Quantifying Faithful Confidence Expression in Large Reasoning Models
Pith reviewed 2026-06-28 10:20 UTC · model grok-4.3
The pith
Large reasoning models struggle to faithfully express their internal confidence in long traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
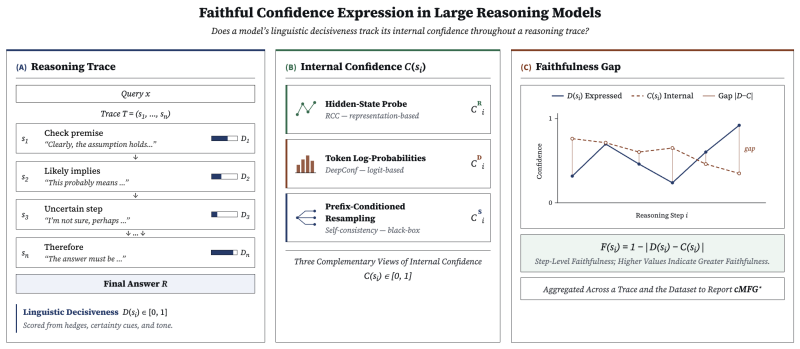
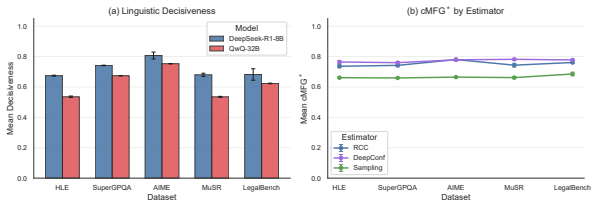
Faithful confidence expression is a significant challenge for LRMs. Reasoning behaviors do not automatically translate to improved FC, and prompt interventions for non-reasoning models do not improve faithfulness in the reasoning setting. The introduced framework analyzes linguistic decisiveness relative to internal uncertainty from token probabilities, hidden states, and sampled response consistency, using prefix-conditioned sampling.
What carries the argument
Framework for quantifying FC by analyzing linguistic decisiveness relative to three sources of internal uncertainty with prefix-conditioned sampling to control for trace variations.
If this is right
- FC is established as a distinct reliability and alignment target for LRMs.
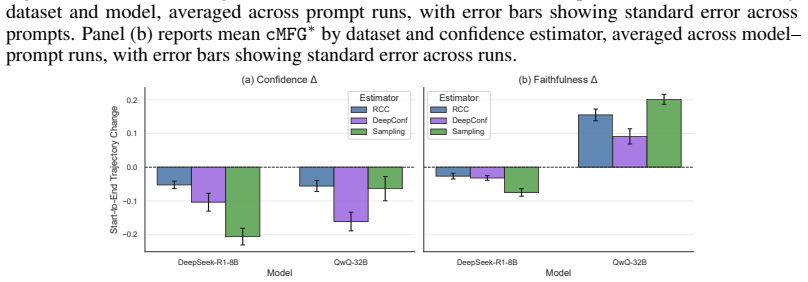
- Extended reasoning does not inherently lead to better confidence faithfulness.
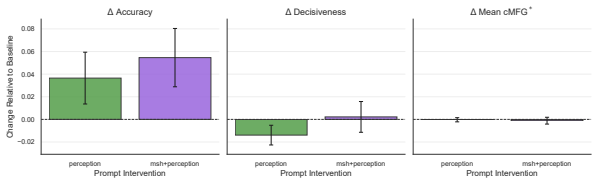
- Prompt interventions effective for non-reasoning models fail to improve FC in LRMs.
- Multiple confidence estimators can produce divergent assessments of the same traces.
Where Pith is reading between the lines
- High-stakes deployments of LRMs may require additional safeguards against over-trust in apparent confidence.
- New training approaches could aim to directly optimize alignment between internal states and linguistic expressions of certainty.
- The divergence in estimators suggests potential value in combining multiple uncertainty signals for more robust assessment.
Load-bearing premise
The three sources of internal uncertainty provide a reliable proxy for the model's intrinsic confidence that can be compared to its linguistic decisiveness.
What would settle it
Showing that linguistic decisiveness in LRM traces consistently aligns with the combined internal uncertainty measures on multiple datasets would contradict the claim that FC is a significant challenge.
Figures
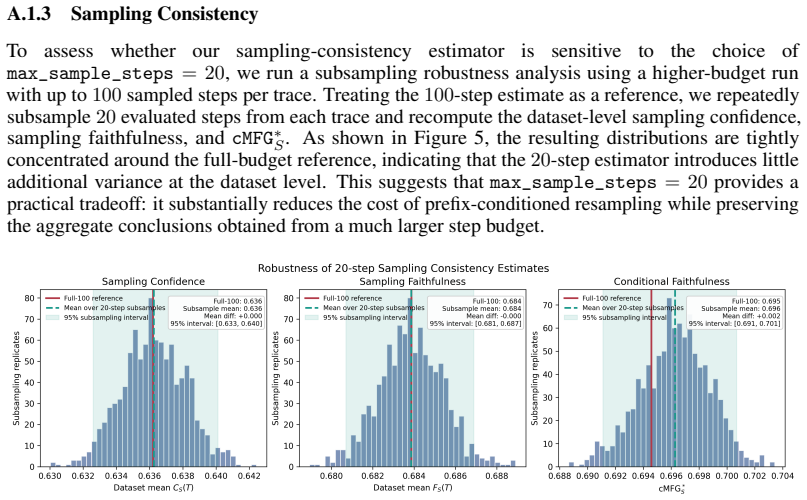


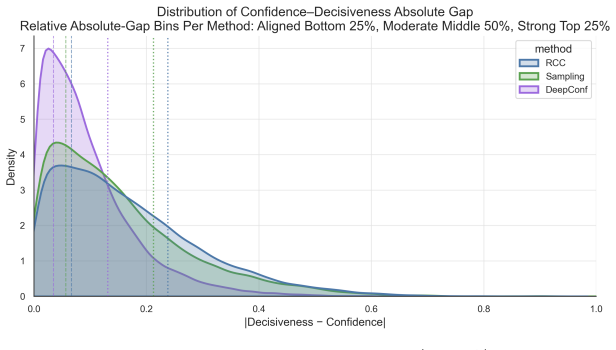
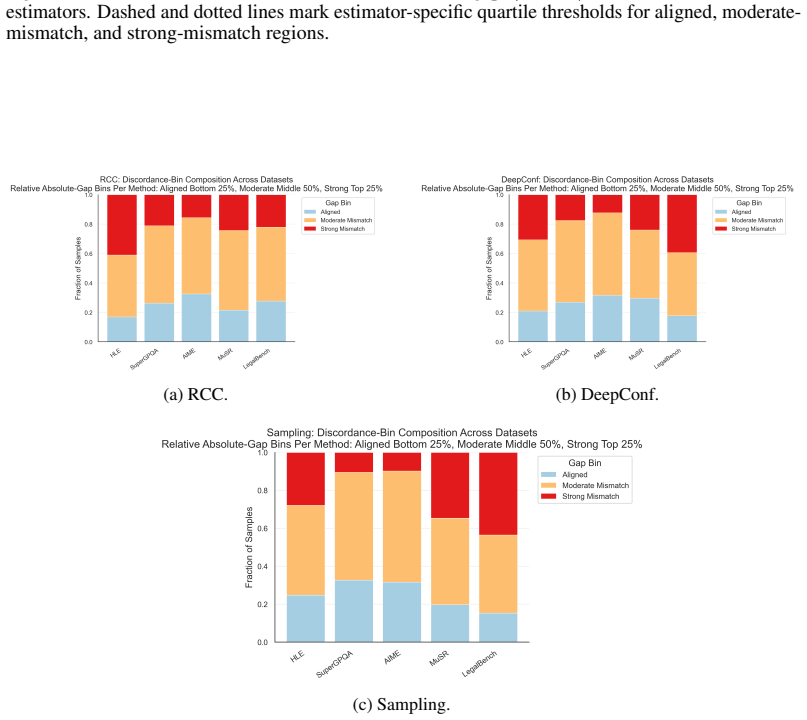
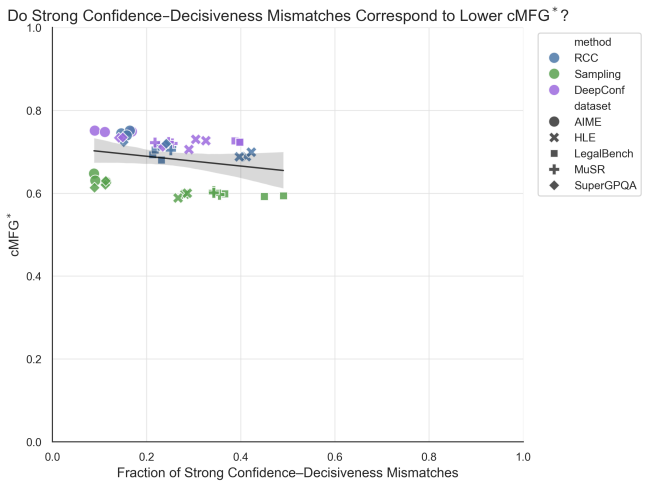
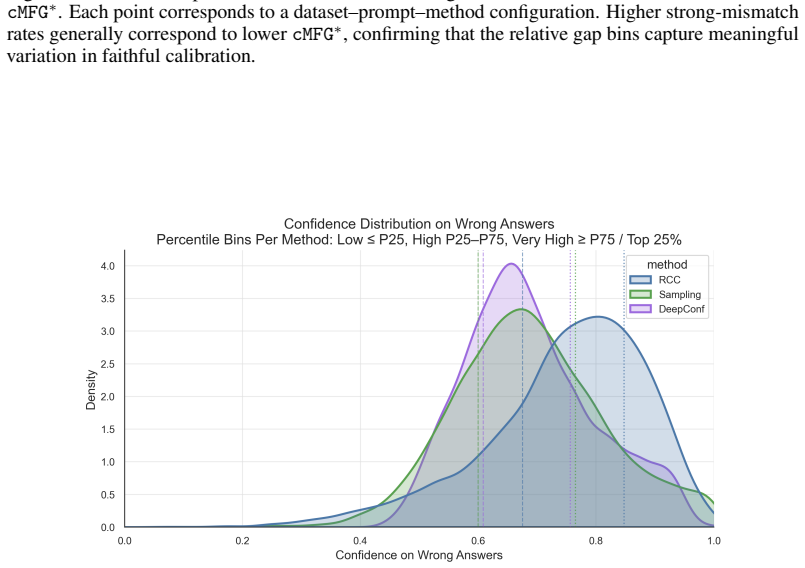
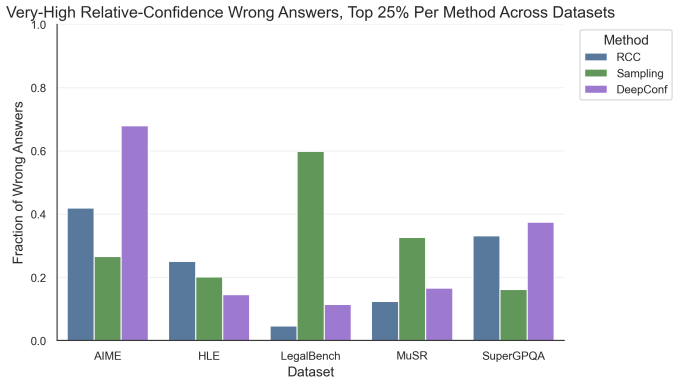
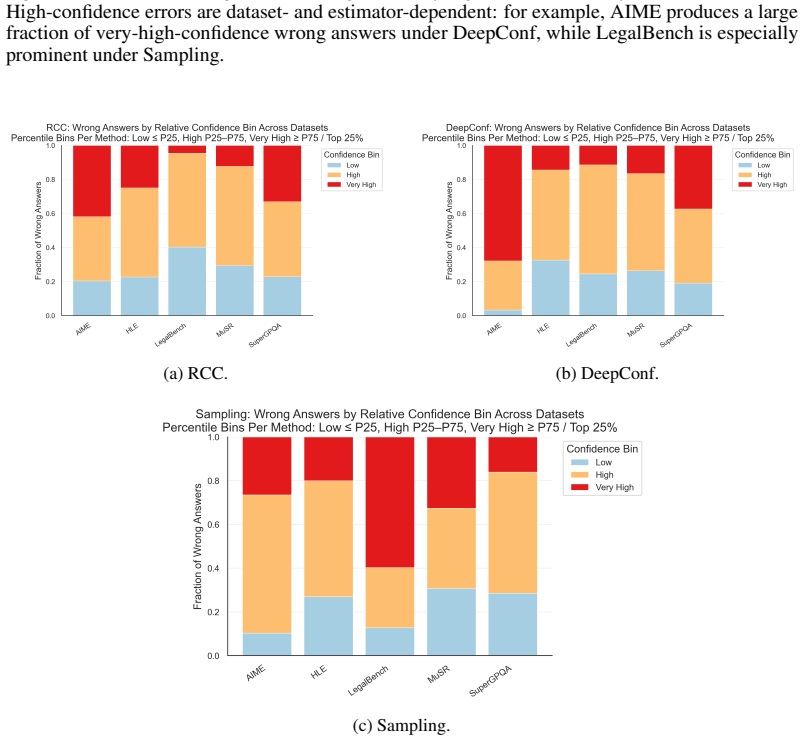
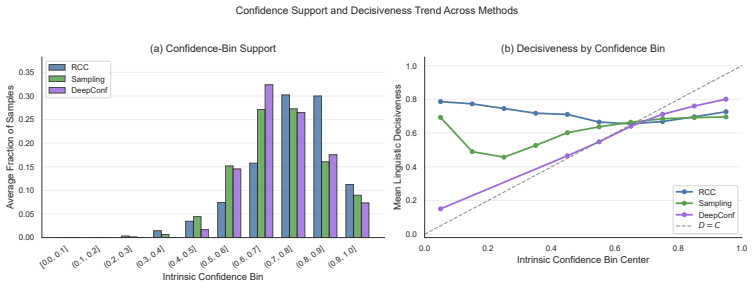
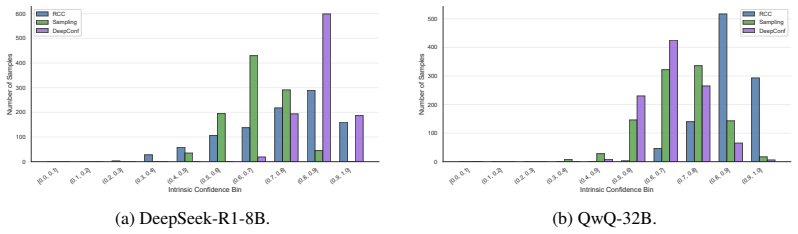
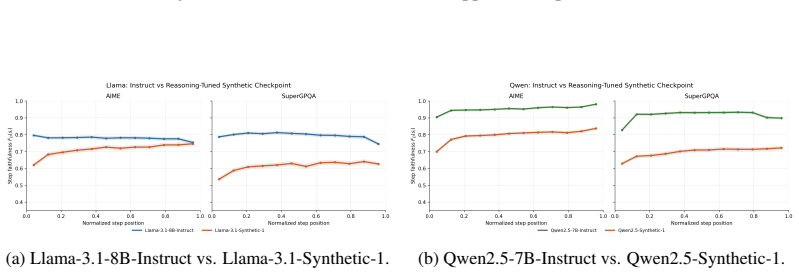
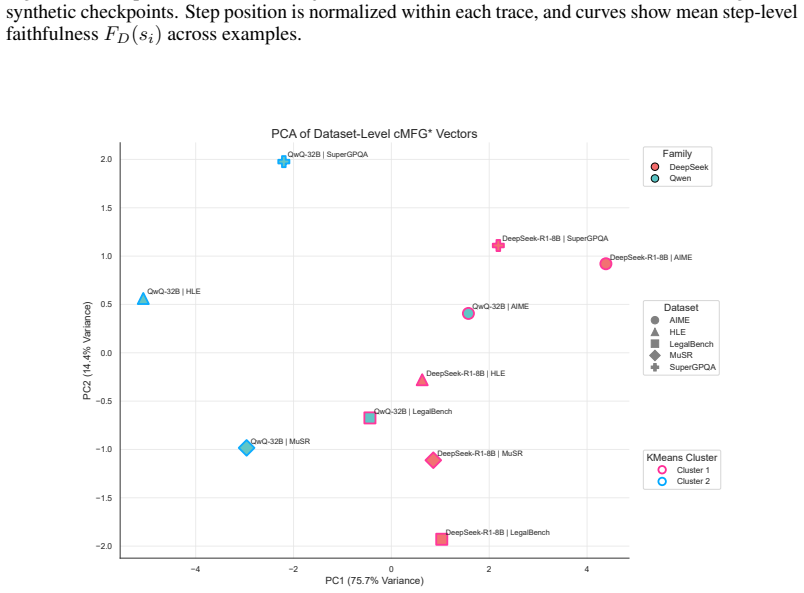
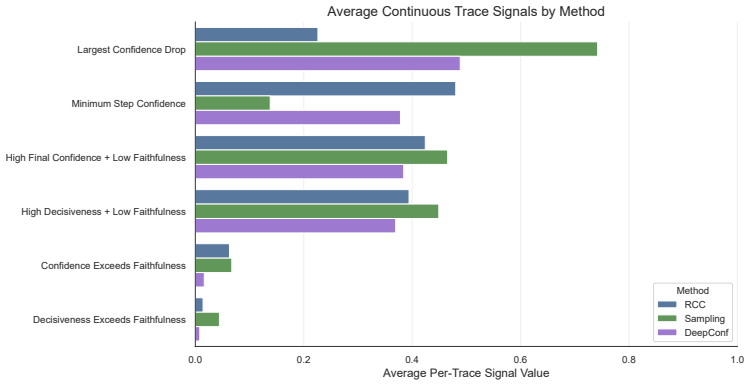
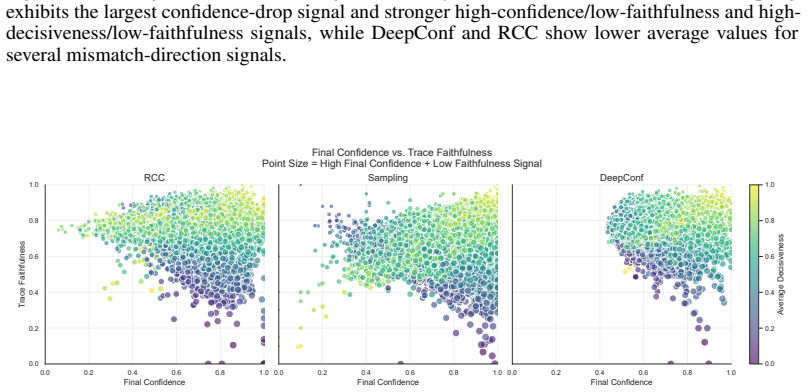
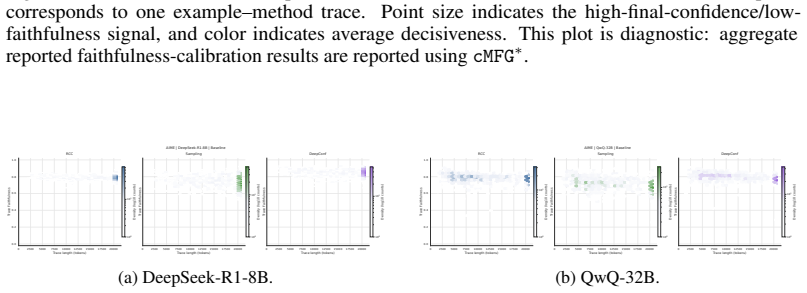

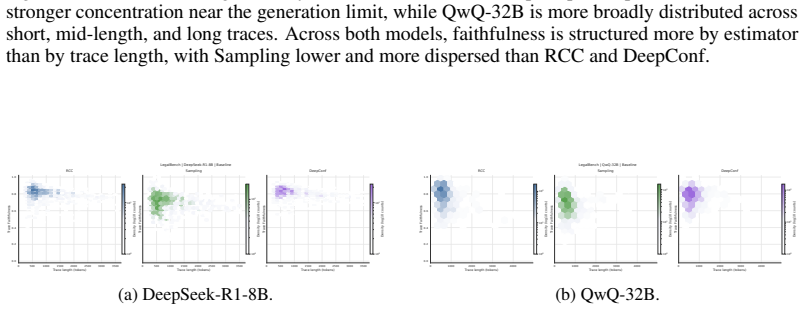
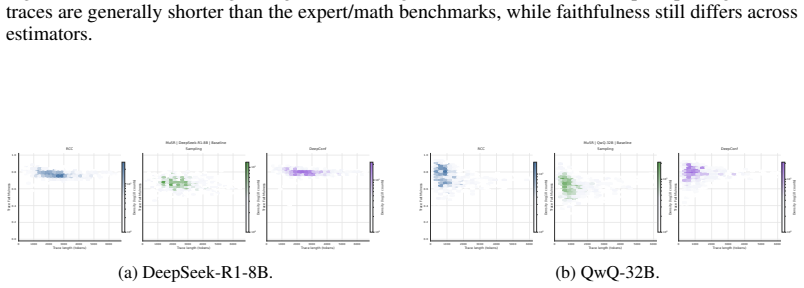
read the original abstract
Reliable uncertainty communication is critical to the trustworthiness of LLMs, yet faithful calibration (FC)--the alignment between models' intrinsic and (linguistically) expressed confidence--is a persistent failure mode. This challenge is key for large reasoning models (LRMs), whose extended reasoning traces are often interpreted by users as evidence of deliberation, competence, and confidence. Despite the importance of FC and wide usage of LRMs, the extent to which LRMs can faithfully express their confidence remains poorly understood. Moreover, the prevailing paradigm to measure FC does not generalize well to the long chain-of-thought outputs generated by LRMs, which tend to lack clear step boundaries, involve inconsistent step structure, and encode complex conditional dependencies throughout the trace--complicating estimation of intrinsic confidence. To address this challenge, we introduce a novel framework to systematically quantify FC of LRMs. Our framework analyzes linguistic decisiveness relative to three sources of internal uncertainty, based on token probabilities, hidden states, and sampled response consistency. We also devise a prefix-conditioned sampling approach to control for conditional and structural variation across traces. Applying our framework to a diverse suite of leading models, datasets, and prompts, we find that faithful confidence expression is a significant challenge for LRMs. Reasoning behaviors do not automatically translate to improved FC, and prompt interventions for non-reasoning models do not improve faithfulness in the reasoning setting. Different confidence estimators further produce divergent assessments of the same traces, revealing fragility in prior evaluation methodologies. Taken together, our work establishes FC as a distinct reliability and alignment target for LRMs, particularly as such systems are increasingly deployed in high-stakes contexts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that faithful confidence expression (FC) remains a significant challenge for large reasoning models (LRMs) despite their extended chain-of-thought traces. It introduces a framework that measures linguistic decisiveness against three internal uncertainty sources (token probabilities, hidden states, and sampled response consistency) and employs prefix-conditioned sampling to handle variable trace structure and conditional dependencies. Experiments across models, datasets, and prompts show that reasoning behaviors do not improve FC, prompt interventions effective for non-reasoning models fail to transfer, and different estimators yield divergent assessments of the same traces.
Significance. If the proxy measurements are valid, the work establishes FC as a distinct reliability target for LRMs in high-stakes deployment, separate from general reasoning capability. The framework's handling of long, unstructured traces addresses a methodological gap in prior calibration studies, and the finding of estimator fragility highlights limitations in existing evaluation approaches.
major comments (3)
- [§3] §3 (Framework): The central claim of poor FC rests on treating the joint distribution over token probabilities, hidden-state aggregates, and prefix-conditioned consistency samples as a reliable proxy for the model's intrinsic epistemic uncertainty about the final answer. In traces flagged by the authors as lacking clear boundaries and containing conditional dependencies, these signals may capture only local or entangled uncertainty; without an explicit validation (e.g., correlation with downstream correctness or an external oracle), misalignment with linguistic decisiveness could be measurement artifact rather than evidence of a faithfulness deficit.
- [§5] §5 (Results on estimator divergence): The observation that different confidence estimators produce divergent FC assessments is presented as evidence of fragility in prior methodologies. However, this same divergence undermines the robustness of the paper's own primary conclusions unless the authors demonstrate which estimator (or combination) best tracks correctness on the evaluated tasks; the current presentation leaves open whether the reported poor FC is estimator-specific.
- [§4.3] §4.3 (Prefix-conditioned sampling): The method is introduced to control for structural variation, yet the paper does not report an ablation showing that the controlled samples materially change the FC estimates relative to unconditional sampling. If the prefix conditioning does not demonstrably reduce the entanglement noted in the skeptic's concern, the control may be insufficient to support the claim that reasoning traces exhibit intrinsically poor faithfulness.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from one or two concrete quantitative examples (e.g., a specific FC score or divergence value) to ground the high-level claims before the reader reaches the methods.
- [§3] Notation for the three uncertainty sources is introduced without an explicit summary table; a small table listing each source, its mathematical definition, and how linguistic decisiveness is compared would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the scope and robustness of our framework. We address each major comment below and outline planned revisions where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (Framework): The central claim of poor FC rests on treating the joint distribution over token probabilities, hidden-state aggregates, and prefix-conditioned consistency samples as a reliable proxy for the model's intrinsic epistemic uncertainty about the final answer. In traces flagged by the authors as lacking clear boundaries and containing conditional dependencies, these signals may capture only local or entangled uncertainty; without an explicit validation (e.g., correlation with downstream correctness or an external oracle), misalignment with linguistic decisiveness could be measurement artifact rather than evidence of a faithfulness deficit.
Authors: We agree that explicit validation against downstream correctness would strengthen the interpretation. Our proxies follow standard practice in calibration literature, where token probabilities, hidden-state norms, and consistency under sampling are treated as indicators of internal uncertainty. The core claim is that linguistic decisiveness fails to align with these signals, which we interpret as a faithfulness gap by definition. To address the concern directly, we will add a new subsection discussing the choice of proxies, their known limitations in long traces, and a supplementary correlation analysis with answer correctness on a subset of tasks. This will clarify that the observed misalignment is not solely an artifact. revision: partial
-
Referee: [§5] §5 (Results on estimator divergence): The observation that different confidence estimators produce divergent FC assessments is presented as evidence of fragility in prior methodologies. However, this same divergence undermines the robustness of the paper's own primary conclusions unless the authors demonstrate which estimator (or combination) best tracks correctness on the evaluated tasks; the current presentation leaves open whether the reported poor FC is estimator-specific.
Authors: The divergence is reported precisely to demonstrate fragility in existing evaluation approaches, as stated in the abstract and §5. Across all three estimators, we observe consistent poor alignment between linguistic decisiveness and internal signals, supporting the claim that FC remains a challenge independent of any single estimator. We will revise §5 to explicitly state that the poor-FC finding holds across estimators (with quantitative support) and add a brief analysis showing that no single estimator reverses the overall conclusion of misalignment. This removes ambiguity about estimator-specificity. revision: partial
-
Referee: [§4.3] §4.3 (Prefix-conditioned sampling): The method is introduced to control for structural variation, yet the paper does not report an ablation showing that the controlled samples materially change the FC estimates relative to unconditional sampling. If the prefix conditioning does not demonstrably reduce the entanglement noted in the skeptic's concern, the control may be insufficient to support the claim that reasoning traces exhibit intrinsically poor faithfulness.
Authors: We acknowledge that an explicit ablation comparing prefix-conditioned versus unconditional sampling is missing and would directly address this concern. We will add this ablation in the revised §4.3 (and corresponding appendix), reporting the difference in FC scores and entanglement metrics. Preliminary internal checks indicate that prefix conditioning does reduce variance attributable to structural differences, but we will include the full results to substantiate the method's contribution. revision: yes
Circularity Check
No circularity detected in framework or claims
full rationale
The paper introduces a measurement framework that compares linguistic decisiveness against three separately motivated internal uncertainty signals (token probabilities, hidden states, and response consistency) plus a prefix-conditioned sampling control. None of these reduce to each other by definition, nor are any presented as fitted parameters that are then relabeled as predictions. No self-citation chains, uniqueness theorems, or ansatzes imported from prior author work appear as load-bearing steps in the abstract or described methodology. The derivation therefore remains self-contained and does not collapse to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linguistic decisiveness in reasoning traces can be aligned with internal model uncertainty sources
Reference graph
Works this paper leans on
-
[1]
David V Budescu and Thomas S Wallsten. Consistency in interpretation of probabilistic phrases.Organizational Behavior and Human Decision Processes, 36(3):391–405, 1985. ISSN 0749-5978. doi: https://doi.org/10.1016/0749-5978(85)90007-X. URL https://www. sciencedirect.com/science/article/pii/074959788590007X
-
[2]
Carrie J. Cai, Samantha Winter, David Steiner, Lauren Wilcox, and Michael Terry. "hello ai": Uncovering the onboarding needs of medical practitioners for human-ai collaborative decision-making.Proc. ACM Hum.-Comput. Interact., 3(CSCW), November 2019. doi: 10.1145/3359206. URLhttps://doi.org/10.1145/3359206
-
[3]
A benchmark of expert-level academic questions to assess AI capabilities.Nature, 649:1139–1146, 2026
Center for AI Safety, Scale AI, and HLE Contributors Consortium. A benchmark of expert-level academic questions to assess AI capabilities.Nature, 649:1139–1146, 2026. doi: 10.1038/ s41586-025-09962-4. URLhttps://arxiv.org/abs/2501.14249
Pith/arXiv arXiv 2026
-
[4]
Quantifying uncertainty in answers from any language model and enhancing their trustworthiness
Jiuhai Chen and Jonas Mueller. Quantifying uncertainty in answers from any language model and enhancing their trustworthiness. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pages 5186–5200, Bangkok, Thailand, August
-
[5]
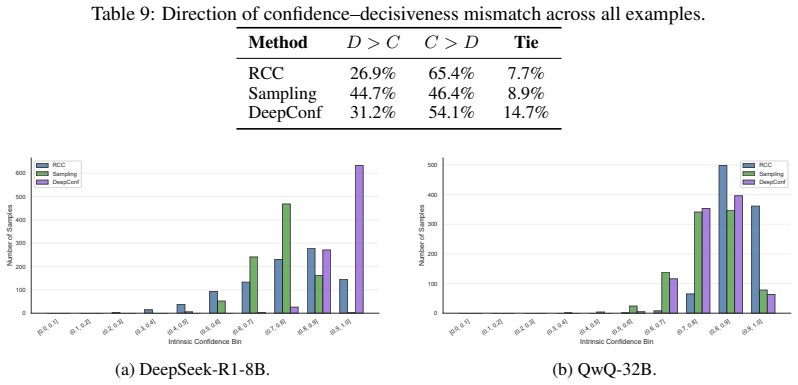
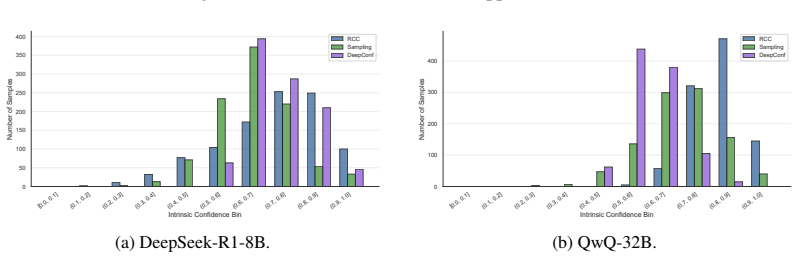
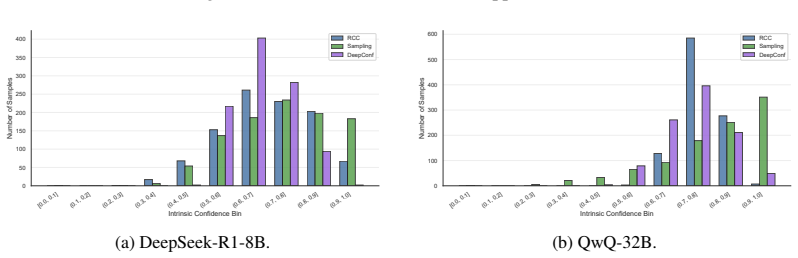
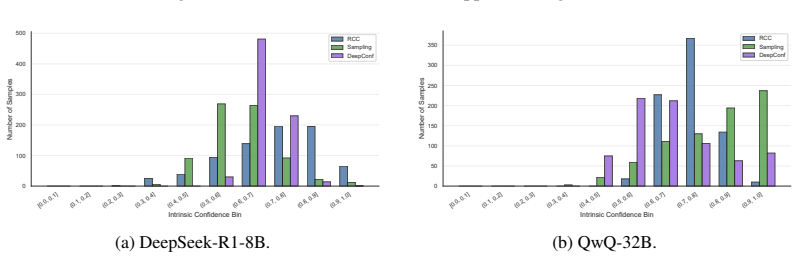
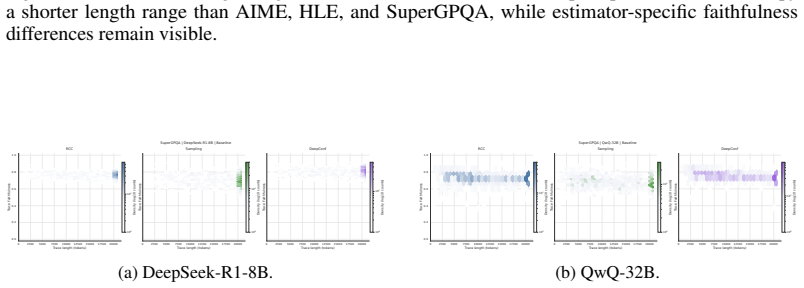
doi: 10.18653/v1/2024.acl-long.283
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.283. URL https://aclanthology.org/2024.acl-long.283/
-
[6]
Bowman, Jan Leike, Jared Kaplan, and Ethan Perez
Yanda Chen, Joe Benton, Ansh Radhakrishnan, Jonathan Uesato, Carson Denison, John Schul- man, Arushi Somani, Peter Hase, Misha Wagner, Fabien Roger, Vlad Mikulik, Samuel R. Bowman, Jan Leike, Jared Kaplan, and Ethan Perez. Reasoning models don’t always say what they think, 2025. URLhttps://arxiv.org/abs/2505.05410
Pith/arXiv arXiv 2025
-
[7]
Matthew Dahl, Varun Magesh, Mirac Suzgun, and Daniel E. Ho. Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models, 2024
2024
-
[8]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025. URLhttps://arxiv.org/abs/2501.12948
Pith/arXiv arXiv 2025
-
[9]
Calibration of pre-trained transformers
Shrey Desai and Greg Durrett. Calibration of pre-trained transformers. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu, editors,Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 295–302, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main.21. URL https...
-
[10]
Communicating uncertainty using words and numbers
Mandeep Dhami and David Mandel. Communicating uncertainty using words and numbers. Trends in Cognitive Sciences, 26, 04 2022. doi: 10.1016/j.tics.2022.03.002
-
[11]
Aime_1983_2024 (revision 6283828), 2025
Di Zhang. Aime_1983_2024 (revision 6283828), 2025. URL https://huggingface.co/ datasets/di-zhang-fdu/AIME_1983_2024
2025
-
[12]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[13]
Bryan Eikema, Evgenia Ilia, José G. C. de Souza, Chrysoula Zerva, and Wilker Aziz. Teaching language models to faithfully express their uncertainty, 2025. URL https://arxiv.org/ abs/2510.12587
arXiv 2025
-
[14]
Perception of probability words — waf.cs.illinois.edu
Wade Fagen-Ulmschneider. Perception of probability words — waf.cs.illinois.edu. https:// waf.cs.illinois.edu/visualizations/Perception-of-Probability-Words/ . [Ac- cessed 07-05-2026]. 10
2026
-
[15]
Tairan Fu, Javier Conde, Gonzalo Martínez, María Grandury, and Pedro Reviriego. Multiple choice questions: Reasoning makes large language models (llms) more self-confident even when they are wrong, 2025. URLhttps://arxiv.org/abs/2501.09775
Pith/arXiv arXiv 2025
-
[16]
Deep think with confidence, 2025
Yichao Fu, Xuewei Wang, Yuandong Tian, and Jiawei Zhao. Deep think with confidence, 2025. URLhttps://arxiv.org/abs/2508.15260
Pith/arXiv arXiv 2025
-
[17]
A survey of confidence estimation and calibration in large language models
Jiahui Geng, Fengyu Cai, Yuxia Wang, Heinz Koeppl, Preslav Nakov, and Iryna Gurevych. A survey of confidence estimation and calibration in large language models. In Kevin Duh, Helena Gomez, and Steven Bethard, editors,Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technolog...
-
[18]
Epistemic integrity in large language models
Bijean Ghafouri, Shahrad Mohammadzadeh, James Zhou, Pratheeksha Nair, Jacob-Junqi Tian, Mayank Goel, Reihaneh Rabbany, Jean-François Godbout, and Kellin Pelrine. Epistemic integrity in large language models. InNeurips Safe Generative AI Workshop 2024, 2024. URL https://openreview.net/forum?id=o3wQbxRaKo
2024
-
[19]
Ho, Christopher Ré, Adam Chilton, Aditya Narayana, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel N
Neel Guha, Julian Nyarko, Daniel E. Ho, Christopher Ré, Adam Chilton, Aditya Narayana, Alex Chohlas-Wood, Austin Peters, Brandon Waldon, Daniel N. Rockmore, Diego Zambrano, Dmitry Talisman, Enam Hoque, Faiz Surani, Frank Fagan, Galit Sarfaty, Gregory M. Dickinson, Haggai Porat, Jason Hegland, Jessica Wu, Joe Nudell, Joel Niklaus, John Nay, Jonathan H. Cho...
2023
-
[20]
Weinberger
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. In Doina Precup and Yee Whye Teh, editors,Proceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 1321–1330. PMLR, 06–11 Aug 2017. URL https://proceedings.mlr.press/v70/ guo17a.html
2017
-
[21]
Llms should express uncertainty explicitly, 2026
Junyu Guo, Shangding Gu, Ming Jin, Costas Spanos, and Javad Lavaei. Llms should express uncertainty explicitly, 2026. URLhttps://arxiv.org/abs/2604.05306
Pith/arXiv arXiv 2026
-
[22]
Yi Hu, Jiaqi Gu, Ruxin Wang, Zijun Yao, Hao Peng, Xiaobao Wu, Jianhui Chen, Muhan Zhang, and Liangming Pan. Towards a mechanistic understanding of large reasoning models: A survey of training, inference, and failures, 2026. URLhttps://arxiv.org/abs/2601.19928
arXiv 2026
-
[23]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qian- glong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A survey on hallu- cination in large language models: Principles, taxonomy, challenges, and open questions. ACM Trans. Inf. Syst., 43(2), January 2025. ISSN 1046-8188. doi: 10.1145/3703155. URL https://doi.o...
-
[24]
Alon Jacovi and Yoav Goldberg. Towards faithfully interpretable NLP systems: How should we define and evaluate faithfulness? In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors,Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4198–4205, Online, July 2020. Association for Computational Li...
-
[25]
Chaeyun Jang, Moonseok Choi, Yegon Kim, Hyungi Lee, and Juho Lee. Verbalized confidence triggers self-verification: Emergent behavior without explicit reasoning supervision, 2025. URL https://arxiv.org/abs/2506.03723
arXiv 2025
-
[26]
Ziwei Ji, Lei Yu, Yeskendir Koishekenov, Yejin Bang, Anthony Hartshorn, Alan Schelten, Cheng Zhang, Pascale Fung, and Nicola Cancedda. Calibrating verbal uncertainty as a linear feature to reduce hallucinations.arXiv preprint arXiv:2503.14477, 2025. 11
arXiv 2025
-
[27]
The path of least resistance: Guiding llm reasoning trajectories with prefix consensus, 2026
Ishan Jindal, Sai Prashanth Akuthota, Jayant Taneja, and Sachin Dev Sharma. The path of least resistance: Guiding llm reasoning trajectories with prefix consensus, 2026. URL https://arxiv.org/abs/2601.21494
arXiv 2026
-
[28]
Johnson, Rachel S Goodman, J
Douglas B. Johnson, Rachel S Goodman, J. Randall Patrinely, Cosby A Stone, Eli Zimmerman, Rebecca Rigel Donald, Sam S Chang, Sean T Berkowitz, Avni P Finn, Eiman Jahangir, Eliza- beth A Scoville, Tyler Reese, Debra E. Friedman, Julie A. Bastarache, Yuri F van der Heijden, Jordan Wright, Nicholas Carter, Matthew R Alexander, Jennifer H Choe, Cody A Chastai...
2023
-
[29]
Language models (mostly) know what they know, 2022
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kravec,...
Pith/arXiv arXiv 2022
-
[30]
Reza Khanmohammadi, Erfan Miahi, Simerjot Kaur, Charese Smiley, Ivan Brugere, Kundan S Thind, and Mohammad M. Ghassemi. How reliable are confidence estimators for large reasoning models? a systematic benchmark on high-stakes domains. In Vera Demberg, Kentaro Inui, and Lluís Marquez, editors,Proceedings of the 19th Conference of the European Chapter of the...
-
[31]
Sunnie S. Y . Kim, Q. Vera Liao, Mihaela V orvoreanu, Stephanie Ballard, and Jennifer Wortman Vaughan. "i’m not sure, but...": Examining the impact of large language models’ uncertainty expression on user reliance and trust. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’24, page 822–835, New York, NY , USA,...
-
[32]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum? id=VD-AYtP0dve
2023
-
[33]
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, Kamil ˙e Lukoši¯ut˙e, Karina Nguyen, Newton Cheng, Nicholas Joseph, Nicholas Schiefer, Oliver Rausch, Robin Lar- son, Sam McCandlish, Sandipan Kundu, Saurav Kadavath, Shannon Yang, Thomas Henighan, Timothy ...
Pith/arXiv arXiv 2023
-
[34]
Demystifying scientific problem-solving in llms by probing knowledge and reasoning, 2026
Alan Li, Yixin Liu, Arpan Sarkar, Doug Downey, and Arman Cohan. Demystifying scientific problem-solving in llms by probing knowledge and reasoning, 2026. URL https://arxiv. org/abs/2508.19202
Pith/arXiv arXiv 2026
-
[35]
LegalAgentBench: Eval- uating LLM agents in legal domain
Haitao Li, Junjie Chen, Jingli Yang, Qingyao Ai, Wei Jia, Youfeng Liu, Kai Lin, Yueyue Wu, Guozhi Yuan, Yiran Hu, Wuyue Wang, Yiqun Liu, and Minlie Huang. LegalAgentBench: Eval- uating LLM agents in legal domain. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Associatio...
2025
-
[36]
Conftuner: Training large language models to express their confidence verbally, 2025
Yibo Li, Miao Xiong, Jiaying Wu, and Bryan Hooi. Conftuner: Training large language models to express their confidence verbally, 2025. URLhttps://arxiv.org/abs/2508.18847
arXiv 2025
-
[37]
Teaching models to express their uncertainty in words, 2022
Stephanie Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words, 2022. URLhttps://arxiv.org/abs/2205.14334
Pith/arXiv arXiv 2022
-
[38]
Gabrielle Kaili-May Liu, Gal Yona, Avi Caciularu, Idan Szpektor, Tim G. J. Rudner, and Arman Cohan. Metafaith: Faithful natural language uncertainty expression in llms, 2025. URL https://arxiv.org/abs/2505.24858
arXiv 2025
-
[39]
Qing Lyu, Marianna Apidianaki, and Chris Callison-Burch. Towards faithful model explanation in NLP: A survey.Computational Linguistics, 50(2):657–723, June 2024. doi: 10.1162/coli_a_ 00511. URLhttps://aclanthology.org/2024.cl-2.6/
-
[40]
Bogdan, Senthooran Rajamanoharan, and Neel Nanda
Uzay Macar, Paul C. Bogdan, Senthooran Rajamanoharan, and Neel Nanda. Thought branches: Interpreting llm reasoning requires resampling, 2026. URL https://arxiv.org/abs/2510. 27484
2026
-
[41]
SelfCheckGPT: Zero-resource black- box hallucination detection for generative large language models
Potsawee Manakul, Adian Liusie, and Mark Gales. SelfCheckGPT: Zero-resource black- box hallucination detection for generative large language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9004–9017, Singapore, December 2023. Association for Computa...
-
[42]
Recurrent confidence chain: Temporal-aware uncertainty quantification in large language models, 2026
Zhenjiang Mao and Anirudhh Venkat. Recurrent confidence chain: Temporal-aware uncertainty quantification in large language models, 2026. URL https://arxiv.org/abs/2601.13368
arXiv 2026
-
[43]
Zhenjiang Mao, Anirudhh Venkat, Artem Bisliouk, Akshat Kothiyal, Sindhura Kumbakonam Subramanian, Saithej Singhu, and Ivan Ruchkin. Confidence over time: Confidence calibration with temporal logic for large language model reasoning, 2026. URL https://arxiv.org/ abs/2601.13387
arXiv 2026
-
[44]
Synthetic-1: Two million collaboratively generated reasoning traces from deepseek-r1, 2025
Justus Mattern, Sami Jaghouar, Manveer Basra, Jannik Straube, Matthew Di Ferrante, Fe- lix Gabriel, Jack Min Ong, Vincent Weisser, and Johannes Hagemann. Synthetic-1: Two million collaboratively generated reasoning traces from deepseek-r1, 2025. URL https: //www.primeintellect.ai/blog/synthetic-1-release
2025
-
[45]
Do explanations generalize across large reasoning models?, 2026
Koyena Pal, David Bau, and Chandan Singh. Do explanations generalize across large reasoning models?, 2026. URLhttps://arxiv.org/abs/2601.11517
arXiv 2026
-
[46]
Cer: Confidence enhanced reasoning in llms, 2025
Ali Razghandi, Seyed Mohammad Hadi Hosseini, and Mahdieh Soleymani Baghshah. Cer: Confidence enhanced reasoning in llms, 2025. URL https://arxiv.org/abs/2502.14634
arXiv 2025
-
[47]
Mauricio Rivera, Jean-François Godbout, Reihaneh Rabbany, and Kellin Pelrine. Combining confidence elicitation and sample-based methods for uncertainty quantification in misinfor- mation mitigation. In Raúl Vázquez, Hande Celikkanat, Dennis Ulmer, Jörg Tiedemann, Swabha Swayamdipta, Wilker Aziz, Barbara Plank, Joris Baan, and Marie-Catherine de Marn- effe...
-
[48]
Prompting GPT-3 to be reliable
Chenglei Si, Zhe Gan, Zhengyuan Yang, Shuohang Wang, Jianfeng Wang, Jordan Lee Boyd- Graber, and Lijuan Wang. Prompting GPT-3 to be reliable. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum? id=98p5x51L5af
2023
-
[49]
Trust me, i’m wrong: High-certainty hallucinations in llms.arXiv preprint arXiv:2502.12964, 2025
Adi Simhi, Itay Itzhak, Fazl Barez, Gabriel Stanovsky, and Yonatan Belinkov. Trust me, i’m wrong: High-certainty hallucinations in llms.arXiv preprint arXiv:2502.12964, 2025. 13
arXiv 2025
-
[50]
Zhangde Song, Jieyu Lu, Yuanqi Du, Botao Yu, Thomas M. Pruyn, Yue Huang, Kehan Guo, Xiuzhe Luo, Yuanhao Qu, Yi Qu, Yinkai Wang, Haorui Wang, Jeff Guo, Jingru Gan, Parshin Shojaee, Di Luo, Andres M Bran, Gen Li, Qiyuan Zhao, Shao-Xiong Lennon Luo, Yuxuan Zhang, Xiang Zou, Wanru Zhao, Yifan F. Zhang, Wucheng Zhang, Shunan Zheng, Saiyang Zhang, Sartaaj Takri...
Pith/arXiv arXiv 2025
-
[51]
Musr: Testing the limits of chain-of-thought with multistep soft reasoning, 2024
Zayne Sprague, Xi Ye, Kaj Bostrom, Swarat Chaudhuri, and Greg Durrett. Musr: Testing the limits of chain-of-thought with multistep soft reasoning, 2024. URL https://arxiv.org/ abs/2310.16049
arXiv 2024
-
[52]
What large language models know and what people think they know.Nature Machine Intelligence, 7(2):221–231, 2025
Mark Steyvers, Heliodoro Tejeda, Aakriti Kumar, Catarina Belem, Sheer Karny, Xinyue Hu, Lukas W Mayer, and Padhraic Smyth. What large language models know and what people think they know.Nature Machine Intelligence, 7(2):221–231, 2025
2025
-
[53]
Seeing the reasoning: How llm rationales influence user trust and decision-making in factual verification tasks
Xin Sun, Shu Wei, Jos A Bosch, Isao Echizen, Saku Sugawara, and Abdallah El Ali. Seeing the reasoning: How llm rationales influence user trust and decision-making in factual verification tasks. InProceedings of the Extended Abstracts of the 2026 CHI Conference on Human Factors in Computing Systems, pages 1–7, 2026
2026
-
[54]
Supergpqa: Scaling llm evaluation across 285 graduate disciplines, 2025
M-A-P Team, Xinrun Du, Yifan Yao, Kaijing Ma, Bingli Wang, Tianyu Zheng, Kang Zhu, Minghao Liu, Yiming Liang, Xiaolong Jin, Zhenlin Wei, Chujie Zheng, Kaixin Deng, Shian Jia, Sichao Jiang, Yiyan Liao, Rui Li, Qinrui Li, Sirun Li, Yizhi Li, Yunwen Li, Dehua Ma, Yuansheng Ni, Haoran Que, Qiyao Wang, Zhoufutu Wen, Siwei Wu, Tianshun Xing, Ming Xu, Zhenzhu Ya...
Pith/arXiv arXiv 2025
-
[55]
Qwen2.5: A party of foundation models, September 2024
Qwen Team. Qwen2.5: A party of foundation models, September 2024. URL https:// qwenlm.github.io/blog/qwen2.5/
2024
-
[56]
Qwq-32b: Embracing the power of reinforcement learning, March 2025
Qwen Team. Qwq-32b: Embracing the power of reinforcement learning, March 2025. URL https://qwenlm.github.io/blog/qwq-32b/
2025
-
[57]
A comprehensive survey of hallucination mitigation techniques in large language models
SM Tonmoy, SM Zaman, Vinija Jain, Anku Rani, Vipula Rawte, Aman Chadha, and Amitava Das. A comprehensive survey of hallucination mitigation techniques in large language models. arXiv preprint arXiv:2401.01313, 6, 2024
Pith/arXiv arXiv 2024
-
[58]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. Language models don’t always say what they think: unfaithful explanations in chain-of-thought prompting. InProceed- ings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA, 2023. Curran Associates Inc
2023
-
[59]
Measuring chain of thought faithfulness by unlearning reasoning steps
Martin Tutek, Fateme Hashemi Chaleshtori, Ana Marasovic, and Yonatan Belinkov. Measuring chain of thought faithfulness by unlearning reasoning steps. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Confer- ence on Empirical Methods in Natural Language Processing, pages 9935–9960, Suzhou, 1...
-
[60]
Reasoning models will sometimes lie about their reason- ing, 2026
William Walden and Miriam Wanner. Reasoning models will sometimes lie about their reason- ing, 2026. URLhttps://arxiv.org/abs/2601.07663
Pith/arXiv arXiv 2026
-
[61]
Preferences and reasons for communicating probabilistic information in verbal or numerical terms.Bulletin of the Psychonomic Society, 31(2):135–138, 1993
Thomas S Wallsten, David V Budescu, Rami Zwick, and Steven M Kemp. Preferences and reasons for communicating probabilistic information in verbal or numerical terms.Bulletin of the Psychonomic Society, 31(2):135–138, 1993
1993
-
[62]
A survey of uncertainty estimation methods on large language models
Zhiqiu Xia, Jinxuan Xu, Yuqian Zhang, and Hang Liu. A survey of uncertainty estimation methods on large language models. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 2025, pages 21381–21396, Vienna, Austria, July 2025. Association for Computational Li...
-
[63]
On hallucination and predictive uncertainty in con- ditional language generation
Yijun Xiao and William Yang Wang. On hallucination and predictive uncertainty in con- ditional language generation. In Paola Merlo, Jorg Tiedemann, and Reut Tsarfaty, edi- tors,Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 2734–2744, Online, April 2021. Associ- ation for Com...
-
[64]
Gal Yona, Roee Aharoni, and Mor Geva. Can large language models faithfully express their intrinsic uncertainty in words? In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 7752–7764, Miami, Florida, USA, November 2024. Association for Computational Li...
-
[65]
Reasoning models better express their confidence,
Dongkeun Yoon, Seungone Kim, Sohee Yang, Sunkyoung Kim, Soyeon Kim, Yongil Kim, Eunbi Choi, Yireun Kim, and Minjoon Seo. Reasoning models better express their confidence,
-
[66]
URLhttps://arxiv.org/abs/2505.14489
-
[67]
Yanbo Zhang, Sumeer A. Khan, Adnan Mahmud, Huck Yang, Alexander Lavin, Michael Levin, Jeremy Frey, Jared Dunnmon, James Evans, Alan Bundy, Saso Dzeroski, Jesper Tegner, and Hector Zenil. Advancing the scientific method with large language models: From hypothesis to discovery, 2025. URLhttps://arxiv.org/abs/2505.16477
arXiv 2025
-
[68]
Wired for overconfidence: A mechanistic perspective on inflated verbalized confidence in llms, 2026
Tianyi Zhao, Yinhan He, Wendy Zheng, Yujie Zhang, and Chen Chen. Wired for overconfidence: A mechanistic perspective on inflated verbalized confidence in llms, 2026. URL https: //arxiv.org/abs/2604.01457
arXiv 2026
-
[69]
Navigating the grey area: How expressions of uncertainty and overconfidence affect language models
Kaitlyn Zhou, Dan Jurafsky, and Tatsunori Hashimoto. Navigating the grey area: How ex- pressions of uncertainty and overconfidence affect language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Meth- ods in Natural Language Processing, pages 5506–5524, Singapore, December 2023. As- sociation f...
-
[70]
Hwang, Xiang Ren, and Maarten Sap
Kaitlyn Zhou, Jena D. Hwang, Xiang Ren, and Maarten Sap. Relying on the unreliable: The impact of language models’ reluctance to express uncertainty. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3623–3643, Bangkok, Thailand, ...
-
[71]
Hwang, Xiang Ren, Nouha Dziri, Dan Jurafsky, and Maarten Sap
Kaitlyn Zhou, Jena D. Hwang, Xiang Ren, Nouha Dziri, Dan Jurafsky, and Maarten Sap. REL- A.I.: An interaction-centered approach to measuring human-LM reliance. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Proceedings of the 2025 Conference of the Nations of 15 the Americas Chapter of the Association for Computational Linguistics: Human Language Tec...
2025
-
[72]
Association for Computational Linguistics. ISBN 979-8-89176-189-6. doi: 10.18653/v1/ 2025.naacl-long.556. URLhttps://aclanthology.org/2025.naacl-long.556/
-
[73]
Large language models for disease diagnosis: A scoping review.npj Artificial Intelligence, 1(1):9, 2025
Shuang Zhou, Zidu Xu, Mian Zhang, Chunpu Xu, Yawen Guo, Zaifu Zhan, Yi Fang, Sirui Ding, Jiashuo Wang, Kaishuai Xu, et al. Large language models for disease diagnosis: A scoping review.npj Artificial Intelligence, 1(1):9, 2025
2025
-
[74]
Alf C. Zimmer. Verbal vs. numerical processing of subjective probabilities.Advances in psychology, 16:159–182, 1983. URL https://api.semanticscholar.org/CorpusID: 120835208. A Methodological Details A.1 Intrinsic Confidence Estimation A.1.1 RCC We implement RCC confidence estimation following the approach of Mao and Venkat[41]. Let the generated reasoning...
arXiv 1983
-
[75]
Each figure compares DeepSeek-R1-8B and QwQ-32B on one dataset, plotting reasoning-trace length against trace-level faithfulness under RCC, Sampling Consistency, and DeepConf. The goal is to check whether the trajectory patterns in Figure 3 can be visually attributed to trace length alone. Overall, trace length varies substantially across datasets and mod...
arXiv 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.