Testing LLM Arithmetic Reasoning Generalization with Automatic Numeric-Remapping Attacks
Pith reviewed 2026-06-28 09:25 UTC · model grok-4.3
The pith
Numeric-remapping attacks that keep the original reasoning program drop LLM accuracy on GSM8K by 12 to 26 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An automatic pipeline that derives symbolic representations of problems, generates constrained numeric remappings, recomputes gold answers, and applies deterministic edits via LLM-generated plans produces reliable attacks; on GSM8K these attacks reduce conditional accuracy by 12.16 to 25.82 points for the tested models while MAWPS and MultiArith remain stable near or above 98 percent.
What carries the argument
The automatic numeric-remapping attack generator that produces problem-specific symbolic forms, constrained remappings, recomputed answers, and LLM-guided deterministic edits followed by stage-wise validation.
If this is right
- GSM8K remains sensitive to numeric variation even when reasoning programs are preserved and answers are recomputed.
- Shorter and more regular datasets like MAWPS and MultiArith show near-perfect stability under the same attacks.
- Trustworthy direct reasoning on word problems requires robustness to small numeric changes that preserve logic.
- Dataset structure strongly determines how much numeric variation affects model performance.
Where Pith is reading between the lines
- If the attacks scale to other arithmetic benchmarks, current evaluation practices may systematically overestimate generalization.
- Models that pass short regular problems may still fail on longer problems that require the same logic with varied numbers.
- Future robustness tests could incorporate automatic remapping as a standard check rather than relying only on original problem sets.
Load-bearing premise
The generated numeric changes and edit plans keep the original reasoning steps exactly the same and yield valid new answers without creating ambiguities or calculation mistakes.
What would settle it
A manual audit of a sample of the generated attacks that finds any remapping where the reasoning program changes or the recomputed answer is incorrect.
Figures

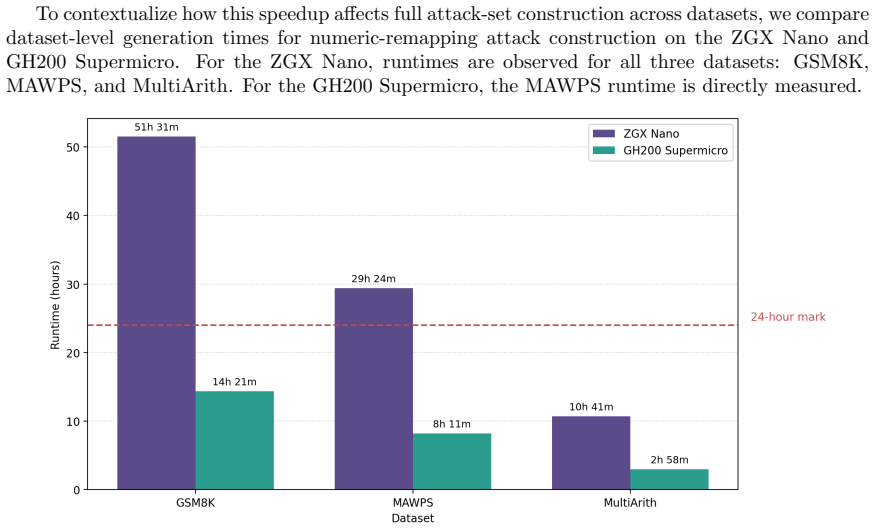
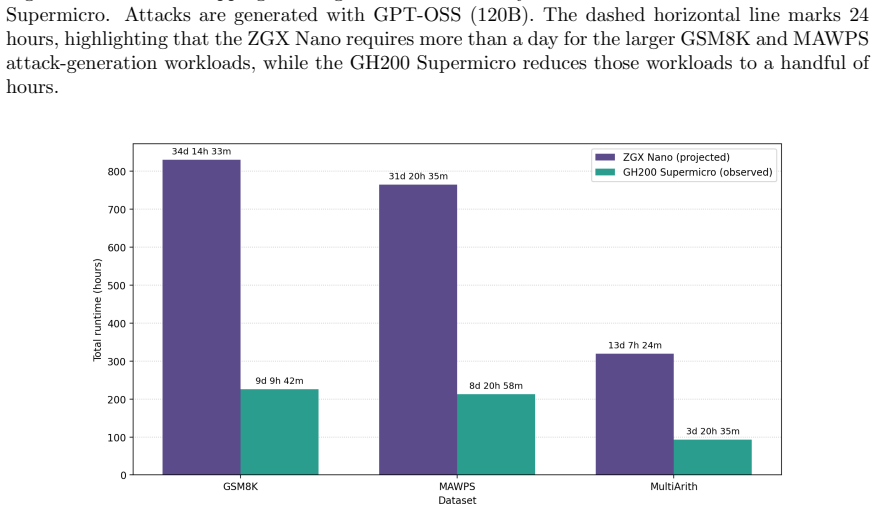
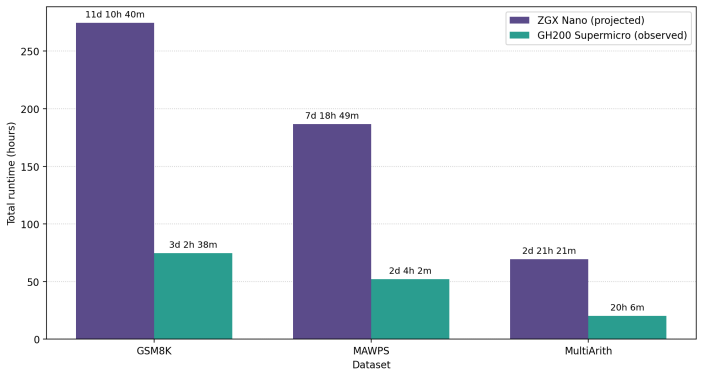
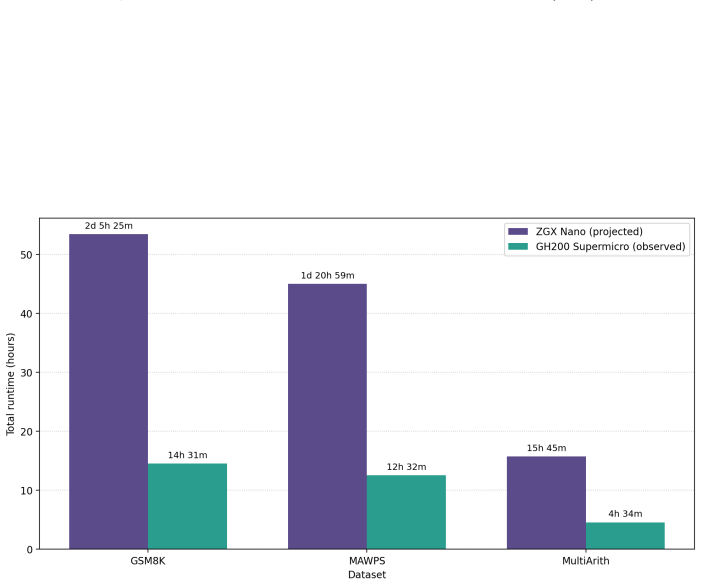
read the original abstract
Large language models achieve strong performance on arithmetic reasoning benchmarks, and one common response to arithmetic brittleness is to delegate computation to code. Yet models are still often used in settings where they must reason directly from natural language, and trustworthy models should solve small-number arithmetic word problems without external tools. Prior work shows that LLMs are sensitive to numerical variation: a model may solve an original problem but fail on structurally similar variants requiring the same reasoning procedure with different numbers. We ask whether this fragility persists under a stricter setting involving small, schema-preserving numeric changes that retain the original reasoning program and avoid large-number stress tests. We introduce an automatic algorithm for generating numeric-remapping attacks on arithmetic word problems. Unlike template-based perturbation methods requiring manual schemas or constraints, our approach derives problem-specific symbolic representations, generates constrained numeric remappings, recomputes gold answers, and realizes transformed questions through deterministic edits guided by LLM-generated edit plans. Stage-wise validation and a high-confidence audit retain reliable attacks, making the pipeline scalable with limited human intervention. We evaluate DeepSeek-R1 (70B), Gemma4 (31B), and GPT-OSS (120B) on GSM8K, MAWPS, and MultiArith. On GSM8K, completed runs show conditional accuracy drops of 12.16 to 25.82 percentage points. MAWPS and MultiArith are far more stable, with most attacked accuracies near or above 98%. These results show that numeric-remapping robustness depends strongly on dataset structure: GSM8K remains sensitive even when reasoning programs are preserved and answers are recomputed, while shorter, more regular datasets are more robust.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an automatic pipeline for generating numeric-remapping attacks on arithmetic word problems. The method derives symbolic representations, samples constrained remappings, recomputes gold answers, and applies LLM-guided deterministic edits, followed by stage-wise validation and a high-confidence audit to retain only reliable attacks that preserve the original reasoning program. Experiments on DeepSeek-R1 (70B), Gemma4 (31B), and GPT-OSS (120B) across GSM8K, MAWPS, and MultiArith report conditional accuracy drops of 12.16–25.82 pp on GSM8K while the shorter datasets remain near or above 98% accuracy, concluding that numeric-remapping robustness is dataset-dependent even under preserved reasoning.
Significance. If the attack validity holds, the result provides evidence that LLM arithmetic reasoning remains brittle to small numeric changes that preserve reasoning structure and gold labels, with clear dataset-structure dependence. The automatic, scalable pipeline (symbolic derivation + constrained remapping + audit) is a methodological strength over manual template methods.
major comments (2)
- [Abstract / pipeline description] Abstract and pipeline description: the central claim of 12–26 pp drops on GSM8K is interpretable only if retained attacks preserve the reasoning program and produce error-free gold answers. No quantitative audit statistics (fraction filtered, failure modes, inter-rater protocol, or examples of rejected cases) are reported, leaving open the possibility that residual edit errors or introduced ambiguities drive the observed drops.
- [Evaluation / results] Evaluation section: the reported conditional accuracy drops lack error bars, details on the number of attacks retained per model/dataset after the high-confidence audit, and a baseline comparison against random numeric perturbations that do not preserve reasoning. These omissions make it difficult to assess whether the drops exceed what would be expected from any numeric change.
minor comments (1)
- [Abstract] The abstract states 'completed runs' without clarifying how many problems were ultimately evaluated after filtering; this should be stated explicitly with counts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where additional transparency would strengthen the paper. We address both major comments below and will incorporate the suggested additions in the revision.
read point-by-point responses
-
Referee: [Abstract / pipeline description] Abstract and pipeline description: the central claim of 12–26 pp drops on GSM8K is interpretable only if retained attacks preserve the reasoning program and produce error-free gold answers. No quantitative audit statistics (fraction filtered, failure modes, inter-rater protocol, or examples of rejected cases) are reported, leaving open the possibility that residual edit errors or introduced ambiguities drive the observed drops.
Authors: We agree that quantitative audit statistics are necessary for full interpretability of the results. In the revised manuscript we will add a new subsection (or appendix table) reporting: (i) the fraction of candidates filtered at each stage of the pipeline, (ii) the main failure modes observed during validation, (iii) the inter-rater protocol and agreement rate used in the high-confidence audit, and (iv) representative examples of rejected attacks. These additions will directly address the concern that residual errors might explain the accuracy drops. revision: yes
-
Referee: [Evaluation / results] Evaluation section: the reported conditional accuracy drops lack error bars, details on the number of attacks retained per model/dataset after the high-confidence audit, and a baseline comparison against random numeric perturbations that do not preserve reasoning. These omissions make it difficult to assess whether the drops exceed what would be expected from any numeric change.
Authors: We will add bootstrap-derived error bars on all reported accuracy figures and explicitly state the number of retained attacks per model–dataset combination after the audit. We will also include a new baseline experiment using random numeric perturbations (subject to the same magnitude and non-zero constraints) that do not preserve the reasoning program. This comparison will allow readers to evaluate whether the observed drops exceed those attributable to unstructured numeric variation. revision: yes
Circularity Check
No circularity: purely empirical attack generation and evaluation on external benchmarks
full rationale
The paper describes an algorithmic pipeline for generating numeric-remapping attacks on arithmetic word problems and reports measured accuracy drops on fixed datasets (GSM8K, MAWPS, MultiArith) for specific LLMs. No mathematical derivations, equations, fitted parameters, or predictions appear. Central claims rest on empirical results from model outputs rather than any self-referential reduction, self-citation chain, or ansatz. The work is self-contained against external benchmarks with no load-bearing steps that reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
TrustLLM: Trustworthiness in Large Language Models
L. Sun, Y. Huang, H. Wang, S. Wu, et al. “TrustLLM: Trustworthiness in Large Language Models”. In:ArXivabs/2401.05561 (2024).url:https : / / api . semanticscholar . org / CorpusID:266933236. 22
Pith/arXiv arXiv 2024
-
[2]
Same Meaning, Different Scores: Lexical and Syntactic Sensitivity in LLM Evaluation
B. Kosti’c, C. Fallon, J. Risch, and A. Loser. “Same Meaning, Different Scores: Lexical and Syntactic Sensitivity in LLM Evaluation”. In:ArXivabs/2602.17316 (2026).url:https : //api.semanticscholar.org/CorpusID:285787510
arXiv 2026
-
[3]
On the Adversarial Robustness of Instruction-Tuned Large Lan- guage Models for Code
M. I. Hossen and X. S. Hei. “On the Adversarial Robustness of Instruction-Tuned Large Lan- guage Models for Code”. In:ArXivabs/2411.19508 (2024).url:https://api.semanticscholar. org/CorpusID:274422941
arXiv 2024
-
[4]
A Hierarchical Language Model For Interpretable Graph Reasoning
S. Khurana, X. Li, S. Gui, and S. Ji. “A Hierarchical Language Model For Interpretable Graph Reasoning”. In:ArXivabs/2410.22372 (2024).url:https://api.semanticscholar.org/ CorpusID:273695352
arXiv 2024
-
[5]
Y. Tian, R. Huang, X. Wang, J. Ma, et al. “EvolProver: Advancing Automated Theorem Prov- ing by Evolving Formalized Problems via Symmetry and Difficulty”. In:ArXivabs/2510.00732 (2025).url:https://api.semanticscholar.org/CorpusID:281706210
arXiv 2025
-
[6]
Forget What You Know about LLMs Evaluations - LLMs are Like a Chameleon
N. Cohen-Inger, Y. Elisha, B. Shapira, L. Rokach, et al. “Forget What You Know about LLMs Evaluations - LLMs are Like a Chameleon”. In:Conference on Empirical Methods in Natural Language Processing. 2025.url:https://api.semanticscholar.org/CorpusID:276259405
2025
-
[7]
On Robustness and Reliability of Benchmark-Based Evaluation of LLMs
R. Lunardi, V. D. Mea, S. Mizzaro, and K. Roitero. “On Robustness and Reliability of Benchmark-Based Evaluation of LLMs”. In:European Conference on Artificial Intelligence. 2025.url:https://api.semanticscholar.org/CorpusID:281103089
2025
-
[8]
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
I. Mirzadeh, K. Alizadeh-Vahid, H. Shahrokhi, O. Tuzel, et al. “GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models”. In:ArXivabs/2410.05229 (2024).url:https://api.semanticscholar.org/CorpusID:273186279
Pith/arXiv arXiv 2024
-
[9]
Q. Li, L. Cui, X. Zhao, L. Kong, et al.GSM-Plus: A Comprehensive Benchmark for Evaluating the Robustness of LLMs as Mathematical Problem Solvers. 2024. arXiv:2402.19255 [cs.CL]. url:https://arxiv.org/abs/2402.19255
arXiv 2024
-
[10]
Evaluating Robustness of LLMs to Numerical Varia- tions in Mathematical Reasoning
Y. Yang, H. Yamada, and T. Tokunaga. “Evaluating Robustness of LLMs to Numerical Varia- tions in Mathematical Reasoning”. In:The Sixth Workshop on Insights from Negative Results in NLP. Ed. by A. Drozd, J. Sedoc, S. Tafreshi, A. Akula, et al. Albuquerque, New Mexico: As- sociation for Computational Linguistics, May 2025, pp. 171–180.isbn: 979-8-89176-240-...
- [11]
-
[12]
Training verifiers to solve math word problems
K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, et al. “Training verifiers to solve math word problems”. In:arXiv preprint arXiv:2110.14168(2021)
Pith/arXiv arXiv 2021
-
[13]
Are NLP Models really able to Solve Simple Math Word Problems?
A. Patel, S. Bhattamishra, and N. Goyal. “Are NLP Models really able to Solve Simple Math Word Problems?” In:North American Chapter of the Association for Computational Linguis- tics. 2021.url:https://api.semanticscholar.org/CorpusID:232223322
2021
-
[14]
Learning to Solve Arithmetic Word Problems with Verb Categorization
M. J. Hosseini, H. Hajishirzi, O. Etzioni, and N. Kushman. “Learning to Solve Arithmetic Word Problems with Verb Categorization”. In:Conference on Empirical Methods in Natural Language Processing. 2014.url:https://api.semanticscholar.org/CorpusID:428579
2014
-
[15]
Solving General Arithmetic Word Problems
S. Roy and D. Roth. “Solving General Arithmetic Word Problems”. In:ArXivabs/1608.01413 (2016).url:https://api.semanticscholar.org/CorpusID:560565
Pith/arXiv arXiv 2016
-
[16]
A Diverse Corpus for Evaluating and Developing En- glish Math Word Problem Solvers
S.-Y. Miao, C.-C. Liang, and K.-Y. Su. “A Diverse Corpus for Evaluating and Developing En- glish Math Word Problem Solvers”. In:Annual Meeting of the Association for Computational Linguistics. 2020.url:https://api.semanticscholar.org/CorpusID:220047831. 23
2020
-
[17]
Program Induction by Rationale Gener- ation: Learning to Solve and Explain Algebraic Word Problems
W. Ling, D. Yogatama, C. Dyer, and P. Blunsom. “Program Induction by Rationale Gener- ation: Learning to Solve and Explain Algebraic Word Problems”. In:Annual Meeting of the Association for Computational Linguistics. 2017.url:https://api.semanticscholar.org/ CorpusID:12777818
2017
-
[18]
Parsing Algebraic Word Problems into Equations
R. Koncel-Kedziorski, H. Hajishirzi, A. Sabharwal, O. Etzioni, et al. “Parsing Algebraic Word Problems into Equations”. In:Transactions of the Association for Computational Linguistics 3 (2015), pp. 585–597.url:https://api.semanticscholar.org/CorpusID:4894130
2015
-
[19]
Dynamic Prompt Learning via Policy Gradient for Semi-structured Mathematical Reasoning
P. Lu, L. Qiu, K.-W. Chang, Y. N. Wu, et al. “Dynamic Prompt Learning via Policy Gradient for Semi-structured Mathematical Reasoning”. In:ArXivabs/2209.14610 (2022).url:https: //api.semanticscholar.org/CorpusID:252595921
arXiv 2022
-
[20]
Measuring Mathematical Problem Solving With the MATH Dataset
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, et al. “Measuring Mathematical Problem Solving With the MATH Dataset”. In:ArXivabs/2103.03874 (2021).url:https://api. semanticscholar.org/CorpusID:232134851
Pith/arXiv arXiv 2021
-
[21]
OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems
C. He, R. Luo, Y. Bai, S. Hu, et al. “OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems”. In:Annual Meeting of the Association for Computational Linguistics. 2024.url:https://api.semanticscholar. org/CorpusID:267770504
2024
-
[22]
PertEval: Unveiling Real Knowledge Capacity of LLMs with Knowledge-Invariant Perturbations
J. Li, R. Hu, K. Huang, Z. Yan, et al. “PertEval: Unveiling Real Knowledge Capacity of LLMs with Knowledge-Invariant Perturbations”. In:ArXivabs/2405.19740 (2024).url:https : //api.semanticscholar.org/CorpusID:270123642
arXiv 2024
-
[23]
Chain-of-Code Collapse: Reasoning Failures in LLMs via Adversarial Prompting in Code Generation
J. Roh, V. Gandhi, S. Anilkumar, and A. Garg. “Chain-of-Code Collapse: Reasoning Failures in LLMs via Adversarial Prompting in Code Generation”. In:ArXivabs/2506.06971 (2025). url:https://api.semanticscholar.org/CorpusID:279251869
arXiv 2025
-
[24]
When Benchmarks are Targets: Revealing the Sensitivity of Large Language Model Leaderboards
N. A. Alzahrani, H. A. Alyahya, S. Y. Alnumay, S. Z. Alsubaie, et al. “When Benchmarks are Targets: Revealing the Sensitivity of Large Language Model Leaderboards”. In:Annual Meet- ing of the Association for Computational Linguistics. 2024.url:https://api.semanticscholar. org/CorpusID:267412932
2024
-
[25]
Robustness in Large Language Models: A Survey of Mitigation Strategies and Evaluation Metrics
P. Kumar and S. Mishra. “Robustness in Large Language Models: A Survey of Mitigation Strategies and Evaluation Metrics”. In:Trans. Mach. Learn. Res.2025 (2025).url:https: //api.semanticscholar.org/CorpusID:278905678
2025
-
[26]
Using Natural Language Explana- tions to Improve Robustness of In-context Learning for Natural Language Inference
X. He, Y. Wu, O.-M. Camburu, P. Minervini, et al. “Using Natural Language Explana- tions to Improve Robustness of In-context Learning for Natural Language Inference”. In: Annual Meeting of the Association for Computational Linguistics. 2023.url:https://api. semanticscholar.org/CorpusID:265150621
2023
-
[27]
Revisiting Out-of-distribution Robustness in NLP: Benchmark, Analysis, and LLMs Evaluations
L. Yuan, Y. Chen, G. Cui, H. Gao, et al. “Revisiting Out-of-distribution Robustness in NLP: Benchmark, Analysis, and LLMs Evaluations”. In:ArXivabs/2306.04618 (2023).url:https: //api.semanticscholar.org/CorpusID:259096157
arXiv 2023
-
[28]
Standard Benchmarks Fail – Auditing LLM Agents in Finance Must Prioritize Risk
Z. Chen, J. Chen, J. Chen, and M. Sra. “Standard Benchmarks Fail – Auditing LLM Agents in Finance Must Prioritize Risk”. In: 2025.url:https : / / api . semanticscholar . org / CorpusID:276575244
2025
-
[29]
From Calibration to Col- laboration: LLM Uncertainty Quantification Should Be More Human-Centered
S. Devic, T. Srinivasan, J. Thomason, W. Neiswanger, et al. “From Calibration to Col- laboration: LLM Uncertainty Quantification Should Be More Human-Centered”. In:ArXiv abs/2506.07461 (2025).url:https://api.semanticscholar.org/CorpusID:279251692
arXiv 2025
-
[30]
Adversarial GLUE: A Multi-Task Benchmark for Robustness Evaluation of Language Models
B. Wang, C. Xu, S. Wang, Z. Gan, et al. “Adversarial GLUE: A Multi-Task Benchmark for Robustness Evaluation of Language Models”. In:CoRRabs/2111.02840 (2021). arXiv: 2111.02840.url:https://arxiv.org/abs/2111.02840. 24
arXiv 2021
-
[31]
Chain of Thought Prompting Elicits Reasoning in Large Language Models
J. Wei, X. Wang, D. Schuurmans, M. Bosma, et al. “Chain of Thought Prompting Elicits Reasoning in Large Language Models”. In:CoRRabs/2201.11903 (2022). arXiv:2201.11903. url:https://arxiv.org/abs/2201.11903
Pith/arXiv arXiv 2022
-
[32]
T. Kojima, S. S. Gu, M. Reid, Y. Matsuo, et al.Large Language Models are Zero-Shot Rea- soners. 2023. arXiv:2205.11916 [cs.CL].url:https://arxiv.org/abs/2205.11916
Pith/arXiv arXiv 2023
-
[33]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
X. Wang, J. Wei, D. Schuurmans, Q. Le, et al. “Self-Consistency Improves Chain of Thought Reasoning in Language Models”. In:ArXivabs/2203.11171 (2022).url:https : / / api . semanticscholar.org/CorpusID:247595263
Pith/arXiv arXiv 2022
-
[34]
D. Zhou, N. Sch¨ arli, L. Hou, J. Wei, et al.Least-to-Most Prompting Enables Complex Reasoning in Large Language Models. 2023. arXiv:2205.10625 [cs.AI].url:https://arxiv.org/ abs/2205.10625
Pith/arXiv arXiv 2023
-
[35]
S. Yao, D. Yu, J. Zhao, I. Shafran, et al.Tree of Thoughts: Deliberate Problem Solving with Large Language Models. 2023. arXiv:2305.10601 [cs.CL].url:https://arxiv.org/abs/ 2305.10601
Pith/arXiv arXiv 2023
-
[36]
Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Oksana Yakhnenko
M. Besta, N. Blach, A. Kubicek, R. Gerstenberger, et al. “Graph of Thoughts: Solving Elab- orate Problems with Large Language Models”. In:Proceedings of the AAAI Conference on Artificial Intelligence38.16 (Mar. 2024), pp. 17682–17690.issn: 2159-5399.doi:10.1609/ aaai.v38i16.29720.url:http://dx.doi.org/10.1609/aaai.v38i16.29720
-
[37]
L. Gao, A. Madaan, S. Zhou, U. Alon, et al.PAL: Program-aided Language Models. 2023. arXiv:2211.10435 [cs.CL].url:https://arxiv.org/abs/2211.10435
Pith/arXiv arXiv 2023
-
[38]
W. Chen, X. Ma, X. Wang, and W. W. Cohen.Program of Thoughts Prompting: Disentan- gling Computation from Reasoning for Numerical Reasoning Tasks. 2023. arXiv:2211.12588 [cs.CL].url:https://arxiv.org/abs/2211.12588
Pith/arXiv arXiv 2023
-
[39]
S. Yao, J. Zhao, D. Yu, N. Du, et al.ReAct: Synergizing Reasoning and Acting in Language Models. 2023. arXiv:2210.03629 [cs.CL].url:https://arxiv.org/abs/2210.03629
Pith/arXiv arXiv 2023
-
[40]
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, et al.Self-Refine: Iterative Refinement with Self-Feedback. 2023. arXiv:2303.17651 [cs.CL].url:https://arxiv.org/abs/2303.17651
Pith/arXiv arXiv 2023
-
[41]
N. Shinn, F. Cassano, E. Berman, A. Gopinath, et al.Reflexion: Language Agents with Verbal Reinforcement Learning. 2023. arXiv:2303.11366 [cs.AI].url:https://arxiv.org/abs/ 2303.11366. 11 Appendix A Additional Numeric-Remapping Examples Table 7 provides additional examples of valid numeric-remapping attacks. Each attacked problem changes the concrete quan...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.