather than exposure volume. Counterfactual controls in competitive settings show general rather than opponent-specific improvement.
Significance. If the results hold, the work supplies controlled empirical evidence that social mechanisms in agent ecosystems produce conditional rather than universal gains, with direct implications for designing multi-agent self-improvement systems. The compute-matched design, use of counterfactual controls, and comparison of trace formats (raw vs. filtered vs. reflective) are methodological strengths that support attribution of effects to social abstraction.
major comments (2)
- [Abstract and §4 (Results)] The conclusion that 'peer-history gains are agent-specific, arena-dependent, and [not universal]' (abstract) rests on experiments in only three arenas using five model families. These arenas share language-mediated structure with public outcome visibility; the manuscript should add a limitations discussion or sensitivity analysis addressing whether the plateauing-agent benefit pattern would replicate in structurally dissimilar domains (e.g., continuous control or formal verification).
- [Abstract and Results sections] Quantitative claims of 'significant breakthroughs' and 'often outperform' lack reported error bars, statistical tests, or raw per-agent/per-arena data in the abstract and high-level description; without these the agent-specific and arena-dependent claims cannot be assessed for robustness.
minor comments (2)
- [Abstract] Define the SAGE acronym on first use rather than introducing it before the expansion.
- [Results and Appendix] Ensure all result tables or figures report sample sizes, variance measures, and exact evolutionary round counts for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, agreeing where revisions are warranted to improve clarity and robustness.
read point-by-point responses
-
Referee: [Abstract and §4 (Results)] The conclusion that 'peer-history gains are agent-specific, arena-dependent, and [not universal]' (abstract) rests on experiments in only three arenas using five model families. These arenas share language-mediated structure with public outcome visibility; the manuscript should add a limitations discussion or sensitivity analysis addressing whether the plateauing-agent benefit pattern would replicate in structurally dissimilar domains (e.g., continuous control or formal verification).
Authors: We agree that the evaluation is confined to three language-mediated arenas with public outcome visibility, which constrains claims of broader applicability. In the revised manuscript we will insert a dedicated Limitations section that explicitly notes this scope, discusses why the plateauing-agent benefit may not hold in structurally different settings such as continuous control or formal verification, and outlines the need for future sensitivity analyses in those domains. revision: yes
-
Referee: [Abstract and Results sections] Quantitative claims of 'significant breakthroughs' and 'often outperform' lack reported error bars, statistical tests, or raw per-agent/per-arena data in the abstract and high-level description; without these the agent-specific and arena-dependent claims cannot be assessed for robustness.
Authors: The full results (§4) and appendix already contain per-agent/per-arena tables across multiple runs with variability measures. We nevertheless accept that the abstract and high-level summaries would benefit from explicit robustness indicators. We will revise the abstract to include a concise qualifier referencing observed variability (e.g., gains exceeding self-evolution standard deviation) and add a cross-reference in the Results overview to the statistical details and raw data provided in the main text and appendix. revision: yes
Circularity Check
No circularity: purely empirical comparison of SocialEvo vs SelfEvo conditions
full rationale
The paper presents an evaluation framework (SAGE) that runs compute-matched experiments in three arenas using five model families, directly comparing agent performance under peer-history access versus isolated self-history. No equations, fitted parameters, ansatzes, or derivation chains are described in the abstract or provided text. The central findings (plateauing agents benefit from peers while strongest agents do not exceed self-ceilings; gains are agent-specific and arena-dependent) are presented as direct observations from the runs rather than reductions from prior self-citations or self-definitions. The limited number of arenas is a generalization concern but does not constitute circularity under the defined patterns, as there is no load-bearing step that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nikolas Belle, Dakota Barnes, Alfonso Amayuelas, Ivan Bercovich, Xin Eric Wang, and William Wang
Human-level play in the game of Diplomacy by combining language models with strategic reason- ing.Science, 378(6624):1067–1074. Nikolas Belle, Dakota Barnes, Alfonso Amayuelas, Ivan Bercovich, Xin Eric Wang, and William Wang. 2025. Agents of change: Self-evolving LLM agents for strategic planning.Preprint, arXiv:2506.04651. Avrim Blum and Moritz Hardt. 20...
arXiv 2025
-
[2]
InProceed- ings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 20271–20309
MLAgentBench: Evaluating language agents on machine learning experimentation. InProceed- ings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 20271–20309. PMLR. Max Jaderberg, Valentin Dalibard, Simon Osindero, Wo- jciech M. Czarnecki, Jeff Donahue, Ali Razavi, Oriol Vinyals, Tim Green...
-
[3]
Population based training of neural networks. Preprint, arXiv:1711.09846. Douwe Kiela, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, Zhengxuan Wu, Bertie Vid- gen, Grusha Prasad, Amanpreet Singh, Pratik Ring- shia, Zhiyi Ma, Tristan Thrush, Sebastian Riedel, Zeerak Waseem, Pontus Stenetorp, Robin Jia, Mohit Bansal, Christopher Potts, and Adina...
Pith/arXiv arXiv 2021
-
[4]
Jonathan Light, Min Cai, Sheng Shen, and Ziniu Hu
Rethinking mixture-of-agents: Is mixing dif- ferent large language models beneficial?Preprint, arXiv:2502.00674. Jonathan Light, Min Cai, Sheng Shen, and Ziniu Hu
-
[5]
Andrei Lupu, Timon Willi, and Jakob Foerster
Avalonbench: Evaluating llms playing the game of avalon.Preprint, arXiv:2310.05036. Andrei Lupu, Timon Willi, and Jakob Foerster. 2025. The decrypto benchmark for multi-agent reasoning and theory of mind.Preprint, arXiv:2506.20664. Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumo...
arXiv 2025
-
[6]
Evaluating very long-term conversational memory of LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 13851– 13870, Bangkok, Thailand. Association for Compu- tational Linguistics. Deepak Nathani, Lovish Madaan, Nicholas Roberts, Nikolay Bashlykov, Ajay Menon, Vincent Moens,...
arXiv 2025
-
[7]
Reflexion: Language agents with verbal rein- forcement learning.Preprint, arXiv:2303.11366. Chandler Smith, Marwa Abdulhai, Manfred Diaz, Marko Tesic, Rakshit Trivedi, Sasha Vezhnevets, Lewis Hammond, Jesse Clifton, Minsuk Chang, Edgar A. Duéñez-Guzmán, John P Agapiou, Jayd Matyas, Danny Karmon, Beining Zhang, Jim Dilkes, Akash Kundu, Jord Nguyen, Emanuel...
Pith/arXiv arXiv 2026
-
[8]
In prospect and retrospect: Reflective mem- ory management for long-term personalized dialogue agents. InProceedings of the 63rd Annual Meet- ing of the Association for Computational Linguistics (V olume 1: Long Papers), pages 8416–8439, Vienna, Austria. Association for Computational Linguistics. Jiwei Tang, Zhijing Huang, Xinyu Zhang, Chen Jason Zhang, J...
Pith/arXiv arXiv 2025
-
[9]
Group-evolving agents: Open-ended self- improvement via experience sharing.Preprint, arXiv:2602.04837. Hjalmar Wijk, Tao Roa Lin, Joel Becker, Sami Jawhar, Neev Parikh, Thomas Broadley, Lawrence Chan, Michael Chen, Joshua M Clymer, Jai Dhyani, Elena Ericheva, Katharyn Garcia, Brian Goodrich, Nikola Jurkovic, Megan Kinniment, Aron Lajko, Seraphina Nix, Luc...
arXiv 2025
-
[10]
Weiwei Xie, Shaoxiong Guo, Fan Zhang, Tian Xia, Xue Yang, Lizhuang Ma, Junchi Yan, and Qibing Ren
Autogen: Enabling next-gen LLM appli- cations via multi-agent conversation.Preprint, arXiv:2308.08155. Weiwei Xie, Shaoxiong Guo, Fan Zhang, Tian Xia, Xue Yang, Lizhuang Ma, Junchi Yan, and Qibing Ren
-
[11]
Memevobench: Benchmarking safety risks from memory misevolution in LLM agents.Preprint, arXiv:2604.15774. Zidi Xiong, Yuping Lin, Wenya Xie, Pengfei He, Zirui Liu, Jiliang Tang, Himabindu Lakkaraju, and Zhen Xiang. 2025. How memory management impacts LLM agents: An empirical study of experience- following behavior.Preprint, arXiv:2505.16067. Mert Yuksekgo...
Pith/arXiv arXiv 2025
-
[12]
Jenny Zhang, Shengran Hu, Cong Lu, Robert Lange, and Jeff Clune
Learning to discover at test time.Preprint, arXiv:2601.16175. Jenny Zhang, Shengran Hu, Cong Lu, Robert Lange, and Jeff Clune. 2026a. Darwin godel machine: Open- ended evolution of self-improving agents.Preprint, arXiv:2505.22954. Yunxiang Zhang, Muhammad Khalifa, Shitanshu Bhushan, Grant D Murphy, Lajanugen Logeswaran, Jaekyeom Kim, Moontae Lee, Honglak ...
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.