EvoDrive: Pareto Evolution for Safety-Critical Autonomous Driving via Self-Improving LLM Agents
Pith reviewed 2026-06-28 10:17 UTC · model grok-4.3
The pith
EvoDrive uses LLM agents in an actor-critic loop to expand the Pareto frontier of safety-critical driving scenarios.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EvoDrive is the first automated LLM-based agentic evolution framework for multi-objective scenario generation. It employs a simulator-grounded actor-critic architecture where a memory-driven actor iteratively proposes improvements to the generators, critics filter out implausible candidates, and a self-evolving world evaluator routes promising proposals to optimize simulation budgets. EvoDrive maintains a Pareto archive of evaluated candidates to preserve diverse attack-realism trade-offs and guide future evolution via simulation feedback.
What carries the argument
Simulator-grounded actor-critic architecture with memory-driven actor, filtering critics, self-evolving evaluator, and Pareto archive that routes proposals and preserves trade-off diversity through simulation feedback.
If this is right
- Scenario generators reach previously inaccessible regions of the attack-realism space.
- Policy training receives scenarios that expose failures more effectively while remaining usable.
- Evolution proceeds without handcrafted heuristics that confine search to known patterns.
- Diverse trade-off candidates are retained and reused to steer subsequent generations.
Where Pith is reading between the lines
- The same grounded evolution loop could be applied to other multi-objective simulation domains such as robotics or network traffic.
- Over repeated runs the archive might surface failure modes that human scenario designers have not yet enumerated.
- If the Pareto set grows steadily, downstream safety validation pipelines could shift from static test suites to continuously refreshed scenario collections.
Load-bearing premise
The actor-critic loop with critics and Pareto archive will keep the attack-realism tension from collapsing into single-objective maximization across iterations.
What would settle it
A direct comparison on MetaDrive or CARLA in which EvoDrive-generated scenario sets produce no measurable expansion of the Pareto frontier relative to the strongest baseline generators.
Figures

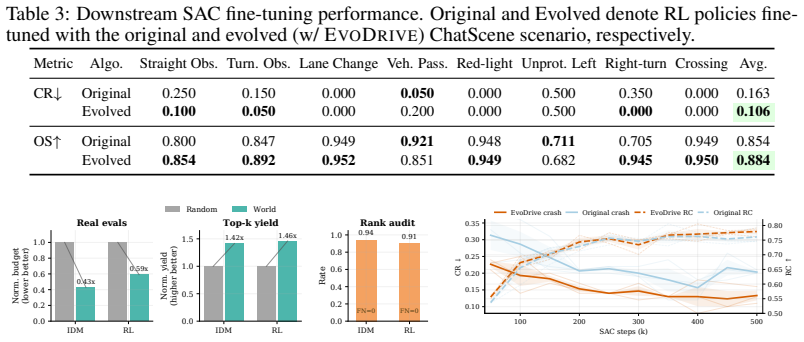
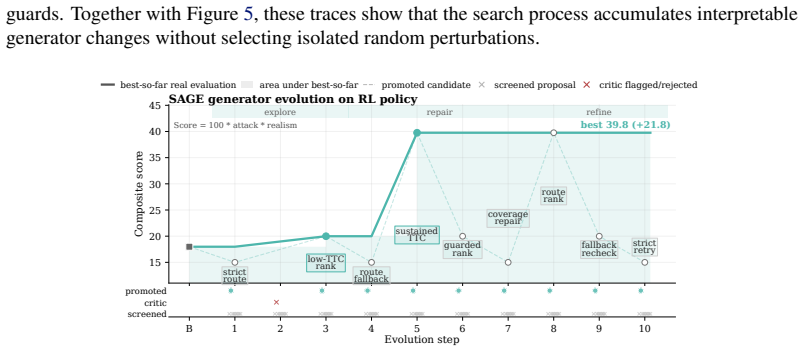
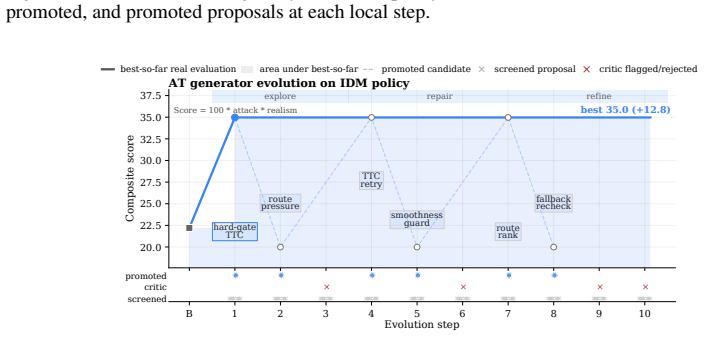
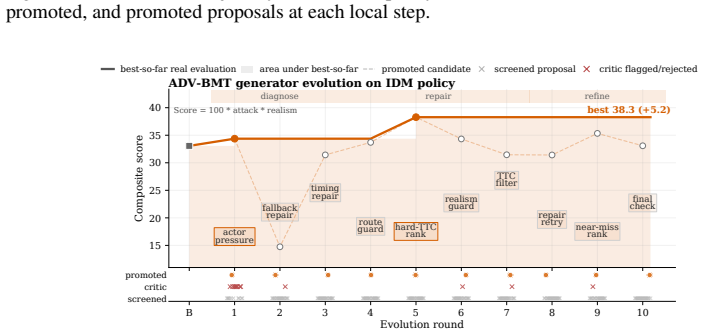

read the original abstract
Generating safety-critical scenarios is essential for validating and improving autonomous driving systems, yet it inherently requires maximizing adversariality to expose failures while preserving realism. Existing methods usually manage this trade-off with handcrafted heuristics, confining generation to known priors and overlooking underexplored patterns. While recent open-ended agentic evolution can push this limit, unconstrained general agents lack strict simulator grounding and tend to collapse the multi-objective tension into single-scalar maximization. Here we present EvoDrive, the first automated, LLM-based agentic evolution framework for multi-objective scenario generation. EvoDrive employs a simulator-grounded actor-critic architecture where a memory-driven actor iteratively proposes improvements to the generators and critics filter out implausible candidates, and a self-evolving world evaluator routes promising proposals to optimize simulation budgets. EvoDrive further maintains a Pareto archive of evaluated candidates to preserve diverse attack-realism trade-offs and guide future evolution via simulation feedback. Benchmark results on MetaDrive and CARLA show that EvoDrive not only significantly expands the Pareto frontier across various generators, but also produces valuable scenarios for policy training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents EvoDrive, an LLM-based agentic evolution framework for multi-objective safety-critical scenario generation in autonomous driving. It employs a simulator-grounded actor-critic setup with a memory-driven actor iteratively proposing generator improvements, critics filtering implausible candidates, a self-evolving world evaluator for routing proposals, and a Pareto archive to preserve diverse attack-realism trade-offs. The central empirical claim is that EvoDrive significantly expands the Pareto frontier across generators on MetaDrive and CARLA benchmarks while also yielding scenarios valuable for downstream policy training.
Significance. If the reported benchmark results hold, the work is significant for automating exploration of the adversariality-realism trade-off in AV scenario generation without handcrafted heuristics or single-objective collapse. The combination of LLM agents, simulator grounding, and explicit Pareto archiving represents a concrete advance over prior open-ended evolution methods, with direct applicability to improving policy robustness.
minor comments (3)
- Abstract: the phrase 'across various generators' should explicitly name the baselines (e.g., in parentheses or with a forward reference to §4) so readers can immediately assess the scope of the claimed improvement.
- §3 (Architecture): the routing logic of the self-evolving world evaluator is described at a high level; adding a short pseudocode block or flowchart would clarify how simulation budgets are allocated without introducing new notation.
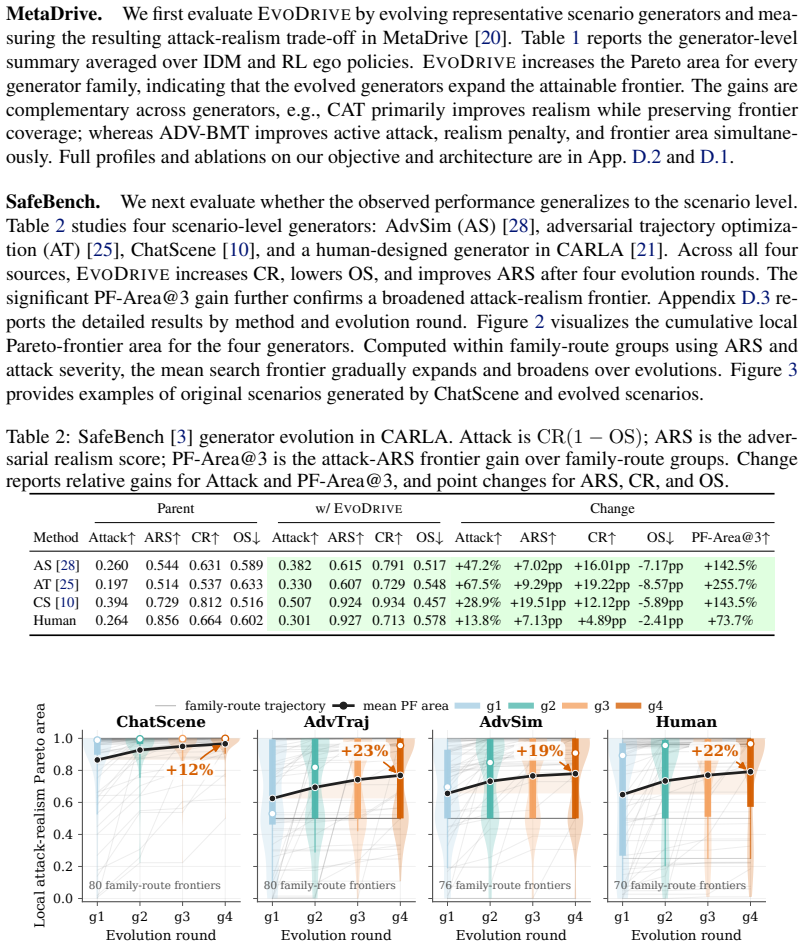
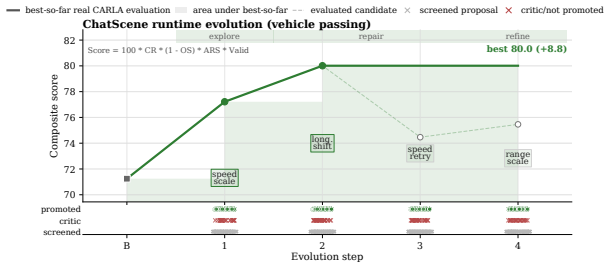
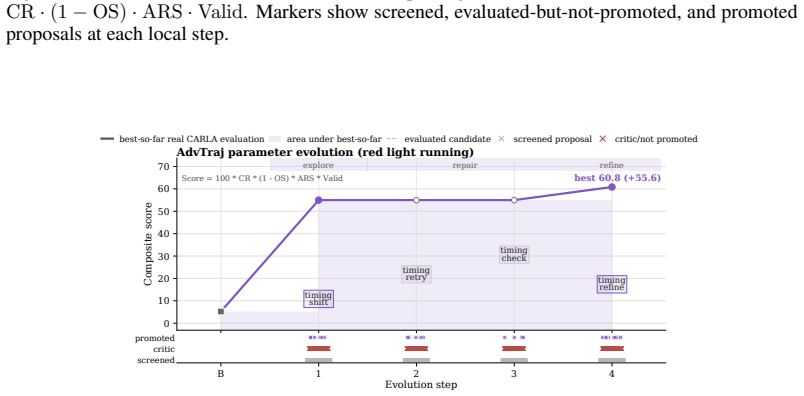
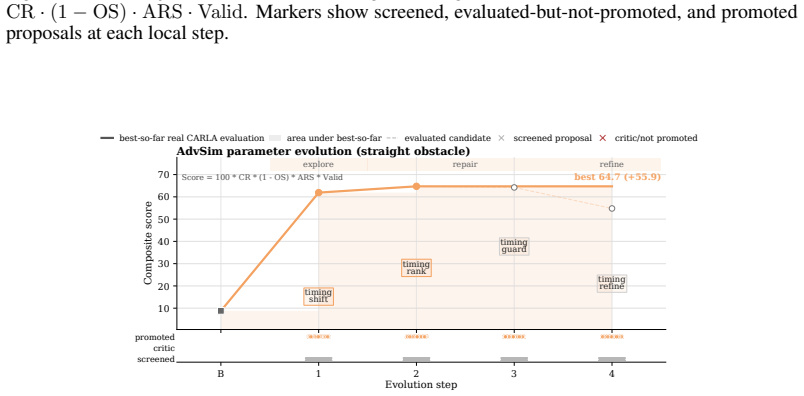
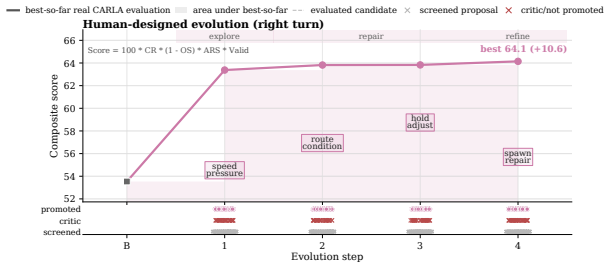
- Figure 3 / Table 2: axis labels and legend entries for the Pareto plots should include units or normalized scales so that the reported frontier expansion can be directly compared across MetaDrive and CARLA.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of EvoDrive and the recommendation for minor revision. The assessment of the work's significance for automating the adversariality-realism trade-off is appreciated. No major comments were provided in the report.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an architectural framework (memory-driven actor-critic with Pareto archive and self-evolving evaluator) for multi-objective scenario generation, evaluated via external benchmarks on MetaDrive and CARLA simulators. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or described structure. The central claims rest on empirical expansion of the Pareto frontier and downstream policy training value, which are independent of the architecture description itself. The derivation is self-contained against external simulators and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. Feng, X. Yan, H. Sun, Y . Feng, and H. X. Liu. Intelligent driving intelligence test for autonomous vehicles with naturalistic and adversarial environment.Nature communications, 12(1):748, 2021
2021
-
[2]
S. Feng, H. Sun, X. Yan, H. Zhu, Z. Zou, S. Shen, and H. X. Liu. Dense reinforcement learning for safety validation of autonomous vehicles.Nature, 615(7953):620–627, 2023
2023
-
[3]
C. Xu, W. Ding, W. Lyu, Z. Liu, S. Wang, Y . He, H. Hu, D. Zhao, and B. Li. Safebench: A benchmarking platform for safety evaluation of autonomous vehicles.Advances in Neural Information Processing Systems, 35:25667–25682, 2022
2022
-
[4]
T. Nie, Y . Mei, Y . Tang, J. He, J. Sun, H. Shi, W. Ma, and J. Sun. Steerable adversarial scenario generation through test-time preference alignment.arXiv preprint arXiv:2509.20102, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
S. Feng, H. Zhu, H. Sun, X. Yan, L. He, J. Yang, G. Su, B. Li, S. Li, L. Wang, et al. Breaking through safety performance stagnation in autonomous vehicles with dense learning.Nature Communications, 2026
2026
-
[6]
Rempe, J
D. Rempe, J. Philion, L. J. Guibas, S. Fidler, and O. Litany. Generating useful accident-prone driving scenarios via a learned traffic prior. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17305–17315, 2022
2022
- [7]
-
[8]
C. Xu, A. Petiushko, D. Zhao, and B. Li. Diffscene: Diffusion-based safety-critical scenario generation for autonomous vehicles. InProceedings of the AAAI conference on artificial intel- ligence, volume 39, pages 8797–8805, 2025
2025
-
[9]
Y . Liu, Z. M. Peng, X. Cui, and B. Zhou. Adv-bmt: Bidirectional motion transformer for safety-critical traffic scenario generation.Advances in Neural Information Processing Systems, 38:55310–55335, 2026
2026
-
[10]
Zhang, C
J. Zhang, C. Xu, and B. Li. Chatscene: Knowledge-enabled safety-critical scenario generation for autonomous vehicles. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15459–15469, 2024
2024
-
[11]
Y . Mei, T. Nie, J. Sun, and Y . Tian. Llm-attacker: Enhancing closed-loop adversarial sce- nario generation for autonomous driving with large language models.IEEE Transactions on Intelligent Transportation Systems, 2025
2025
-
[12]
H. Tian, K. Reddy, Y . Feng, M. Quddus, Y . Demiris, and P. Angeloudis. Enhancing au- tonomous vehicle training with language model integration and critical scenario generation,
- [13]
-
[14]
Shinn, F
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36: 8634–8652, 2023
2023
-
[15]
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandku- mar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
C. Lu, C. Lu, R. T. Lange, J. Foerster, J. Clune, and D. Ha. The ai scientist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
A. Novikov, N. V ˜u, M. Eisenberger, E. Dupont, P.-S. Huang, A. Z. Wagner, S. Shirobokov, B. Kozlovskii, F. J. Ruiz, A. Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
R. T. Lange, Y . Imajuku, and E. Cetin. Shinkaevolve: Towards open-ended and sample- efficient program evolution.arXiv preprint arXiv:2509.19349, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
A. Qu, H. Zheng, Z. Zhou, Y . Yan, Y . Tang, S. Y . Ong, F. Hong, K. Zhou, C. Jiang, M. Kong, et al. Coral: Towards autonomous multi-agent evolution for open-ended discovery.arXiv preprint arXiv:2604.01658, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [20]
-
[21]
Q. Li, Z. Peng, L. Feng, Q. Zhang, Z. Xue, and B. Zhou. Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning.IEEE transactions on pattern analysis and machine intelligence, 45(3):3461–3475, 2022
2022
-
[22]
Dosovitskiy, G
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V . Koltun. Carla: An open urban driving simulator. InConference on robot learning, pages 1–16. PMLR, 2017
2017
-
[23]
Codex.https://developers.openai.com/codex, 2026
OpenAI. Codex.https://developers.openai.com/codex, 2026. OpenAI coding agent for software development. Accessed: 2026-05-25
2026
-
[24]
Claude Code.https://docs.anthropic.com/en/docs/agents-and-tools/ claude-code/overview, 2026
Anthropic. Claude Code.https://docs.anthropic.com/en/docs/agents-and-tools/ claude-code/overview, 2026. AI-powered coding assistant. Accessed: 2026-05-25. 10
2026
-
[25]
Zhang, Z
L. Zhang, Z. Peng, Q. Li, and B. Zhou. Cat: Closed-loop adversarial training for safe end-to- end driving. InConference on Robot Learning, pages 2357–2372. PMLR, 2023
2023
-
[26]
Zhang, S
Q. Zhang, S. Hu, J. Sun, Q. A. Chen, and Z. M. Mao. On adversarial robustness of trajectory prediction for autonomous vehicles. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15159–15168, 2022
2022
-
[27]
Hanselmann, K
N. Hanselmann, K. Renz, K. Chitta, A. Bhattacharyya, and A. Geiger. King: Generating safety-critical driving scenarios for robust imitation via kinematics gradients. InEuropean Conference on Computer Vision, pages 335–352. Springer, 2022
2022
-
[28]
Stoler, I
B. Stoler, I. Navarro, J. Francis, and J. Oh. Seal: Towards safe autonomous driving via skill- enabled adversary learning for closed-loop scenario generation.IEEE Robotics and Automa- tion Letters, 10(9):9320–9327, 2025
2025
-
[29]
J. Wang, A. Pun, J. Tu, S. Manivasagam, A. Sadat, S. Casas, M. Ren, and R. Urtasun. Advsim: Generating safety-critical scenarios for self-driving vehicles. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9909–9918, 2021
2021
-
[30]
Y . Cao, C. Xiao, A. Anandkumar, D. Xu, and M. Pavone. Advdo: Realistic adversarial attacks for trajectory prediction. InEuropean Conference on Computer Vision, pages 36–52. Springer, 2022
2022
- [31]
-
[32]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
X. Yin, X. Wang, L. Pan, L. Lin, X. Wan, and W. Y . Wang. G¨odel agent: A self-referential agent framework for recursively self-improvement. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 27890–27913, 2025
2025
-
[34]
Zhang, S
J. Zhang, S. Hu, C. Lu, R. T. Lange, and J. Clune. Darwin g ¨odel machine: Open-ended evolution of self-improving agents. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=pUpzQZTvGY
2026
-
[35]
Y . Lee, R. Nair, Q. Zhang, K. Lee, O. Khattab, and C. Finn. Meta-harness: End-to-end opti- mization of model harnesses.arXiv preprint arXiv:2603.28052, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
S. Ettinger, S. Cheng, B. Caine, C. Liu, H. Zhao, S. Pradhan, Y . Chai, B. Sapp, C. R. Qi, Y . Zhou, et al. Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset. InProceedings of the IEEE/CVF international conference on computer vision, pages 9710–9719, 2021. 11 Appendix Appendix Contents A Related Work 12 B Ext...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.