Attribution via Distributional Paths for Information Revelation
Pith reviewed 2026-06-28 11:26 UTC · model grok-4.3
The pith
Reveal-IG attributes model predictions by integrating expected output changes along paths through structured probe distributions instead of raw inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Reveal-IG defines attribution as the integral of changes in expected model output along a path in the space of probe distributions. By traversing distributions that gradually reveal information rather than raw input values, the method retains the completeness axiom, accommodates multiscale and uncertain probes without equal weighting of all scales, and eliminates the path artifacts that arise when early baseline-adjacent points contribute on equal footing with the input itself.
What carries the argument
The distributional path through a family of structured probe distributions, along which the integral of the gradient of expected model output is taken.
If this is right
- Attributions sum exactly to the difference between the expected model output at the baseline distribution and at the input distribution.
- Multiscale image probes receive resolution-appropriate weighting without manual adjustment of the path.
- Feature-wise uncertainty in tabular data is incorporated directly into the probe distributions rather than treated as post-processing.
- Synthetic tests show the method avoids the path artifacts that affect input-space trajectory methods.
- Signed attributions remain stable across runs and outperform other methods on sign-aware evaluation metrics.
Where Pith is reading between the lines
- The same distributional-path construction could be applied to other path-based explanation techniques to obtain completeness with respect to expectations.
- Domains with high input uncertainty, such as sensor data or noisy measurements, could adopt the framework to produce attributions that reflect that uncertainty by design.
- Automatic or learned selection of probe families might remove the remaining manual choice of distribution family while preserving the artifact-free property.
- Information-theoretic measures of revelation along the path could quantify how much new information each scale or feature contributes to the prediction.
Load-bearing premise
A family of structured probe distributions can be chosen so that the integral along the distributional path produces attributions free of new artifacts and without requiring post-hoc tuning of the probe family for each model or dataset.
What would settle it
A synthetic diagnostic in which Reveal-IG attributions on a controlled example display path artifacts of comparable magnitude to those seen in input-space Integrated Gradients or fail to sum exactly to the change in expected model output.
Figures
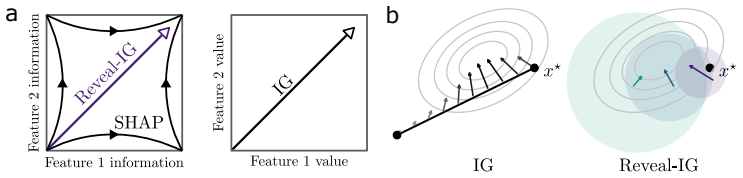
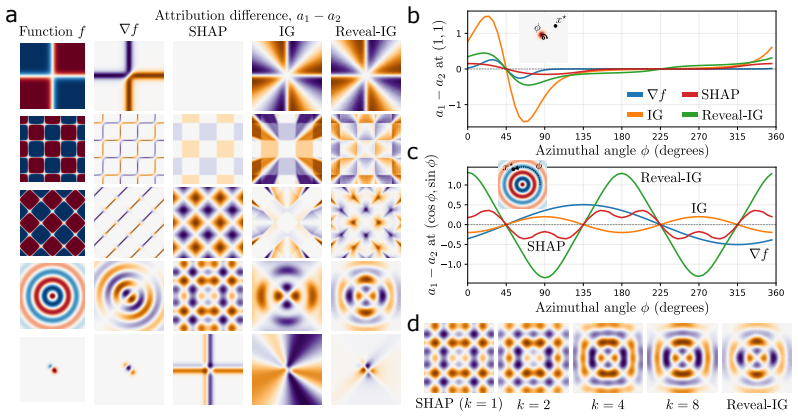

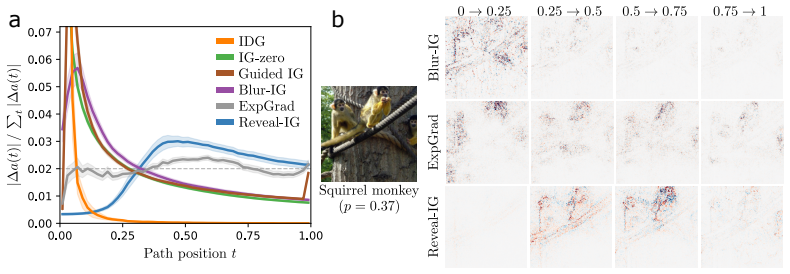


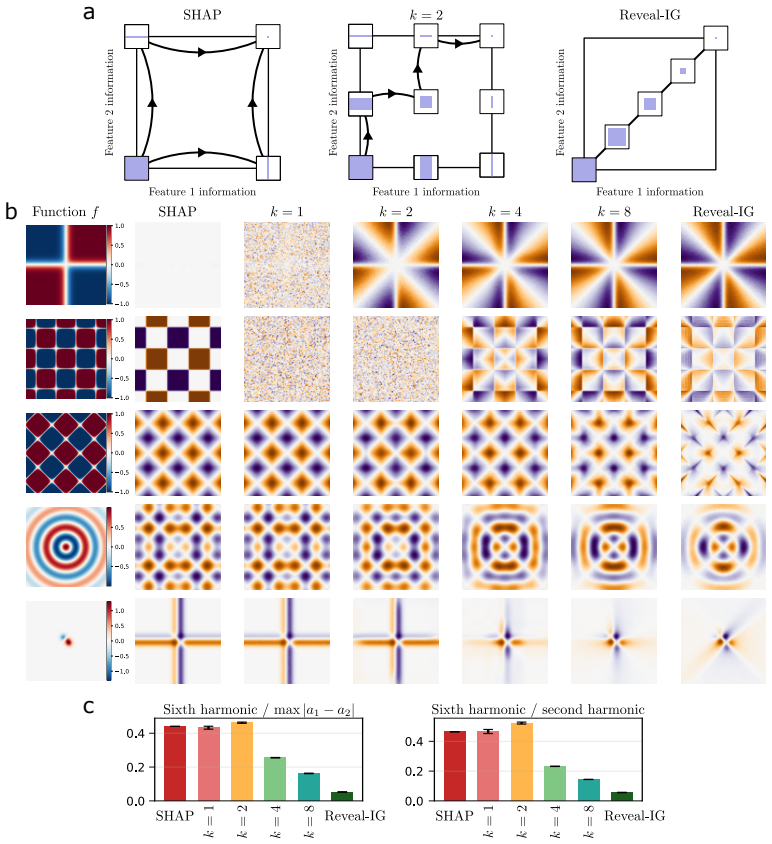
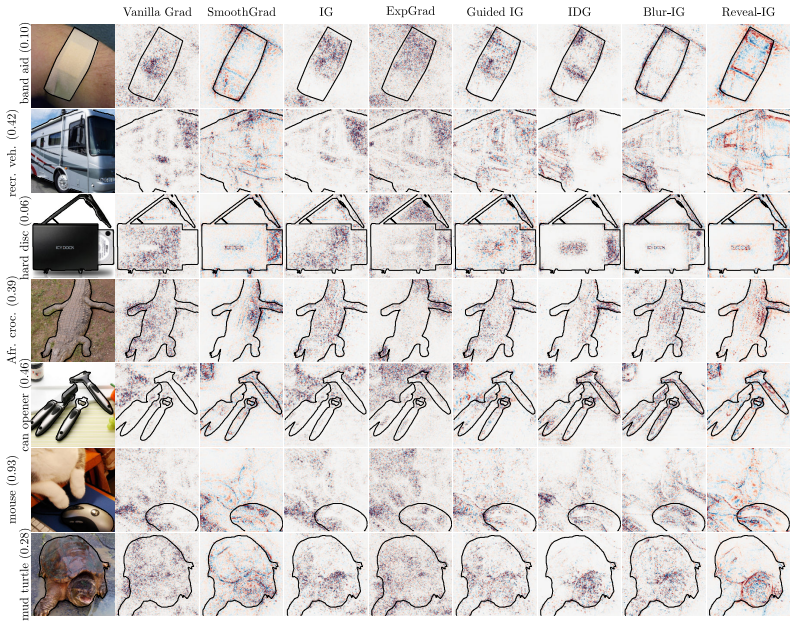

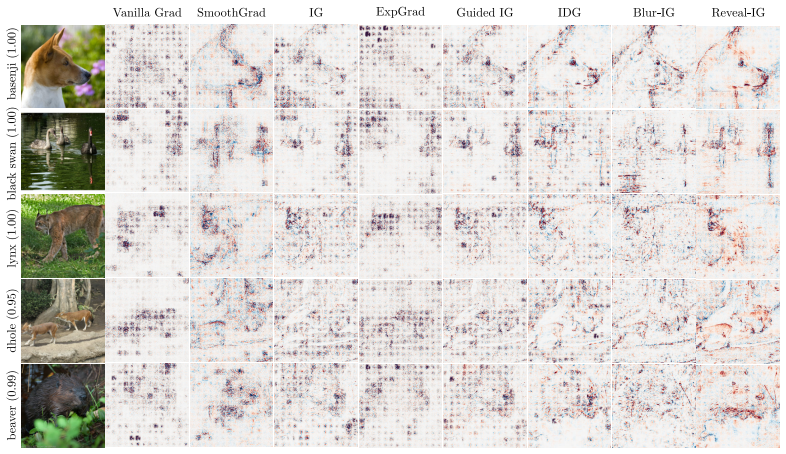
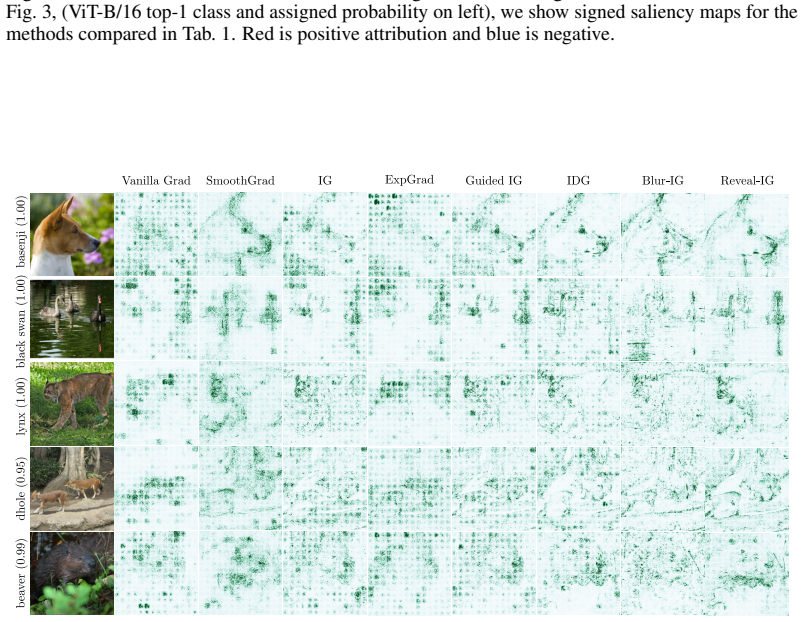
read the original abstract
Feature attribution methods explain predictions by assigning importance scores to input features. Path-based methods such as Integrated Gradients are especially appealing because they satisfy \textit{completeness}: attributions sum to the change in model output between a reference state and the input. Yet most path methods define this trajectory in input space, explaining a model through pointwise perturbed inputs along a chosen path. An input-space path integrates the model's raw response at each point it passes through, with no control over the resolution at which a feature is queried; the early, baseline-adjacent part of the trajectory contributes to the explanation on equal footing with the input itself. Here, we lift path attribution from input space to a space of structured probe distributions around the example of interest, and call our method Reveal-IG. Rather than traversing raw input values, Reveal-IG progressively reveals information about the input and attributes changes in the model's expected output along this distributional path. The result is a path-attribution framework that retains completeness with respect to the expected model response, and naturally accommodates multiscale image probes and feature-wise uncertainty in tabular data. Synthetic diagnostics show that Reveal-IG avoids path artifacts that affect input-space methods, and across ImageNet classification and tabular regression it produces stable, signed attributions -- leading on metrics that use attribution sign while remaining competitive on the rest.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Reveal-IG, which lifts Integrated Gradients from input-space paths to paths in a space of structured probe distributions. Rather than integrating the model's response along a trajectory of raw inputs, the method integrates changes in expected model output as information about the input is progressively revealed through a family of probe distributions. The central claims are that the resulting attributions satisfy completeness with respect to the expected model response, naturally support multiscale image probes and feature-wise uncertainty, avoid common path artifacts, and produce stable signed attributions that lead on sign-aware metrics while remaining competitive on others, as shown in synthetic diagnostics and experiments on ImageNet classification and tabular regression.
Significance. If the derivations and empirical results hold, Reveal-IG offers a principled way to control the resolution and uncertainty at which features are queried during attribution, addressing a limitation of standard input-space path methods. The preservation of completeness, the handling of multiscale and uncertain data, and the reported stability on sign-aware metrics would constitute a useful technical contribution to the feature attribution literature.
major comments (2)
- [Method and Experiments] The central construction relies on the existence of a well-behaved probe distribution family that introduces no new artifacts and requires no post-hoc tuning. The paper should provide a concrete sensitivity analysis (e.g., in the experimental section) showing that attribution rankings and sign-aware metrics remain stable across reasonable choices within the family, or else clarify the selection procedure.
- [Synthetic diagnostics] Synthetic diagnostics are invoked to show avoidance of path artifacts, but the specific artifacts tested, the quantitative metrics used, and the comparison baselines must be stated explicitly with numerical results (e.g., in a table) so that the claim can be verified independently.
minor comments (2)
- Notation for the distributional path and the expectation operator should be introduced once and used consistently; cross-references to the completeness proof would help readers.
- Figure captions should explicitly state the probe family and any hyperparameters used so that the visualizations can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation for minor revision. The comments highlight useful ways to strengthen verifiability. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Method and Experiments] The central construction relies on the existence of a well-behaved probe distribution family that introduces no new artifacts and requires no post-hoc tuning. The paper should provide a concrete sensitivity analysis (e.g., in the experimental section) showing that attribution rankings and sign-aware metrics remain stable across reasonable choices within the family, or else clarify the selection procedure.
Authors: We agree that explicit robustness checks are valuable. In the revised version we will add a dedicated sensitivity analysis subsection (and accompanying table) in the experimental section. It will report attribution ranking stability and sign-aware metric values across a range of probe-family parameters (different multiscale widths and uncertainty levels) on both the ImageNet and tabular tasks, together with a brief description of the default selection rule used in the main experiments. revision: yes
-
Referee: [Synthetic diagnostics] Synthetic diagnostics are invoked to show avoidance of path artifacts, but the specific artifacts tested, the quantitative metrics used, and the comparison baselines must be stated explicitly with numerical results (e.g., in a table) so that the claim can be verified independently.
Authors: We accept the request for greater explicitness. The revised synthetic-diagnostics section will enumerate the concrete artifacts examined (saturation near baselines, discontinuity at feature boundaries), define the quantitative metrics (e.g., attribution variance under path perturbation, sign-consistency score), list the baselines (standard IG, SmoothGrad, and a random-path variant), and present the numerical results in a compact table. revision: yes
Circularity Check
No significant circularity; derivation is a direct mathematical lift of IG to distributional paths
full rationale
The paper defines Reveal-IG by lifting the standard Integrated Gradients path integral from input space to a space of structured probe distributions, with the central claim being that the integral of expected-output changes along this distributional path yields attributions that retain completeness w.r.t. the expected model response. No equation reduces the final attribution to a fitted parameter, a quantity defined only in terms of itself, or a result justified solely by self-citation. The construction is presented as a straightforward change of integration domain that preserves the original completeness axiom without introducing new fitted elements or ansatzes smuggled via prior work. Synthetic diagnostics and empirical comparisons are offered as external validation rather than as part of the derivation itself. This is the most common honest finding for a mathematically coherent extension of an existing method.
Axiom & Free-Parameter Ledger
free parameters (1)
- probe distribution family
axioms (1)
- domain assumption The integral of changes in expected model output along the distributional path equals the difference between expected output on the full input and on the baseline.
Reference graph
Works this paper leans on
-
[1]
Explaining deep neural networks and beyond: A review of methods and applications.Proceedings of the IEEE, 109(3):247–278, 2021
Wojciech Samek, Grégoire Montavon, Sebastian Lapuschkin, Christopher J Anders, and Klaus-Robert Müller. Explaining deep neural networks and beyond: A review of methods and applications.Proceedings of the IEEE, 109(3):247–278, 2021
2021
-
[2]
Christoph Molnar.Interpretable Machine Learning: A Guide for Making Black Box Models Explainable. 2022
2022
-
[3]
A unified approach to interpreting model predictions.Advances in neural information processing systems, 30, 2017
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions.Advances in neural information processing systems, 30, 2017
2017
-
[4]
Axiomatic attribution for deep networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. InInternational conference on machine learning, pages 3319–3328. PMLR, 2017
2017
-
[5]
Visualizing the impact of feature attribution baselines
Pascal Sturmfels, Scott Lundberg, and Su-In Lee. Visualizing the impact of feature attribution baselines. Distill, 2020. doi: 10.23915/distill.00022. https://distill.pub/2020/attribution-baselines
-
[6]
Attribution in scale and space
Shawn Xu, Subhashini Venugopalan, and Mukund Sundararajan. Attribution in scale and space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
2020
-
[7]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Andrei Kapishnikov, Subhashini Venugopalan, Besim Avci, Ben Wedin, Michael Terry, and Tolga Bolukbasi. Guided integrated gradients: an adaptive path method for removing noise. In2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5048–5056, 2021. doi: 10.1109/CVPR46437.2021.00501
-
[8]
Understanding global feature contributions with additive importance measures.Advances in neural information processing systems, 33:17212–17223, 2020
Ian Covert, Scott M Lundberg, and Su-In Lee. Understanding global feature contributions with additive importance measures.Advances in neural information processing systems, 33:17212–17223, 2020. 11
2020
-
[9]
Kingma and Max Welling
Diederik P. Kingma and Max Welling. Auto-encoding variational Bayes. InInternational Conference on Learning Representations (ICLR), 2014
2014
-
[10]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[11]
Imagenet large scale visual recognition challenge
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3):211–252, 2015
2015
-
[12]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[13]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021. URL https...
2021
-
[14]
Integrated decision gradients: Compute your attributions where the model makes its decision
Chase Walker, Sumit Jha, Kenny Chen, and Rickard Ewetz. Integrated decision gradients: Compute your attributions where the model makes its decision. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 5289–5297, 2024
2024
-
[15]
Improving performance of deep learning models with axiomatic attribution priors and expected gradients.Nature machine intelligence, 3(7):620–631, 2021
Gabriel Erion, Joseph D Janizek, Pascal Sturmfels, Scott M Lundberg, and Su-In Lee. Improving performance of deep learning models with axiomatic attribution priors and expected gradients.Nature machine intelligence, 3(7):620–631, 2021
2021
-
[16]
Smoothgrad: removing noise by adding noise.arXiv preprint arXiv:1706.03825, 2017
Daniel Smilkov, Nikhil Thorat, Been Kim, Fernanda Viégas, and Martin Wattenberg. Smoothgrad: removing noise by adding noise.arXiv preprint arXiv:1706.03825, 2017
Pith/arXiv arXiv 2017
-
[17]
Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps.arXiv:1312.6034, 2013
Pith/arXiv arXiv 2013
-
[18]
RISE: Randomized input sampling for explanation of black-box models
Vitali Petsiuk, Abir Das, and Kate Saenko. RISE: Randomized input sampling for explanation of black-box models. InBMVC, 2018
2018
-
[19]
Towards better understanding of gradient-based attribution methods for deep neural networks
Marco Ancona, Enea Ceolini, Cengiz Öztireli, and Markus Gross. Towards better understanding of gradient-based attribution methods for deep neural networks. InInternational Conference on Learning Representations, 2018. URLhttps://openreview.net/forum?id=Sy21R9JAW
2018
-
[20]
Clevr-xai: A benchmark dataset for the ground truth evaluation of neural network explanations.Information Fusion, 81:14–40, 2022
Leila Arras, Ahmed Osman, and Wojciech Samek. Clevr-xai: A benchmark dataset for the ground truth evaluation of neural network explanations.Information Fusion, 81:14–40, 2022
2022
-
[21]
Large- scale unsupervised semantic segmentation
Shanghua Gao, Zhong-Yu Li, Ming-Hsuan Yang, Ming-Ming Cheng, Junwei Han, and Philip Torr. Large- scale unsupervised semantic segmentation. 2022
2022
-
[22]
Event labeling combining ensemble detectors and background knowledge
Hadi Fanaee-T and Joao Gama. Event labeling combining ensemble detectors and background knowledge. Progress in Artificial Intelligence, 2(2):113–127, 2014
2014
-
[23]
Sparse spatial autoregressions.Statistics & Probability Letters, 33(3): 291–297, 1997
R Kelley Pace and Ronald Barry. Sparse spatial autoregressions.Statistics & Probability Letters, 33(3): 291–297, 1997
1997
-
[24]
Modeling wine preferences by data mining from physicochemical properties.Decision support systems, 47(4):547–553, 2009
Paulo Cortez, António Cerdeira, Fernando Almeida, Telmo Matos, and José Reis. Modeling wine preferences by data mining from physicochemical properties.Decision support systems, 47(4):547–553, 2009
2009
-
[25]
why should i trust you?
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. " why should i trust you?" explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pages 1135–1144, 2016
2016
-
[26]
Eraser: A benchmark to evaluate rationalized nlp models
Jay DeYoung, Sarthak Jain, Nazneen Fatema Rajani, Eric Lehman, Caiming Xiong, Richard Socher, and Byron C Wallace. Eraser: A benchmark to evaluate rationalized nlp models. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 4443–4458, 2020
2020
-
[27]
Inouye, and Pradeep Ravikumar
Chih-Kuan Yeh, Cheng-Yu Hsieh, Arun Sai Suggala, David I. Inouye, and Pradeep Ravikumar. On the (in)fidelity and sensitivity of explanations. InAdvances in Neural Information Processing Systems (NeurIPS), 2019. 12
2019
-
[28]
Aumann and L.S
R.J. Aumann and L.S. Shapley.Values of Non-atomic Games. Princeton Legacy Library. Prince- ton University Press, 1974. ISBN 9780691081038. URL https://books.google.com/books?id= SIvUAQAACAAJ
1974
-
[29]
Spectral integrated gradients for coarse-to- fine feature attribution
Soyeon Kim, Seongwoo Lim, Kyowoon Lee, and Jaesik Choi. Spectral integrated gradients for coarse-to- fine feature attribution. InProceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2026. URLhttp://arxiv.org/abs/2605.19607
Pith/arXiv arXiv 2026
-
[30]
A rigorous study of integrated gradients method and extensions to internal neuron attributions
Daniel D Lundstrom, Tianjian Huang, and Meisam Razaviyayn. A rigorous study of integrated gradients method and extensions to internal neuron attributions. InInternational Conference on Machine Learning, pages 14485–14508. PMLR, 2022
2022
-
[31]
Stochastic integrated explanations for vision models
Oren Barkan, Yehonatan Elisha, Jonathan Weill, Yuval Asher, Amit Eshel, and Noam Koenigstein. Stochastic integrated explanations for vision models. In2023 IEEE International Conference on Data Mining (ICDM), pages 938–943. IEEE, 2023
2023
-
[32]
Visual explanations via iterated integrated attributions
Oren Barkan, Yehonatan Elisha, Yuval Asher, Amit Eshel, and Noam Koenigstein. Visual explanations via iterated integrated attributions. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[33]
Denoising diffusion path: Attribution noise reduction with an auxiliary diffusion model.Advances in Neural Information Processing Systems, 37: 54003–54025, 2024
Yiming Lei, Zilong Li, Junping Zhang, and Hongming Shan. Denoising diffusion path: Attribution noise reduction with an auxiliary diffusion model.Advances in Neural Information Processing Systems, 37: 54003–54025, 2024
2024
-
[34]
Probabilistic path integration with mixture of baseline distributions
Yehonatan Elisha, Oren Barkan, and Noam Koenigstein. Probabilistic path integration with mixture of baseline distributions. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 570–580, 2024
2024
-
[35]
Restricting the flow: Information bottlenecks for attribution
Karl Schulz, Leon Sixt, Federico Tombari, and Tim Landgraf. Restricting the flow: Information bottlenecks for attribution. InInternational Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=S1xWh1rYwB
2020
-
[36]
Inserting Information Bottlenecks for Attribution in Transformers
Zhiying Jiang, Raphael Tang, Ji Xin, and Jimmy Lin. Inserting Information Bottlenecks for Attribution in Transformers. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 3850–3857, Online, November 2020. Association for Computational Linguistics. URL https://www. aclweb.org/anthology/2020.findings-emnlp.343
2020
-
[37]
Showui: One vision-language- action model for GUI visual agent
Jung-Ho Hong, Ho-Joong Kim, Kyu-Sung Jeon, and Seong-Whan Lee. Comprehensive information bottleneck for unveiling universal attribution to interpret vision transformers. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 25166–25175, 2025. doi: 10.1109/CVPR52734.2025.02343
-
[38]
Kieran A Murphy and Dani S. Bassett. Interpretability with full complexity by constraining feature information. InInternational Conference on Learning Representations (ICLR), 2023. URL https: //openreview.net/forum?id=R_OL5mLhsv
2023
-
[39]
Information decomposition in complex systems via machine learning.Proceedings of the National Academy of Sciences, 121(13):e2312988121, 2024
Kieran A Murphy and Dani S Bassett. Information decomposition in complex systems via machine learning.Proceedings of the National Academy of Sciences, 121(13):e2312988121, 2024
2024
-
[40]
Captum: A unified and generic model interpretability library for pytorch, 2020
Narine Kokhlikyan, Vivek Miglani, Miguel Martin, Edward Wang, Bilal Alsallakh, Jonathan Reynolds, Alexander Melnikov, Natalia Kliushkina, Carlos Araya, Siqi Yan, and Orion Reblitz-Richardson. Captum: A unified and generic model interpretability library for pytorch, 2020. A Implementation Details Code for the synthetic, image, and tabular attribution exper...
arXiv 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.