BigFinanceBench: A Workflow-Grounded Benchmark for Financial-Research Agents
Pith reviewed 2026-06-28 09:33 UTC · model grok-4.3
The pith
A new benchmark measures AI financial agents on complete auditable derivations using expert rubrics rather than final answers alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
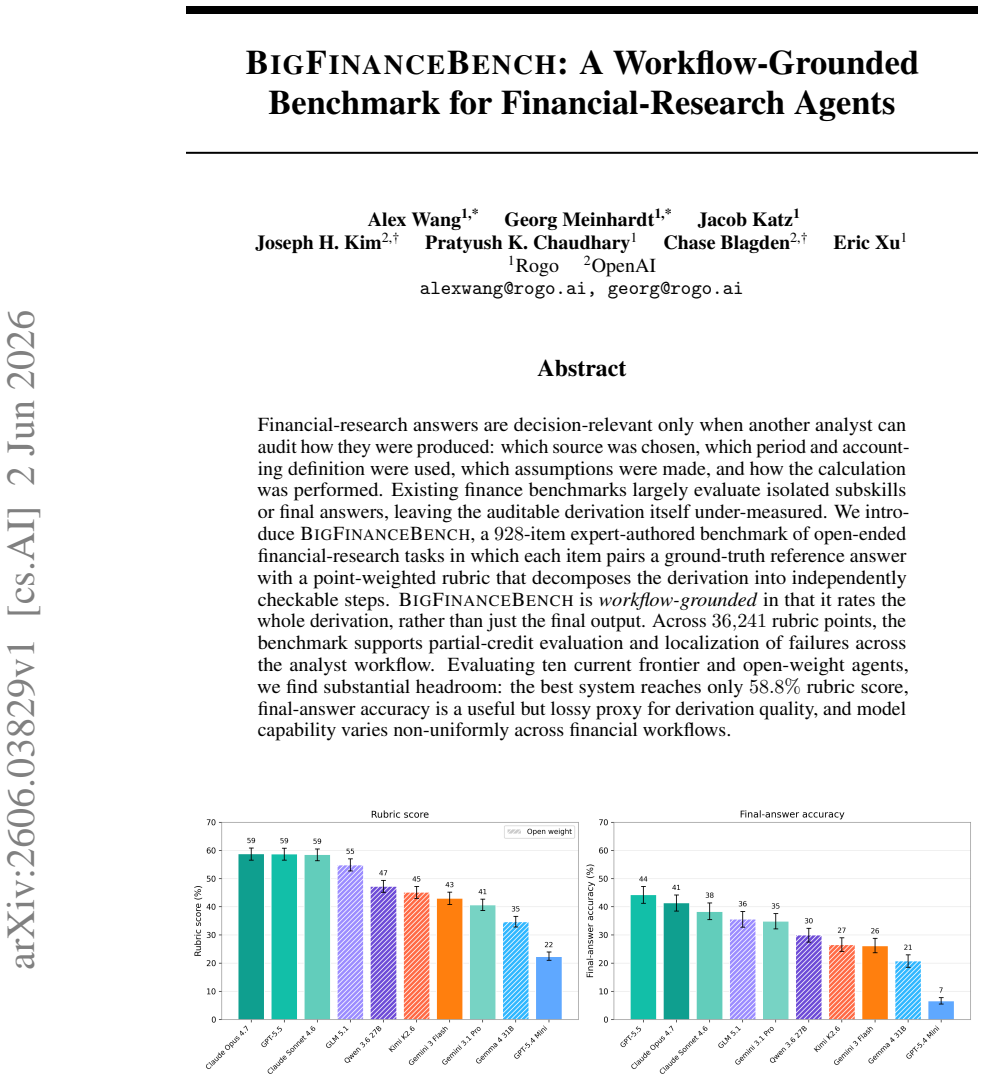
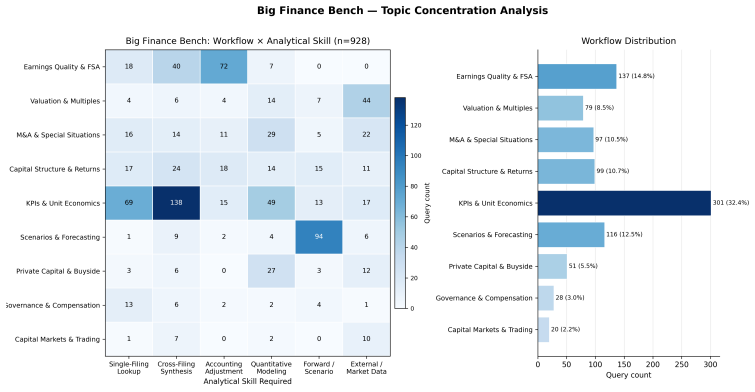
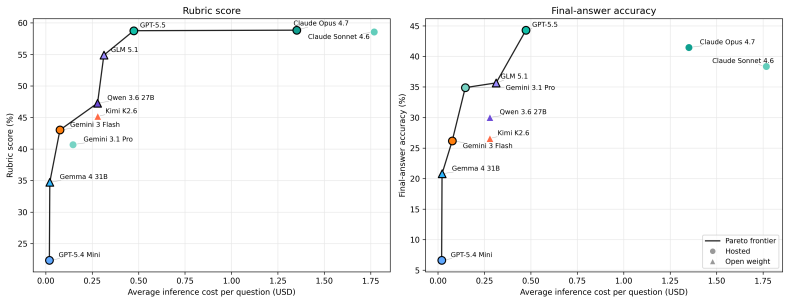
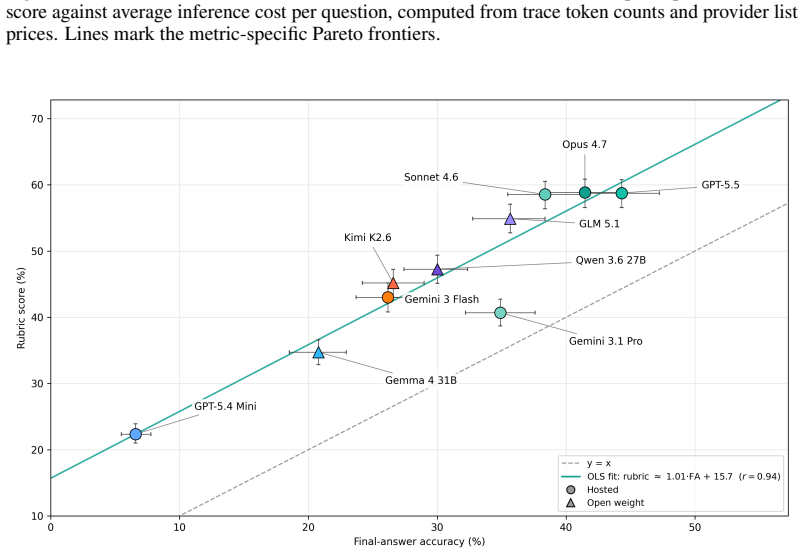
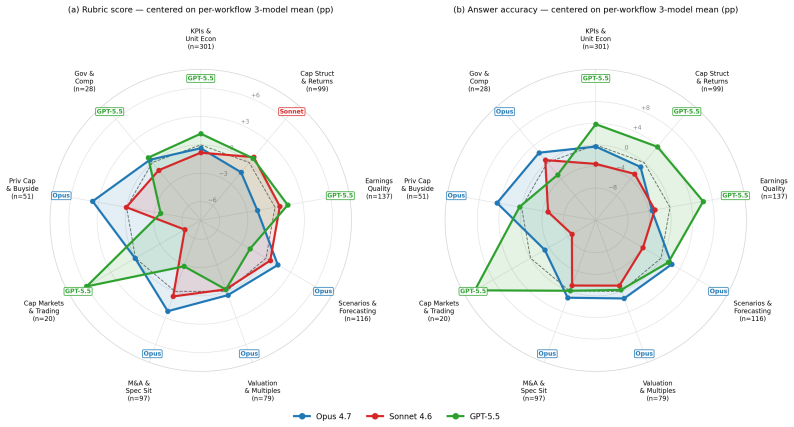
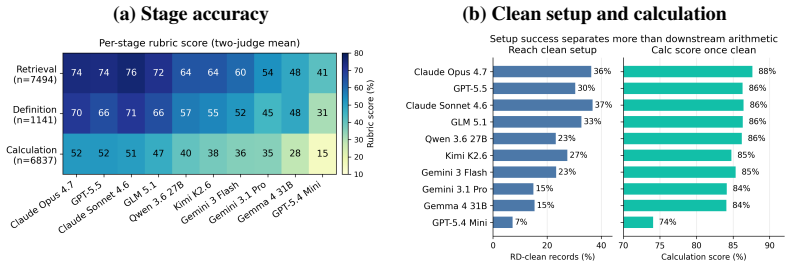
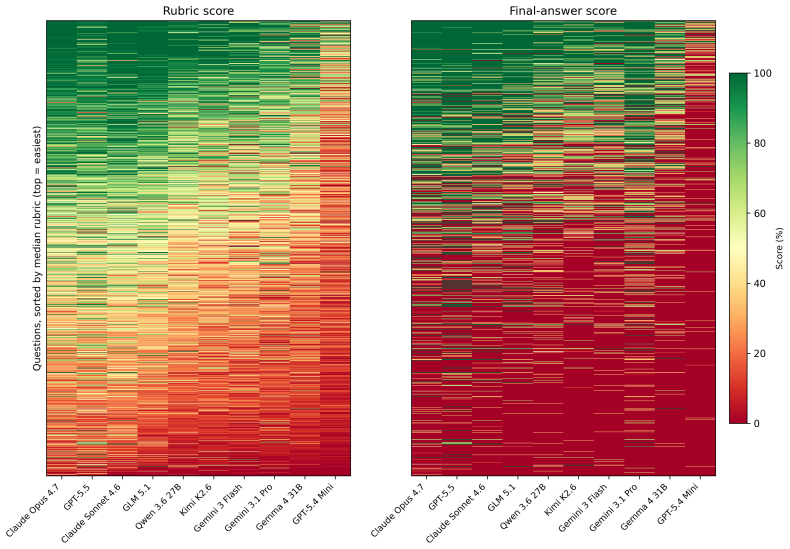
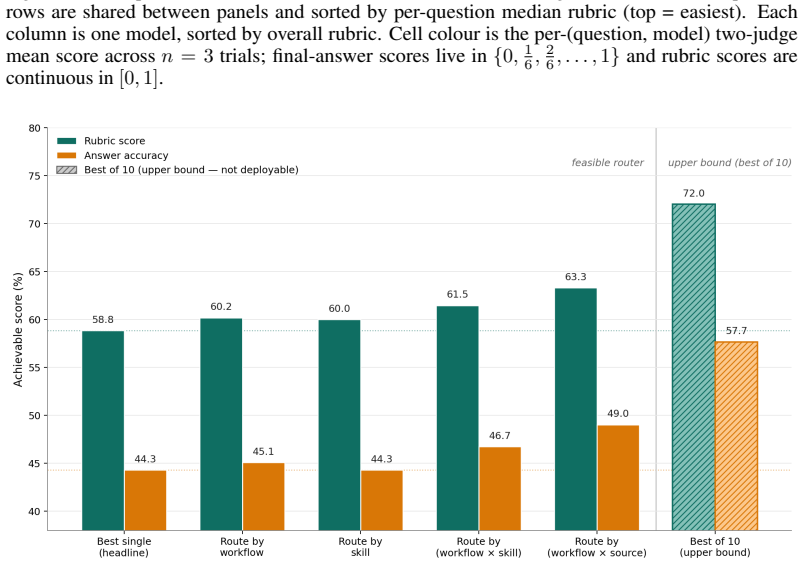
BigFinanceBench is a workflow-grounded benchmark of 928 open-ended financial-research tasks in which each item supplies both a reference answer and a point-weighted rubric that decomposes the required derivation into checkable steps. Across 36,241 rubric points the benchmark therefore supports partial-credit scoring and failure localization along the analyst workflow. Evaluation of ten current agents shows the best system attaining only 58.8 percent rubric score, demonstrates that final-answer accuracy is an incomplete proxy for derivation quality, and reveals non-uniform capability variation across financial workflows.
What carries the argument
Point-weighted rubrics that decompose each financial-research derivation into independently checkable steps and thereby enable partial-credit evaluation of the full workflow.
If this is right
- Final-answer accuracy alone is an incomplete measure of agent performance on financial tasks.
- Agent capability is not uniform; some workflows expose larger gaps than others.
- Substantial headroom remains for agents that can produce auditable derivations.
- The benchmark permits localization of specific failure points within the research workflow.
Where Pith is reading between the lines
- Rubric-based workflow evaluation could be adapted to other domains that require traceable reasoning, such as legal analysis or scientific literature review.
- Training regimes focused on step-by-step derivation rather than end answers might close the observed gaps more effectively than scaling alone.
- Extending the benchmark to include live data feeds or multi-document synthesis would test whether current headroom persists under more realistic conditions.
Load-bearing premise
The expert-authored rubrics supply a reliable, comprehensive, and unbiased breakdown of what constitutes high-quality financial-research derivation.
What would settle it
A study in which independent human experts score the same agent outputs once with the provided rubrics and once with holistic judgment, then find low agreement between the two methods, would show the rubrics do not capture derivation quality.
Figures



read the original abstract
Financial-research answers are decision-relevant only when another analyst can audit how they were produced: which source was chosen, which period and accounting definition were used, which assumptions were made, and how the calculation was performed. Existing finance benchmarks largely evaluate isolated subskills or final answers, leaving the auditable derivation itself under-measured. We introduce BigFinanceBench, a 928-item expert-authored benchmark of open-ended financial-research tasks in which each item pairs a ground-truth reference answer with a point-weighted rubric that decomposes the derivation into independently checkable steps. BigFinanceBench is workflow-grounded in that it evaluates the full derivation rather than only the final output. Across 36,241 rubric points, the benchmark supports partial-credit evaluation and localization of failures across the analyst workflow. Evaluating ten current frontier and open-weight agents, we find substantial headroom: the best system reaches only 58.8% rubric score, final-answer accuracy is a useful but lossy proxy for derivation quality, and model capability varies non-uniformly across financial workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BigFinanceBench, a 928-item benchmark of open-ended financial-research tasks. Each item includes a ground-truth reference answer paired with an expert-authored, point-weighted rubric that decomposes the derivation into independently checkable steps (totaling 36,241 rubric points). The benchmark is positioned as workflow-grounded, enabling partial-credit evaluation of full derivations rather than isolated subskills or final answers alone. Evaluation of ten frontier and open-weight agents shows the best system achieves only 58.8% rubric score, that final-answer accuracy is a lossy proxy for derivation quality, and that model capability varies non-uniformly across financial workflows.
Significance. If the rubric decompositions prove reliable and comprehensive, the benchmark would address a genuine gap in existing finance evaluations by measuring auditable derivation quality at scale. The reported headroom (58.8% ceiling) and the distinction between final-answer accuracy and rubric score would supply concrete, falsifiable targets for agent development in a high-stakes domain.
major comments (1)
- [Abstract and methods description of rubric construction] The central claims (58.8% best score, final-answer accuracy as lossy proxy, non-uniform workflow variation) rest on the assumption that the 36,241 point-weighted rubric items constitute an objective, reliable decomposition of derivation quality. The manuscript describes expert authorship and point weighting but reports no inter-rater agreement statistics, no external correlation with independent expert quality judgments, and no sensitivity analysis to rubric authoring choices. Without such validation, both absolute scores and comparative agent rankings remain sensitive to the specific rubric construction rather than to agent behavior alone.
minor comments (1)
- [Abstract] The abstract states benchmark size, rubric count, and agent scores but supplies no methods details on how the 58.8% figure or rubric reliability was established; this should be expanded in the main text even if full methods appear later.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for rubric validation. This is a substantive point that strengthens the benchmark's credibility. We address it directly below and commit to revisions that add empirical support for rubric reliability.
read point-by-point responses
-
Referee: [Abstract and methods description of rubric construction] The central claims (58.8% best score, final-answer accuracy as lossy proxy, non-uniform workflow variation) rest on the assumption that the 36,241 point-weighted rubric items constitute an objective, reliable decomposition of derivation quality. The manuscript describes expert authorship and point weighting but reports no inter-rater agreement statistics, no external correlation with independent expert quality judgments, and no sensitivity analysis to rubric authoring choices. Without such validation, both absolute scores and comparative agent rankings remain sensitive to the specific rubric construction rather than to agent behavior alone.
Authors: We agree that inter-rater agreement, external correlation, and sensitivity analysis are important for establishing that rubric scores reflect agent behavior rather than authoring artifacts. The current manuscript relies on expert authorship by domain specialists and workflow-grounded decomposition but does not quantify reliability. In the revised manuscript we will add: (1) inter-rater agreement on a stratified sample of 100 tasks scored independently by a second financial expert, reporting Cohen's kappa and percentage agreement; (2) correlation between rubric scores and an independent expert's holistic quality rating on the same sample; and (3) a brief sensitivity discussion noting that rubric points were derived from standard financial-analysis workflows (e.g., DCF, ratio analysis) with explicit point allocation rules. These additions will directly support the reported 58.8% ceiling and the claim that final-answer accuracy is lossy. We view this as a necessary major revision. revision: yes
Circularity Check
No significant circularity; benchmark and evaluations are self-contained
full rationale
The paper introduces a new expert-authored benchmark (BigFinanceBench) consisting of 928 tasks with point-weighted rubrics and reports direct evaluations of ten agents on those rubrics. No equations, fitted parameters, or predictions are defined in terms of the target results; the central claims (58.8% best score, final-answer accuracy as lossy proxy, non-uniform variation) follow from straightforward scoring of agent outputs against the provided rubrics. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify the benchmark construction or results. The work is externally falsifiable via the released benchmark items and does not reduce any reported quantity to its own inputs by construction.
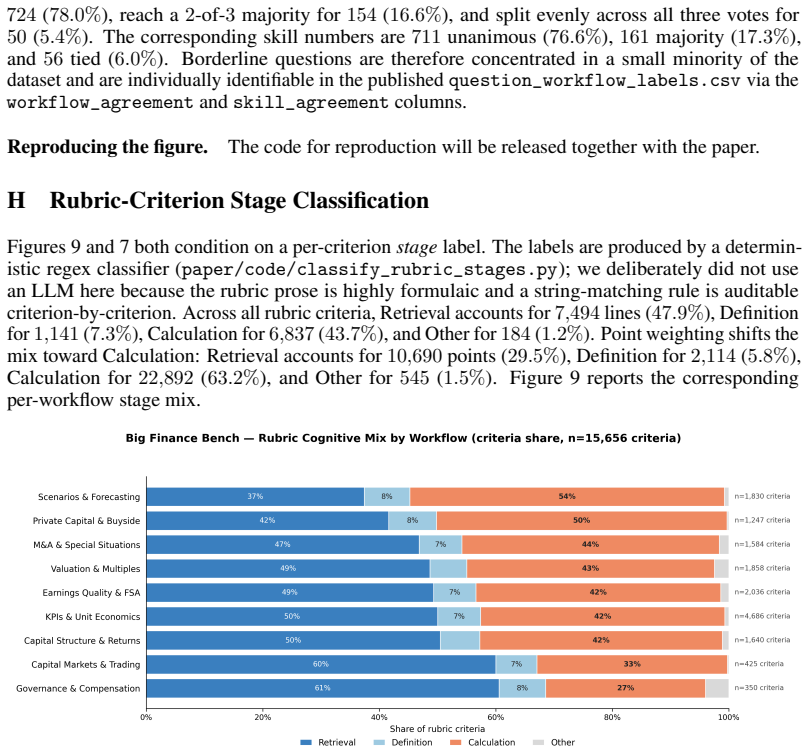
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert-authored rubrics can decompose financial research derivations into independently checkable steps with reliable point weights.
Reference graph
Works this paper leans on
-
[1]
FinTradeBench: A Financial Reasoning Benchmark for LLMs
Yogesh Agrawal, Aniruddha Dutta, Md Mahadi Hasan, Santu Karmaker, and Aritra Dutta. Fin- TradeBench: A financial reasoning benchmark for LLMs.arXiv preprint arXiv:2603.19225,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Afra Feyza Akyürek, Advait Gosai, Chen Bo Calvin Zhang, Vipul Gupta, Jaehwan Jeong, Anisha Gunjal, Tahseen Rabbani, Maria Mazzone, David Randolph, Mohammad Mahmoudi Meymand, et al. PRBench: Large-scale expert rubrics for evaluating high-stakes professional reasoning.arXiv preprint arXiv:2511.11562,
-
[3]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
Rahul K Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Quiñonero-Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, et al. Health- Bench: Evaluating large language models towards improved human health.arXiv preprint arXiv:2505.08775,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Antoine Bigeard, Langston Nashold, Rayan Krishnan, and Shirley Wu. Finance Agent Benchmark: Benchmarking LLMs on real-world financial research tasks.arXiv preprint arXiv:2508.00828,
-
[5]
FinQA: A dataset of numerical reasoning over financial data
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan R Routledge, et al. FinQA: A dataset of numerical reasoning over financial data. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3697–3711,
2021
-
[6]
FinDER: Financial dataset for question answering and evaluating retrieval-augmented generation
Chanyeol Choi, Jihoon Kwon, Jaeseon Ha, Hojun Choi, Chaewoon Kim, Yongjae Lee, Jy-yong Sohn, and Alejandro Lopez-Lira. FinDER: Financial dataset for question answering and evaluating retrieval-augmented generation. InProceedings of the 6th ACM International Conference on AI in Finance, pages 638–646, 2025a. Chanyeol Choi, Jihoon Kwon, Alejandro Lopez-Lira...
2025
-
[7]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Yunzhong He, Bing Liu, and Sean Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains.arXiv preprint arXiv:2507.17746,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[9]
Zenan Huang, Yihong Zhuang, Guoshan Lu, Zeyu Qin, Haokai Xu, Tianyu Zhao, Ru Peng, Jiaqi Hu, Zhanming Shen, Xiaomeng Hu, et al. Reinforcement learning with rubric anchors.arXiv preprint arXiv:2508.12790,
-
[10]
FinanceBench: A New Benchmark for Financial Question Answering
10 Pranab Islam, Anand Kannappan, Douwe Kiela, Rebecca Qian, Nino Scherrer, and Bertie Vidgen. Fi- nanceBench: A new benchmark for financial question answering.arXiv preprint arXiv:2311.11944,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
FinRetrieval: A benchmark for financial data retrieval by AI agents
Eric Y Kim and Jie Huang. FinRetrieval: A benchmark for financial data retrieval by AI agents. arXiv preprint arXiv:2603.04403,
-
[12]
ToolSandbox: A stateful, conversational, interactive evalua- tion benchmark for LLM tool use capabilities
Jiarui Lu, Thomas Holleis, Yizhe Zhang, Bernhard Aumayer, Feng Nan, Haoping Bai, Shuang Ma, Shen Ma, Mengyu Li, Guoli Yin, et al. ToolSandbox: A stateful, conversational, interactive evalua- tion benchmark for LLM tool use capabilities. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 1160–1183,
2025
-
[13]
Xing Han Lù, Amirhossein Kazemnejad, Nicholas Meade, Arkil Patel, Dongchan Shin, Alejandra Zambrano, Karolina Sta´nczak, Peter Shaw, Christopher J Pal, and Siva Reddy. AgentRewardBench: Evaluating automatic evaluations of web agent trajectories.arXiv preprint arXiv:2504.08942,
-
[14]
Remote labor index: Measuring AI automation of remote work.arXiv preprint arXiv:2510.26787,
Mantas Mazeika, Alice Gatti, Cristina Menghini, Udari Madhushani Sehwag, Shivam Singhal, Yury Orlovskiy, Steven Basart, Manasi Sharma, Denis Peskoff, Elaine Lau, et al. Remote labor index: Measuring AI automation of remote work.arXiv preprint arXiv:2510.26787,
-
[15]
Samuel Miserendino, Michele Wang, Tejal Patwardhan, and Johannes Heidecke. SWE-Lancer: Can frontier LLMs earn $1 million from real-world freelance software engineering?arXiv preprint arXiv:2502.12115,
-
[16]
ToolComp: A multi-tool reasoning & process supervision benchmark.arXiv preprint arXiv:2501.01290,
Vaskar Nath, Pranav Raja, Claire Yoon, and Sean Hendryx. ToolComp: A multi-tool reasoning & process supervision benchmark.arXiv preprint arXiv:2501.01290,
-
[17]
GDPval: Evaluating AI Model Performance on Real-World Economically Valuable Tasks
Tejal Patwardhan, Rachel Dias, Elizabeth Proehl, Grace Kim, Michele Wang, Olivia Watkins, Simón Posada Fishman, Marwan Aljubeh, Phoebe Thacker, Laurance Fauconnet, et al. GDPval: Evaluating AI model performance on real-world economically valuable tasks.arXiv preprint arXiv:2510.04374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. GPQA: A graduate-level google-proof q&a benchmark. arXiv preprint arXiv:2311.12022,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
The AI productivity index (APEX).arXiv preprint arXiv:2509.25721,
Bertie Vidgen, Abby Fennelly, Evan Pinnix, Julien Benchek, Daniyal Khan, Zach Richards, Austin Bridges, Calix Huang, Kanishka Sahu, Abhishek Kottamasu, et al. The AI productivity index (APEX).arXiv preprint arXiv:2509.25721,
-
[20]
Mingzhu Wang, Yuzhe Zhang, Qihang Zhao, Junyi Yang, and Hong Zhang. Redefining information retrieval of structured database via large language models.arXiv preprint arXiv:2405.05508,
-
[21]
ProfBench: Multi-Domain Rubrics requiring Professional Knowledge to Answer and Judge
Zhilin Wang, Jaehun Jung, Ximing Lu, Shizhe Diao, Ellie Evans, Jiaqi Zeng, Pavlo Molchanov, Yejin Choi, Jan Kautz, and Yi Dong. ProfBench: Multi-domain rubrics requiring professional knowledge to answer and judge.arXiv preprint arXiv:2510.18941,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. BrowseComp: A simple yet challenging benchmark for browsing agents.arXiv preprint arXiv:2504.12516,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
11 Siqiao Xue, Xiaojing Li, Fan Zhou, Qingyang Dai, Zhixuan Chu, and Hongyuan Mei. FAMMA: A benchmark for financial domain multilingual multimodal question answering.arXiv preprint arXiv:2410.04526,
-
[24]
The harness recorded visible assistant text and tool calls, but no private chain of thought (thinking=off)
The run is from Claude Opus 4.7 and illustrates a successful EDGAR path: the agent finds the Q3 2025 8-K, follows the SEC filing directory to the press-release exhibit, extracts the ARR and NDRR inputs, and computes the projection. The harness recorded visible assistant text and tool calls, but no private chain of thought (thinking=off). Long URLs and que...
2025
-
[25]
Correctly identifies
The graph over models and questions is connected, so the model effects are comparable on one scale. The fitted design uses 2,909 RD-clean observations. The relevant diagnostic is not overall fit quality but the relative scale of question and model variation after setup is clean. The centered question effects have standard deviation22.1 percentage points a...
1977
-
[26]
Other" includes $19.8m of restructuring expenses [+1]Identifies that
Question Reference answer Full rubric If I take Dayforce’s management adjusted reported EBIT as is, would it be overstated or understated or the same last year if I think capitalized software expense is a real cost? If so, by how much? Overstated by $90.1m of excluded capitalized software development costs. Adj EBIT was unburdened by any amortization of c...
2024
-
[27]
Please round the final answer to the nearest tenth of a billion
Question Reference answer Full rubric What would be the payouts to Spotify’s executive officers if Spotify received a buyout offer at a $800 per share price? Please use the latest disclosed incentive program payments (including options and RSUs), shareholdings, and change of control severance payments in addition to any other compensation schemes as of 9/...
2025
-
[28]
I’ll research Udemy’s Q3 2025 financials to find the relevant metrics
The model submitted 1.74% YoY growth, a $9.18M ARR increase, and $536.38M implied Q3’26 ARR; both judges marked the final answer correct and awarded32/32rubric points (9/9lines). Step Visible agent text and tool call Key returned content Reward signal 0a“I’ll research Udemy’s Q3 2025 financials to find the relevant metrics. ” edgar_search(ticker=UDMY, for...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.