Value-Aware Stochastic KV Cache Eviction for Reasoning Models
Pith reviewed 2026-06-28 11:11 UTC · model grok-4.3
The pith
Protecting large-magnitude value states and adding stochasticity during eviction lets KV cache methods exceed selection-based accuracy at 4x compression on reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
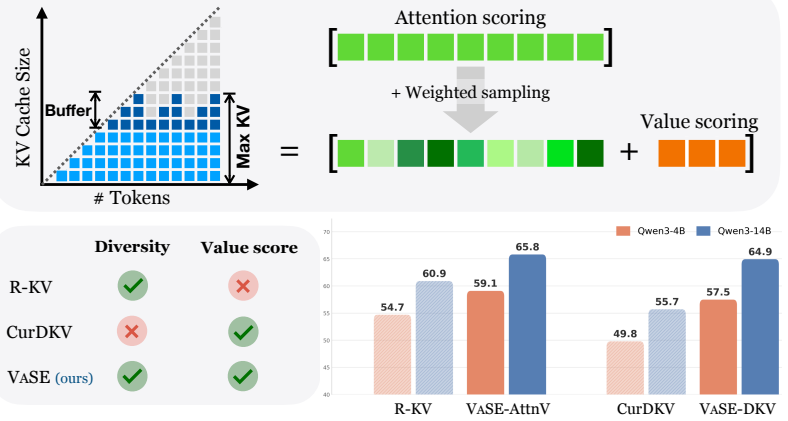
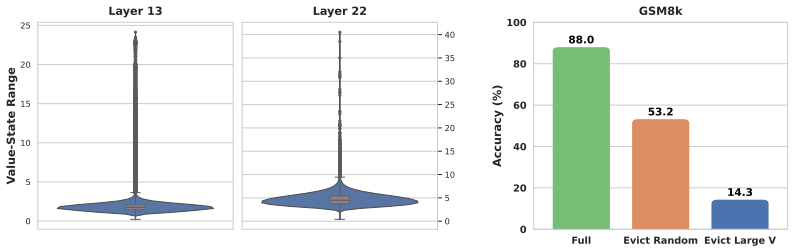
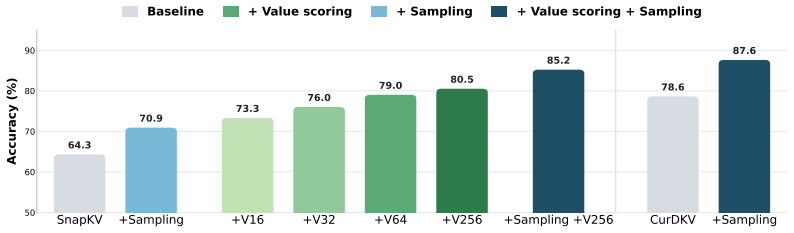
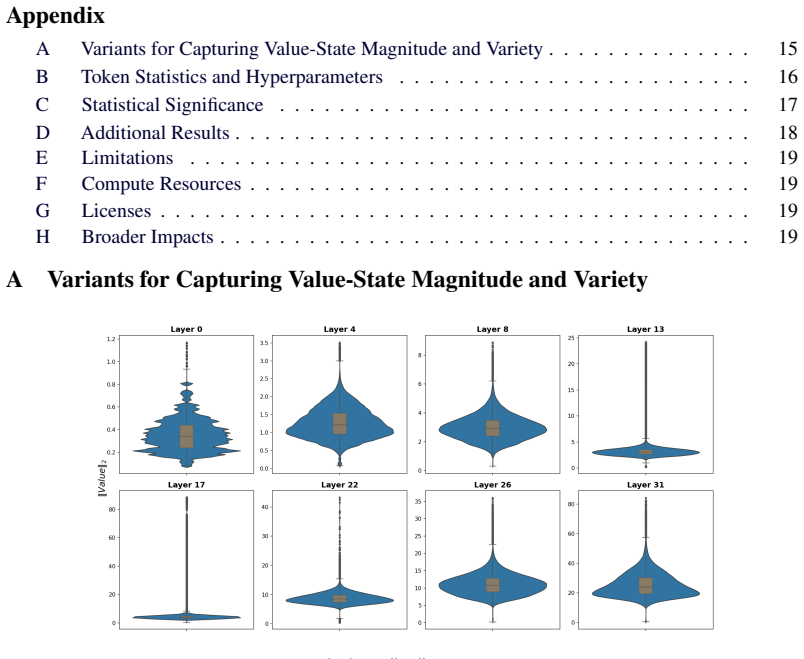
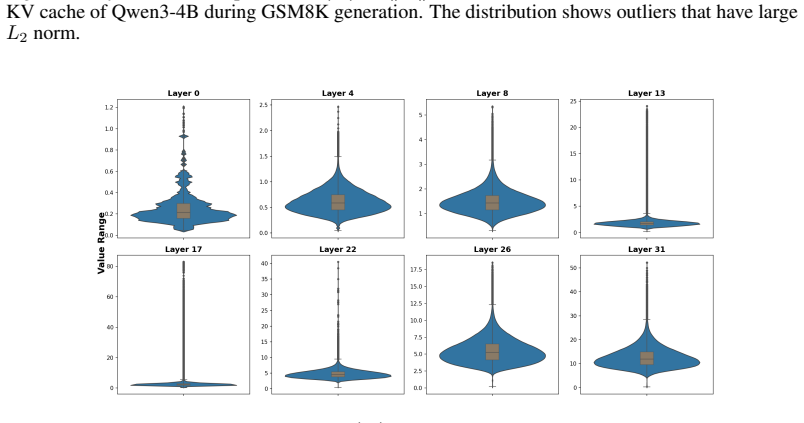
A small fraction of value states carry abnormally large magnitudes whose removal triggers repetitive reasoning loops and catastrophic accuracy collapse. Introducing stochasticity in the eviction process improves accuracy by increasing the diversity of retained cache entries. Value-aware Stochastic KV Cache Eviction (VaSE) therefore protects these large-magnitude values while making eviction decisions stochastically, yielding a training-free procedure that supports FlashAttention2 and produces static memory footprints.
What carries the argument
Value-aware Stochastic KV Cache Eviction (VaSE), which identifies and protects abnormally large-magnitude value states while randomizing eviction selections to preserve diversity.
If this is right
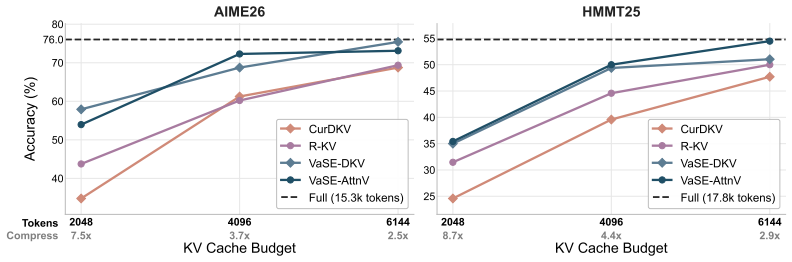
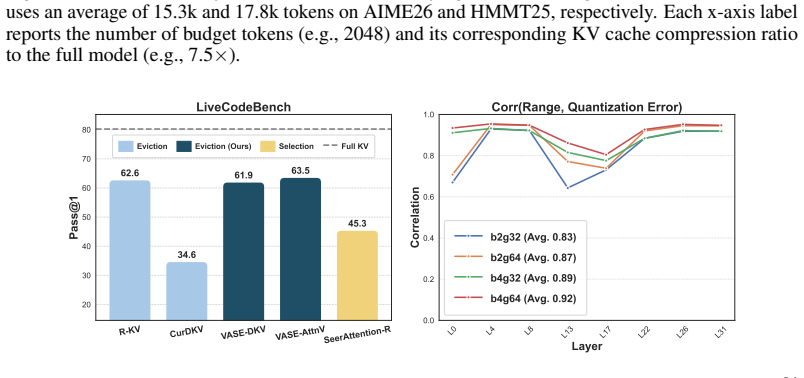
- Qwen3 models achieve higher average accuracy with 4x KV cache compression than state-of-the-art selection methods at identical sparsity.
- VaSE exceeds the strongest prior eviction baseline by more than 4% on the six evaluated tasks.
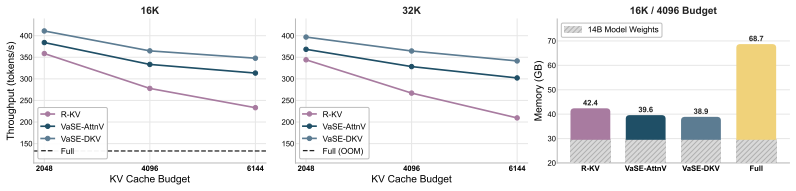
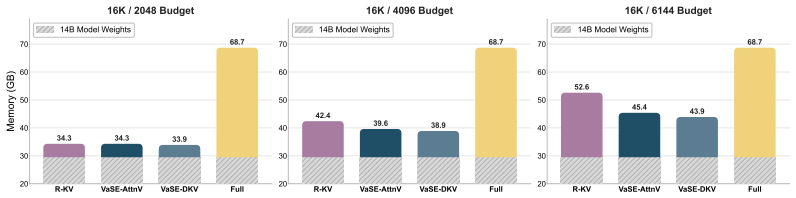
- The method produces a fixed memory footprint while remaining compatible with FlashAttention2.
- Eviction no longer forces models into repetitive reasoning loops when large-magnitude value states are retained.
Where Pith is reading between the lines
- The same magnitude-based protection rule may reduce accuracy loss in long-context tasks outside explicit reasoning.
- Stochastic eviction could be layered with other compression strategies to reach higher compression ratios.
- Replicating the large-magnitude value observation on additional model families would test whether the pattern is architecture-specific.
Load-bearing premise
That safeguarding the abnormally large-magnitude value states and adding stochasticity are the primary and sufficient changes needed to avoid accuracy degradation and repetitive loops.
What would settle it
Measure accuracy and loop frequency on the same reasoning tasks after deliberately evicting the large-magnitude value states while retaining stochastic selection; a sharp drop relative to VaSE would falsify the claim.
Figures


read the original abstract
Reasoning models improve accuracy through extended chains of thought, but their long outputs create a memory and compute bottleneck. KV cache eviction methods reduce this cost by evicting unimportant key-value pairs from the cache, yet they often yield worse accuracy than selection-based sparse attention alternatives, which keep the full KV cache. We identify key factors crucial to KV cache eviction accuracy. First, a small fraction of value states have abnormally large magnitudes, and evicting them causes catastrophic failure where models enter repetitive reasoning loops. Second, introducing stochasticity during eviction improves accuracy by increasing cache diversity. Based on these findings, we propose Value-aware Stochastic KV Cache Eviction (VaSE), a training-free recipe that protects large-magnitude value states and promotes diverse eviction decisions. Across six reasoning tasks, Qwen3 models using VaSE with 4x KV cache compression yield higher average accuracies than SOTA selection method at the same sparsity, while outperforming the strongest eviction method by more than 4%. Overall, VaSE bridges the gap between efficiency and accuracy, supporting FlashAttention2 and enabling a static memory footprint for reasoning models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Value-Aware Stochastic KV Cache Eviction (VaSE), a training-free method for reasoning models that protects value states with abnormally large magnitudes (to avoid repetitive loops) and introduces stochasticity during eviction (to increase cache diversity). It reports that Qwen3 models using VaSE at 4x KV cache compression achieve higher average accuracies across six reasoning tasks than both SOTA selection-based sparse attention and the strongest prior eviction method (by >4%).
Significance. If the empirical results hold under rigorous controls, VaSE would narrow the accuracy gap between eviction and selection methods for long CoT reasoning, enabling static memory footprints and FlashAttention2 compatibility without training. The identification of magnitude-based failure modes and the benefit of stochasticity constitute a concrete, actionable recipe with potential deployment impact.
major comments (2)
- [Abstract] The central empirical claim (higher accuracy than SOTA at 4x compression) is load-bearing yet the provided abstract supplies no baseline definitions, task list, statistical tests, or ablation results; without these in the full manuscript the claim cannot be evaluated.
- [Method] §4 (or equivalent method section): the assumption that protecting large-magnitude values and adding stochasticity are both necessary and sufficient is presented as directly following from observed failure modes, but no controlled ablation isolating each factor versus their combination is referenced, weakening the causal attribution.
minor comments (2)
- [Method] Notation for 'value state magnitude' and the precise eviction probability schedule should be defined with an equation or pseudocode for reproducibility.
- [Experiments] Figure or table captions should explicitly state the sparsity level, model sizes, and exact baselines used for the 'SOTA selection method' comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying details present in the manuscript and committing to revisions where the concerns identify genuine gaps in evidence.
read point-by-point responses
-
Referee: [Abstract] The central empirical claim (higher accuracy than SOTA at 4x compression) is load-bearing yet the provided abstract supplies no baseline definitions, task list, statistical tests, or ablation results; without these in the full manuscript the claim cannot be evaluated.
Authors: The full manuscript supplies the requested elements: the six reasoning tasks are enumerated in Section 5 (Experiments), baselines are defined in Sections 3 (Related Work) and 5 with explicit comparisons to the SOTA selection-based sparse attention method and the strongest prior eviction method, results report average accuracies across tasks with the stated >4% improvement at 4x compression, and Section 6 contains ablation studies. Statistical tests are not currently reported; we can add them if the editor requests. The abstract follows standard length constraints but already references the task count, SOTA selection method, and eviction baseline. We will revise the abstract to more explicitly name the tasks and note the performance delta if space permits. revision: partial
-
Referee: [Method] §4 (or equivalent method section): the assumption that protecting large-magnitude values and adding stochasticity are both necessary and sufficient is presented as directly following from observed failure modes, but no controlled ablation isolating each factor versus their combination is referenced, weakening the causal attribution.
Authors: We agree that the current presentation relies on observational motivation from failure modes without a controlled isolation of the two factors. The manuscript describes the large-magnitude value protection (to prevent repetitive loops) and stochastic eviction (to increase diversity) as jointly forming VaSE, with overall empirical gains shown. To strengthen causal attribution, we will add a controlled ablation study in the revised manuscript comparing (i) magnitude protection alone, (ii) stochasticity alone, (iii) their combination, and (iv) the full VaSE recipe against the baselines. revision: yes
Circularity Check
No significant circularity; derivation is observational and empirical
full rationale
The paper's chain consists of empirical observations (large-magnitude value states cause repetitive loops; stochastic eviction increases diversity) followed by a training-free method (VaSE) that directly implements protection of those states plus stochastic decisions, with results reported as measured accuracies on six tasks. No equations or claims reduce a 'prediction' or 'first-principles result' to the inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems, no parameters are fitted then renamed as predictions, and no ansatz is smuggled via prior work. The central claim remains an empirical comparison at fixed sparsity, independent of the method's own definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
H2o: Heavy-hitter oracle for efficient generative inference of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
The Twelfth International Conference on Learning Representations , year=
Efficient Streaming Language Models with Attention Sinks , author=. The Twelfth International Conference on Learning Representations , year=
-
[3]
Yuhong Li and Yingbing Huang and Bowen Yang and Bharat Venkitesh and Acyr Locatelli and Hanchen Ye and Tianle Cai and Patrick Lewis and Deming Chen , booktitle=. Snap
-
[4]
Abdi and Dongsheng Li and Chin-Yew Lin and Yuqing Yang and Lili Qiu , booktitle=
Huiqiang Jiang and YUCHENG LI and Chengruidong Zhang and Qianhui Wu and Xufang Luo and Surin Ahn and Zhenhua Han and Amir H. Abdi and Dongsheng Li and Chin-Yew Lin and Yuqing Yang and Lili Qiu , booktitle=
-
[5]
Not All Heads Matter: A Head-Level
Yu Fu and Zefan Cai and Abedelkadir Asi and Wayne Xiong and Yue Dong and Wen Xiao , booktitle=. Not All Heads Matter: A Head-Level
-
[6]
Transformers are Multi-State RNN s
Oren, Matanel and Hassid, Michael and Yarden, Nir and Adi, Yossi and Schwartz, Roy. Transformers are Multi-State RNN s. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.1043
-
[7]
The Fourteenth International Conference on Learning Representations , year=
Sparse Attention Adaptation for Long Reasoning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[8]
2024 , editor =
Ribar, Luka and Chelombiev, Ivan and Hudlass-Galley, Luke and Blake, Charlie and Luschi, Carlo and Orr, Douglas , booktitle =. 2024 , editor =
2024
-
[9]
Proceedings of the 41st International Conference on Machine Learning , year =
QUEST: Query-Aware Sparsity for Efficient Long-Context LLM Inference , author=. Proceedings of the 41st International Conference on Machine Learning , year =
-
[10]
TidalDecode: Fast and Accurate
Lijie Yang and Zhihao Zhang and Zhuofu Chen and Zikun Li and Zhihao Jia , booktitle=. TidalDecode: Fast and Accurate. 2025 , url=
2025
-
[11]
Zefan Cai and Wen Xiao and Hanshi Sun and Cheng Luo and Yikai Zhang and Ke Wan and Yucheng Li and Yeyang Zhou and Li-Wen Chang and Jiuxiang Gu and Zhen Dong and Anima Anandkumar and Abedelkadir Asi and Junjie Hu , booktitle=. R-
-
[12]
Reasoning Path Compression: Compressing Generation Trajectories for Efficient
Jiwon Song and Dongwon Jo and Yulhwa Kim and Jae-Joon Kim , booktitle=. Reasoning Path Compression: Compressing Generation Trajectories for Efficient
-
[13]
Xingyu Chen and Jiahao Xu and Tian Liang and Zhiwei He and Jianhui Pang and Dian Yu and Linfeng Song and Qiuzhi Liu and Mengfei Zhou and Zhuosheng Zhang and Rui Wang and Zhaopeng Tu and Haitao Mi and Dong Yu , booktitle=. Do. 2025 , url=
2025
-
[14]
2024 , howpublished =
OpenAI , title =. 2024 , howpublished =
2024
-
[15]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[16]
2024 , month = nov, howpublished =
Qwen , title =. 2024 , month = nov, howpublished =
2024
-
[17]
Charlie Victor Snell and Jaehoon Lee and Kelvin Xu and Aviral Kumar , booktitle=. Scaling. 2025 , url=
2025
-
[18]
Value-Guided
Ayan Sengupta and Siddhant Chaudhary and Tanmoy Chakraborty , booktitle=. Value-Guided
-
[19]
arXiv preprint arXiv:2004.05150 , year=
Longformer: The long-document transformer , author=. arXiv preprint arXiv:2004.05150 , year=
Pith/arXiv arXiv 2004
-
[20]
Advances in neural information processing systems , volume=
Big bird: Transformers for longer sequences , author=. Advances in neural information processing systems , volume=
-
[21]
International Conference on Learning Representations , year=
Reformer: The Efficient Transformer , author=. International Conference on Learning Representations , year=
-
[22]
Model Tells You What to Discard: Adaptive
Suyu Ge and Yunan Zhang and Liyuan Liu and Minjia Zhang and Jiawei Han and Jianfeng Gao , booktitle=. Model Tells You What to Discard: Adaptive. 2024 , url=
2024
-
[23]
arXiv preprint arXiv:1912.11637 , year=
Explicit sparse transformer: Concentrated attention through explicit selection , author=. arXiv preprint arXiv:1912.11637 , year=
arXiv 1912
-
[24]
A Simple and Effective L\_2 Norm-Based Strategy for KV Cache Compression
Devoto, Alessio and Zhao, Yu and Scardapane, Simone and Minervini, Pasquale. A Simple and Effective L\_2 Norm-Based Strategy for KV Cache Compression. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.1027
-
[25]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[26]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[27]
Mahoney and Sophia Shao and Kurt Keutzer and Amir Gholami , booktitle=
Coleman Richard Charles Hooper and Sehoon Kim and Hiva Mohammadzadeh and Michael W. Mahoney and Sophia Shao and Kurt Keutzer and Amir Gholami , booktitle=. 2024 , url=
2024
-
[28]
International Conference on Machine Learning , pages=
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[29]
arXiv preprint arXiv:2510.10964 , year=
Not All Bits Are Equal: Scale-Dependent Memory Optimization Strategies for Reasoning Models , author=. arXiv preprint arXiv:2510.10964 , year=
-
[30]
The Fourteenth International Conference on Learning Representations , year=
TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate , author=. The Fourteenth International Conference on Learning Representations , year=
-
[31]
Scissorhands: Exploiting the Persistence of Importance Hypothesis for
Zichang Liu and Aditya Desai and Fangshuo Liao and Weitao Wang and Victor Xie and Zhaozhuo Xu and Anastasios Kyrillidis and Anshumali Shrivastava , booktitle=. Scissorhands: Exploiting the Persistence of Importance Hypothesis for. 2023 , url=
2023
-
[32]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Eigen attention: Attention in low-rank space for kv cache compression , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[33]
Abdelfattah and Kai-Chiang Wu , booktitle=
Chi-Chih Chang and Wei-Cheng Lin and Chien-Yu Lin and Chong-Yan Chen and Yu-Fang Hu and Pei-Shuo Wang and Ning-Chi Huang and Luis Ceze and Mohamed S. Abdelfattah and Kai-Chiang Wu , booktitle=. Palu:. 2025 , url=
2025
-
[34]
arXiv preprint arXiv:2405.04434 , year=
Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model , author=. arXiv preprint arXiv:2405.04434 , year=
-
[35]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Loki: Low-rank Keys for Efficient Sparse Attention , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[36]
arXiv preprint arXiv:2510.00636 , year=
Expected attention: Kv cache compression by estimating attention from future queries distribution , author=. arXiv preprint arXiv:2510.00636 , year=
-
[37]
Forty-second International Conference on Machine Learning , year=
HashAttention: Semantic Sparsity for Faster Inference , author=. Forty-second International Conference on Machine Learning , year=
-
[38]
The Fourteenth International Conference on Learning Representations , year=
vAttention: Verified Sparse Attention via Sampling , author=. The Fourteenth International Conference on Learning Representations , year=
-
[39]
arXiv preprint arXiv:2507.08143 , year=
Compactor: Calibrated Query-Agnostic KV Cache Compression with Approximate Leverage Scores , author=. arXiv preprint arXiv:2507.08143 , year=
-
[40]
arXiv preprint arXiv:2406.02069 , year=
Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling , author=. arXiv preprint arXiv:2406.02069 , year=
-
[41]
DuoAttention: Efficient Long-Context
Guangxuan Xiao and Jiaming Tang and Jingwei Zuo and junxian guo and Shang Yang and Haotian Tang and Yao Fu and Song Han , booktitle=. DuoAttention: Efficient Long-Context. 2025 , url=
2025
-
[42]
arXiv preprint arXiv:2509.05165 , year=
KVCompose: Efficient Structured KV Cache Compression with Composite Tokens , author=. arXiv preprint arXiv:2509.05165 , year=
-
[43]
Guo, Zhiyu and Kamigaito, Hidetaka and Watanabe, Taro. Attention Score is not All You Need for Token Importance Indicator in KV Cache Reduction: Value Also Matters. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.1178
-
[44]
Jordan and Song Mei , booktitle=
Tianyu Guo and Druv Pai and Yu Bai and Jiantao Jiao and Michael I. Jordan and Song Mei , booktitle=. Active-Dormant Attention Heads: Mechanistically Demystifying Extreme-Token Phenomena in. 2025 , url=
2025
-
[45]
Measuring Mathematical Problem Solving With the
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , booktitle=. Measuring Mathematical Problem Solving With the. 2021 , url=
2021
-
[46]
The Thirteenth International Conference on Learning Representations , year=
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , author=. The Thirteenth International Conference on Learning Representations , year=
-
[47]
Bowman , booktitle=
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , booktitle=. 2024 , url=
2024
-
[48]
MathArena: Evaluating
Mislav Balunovic and Jasper Dekoninck and Ivo Petrov and Nikola Jovanovi. MathArena: Evaluating. The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[49]
arXiv preprint arXiv:2110.14168 , year=
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[50]
2022 , url=
Tim Dettmers and Mike Lewis and Younes Belkada and Luke Zettlemoyer , booktitle=. 2022 , url=
2022
-
[51]
2023 , url=
Elias Frantar and Saleh Ashkboos and Torsten Hoefler and Dan Alistarh , booktitle=. 2023 , url=
2023
-
[52]
2025 , url=
Zunhai Su and Kehong Yuan , booktitle=. 2025 , url=
2025
-
[53]
Half-Quadratic Quantization of Large Machine Learning Models , url =
Hicham Badri and Appu Shaji , month =. Half-Quadratic Quantization of Large Machine Learning Models , url =
-
[54]
arXiv preprint arXiv:2601.18383 , year=
Dynamic Thinking-Token Selection for Efficient Reasoning in Large Reasoning Models , author=. arXiv preprint arXiv:2601.18383 , year=
-
[55]
Dao, Tri , booktitle=. Flash
-
[56]
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph and Zhang, Hao and Stoica, Ion , title =. 2023 , isbn =. doi:10.1145/3600006.3613165 , booktitle =
-
[57]
First Conference on Language Modeling , year=
Massive Activations in Large Language Models , author=. First Conference on Language Modeling , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.