SparseStreet: Sparse Gaussian Splatting for Real-Time Street Scene Simulation
Pith reviewed 2026-06-28 10:50 UTC · model grok-4.3
The pith
SparseStreet prunes 3D Gaussians in street scenes to cut storage by up to 80 percent while keeping moving objects intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
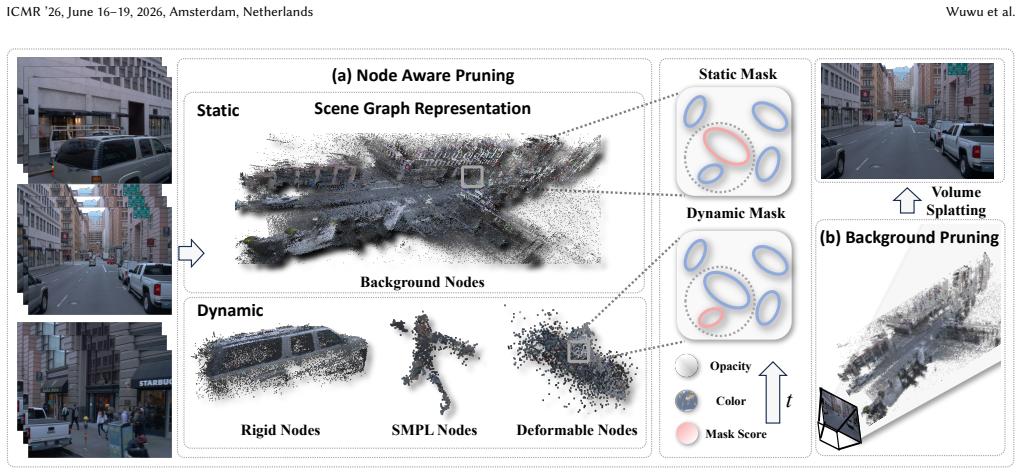
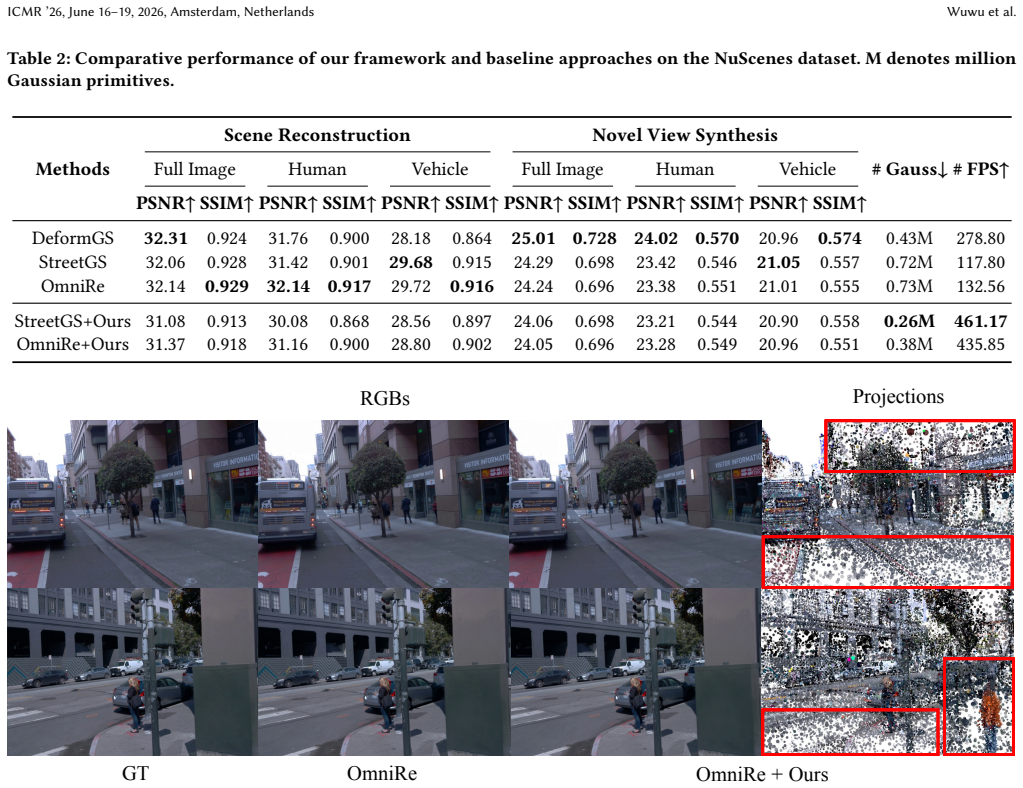
SparseStreet introduces a compression framework for Gaussian Splatting in street scenes that first applies node-based learnable pruning to remove low-contributing primitives and then compresses static background regions, achieving up to 80% reduction in primitives while preserving the geometry and appearance of dynamic objects on Waymo and nuScenes datasets.
What carries the argument
Node-based learnable pruning strategy that removes low-contributing Gaussian primitives while preserving critical regions, followed by background compression.
If this is right
- Real-time rendering becomes feasible on hardware with limited memory because the total number of Gaussians drops sharply.
- Dynamic objects retain their geometry and appearance, so simulation applications can still track moving traffic accurately.
- Storage costs for large-scale street scene datasets fall enough to allow more scenes to be kept on disk or in memory.
- The same pruning logic can be applied after any initial Gaussian optimization step once the scene representation stabilizes.
Where Pith is reading between the lines
- The same dynamic-versus-static distinction could guide compression in other outdoor reconstruction tasks such as aerial mapping.
- Combining the pruning with existing acceleration structures for Gaussian splatting might push frame rates higher without further quality loss.
- If the redundancy pattern holds in indoor scenes, the framework could be adapted by redefining which regions count as background.
Load-bearing premise
Static background regions contain substantial redundancy that can be pruned without harming overall scene quality or the temporal consistency of dynamic objects.
What would settle it
Rendering the compressed model on held-out Waymo sequences and measuring whether temporal consistency metrics for vehicles and pedestrians drop below the uncompressed baseline.
Figures


read the original abstract
While 3D Gaussian Splatting has shown promising results in street scene reconstruction, existing methods require massive numbers of Gaussian primitives to capture fine details, leading to prohibitive storage costs and slow rendering speeds. We observe that dynamic objects (e.g., vehicles and pedestrians) demand high-fidelity representations to maintain temporal consistency, while static background regions often contain substantial redundancy. Motivated by this, we propose SparseStreet, a general compression framework specifically designed for street scenes. First, we introduce a node-based learnable pruning strategy that systematically removes low-contributing Gaussian primitives while preserving visually critical regions. Second, after the scene representation stabilizes, we apply background compression, further reducing redundancy in static regions. Our method effectively preserves the geometry and appearance of dynamic objects while significantly reducing the total number of Gaussian primitives. Extensive experiments on the Waymo and nuScenes demonstrate that SparseStreet achieves up to 80% compression ratio with minimal quality degradation, enabling resource-efficient, high-fidelity dynamic scene reconstruction. Project website: https://sparsestreet.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SparseStreet, a compression framework for 3D Gaussian Splatting in street scenes. It introduces a node-based learnable pruning strategy to remove low-contributing primitives while preserving visually critical regions, followed by background compression on static areas. The central claim is that this achieves up to 80% compression ratio on Waymo and nuScenes with minimal quality degradation, while preserving the geometry and appearance of dynamic objects for temporal consistency.
Significance. If the empirical claims hold with proper validation, the work could support more resource-efficient real-time rendering and simulation of complex urban environments, which is relevant for applications requiring both fidelity on moving objects and reduced storage/rendering costs.
major comments (2)
- Abstract: the central claim of 'up to 80% compression ratio with minimal quality degradation' and preservation of dynamic objects is stated without any quantitative metrics, baselines, ablation studies, or error analysis, so the result cannot be assessed from the provided text.
- Abstract (motivation and method): the node-based learnable pruning is said to remove low-contributing Gaussians while 'preserving visually critical regions' and dynamic objects, but no explicit mechanism (dynamic mask, motion-aware weighting, or post-pruning re-optimization) is described; contribution-based pruning can assign low scores to dynamic-object Gaussians due to limited views and occlusions, directly risking the temporal-consistency claim.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on the abstract. We address each point below and indicate where revisions will be made to strengthen the presentation of claims and method details.
read point-by-point responses
-
Referee: Abstract: the central claim of 'up to 80% compression ratio with minimal quality degradation' and preservation of dynamic objects is stated without any quantitative metrics, baselines, ablation studies, or error analysis, so the result cannot be assessed from the provided text.
Authors: We agree that the abstract summarizes results at a high level without embedding specific metrics. The full manuscript reports quantitative results on Waymo and nuScenes, including compression ratios up to 80%, PSNR/SSIM/LPIPS comparisons to 3DGS baselines and prior compression methods, ablation studies on the pruning components, and separate analysis of dynamic-object fidelity. To improve assessability from the abstract itself, we will revise it to incorporate one or two key quantitative indicators (e.g., “80% compression with <0.5 dB average PSNR drop”) while remaining within length limits. revision: yes
-
Referee: Abstract (motivation and method): the node-based learnable pruning is said to remove low-contributing Gaussians while 'preserving visually critical regions' and dynamic objects, but no explicit mechanism (dynamic mask, motion-aware weighting, or post-pruning re-optimization) is described; contribution-based pruning can assign low scores to dynamic-object Gaussians due to limited views and occlusions, directly risking the temporal-consistency claim.
Authors: The node-based pruning mechanism, which operates on learned per-node importance scores aggregated across multiple views rather than per-Gaussian contribution alone, is detailed in Section 3.2; this grouping helps mitigate the low-view-count problem for dynamic objects. Experiments in Section 4.3 and 4.4 demonstrate that temporal consistency on moving vehicles and pedestrians is maintained (quantified via per-object PSNR and visual inspection across frames). Because the abstract is brief, we will add a short clarifying phrase on the node-level aggregation. We acknowledge the referee’s concern about potential bias against dynamic Gaussians and will ensure the revised abstract and introduction explicitly note this design choice. revision: partial
Circularity Check
No significant circularity; claims rest on external empirical validation
full rationale
The paper introduces a node-based learnable pruning strategy followed by background compression for 3D Gaussian Splatting in street scenes. The central result (up to 80% compression with minimal quality loss on Waymo and nuScenes) is presented as an experimental outcome measured against public datasets, not derived from any self-referential equation or fitted parameter renamed as a prediction. No self-citation chain, uniqueness theorem, or ansatz is invoked to force the compression ratio. The motivation (dynamic objects need high fidelity while backgrounds are redundant) is an observation, not a definitional loop. This matches the default case of a non-circular empirical methods paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. 2013. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432(2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[2]
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. 2020. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11621–11631
2020
-
[3]
Jiajun Cao, Qizhe Zhang, Peidong Jia, Xuhui Zhao, Bo Lan, Xiaoan Zhang, Xiaobao Wei, Sixiang Chen, Liyun Li, Xianming Liu, et al. 2026. Fastdrivevla: Efficient end-to-end driving via plug-and-play reconstruction-based token pruning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 2571–2579
2026
-
[4]
Jiajun Cao, Xiaoan Zhang, Xiaobao Wei, Liyuqiu Huang, Wang Zijian, Hanzhen Zhang, Zhengyu Jia, Wei Mao, Hao Wang, Xianming Liu, et al . 2026. Evo- DriveVLA: Evolving Autonomous Driving Vision-Language-Action Model via Collaborative Perception-Planning Distillation.arXiv preprint arXiv:2603.09465 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Peng Chen, Xiaobao Wei, Qingpo Wuwu, Xinyi Wang, Xingyu Xiao, and Ming Lu. 2025. Mixedgaussianavatar: Realistically and geometrically accurate head avatar via mixed 2d-3d gaussians. InProceedings of the 33rd ACM International Conference on Multimedia. 945–954
2025
- [6]
- [7]
- [8]
-
[9]
Howell, Ruohan Gao, Jiajun Wu, Zachary Manchester, and Mac Schwager
Simon Le Cleac’h, Hong Yu, Michelle Guo, Taylor A. Howell, Ruohan Gao, Jiajun Wu, Zachary Manchester, and Mac Schwager. 2022. Differentiable Physics Simu- lation of Dynamics-Augmented Neural Objects.IEEE Robotics and Automation Letters8 (2022), 2780–2787. https://api.semanticscholar.org/CorpusID:252967901
2022
-
[10]
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. 2017. CARLA: An open urban driving simulator. InConference on robot learning. PMLR, 1–16
2017
-
[11]
Zhiwen Fan, Kevin Wang, Kairun Wen, Zehao Zhu, Dejia Xu, Zhangyang Wang, et al. 2025. Lightgaussian: Unbounded 3d gaussian compression with 15x reduc- tion and 200+ fps.Advances in neural information processing systems37 (2025), 140138–140158
2025
-
[12]
Guangchi Fang and Bing Wang. 2024. Mini-splatting: Representing scenes with a constrained number of gaussians. InEuropean Conference on Computer Vision. Springer, 165–181
2024
-
[13]
Tobias Fischer, Lorenzo Porzi, Samuel Rota Bulo, Marc Pollefeys, and Peter Kontschieder. 2024. Multi-level neural scene graphs for dynamic urban en- vironments. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 21125–21135
2024
-
[14]
Sharath Girish, Kamal Gupta, and Abhinav Shrivastava. 2024. Eagles: Efficient accelerated 3d gaussians with lightweight encodings. InEuropean Conference on Computer Vision. Springer, 54–71
2024
-
[15]
Nan Huang, Xiaobao Wei, Wenzhao Zheng, Pengju An, Ming Lu, Wei Zhan, Masayoshi Tomizuka, Kurt Keutzer, and Shanghang Zhang. 2026. S3Gaussian: Self-Supervised Street Gaussians for Autonomous Driving. (2026)
2026
-
[16]
Sheng Yu Huang, Zan Gojcic, Zian Wang, Francis Williams, Yoni Kasten, Sanja Fidler, Konrad Schindler, and Or Litany. 2023. Neural LiDAR Fields for Novel View Synthesis.2023 IEEE/CVF International Conference on Computer Vision (ICCV) (2023), 18190–18200. https://api.semanticscholar.org/CorpusID:258437311
2023
- [17]
-
[18]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. 2023. Segment Anything.arXiv:2304.02643(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Joo Chan Lee, Daniel Rho, Xiangyu Sun, Jong Hwan Ko, and Eunbyung Park
-
[20]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Compact 3d gaussian representation for radiance field. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 21719–21728
- [21]
-
[22]
Ying Li, Xiaobao Wei, Xiaowei Chi, Yuming Li, Zhongyu Zhao, Hao Wang, Ningn- ing Ma, Ming Lu, and Sirui Han. 2026. Manipdreamer3d: Synthesizing plausible robotic manipulation video with occupancy-aware 3d trajectory. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 6644–6652
2026
-
[23]
Zhengqi Li, Simon Niklaus, Noah Snavely, and Oliver Wang. 2021. Neural Scene Flow Fields for Space-Time View Synthesis of Dynamic Scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2021
-
[24]
Jeffrey Yunfan Liu, Yun Chen, Ze Yang, Jingkang Wang, Sivabalan Manivasagam, and Raquel Urtasun. 2023. Real-Time Neural Rasterization for Large Scenes.2023 IEEE/CVF International Conference on Computer Vision (ICCV)(2023), 8382–8393. https://api.semanticscholar.org/CorpusID:264870747
2023
-
[25]
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. 2015. SMPL: a skinned multi-person linear model.ACM Trans. Graph.34, 6, Article 248 (Oct. 2015), 16 pages. doi:10.1145/2816795.2818013
-
[26]
Fan Lu, Yan Xu, Guang-Sheng Chen, Hongsheng Li, Kwan-Yee Lin, and Changjun Jiang. 2023. Urban Radiance Field Representation with Deformable Neural Mesh Primitives.2023 IEEE/CVF International Conference on Computer Vision (ICCV) (2023), 465–476. https://api.semanticscholar.org/CorpusID:259991347
2023
-
[27]
Mechanical Simulation. 2024. CarSim. Available online: https://www.carsim. com/products/carsim/. Accessed on 16 July 2024
2024
-
[28]
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. 2020. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. arXiv:2003.08934 [cs.CV] https://arxiv.org/abs/2003. 08934
-
[29]
Simon Niedermayr, Josef Stumpfegger, and Rüdiger Westermann. 2024. Com- pressed 3d gaussian splatting for accelerated novel view synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10349– 10358
2024
-
[30]
NVIDIA. 2023. NVIDIA DRIVE Sim. Available online: https://developer.nvidia. com/drive/drive-sim. Accessed on 18 April 2024
2023
-
[32]
Julian Ost, Fahim Mannan, Nils Thuerey, Julian Knodt, and Felix Heide. 2021. Neu- ral Scene Graphs for Dynamic Scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2856–2865
2021
-
[33]
Julian Ost, Fahim Mannan, Nils Thuerey, Julian Knodt, and Felix Heide. 2021. Neural scene graphs for dynamic scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2856–2865
2021
-
[34]
Keunhong Park, Utkarsh Sinha, Jonathan T Barron, Sofien Bouaziz, Dan B Gold- man, Steven M Seitz, and Ricardo Martin-Brualla. 2021. Nerfies: Deformable neural radiance fields. InProceedings of the IEEE/CVF International Conference on Computer Vision. 5865–5874
2021
-
[35]
Barron, Sofien Bouaziz, Dan B Goldman, Ricardo Martin-Brualla, and Steven M
Keunhong Park, Utkarsh Sinha, Peter Hedman, Jonathan T. Barron, Sofien Bouaziz, Dan B Goldman, Ricardo Martin-Brualla, and Steven M. Seitz. 2021. HyperNeRF: A Higher-Dimensional Representation for Topologically Varying Neural Radiance Fields.ACM Trans. Graph.40, 6, Article 238 (dec 2021)
2021
-
[36]
Chensheng Peng, Chengwei Zhang, Yixiao Wang, Chenfeng Xu, Yichen Xie, Wen- zhao Zheng, Kurt Keutzer, Masayoshi Tomizuka, and Wei Zhan. 2024. Desire-gs: 4d street gaussians for static-dynamic decomposition and surface reconstruction for urban driving scenes.arXiv preprint arXiv:2411.11921(2024). SparseStreet: Sparse Gaussian Splatting for Real-Time Street ...
-
[37]
Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer
-
[38]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
D-NeRF: Neural Radiance Fields for Dynamic Scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
-
[39]
Srinivasan, Jonathan T
Konstantinos Rematas, Andrew Liu, Pratul P. Srinivasan, Jonathan T. Barron, Andrea Tagliasacchi, Tom Funkhouser, and Vittorio Ferrari. 2022. Urban Radiance Fields.CVPR(2022)
2022
-
[40]
Shital Shah, Debadeepta Dey, Chris Lovett, and Ashish Kapoor. 2018. Airsim: High-fidelity visual and physical simulation for autonomous vehicles. InField and Service Robotics: Results of the 11th International Conference. Springer, 621–635
2018
-
[41]
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al
-
[42]
In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2446–2454
-
[43]
Yihong Sun and Bharath Hariharan. 2023. Dynamo-Depth: Fixing Unsupervised Depth Estimation for Dynamical Scenes. InThirty-seventh Conference on Neural Information Processing Systems
2023
-
[44]
Srinivasan, Jonathan T
Matthew Tancik, Vincent Casser, Xinchen Yan, Sabeek Pradhan, Ben Mildenhall, Pratul P. Srinivasan, Jonathan T. Barron, and Henrik Kretzschmar. 2022. Block- NeRF: Scalable Large Scene Neural View Synthesis.2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)(2022), 8238–8248. https: //api.semanticscholar.org/CorpusID:246706356
2022
- [45]
- [46]
-
[47]
Haithem Turki, Deva Ramanan, and Mahadev Satyanarayanan. 2021. Mega- NeRF: Scalable Construction of Large-Scale NeRFs for Virtual Fly- Throughs. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2021), 12912–12921. https://api.semanticscholar.org/CorpusID:245334780
2021
-
[48]
Haithem Turki, Jason Y Zhang, Francesco Ferroni, and Deva Ramanan. 2023. SUDS: Scalable Urban Dynamic Scenes. InComputer Vision and Pattern Recogni- tion (CVPR)
2023
- [49]
-
[50]
Hao Wang, Xiaobao Wei, Xiaoan Zhang, Jianing Li, Chengyu Bai, Ying Li, Ming Lu, Wenzhao Zheng, and Shanghang Zhang. 2025. Embodiedocc++: Boosting embodied 3d occupancy prediction with plane regularization and uncertainty sampler. InProceedings of the 33rd ACM International Conference on Multimedia. 925–934
2025
-
[51]
Liao Wang, Jiakai Zhang, Xinhang Liu, Fuqiang Zhao, Yanshun Zhang, Yingliang Zhang, Minye Wu, Jingyi Yu, and Lan Xu. 2022. Fourier PlenOctrees for Dynamic Radiance Field Rendering in Real-Time. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 13524–13534
2022
-
[52]
Yu Wang, Xiaobao Wei, Ming Lu, and Guoliang Kang. 2025. Plgs: Robust panoptic lifting with 3d gaussian splatting.IEEE Transactions on Image Processing(2025)
2025
-
[53]
Xiaobao Wei, Jiajun Cao, Yizhu Jin, Ming Lu, Guangyu Wang, and Shanghang Zhang. 2024. I-medsam: Implicit medical image segmentation with segment anything. InEuropean Conference on Computer Vision. Springer, 90–107
2024
-
[54]
Xiaobao Wei, Peng Chen, Guangyu Li, Ming Lu, Hui Chen, and Feng Tian. 2025. Gazegaussian: High-fidelity gaze redirection with 3d gaussian splatting. InPro- ceedings of the IEEE/CVF International Conference on Computer Vision. 13293– 13303
2025
-
[55]
Xiaobao Wei, Peng Chen, Ming Lu, Hui Chen, and Feng Tian. 2025. Graphavatar: Compact head avatars with gnn-generated 3d gaussians. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 8295–8303
2025
-
[56]
Xiaobao Wei, Qingpo Wuwu, Zhongyu Zhao, Zhuangzhe Wu, Nan Huang, Ming Lu, Ningning Ma, and Shanghang Zhang. 2025. Emd: Explicit motion modeling for high-quality street gaussian splatting. InProceedings of the IEEE/CVF international conference on computer vision. 28462–28472
2025
- [57]
-
[58]
Xiaobao Wei, Renrui Zhang, Jiarui Wu, Jiaming Liu, Ming Lu, Yandong Guo, and Shanghang Zhang. 2024. Nto3d: Neural target object 3d reconstruction with segment anything. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 20352–20362
2024
- [59]
-
[60]
Zirui Wu, Tianyu Liu, Liyi Luo, Zhide Zhong, Jianteng Chen, Hongmin Xiao, Chao Hou, Haozhe Lou, Yuantao Chen, Runyi Yang, Yuxin Huang, Xiaoyu Ye, Zike Yan, Yongliang Shi, Yiyi Liao, and Hao Zhao. 2023. MARS: An Instance-aware, Modular and Realistic Simulator for Autonomous Driving.CICAI(2023)
2023
-
[61]
Wenqi Xian, Jia-Bin Huang, Johannes Kopf, and Changil Kim. 2020. Space-time Neural Irradiance Fields for Free-Viewpoint Video.2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)(2020), 9416–9426. https: //api.semanticscholar.org/CorpusID:227162620
2020
-
[62]
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. 2021. SegFormer: Simple and efficient design for semantic segmentation with transformers.Advances in neural information processing systems34 (2021), 12077–12090
2021
-
[63]
Hongyi Xu, Thiemo Alldieck, and Cristian Sminchisescu. 2021. H-NeRF: Neural Radiance Fields for Rendering and Temporal Reconstruction of Humans in Mo- tion. InNeural Information Processing Systems. https://api.semanticscholar.org/ CorpusID:239885257
2021
-
[64]
Yunzhi Yan, Haotong Lin, Chenxu Zhou, Weijie Wang, Haiyang Sun, Kun Zhan, Xianpeng Lang, Xiaowei Zhou, and Sida Peng. 2024. Street Gaussians: Modeling Dynamic Urban Scenes with Gaussian Splatting. InECCV
2024
- [65]
-
[66]
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Heng- shuang Zhao. 2024. Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data. InCVPR
2024
-
[67]
Ziyi Yang, Xinyu Gao, Wen Zhou, Shaohui Jiao, Yuqing Zhang, and Xiaogang Jin
-
[68]
arXiv preprint arXiv:2309.13101 (2023)
Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction. arXiv:2309.13101 [cs.CV] https://arxiv.org/abs/2309.13101
-
[69]
Zhifan Ye, Chenxi Wan, Chaojian Li, Jihoon Hong, Sixu Li, Leshu Li, Yongan Zhang, and Yingyan Celine Lin. 2024. 3D Gaussian Rendering Can Be Sparser: Ef- ficient Rendering via Learned Fragment Pruning.Advances in Neural Information Processing Systems37 (2024), 5850–5869
2024
- [70]
-
[71]
Hongyu Zhou, Jiahao Shao, Lu Xu, Dongfeng Bai, Weichao Qiu, Bingbing Liu, Yue Wang, Andreas Geiger, and Yiyi Liao. 2024. Hugs: Holistic urban 3d scene understanding via gaussian splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 21336–21345
2024
-
[72]
Hongyu Zhou, Jiahao Shao, Lu Xu, Dongfeng Bai, Weichao Qiu, Bingbing Liu, Yue Wang, Andreas Geiger, and Yiyi Liao. 2024. HUGS: Holistic Urban 3D Scene Understanding via Gaussian Splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 21336–21345
2024
-
[73]
Xiaoyu Zhou, Zhiwei Lin, Xiaojun Shan, Yongtao Wang, Deqing Sun, and Ming- Hsuan Yang. 2024. Drivinggaussian: Composite gaussian splatting for surround- ing dynamic autonomous driving scenes. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition. 21634–21643
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.