DyaPlex: Full-Duplex Speech-Motion Model for Dyadic Interaction
Pith reviewed 2026-06-28 10:20 UTC · model grok-4.3
The pith
DyaPlex adds a streaming motion pathway to a frozen full-duplex speech model via dual-tower Transformers for synchronized dyadic interaction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
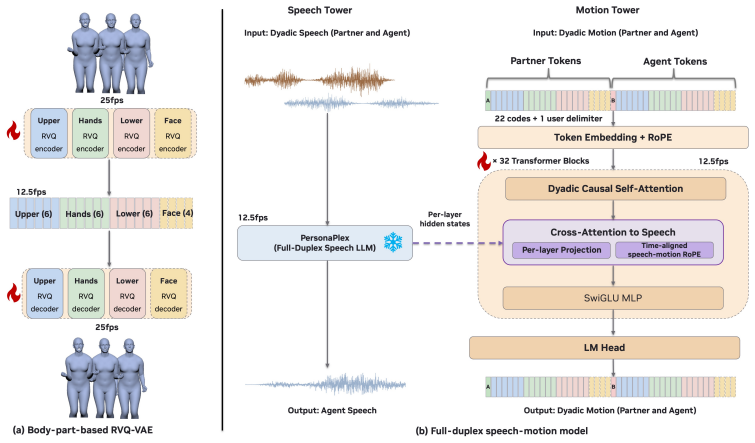
Our method leverages the strong priors of a foundational full-duplex speech model and integrates a novel motion pathway, thereby achieving fully synchronized multi-modal interaction. Specifically, we design a dual-tower Transformer architecture that preserves the zero-shot conversational reasoning of a frozen base speech model while constructing a deeply coupled, streaming motion pathway. By introducing a unified dyadic token interleaving mechanism and guiding cross-attention via a time-aligned speech-motion RoPE, our model effectively aligns autoregressive motions with rich latent speech features.
What carries the argument
dual-tower Transformer architecture with unified dyadic token interleaving and time-aligned speech-motion RoPE added to a frozen base speech model
Load-bearing premise
Adding the dual-tower Transformer and motion pathway to the frozen base speech model does not degrade its zero-shot conversational reasoning abilities.
What would settle it
Measuring the base speech model's performance on zero-shot conversational tasks before and after integrating the motion pathway; a drop would indicate the assumption fails.
Figures
read the original abstract
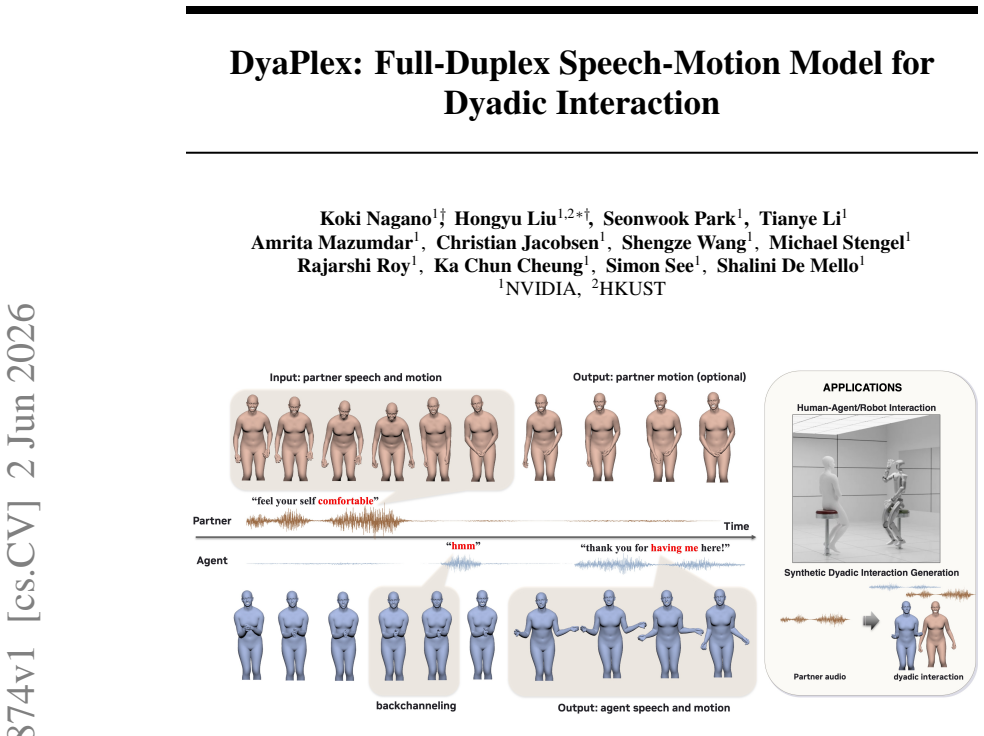
We present DyaPlex, a streaming, full-duplex speech-and-motion model designed for dyadic interaction. To capture the continuous and reciprocal nature of human communication, this full-duplex capability empowers the agent to simultaneously perceive and generate both speech and physical motion in a streaming fashion. At its core, our method leverages the strong priors of a foundational full-duplex speech model and integrates a novel motion pathway, thereby achieving fully synchronized multi-modal interaction. Specifically, we design a dual-tower Transformer architecture that preserves the zero-shot conversational reasoning of a frozen base speech model while constructing a deeply coupled, streaming motion pathway. By introducing a unified dyadic token interleaving mechanism and guiding cross-attention via a time-aligned speech-motion RoPE, our model effectively aligns autoregressive motions with rich latent speech features. Trained on the 4,000-hour Seamless Interaction dataset, our model effectively captures cross-speaker dependencies and establishes new state-of-the-art performance across both monadic and dyadic human interaction benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents DyaPlex, a streaming full-duplex speech-and-motion model for dyadic interaction. It builds a dual-tower Transformer on a frozen foundational full-duplex speech model, using unified dyadic token interleaving and time-aligned speech-motion RoPE to align autoregressive motions with speech features. Trained on the 4,000-hour Seamless Interaction dataset, the model is claimed to capture cross-speaker dependencies while preserving the base model's zero-shot conversational reasoning and achieving new state-of-the-art results on both monadic and dyadic human interaction benchmarks.
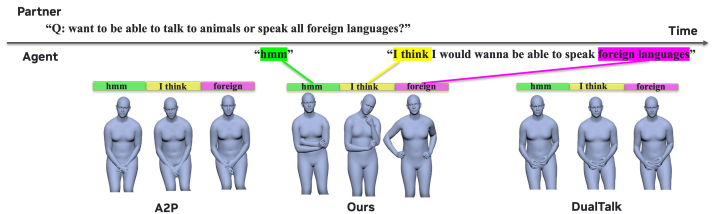
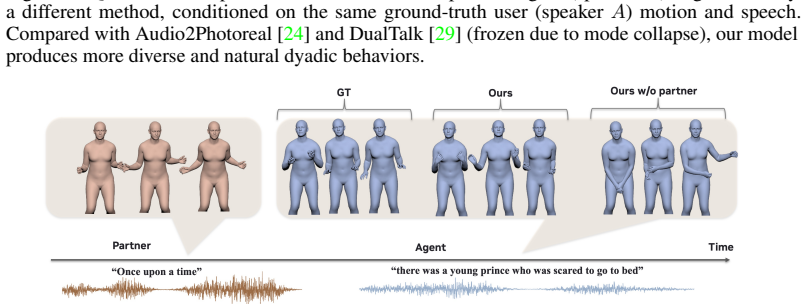
Significance. If the central architectural claim holds—that a motion pathway can be grafted onto a frozen speech model without degrading its zero-shot capabilities—the work would advance streaming multi-modal agents for synchronized speech-motion dyadic interaction. The 4000-hour training scale and dual-tower design could provide a template for extending speech priors to motion, but the absence of supporting metrics makes the significance currently unassessable.
major comments (1)
- [Abstract] Abstract: The claim that the dual-tower Transformer 'preserves the zero-shot conversational reasoning of a frozen base speech model' is load-bearing for attributing any benchmark gains to the proposed architecture rather than interference or degradation. No pre/post integration results on speech-only tasks (e.g., coherence, response quality, or zero-shot benchmarks), ablation studies removing the motion pathway, or quantitative verification of preserved autoregressive generation are supplied.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of verifying that the frozen base model’s zero-shot capabilities are preserved. We address this point directly below and will strengthen the manuscript with additional evidence.
read point-by-point responses
-
Referee: The claim that the dual-tower Transformer 'preserves the zero-shot conversational reasoning of a frozen base speech model' is load-bearing for attributing any benchmark gains to the proposed architecture rather than interference or degradation. No pre/post integration results on speech-only tasks (e.g., coherence, response quality, or zero-shot benchmarks), ablation studies removing the motion pathway, or quantitative verification of preserved autoregressive generation are supplied.
Authors: We agree that quantitative verification is necessary to substantiate the claim. Because the speech tower is kept frozen and the motion pathway operates through a separate tower with time-aligned cross-attention, speech autoregression is architecturally isolated from motion parameters. To make this explicit, the revised manuscript will include (1) direct comparisons of the base model versus DyaPlex on held-out speech-only zero-shot benchmarks (coherence, response quality) and (2) an ablation that removes the motion tower while keeping all other components fixed. These results will be reported in a new subsection of the experiments. revision: yes
Circularity Check
No significant circularity; claims rest on empirical training and architecture, not self-referential reduction
full rationale
The provided abstract and description contain no equations, derivations, or parameter-fitting steps that reduce by construction to the inputs. The central claim—that the dual-tower Transformer with dyadic interleaving and time-aligned RoPE preserves zero-shot reasoning of a frozen base model while adding motion—is presented as an architectural outcome trained on the external 4,000-hour Seamless Interaction dataset and evaluated on monadic/dyadic benchmarks. No self-citation load-bearing premises, uniqueness theorems, ansatzes smuggled via citation, or fitted inputs renamed as predictions appear. The derivation chain is self-contained against external benchmarks, yielding a normal non-finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Seamless interaction: Dyadic audiovisual motion modeling and large-scale dataset
Vasu Agrawal, Akinniyi Akinyemi, Kathryn Alvero, Morteza Behrooz, Julia Buffalini, Fabio Maria Carlucci, Joy Chen, Junming Chen, Zhang Chen, Shiyang Cheng, Praveen Chowdary, Joe Chuang, Antony D’Avirro, Jon Daly, Ning Dong, Mark Duppenthaler, Cynthia Gao, Jeff Girard, Martin Gleize, Sahir Gomez, Hongyu Gong, Srivathsan Govindarajan, Brandon Han, Sen He, D...
2025
-
[2]
Ready-to-react: Online reaction policy for two-character interaction generation
Zhi Cen, Huaijin Pi, Sida Peng, Qing Shuai, Yujun Shen, Hujun Bao, Xiaowei Zhou, and Ruizhen Hu. Ready-to-react: Online reaction policy for two-character interaction generation. InICLR, 2025
2025
-
[3]
Seeing what matters: Generalizable ai-generated video detection with forensic-oriented augmentation
Riccardo Corvi, Davide Cozzolino, Ekta Prashnani, Shalini De Mello, Koki Nagano, and Luisa Verdoliva. Seeing what matters: Generalizable ai-generated video detection with forensic-oriented augmentation. In NeurIPS, 2025
2025
-
[4]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. Moshi: a speech-text foundation model for real-time dialogue.arXiv preprint arXiv:2410.00037, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Panagiotis P Filntisis, George Retsinas, Foivos Paraperas-Papantoniou, Athanasios Katsamanis, Anastasios Roussos, and Petros Maragos. Visual speech-aware perceptual 3d facial expression reconstruction from videos.arXiv preprint arXiv:2207.11094, 2022
-
[6]
Remos: 3d motion-conditioned reaction synthesis for two-person interactions
Anindita Ghosh, Rishabh Dabral, Vladislav Golyanik, Christian Theobalt, and Philipp Slusallek. Remos: 3d motion-conditioned reaction synthesis for two-person interactions. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[7]
Hu- mans in 4d: Reconstructing and tracking humans with transformers
Shubham Goel, Georgios Pavlakos, Jathushan Rajasegaran, Angjoo Kanazawa, and Jitendra Malik. Hu- mans in 4d: Reconstructing and tracking humans with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 14783–14794, October 2023. 10
2023
-
[8]
Learning speech-driven 3d conversational gestures from video
Ikhsanul Habibie, Weipeng Xu, Dushyant Mehta, Lingjie Liu, Hans-Peter Seidel, Gerard Pons-Moll, Mohamed Elgharib, and Christian Theobalt. Learning speech-driven 3d conversational gestures from video. InProceedings of the 21st ACM international conference on intelligent virtual agents, pages 101–108, 2021
2021
-
[9]
Motiongpt: Human motion as a foreign language.Advances in Neural Information Processing Systems, 36:20067–20079, 2023
Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang Yu, and Tao Chen. Motiongpt: Human motion as a foreign language.Advances in Neural Information Processing Systems, 36:20067–20079, 2023
2023
-
[10]
Arflow: Human action-reaction flow matching with physical guidance.ArXiv, 2025
Wentao Jiang, Jingya Wang, Haotao Lu, Kaiyang Ji, Baoxiong Jia, Siyuan Huang, and Ye Shi. Arflow: Human action-reaction flow matching with physical guidance.ArXiv, 2025
2025
-
[11]
Panoptic studio: A massively multiview system for social interaction
Hanbyul Joo, Tomas Simon, Xulong Li, Hao Liu, Lei Tan, Lin Gui, Sean Banerjee, Timothy Scott Godisart, Bart Nabbe, Iain Matthews, et al. Panoptic studio: A massively multiview system for social interaction. IEEE Transactions on Pattern Analysis and Machine Intelligence, 16, 2017
2017
-
[12]
Ross, and Angjoo Kanazawa
Ruilong Li, Sha Yang, David A. Ross, and Angjoo Kanazawa. Ai choreographer: Music conditioned 3d dance generation with aist++. InICCV, 2021
2021
-
[13]
Tianye Li, Timo Bolkart, Michael. J. Black, Hao Li, and Javier Romero. Learning a model of facial shape and expression from 4D scans.ACM Transactions on Graphics, (Proc. SIGGRAPH Asia), 36(6), 2017
2017
-
[14]
Intergen: Diffusion-based multi- human motion generation under complex interactions.International Journal of Computer Vision, 132(9): 3463–3483, 2024
Han Liang, Wenqian Zhang, Wenxuan Li, Jingyi Yu, and Lan Xu. Intergen: Diffusion-based multi- human motion generation under complex interactions.International Journal of Computer Vision, 132(9): 3463–3483, 2024
2024
-
[15]
Beat: A large-scale semantic and emotional multi-modal dataset for conversational gestures synthesis
Haiyang Liu, Zihao Zhu, Naoya Iwamoto, Yichen Peng, Zhengqing Li, You Zhou, Elif Bozkurt, and Bo Zheng. Beat: A large-scale semantic and emotional multi-modal dataset for conversational gestures synthesis. InECCV, 2022
2022
-
[16]
Emage: Towards unified holistic co-speech gesture generation via expressive masked audio gesture modeling
Haiyang Liu, Zihao Zhu, Giorgio Becherini, Yichen Peng, Mingyang Su, You Zhou, Xuefei Zhe, Naoya Iwamoto, Bo Zheng, and Michael J Black. Emage: Towards unified holistic co-speech gesture generation via expressive masked audio gesture modeling. InCVPR, 2024
2024
-
[17]
Pinxin Liu, Luchuan Song, Junhua Huang, Haiyang Liu, and Chenliang Xu. Gesturelsm: Latent shortcut based co-speech gesture generation with spatial-temporal modeling.arXiv preprint arXiv:2501.18898, 2025
-
[18]
Decoupled Weight Decay Regularization
I Loshchilov. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Posegpt: Quantization-based 3d human motion generation and forecasting
Thomas Lucas, Fabien Baradel, Philippe Weinzaepfel, and Grégory Rogez. Posegpt: Quantization-based 3d human motion generation and forecasting. InEuropean Conference on Computer Vision, pages 417–435. Springer, 2022
2022
-
[20]
Synergy and synchrony in couple dances.arXiv preprint arXiv:2409.04440, 2024
V ongani H Maluleke, Lea Müller, Jathushan Rajasegaran, Georgios Pavlakos, Shiry Ginosar, Angjoo Kanazawa, and Jitendra Malik. Synergy and synchrony in couple dances.arXiv preprint arXiv:2409.04440, 2024
-
[21]
Retrieving semantics from the deep: an rag solution for gesture synthesis
M Hamza Mughal, Rishabh Dabral, Merel CJ Scholman, Vera Demberg, and Christian Theobalt. Retrieving semantics from the deep: an rag solution for gesture synthesis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16578–16588, 2025
2025
-
[22]
Hamza Mughal, Rishabh Dabral, Vera Demberg, and Christian Theobalt
M. Hamza Mughal, Rishabh Dabral, Vera Demberg, and Christian Theobalt. Miburi: Towards expressive interactive gesture synthesis. InCVPR, 2026
2026
-
[23]
Learning to listen: Modeling non-deterministic dyadic facial motion.CVPR, 2022
Evonne Ng, Hanbyul Joo, Liwen Hu, Hao Li, Trevor Darrell, Angjoo Kanazawa, and Shiry Ginosar. Learning to listen: Modeling non-deterministic dyadic facial motion.CVPR, 2022
2022
-
[24]
From audio to photoreal embodiment: Synthesizing humans in conversations
Evonne Ng, Javier Romero, Timur Bagautdinov, Shaojie Bai, Trevor Darrell, Angjoo Kanazawa, and Alexander Richard. From audio to photoreal embodiment: Synthesizing humans in conversations. In CVPR, 2024
2024
-
[25]
Sarah: Spatially aware real-time agentic humans, 2026
Evonne Ng, Siwei Zhang, Zhang Chen, Michael Zollhoefer, and Alexander Richard. Sarah: Spatially aware real-time agentic humans, 2026. URLhttps://arxiv.org/abs/2602.18432
-
[26]
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black. Expressive body capture: 3D hands, face, and body from a single image. In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 10975–10985, 2019. 11
2019
-
[27]
Reconstructing hands in 3D with transformers
Georgios Pavlakos, Dandan Shan, Ilija Radosavovic, Angjoo Kanazawa, David Fouhey, and Jitendra Malik. Reconstructing hands in 3D with transformers. InCVPR, 2024
2024
-
[28]
Dyadit: A multi-modal diffusion transformer for socially favorable dyadic gesture generation
Yichen Peng, Jyun-Ting Song, Siyeol Jung, Ruofan Liu, Haiyang Liu, Xuangeng Chu, Ruicong Liu, Erwin Wu, Hideki Koike, and Kris Kitani. Dyadit: A multi-modal diffusion transformer for socially favorable dyadic gesture generation. InCVPR, 2026
2026
-
[29]
Dualtalk: Dual-speaker interaction for 3d talking head conversations
Ziqiao Peng, Yanbo Fan, Haoyu Wu, Xuan Wang, Hongyan Liu, Jun He, and Zhaoxin Fan. Dualtalk: Dual-speaker interaction for 3d talking head conversations. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21055–21064, 2025
2025
-
[30]
Ope- nAI announcement, accessed 2026-05-18
Rajarshi Roy, Jonathan Raiman, Sang gil Lee, Teodor-Dumitru Ene, Robert Kirby, Sungwon Kim, Jaehyeon Kim, and Bryan Catanzaro. Personaplex: V oice and role control for full duplex conversational speech models, 2026. URLhttps://arxiv.org/abs/2602.06053
-
[31]
Glu variants improve transformer, 2020
Noam Shazeer. Glu variants improve transformer, 2020
2020
-
[32]
Roformer: Enhanced transformer with rotary position embedding.Neurocomput., 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomput., 2024
2024
-
[33]
Motionclip: Exposing human motion generation to clip space
Guy Tevet, Brian Gordon, Amir Hertz, Amit H Bermano, and Daniel Cohen-Or. Motionclip: Exposing human motion generation to clip space. InEuropean Conference on Computer Vision, pages 358–374. Springer, 2022
2022
-
[34]
Intercontrol: Zero-shot human interaction generation by controlling every joint.Advances in Neural Information Processing Systems, 37:105397– 105424, 2024
Zhenzhi Wang, Jingbo Wang, Yixuan Li, Dahua Lin, and Bo Dai. Intercontrol: Zero-shot human interaction generation by controlling every joint.Advances in Neural Information Processing Systems, 37:105397– 105424, 2024
2024
-
[35]
Regennet: Towards human action-reaction synthesis
Liang Xu, Yizhou Zhou, Yichao Yan, Xin Jin, Wenhan Zhu, Fengyun Rao, Xiaokang Yang, and Wenjun Zeng. Regennet: Towards human action-reaction synthesis. InCVPR, 2024
2024
-
[36]
Generating holistic 3D human motion from speech
Hongwei Yi, Hualin Liang, Yifei Liu, Qiong Cao, Yandong Wen, Timo Bolkart, Dacheng Tao, and Michael J Black. Generating holistic 3D human motion from speech. InCVPR, 2023
2023
-
[37]
Speech gesture generation from the trimodal context of text, audio, and speaker identity.ACM TOG, page 1–16, 2020
Youngwoo Yoon, Bok Cha, Joo-Haeng Lee, Minsu Jang, Jaeyeon Lee, Jaehong Kim, and Geehyuk Lee. Speech gesture generation from the trimodal context of text, audio, and speaker identity.ACM TOG, page 1–16, 2020
2020
-
[38]
T2m-gpt: Generating human motion from textual descriptions with discrete representations
Jianrong Zhang, Yangsong Zhang, Xiaodong Cun, Shaoli Huang, Yong Zhang, Hongwei Zhao, Hongtao Lu, and Xi Shen. T2m-gpt: Generating human motion from textual descriptions with discrete representations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[39]
Vibes: A conversational agent with behaviorally-intelligent 3d virtual body
Juze Zhang, Changan Chen, Xin Chen, Heng Yu, Tiange Xiang, Ali Sartaz Khan, Shrinidhi Kowshika Lakshmikanth, and Ehsan Adeli. Vibes: A conversational agent with behaviorally-intelligent 3d virtual body. InCVPR, 2026
2026
-
[40]
On the continuity of rotation representa- tions in neural networks
Yi Zhou, Connelly Barnes, Jingwan Lu, Jimei Yang, and Hao Li. On the continuity of rotation representa- tions in neural networks. InCVPR, 2019
2019
-
[41]
<system> You enjoy having a good conversation. <system>
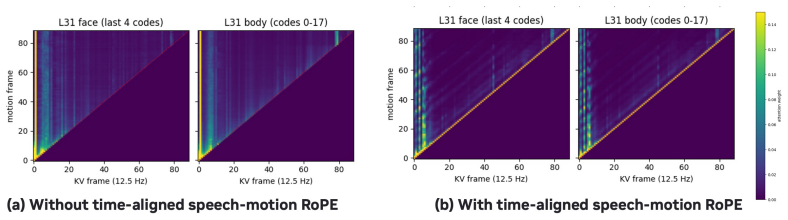
Lingting Zhu, Xian Liu, Xuanyu Liu, Rui Qian, Ziwei Liu, and Lequan Yu. Taming diffusion models for audio-driven co-speech gesture generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10544–10553, 2023. 12 Figure 5: Comparisons without (a) and with (b) time-aligned speech-motion RoPE. A Discussion A.1 Limi...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.