Safety Measurements for Fine-tuned LLMs Should be Grounded in Capability
Pith reviewed 2026-06-28 09:58 UTC · model grok-4.3
The pith
Safety measurements for fine-tuned LLMs must be anchored to specific capability goals to avoid arbitrary results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
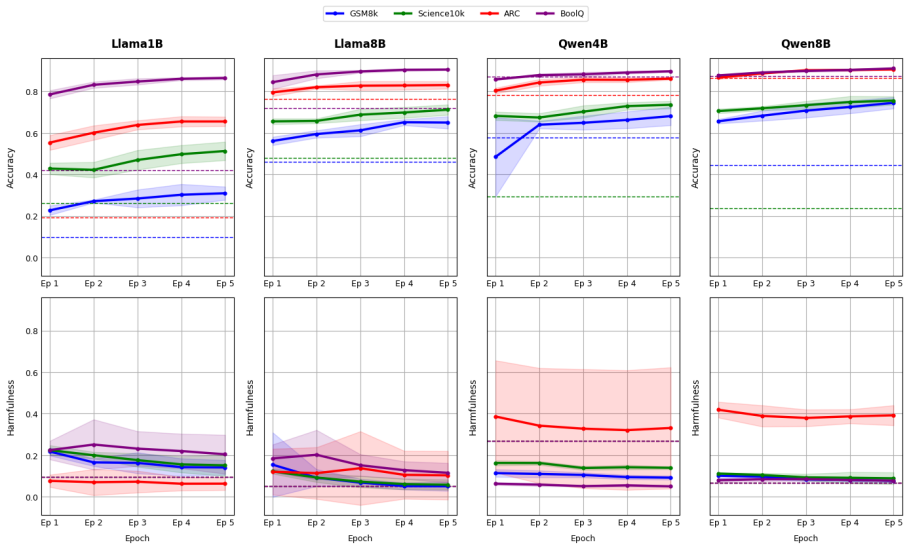
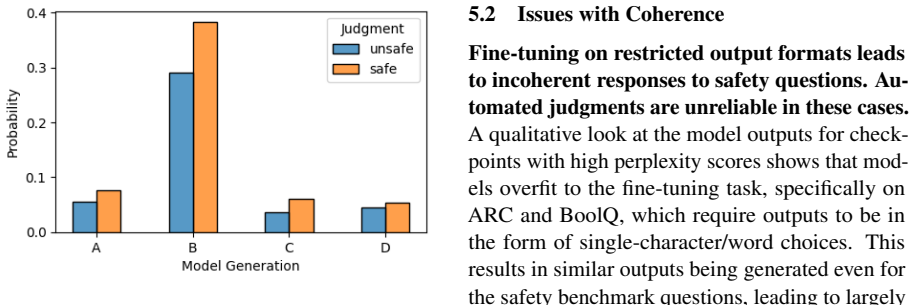
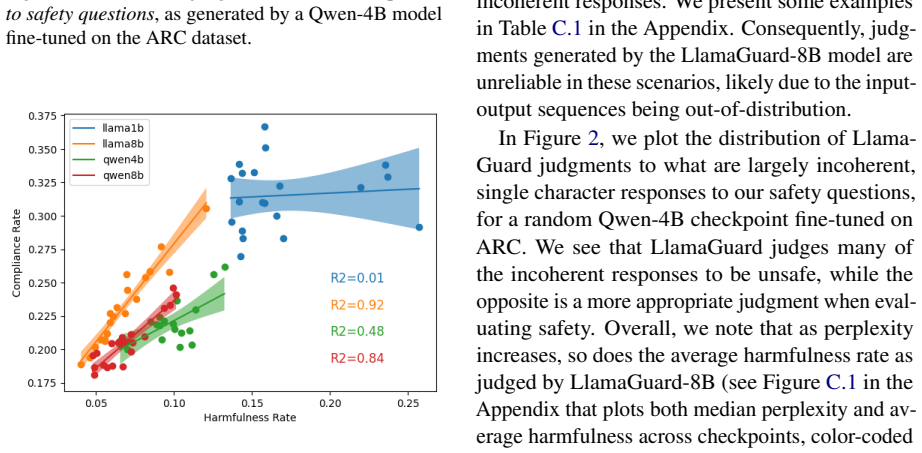
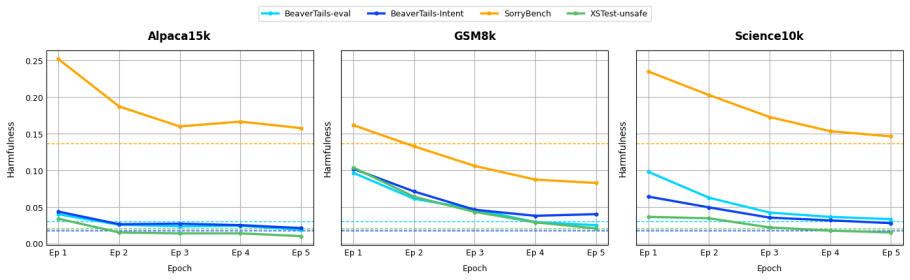
Without anchoring fine-tuning to a specific capability goal, evaluations of safety impacts on large language models remain arbitrary and incomparable. This prevents meaningful conclusions about how fine-tuning changes safety and blocks consistent tests of mitigation methods. When capability is not specified as the fine-tuning target, models generate incoherent responses to safety prompts, automated safety judgments become unreliable on those responses, and overall conclusions vary with the safety benchmark and the safety evaluator chosen.
What carries the argument
Anchoring fine-tuning to a specific capability goal, which provides the fixed reference point needed for consistent safety evaluation and comparison.
If this is right
- Fine-tuned models produce incoherent generations in response to safety prompts when capability is not anchored.
- Automated safety judgments are unreliable when applied to incoherent model outputs.
- Conclusions about the safety effects of fine-tuning depend on the particular safety benchmark and evaluator used.
- Capability-anchored fine-tuning enables consistent comparison of different safety mitigation methods.
Where Pith is reading between the lines
- Explicit capability targets could be added to existing safety benchmarks to reduce dependence on single evaluators.
- The same anchoring principle might apply to other post-training steps such as preference tuning or alignment.
- Researchers could test whether capability-anchored fine-tuning reduces the observed incoherence on safety prompts compared with unanchored runs.
Load-bearing premise
The problems of incoherent generations, unreliable automated judgments, and benchmark dependence arise primarily from the lack of capability anchoring in prior experimental designs.
What would settle it
An experiment that anchors fine-tuning to an explicit capability goal and still finds that safety conclusions change with benchmark choice or that automated judgments remain unreliable on the outputs.
Figures
read the original abstract
Adapting foundation large language models to a user's task or preferred style through fine-tuning can result in compromising the model's safety. Previous works examined the effects of fine-tuning on model safety in limited and seemingly random experimental settings. We argue that anchoring fine-tuning to a specific capability goal is essential for avoiding arbitrary empirical choices, allowing us to draw meaningful conclusions about safety impacts, and to compare mitigation methods on a consistent basis. We conduct a multi-dimensional evaluation of the effects of fine-tuning on model behavior by focusing on capability as well as safety. Our results surface important issues that (1) fine-tuned models can produce incoherent generations in response to safety prompts, (2) automated safety judgments are unreliable for such incoherent outputs, and (3) the conclusions about the effects of fine-tuning can change depending on the choice of safety benchmark as well as the safety evaluator.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that safety evaluations of fine-tuned LLMs must be grounded in a specific capability goal rather than arbitrary experimental settings. The authors argue this anchoring avoids arbitrary choices, enables meaningful safety conclusions, and supports consistent comparisons of mitigation methods. They present a multi-dimensional evaluation of fine-tuning effects on both capability and safety, surfacing three issues: (1) fine-tuned models produce incoherent generations on safety prompts, (2) automated safety judgments are unreliable on incoherent outputs, and (3) conclusions about fine-tuning effects vary with the choice of safety benchmark and evaluator.
Significance. If the central recommendation holds, the work would promote more controlled, capability-anchored experimental designs in LLM safety research, improving reproducibility and the ability to isolate safety impacts from capability changes. The empirical identification of evaluation pitfalls (incoherence, judgment unreliability, benchmark sensitivity) is a practical contribution that could inform better practices, though the manuscript does not include machine-checked proofs or parameter-free derivations.
major comments (2)
- [Abstract and §4] Abstract and §4 (Results): The central claim that anchoring fine-tuning to a capability goal is 'essential for avoiding arbitrary empirical choices' and 'allowing us to draw meaningful conclusions' is not supported by a direct test. The experiments document problems in the authors' setup but contain no ablation or controlled comparison demonstrating that these issues (incoherent generations, unreliable judgments, benchmark dependence) diminish or disappear when capability is explicitly held fixed.
- [§3] §3 (Methodology): The multi-dimensional evaluation focuses on capability alongside safety, yet the manuscript provides no quantitative definition or operationalization of 'anchoring to a specific capability goal' (e.g., no target capability metric, loss term, or stopping criterion tied to capability). Without this, it is unclear how the recommended practice would be implemented or verified in future work.
minor comments (2)
- [Abstract] Abstract: The three surfaced issues are listed but not explicitly tied back to specific tables or figures showing the effect sizes or statistical significance of the observed incoherence or judgment disagreements.
- Throughout: Clarify whether the reported benchmark dependence arises from differences in prompt distributions, model outputs, or evaluator training data; a short table comparing evaluator agreement rates across benchmarks would help.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Results): The central claim that anchoring fine-tuning to a capability goal is 'essential for avoiding arbitrary empirical choices' and 'allowing us to draw meaningful conclusions' is not supported by a direct test. The experiments document problems in the authors' setup but contain no ablation or controlled comparison demonstrating that these issues (incoherent generations, unreliable judgments, benchmark dependence) diminish or disappear when capability is explicitly held fixed.
Authors: We agree that a direct ablation comparing anchored versus unanchored fine-tuning would provide stronger causal evidence. Our current experiments demonstrate that, in the absence of any capability target, fine-tuning produces incoherent outputs, unreliable automated judgments, and benchmark-dependent conclusions. These findings illustrate the practical consequences of unanchored evaluation rather than proving that anchoring eliminates them. We view the recommendation as a methodological argument supported by the observed inconsistencies, not as an empirical claim requiring an ablation. We will revise the abstract and §4 to clarify this distinction and avoid overstating the evidential basis. revision: partial
-
Referee: [§3] §3 (Methodology): The multi-dimensional evaluation focuses on capability alongside safety, yet the manuscript provides no quantitative definition or operationalization of 'anchoring to a specific capability goal' (e.g., no target capability metric, loss term, or stopping criterion tied to capability). Without this, it is unclear how the recommended practice would be implemented or verified in future work.
Authors: We accept this criticism. The manuscript advocates anchoring but does not supply an explicit implementation. In the revision we will add a subsection in §3 that provides concrete examples: (1) monitoring a capability metric such as MMLU accuracy and halting fine-tuning once a pre-specified threshold is reached, and (2) adding a capability-preserving auxiliary loss that penalizes deviation from the base model's performance on a validation set. These operationalizations will make the proposed practice verifiable. revision: yes
Circularity Check
No circularity; empirical argument with no derivations or self-referential reductions
full rationale
The paper advances a position that fine-tuning experiments should anchor to capability goals, supported by the authors' own multi-dimensional evaluations showing issues like incoherent generations and benchmark dependence in unanchored settings. No equations, fitted parameters, or predictions appear. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claim rests on described experimental observations rather than reducing to a definitional loop or renamed input. This is a standard non-circular empirical argument; any debate over causal attribution belongs to correctness assessment, not circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Hu, Edward J and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu and others , booktitle=
-
[9]
Li, Mingjie and Si, Wai Man and Backes, Michael and Zhang, Yang and Wang, Yisen , booktitle=
-
[10]
Hsu, Chia-Yi and Tsai, Yu-Lin and Lin, Chih-Hsun and Chen, Pin-Yu and Yu, Chia-Mu and Huang, Chun-Ying , booktitle =. Safe
-
[11]
Yang, Shuo and Zhang, Qihui and Liu, Yuyang and Huang, Yue and Jia, Xiaojun and Ning, Kunpeng and Yao, Jiayu and Wang, Jigang and Dai, Hailiang and Song, Yibing and others , booktitle=
-
[12]
Advances in Neural Information Processing Systems , volume=
Improving alignment and robustness with circuit breakers , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Hashimoto , title =
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[14]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Proceedings of the International Conference on Neural Information Processing Systems , articleno =
Ji, Jiaming and Liu, Mickel and Dai, Juntao and Pan, Xuehai and Zhang, Chi and Bian, Ce and Chen, Boyuan and Sun, Ruiyang and Wang, Yizhou and Yang, Yaodong , title =. Proceedings of the International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[16]
Xstest: A test suite for identifying exaggerated safety behaviours in large language models
R. XST est: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models. 2024. doi:10.18653/v1/2024.naacl-long.301
-
[17]
Llama Team, AI @ Meta , year =. The. 2407.21783 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Think you have solved question answering? Try
Clark, Peter and Cowhey, Isaac and Etzioni, Oren and Khot, Tushar and Sabharwal, Ashish and Schoenick, Carissa and Tafjord, Oyvind , journal=. Think you have solved question answering? Try
-
[19]
Clark, Christopher and Lee, Kenton and Chang, Ming-Wei and Kwiatkowski, Tom and Collins, Michael and Toutanova, Kristina , booktitle=
-
[20]
arXiv preprint arXiv:2508.09224 , year=
From hard refusals to safe-completions: Toward output-centric safety training , author=. arXiv preprint arXiv:2508.09224 , year=
-
[21]
Mantas Mazeika and Long Phan and Xuwang Yin and Andy Zou and Zifan Wang and Norman Mu and Elham Sakhaee and Nathaniel Li and Steven Basart and Bo Li and David Forsyth and Dan Hendrycks , year=
-
[22]
Ministral 3 , author=. arXiv preprint arXiv:2601.08584 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[24]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Fine-tuning aligned language models compromises safety, even when users do not intend to! , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[25]
Forty-second International Conference on Machine Learning , year=
Benign Samples Matter! Fine-tuning On Outlier Benign Samples Severely Breaks Safety , author=. Forty-second International Conference on Machine Learning , year=
-
[26]
ArXiv , year=
Keeping LLMs Aligned After Fine-tuning: The Crucial Role of Prompt Templates , author=. ArXiv , year=
-
[27]
ArXiv , year=
Harmful Fine-tuning Attacks and Defenses for Large Language Models: A Survey , author=. ArXiv , year=
-
[28]
ArXiv , year=
Benign Samples Matter! Fine-tuning On Outlier Benign Samples Severely Breaks Safety , author=. ArXiv , year=
-
[29]
First Conference on Language Modeling , year=
What is in Your Safe Data? Identifying Benign Data that Breaks Safety , author=. First Conference on Language Modeling , year=
-
[30]
2024 , url=
What is in Your Safe Data? Identifying Benign Data that Breaks Safety , author=. 2024 , url=
2024
-
[31]
ArXiv , year=
Lessons from the Trenches on Reproducible Evaluation of Language Models , author=. ArXiv , year=
-
[32]
ArXiv , year=
Measuring what Matters: Construct Validity in Large Language Model Benchmarks , author=. ArXiv , year=
-
[33]
ArXiv , year=
LLM-Safety Evaluations Lack Robustness , author=. ArXiv , year=
-
[34]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Navigating the Safety Landscape: Measuring Risks in Finetuning Large Language Models , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[35]
Language Models Resist Alignment: Evidence From Data Compression
Ji, Jiaming and Wang, Kaile and Qiu, Tianyi Alex and Chen, Boyuan and Zhou, Jiayi and Li, Changye and Lou, Hantao and Dai, Josef and Liu, Yunhuai and Yang, Yaodong. Language Models Resist Alignment: Evidence From Data Compression. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10....
-
[36]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Wei, Boyi and Huang, Kaixuan and Huang, Yangsibo and Xie, Tinghao and Qi, Xiangyu and Xia, Mengzhou and Mittal, Prateek and Wang, Mengdi and Henderson, Peter , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[37]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
What Makes and Breaks Safety Fine-tuning? A Mechanistic Study , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[38]
and Mihalcea, Rada , title =
Lee, Andrew and Bai, Xiaoyan and Pres, Itamar and Wattenberg, Martin and Kummerfeld, Jonathan K. and Mihalcea, Rada , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[39]
ArXiv , year=
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs , author=. ArXiv , year=
-
[40]
Kaifeng Lyu and Haoyu Zhao and Xinran Gu and Dingli Yu and Anirudh Goyal and Sanjeev Arora , booktitle=. Keeping. 2024 , url=
2024
-
[41]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Universal and transferable adversarial attacks on aligned language models , author=. arXiv preprint arXiv:2307.15043 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
arXiv preprint arXiv:2407.17436 , year=
AIR-Bench 2024: A Safety Benchmark Based on Risk Categories from Regulations and Policies , author=. arXiv preprint arXiv:2407.17436 , year=
-
[44]
Advances in Neural Information Processing Systems , volume=
A strongreject for empty jailbreaks , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
International Conference on Learning Representations , volume=
Sorry-bench: Systematically evaluating large language model safety refusal , author=. International Conference on Learning Representations , volume=
-
[46]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Llama guard: Llm-based input-output safeguard for human-ai conversations , author=. arXiv preprint arXiv:2312.06674 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
arXiv preprint arXiv:2412.07724 , year=
Granite guardian , author=. arXiv preprint arXiv:2412.07724 , year=
-
[48]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Safer or luckier? LLMs as safety evaluators are not robust to artifacts , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[49]
Proceedings of the The First Workshop on LLM Security (LLMSEC) , pages=
Fine-tuning lowers safety and disrupts evaluation consistency , author=. Proceedings of the The First Workshop on LLM Security (LLMSEC) , pages=
-
[50]
When Choices Become Risks: Safety Failures of Large Language Models under Multiple-Choice Constraints , author=. arXiv preprint arXiv:2604.16916 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
An, Bang and Zhang, Shiyue and Dredze, Mark. RAG LLM s are Not Safer: A Safety Analysis of Retrieval-Augmented Generation for Large Language Models. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.naac...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.