A Close Look At World Model Recovery In Supervised Fine-Tuned LLM Planners
Pith reviewed 2026-06-28 11:34 UTC · model grok-4.3
The pith
Supervised fine-tuning on valid action sequences enables LLMs to linearly encode action validity and state predicates in internal representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
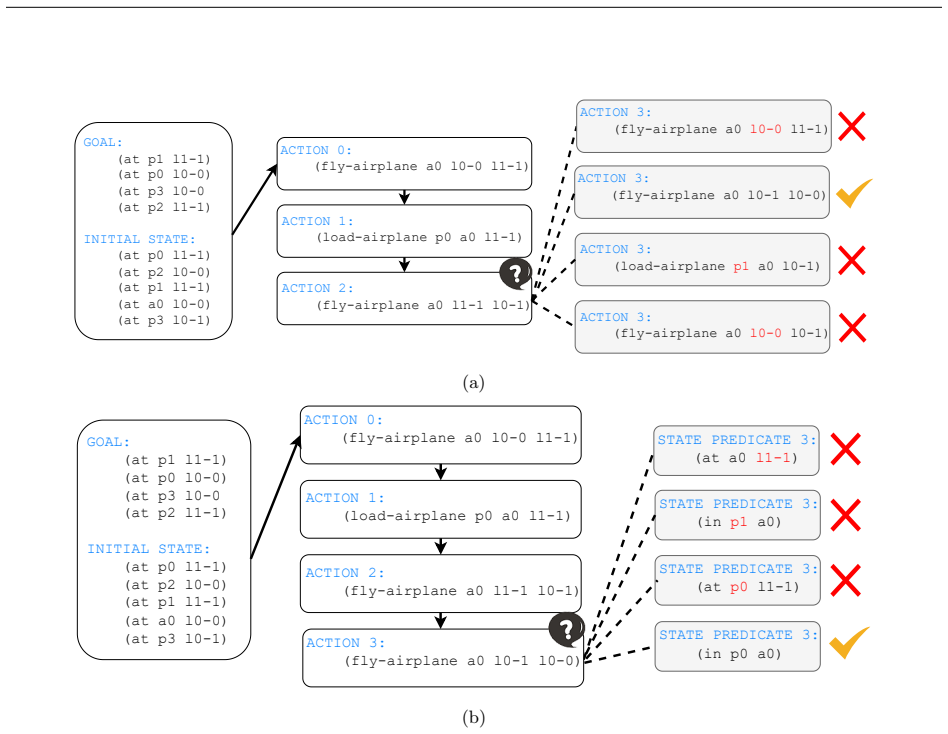
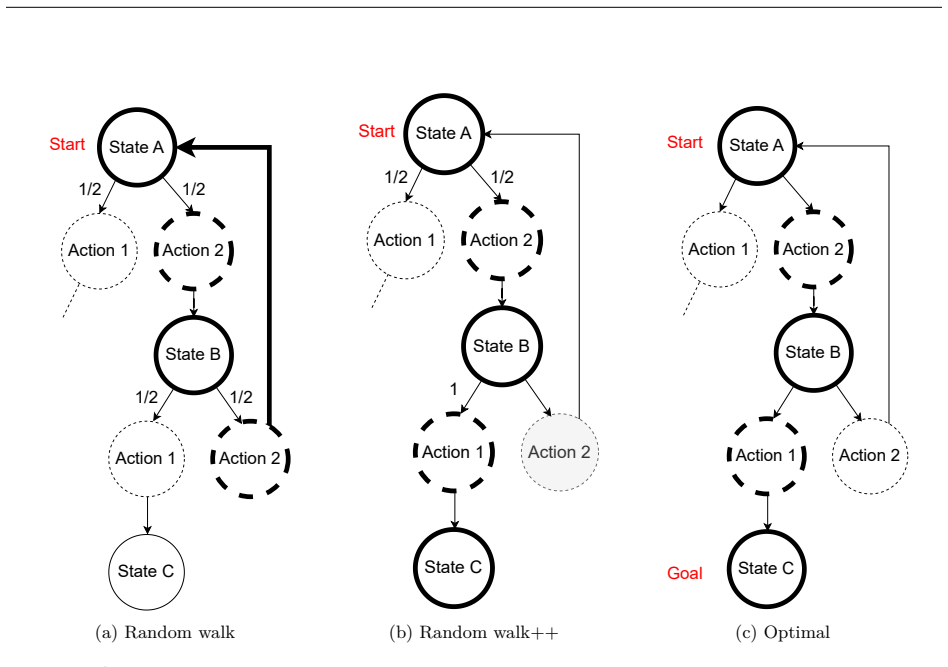
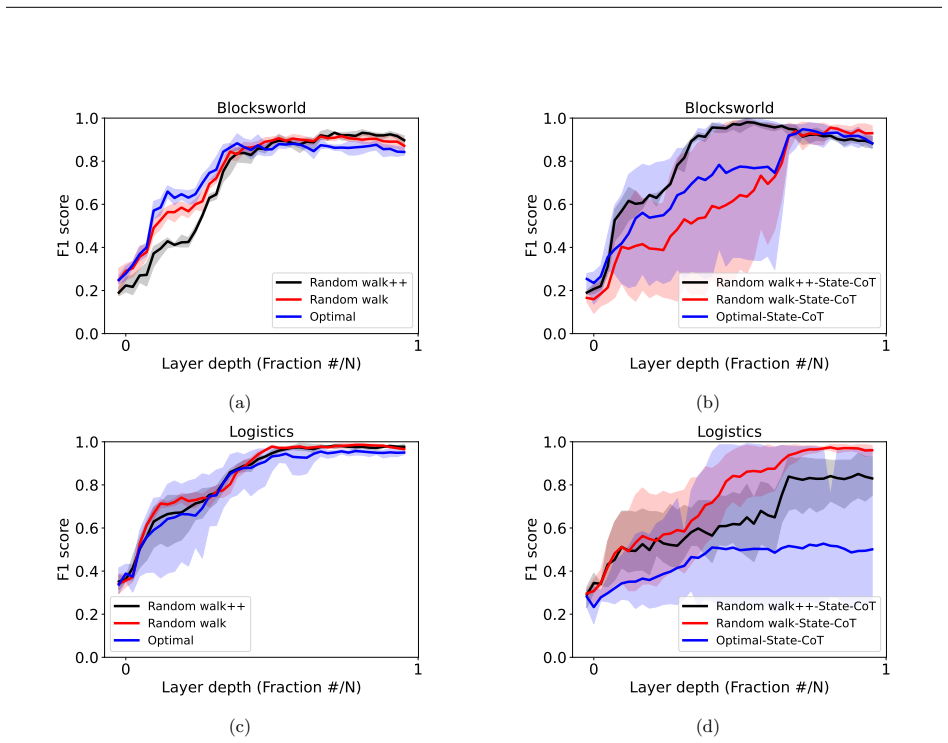
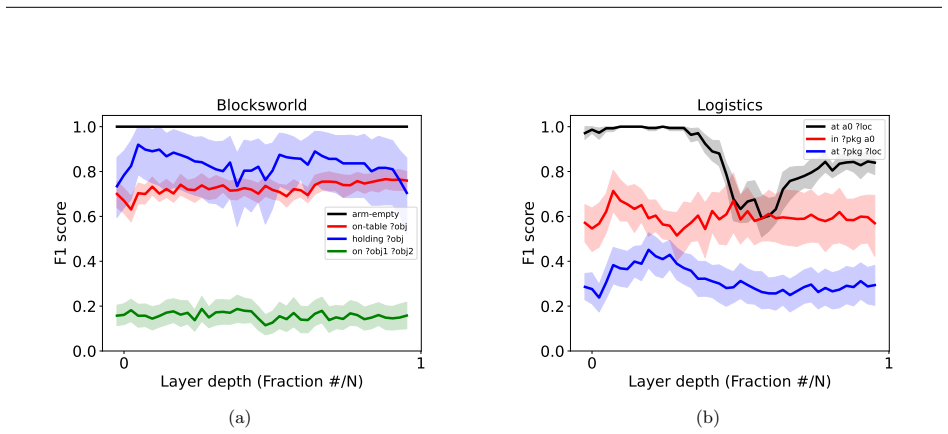
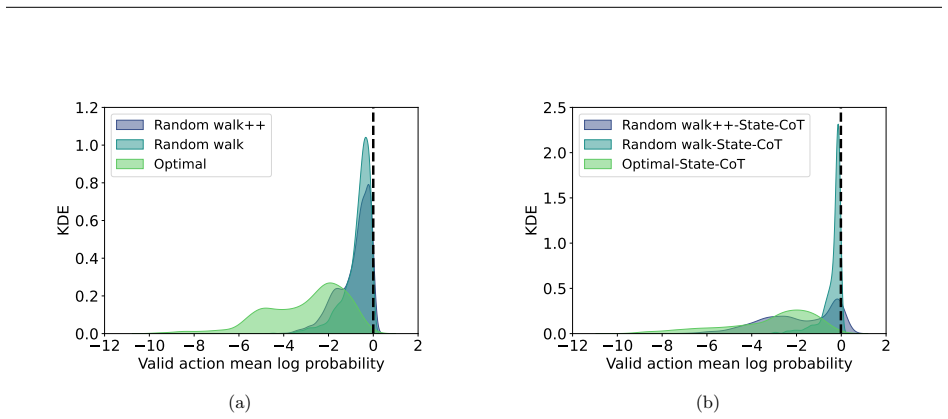
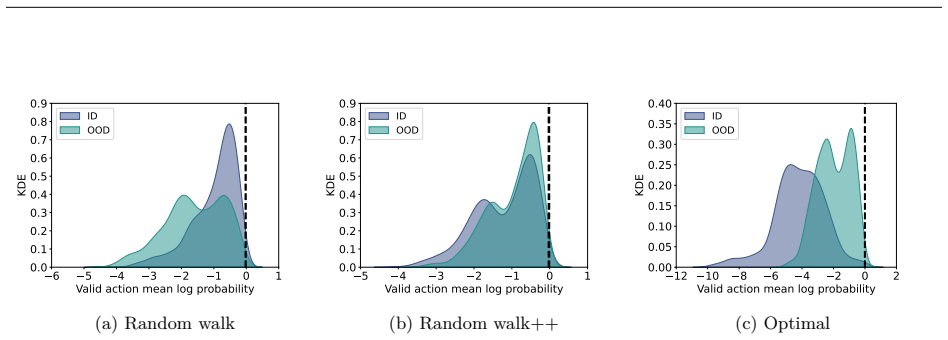
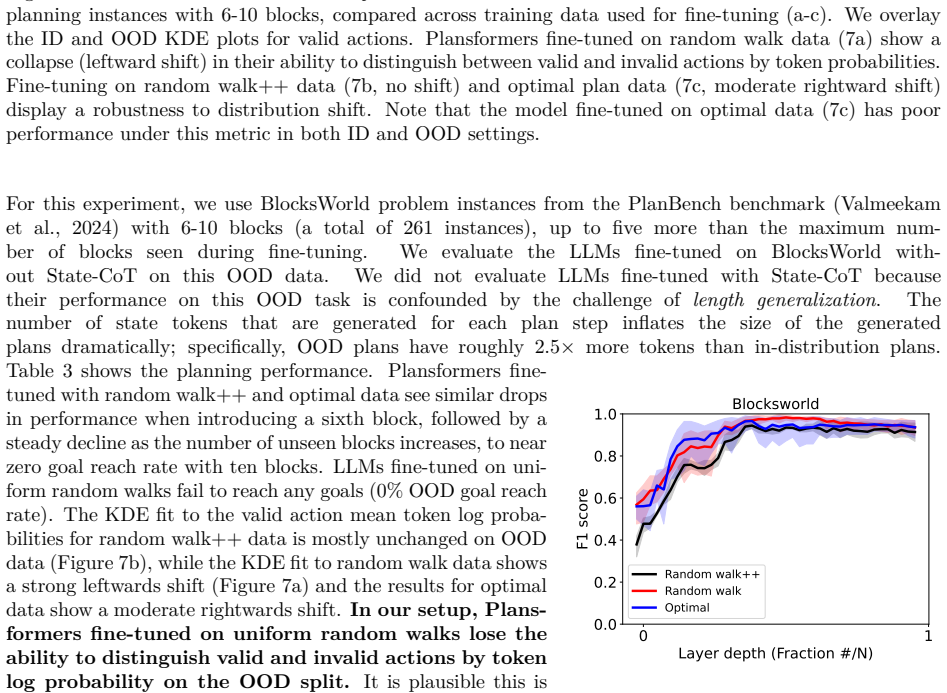
Supervised fine-tuning on valid action sequences enables LLMs to linearly encode action validity and some state predicates. Models that struggle to use output probabilities for classifying action validity may still learn internal representations that separate valid from invalid actions. Broader state space coverage during fine-tuning, such as from random walk data, yields more accurate recovery of the underlying world model.
What carries the argument
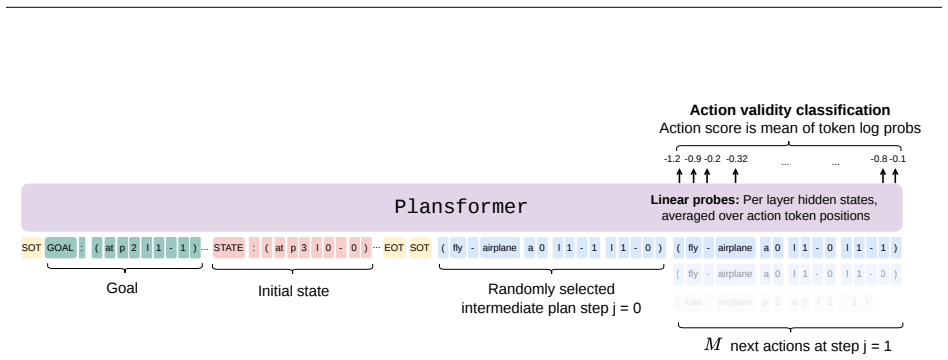
Linear probes on model activations that detect encoding of action validity and state predicates, combined with analysis of output probabilities for the same distinctions.
If this is right
- LLMs can acquire internal representations of planning constraints through SFT without direct supervision on state variables.
- Internal activations may reveal model understanding more reliably than the probabilities the model assigns to its own outputs.
- Collecting training data with greater state-space coverage during fine-tuning directly improves the fidelity of the recovered world model.
Where Pith is reading between the lines
- If internal encodings prove stable across tasks, probing could become a practical tool for auditing or selecting planning datasets before full training.
- The gap between internal separation and output probabilities suggests that hybrid systems might combine probed representations with generative decoding for verification.
- The same linear-probe approach could be applied to other structured domains such as code generation or theorem proving to test whether SFT induces similar world-model-like encodings.
Load-bearing premise
The selected interpretability techniques capture world-model recovery comprehensively without missing non-linear representations or alternative reasoning paths.
What would settle it
A finding that linear probes on activations achieve near-chance accuracy on validity prediction while the model still generates correct plans at high rates, or that random-walk training data produces no measurable improvement in probe accuracy over narrower datasets.
Figures
read the original abstract
Supervised fine-tuning (SFT) improves end-to-end classical planning in large language models (LLMs), but do these models also learn to represent and reason about the planning problems they are solving? Due to the relative complexity of classical planning problems and the challenge that end-to-end plan generation poses for LLMs, it has been difficult to explore this question. In our work, we devise and perform a series of interpretability experiments that holistically interrogate world model recovery by examining both internal representations and generative capabilities of fine-tuned LLMs. We find that: a) Supervised fine-tuning on valid action sequences enables LLMs to linearly encode action validity and some state predicates. b) Models that struggle to use output probabilities for classifying action validity may still learn internal representations that separate valid from invalid actions. c) Broader state space coverage during fine-tuning, such as from random walk data, yields more accurate recovery of the underlying world model. In summary, this work contributes a recipe for applying interpretability techniques to planning LLMs and generates insights that shed light on open questions about how knowledge is represented in LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical interpretability study examining whether supervised fine-tuning (SFT) on valid action sequences enables LLMs to recover world models for classical planning. Using linear probes on internal activations and analysis of output probabilities, the authors report three findings: (a) SFT produces linear encodings of action validity and some state predicates; (b) internal representations can separate valid from invalid actions even when output probabilities are ineffective for classification; (c) broader state-space coverage during fine-tuning (e.g., random-walk data) yields more accurate world-model recovery. The work also supplies a methodological recipe for applying interpretability techniques to planning LLMs.
Significance. If the results hold after addressing causal questions, the paper would contribute useful mechanistic insight into how SFT shapes internal representations in LLM planners, moving beyond end-to-end accuracy to questions of world-model recovery. The dual focus on probes and generative behavior, together with the coverage finding, offers practical guidance for data curation. The study is grounded in standard linear-probe methodology and addresses a timely question in LLM planning research.
major comments (1)
- [Abstract and interpretability experiments] Abstract and interpretability experiments: The central claim that SFT enables 'recovery of the underlying world model' is supported only by evidence of linear separability. No activation interventions, direction ablations, or causal tests (e.g., patching the probe directions and measuring downstream planning accuracy) are described, leaving open whether the observed encodings are used by the model or are epiphenomenal.
minor comments (1)
- [Abstract] Abstract: Key experimental details (model sizes, planning domains, number of trajectories, statistical tests) are absent, making it difficult for readers to gauge the scope and robustness of the reported findings.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the opportunity to clarify the scope of our claims. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract and interpretability experiments] Abstract and interpretability experiments: The central claim that SFT enables 'recovery of the underlying world model' is supported only by evidence of linear separability. No activation interventions, direction ablations, or causal tests (e.g., patching the probe directions and measuring downstream planning accuracy) are described, leaving open whether the observed encodings are used by the model or are epiphenomenal.
Authors: We agree that the evidence is correlational, relying on linear probes for action validity and state predicates together with analysis of output probabilities and planning performance. The manuscript does not include activation interventions or patching experiments. We will revise the abstract, introduction, and conclusion to replace the phrasing 'recovery of the underlying world model' with 'linearly decodable components of a world model' and add an explicit limitations paragraph noting the absence of causal tests. These changes preserve the reported findings on probe accuracy, the gap between internal representations and output probabilities, and the coverage effect while accurately bounding the strength of the claims. revision: partial
Circularity Check
No circularity: empirical interpretability study with no derivations or self-referential predictions
full rationale
This is an empirical paper that fine-tunes LLMs on planning data and applies linear probes plus output-probability analysis to inspect representations. No equations, predictions, or derivations are present that could reduce to fitted parameters or self-citations by construction. All claims rest on direct experimental measurements (probe accuracies, separability metrics) that are independently falsifiable from the training data itself. The work is self-contained against external benchmarks and contains no load-bearing self-citation chains or ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear probes on internal activations can reveal whether the model encodes action validity and state predicates
Reference graph
Works this paper leans on
-
[1]
Jannik Brinkmann, Abhay Sheshadri, Victor Levoso, Paul Swoboda, and Christian Bartelt. A mechanistic analysisofatransformertrainedonasymbolicmulti-stepreasoningtask.arXiv preprint arXiv:2402.11917,
-
[2]
Do androids know they’re only dreaming of electric sheep?arXiv preprint arXiv:2312.17249,
Sky CH-Wang, Benjamin Van Durme, Jason Eisner, and Chris Kedzie. Do androids know they’re only dreaming of electric sheep?arXiv preprint arXiv:2312.17249,
-
[3]
Antoine Dedieu, Wolfgang Lehrach, Guangyao Zhou, Dileep George, and Miguel Lázaro-Gredilla. Learning cognitive maps from transformer representations for efficient planning in partially observed environments. arXiv preprint arXiv:2401.05946,
-
[4]
Languagemodelsrepresentspaceandtime.arXiv preprint arXiv:2310.02207,
WesGurneeandMaxTegmark. Languagemodelsrepresentspaceandtime.arXiv preprint arXiv:2310.02207,
-
[5]
Reasoning with language model is planning with world model.arXiv preprint arXiv:2305.14992,
Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. Reasoning with language model is planning with world model.arXiv preprint arXiv:2305.14992,
-
[6]
Eran Hirsch, Guy Uziel, and Ateret Anaby-Tavor. What’s the plan? evaluating and developing planning- aware techniques for llms.arXiv preprint arXiv:2402.11489,
-
[7]
15 Sukai Huang, Trevor Cohn, and Nir Lipovetzky. Chasing progress, not perfection: Revisiting strategies for end-to-end llm plan generation.arXiv preprint arXiv:2412.10675,
-
[8]
Structured world representa- tions in maze-solving transformers.arXiv preprint arXiv:2312.02566,
Michael Igorevich Ivanitskiy, Alex F Spies, Tilman Räuker, Guillaume Corlouer, Chris Mathwin, Lucia Quirke, Can Rager, Rusheb Shah, Dan Valentine, Cecilia Diniz Behn, et al. Structured world representa- tions in maze-solving transformers.arXiv preprint arXiv:2312.02566,
-
[9]
Evidence of learned look-ahead in a chess-playing neural network.arXiv preprint arXiv:2406.00877,
Erik Jenner, Shreyas Kapur, Vasil Georgiev, Cameron Allen, Scott Emmons, and Stuart Russell. Evidence of learned look-ahead in a chess-playing neural network.arXiv preprint arXiv:2406.00877,
-
[10]
Marek Kadlčík, Michal Štefánik, Timothee Mickus, Michal Spiegel, and Josef Kuchař. Pre-trained language models learn remarkably accurate representations of numbers.arXiv preprint arXiv:2506.08966,
-
[11]
Emergent world models and latent variable estimation in chess-playing language models
Adam Karvonen. Emergent world models and latent variable estimation in chess-playing language models. arXiv preprint arXiv:2403.15498,
-
[12]
Implicit representations of meaning in neural language models.arXiv preprint arXiv:2106.00737,
Belinda Z Li, Maxwell Nye, and Jacob Andreas. Implicit representations of meaning in neural language models.arXiv preprint arXiv:2106.00737,
-
[13]
Kenneth Li, Aspen K Hopkins, David Bau, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Emergent world representations: Exploring a sequence model trained on a synthetic task.arXiv preprint arXiv:2210.13382,
-
[14]
Wenjun Li, Changyu Chen, and Pradeep Varakantham. Unlocking large language model’s planning capabil- ities with maximum diversity fine-tuning.arXiv preprint arXiv:2406.10479,
-
[15]
Transformers learn shortcuts to automata.arXiv preprint arXiv:2210.10749,
Bingbin Liu, Jordan T Ash, Surbhi Goel, Akshay Krishnamurthy, and Cyril Zhang. Transformers learn shortcuts to automata.arXiv preprint arXiv:2210.10749,
-
[16]
Jiarui Liu, Jivitesh Jain, Mona Diab, and Nishant Subramani. Llm microscope: What model internals reveal about answer correctness and context utilization.arXiv preprint arXiv:2510.04013,
-
[17]
Tianyi Men, Pengfei Cao, Zhuoran Jin, Yubo Chen, Kang Liu, and Jun Zhao. Unlocking the future: Exploring look-ahead planning mechanistic interpretability in large language models.arXiv preprint arXiv:2406.16033,
-
[18]
Neel Nanda, Andrew Lee, and Martin Wattenberg. Emergent linear representations in world models of self-supervised sequence models.arXiv preprint arXiv:2309.00941,
-
[19]
Hadas Orgad, Michael Toker, Zorik Gekhman, Roi Reichart, Idan Szpektor, Hadas Kotek, and Yonatan Belinkov. Llms know more than they show: On the intrinsic representation of llm hallucinations.arXiv preprint arXiv:2410.02707,
-
[20]
Plansformer: Generating symbolic plans using transform- ers.arXiv preprint arXiv:2212.08681,
Vishal Pallagani, Bharath Muppasani, Keerthiram Murugesan, Francesca Rossi, Lior Horesh, Biplav Srivas- tava, Francesco Fabiano, and Andrea Loreggia. Plansformer: Generating symbolic plans using transform- ers.arXiv preprint arXiv:2212.08681,
-
[21]
16 John Schultz, Jakub Adamek, Matej Jusup, Marc Lanctot, Michael Kaisers, Sarah Perrin, Daniel Hennes, JeremyShar, CannadaLewis, Anian Ruoss, et al. Masteringboardgames byexternaland internalplanning with language models.arXiv preprint arXiv:2412.12119,
-
[22]
JendrikSeipp, ÁlvaroTorralba, andJörgHoffmann. PDDLgenerators.https://doi.org/10.5281/zenodo. 6382173,
-
[23]
Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118,
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118,
-
[24]
Qwen2 technical report.arXiv preprint arXiv:2407.10671, 2,
Qwen Team. Qwen2 technical report.arXiv preprint arXiv:2407.10671, 2,
-
[25]
Evaluating the world model implicit in a generative model.arXiv preprint arXiv:2406.03689,
Keyon Vafa, Justin Y Chen, Jon Kleinberg, Sendhil Mullainathan, and Ashesh Rambachan. Evaluating the world model implicit in a generative model.arXiv preprint arXiv:2406.03689,
-
[26]
On memorization of large language models in logical reasoning.arXiv preprint arXiv:2410.23123,
Chulin Xie, Yangsibo Huang, Chiyuan Zhang, Da Yu, Xinyun Chen, Bill Yuchen Lin, Bo Li, Badih Ghazi, and Ravi Kumar. On memorization of large language models in logical reasoning.arXiv preprint arXiv:2410.23123,
-
[27]
Revisiting the othello world model hypothesis.arXiv preprint arXiv:2503.04421,
Yifei Yuan and Anders Søgaard. Revisiting the othello world model hypothesis.arXiv preprint arXiv:2503.04421,
-
[28]
Tian Yun, Zilai Zeng, Kunal Handa, Ashish V Thapliyal, Bo Pang, Ellie Pavlick, and Chen Sun. Emergence of abstract state representations in embodied sequence modeling.arXiv preprint arXiv:2311.02171,
-
[29]
On the paradox of learning to reason from data.arXiv preprint arXiv:2205.11502,
Honghua Zhang, Liunian Harold Li, Tao Meng, Kai-Wei Chang, and Guy Van den Broeck. On the paradox of learning to reason from data.arXiv preprint arXiv:2205.11502,
-
[30]
Natural plan: Benchmarking llms on natural language planning.arXiv preprint arXiv:2406.04520,
Huaixiu Steven Zheng, Swaroop Mishra, Hugh Zhang, Xinyun Chen, Minmin Chen, Azade Nova, Le Hou, Heng-Tze Cheng, Quoc V Le, Ed H Chi, et al. Natural plan: Benchmarking llms on natural language planning.arXiv preprint arXiv:2406.04520,
-
[31]
Max Zuo, Francisco Piedrahita Velez, Xiaochen Li, Michael L Littman, and Stephen H Bach. Plane- tarium: A rigorous benchmark for translating text to structured planning languages.arXiv preprint arXiv:2407.03321,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.