Re-Evaluating Continual Learning with Few-Shot Adaptation
Pith reviewed 2026-06-28 11:33 UTC · model grok-4.3
The pith
Few-shot evaluation reveals that meta-learning future tasks induces learning-to-learn behavior in continual learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
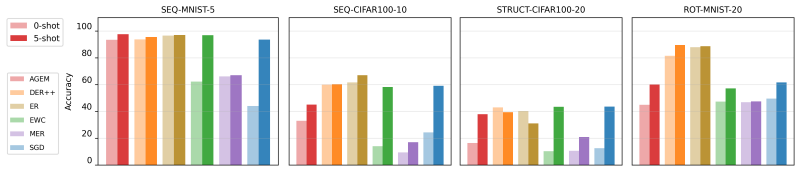
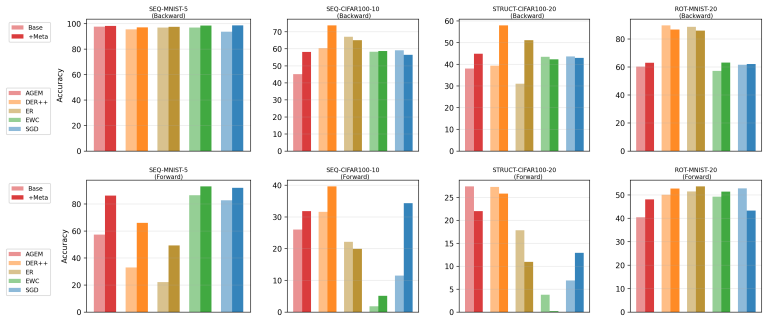
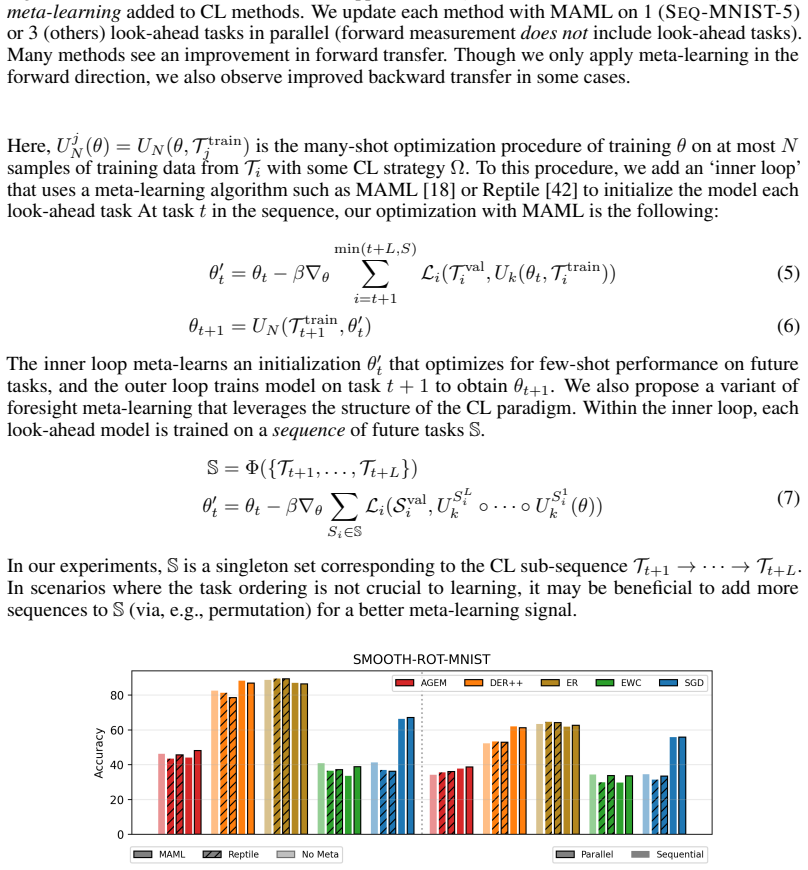
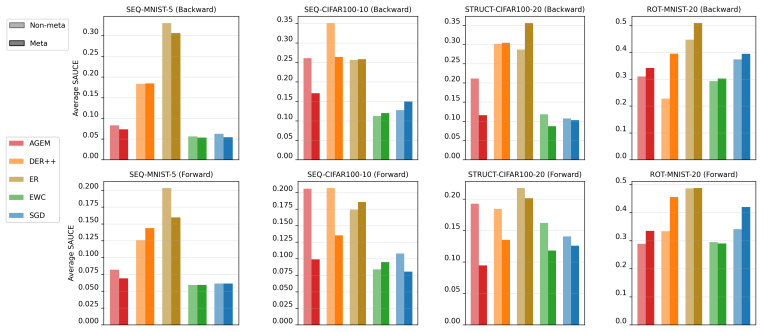
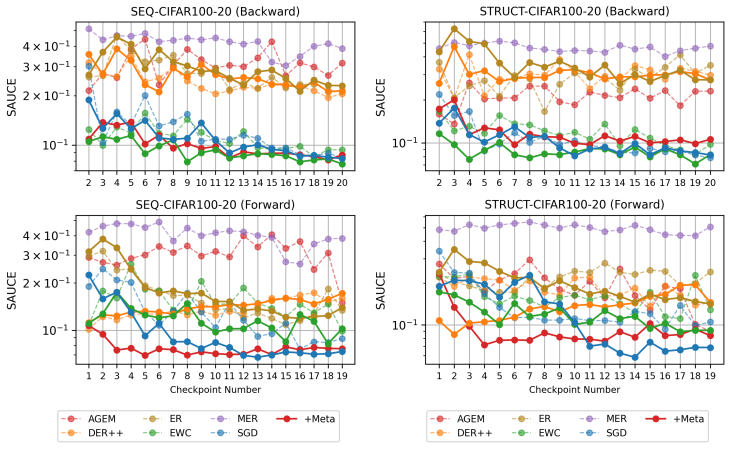
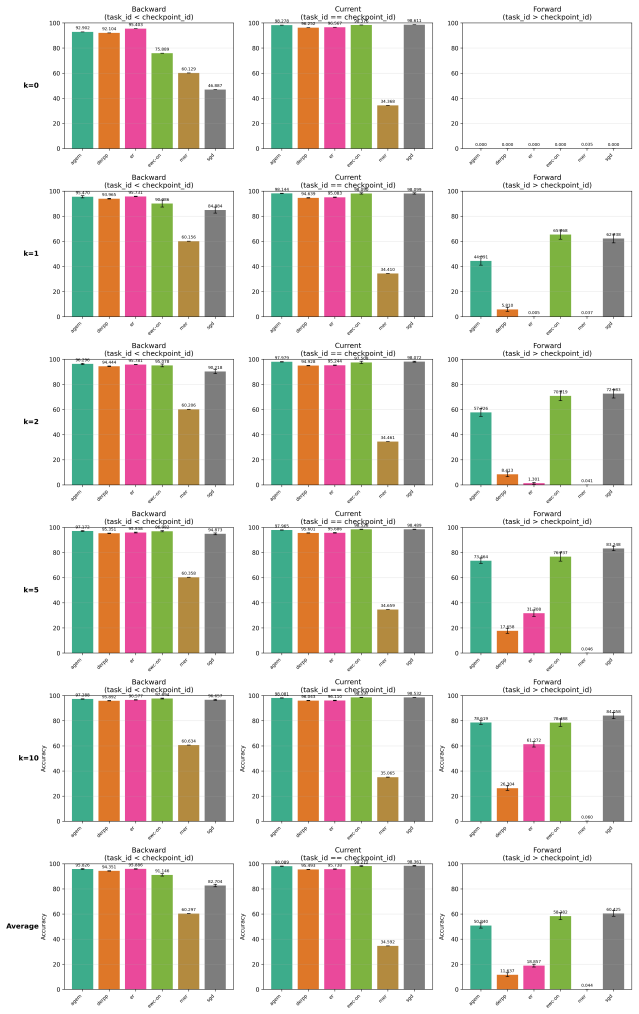
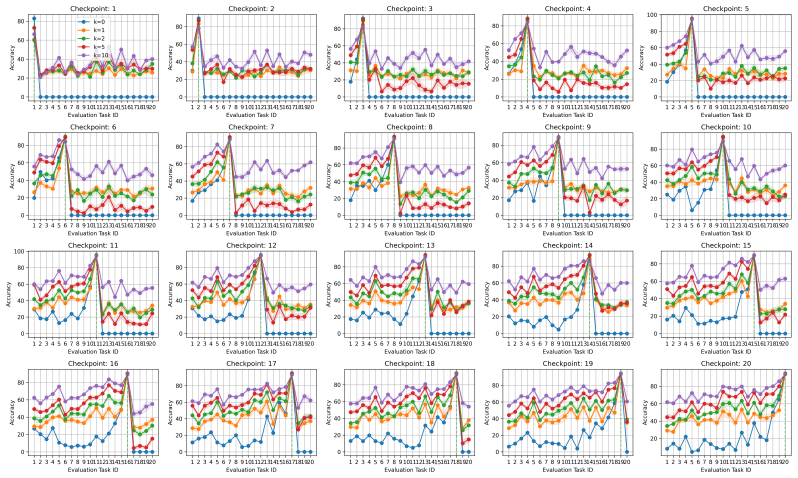
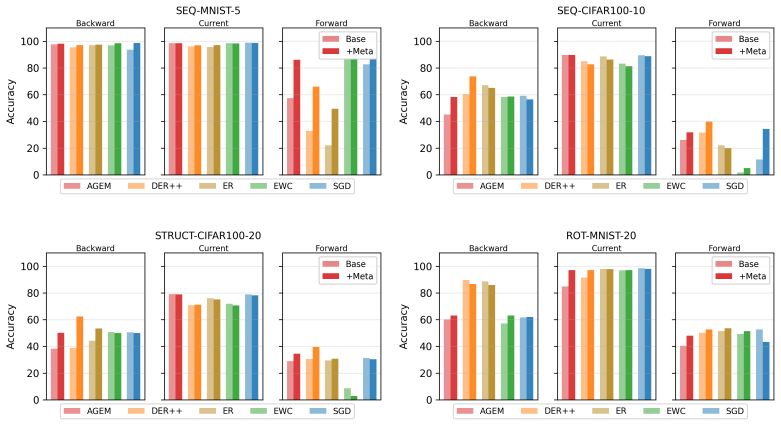
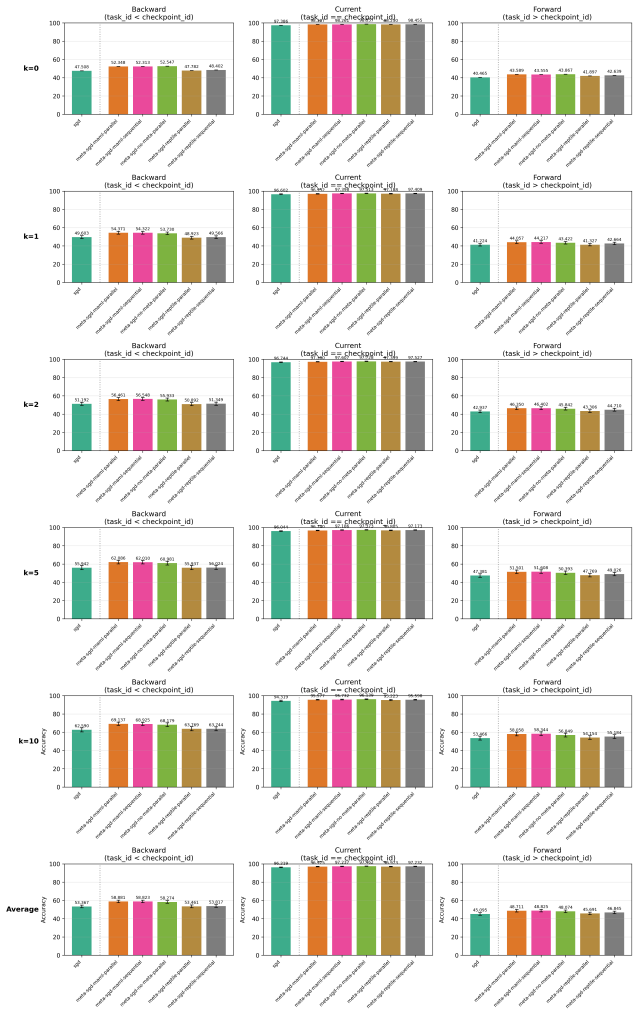
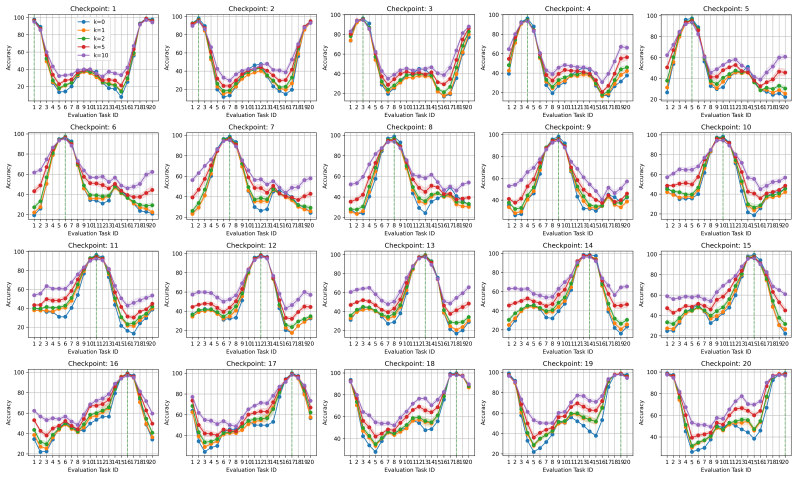
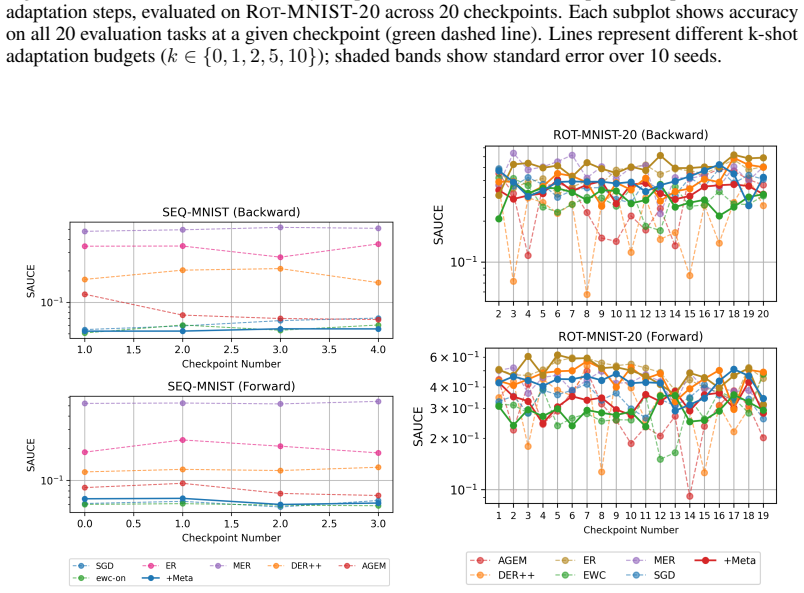
The paper claims that incorporating foresight into continual learning methods by meta-learning a short sequence of future tasks induces learning-to-learn behavior over the task sequence, as shown by improved per-shot plasticity under few-shot evaluation on continual image classification benchmarks.
What carries the argument
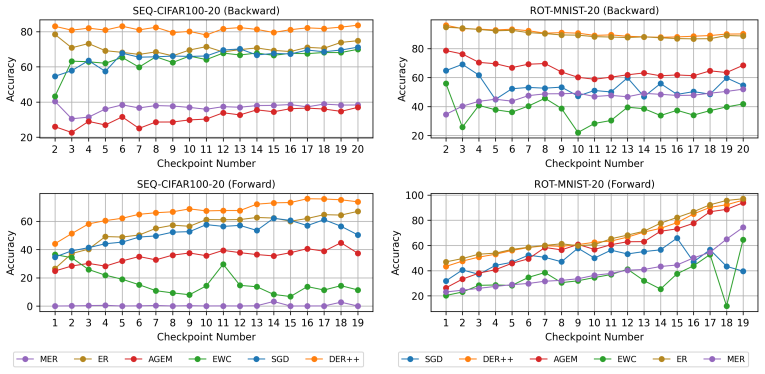
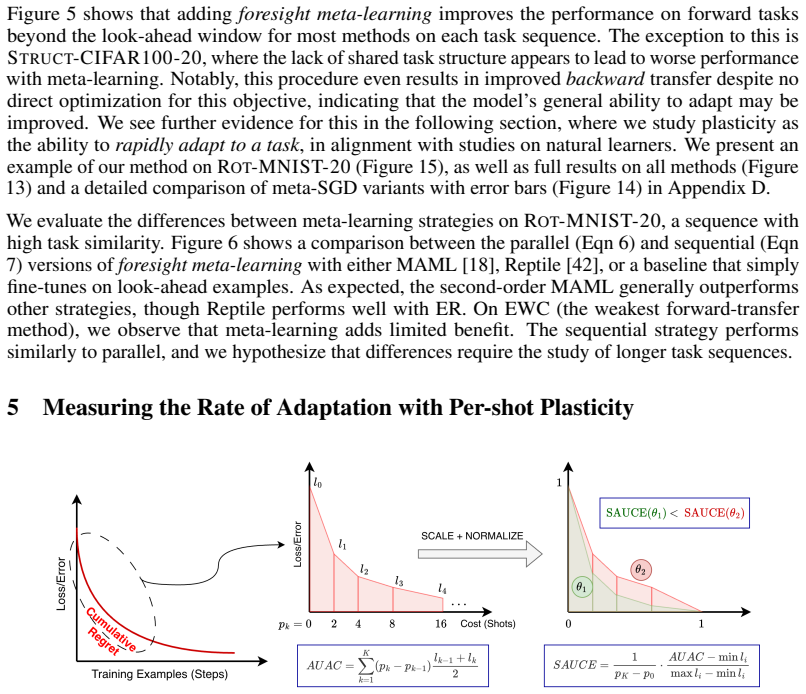
The per-shot plasticity metric, which measures how performance on a new task improves with each additional labeled example, paired with meta-learning of a short future-task sequence to inject foresight into the continual learner.
If this is right
- Few-shot evaluation supplies a finer-grained picture of stability and plasticity than 0-shot alone.
- Popular continual learning strategies exhibit previously unseen behaviors once assessed with per-shot plasticity.
- Meta-learning a short sequence of future tasks produces measurable learning-to-learn across an entire task stream.
- Foresight-augmented methods retain and adapt information more effectively when new tasks arrive in sequence.
Where Pith is reading between the lines
- The same foresight mechanism could be tested in settings where task boundaries are unknown in advance.
- Per-shot plasticity may serve as a diagnostic for how quickly any sequential learner recovers from distribution shifts.
- If the pattern holds, training pipelines for deployed systems could routinely include short future-task meta-training to improve long-term adaptation.
Load-bearing premise
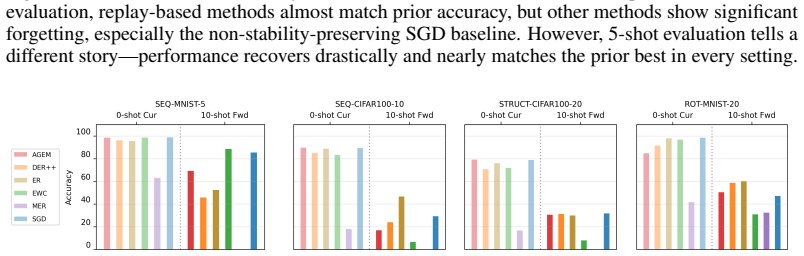
0-shot evaluation requires perfect recall across tasks and therefore cannot measure a method's capacity for quick adaptation to new information.
What would settle it
Experiments that apply the same base continual learning methods both with and without the meta-learning foresight step and find no measurable difference in per-shot plasticity on the task sequences would falsify the central claim.
Figures

read the original abstract
Continual learning methods aim to maximize the stability and plasticity of machine learning models that are trained on a sequence of tasks. The standard measure of stability (i.e., forgetting) is the 0-shot performance of a model on previously learned tasks, and plasticity, the performance on the most recently learned task. However, 0-shot evaluation does not fully measure a model or method's ability to retain learned information or adapt quickly to new information, as it requires perfect recall across multiple tasks. In this paper, we propose few-shot evaluation as a more comprehensive assessment of the stability and plasticity of a continual learning system. We conduct a fine-grained assessment on task sequences for continual image classification and find that this paradigm produces novel insights into the performance of popular continual learning strategies. Through few-shot evaluation with a novel metric -- per-shot plasticity -- we show that adding `foresight' to continual learning methods via the meta-learning of a short sequence of future tasks induces learning-to-learn behavior over the task sequence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that 0-shot evaluation is insufficient to measure stability and plasticity in continual learning because it requires perfect recall across tasks. It proposes few-shot evaluation as a more comprehensive paradigm, introduces the per-shot plasticity metric, and reports that meta-learning a short sequence of future tasks to add 'foresight' induces learning-to-learn behavior, yielding novel insights into popular continual learning strategies on continual image classification task sequences.
Significance. If the empirical findings on per-shot plasticity and the foresight effect hold under rigorous controls, the work could shift evaluation standards in continual learning away from 0-shot metrics and highlight a practical way to improve adaptation via meta-learning of future tasks. The introduction of a targeted metric for few-shot regimes is a clear contribution if the results prove reproducible.
minor comments (1)
- The abstract refers to a 'fine-grained assessment on task sequences for continual image classification' but does not name the datasets, number of tasks, or specific CL baselines evaluated; this detail would strengthen the claim of novel insights.
Simulated Author's Rebuttal
We thank the referee for their summary of the manuscript and for noting its potential to influence evaluation standards in continual learning. The report lists no specific major comments under the MAJOR COMMENTS section, so we provide no point-by-point responses below. We remain available to address any additional concerns or requests for clarification.
Circularity Check
No significant circularity
full rationale
The paper is an empirical study that proposes few-shot evaluation and a per-shot plasticity metric for assessing continual learning methods, then reports experimental findings on image classification task sequences. The central claim (that meta-learning a short sequence of future tasks induces learning-to-learn behavior) is presented as an observed outcome of experiments rather than a mathematical derivation or prediction that reduces to fitted parameters or self-citations by construction. No load-bearing self-citations, self-definitional constructs, or renamings of known results appear in the abstract or described methodology. The work is self-contained against external benchmarks via standard continual learning evaluations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
W. C. Abraham and A. Robins. Memory retention – the synaptic stability versus plasticity dilemma.Trends in Neurosciences, 28(2):73–78, 2005
2005
-
[2]
Aljundi, L
R. Aljundi, L. Caccia, E. Belilovsky, M. Caccia, M. Lin, L. Charlin, and T. Tuytelaars. Online continual learning with maximally interfered retrieval, 2019
2019
-
[3]
J. Bang, H. Kim, Y . Yoo, J.-W. Ha, and J. Choi. Rainbow memory: Continual learning with a memory of diverse samples. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8218–8227, 2021
2021
-
[4]
S. Beaulieu, L. Frati, T. Miconi, J. Lehman, K. O. Stanley, J. Clune, and N. Cheney. Learning to continually learn.arXiv preprint arXiv:2002.09571, 2020
-
[5]
Benfenati
F. Benfenati. Synaptic plasticity and the neurobiology of learning and memory.Acta Biomed, 78(Suppl 1):58–66, 2007
2007
- [6]
-
[7]
Blackwell
D. Blackwell. An analog of the minimax theorem for vector payoffs.Pacific Journal of Mathematics, 6(1) , 1–8., 1956
1956
-
[8]
Boschini, L
M. Boschini, L. Bonicelli, P. Buzzega, A. Porrello, and S. Calderara. Class-incremental continual learning into the extended der-verse.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022
2022
-
[9]
M. E. Bouton. Context and behavioral processes in extinction.Learning & memory, 11(5):485– 494, 2004
2004
-
[10]
Brown, B
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[11]
Buzzega, M
P. Buzzega, M. Boschini, A. Porrello, D. Abati, and S. Calderara. Dark experience for general continual learning: a strong, simple baseline, 2020
2020
-
[12]
Buzzega, M
P. Buzzega, M. Boschini, A. Porrello, D. Abati, and S. Calderara. Dark experience for general continual learning: a strong, simple baseline. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 15920–15930. Curran Associates, Inc., 2020
2020
-
[13]
Chaudhry, M
A. Chaudhry, M. Ranzato, M. Rohrbach, and M. Elhoseiny. Efficient lifelong learning with a-gem. InICLR, 2019. 11
2019
-
[14]
M. De Lange, G. van de Ven, and T. Tuytelaars. Continual evaluation for lifelong learning: Identifying the stability gap.arXiv preprint arXiv:2205.13452, 2022
-
[15]
Dohare, J
S. Dohare, J. F. Hernandez-Garcia, P. Rahman, A. R. Mahmood, and R. S. Sutton. Maintaining plasticity in deep continual learning, 2024
2024
-
[16]
Q. Dong, L. Li, D. Dai, C. Zheng, J. Ma, R. Li, H. Xia, J. Xu, Z. Wu, T. Liu, B. Chang, X. Sun, L. Li, and Z. Sui. A survey on in-context learning, 2024
2024
-
[17]
Ebbinghaus.Über das gedächtnis: untersuchungen zur experimentellen psychologie
H. Ebbinghaus.Über das gedächtnis: untersuchungen zur experimentellen psychologie. Duncker & Humblot, 1885
-
[18]
C. Finn, P. Abbeel, and S. Levine. Model-agnostic meta-learning for fast adaptation of deep networks, 2017
2017
-
[19]
C. Finn, A. Rajeswaran, S. Kakade, and S. Levine. Online meta-learning. In K. Chaudhuri and R. Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 1920–1930. PMLR, 09–15 Jun 2019
1920
-
[20]
R. M. French. Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 3(4):128–135, 1999
1999
-
[21]
C. Ge, X. Wang, Z. Zhang, H. Chen, J. Fan, L. Huang, H. Xue, and W. Zhu. Dynamic mixture of curriculum lora experts for continual multimodal instruction tuning. InProceedings of the 42nd International Conference on Machine Learning, ICML ’25. PMLR, 2025
2025
-
[22]
I. J. Goodfellow, M. Mirza, A. Courville, and Y . Bengio. An empirical investigation of catastrophic forgetting in gradient-based neural networks.stat, 1050:4, 2015
2015
-
[23]
Gupta, K
G. Gupta, K. Yadav, and L. Paull. La-maml: Look-ahead meta learning for continual learning, 2020
2020
-
[24]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770– 778, 2016
2016
-
[25]
Hospedales, A
T. Hospedales, A. Antoniou, P. Micaelli, and A. Storkey. Meta-learning in neural networks: A survey, 2020
2020
-
[26]
Ibrahim, B
A. Ibrahim, B. Thérien, K. Gupta, M. L. Richter, Q. G. Anthony, E. Belilovsky, T. Lesort, and I. Rish. Simple and scalable strategies to continually pre-train large language models. Transactions on Machine Learning Research, 2024
2024
-
[27]
Javed and M
K. Javed and M. White. Meta-learning representations for continual learning.Advances in neural information processing systems, 32, 2019
2019
-
[28]
Jirenhed, F
D.-A. Jirenhed, F. Bengtsson, and G. Hesslow. Acquisition, extinction, and reacquisition of a cerebellar cortical memory trace.Journal of Neuroscience, 27(10):2493–2502, 2007
2007
-
[29]
Kirkpatrick, R
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
2017
-
[30]
Krizhevsky
A. Krizhevsky. Learning multiple layers of features from tiny images. Technical report, 2009
2009
-
[31]
B. Lake, R. Salakhutdinov, J. Gross, and J. Tenenbaum. One shot learning of simple visual concepts. InProceedings of the annual meeting of the cognitive science society, volume 33, 2011
2011
-
[32]
LeCun, C
Y . LeCun, C. Cortes, and C. Burges. Mnist handwritten digit database.ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist, 2, 2010. 12
2010
-
[33]
J. Li, M. Armandpour, S. I. Mirzadeh, S. Mehta, V . Shankar, R. Vemulapalli, S. Bengio, O. Tuzel, M. Farajtabar, H. Pouransari, et al. Tic-lm: A web-scale benchmark for time-continual llm pretraining. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 32231–32273, 2025
2025
-
[34]
Li and D
Z. Li and D. Hoiem. Learning without forgetting, 2017
2017
-
[35]
L.-J. Lin. Self-improving reactive agents based on reinforcement learning, planning and teaching. Machine learning, 8:293–321, 1992
1992
-
[36]
Y . Liu, Y . Su, A.-A. Liu, B. Schiele, and Q. Sun. Mnemonics training: Multi-class incremental learning without forgetting. InProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 12245–12254, 2020
2020
-
[37]
Lopez-Paz and M
D. Lopez-Paz and M. Ranzato. Gradient episodic memory for continual learning.Advances in neural information processing systems, 30, 2017
2017
-
[38]
Y . Mahdaviyeh, J. Lucas, M. Ren, A. S. Tolias, R. Zemel, and T. Pitassi. Replay can provably increase forgetting.arXiv preprint arXiv:2506.04377, 2025
-
[39]
McCloskey and N
M. McCloskey and N. J. Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. InPsychology of learning and motivation, volume 24, pages 109–165. Elsevier, 1989
1989
-
[40]
J. M. Murre and J. Dros. Replication and analysis of ebbinghaus’ forgetting curve.PloS one, 10(7):e0120644, 2015
2015
-
[41]
R. M. Napier, M. Macrae, and E. J. Kehoe. Rapid reacquisition in conditioning of the rab- bit’s nictitating membrane response.Journal of Experimental Psychology: Animal Behavior Processes, 18(2):182, 1992
1992
-
[42]
Nichol, J
A. Nichol, J. Achiam, and J. Schulman. On first-order meta-learning algorithms, 2018
2018
-
[43]
S. T. Ricker and M. E. Bouton. Reacquisition following extinction in appetitive conditioning. Animal Learning & Behavior, 24(4):423–436, 1996
1996
-
[44]
Riemer, I
M. Riemer, I. Cases, R. Ajemian, M. Liu, I. Rish, Y . Tu, and G. Tesauro. Learning to learn without forgetting by maximizing transfer and minimizing interference, 2019
2019
-
[45]
H. Shin, J. K. Lee, J. Kim, and J. Kim. Continual learning with deep generative replay.Advances in neural information processing systems, 30, 2017
2017
-
[46]
Snell, K
J. Snell, K. Swersky, and R. Zemel. Prototypical networks for few-shot learning.Advances in neural information processing systems, 30, 2017
2017
-
[47]
Tulving and D
E. Tulving and D. M. Thomson. Encoding specificity and retrieval processes in episodic memory. Psychological review, 80(5):352, 1973
1973
-
[48]
Vinyals, C
O. Vinyals, C. Blundell, T. Lillicrap, D. Wierstra, et al. Matching networks for one shot learning. Advances in neural information processing systems, 29, 2016
2016
-
[49]
A. J. Wang, K. Q. Lin, D. J. Zhang, S. W. Lei, and M. Z. Shou. Too large; data reduction for vision-language pre-training. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3147–3157, 2023
2023
-
[50]
L. Wang, X. Zhang, H. Su, and J. Zhu. A comprehensive survey of continual learning: Theory, method and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[51]
Wu, L.-K
Y . Wu, L.-K. Huang, R. Wang, D. Meng, and Y . Wei. Meta continual learning revisited: Implicitly enhancing online hessian approximation via variance reduction. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[52]
arXiv preprint arXiv:2404.19132 , year=
Y . Zhang, L. Charlin, R. Zemel, and M. Ren. Integrating present and past in unsupervised continual learning.arXiv preprint arXiv:2404.19132, 2024. 13 A Additional Related Work A.1 Continual Learning Strategies Existing methods for continual learning can generally be categorized into replay-based, regularization- based, architectural, and distillation str...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.