MAdam: Metric-Aware Multi-Objective Adam
Pith reviewed 2026-06-28 11:19 UTC · model grok-4.3
The pith
MAdam preconditions the reconciled direction with the preference-conditioned curvature of the scalarized objective to align Adam's updates with the multi-objective solver's intent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
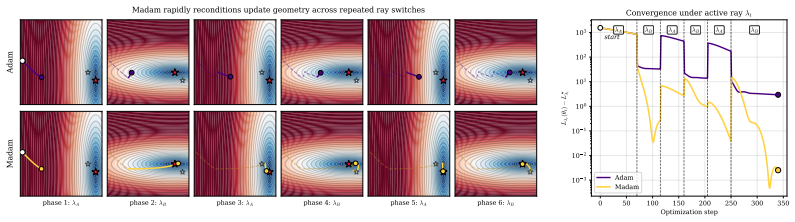
MAdam resolves the weighting and geometric mismatches by preconditioning the reconciled direction by the preference-conditioned curvature of the scalarized objective; on this whitened input, Adam's second moment collapses to identity, so the realized update is governed by the preference-conditioned metric.
What carries the argument
The preference-conditioned curvature preconditioner applied to the reconciled direction before it enters Adam.
If this is right
- Adam's second-moment denominator no longer marginalizes the time-varying preference into a history average.
- The adaptive metric stops turning aligned objectives into apparent conflicts by respecting the Euclidean geometry assumed by the solver.
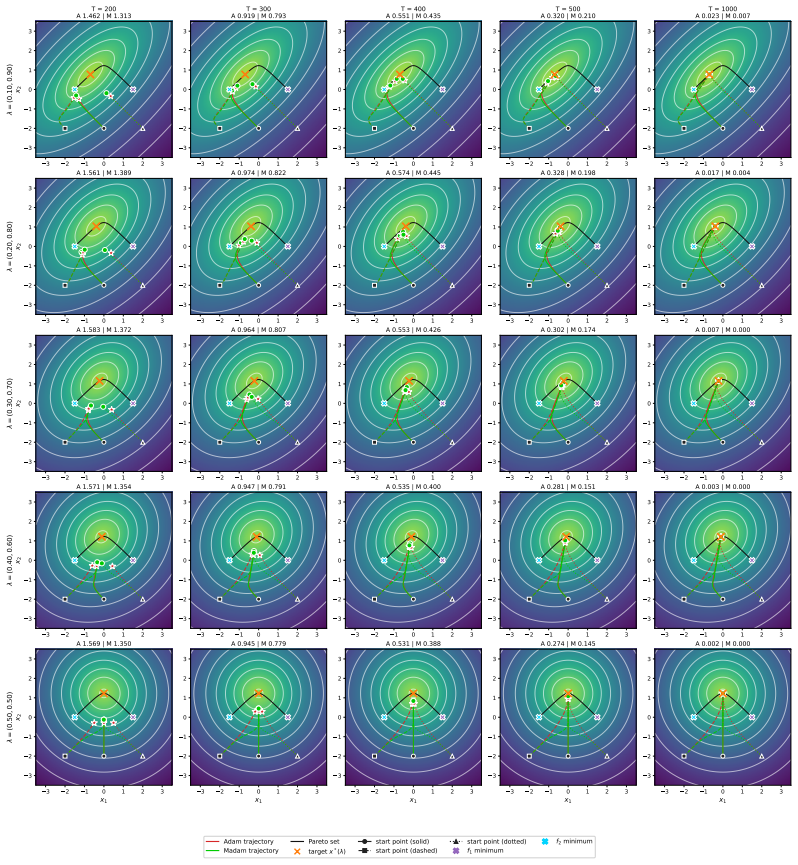
- Distinct Pareto trade-offs remain separated instead of collapsing toward a uniform mixture.
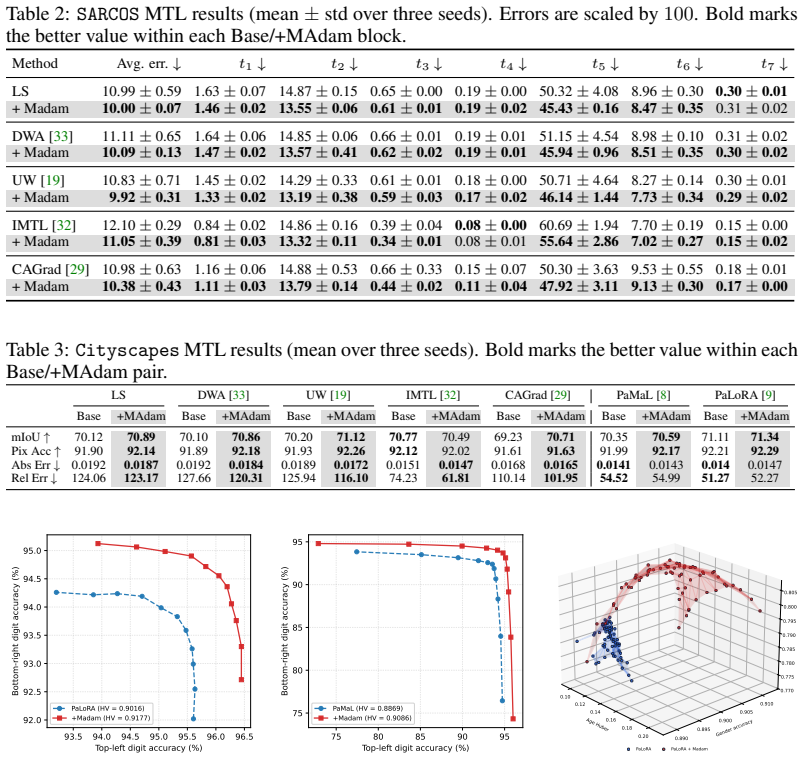
- MAdam improves performance over Adam for loss-balancing, gradient-balancing, and Pareto-based solver families.
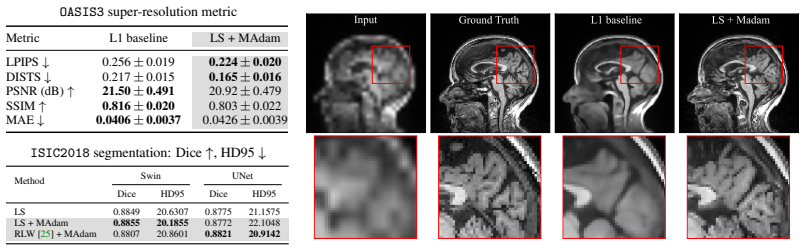
- Gains appear across multi-task learning, Pareto-front recovery, physics-informed neural networks, and medical imaging.
Where Pith is reading between the lines
- The same preconditioning idea could be tested on other adaptive methods such as RMSProp or Adagrad to check whether similar preference-entanglement effects appear.
- Dynamic preference vectors that change during training might become easier to track once the curvature term isolates the current preference from historical statistics.
- If the curvature computation stays cheap, the wrapper pattern suggests a general route for making any adaptive optimizer respect an externally supplied scalarization metric.
Load-bearing premise
That the weighting and geometric mismatches are the dominant sources of sub-optimality and that preconditioning with the preference-conditioned curvature removes them without new side effects or prohibitive cost.
What would settle it
Experiments on the same multi-task, Pareto, and physics-informed tasks where MAdam produces no consistent improvement or worse results than standard Adam would falsify the claim that the preconditioner resolves the identified mismatches.
Figures

read the original abstract
Multi-objective optimization (MOO) underlies many machine learning problems, yet MOO solvers across the loss-balancing, gradient-balancing, and Pareto-based families almost universally hand their reconciled directions to Adam~\cite{kingma2015adam}. We show this coupling introduces two systematic gaps between the solver's intent and the optimizer's execution. The first is a \emph{weighting mismatch}: Adam's second-moment denominator entangles the time-varying preference vector with gradient statistics, marginalizing the preference into a history average and collapsing distinct Pareto trade-offs toward a near-uniform mixture. The second is a \emph{geometric mismatch}: Adam's adaptive metric distorts the Euclidean geometry MOO solvers assume, turning aligned objectives into apparent conflicts. To resolve both jointly, we introduce \textbf{MAdam} (Metric-Aware Multi-Objective Adam), a drop-in wrapper that leaves both solver and optimizer unchanged. MAdam preconditions the reconciled direction by the preference-conditioned curvature of the scalarized objective; on this whitened input, Adam's second moment collapses to identity, so the realized update is governed by the preference-conditioned metric. Across multi-task learning, Pareto-front recovery, physics-informed neural networks, and medical imaging, MAdam consistently improves over Adam for every solver family.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies two systematic gaps when MOO solvers (loss-balancing, gradient-balancing, Pareto-based) hand reconciled directions to Adam: a weighting mismatch in which Adam's second-moment statistics entangle the time-varying preference vector, and a geometric mismatch in which Adam's adaptive metric distorts the Euclidean geometry assumed by the solvers. It introduces MAdam, a drop-in wrapper that preconditions the reconciled direction by the preference-conditioned curvature of the scalarized objective; the abstract asserts that this whitens the input so Adam's second moment collapses to identity and the realized update is governed by the preference-conditioned metric. Experiments across multi-task learning, Pareto-front recovery, PINNs, and medical imaging report consistent gains over Adam for every solver family.
Significance. If the central preconditioning argument holds and the realized update is indeed governed purely by the supplied preference-conditioned metric, the method would supply a lightweight, solver-agnostic fix for a pervasive coupling problem in multi-objective machine learning, with direct applicability to the listed domains.
major comments (1)
- [Abstract] Abstract: the claim that preconditioning the reconciled direction r by the curvature C of the scalarized loss L_λ produces a whitened input on which 'Adam's second moment collapses to identity' is not supported by the stated construction. Adam's v_t is an EMA of g_t ⊙ g_t where g = C^{-1/2} r; for the EMA to become the identity vector it is necessary that E[g_i²] = 1 coordinate-wise, which holds only if C is (approximately) the second-moment matrix of r itself. Because r is the output of an arbitrary MOO solver and is not in general distributed as ∇L_λ, E[r r^T] ≠ C, so the second-moment adaptation remains non-trivial and the update is governed by a composite rather than a pure preference-conditioned metric. This directly undermines the stated resolution of both mismatches.
Simulated Author's Rebuttal
We thank the referee for identifying this subtlety in the abstract's central claim. The comment correctly notes that exact collapse of Adam's second-moment vector to the identity requires the preconditioned direction to match the second-moment structure of the scalarized gradient, which does not hold for arbitrary MOO solvers. We address this point directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that preconditioning the reconciled direction r by the curvature C of the scalarized loss L_λ produces a whitened input on which 'Adam's second moment collapses to identity' is not supported by the stated construction. Adam's v_t is an EMA of g_t ⊙ g_t where g = C^{-1/2} r; for the EMA to become the identity vector it is necessary that E[g_i²] = 1 coordinate-wise, which holds only if C is (approximately) the second-moment matrix of r itself. Because r is the output of an arbitrary MOO solver and is not in general distributed as ∇L_λ, E[r r^T] ≠ C, so the second-moment adaptation remains non-trivial and the update is governed by a composite rather than a pure preference-conditioned metric. This directly undermines the stated resolution of both mismatches.
Authors: We agree that the abstract's wording is imprecise. The preconditioning g = C^{-1/2} r aligns the input direction with the preference-conditioned metric of L_λ, so that the geometry of the update is governed by that metric rather than the original Euclidean geometry assumed by the MOO solver. However, Adam's subsequent EMA of g ⊙ g will generally remain non-identity because r is a reconciled direction whose second-moment structure need not coincide with C. Consequently the realized step is a composite of the preference-conditioned metric and Adam's adaptive normalization in the whitened coordinates. We will revise the abstract to remove the claim that the second moment 'collapses to identity' and instead state that MAdam ensures the effective metric of the update is the preference-conditioned curvature (with Adam providing coordinate-wise normalization within that metric). This preserves the resolution of the geometric mismatch while acknowledging that the weighting mismatch is mitigated rather than eliminated. revision: yes
Circularity Check
No circularity: MAdam is a new wrapper construction whose central claim does not reduce to fitted inputs or self-citation chains.
full rationale
The paper introduces MAdam as a drop-in preconditioner that leaves solver and optimizer unchanged. The abstract states the preconditioning step and asserts the collapse of Adam's second moment without any equations that define the output in terms of itself or rename a fitted quantity as a prediction. No self-citations appear in the provided text, and the cited Adam reference is external. The derivation chain is therefore self-contained; the method's validity rests on external empirical evaluation rather than internal reduction to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S.-i. Amari. Natural gradient works efficiently in learning.Neural Computation, 10(2):251– 276, 1998
1998
-
[2]
Blau and T
Y . Blau and T. Michaeli. The perception-distortion tradeoff. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6228–6237, 2018
2018
-
[3]
L. Chen, A. Saif, Y . Shen, and T. Chen. Ferero: A flexible framework for preference-guided multi-objective learning.Advances in Neural Information Processing Systems, 37:18758– 18805, 2024
2024
- [4]
-
[5]
Z. Chen, V . Badrinarayanan, C.-Y . Lee, and A. Rabinovich. Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks. InInternational conference on machine learning, pages 794–803. PMLR, 2018
2018
-
[6]
N. Codella, V . Rotemberg, P. Tschandl, M. E. Celebi, S. Dusza, D. Gutman, B. Helba, A. Kalloo, K. Liopyris, M. Marchetti, et al. Skin lesion analysis toward melanoma detec- tion 2018: A challenge hosted by the international skin imaging collaboration (ISIC). InarXiv preprint arXiv:1902.03368, 2019
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Cordts, M
M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016
2016
-
[8]
Dimitriadis, P
N. Dimitriadis, P. Frossard, and F. Fleuret. Pareto manifold learning: Tackling multiple tasks via ensembles of single-task models. InInternational Conference on Machine Learning. PMLR, 2023
2023
-
[9]
Dimitriadis, P
N. Dimitriadis, P. Frossard, and F. Fleuret. Pareto low-rank adapters: Efficient multi-task learning with preferences. InInternational Conference on Learning Representations, 2025
2025
-
[10]
K. Ding, K. Ma, S. Wang, and E. P. Simoncelli. Image quality assessment: Unifying structure and texture similarity.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44 (5):2567–2581, 2022
2022
-
[11]
Fifty, E
C. Fifty, E. Amid, Z. Zhao, T. Yu, R. Anil, and C. Finn. Efficiently identifying task groupings for multi-task learning. InAdvances in Neural Information Processing Systems, 2021
2021
-
[12]
George, C
T. George, C. Laurent, X. Bouthillier, N. Ballas, and P. Vincent. Fast approximate natural gradient descent in a kronecker factored eigenbasis. InAdvances in Neural Information Pro- cessing Systems, volume 31, 2018
2018
-
[13]
Gupta, T
V . Gupta, T. Koren, and Y . Singer. Shampoo: Preconditioned stochastic tensor optimization. InInternational Conference on Machine Learning, pages 1842–1850. PMLR, 2018
2018
-
[14]
Z. Hao, J. Yao, C. Su, H. Su, Z. Wang, F. Lu, Z. Xia, Y . Zhang, S. Liu, L. Lu, et al. Pinnacle: A comprehensive benchmark of physics-informed neural networks for solving pdes.Advances in Neural Information Processing Systems, 37:76721–76774, 2024
2024
-
[15]
Hatamizadeh, V
A. Hatamizadeh, V . Nath, Y . Tang, D. Yang, H. R. Roth, and D. Xu. Swin unetr: Swin trans- formers for semantic segmentation of brain tumors in mri images. InInternational MICCAI brainlesion workshop, pages 272–284. Springer, 2021
2021
- [16]
-
[17]
A. D. Jagtap, K. Kawaguchi, and G. E. Karniadakis. Adaptive activation functions acceler- ate convergence in deep and physics-informed neural networks.Journal of Computational Physics, 404:109136, 2020. 10
2020
-
[18]
Javaloy and I
A. Javaloy and I. Valera. RotoGrad: Gradient homogenization in multitask learning. InInter- national Conference on Learning Representations, 2022
2022
-
[19]
Kendall, Y
A. Kendall, Y . Gal, and R. Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. InIEEE Conference on Computer Vision and Pattern Recog- nition, 2018
2018
-
[20]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. InInternational Conference on Learning Representations, 2015
2015
-
[21]
Kunstner, L
F. Kunstner, L. Balles, and P. Hennig. Limitations of the empirical fisher approximation for natural gradient descent. InAdvances in Neural Information Processing Systems, 2019
2019
-
[22]
P. J. LaMontagne, T. L. Benzinger, J. C. Morris, S. Keefe, R. Hornbeck, C. Xiong, E. Grant, J. Hassenstab, K. Moulder, A. G. Vlassenko, et al. Oasis-3: longitudinal neuroimaging, clin- ical, and cognitive dataset for normal aging and alzheimer disease.medrxiv, pages 2019–12, 2019
2019
-
[23]
Y . LeCun. The mnist database of handwritten digits.http://yann. lecun. com/exdb/mnist/, 1998
1998
- [24]
-
[25]
B. Lin, F. Ye, Y . Zhang, and I. W. Tsang. Reasonable effectiveness of random weighting: A litmus test for multi-task learning.Transactions on Machine Learning Research, 2022
2022
- [26]
-
[27]
Lin, H.-L
X. Lin, H.-L. Zhen, Z. Li, Q.-F. Zhang, and S. Kwong. Pareto multi-task learning. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
- [28]
-
[29]
B. Liu, X. Liu, X. Jin, P. Stone, and Q. Liu. Conflict-averse gradient descent for multi-task learning.Advances in neural information processing systems, 34:18878–18890, 2021
2021
-
[30]
B. Liu, Y . Feng, P. Stone, and Q. Liu. Famo: Fast adaptive multitask optimization. InAdvances in Neural Information Processing Systems, 2024
2024
- [31]
-
[32]
L. Liu, Y . Li, Z. Kuang, J.-H. Xue, Y . Chen, W. Yang, Q. Liao, and W. Zhang. Towards impartial multi-task learning. InInternational Conference on Learning Representations, 2021
2021
-
[33]
S. Liu, E. Johns, and A. J. Davison. End-to-end multi-task learning with attention. InIEEE Conference on Computer Vision and Pattern Recognition, 2019
2019
-
[34]
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF in- ternational conference on computer vision, pages 10012–10022, 2021
2021
-
[35]
Mahapatra and V
D. Mahapatra and V . Rajan. Multi-task learning with user preferences: Gradient descent with controlled ascent in Pareto optimization. InInternational Conference on Machine Learning. PMLR, 2020
2020
-
[36]
Malkiel and L
I. Malkiel and L. Wolf. MTAdam: Automatic balancing of multiple training loss terms. InCon- ference on Empirical Methods in Natural Language Processing, pages 10713–10729, 2021
2021
-
[37]
J. Martens. New insights and perspectives on the natural gradient method.Journal of Machine Learning Research, 21(146):1–76, 2020. 11
2020
-
[38]
Martens and R
J. Martens and R. Grosse. Optimizing neural networks with Kronecker-factored approximate curvature. InInternational Conference on Machine Learning, pages 2408–2417. PMLR, 2015
2015
-
[39]
Navon, A
A. Navon, A. Shamsian, I. Achituve, H. Maron, K. Kawaguchi, G. Chechik, and E. Fetaya. Multi-task learning as a bargaining game. InInternational Conference on Machine Learning, pages 16428–16446. PMLR, 2022
2022
-
[40]
Paszke, S
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[41]
Raissi, P
M. Raissi, P. Perdikaris, and G. E. Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial dif- ferential equations.Journal of Computational Physics, 378:686–707, 2019
2019
-
[42]
Ronneberger, P
O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical im- age segmentation. InInternational Conference on Medical image computing and computer- assisted intervention, pages 234–241. Springer, 2015
2015
-
[43]
Ruchte and J
M. Ruchte and J. Grabocka. Scalable pareto front approximation for deep multi-objective learning. InIEEE International Conference on Data Mining, pages 1306–1311. IEEE, 2021
2021
-
[44]
Sener and V
O. Sener and V . Koltun. Multi-task learning as multi-objective optimization. InAdvances in Neural Information Processing Systems, volume 31, 2018
2018
-
[45]
Senushkin, N
D. Senushkin, N. Patakin, A. Kuznetsov, and A. Konushin. Independent component alignment for multi-task learning. InIEEE Conference on Computer Vision and Pattern Recognition, 2023
2023
-
[46]
Silberman, D
N. Silberman, D. Hoiem, P. Kohli, and R. Fergus. Indoor segmentation and support inference from rgbd images. InEuropean conference on computer vision, pages 746–760. Springer, 2012
2012
-
[47]
Soen and K
A. Soen and K. Sun. Trade-offs of diagonal fisher information matrix estimators.Advances in Neural Information Processing Systems, 37:5870–5912, 2024
2024
-
[48]
Q. Tong, G. Liang, and J. Bi. Calibrating the adaptive learning rate to improve convergence of ADAM.Neurocomputing, 481:333–356, 2022
2022
-
[49]
Vijayakumar and S
S. Vijayakumar and S. Schaal. Locally weighted projection regression: An o (n) algorithm for incremental real time learning in high dimensional space. InProceedings of the seven- teenth international conference on machine learning (ICML 2000), volume 1, pages 288–293. Stanford, CA, 2000
2000
-
[50]
N. Vyas, D. Morwani, R. Zhao, I. Shapira, D. Brandfonbrener, L. Janson, and S. M. Kakade. SOAP: Improving and stabilizing shampoo using adam for language modeling. InInterna- tional Conference on Learning Representations, 2025
2025
-
[51]
S. Wang, Y . Teng, and P. Perdikaris. Understanding and mitigating gradient flow pathologies in physics-informed neural networks.SIAM Journal on Scientific Computing, 43(5):A3055– A3081, 2021
2021
-
[52]
S. Wang, X. Yu, and P. Perdikaris. When and why PINNs fail to train: A neural tangent kernel perspective.Journal of Computational Physics, 449:110768, 2022
2022
-
[53]
Z. Wang, Y . Tsvetkov, O. Firat, and Y . Cao. Gradient vaccine: Investigating and improving multi-task optimization in massively multilingual models. InInternational Conference on Learning Representations, 2021
2021
-
[54]
C. Wu, M. Zhu, Q. Tan, Y . Kartha, and L. Lu. A comprehensive study of non-adaptive and residual-based adaptive sampling for physics-informed neural networks.Computer Methods in Applied Mechanics and Engineering, 403:115671, 2023. 12
2023
-
[55]
X. Wu, W. Yu, C. Zhang, and P. Woodland. An improved empirical fisher approximation for natural gradient descent.Advances in Neural Information Processing Systems, 37:134151– 134194, 2024
2024
-
[56]
E. Yang, J. Pan, X. Wang, H. Yu, L. Shen, X. Chen, L. Xiao, J. Jiang, and G. Guo. AdaTask: A task-aware adaptive learning rate approach to multi-task learning. InAAAI Conference on Artificial Intelligence, pages 10745–10753, 2023
2023
-
[57]
Z. Yao, A. Gholami, S. Shen, M. Mustafa, K. Keutzer, and M. W. Mahoney. AdaHessian: An adaptive second order optimizer for machine learning. InAAAI Conference on Artificial Intelligence, 2021
2021
-
[58]
T. Yu, S. Kumar, A. Gupta, S. Levine, K. Hausman, and C. Finn. Gradient surgery for multi- task learning. InAdvances in Neural Information Processing Systems, volume 33, pages 5824– 5836, 2020
2020
-
[59]
Zhang, P
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 586–595, 2018
2018
-
[60]
Zhang, C
Y . Zhang, C. Chen, T. Ding, Z. Li, R. Sun, and Z.-Q. Luo. Why transformers need Adam: A Hessian perspective. InAdvances in Neural Information Processing Systems, 2024
2024
-
[61]
Z. Zhang, Y . Song, and H. Qi. Age progression/regression by conditional adversarial autoen- coder. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5810–5818, 2017. 13 Appendix Outline A Comprehensive Related Work 15 B Proof of Proposition 2 16 C Sign-Flip Under Adam’s Geometric Mismatch 17 C.1 Geometric Sign Flips (...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.