PyraMathBench: Evaluating and Improving Mathematical Capability in Large Language Models
Pith reviewed 2026-06-28 09:28 UTC · model grok-4.3
The pith
PyraMathBench shows LLMs fail on numerical computation in math tasks, and SOLVE plus IRPO training raises Qwen-2.5 scores by 5 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
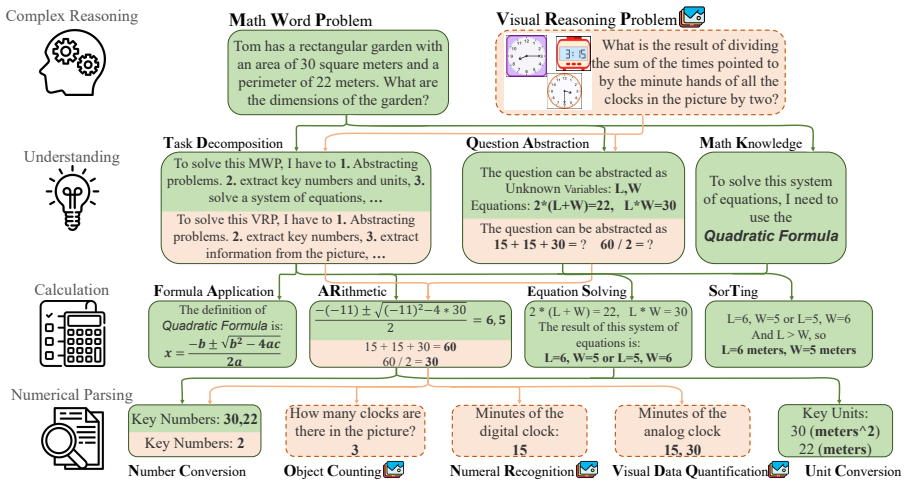
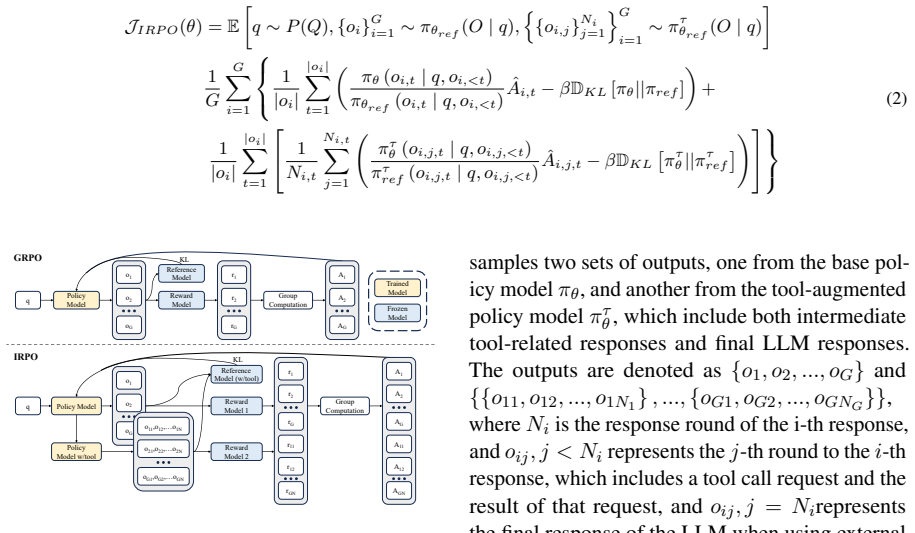
The paper establishes that LLMs' mathematical performance is limited by weak numerical computation and poor handling of abstract numerical questions. It introduces PyraMathBench as a 32,505-question benchmark spanning four cognitive aspects and two modalities to expose these gaps. SOLVE and IRPO are presented as methods that improve numerical-mathematical synergy through efficient tool calls, producing a five-point score increase for Qwen-2.5 under comparative training.
What carries the argument
SOLVE and IRPO, which strengthen numerical-mathematical synergy in LLMs through efficient tool calls that include fuzzy matching and rejection of low-quality calls.
If this is right
- Models trained with SOLVE and IRPO will show higher accuracy on tasks that require both calculation and logical steps.
- The benchmark can isolate whether a model's math errors stem from number handling or from reasoning structure.
- Abstract numerical questions become more tractable once tool-call efficiency is improved.
- The same training approach can be applied to other base models to test for similar gains.
Where Pith is reading between the lines
- If the methods transfer, they could raise reliability in domains such as physics simulation or financial modeling that mix numbers with rules.
- The hierarchical design of the benchmark could be reused to create parallel tests for other integrated skills like spatial reasoning.
- Longer training runs or larger models might reveal whether the five-point lift scales or saturates.
Load-bearing premise
The five-point gain is produced by SOLVE and IRPO rather than by uncontrolled differences in training data, compute, or evaluation setup.
What would settle it
Run the identical training schedule on Qwen-2.5 without the SOLVE module or IRPO objective and measure whether the five-point gain on PyraMathBench disappears.
Figures







read the original abstract
Despite the pivotal role of numerical reasoning as the cornerstone of mathematical capabilities in large language models (LLMs) across applications, few benchmarks evaluate LLMs by integrating numerical processing and mathematical reasoning, hindering the interpretability of failures in math tasks. We introduce PyraMathBench, a comprehensive hierarchical benchmark with 32,505 questions derived from 7,404 math word problems, spanning 4 key cognitive aspects, 14 subcategories, and 2 modalities. Experiments reveal that LLMs' performance is severely compromised by inadequate numerical computation and weak handling of abstract numerical questions. To address this, we propose the Smart Optimization & Learning-based VErsatile module (SOLVE) and Interactive Relative Policy Optimization (IRPO), which enhance LLMs' numerical-mathematical synergy via efficient tool calls (fuzzy matching and low-quality call rejection). Comparative experiments show Qwen-2.5 achieves a 5.0 score improvement with SOLVE and IRPO training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PyraMathBench, a hierarchical benchmark comprising 32,505 questions derived from 7,404 math word problems across 4 cognitive aspects, 14 subcategories, and 2 modalities. It reports that LLMs struggle with numerical computation and abstract numerical questions, and proposes SOLVE (with fuzzy matching and low-quality call rejection) plus IRPO to improve numerical-mathematical synergy via tool calls, claiming a 5.0-point score gain on Qwen-2.5 after training with these modules.
Significance. A well-validated benchmark focused on numerical reasoning integration could usefully complement existing math evaluations. The proposed SOLVE and IRPO modules target a plausible failure mode, but any significance is conditional on the experimental claims being supported by controls, ablations, and statistical reporting, none of which are described.
major comments (3)
- [Abstract] Abstract: the central claim that Qwen-2.5 achieves a 5.0 score improvement attributable to SOLVE and IRPO is unsupported because the text supplies no details on experimental controls, ablations, matched baselines, number of training steps, learning-rate schedules, or evaluation-prompt formatting; without these, the delta cannot be isolated from confounders.
- [Abstract] Abstract: no information is given on benchmark construction validation (e.g., human verification of question quality, difficulty calibration, inter-rater reliability, or statistical comparison against existing suites such as GSM8K or MATH), which is load-bearing for interpreting all reported LLM performance numbers.
- [Abstract] Abstract: the performance findings are stated without error bars, statistical significance tests on the reported deltas, or any description of the evaluation protocol, leaving the 5.0-point gain uninterpretable.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on experimental transparency and benchmark validation. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Qwen-2.5 achieves a 5.0 score improvement attributable to SOLVE and IRPO is unsupported because the text supplies no details on experimental controls, ablations, matched baselines, number of training steps, learning-rate schedules, or evaluation-prompt formatting; without these, the delta cannot be isolated from confounders.
Authors: We agree that the abstract is too concise to support the central claim in isolation. The current manuscript reports the 5.0-point gain but does not detail the full set of controls or ablations in the abstract. We will revise the abstract to include a brief summary of the training protocol, key ablations, and evaluation formatting, and expand the experimental section with matched baselines and training hyperparameters. revision: yes
-
Referee: [Abstract] Abstract: no information is given on benchmark construction validation (e.g., human verification of question quality, difficulty calibration, inter-rater reliability, or statistical comparison against existing suites such as GSM8K or MATH), which is load-bearing for interpreting all reported LLM performance numbers.
Authors: The benchmark is derived from 7,404 existing math word problems, but the manuscript does not describe explicit validation procedures. We will add a dedicated subsection on benchmark construction that includes details of any human review, difficulty calibration steps, and direct statistical comparisons against GSM8K and MATH to allow readers to assess the new benchmark's properties. revision: yes
-
Referee: [Abstract] Abstract: the performance findings are stated without error bars, statistical significance tests on the reported deltas, or any description of the evaluation protocol, leaving the 5.0-point gain uninterpretable.
Authors: We acknowledge that the reported performance numbers lack error bars, significance testing, and a clear evaluation protocol description. In the revision we will report standard deviations across multiple runs, perform statistical significance tests on the observed deltas, and provide an explicit description of the evaluation protocol (including prompt formatting and decoding settings) in both the abstract and main text. revision: yes
Circularity Check
No circularity; empirical benchmark and training results are self-contained experimental outcomes
full rationale
The paper presents PyraMathBench as a new hierarchical benchmark and reports comparative experimental gains from SOLVE and IRPO modules on Qwen-2.5. No derivation chain, equations, or first-principles predictions are claimed that could reduce to inputs by construction. The 5.0-point improvement is framed as an observed experimental result rather than a fitted or self-referential quantity. No self-citations, ansatzes, or uniqueness theorems appear in the abstract or described content to create load-bearing circularity. The work is therefore self-contained against external benchmarks and evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capa- bility in llms via reinforcement learning.Preprint, arXiv:2501.12948. Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, and 1 others. 2025. Omni-MATH: A universal olympiad level mathematic benchmark for large language models. InThe Thirteenth Inter- ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
arXiv preprint arXiv:2308.00675 , year=
Toolkengpt: Augmenting frozen language models with massive tools via tool embeddings.Ad- vances in neural information processing systems, 36:45870–45894. Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, and 1 others. 2024. OlympiadBench: A challenging benchmark for pro- moting AGI...
-
[3]
arXiv preprint arXiv:2305.14201 , year=
Learning numeral embedding. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 2586–2599, Online. Association for Computational Linguistics. Nate Kushman, Yoav Artzi, Luke Zettlemoyer, and Regina Barzilay. 2014. Learning to automatically solve algebra word problems. InProceedings of the 52nd Annual Meeting of the Association fo...
-
[4]
arXiv preprint arXiv:2205.12255 , year=
A diverse corpus for evaluating and developing english math word problem solvers. InProceedings of the 58th annual meeting of the Association for Computational Linguistics, pages 975–984. Swaroop Mishra, Matthew Finlayson, Pan Lu, Leonard Tang, Sean Welleck, Chitta Baral, Tanmay Rajpuro- hit, Oyvind Tafjord, Ashish Sabharwal, Peter Clark, and Ashwin Kalya...
-
[5]
Association for Computational Linguistics
Are NLP models really able to solve simple math word problems? InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2080–2094, Online. Association for Computational Linguistics. Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. 2024. Gorilla: ...
2021
-
[6]
arXiv preprint arXiv:2307.13692 (2023)
Arb: Advanced reasoning benchmark for large language models.arXiv preprint arXiv:2307.13692. Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Pro- cessing Syste...
-
[7]
Mathbert: A pre-trained language model for general nlp tasks in mathematics education.arXiv preprint arXiv:2106.07340. Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. 2023. Hugging- gpt: Solving ai tasks with chatgpt and its friends in hugging face.Advances in Neural Information Processing Systems, 36:38154–38180. Shumin...
-
[8]
Arithmetic, 2) Equation Solving, 3) Sorting, and
-
[9]
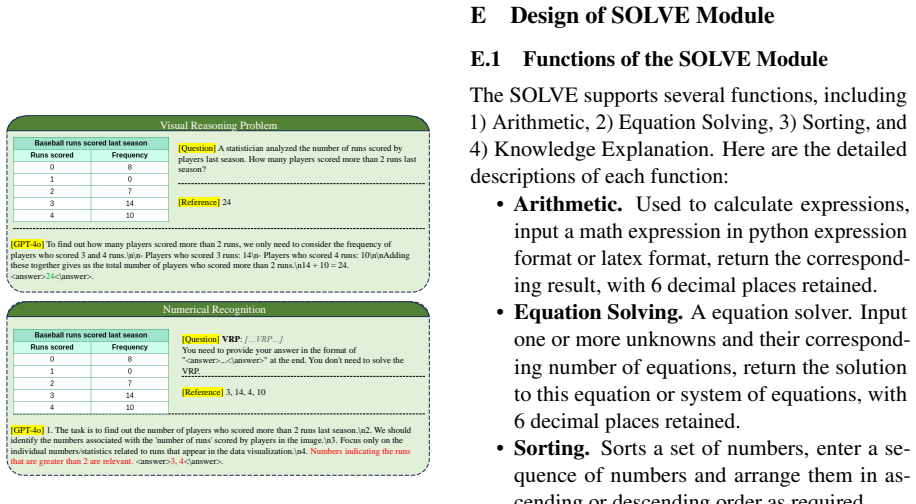
Knowledge Explanation. Here are the detailed descriptions of each function: • Arithmetic.Used to calculate expressions, input a math expression in python expression format or latex format, return the correspond- ing result, with 6 decimal places retained. • Equation Solving.A equation solver. Input one or more unknowns and their correspond- ing number of ...
-
[10]
x”, “y”, “total
Question Abstraction Goal: To convert the problem into a structured mathematical representation. Steps to Annotate: Check for mathematical operations or relationships: Look for direct operations or relationships that can be mathematically represented (e.g., addition, multiplication, algebraic expressions). Identify variables or unknowns: Look for words th...
-
[11]
Task Decomposition Goal: To break down the problem into steps for solving. Steps to Annotate: Identify the main goal: What is the problem asking for (e.g., finding an unknown, calculating a total)? Determine substeps: Select the sub steps required from A-I below: A: Additional information such as mathematical formulas, constants, theorems, etc. that are n...
-
[12]
Math Knowledge Goal: To evaluate whether the model needs to apply advanced mathematical concepts not explicitly stated in the problem. Steps to Annotate: Check for implicit knowledge: Look for problems that require knowledge of constants, special numbers (like pi, e), or advanced mathematical formulas (e.g., quadratic formula, trigonometric identities). S...
-
[13]
Steps to Annotate: Check for simple operations: Identify basic arithmetic operations such as addition, subtraction, multiplication, division, exponentiation, or square roots
Arithmetic Goal: To evaluate the basic arithmetic operations ability of LLMs. Steps to Annotate: Check for simple operations: Identify basic arithmetic operations such as addition, subtraction, multiplication, division, exponentiation, or square roots. Check for complex arithmetic expressions: Some problems may involve multiple operations that need to be ...
-
[14]
x + 5 = 10
Equation Solving Goal: To solve equations involving one or more variables. Steps to Annotate: Identify equations: Look for sentences that imply an equation that can be solved for an unknown (e.g., "x + 5 = 10"). Identify types of equations: Distinguish between linear, quadratic, or higher-degree equations, as well as systems of equations. Equation abstrac...
-
[15]
Steps to Annotate: Identify ordering criteria: Look for instructions that require the arrangement of numbers(ascending/descending), objects, or values based on a given condition
Sorting Goal: To arrange numbers or objects in a specific order. Steps to Annotate: Identify ordering criteria: Look for instructions that require the arrangement of numbers(ascending/descending), objects, or values based on a given condition. Check for number: Extract the numbers that need to be sorted from the question and use the sorted result as the a...
-
[16]
Steps to Annotate: Identify number types: Check for numbers expressed in various forms (e.g., words, scientific notation, fractions) and convert to Arabic numerals
Number Conversion Goal: To convert numbers between formats. Steps to Annotate: Identify number types: Check for numbers expressed in various forms (e.g., words, scientific notation, fractions) and convert to Arabic numerals. Check for required numbers: Identify which numbers are truly needed to solve the problem and eliminate irrelevant numbers. Example A...
-
[17]
Steps to Annotate: Identify units: Look for units mentioned in the problem (e.g., meters, kilograms, degrees Celsius)
Unit Conversion Goal: To convert between different units of measurement. Steps to Annotate: Identify units: Look for units mentioned in the problem (e.g., meters, kilograms, degrees Celsius). Check for necessary conversions: Determine if the problem requires converting between units (e.g., from kilometers to miles, Celsius to Fahrenheit). Apply conversion...
-
[18]
Numeral Recognition Goal: Look for visual content in the image that contains numbers, symbols, or math- ematical expressions. (e.g.Numbers, Variables/Constants, Formulas or Expressions) Steps to Annotate: Extracting Numbers and Symbols: Carefully select all visible numerical elements, ensuring that only those that are directly relevant to the problem are ...
-
[19]
Visual Data Quantification Goal: Look for elements in the image that involve visual representations of data that aren’t explicitly presented as numbers. Steps to Annotate: Check for quantified data: Check if the image contain any visual data (like clocks, rulers, or diagrams) that requires interpretation and transformation into a numerical value. Extract ...
-
[20]
<answer>...<\answer>
Object Counting Goal: Look for descriptions or instructions that request a specific count of objects or items within the image. These objects can vary from physical items to abstract representations. Steps to Annotate: Identify and Isolate Objects: Find all objects that match the description and isolate them visually. If objects are grouped or clustered t...
1928
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.