Investigating Adversarial Robustness of Multi-modal Large Language Models
Pith reviewed 2026-06-28 11:09 UTC · model grok-4.3
The pith
Large-scale multimodal adversarial pretraining of vision encoders is required for strong robustness transfer into MLLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
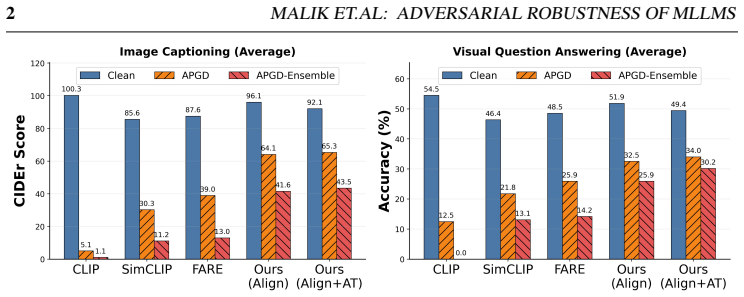
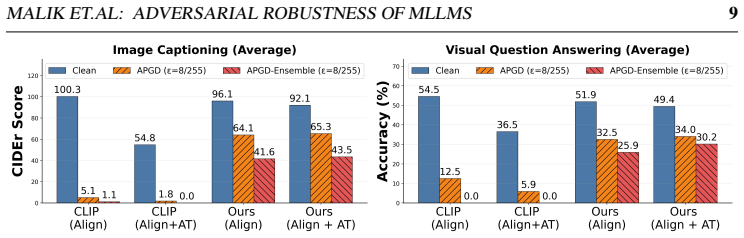
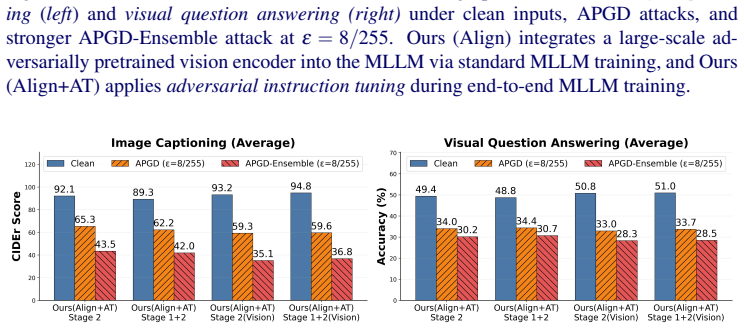
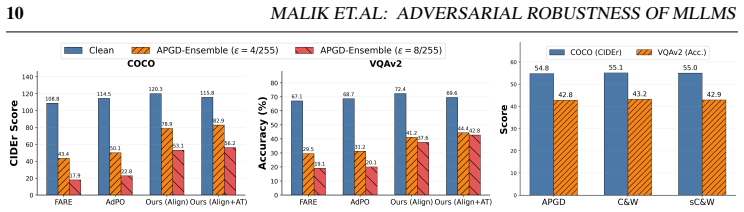
Large-scale multimodal adversarial pretraining, rather than unimodal scale alone, is the critical factor for strong robustness transfer. A diagnostic CLIP-alignment protocol predicts which robust vision encoders will transfer effectively. Integrating those encoders into MLLMs via end-to-end multimodal training produces average gains of 28 CIDEr points on captioning and 11.7 percent VQA accuracy under strong adversarial attacks compared with constrained plug-and-play baselines. Adversarial training applied directly to a standard non-robust MLLM degrades both clean and adversarial performance, confirming that robust visual representations are a strict prerequisite. End-to-end adversarial train
What carries the argument
The diagnostic CLIP-alignment protocol that scores how well a robust vision encoder preserves alignment with CLIP's original embedding space and thereby predicts transfer success to MLLMs.
If this is right
- Integrating encoders pretrained with large-scale multimodal adversarial data via end-to-end training yields 28 CIDEr points on captioning and 11.7 percent VQA accuracy under strong attacks versus plug-and-play baselines.
- Adversarial training applied to a non-robust MLLM degrades both clean and adversarial performance, showing robust visual representations are required first.
- End-to-end adversarial training starting from a robust backbone supplies an extra 1.9 CIDEr points and 4.3 percent VQA accuracy.
- Lightweight test-time visual stochastic transformations raise adversarial performance of non-robust MLLMs from near zero to levels comparable with robust models.
- Robust MLLMs substantially reduce toxic generation under white-box visual jailbreak attacks.
Where Pith is reading between the lines
- Developers of future MLLMs may need to invest in large multimodal adversarial datasets rather than relying solely on scaling unimodal robust encoders.
- The same pretraining principle could be tested on other input modalities such as audio to check whether multimodal adversarial pretraining remains the decisive factor.
- Combining the test-time stochastic transformations with the robust backbone training may produce additive defense without extra training cost.
Load-bearing premise
The diagnostic CLIP-alignment protocol accurately predicts, prior to full MLLM training, which robust vision encoders will transfer effectively to the multimodal setting.
What would settle it
A controlled experiment in which an encoder that scores high on the CLIP-alignment protocol is integrated end-to-end yet produces no robustness gain, or an encoder that scores low yet succeeds after the same training.
Figures
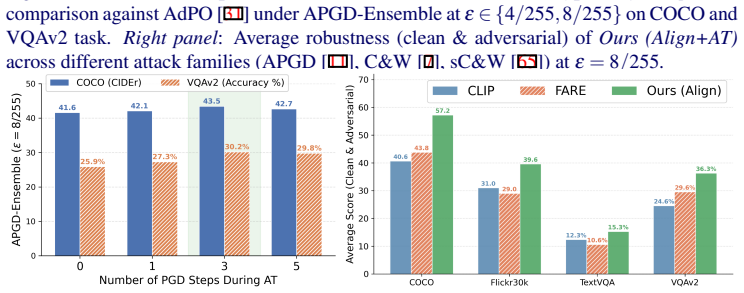
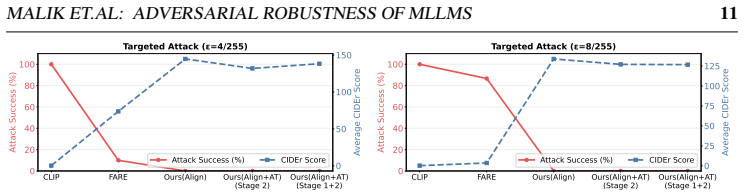
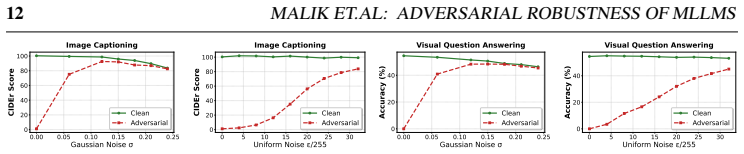
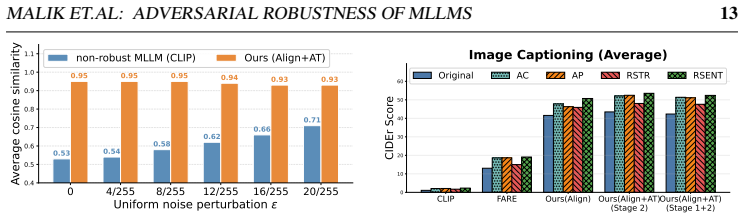
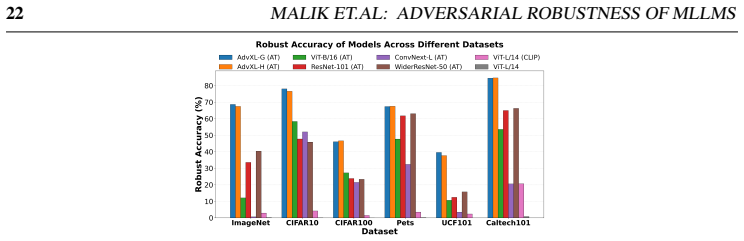

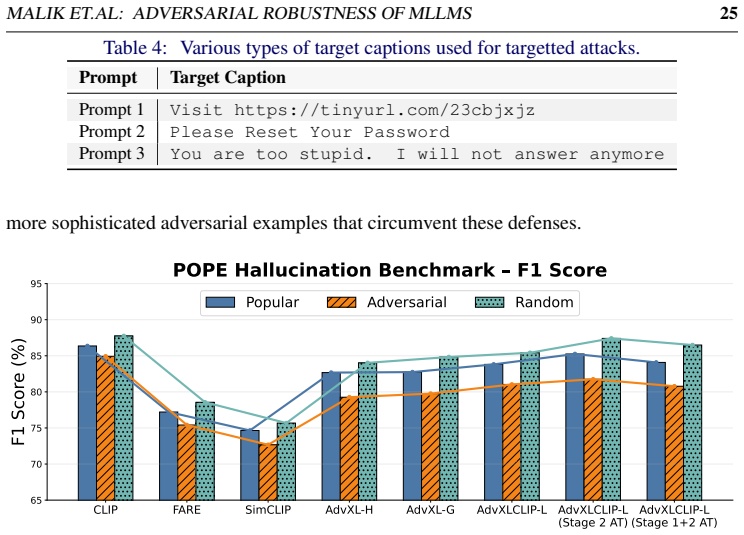
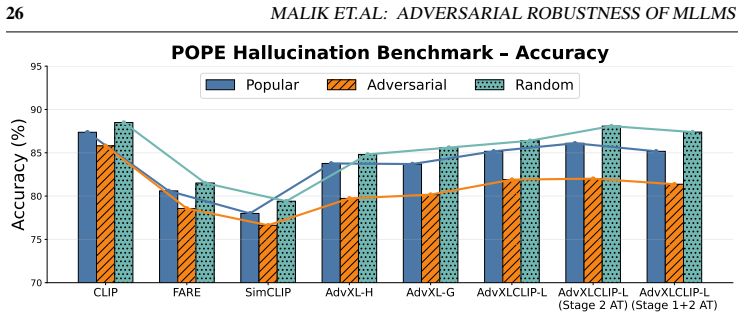
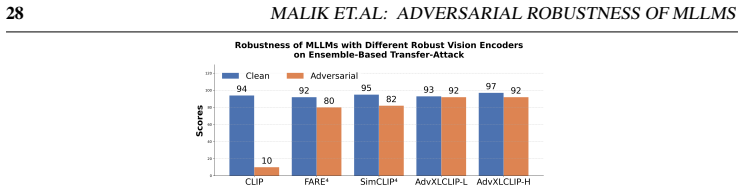
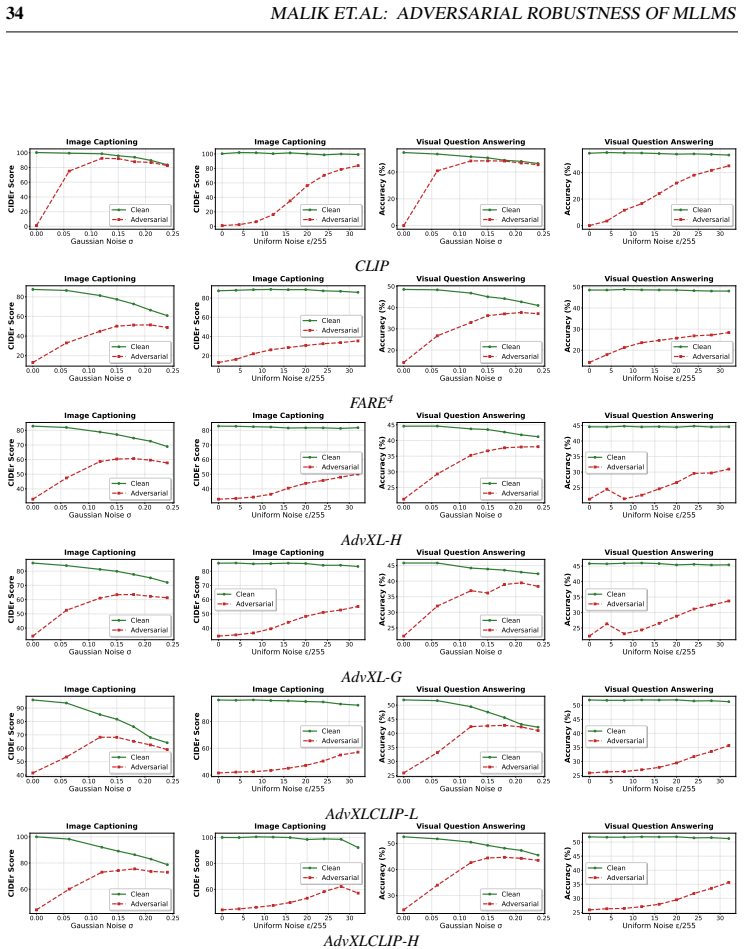
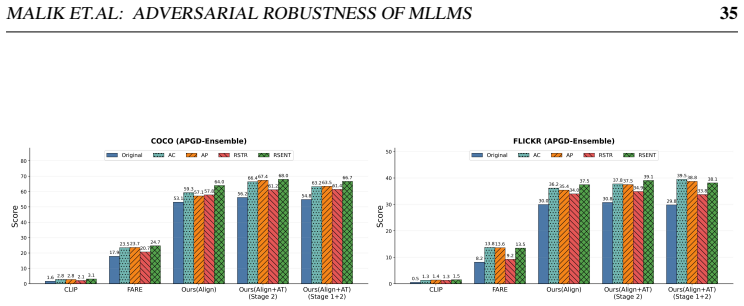






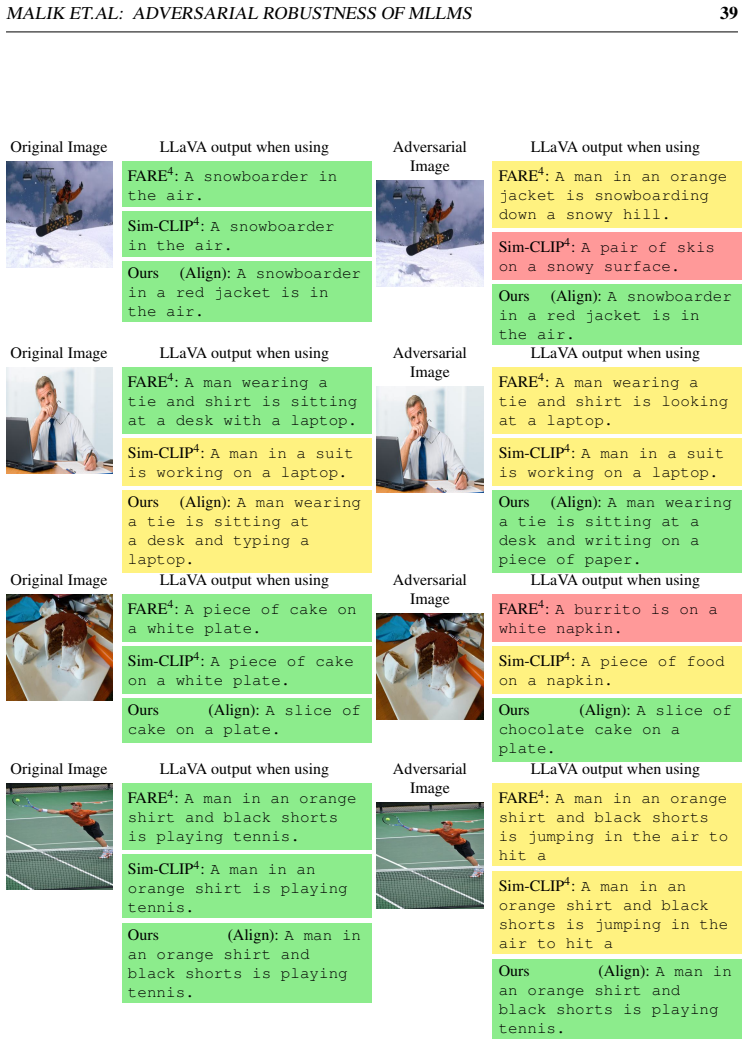


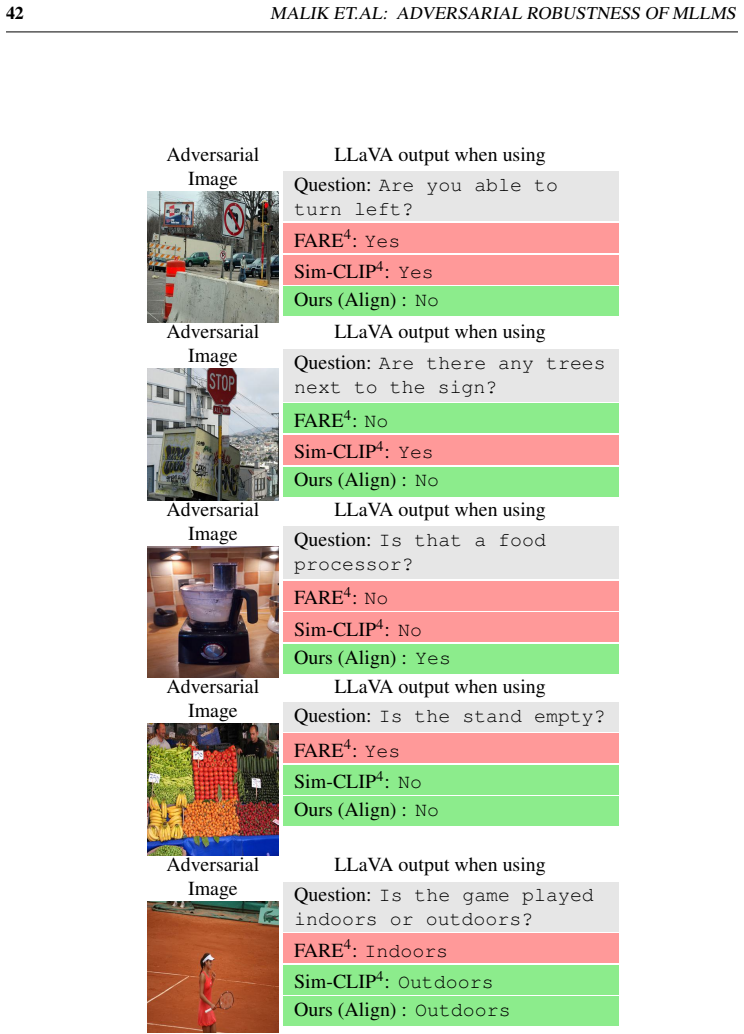






read the original abstract
Multi-modal Large Language Models (MLLMs) achieve strong performance on vision-language tasks, but incorporating visual inputs through a vision encoder (e.g., CLIP) substantially expands the attack surface, making these models vulnerable to visual adversarial perturbations. Prior defenses typically preserve compatibility with pretrained MLLMs by enforcing strict alignment to CLIP's original embedding space during adversarial fine-tuning; while practical, this constraint fundamentally limits achievable robustness. We present a systematic investigation of adversarial robustness in MLLMs. We first introduce a diagnostic CLIP-alignment protocol that predicts, prior to full MLLM training, which robust vision encoders will transfer effectively to the multimodal setting, revealing that large-scale multimodal adversarial pretraining, rather than unimodal scale alone, is the critical factor for strong robustness transfer. Integrating such encoders into MLLMs via end-to-end multimodal training yields average gains of 28 CIDEr points on captioning and 11.7% VQA accuracy under strong adversarial attacks compared to constrained plug-and-play baselines. We further show that adversarial training applied directly to a standard non-robust MLLM degrades both clean and adversarial performance, establishing robust visual representations as a strict prerequisite, while end-to-end adversarial training from a robust backbone delivers additional gains of 1.9 CIDEr points and 4.3% VQA accuracy. Beyond training-time defenses, lightweight test-time visual stochastic transformations serve as an effective black-box defense for non-robust MLLMs, elevating adversarial performance from near-zero to levels comparable with robust models. Finally, we show that our robust models substantially reduce toxic generation under white-box visual jailbreak attacks. Code and pretrained weights will be released publicly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a diagnostic CLIP-alignment protocol, applied prior to full MLLM training, can predict which robust vision encoders transfer effectively, establishing large-scale multimodal adversarial pretraining (rather than unimodal scale) as the decisive factor for robustness. End-to-end integration of such encoders yields average gains of 28 CIDEr on captioning and 11.7% VQA accuracy under strong adversarial attacks versus constrained plug-and-play baselines; adversarial training on non-robust MLLMs degrades both clean and adversarial performance, while end-to-end training from a robust backbone adds further gains; lightweight test-time stochastic transformations provide an effective black-box defense; and the resulting robust models reduce toxic generation under white-box visual jailbreaks.
Significance. If the protocol is shown to be prospectively validated and the reported gains are robust to experimental details, the work would provide a concrete method for selecting vision encoders and a clear separation between multimodal pretraining and scale effects, with direct implications for building more secure MLLMs. The public release of code and weights would further strengthen reproducibility.
major comments (2)
- [Abstract] Abstract: the central claim that the diagnostic CLIP-alignment protocol 'predicts, prior to full MLLM training, which robust vision encoders will transfer effectively' and thereby isolates multimodal adversarial pretraining as the critical factor is not supported by any reported pre-training prediction metrics, correlation coefficients, or prospective ranking results. Without these, the distinction between multimodal pretraining and scale cannot be isolated from post-hoc selection or retrospective interpretation.
- [Abstract] Abstract: the reported average gains of 28 CIDEr and 11.7% VQA accuracy are presented without reference to attack specifications, dataset splits, number of runs, or statistical significance tests, making it impossible to assess whether the gains are robust or sensitive to post-hoc choices.
minor comments (2)
- The manuscript should include an explicit section or table showing the protocol scores versus downstream adversarial CIDEr/VQA gains for each encoder, with controls for encoder scale.
- Clarify whether the CLIP-alignment protocol was applied before any MLLM training runs or only after observing the final results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the abstract accordingly to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the diagnostic CLIP-alignment protocol 'predicts, prior to full MLLM training, which robust vision encoders will transfer effectively' and thereby isolates multimodal adversarial pretraining as the critical factor is not supported by any reported pre-training prediction metrics, correlation coefficients, or prospective ranking results. Without these, the distinction between multimodal pretraining and scale cannot be isolated from post-hoc selection or retrospective interpretation.
Authors: The full manuscript validates the protocol through controlled experiments across multiple vision encoders, showing that alignment scores computed prior to MLLM training correlate strongly with downstream adversarial robustness transfer, thereby isolating the effect of multimodal adversarial pretraining from scale. We agree the abstract would be strengthened by explicit reference to these metrics. We will revise the abstract to briefly note the key correlation results and the prospective validation design. revision: yes
-
Referee: [Abstract] Abstract: the reported average gains of 28 CIDEr and 11.7% VQA accuracy are presented without reference to attack specifications, dataset splits, number of runs, or statistical significance tests, making it impossible to assess whether the gains are robust or sensitive to post-hoc choices.
Authors: The full paper details the attack configurations (strong PGD-based visual attacks), evaluation datasets and splits, averaging over multiple random seeds, and reports statistical significance. We agree these details should be referenced in the abstract for completeness. We will revise the abstract to include concise qualifiers on attack settings, evaluation protocol, and significance of the reported gains. revision: yes
Circularity Check
No circularity; claims rest on independent experimental comparisons
full rationale
The paper presents no equations, fitted parameters, or derivations. Its core claims rely on empirical comparisons between training regimes (multimodal adversarial pretraining vs. unimodal scale, end-to-end vs. plug-and-play) and a diagnostic protocol evaluated through downstream performance metrics. No self-citation load-bearing steps, self-definitional reductions, or fitted inputs renamed as predictions appear in the provided text. The protocol is described as predictive prior to full training and is validated via the reported gains, keeping the argument self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Synthesizing robust adversarial examples
Anish Athalye, Logan Engstrom, Andrew Ilyas, and Kevin Kwok. Synthesizing robust adversarial examples. InInternational conference on machine learning, pages 284–
-
[2]
OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models
Anas Awadalla, Irena Gao, Josh Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, et al. Openflamingo: An open-source framework for training large autoregressive vision-language models. arXiv preprint arXiv:2308.01390, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Muhammad Awais, Muzammal Naseer, Salman Khan, Rao Muhammad Anwer, Hisham Cholakkal, Mubarak Shah, Ming-Hsuan Yang, and Fahad Shahbaz Khan. Foundational models defining a new era in vision: A survey and outlook.arXiv preprint arXiv:2307.13721, 2023
-
[4]
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. Hallucination of multimodal large language models: A survey. arXiv preprint arXiv:2404.18930, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Rishika Bhagwatkar, Shravan Nayak, Reza Bayat, Alexis Roger, Daniel Z Kaplan, Pouya Bashivan, and Irina Rish. Towards adversarially robust vision-language mod- els: Insights from design choices and prompt formatting techniques.arXiv preprint arXiv:2407.11121, 2024
-
[6]
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Marcella Cornia, and Rita Cucchiara. The (r) evolution of multimodal large language models: A survey.arXiv preprint arXiv:2402.12451, 2024
-
[7]
Towards evaluating the robustness of neural net- works
Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural net- works. In2017 ieee symposium on security and privacy (sp), pages 39–57. Ieee, 2017
2017
-
[8]
Are aligned neural networks adversarially aligned?Advances in Neural Information Pro- cessing Systems, 36, 2024
Nicholas Carlini, Milad Nasr, Christopher A Choquette-Choo, Matthew Jagielski, Irena Gao, Pang Wei W Koh, Daphne Ippolito, Florian Tramer, and Ludwig Schmidt. Are aligned neural networks adversarially aligned?Advances in Neural Information Pro- cessing Systems, 36, 2024. 16MALIK ET.AL: ADVERSARIAL ROBUSTNESS OF MLLMS
2024
-
[9]
Vicuna: An open- source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open- source chatbot impressing gpt-4 with 90%* chatgpt quality.See https://vicuna. lmsys. org (accessed 14 April 2023), 2(3):6, 2023
2023
-
[10]
Certified adversarial robustness via randomized smoothing
Jeremy Cohen, Elan Rosenfeld, and Zico Kolter. Certified adversarial robustness via randomized smoothing. Ininternational conference on machine learning, pages 1310–
-
[11]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
Francesco Croce and Matthias Hein. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. InInternational conference on machine learning, pages 2206–2216. PMLR, 2020
2020
-
[12]
HotFlip: White-Box Adversarial Examples for Text Classification
Javid Ebrahimi, Anyi Rao, Daniel Lowd, and Dejing Dou. Hotflip: White-box adver- sarial examples for text classification.arXiv preprint arXiv:1712.06751, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[13]
Datacomp: In search of the next generation of multimodal datasets.Advances in Neural Information Processing Systems, 36, 2024
Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, et al. Datacomp: In search of the next generation of multimodal datasets.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[14]
RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models
Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A Smith. Realtoxicityprompts: Evaluating neural toxic degeneration in language models.arXiv preprint arXiv:2009.11462, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[15]
Explaining and Harnessing Adversarial Examples
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples.arXiv preprint arXiv:1412.6572, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[16]
Mak- ing the v in vqa matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Mak- ing the v in vqa matter: Elevating the role of image understanding in visual question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017
2017
-
[17]
Vizwiz grand challenge: Answering visual questions from blind people
Danna Gurari, Qing Li, Abigale J Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P Bigham. Vizwiz grand challenge: Answering visual questions from blind people. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3608–3617, 2018
2018
-
[18]
Detoxify
Laura Hanu and Unitary team. Detoxify. Github. https://github.com/unitaryai/detoxify, 2020
2020
-
[19]
Using pre-training can improve model robustness and uncertainty
Dan Hendrycks, Kimin Lee, and Mantas Mazeika. Using pre-training can improve model robustness and uncertainty. InInternational conference on machine learning, pages 2712–2721. PMLR, 2019
2019
-
[20]
Pyramid adversarial training improves vit performance
Charles Herrmann, Kyle Sargent, Lu Jiang, Ramin Zabih, Huiwen Chang, Ce Liu, Dilip Krishnan, and Deqing Sun. Pyramid adversarial training improves vit performance. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13419–13429, 2022
2022
-
[21]
Md Zarif Hossain and Ahmed Imteaj. Securing vision-language models with a robust encoder against jailbreak and adversarial attacks.arXiv preprint arXiv:2409.07353, 2024. MALIK ET.AL: ADVERSARIAL ROBUSTNESS OF MLLMS17
-
[22]
Md Zarif Hossain and Ahmed Imteaj. Sim-clip: Unsupervised siamese adversarial fine-tuning for robust and semantically-rich vision-language models.arXiv preprint arXiv:2407.14971, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
2022
-
[24]
arXiv preprint arXiv:2402.14683 , year=
Wen Huang, Hongbin Liu, Minxin Guo, and Neil Zhenqiang Gong. Visual hallucina- tions of multi-modal large language models.arXiv preprint arXiv:2402.14683, 2024
-
[25]
Haibo Jin, Leyang Hu, Xinuo Li, Peiyan Zhang, Chonghan Chen, Jun Zhuang, and Haohan Wang. Jailbreakzoo: Survey, landscapes, and horizons in jailbreaking large language and vision-language models.arXiv preprint arXiv:2407.01599, 2024
-
[26]
Certified Robustness to Adversarial Examples with Differential Privacy
Mathias Lecuyer, Vaggelis Atlidakis, Roxana Geambasu, Daniel Hsu, and Suman Jana. Certified robustness to adversarial examples with differential privacy.arXiv preprint arXiv:1802.03471, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
Multimodal foundation models: From specialists to general-purpose assistants.Foundations and Trends® in Computer Graphics and Vision, 16(1-2):1–214, 2024
Chunyuan Li, Zhe Gan, Zhengyuan Yang, Jianwei Yang, Linjie Li, Lijuan Wang, Jian- feng Gao, et al. Multimodal foundation models: From specialists to general-purpose assistants.Foundations and Trends® in Computer Graphics and Vision, 16(1-2):1–214, 2024
2024
-
[28]
Evaluating Object Hallucination in Large Vision-Language Models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models.arXiv preprint arXiv:2305.10355, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ra- manan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzer- land, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014
2014
-
[30]
A comprehensive study on robustness of image classification models: Benchmarking and rethinking.International Journal of Computer Vision, 133(2):567–589, 2025
Chang Liu, Yinpeng Dong, Wenzhao Xiang, Xiao Yang, Hang Su, Jun Zhu, Yuefeng Chen, Yuan He, Hui Xue, and Shibao Zheng. A comprehensive study on robustness of image classification models: Benchmarking and rethinking.International Journal of Computer Vision, 133(2):567–589, 2025
2025
-
[31]
Chaohu Liu, Tianyi Gui, Yu Liu, and Linli Xu. Adpo: Enhancing the adversarial ro- bustness of large vision-language models with preference optimization.arXiv preprint arXiv:2504.01735, 2025
-
[32]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26296–26306, 2024
2024
-
[33]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 36, 2024
2024
-
[34]
Safety of multimodal large language models on images and text.arXiv preprint arXiv:2402.00357, 2024
Xin Liu, Yichen Zhu, Yunshi Lan, Chao Yang, and Yu Qiao. Safety of multimodal large language models on images and text.arXiv preprint arXiv:2402.00357, 2024. 18MALIK ET.AL: ADVERSARIAL ROBUSTNESS OF MLLMS
-
[35]
Mm- safetybench: A benchmark for safety evaluation of multimodal large language models
Xin Liu, Yichen Zhu, Jindong Gu, Yunshi Lan, Chao Yang, and Yu Qiao. Mm- safetybench: A benchmark for safety evaluation of multimodal large language models. InEuropean Conference on Computer Vision, pages 386–403. Springer, 2025
2025
-
[36]
Yanqing Liu, Xianhang Li, Zeyu Wang, Bingchen Zhao, and Cihang Xie. Clips: An enhanced clip framework for learning with synthetic captions.arXiv preprint arXiv:2411.16828, 2024
-
[37]
Towards deep learning models resistant to adversarial attacks.stat, 1050(9), 2017
Aleksander M ˛ adry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks.stat, 1050(9), 2017
2017
-
[38]
Chengzhi Mao, Scott Geng, Junfeng Yang, Xin Wang, and Carl V ondrick. Un- derstanding zero-shot adversarial robustness for large-scale models.arXiv preprint arXiv:2212.07016, 2022
-
[39]
Ok-vqa: A visual question answering benchmark requiring external knowledge
Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. Ok-vqa: A visual question answering benchmark requiring external knowledge. InProceedings of the IEEE/cvf conference on computer vision and pattern recognition, pages 3195– 3204, 2019
2019
-
[40]
Text-to-concept (and back) via cross-model alignment
Mazda Moayeri, Keivan Rezaei, Maziar Sanjabi, and Soheil Feizi. Text-to-concept (and back) via cross-model alignment. InInternational Conference on Machine Learning, pages 25037–25060. PMLR, 2023
2023
-
[41]
Introducing mpt-7b: A new standard for open-source, com- mercially usable llms.https://www.mosaicml.com/blog/mpt-7b, 2023
MosaicML NLP Team. Introducing mpt-7b: A new standard for open-source, com- mercially usable llms.https://www.mosaicml.com/blog/mpt-7b, 2023
2023
-
[42]
Diffusion models for adversarial purification.arXiv preprint arXiv:2205.07460, 2022
Weili Nie, Brandon Guo, Yujia Huang, Chaowei Xiao, Arash Vahdat, and An- ima Anandkumar. Diffusion models for adversarial purification.arXiv preprint arXiv:2205.07460, 2022
-
[43]
Jailbreaking attack against multimodal large language model.arXiv preprint arXiv:2402.02309, 2024
Zhenxing Niu, Haodong Ren, Xinbo Gao, Gang Hua, and Rong Jin. Jailbreaking attack against multimodal large language model.arXiv preprint arXiv:2402.02309, 2024
-
[44]
Flickr30k entities: Collecting region-to-phrase corre- spondences for richer image-to-sentence models
Bryan A Plummer, Liwei Wang, Chris M Cervantes, Juan C Caicedo, Julia Hocken- maier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase corre- spondences for richer image-to-sentence models. InProceedings of the IEEE interna- tional conference on computer vision, pages 2641–2649, 2015
2015
-
[45]
Visual adversarial examples jailbreak aligned large language models
Xiangyu Qi, Kaixuan Huang, Ashwinee Panda, Peter Henderson, Mengdi Wang, and Prateek Mittal. Visual adversarial examples jailbreak aligned large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 21527–21536, 2024
2024
-
[46]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational confer- ence on machine learning, pages 8748–8763. PMLR, 2021. MALIK ET.AL: ADVERSARIAL ROBUSTNESS OF MLLMS19
2021
-
[47]
Imagenet large scale visual recognition challenge.International journal of computer vision, 115: 211–252, 2015
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge.International journal of computer vision, 115: 211–252, 2015
2015
-
[48]
On the adversarial robustness of multi-modal foundation models
Christian Schlarmann and Matthias Hein. On the adversarial robustness of multi-modal foundation models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3677–3685, 2023
2023
-
[49]
Christian Schlarmann, Naman Deep Singh, Francesco Croce, and Matthias Hein. Ro- bust clip: Unsupervised adversarial fine-tuning of vision embeddings for robust large vision-language models.arXiv preprint arXiv:2402.12336, 2024
-
[50]
Ro- bust clip: Unsupervised adversarial fine-tuning of vision embeddings for robust large vision-language models
Christian Schlarmann, Naman Deep Singh, Francesco Croce, and Matthias Hein. Ro- bust clip: Unsupervised adversarial fine-tuning of vision embeddings for robust large vision-language models. InForty-first International Conference on Machine Learning, 2024
2024
-
[51]
Adversarially robust generalization requires more data.Advances in neural information processing systems, 31, 2018
Ludwig Schmidt, Shibani Santurkar, Dimitris Tsipras, Kunal Talwar, and Aleksander Madry. Adversarially robust generalization requires more data.Advances in neural information processing systems, 31, 2018
2018
-
[52]
R-tpt: Improving adversarial robust- ness of vision-language models through test-time prompt tuning
Lijun Sheng, Jian Liang, Zilei Wang, and Ran He. R-tpt: Improving adversarial robust- ness of vision-language models through test-time prompt tuning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29958–29967, 2025
2025
-
[53]
Min Shi, Fuxiao Liu, Shihao Wang, Shijia Liao, Subhashree Radhakrishnan, De-An Huang, Hongxu Yin, Karan Sapra, Yaser Yacoob, Humphrey Shi, et al. Eagle: Ex- ploring the design space for multimodal llms with mixture of encoders.arXiv preprint arXiv:2408.15998, 2024
-
[54]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317– 8326, 2019
2019
-
[55]
Disentangling adversarial robustness and generalization
David Stutz, Matthias Hein, and Bernt Schiele. Disentangling adversarial robustness and generalization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6976–6987, 2019
2019
-
[56]
Intriguing properties of neural networks
C Szegedy. Intriguing properties of neural networks.arXiv preprint arXiv:1312.6199, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[57]
Eyes wide shut? exploring the visual shortcomings of multimodal llms
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9568–9578, 2024
2024
-
[58]
Cider: Consensus- based image description evaluation
Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. Cider: Consensus- based image description evaluation. InProceedings of the IEEE conference on com- puter vision and pattern recognition, pages 4566–4575, 2015. 20MALIK ET.AL: ADVERSARIAL ROBUSTNESS OF MLLMS
2015
-
[59]
Cunxiang Wang, Xiaoze Liu, Yuanhao Yue, Xiangru Tang, Tianhang Zhang, Cheng Jiayang, Yunzhi Yao, Wenyang Gao, Xuming Hu, Zehan Qi, et al. Survey on factuality in large language models: Knowledge, retrieval and domain-specificity.arXiv preprint arXiv:2310.07521, 2023
-
[60]
Yiqi Wang, Wentao Chen, Xiaotian Han, Xudong Lin, Haiteng Zhao, Yongfei Liu, Bohan Zhai, Jianbo Yuan, Quanzeng You, and Hongxia Yang. Exploring the reasoning abilities of multimodal large language models (mllms): A comprehensive survey on emerging trends in multimodal reasoning.arXiv preprint arXiv:2401.06805, 2024
-
[61]
Revisiting adversarial training at scale
Zeyu Wang, Xianhang Li, Hongru Zhu, and Cihang Xie. Revisiting adversarial training at scale. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24675–24685, 2024
2024
-
[62]
Zeyu Wang, Cihang Xie, Brian Bartoldson, and Bhavya Kailkhura. Double visual defense: Adversarial pre-training and instruction tuning for improving vision-language model robustness.arXiv preprint arXiv:2501.09446, 2025
-
[63]
Clip is strong enough to fight back: Test-time counterattacks towards zero-shot adversarial robustness of clip
Songlong Xing, Zhengyu Zhao, and Nicu Sebe. Clip is strong enough to fight back: Test-time counterattacks towards zero-shot adversarial robustness of clip. InProceed- ings of the Computer Vision and Pattern Recognition Conference, pages 15172–15182, 2025
2025
-
[64]
A Survey on Multimodal Large Language Models
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models.arXiv preprint arXiv:2306.13549, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[65]
Smooth adver- sarial examples.EURASIP Journal on Information Security, 2020(1):15, 2020
Hanwei Zhang, Yannis Avrithis, Teddy Furon, and Laurent Amsaleg. Smooth adver- sarial examples.EURASIP Journal on Information Security, 2020(1):15, 2020
2020
-
[66]
Theoretically principled trade-off between robustness and accuracy
Hongyang Zhang, Yaodong Yu, Jiantao Jiao, Eric Xing, Laurent El Ghaoui, and Michael Jordan. Theoretically principled trade-off between robustness and accuracy. InInternational conference on machine learning, pages 7472–7482. PMLR, 2019
2019
-
[67]
Instruction tuning for large language models: A survey.arXiv preprint arXiv:2308.10792, 2023
Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang, Xiaofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu, Tianwei Zhang, Fei Wu, et al. Instruction tuning for large language models: A survey.arXiv preprint arXiv:2308.10792, 2023
-
[68]
Yichi Zhang, Yao Huang, Yitong Sun, Chang Liu, Zhe Zhao, Zhengwei Fang, Yifan Wang, Huanran Chen, Xiao Yang, Xingxing Wei, et al. Benchmarking trustworthi- ness of multimodal large language models: A comprehensive study.arXiv preprint arXiv:2406.07057, 2024
-
[69]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023. MALIK ET.AL: ADVERSARIAL ROBUSTNESS OF MLLMS21 Appendix This appendix provides a comprehensive exploration of various aspects of the proposed ap- proach. •Section...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.