From Answers to States: Verifiable Process-Level Evaluation of Chemical Reasoning in Large Language Models
Pith reviewed 2026-06-28 09:39 UTC · model grok-4.3
The pith
Large language models often output correct chemistry answers while their reasoning steps violate chemical logic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
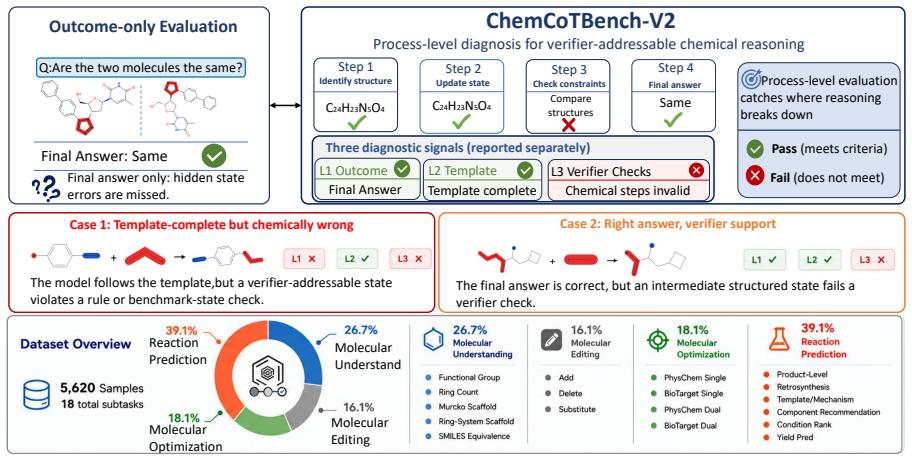
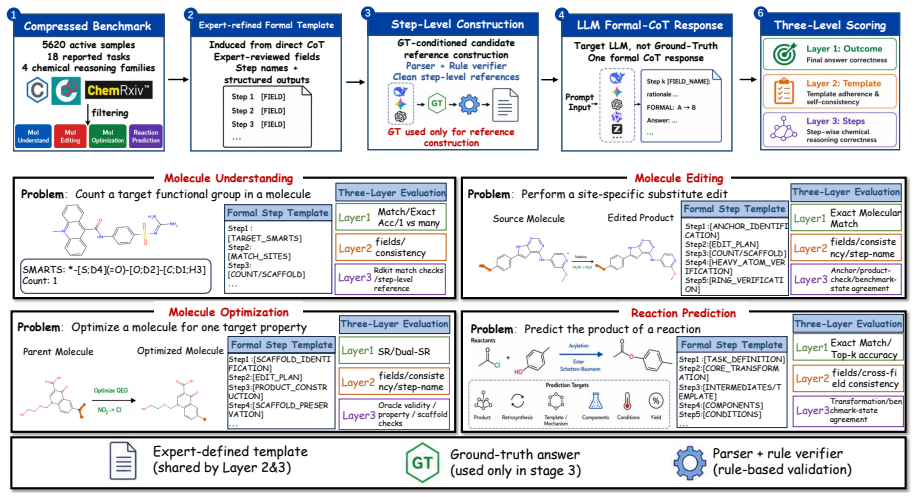
ChemCoTBench-V2 requires models to expose key intermediate steps in expert-designed templates for molecular understanding, editing, optimization, and reaction prediction tasks. These steps are checked with deterministic chemistry rules and reference traces. Experiments on frontier models show a persistent gap between final-answer success and structured-reasoning-state consistency, with models often following format while failing chemical checks or answering correctly with weak reasoning.
What carries the argument
ChemCoTBench-V2 benchmark that uses rule-verifiable templates and deterministic chemistry rules to audit intermediate reasoning states instead of relying on LLM judges.
If this is right
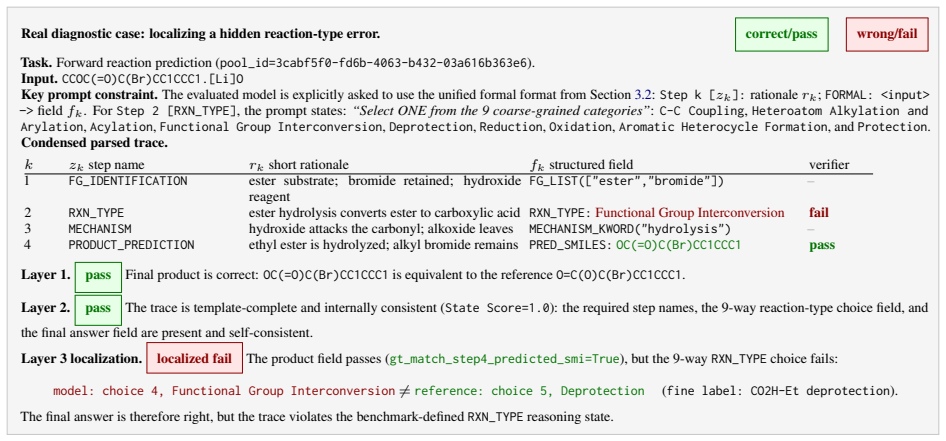
- The benchmark enables identification of the exact step where a reasoning trace violates chemical logic.
- Evaluation of LLMs becomes scalable and consistent without costly human annotation or inconsistent LLM judges.
- Three separate signals are reported: final-answer correctness, template adherence, and step-wise verifier correctness.
- Open-ended molecular optimization is assessed with oracle-verifiable state constraints.
Where Pith is reading between the lines
- This approach could be extended to create similar rule-based verifiers for reasoning in other domains like physics or mathematics.
- Training LLMs with rewards based on step-wise verifier scores might improve chemical reasoning beyond just answer accuracy.
- The identified gap suggests current models may produce unreliable outputs in real-world chemical design workflows where step validity is crucial.
Load-bearing premise
The expert-designed templates and deterministic chemistry rules used for verification accurately capture valid chemical reasoning processes without bias, false positives, or omission of alternative valid reasoning paths.
What would settle it
Finding that step-wise verifier correctness rates closely match final-answer success rates across multiple frontier models would falsify the claimed persistent gap.
Figures
read the original abstract
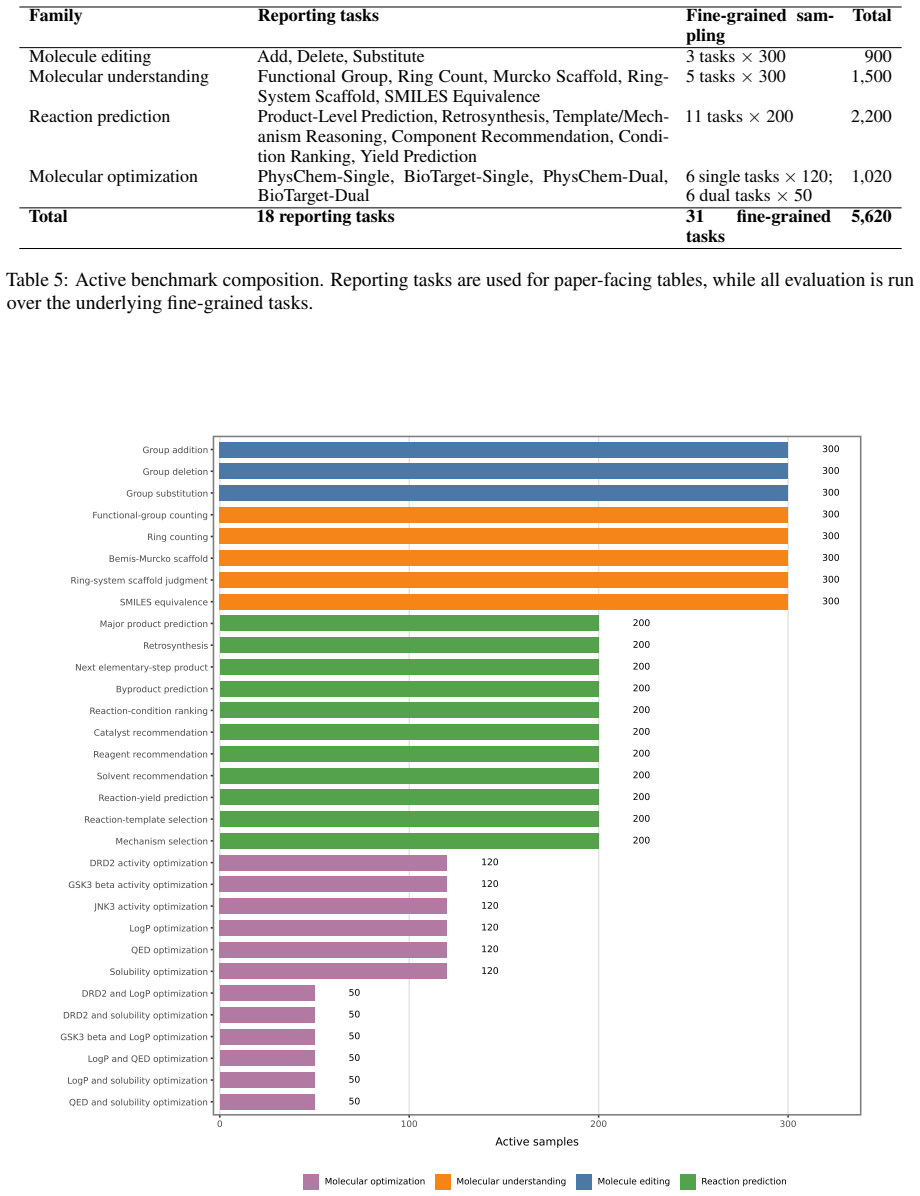
Large language models are increasingly used as chemistry assistants, yet most chemistry benchmarks still score only final answers. This masks a critical failure mode: a model may output the correct molecule, product, or option while its reasoning violates chemical logic. Existing process-level evaluators are hard to scale because LLM judges and human step-level process annotation are costly, inconsistent, and vulnerable to hallucination. We introduce ChemCoTBench-V2, a rule-verifiable diagnostic benchmark for low-cost, auditable evaluation of structured, verifier-addressable chemical reasoning traces. It spans molecular understanding, molecule editing, molecular optimization, and reaction prediction, with 5,620 evaluation samples across 18 reporting tasks. Models must expose key intermediate steps in expert-designed templates, and those steps are checked with deterministic chemistry rules and, for closed-answer tasks, reference traces rather than another LLM judge. Open-ended molecular optimization is evaluated with oracle-verifiable state constraints rather than strict trace matching. The benchmark reports three separate signals: final-answer correctness, template adherence, and step-wise verifier correctness over expert-refined intermediate commitments. Experiments on frontier models reveal a persistent gap between final-answer success and structured-reasoning-state consistency: models often follow the requested format while failing chemical-step checks, or answer correctly with weak supporting reasoning. ChemCoTBench-V2 enables fine-grained model comparison and identifies the concrete step at which the trace first violates the verifier.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ChemCoTBench-V2, a benchmark spanning molecular understanding, editing, optimization, and reaction prediction (5,620 samples across 18 tasks). Models must output structured reasoning traces in expert-designed templates; these traces are checked for template adherence and step-wise correctness using deterministic chemistry rules and reference traces (rather than LLM judges). Open-ended optimization uses oracle-verifiable state constraints. Experiments on frontier models show a persistent gap: high final-answer accuracy often co-occurs with failures on chemical-step checks or weak supporting reasoning, while format adherence does not guarantee verifier correctness. The benchmark aims to enable fine-grained, auditable diagnosis of where reasoning first violates chemical logic.
Significance. If the verifier rules and templates are faithful, the work supplies a scalable, low-cost, and auditable process-level evaluation method for chemical reasoning that avoids the inconsistencies of LLM judges. It directly quantifies the dissociation between answer correctness and reasoning-state consistency, which is a practically important failure mode for chemistry assistants. The use of external deterministic rules and reference traces (independent of the evaluated models) is a clear methodological strength that reduces circularity.
major comments (2)
- [Abstract and §3] Abstract and §3 (Benchmark Design): The central claim of a persistent gap between final-answer success and step-wise verifier correctness is load-bearing on the assumption that the expert-designed templates and deterministic chemistry rules faithfully capture valid chemical reasoning. The manuscript provides no reported inter-expert validation, coverage analysis of alternative valid reasoning paths, or measured false-positive rate of the verifier against human chemists; without this, flagged failures could reflect template mismatch rather than defective reasoning.
- [§4 and Table 2] §4 (Experiments) and Table 2 (model results): The reported gap is quantified only via aggregate signals (final-answer correctness, template adherence, step-wise verifier correctness). No per-task breakdown or statistical test is described that isolates whether the gap persists after controlling for task difficulty or template strictness; this weakens the claim that the gap is a general property of frontier models rather than an artifact of specific template choices.
minor comments (2)
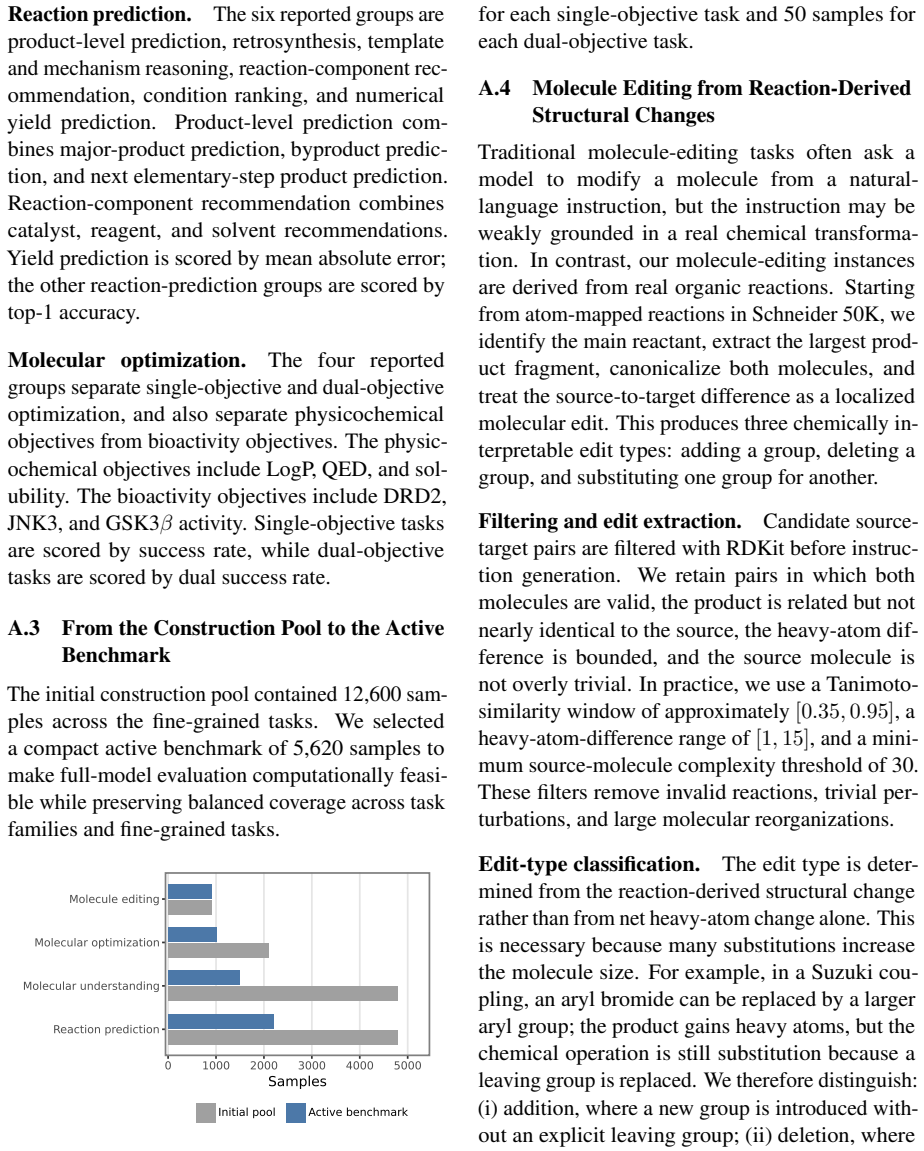
- [Abstract] The abstract states 5,620 samples but does not clarify whether this count includes only unique tasks or multiple templates per task; a clarifying sentence would aid reproducibility.
- [§3] Notation for the three reported signals (final-answer correctness, template adherence, step-wise verifier correctness) is introduced without an explicit equation or table defining how each is computed from the verifier output.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and propose revisions where the concerns identify areas for strengthening the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Benchmark Design): The central claim of a persistent gap between final-answer success and step-wise verifier correctness is load-bearing on the assumption that the expert-designed templates and deterministic chemistry rules faithfully capture valid chemical reasoning. The manuscript provides no reported inter-expert validation, coverage analysis of alternative valid reasoning paths, or measured false-positive rate of the verifier against human chemists; without this, flagged failures could reflect template mismatch rather than defective reasoning.
Authors: We acknowledge that the fidelity of our templates and rules to expert chemical reasoning is central to the benchmark's validity. The templates were designed by chemists with domain expertise and refined through iterative review to align with standard chemical logic (e.g., ensuring correct atom mapping and valence satisfaction in reaction steps). The deterministic rules implement verifiable checks such as molecular formula consistency and reaction balance, which are independent of any model. However, the original manuscript does not include a formal inter-expert validation study, coverage of alternative reasoning paths, or a quantified false-positive rate against human judgments. In the revised version, we will expand §3 to detail the template design and refinement process by experts, and add a limitations section explicitly noting the lack of quantitative human validation metrics. This will clarify the assumptions while maintaining the benchmark's focus on rule-based verifiability. revision: yes
-
Referee: [§4 and Table 2] §4 (Experiments) and Table 2 (model results): The reported gap is quantified only via aggregate signals (final-answer correctness, template adherence, step-wise verifier correctness). No per-task breakdown or statistical test is described that isolates whether the gap persists after controlling for task difficulty or template strictness; this weakens the claim that the gap is a general property of frontier models rather than an artifact of specific template choices.
Authors: The aggregate results in §4 and Table 2 demonstrate the gap across a diverse set of 18 tasks and multiple models, suggesting it is not isolated to particular cases. Nevertheless, we agree that per-task analysis and controls for difficulty would provide stronger evidence. In the revision, we will include a supplementary per-task breakdown of the three metrics and add a short discussion or statistical summary (e.g., noting consistent patterns across task categories) to address whether the gap holds after accounting for task-specific factors. This will better support the generality of the finding. revision: yes
- Providing a measured false-positive rate of the verifier against human chemists would require a new inter-expert annotation study, which we cannot complete within the scope of this revision.
Circularity Check
No circularity: evaluation rests on external deterministic rules independent of models
full rationale
The paper introduces ChemCoTBench-V2 using expert-designed templates checked by deterministic chemistry rules and reference traces (or oracle-verifiable constraints) that are fixed and external to the evaluated LLMs. The reported gap between final-answer correctness and step-wise verifier correctness is computed directly against these independent verifiers rather than any fitted parameter, self-citation chain, or self-definitional loop. No equations, ansatzes, or uniqueness theorems are invoked that reduce the central claim to the paper's own inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Expert-designed templates can elicit structured chemical reasoning from LLMs that exposes verifiable intermediate commitments.
- domain assumption Deterministic chemistry rules can be formulated and applied to verify step correctness reliably across the covered tasks.
Reference graph
Works this paper leans on
-
[1]
Nature , volume=
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author=. Nature , volume=. 2025 , doi=
2025
-
[2]
International Conference on Learning Representations , year=
Mol-Instructions: A Large-Scale Biomolecular Instruction Dataset for Large Language Models , author=. International Conference on Learning Representations , year=
-
[11]
Cao, He and Liu, Zijing and Lu, Xingyu and Yao, Yuan and Li, Yu , journal=
-
[13]
Cell Reports Physical Science , volume=
Developing ChemDFM as a large language foundation model for chemistry , author=. Cell Reports Physical Science , volume=. 2025 , publisher=
2025
-
[14]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Biot5: Enriching cross-modal integration in biology with chemical knowledge and natural language associations , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[16]
arXiv preprint arXiv:2506.17238 , year=
Training a Scientific Reasoning Model for Chemistry , author=. arXiv preprint arXiv:2506.17238 , year=
-
[19]
Journal of Chemical Information and Modeling , volume=
Do large language models understand chemistry? a conversation with chatgpt , author=. Journal of Chemical Information and Modeling , volume=. 2023 , publisher=
2023
-
[20]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Moleculeqa: A dataset to evaluate factual accuracy in molecular comprehension , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[29]
Journal of Chemical Information and Modeling , volume=
Assessing the chemical intelligence of large language models , author=. Journal of Chemical Information and Modeling , volume=. 2026 , publisher=
2026
-
[30]
Advances in Neural Information Processing Systems , volume=
Can llms solve molecule puzzles? a multimodal benchmark for molecular structure elucidation , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
Nucleic acids research , volume=
PubChem substance and compound databases , author=. Nucleic acids research , volume=. 2016 , publisher=
2016
-
[32]
Nucleic acids research , volume=
The ChEMBL database in 2017 , author=. Nucleic acids research , volume=. 2017 , publisher=
2017
-
[33]
Journal of chemical information and modeling , volume=
ZINC: a free tool to discover chemistry for biology , author=. Journal of chemical information and modeling , volume=. 2012 , publisher=
2012
-
[34]
Journal of Chemical Information and Modeling , volume=
What's What: The (Nearly) Definitive Guide to Reaction Role Assignment , author=. Journal of Chemical Information and Modeling , volume=. 2016 , publisher=
2016
-
[35]
Extraction of Chemical Structures and Reactions from the Literature , author=
-
[36]
Journal of the American Chemical Society , volume=
The Open Reaction Database , author=. Journal of the American Chemical Society , volume=. 2021 , publisher=
2021
-
[37]
Journal of the American Chemical Society , volume=
Efficient Cross-Coupling of Secondary Alkyltrifluoroborates with Aryl Chlorides---Reaction Discovery Using Parallel Microscale Experimentation , author=. Journal of the American Chemical Society , volume=. 2008 , doi=
2008
-
[38]
Science , volume=
Predicting reaction performance in C--N cross-coupling using machine learning , author=. Science , volume=. 2018 , publisher=
2018
-
[39]
Science , volume=
A platform for automated nanomole-scale reaction screening and micromole-scale synthesis in flow , author=. Science , volume=. 2018 , publisher=
2018
-
[40]
Proceedings of Neural Information Processing Systems Track on Datasets and Benchmarks , year=
Therapeutics Data Commons: Machine Learning Datasets and Tasks for Drug Discovery and Development , author=. Proceedings of Neural Information Processing Systems Track on Datasets and Benchmarks , year=
-
[41]
RDKit: Open-source cheminformatics , year=
-
[42]
Rdkit: Open-source cheminformatics
2024. Rdkit: Open-source cheminformatics. https://www.rdkit.org
2024
-
[43]
Derek T Ahneman, Jes \'u s G Estrada, Shishi Lin, Spencer D Dreher, and Abigail G Doyle. 2018. Predicting reaction performance in c--n cross-coupling using machine learning. Science, 360(6385):186--190
2018
- [44]
- [45]
-
[46]
Cayque Monteiro Castro Nascimento and Andr \'e Silva Pimentel. 2023. Do large language models understand chemistry? a conversation with chatgpt. Journal of Chemical Information and Modeling, 63(6):1649--1655
2023
-
[47]
Spencer D Dreher, Peter G Dormer, Deidre L Sandrock, and Gary A Molander. 2008. https://doi.org/10.1021/ja8031423 Efficient cross-coupling of secondary alkyltrifluoroborates with aryl chlorides---reaction discovery using parallel microscale experimentation . Journal of the American Chemical Society, 130(29):9257--9259
-
[48]
Yin Fang, Xiaozhuan Liang, Ningyu Zhang, Kangwei Liu, Rui Huang, Zhuo Chen, Xiaohui Fan, and Huajun Chen. 2024. Mol-instructions: A large-scale biomolecular instruction dataset for large language models. In International Conference on Learning Representations
2024
-
[49]
Anna Gaulton, Anne Hersey, Micha Nowotka, A Patr \' cia Bento, Jon Chambers, David Mendez, Prudence Mutowo, Francis Atkinson, Louisa J Bellis, Elena Cibri \'a n-Uhalte, Mark Davies, Nathan Dedman, Anneli Karlsson, Mar \' a Paula Magari \ n os, John P Overington, George Papadatos, Ines Smit, and Andrew R Leach. 2017. The chembl database in 2017. Nucleic ac...
2017
-
[50]
Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. 2025. Rstar-math: Small llms can master math reasoning with self-evolved deep thinking. arXiv preprint arXiv:2501.04519
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Kehan Guo, Bozhao Nan, Yujun Zhou, Taicheng Guo, Zhichun Guo, Mihir Surve, Zhenwen Liang, Nitesh V Chawla, Olaf Wiest, and Xiangliang Zhang. 2024. Can llms solve molecule puzzles? a multimodal benchmark for molecular structure elucidation. Advances in Neural Information Processing Systems, 37:134721--134746
2024
-
[52]
Kexin Huang, Tianfan Fu, Wenhao Gao, Yue Zhao, Yusuf Roohani, Jure Leskovec, Connor W Coley, Cao Xiao, Jimeng Sun, and Marinka Zitnik. 2021. Therapeutics data commons: Machine learning datasets and tasks for drug discovery and development. Proceedings of Neural Information Processing Systems Track on Datasets and Benchmarks
2021
-
[53]
Yuqing Huang, Rongyang Zhang, Xuesong He, Xuyang Zhi, Hao Wang, Xin Li, Feiyang Xu, Deguang Liu, Huadong Liang, Yi Li, Jian Cui, Zimu Liu, Shijin Wang, Guoping Hu, Guiquan Liu, Qi Liu, Defu Lian, and Enhong Chen. 2024. Chemeval: a comprehensive multi-level chemical evaluation for large language models. arXiv preprint arXiv:2409.13989
-
[54]
John J Irwin, Teague Sterling, Michael M Mysinger, Erin S Bolstad, and Ryan G Coleman. 2012. Zinc: a free tool to discover chemistry for biology. Journal of chemical information and modeling, 52(7):1757--1768
2012
- [55]
-
[56]
Steven M Kearnes, Michael R Maser, Michael Wleklinski, Anton Kast, Abigail G Doyle, Spencer D Dreher, Joel M Hawkins, Klavs F Jensen, and Connor W Coley. 2021. The open reaction database. Journal of the American Chemical Society, 143(45):18820--18826
2021
-
[57]
Sunghwan Kim, Paul A Thiessen, Evan E Bolton, Jie Chen, Gang Fu, Asta Gindulyte, Lianyi Han, Jane He, Siqian He, Benjamin A Shoemaker, Jiyao Wang, Bo Yu, Jian Zhang, and Stephen H Bryant. 2016. Pubchem substance and compound databases. Nucleic acids research, 44(D1):D1202--D1213
2016
-
[58]
Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu. 2024 a . Llms-as-judges: a comprehensive survey on llm-based evaluation methods. arXiv preprint arXiv:2412.05579
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
Hanzheng Li, Xi Fang, Yixuan Li, Chaozheng Huang, Junjie Wang, Xi Wang, Hongzhe Bai, Bojun Hao, Shenyu Lin, Huiqi Liang, Linfeng Zhang, and Guolin Ke. 2026. Rxnbench: A multimodal benchmark for evaluating large language models on chemical reaction understanding from scientific literature. arXiv preprint arXiv:2512.23565
- [60]
-
[61]
Jiatong Li, Junxian Li, Weida Wang, Yunqing Liu, Changmeng Zheng, Dongzhan Zhou, Xiao-yong Wei, and Qing Li. 2024 b . Speak-to-structure: Evaluating llms in open-domain natural language-driven molecule generation. arXiv preprint arXiv:2412.14642
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. Let’s verify step by step, 2023. arXiv preprint arXiv:2305.20050, 17
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[63]
Daniel Mark Lowe. 2012. Extraction of Chemical Structures and Reactions from the Literature. Ph.D. thesis, University of Cambridge
2012
-
[64]
Xingyu Lu, He Cao, Zijing Liu, Shengyuan Bai, Leqing Chen, Yuan Yao, Hai-Tao Zheng, and Yu Li. 2024. Moleculeqa: A dataset to evaluate factual accuracy in molecular comprehension. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 3769--3789
2024
-
[65]
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Meiqi Guo, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, Jiao Sun, and Abhinav Rastogi. 2024. Improve mathematical reasoning in language models by automated process supervision. arXiv preprint arXiv:2406.06592
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
Are large language models superhuman chemists?arXiv preprint arXiv:2404.01475, 2024
Adrian Mirza, Nawaf Alampara, Sreekanth Kunchapu, Marti \ n o R \' os-Garc \' a, Benedict Emoekabu, Aswanth Krishnan, Tanya Gupta, Mara Schilling-Wilhelmi, Macjonathan Okereke, Anagha Aneesh, Amir Mohammad Elahi, Mehrdad Asgari, Juliane Eberhardt, Hani M. Elbeheiry, Mar \' a Victoria Gil, Maximilian Greiner, Caroline T. Holick, Christina Glaubitz, Tim Hof...
-
[67]
arXiv preprint arXiv:2506.17238 , year=
Siddharth M. Narayanan, James D. Braza, Ryan-Rhys Griffiths, Albert Bou, Geemi Wellawatte, Mayk Caldas Ramos, Ludovico Mitchener, Samuel G. Rodriques, and Andrew D. White. 2025. https://doi.org/10.48550/arXiv.2506.17238 Training a scientific reasoning model for chemistry . arXiv preprint arXiv:2506.17238
-
[68]
Qizhi Pei, Wei Zhang, Jinhua Zhu, Kehan Wu, Kaiyuan Gao, Lijun Wu, Yingce Xia, and Rui Yan. 2023. Biot5: Enriching cross-modal integration in biology with chemical knowledge and natural language associations. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 1102--1123
2023
-
[69]
Damith Perera, Joseph W Tucker, Shalini Brahmbhatt, Christopher J Helal, Ashley Chong, William Farrell, Paul Richardson, and Neal W Sach. 2018. A platform for automated nanomole-scale reaction screening and micromole-scale synthesis in flow. Science, 359(6374):429--434
2018
-
[70]
Nicholas T Runcie, Charlotte M Deane, and Fergus Imrie. 2026. Assessing the chemical intelligence of large language models. Journal of Chemical Information and Modeling, 66(1):216--227
2026
-
[71]
Nadine Schneider, Nikolaus Stiefl, and Gregory A Landrum. 2016. What's what: The (nearly) definitive guide to reaction role assignment. Journal of Chemical Information and Modeling, 56(12):2336--2346
2016
- [72]
- [73]
-
[74]
Binghai Wang, Yantao Liu, Yuxuan Liu, Tianyi Tang, Shenzhi Wang, Chang Gao, Chujie Zheng, Yichang Zhang, Le Yu, Shixuan Liu, Tao Gui, Qi Zhang, Xuanjing Huang, Bowen Yu, Fei Huang, and Junyang Lin. 2026. Outcome accuracy is not enough: Aligning the reasoning process of reward models. arXiv preprint arXiv:2602.04649
-
[75]
Zichen Wen, Boxue Yang, Shuang Chen, Yaojie Zhang, Yuhang Han, Junlong Ke, Cong Wang, Yicheng Fu, Jiawang Zhao, Jiangchao Yao, Xi Fang, Zhen Wang, Henxing Cai, Lin Yao, Zhifeng Gao, Yanhui Hong, Nang Yuan, Yixuan Li, Guojiang Zhao, and 15 others. 2026. Innovator-vl: A multimodal large language model for scientific discovery. arXiv preprint arXiv:2601.19325
- [76]
- [77]
- [78]
-
[79]
Zehua Zhao, Zhixian Huang, Junren Li, Siyu Lin, Junting Zhou, Fengqi Cao, Kun Zhou, Rui Ge, Tingting Long, Yuexiang Zhu, Yan Liu, Jie Zheng, Junnian Wei, Rong Zhu, Peng Zou, Wenyu Li, Zekai Cheng, Tian Ding, Yaxuan Wang, and 12 others. 2025 a . Superchem: A multimodal reasoning benchmark in chemistry. arXiv preprint arXiv:2512.01274
-
[80]
Zihan Zhao, Da Ma, Lu Chen, Liangtai Sun, Zihao Li, Yi Xia, Bo Chen, Hongshen Xu, Zichen Zhu, Su Zhu, Shuai Fan, Guodong Shen, Kai Yu, and Xin Chen. 2025 b . Developing chemdfm as a large language foundation model for chemistry. Cell Reports Physical Science, 6(4)
2025
-
[81]
Zihan Zhao, Ziping Wan, Lu Chen, Xuanze Lin, Shiyang Yu, Situo Zhang, Da Ma, Zichen Zhu, Danyang Zhang, Huayang Wang, Zhongyang Dai, Liyang Wen, Bo Chen, Xin Chen, and Kai Yu. 2025 c . Chemdfm-r: A chemical reasoning llm enhanced with atomized chemical knowledge. arXiv preprint arXiv:2507.21990
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.