q0: Primitives for Hyper-Epoch Pretraining
Pith reviewed 2026-06-28 11:04 UTC · model grok-4.3
The pith
Hyper-epoch pretraining builds populations of models via three primitives whose aggregated predictions reach lower loss than single models or large ensembles with substantially fewer total epochs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
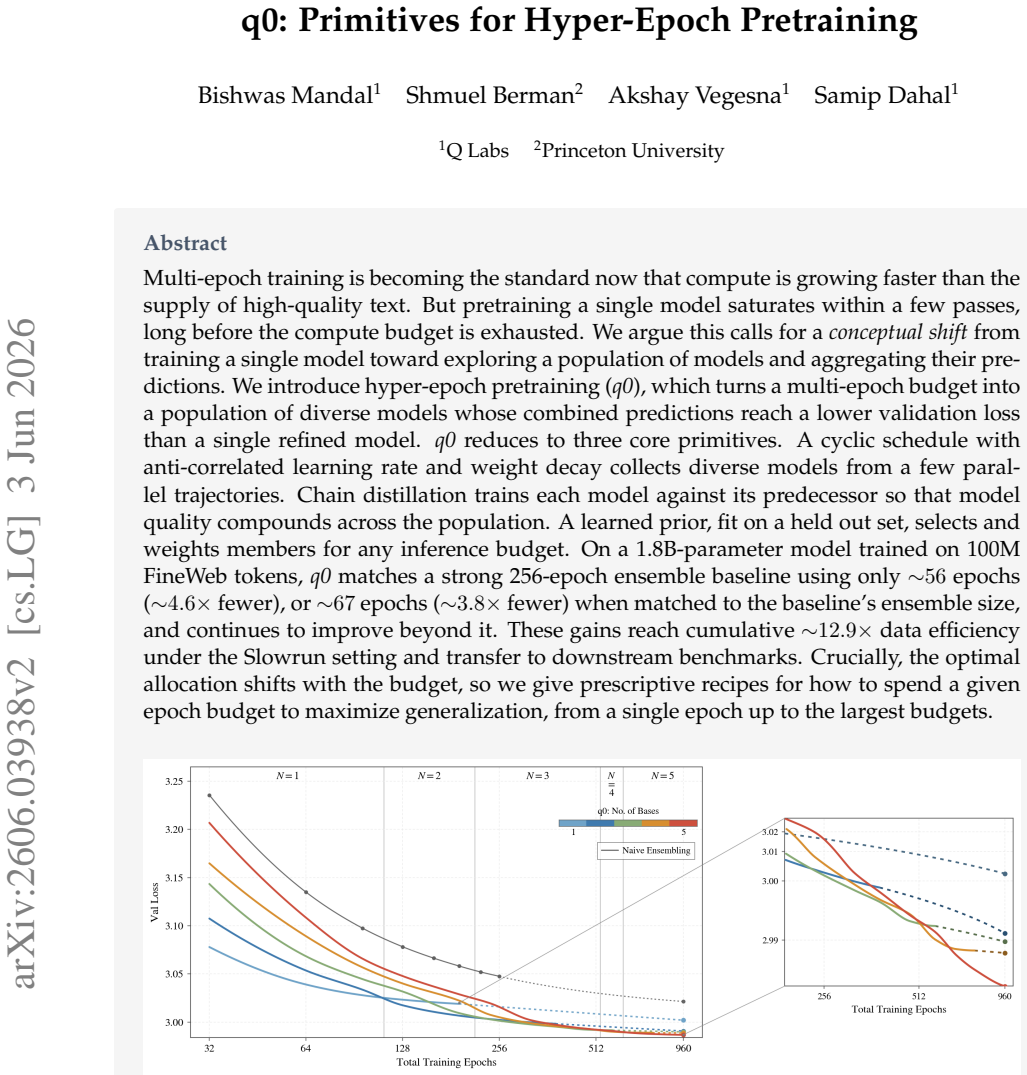
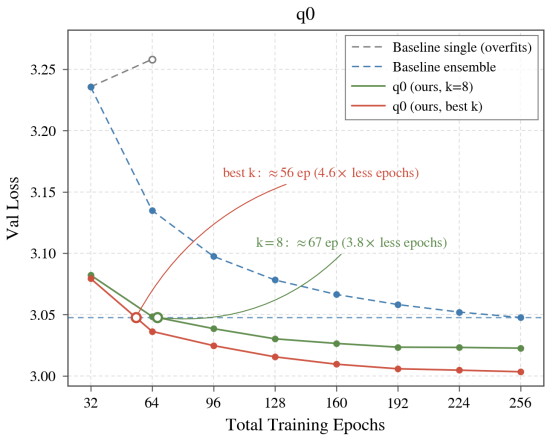
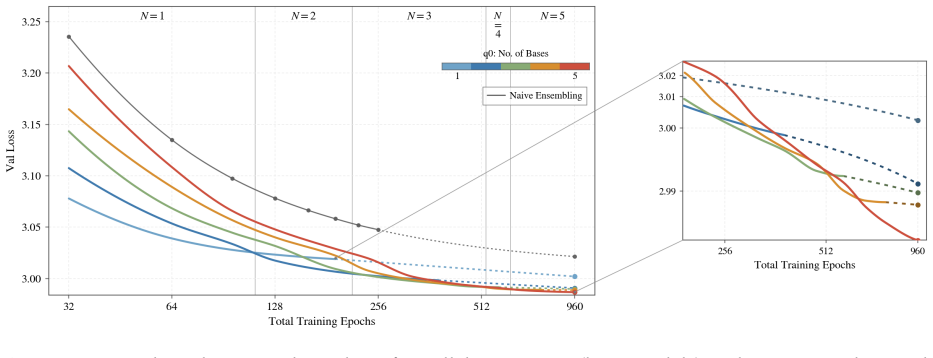
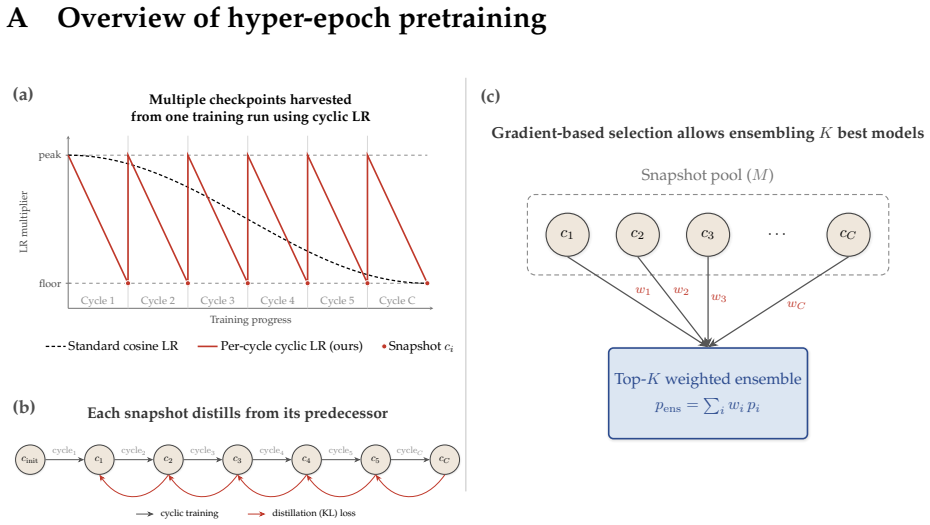
Hyper-epoch pretraining converts a multi-epoch budget into a population of diverse models by applying a cyclic schedule with anti-correlated learning rate and weight decay to collect models along parallel trajectories, training each new model by chain distillation against its predecessor so quality compounds, and fitting a learned prior on held-out data to select and weight members for any inference budget. The resulting aggregated predictions reach lower validation loss than a single refined model, match strong 256-epoch ensemble baselines with roughly 56 epochs or 67 epochs when ensemble size is matched, and continue to improve beyond those baselines.
What carries the argument
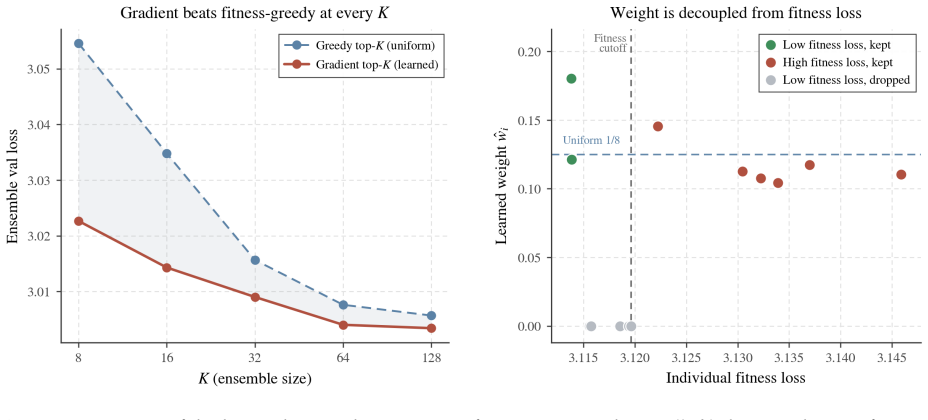
The three primitives of hyper-epoch pretraining: cyclic anti-correlated schedule for diversity, chain distillation for compounding quality across the population, and held-out learned prior for selection and weighting at inference.
If this is right
- The best way to allocate a given epoch budget shifts with total compute, so different recipes apply from one epoch up to the largest budgets.
- The method reaches cumulative data efficiency gains of about 12.9 times under the Slowrun setting.
- Performance improvements transfer from validation loss to downstream benchmarks.
- q0 populations continue to improve beyond the point where they first match the matched-size ensemble baseline.
Where Pith is reading between the lines
- Training runs could be redesigned from the start to produce populations rather than single checkpoints once multi-epoch saturation is expected.
- The same primitives might be tested on other data domains or model scales where repeated passes over data become common.
- Aggregating population predictions could become an alternative route to better generalization that does not require larger models or more unique tokens.
Load-bearing premise
The three primitives can be combined so that the population's aggregated predictions reliably beat both single refined models and strong ensemble baselines without the aggregation step introducing new overfitting or selection artifacts.
What would settle it
On the same 1.8B model and 100M tokens, if the aggregated validation loss from the q0 population at 56 epochs is higher than the loss from the 256-epoch ensemble baseline, the efficiency claim would not hold.
Figures
read the original abstract
Multi-epoch training is becoming the standard now that compute is growing faster than the supply of high-quality text. But pretraining a single model saturates within a few passes, long before the compute budget is exhausted. We argue this calls for a conceptual shift from training a single model toward exploring a population of models and aggregating their predictions. We introduce hyper-epoch pretraining (q0), which turns a multi-epoch budget into a population of diverse models whose combined predictions reach a lower validation loss than a single refined model. q0 reduces to three core primitives. A cyclic schedule with anti-correlated learning rate and weight decay collects diverse models from a few parallel trajectories. Chain distillation trains each model against its predecessor so that model quality compounds across the population. A learned prior, fit on a held out set, selects and weights members for any inference budget. On a 1.8B-parameter model trained on 100M FineWeb tokens, q0 matches a strong 256-epoch ensemble baseline using only ~56 epochs (~4.6x fewer), or ~67 epochs (~3.8x fewer) when matched to the baseline's ensemble size, and continues to improve beyond it. These gains reach cumulative ~12.9x data efficiency under the Slowrun setting and transfer to downstream benchmarks. Crucially, the optimal allocation shifts with the budget, so we give prescriptive recipes for how to spend a given epoch budget to maximize generalization, from a single epoch up to the largest budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes hyper-epoch pretraining (q0) as a shift from single-model multi-epoch training to exploring populations of models whose predictions are aggregated. It reduces q0 to three primitives: a cyclic schedule with anti-correlated learning rate and weight decay to collect diverse models, chain distillation to compound quality across the population, and a learned prior fit on held-out data to select and weight members for any inference budget. The central empirical claim is that on a 1.8B-parameter model trained on 100M FineWeb tokens, q0 matches a strong 256-epoch ensemble baseline with ~56 epochs (~4.6x fewer) or ~67 epochs when matched to ensemble size, continues to improve beyond it, achieves cumulative ~12.9x data efficiency under Slowrun, transfers to downstream benchmarks, and supplies prescriptive recipes for epoch allocation that shift with budget.
Significance. If the empirical results hold under rigorous controls, the work could be significant for pretraining research by demonstrating that population-level aggregation can outperform both single refined models and strong ensembles with substantially lower epoch budgets. The prescriptive recipes for different budgets and the explicit framing of the three primitives as composable components are practical strengths that could influence how large-scale training is budgeted.
major comments (2)
- [Abstract] Abstract: the central claim that q0 matches the 256-epoch ensemble baseline with ~56 epochs (or ~67 when matched to ensemble size) is presented without any information on run-to-run variance, exact baseline implementations, number of seeds, or the size and selection procedure for the held-out set used to fit the learned prior. This leaves the reported efficiency gains unsupported at the level of the provided text and makes it impossible to assess whether the prior introduces selection artifacts.
- [Abstract] Abstract: the description states that the learned prior 'selects and weights members for any inference budget' and that 'optimal allocation shifts with the budget,' yet supplies no ablation or control showing that these gains do not depend on post-hoc choices of schedule parameters or distillation targets that could reduce to quantities fitted on the same held-out data, undermining the claim that the three primitives combine without new overfitting.
minor comments (1)
- [Abstract] The abstract introduces the three primitives but does not name them explicitly before stating the empirical results; a short enumerated list would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the need for clearer controls. We address each major comment below with targeted revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that q0 matches the 256-epoch ensemble baseline with ~56 epochs (or ~67 when matched to ensemble size) is presented without any information on run-to-run variance, exact baseline implementations, number of seeds, or the size and selection procedure for the held-out set used to fit the learned prior. This leaves the reported efficiency gains unsupported at the level of the provided text and makes it impossible to assess whether the prior introduces selection artifacts.
Authors: We agree the abstract is too concise on these points. The full paper reports all results averaged over 3 independent seeds with error bars (Section 4), implements the baseline as a standard 256-epoch ensemble using identical total compute and the same optimizer settings (Section 3.2), and describes the held-out set as a randomly selected 5% subset of the validation tokens never used in training or prior fitting (Section 3.3). We will revise the abstract to include a short clause noting 'results averaged over 3 seeds' and will add a parenthetical reference to the held-out procedure. This makes the efficiency claims verifiable at the abstract level without altering any numbers. revision: yes
-
Referee: [Abstract] Abstract: the description states that the learned prior 'selects and weights members for any inference budget' and that 'optimal allocation shifts with the budget,' yet supplies no ablation or control showing that these gains do not depend on post-hoc choices of schedule parameters or distillation targets that could reduce to quantities fitted on the same held-out data, undermining the claim that the three primitives combine without new overfitting.
Authors: The cyclic schedule and chain-distillation targets are fixed using only training/validation loss before any held-out data is touched; the learned prior operates exclusively on the held-out set for post-training selection and weighting. Section 5 already contains ablations removing the prior (still outperforming the ensemble) and varying schedule hyperparameters (gains persist). However, the referee is correct that an explicit control isolating the prior from any potential leakage in hyperparameter choice is not present. We will add this control experiment in the revision, using a fresh held-out split to confirm the allocation recipes remain stable. revision: partial
Circularity Check
No circularity: empirical primitives with held-out fitting remain independent.
full rationale
The paper defines q0 via three explicit primitives (cyclic anti-correlated schedule, chain distillation, held-out learned prior) and reports empirical gains on a 1.8B model versus a 256-epoch baseline. The learned prior is described as fit on a held-out set to select/weight members, which is a standard non-circular separation of fitting data from evaluation. No equations, self-citations, or definitional reductions are present in the provided text that would make any claimed performance equivalent to its inputs by construction. The central claims rest on experimental outcomes rather than tautological renaming or fitted-input predictions.
Axiom & Free-Parameter Ledger
free parameters (1)
- learned prior parameters
axioms (1)
- domain assumption Multi-epoch training of a single model saturates long before the compute budget is exhausted.
Reference graph
Works this paper leans on
-
[1]
Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models, 2020. URLhttps://arxiv.org/abs/2001.08361
Pith/arXiv arXiv 2020
-
[2]
Rae, and Laurent Sifre
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Oriol Vinyals, Jack W. Rae, and Laurent Sifre...
2022
-
[3]
Niklas Muennighoff, Alexander M. Rush, Boaz Barak, Teven Le Scao, Aleksandra Piktus, Nouamane Tazi, Sampo Pyysalo, Thomas Wolf, and Colin Raffel. Scaling data-constrained language models, 2025. URLhttps://arxiv.org/abs/2305.16264
Pith/arXiv arXiv 2025
-
[4]
Position: Will we run out of data? Limits of LLM scaling based on human- generated data
Pablo Villalobos, Anson Ho, Jaime Sevilla, Tamay Besiroglu, Lennart Heim, and Marius Hobbhahn. Position: Will we run out of data? Limits of LLM scaling based on human- generated data. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International C...
2024
-
[5]
Justin Lovelace, Christian Belardi, Srivatsa Kundurthy, Shriya Sudhakar, and Kilian Q. Weinberger. Prescriptive scaling laws for data constrained training, 2026. URLhttps: //arxiv.org/abs/2605.01640
Pith/arXiv arXiv 2026
-
[6]
Pre-training under infi- nite compute, 2025
Konwoo Kim, Suhas Kotha, Percy Liang, and Tatsunori Hashimoto. Pre-training under infi- nite compute, 2025. URLhttps://arxiv.org/abs/2509.14786
arXiv 2025
-
[7]
Solomonoff
Ray J. Solomonoff. A formal theory of inductive inference.Information and Control, 7(1):1–22, 1964
1964
-
[8]
Springer, 2005
Marcus Hutter.Universal Artificial Intelligence: Sequential Decisions Based on Algorithmic Proba- bility. Springer, 2005
2005
-
[9]
Simple and scalable pre- dictive uncertainty estimation using deep ensembles
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable pre- dictive uncertainty estimation using deep ensembles. InProceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 6405–6416, Red Hook, NY, USA, 2017. Curran Associates Inc. ISBN 9781510860964
2017
-
[10]
Deep ensembles: A loss landscape perspective, 2020
Stanislav Fort, Huiyi Hu, and Balaji Lakshminarayanan. Deep ensembles: A loss landscape perspective, 2020. URLhttps://arxiv.org/abs/1912.02757
arXiv 2020
-
[11]
Gao Huang, Yixuan Li, Geoff Pleiss, Zhuang Liu, John E. Hopcroft, and Kilian Q. Weinberger. Snapshot ensembles: Train 1, get M for free. InInternational Conference on Learning Represen- tations (ICLR), 2017. URLhttps://arxiv.org/abs/1704.00109. 13
Pith/arXiv arXiv 2017
-
[12]
Loss surfaces, mode connectivity, and fast ensembling of dnns
Timur Garipov, Pavel Izmailov, Dmitrii Podoprikhin, Dmitry Vetrov, and Andrew Gordon Wilson. Loss surfaces, mode connectivity, and fast ensembling of dnns. InProceedings of the 32nd International Conference on Neural Information Processing Systems, NIPS’18, page 8803–8812, Red Hook, NY, USA, 2018. Curran Associates Inc
2018
-
[13]
Accounting for variance in machine learning benchmarks
Xavier Bouthillier, Pierre Delaunay, Mirko Bronzi, Assya Trofimov, Brennan Nichyporuk, Justin Szeto, Nazanin Mohammadi Sepahvand, Edward Raff, Kanika Madan, Vikram Voleti, Samira Ebrahimi Kahou, Vincent Michalski, Tal Arbel, Chris Pal, Gael Varoquaux, and Pascal Vincent. Accounting for variance in machine learning benchmarks. In A. Smola, A. Dimakis, and ...
-
[14]
URLhttps://proceedings.mlsys.org/paper_files/paper/2021/file/ 0184b0cd3cfb185989f858a1d9f5c1eb-Paper.pdf
2021
-
[15]
Cecilia Summers and Michael J. Dinneen. Nondeterminism and instability in neural network optimization, 2021. URLhttps://arxiv.org/abs/2103.04514
arXiv 2021
-
[16]
David J. C. MacKay.Bayesian Interpolation, pages 39–66. Springer Netherlands, Dordrecht,
-
[17]
doi: 10.1007/978-94-017-2219-3_3
ISBN 978-94-017-2219-3. doi: 10.1007/978-94-017-2219-3_3. URLhttps://doi.or g/10.1007/978-94-017-2219-3_3
-
[18]
Neal.Bayesian Learning for Neural Networks
Radford M. Neal.Bayesian Learning for Neural Networks. Springer, 1996
1996
-
[19]
URL https: //doi.org/10.1038/s41586-024-07566-y
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Nicolas Papernot, Ross Anderson, and Yarin Gal. AI models collapse when trained on recursively generated data.Nature, 631(8022):755– 759, 2024. doi: 10.1038/s41586-024-07566-y
-
[20]
Lipton, Michael Tschannen, Laurent Itti, and Anima Anand- kumar
Tommaso Furlanello, Zachary C. Lipton, Michael Tschannen, Laurent Itti, and Anima Anand- kumar. Born-again neural networks. InInternational Conference on Machine Learning (ICML),
-
[21]
URLhttps://arxiv.org/abs/1805.04770
-
[22]
Bartlett
Hossein Mobahi, Mehrdad Farajtabar, and Peter L. Bartlett. Self-distillation amplifies reg- ularization in Hilbert space. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[23]
URLhttps://arxiv.org/abs/2002.05715
arXiv 2002
-
[24]
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah D. Goodman. STaR: Bootstrapping reasoning with reasoning. InAdvances in Neural Information Processing Systems (NeurIPS), 2022. URL https://arxiv.org/abs/2203.14465
arXiv 2022
-
[25]
Reinforced self-training (rest) for language modeling, 2023
Caglar Gulcehre, Tom Le Paine, Srivatsan Srinivasan, Ksenia Konyushkova, Lotte Weerts, Abhishek Sharma, Aditya Siddhant, Alex Ahern, Miaosen Wang, Chenjie Gu, Wolfgang Macherey, Arnaud Doucet, Orhan Firat, and Nando de Freitas. Reinforced self-training (rest) for language modeling, 2023. URLhttps://arxiv.org/abs/2308.08998
Pith/arXiv arXiv 2023
-
[26]
Textbooks are all you need, 2023
Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee, and Yuanzhi Li. Textbooks are all you need, 2023. URL https://arxiv....
Pith/arXiv arXiv 2023
-
[27]
The FineWeb datasets: Decanting the web for the finest text data at scale
Guilherme Penedo, Hynek Kydlíˇ cek, Loubna Ben Allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro Von Werra, and Thomas Wolf. The FineWeb datasets: Decanting the web for the finest text data at scale. InThe Thirty-Eighth Conference on Neural Information 14 Processing Systems Datasets and Benchmarks Track, 2024. URLhttps://openreview.net/f orum...
2024
-
[28]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
Pith/arXiv arXiv 2018
-
[29]
PIQA: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. PIQA: Reasoning about physical commonsense in natural language. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 7432–7439, 2020. doi: 10.1609/aaai.v34i05.6239
-
[30]
Johannes Welbl, Nelson F. Liu, and Matt Gardner. Crowdsourcing multiple choice science questions. InProceedings of the 3rd Workshop on Noisy User-generated Text, pages 94–106, Copenhagen, Denmark, September 2017. Association for Computational Linguistics. doi: 10.18653/v1/W17-4413. URLhttps://aclanthology.org/W17-4413/
-
[31]
Neural network ensembles, cross validation, and active learning
Anders Krogh and Jesper Vedelsby. Neural network ensembles, cross validation, and active learning. InAdvances in Neural Information Processing Systems (NeurIPS), volume 7, pages 231–238, 1995
1995
-
[32]
SGDR: Stochastic gradient descent with warm restarts
Ilya Loshchilov and Frank Hutter. SGDR: Stochastic gradient descent with warm restarts. In International Conference on Learning Representations (ICLR), 2017
2017
-
[33]
Essentially no barriers in neural network energy landscape
Felix Draxler, Kambis Veschgini, Manfred Salmhofer, and Fred Hamprecht. Essentially no barriers in neural network energy landscape. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 1309–1318. PMLR, 10–15 Jul 2018. URLhttps://procee ...
2018
-
[34]
Averaging weights leads to wider optima and better generalization
Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. Averaging weights leads to wider optima and better generalization. InUncertainty in Artificial Intelligence (UAI), 2018
2018
-
[35]
Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, and Ludwig Schmidt
Mitchell Wortsman, Gabriel Ilharco, Samir Yitzhak Gadre, Rebecca Roelofs, Raphael Gontijo- Lopes, Ari S. Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, and Ludwig Schmidt. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time, 2022. URLhttps://arxiv.org/abs/2203 .05482
2022
-
[36]
Leslie N. Smith. General cyclical training of neural networks, 2022. URLhttps://arxiv. org/abs/2202.08835
arXiv 2022
-
[37]
Distilling the knowledge in a neural network,
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network,
-
[38]
URLhttps://arxiv.org/abs/1503.02531
-
[39]
Chenglin Yang, Lingxi Xie, Chi Su, and Alan L. Yuille. Snapshot distillation: Teacher-student optimization in one generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019
2019
-
[40]
Efficient knowledge distillation from model checkpoints
Chaofei Wang, Qisen Yang, Rui Huang, Shiji Song, and Gao Huang. Efficient knowledge distillation from model checkpoints. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, 15 pages 607–619. Curran Associates, Inc., 2022. URLhttps://proceedings.neurips.cc /paper_files/...
2022
-
[41]
David H. Wolpert. Stacked generalization.Neural Networks, 5(2):241–259, 1992. ISSN 0893-
1992
-
[42]
doi: https://doi.org/10.1016/S0893-6080(05)80023-1. URLhttps://www.scienc edirect.com/science/article/pii/S0893608005800231. 16 A Overview of hyper-epoch pretraining floor peak Cycle 1Cycle 2Cycle 3Cycle 4Cycle 5Cycle C Training progress LR multiplier Multiple checkpoints harvestedfrom one training run using cyclic LR Standard cosine LRPer-cycle cyclic LR...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.